




Fiddler抓包工具
一、Fiddler工具使用
Fiddler简介:
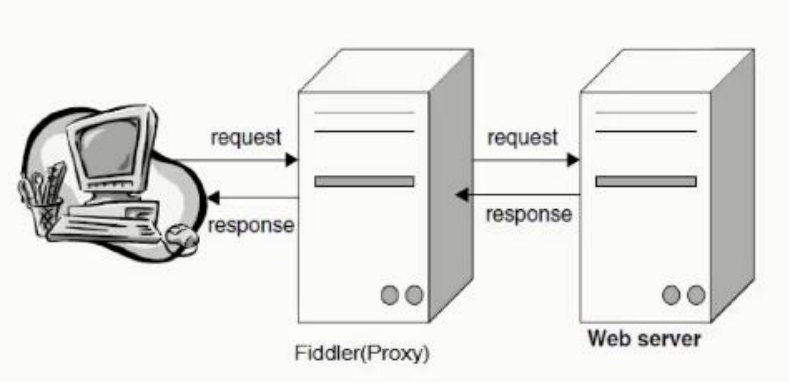
Fiddler 是强大的抓包工具,它的原理是以web代理服务器的形式进行工作的,使用的 代理地址是:127.0.0.1,端口默认为8888,我们也可以通过设置进行修改。代理就是在客户 端和服务器之间设置一道关卡,客户端先将请求数据发送出去后,代理服务器会将数据包进 行拦截,代理服务器再冒充客户端发送数据到服务器;同理,服务器将响应数据返回,代理服务器也会将数据拦截,再返回给客户端。其工作原理图如下图所示:
Fiddler配置流程:
1、打开tools–>>options
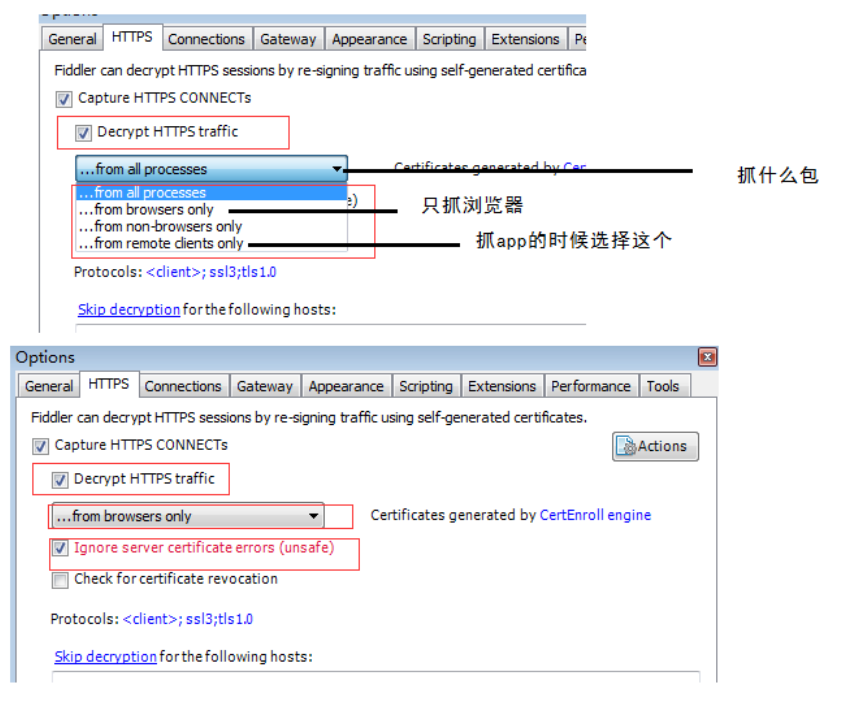
2、配置https
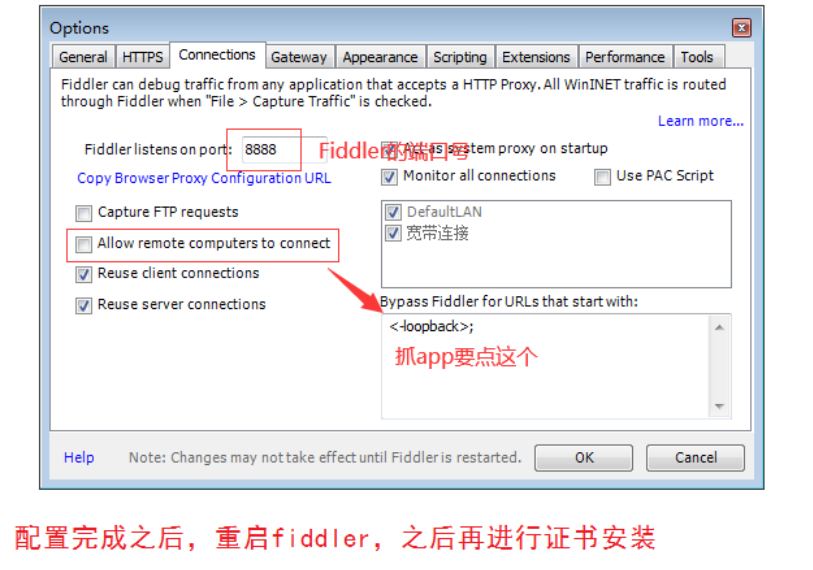
3、配置connections
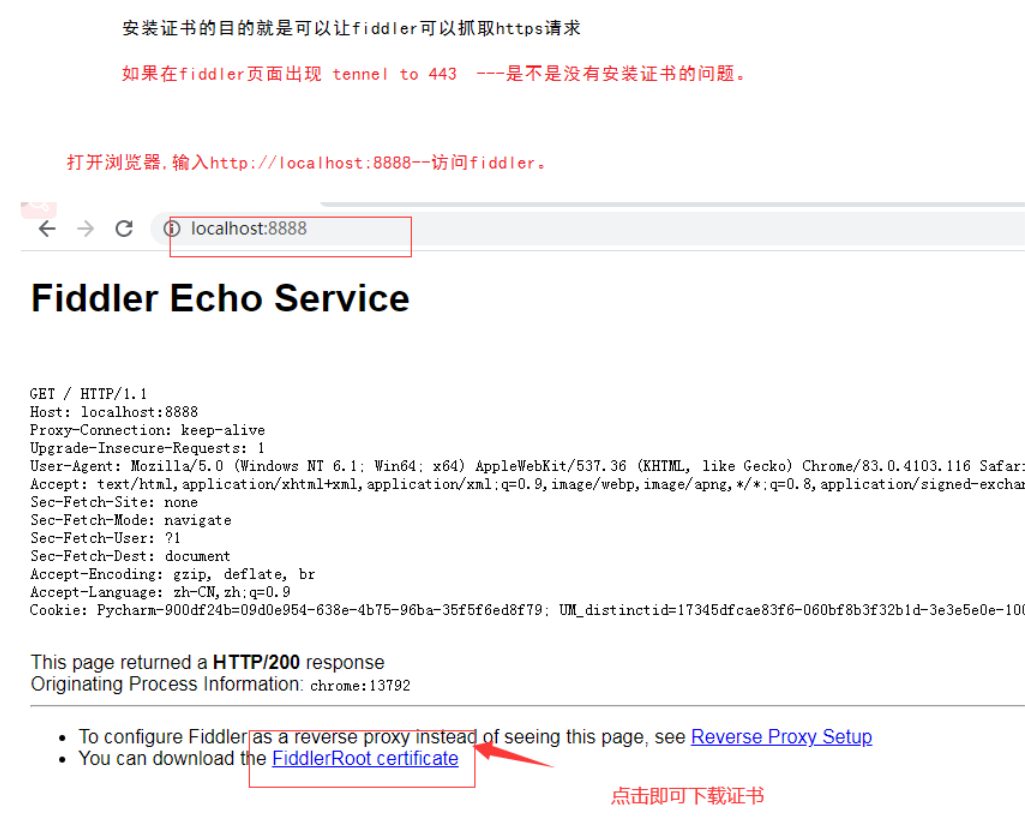
4、安装证书
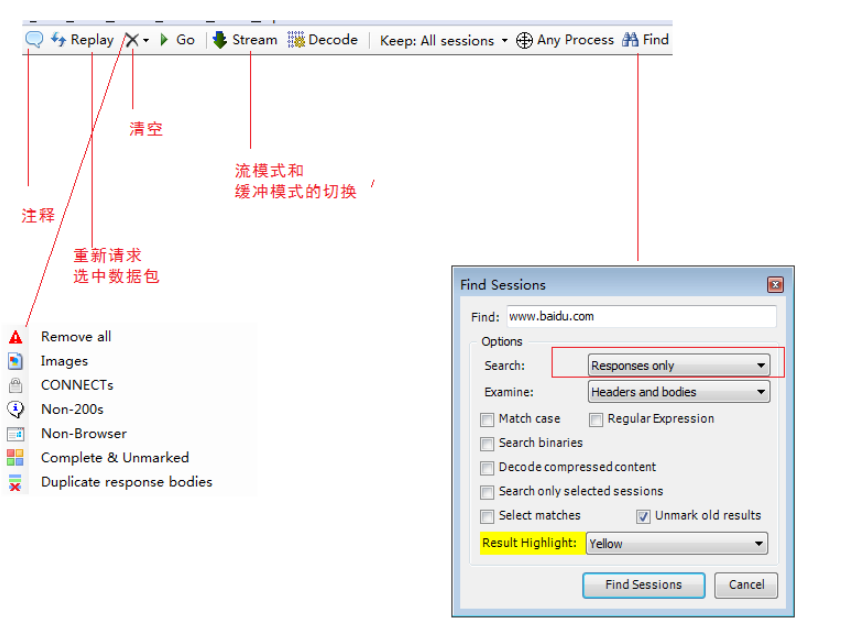
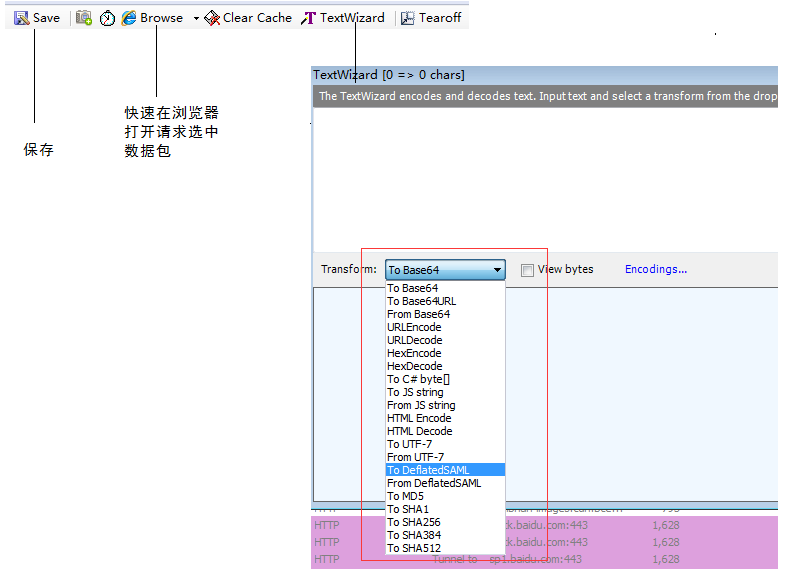
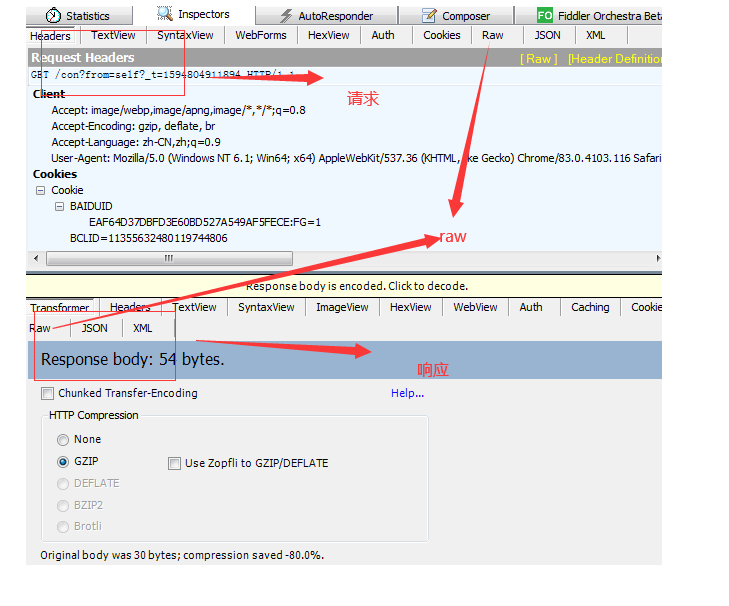
Fiddler工具使用介绍:
二、QQ音乐下载
分析步骤如下:
第一步:
进入QQ音乐歌单点击播放,按F12打开开发者工具
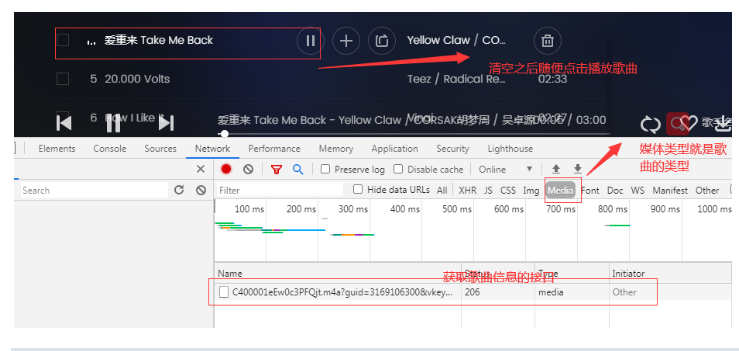
第二步:分析改接口,重点聚焦参数,现vkey不同,接下来找vkey是如何获取的
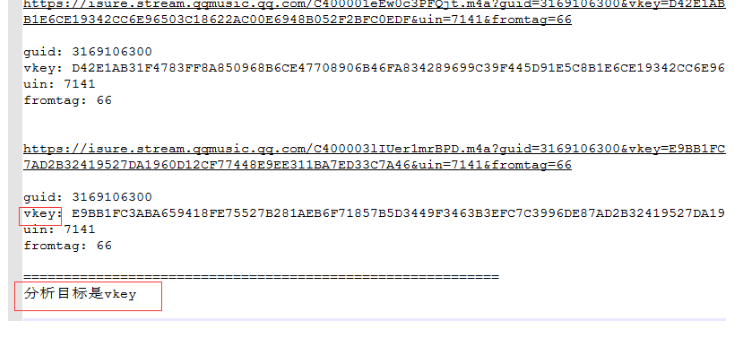
第三步:Ctrl+F搜索vkey即可
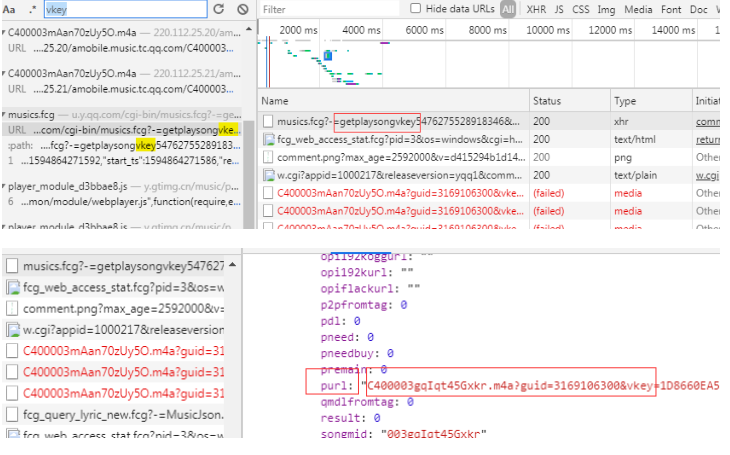
到此找到了vkey的获取方式,这个prul其实就是下载的真实链接
第四步:分析上面接口,找出两个接口
对照参数,找到下面这条接口里面就有songmid
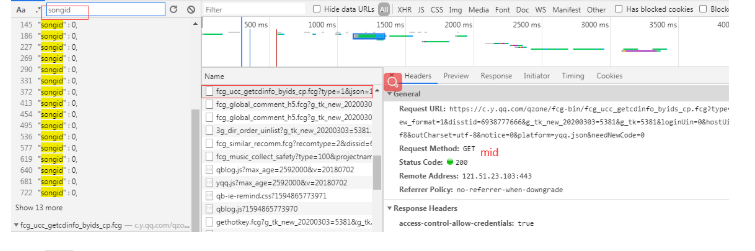
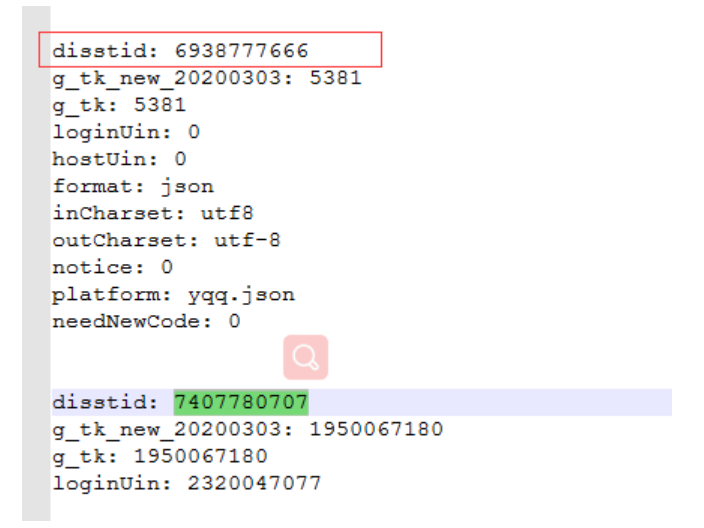
到此找到了vkey的获取方式,这个prul其实就是下载的真实链接

代码实现:
import requests
class QQ_Music(object):
'''
下载歌单歌曲信息
'''
def __init__(self, disst_id):
self.disst_id = disst_id
self.base_headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
# 'origin': 'https://y.qq.com',
}
def get_purl(self, mid):
'''
获取歌曲的下载连接
:param mid: song_mid
:return:
'''
print(mid)
base_url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?'
vkeys_headers = {
# 'Cookie': 'player_exist=1; pgv_pvi=7301237760; pgv_si=s9195997184; pgv_info=ssid=s19087756; pgv_pvid=8415264692; ts_uid=6315578108; qqmusic_fromtag=66; _qpsvr_localtk=0.5418903205743426; RK=sTQE3uo24X; ptcz=5074f2d23e4740c6f000f402aa7f94ea77eb8676fc8a86a6a2ceec24ddc41f9c; psrf_qqopenid=F7E16C6D0CCE28D2D5D406CC7155C804; psrf_qqrefresh_token=6935E771A3A8799DDEE88015C5B8E22D; psrf_access_token_expiresAt=1602642207; euin=owoAoenP7inl7z**; psrf_musickey_createtime=1594866207; psrf_qqunionid=86FBBBC2A4E959DE1573FC4D9BE292B3; uin=2320047077; psrf_qqaccess_token=33BCCB2745ED4C9E2FE1D2B5114F0731; qqmusic_key=Q_H_L_2yXkFy50eeUgoHT0jwWPc2AGt0diA_6iKqbn6VQ8DhYHJ9gZbJGQENVPPvxSyq3; qm_keyst=Q_H_L_2yXkFy50eeUgoHT0jwWPc2AGt0diA_6iKqbn6VQ8DhYHJ9gZbJGQENVPPvxSyq3; tmeLoginType=2; ts_refer=www.baidu.com/link; yq_playschange=0; yq_playdata=; userAction=1; yqq_stat=0; yq_index=0; yplayer_open=1; ts_last=y.qq.com/portal/player.html',
'Referer': 'https://y.qq.com/portal/player.html',
'Sec-Fetch-Site': 'same-site',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Host': 'u.y.qq.com',
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01',
}
vkeys_headers.update(self.base_headers)
params = {
# '-': 'getplaysongvkey9620966003711819',
'g_tk': '5381',
# 'sign': 'zza3h1m88atnk152c37e7307b7c842c6ff45d75a0ec2e',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0',
'data': '{"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"8415264692","calltype":0,"userip":""}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"8415264692","songmid":["' + mid + '"],"songtype":[0],"uin":"0","loginflag":1,"platform":"20"}},"comm":{"uin":2320047077,"format":"json","ct":24,"cv":0}}',
}
# print(self.base_headers)
response = requests.get(base_url, headers=vkeys_headers, params=params)
# print(response.text)
# part_url = response.json()['req']['data']['testfilewifi']
purl = response.json()['req_0']['data']['midurlinfo'][0]['purl']
# print(purl)
if purl:
# print(part_url)
return purl
return -1
def get_songmid(self, id):
'''
获取歌单所有歌曲的songid——list
:param id: disstid,歌单的id
:return:
'''
# 到底使用不使用params,得看变化的参数个数。
base_url = 'https://c.y.qq.com/qzone/fcg-bin/fcg_ucc_getcdinfo_byids_cp.fcg?type=1&json=1&utf8=1&onlysong=0&new_format=1&disstid={}&g_tk_new_20200303=1950067180&g_tk=1950067180&loginUin=2320047077&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'.format(
id)
song_headers = {
'Referer': 'https://y.qq.com/n/yqq/playlist/4279416823.html',
}
song_headers.update(self.base_headers)
response = requests.get(base_url, headers=song_headers)
# print(response.json())
song_infos = []
for data in response.json()['cdlist'][0]['songlist']:
song_infos.append((data['name'], data['mid']))
return song_infos
def download_music1(self, url, name):
'''
下载歌曲
:param url:
:return:
'''
print(self.base_headers)
url = 'http://ws.stream.qqmusic.qq.com/' + url
# headers= {
# 'Referer': 'https://y.qq.com/portal/player.html',
# }
# self.base_headers.update(headers)
try:
print(name, '开始下载', url)
response = requests.get(url, headers=self.base_headers)
# print(response.status_code)
filename = r'.\music2\{}.{}'.format(name, 'm4a')
with open(filename, 'wb') as fp:
fp.write(response.content)
print(name, '下载成功!')
except Exception:
print('下载失败!')
def download_music(self, url, name):
url = 'http://ws.stream.qqmusic.qq.com/' + url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
response = requests.get(url, headers=headers)
filename = './music2/{}.{}'.format(name, 'm4a')
try:
print(name, '开始下载====', sep='%%%%%')
with open(filename, 'wb') as fp:
fp.write(response.content)
print(name, '下载完成')
except Exception:
print(name, '下载失败====', sep='%%%%%')
def run(self):
'''
下载流程
:return:
'''
# 1、获取歌单所有歌曲的songid——list
song_infos = self.get_songmid(self.disst_id)
# print(song_infos)
# 2、遍历拿个每个去个id,获取他下载purl
for name, mid in song_infos:
purl = self.get_purl(mid)
# 3、通过purl进行歌曲下载
if purl != -1:
self.download_music1(purl, name)
if __name__ == '__main__':
# 歌单
# 7100401222
disst_id = '7100401222'
q = QQ_Music(disst_id)
q.run()
三、Fiddler抓取app配置
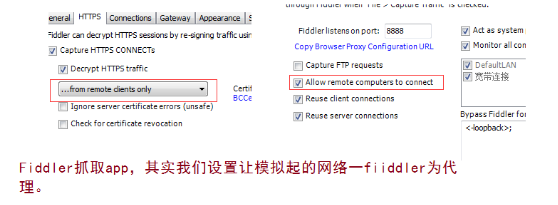
1、设置fiddler
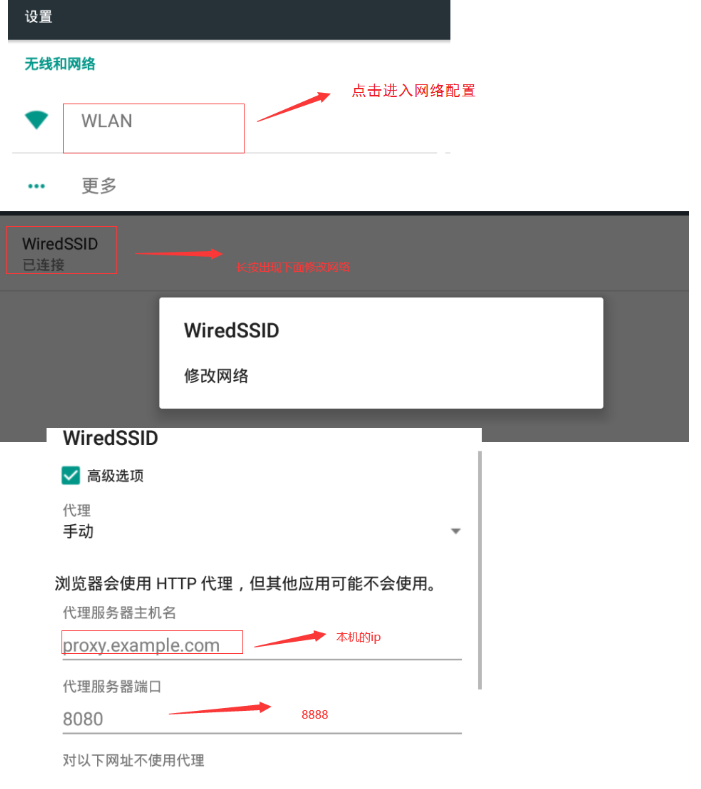
2、配置模拟器网络
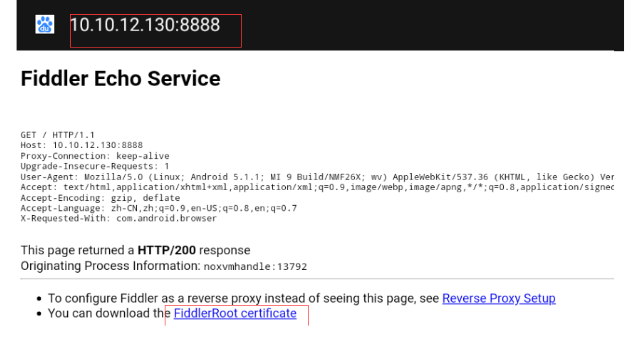
3、给模拟器安装证书
我们可以使用Fillder的代理功能,因为数据是要经过fiidler,所以app在获取数据的过程,fiddler是可以保存下来的,这是我们利用这种功能做到:
1、减少请求次数
2、比较难的ajax可以利用这种功能将数据直接保存,只需要写一个简单程序读取保存文件,就可以提取数据
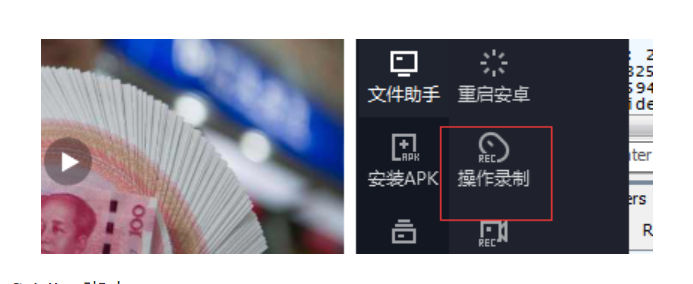
3、这个功能配合selenium和模拟器的操作录制功能,其作用无比强大
四、Fiddler 抓取梨视频 APP 信息
1、首先打开模拟器,点开梨视频app,找到我们要爬取视频的位置,进行滑动加载视频
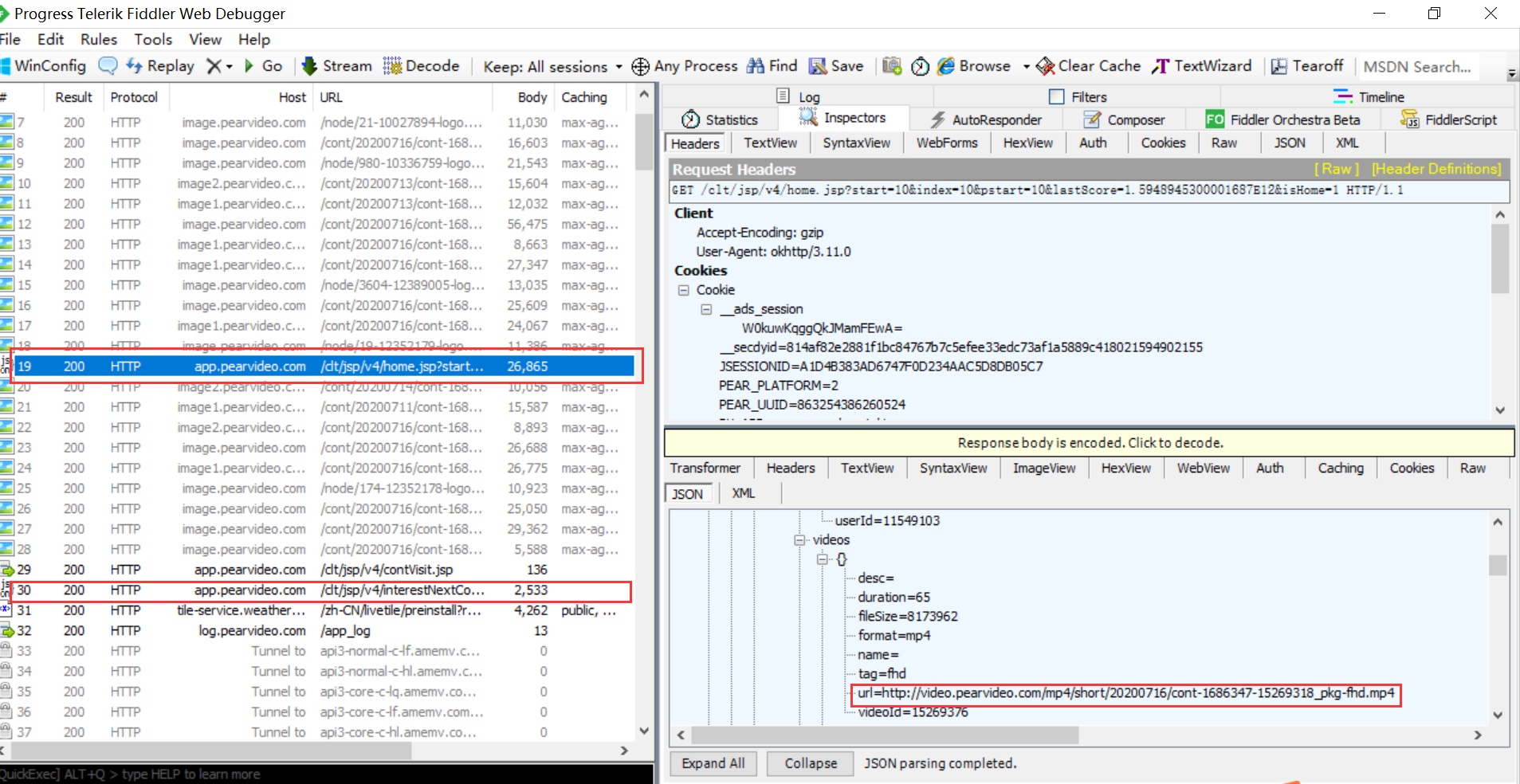
2、加载的过程中查看Fiddler中数据包,通过分析发现,下图中的数据包中包含视频资源
3、打开 Rules–>Customizes Rules,编辑 Fiddler Scrapy 来将数据包保存到本地
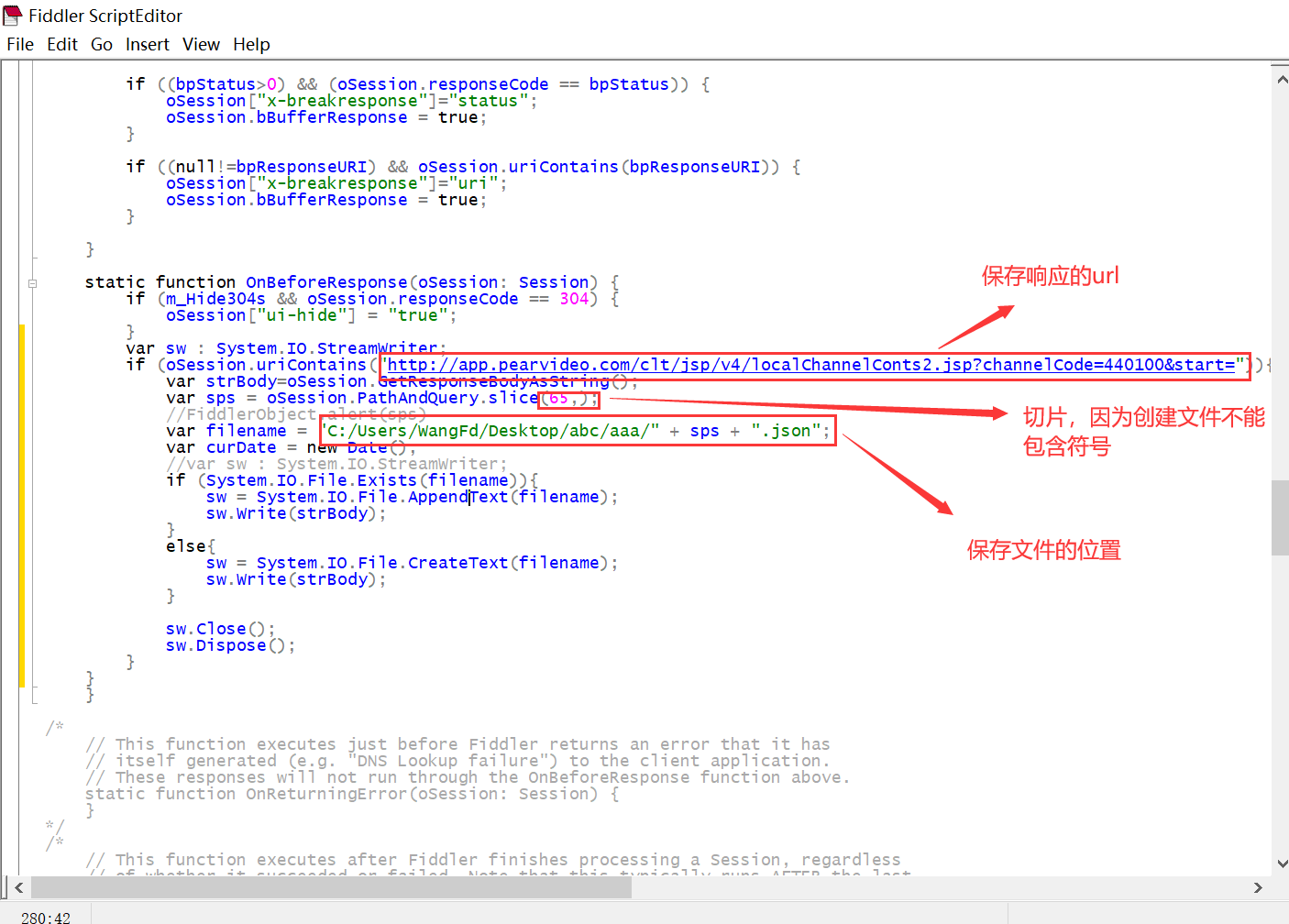
fiddler脚本:
static function OnBeforeResponse(oSession: Session) {
if (m_Hide304s && oSession.responseCode == 304) {
oSession["ui-hide"] = "true";
}
var sw : System.IO.StreamWriter;
if (oSession.uriContains("想要保存这中数据包的公共URL部分")){
var strBody=oSession.GetResponseBodyAsString();
var sps = oSession.PathAndQuery.slice(65,);
//FiddlerObject.alert(sps)
var filename = "保存到哪里" + sps + ".json";
var curDate = new Date();
//var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(strBody);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(strBody);
}
sw.Close();
sw.Dispose();
}
}
4、录制屏幕操作,自动滑动屏幕来保存响应
5、播放录制的动作,查看文件夹中保存的 json 数据文件
6、编写代码,下载 json 数据中包含的视频资源并保存到本地
代码实现:
import requests, os, json
from multiprocessing.pool import Pool
def download(infos):
'''
下载视屏
:param url:
:return:
'''
url = infos[0]
name = infos[1]
print(name, '开始下载!')
response = requests.get(url)
with open('./li_datas/videos/{}.mp4'.format(name), 'wb') as fp:
fp.write(response.content)
print(name, '开始完成!')
def main():
# 存储所有的视屏的url和name
viedo_infos = []
json_files_dir = r'./li_datas/data/'
filenames = os.listdir(json_files_dir)
for filename in filenames:
fp = open(json_files_dir + filename, 'r', encoding='utf-8')
json_data = json.load(fp)
# print(json_data)
for data in json_data['dataList']:
# print(data)
if data['nodeType'] == '13':
url = data['contList'][0]['videos'][0]['url']
name = data['contList'][0]['name']
# print(url,name)
# download(url,name)
viedo_infos.append((url, name))
# 开启多进程
p = Pool(4) # 4就是进程数量
p.map(download, viedo_infos)
if __name__ == '__main__':
main()

















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









