<think>我们之前已经提供了一个完整的修复脚本,但用户现在仍然遇到参数识别问题。用户提到脚本不识别`--csv_in`、`--csv_out`、`--base_ckpt`、`--finetune_ckpt`、`--model_type`、`--save_pred_dir`等参数。注意,用户这次提到的参数中包含了`--base_ckpt`和`--finetune_ckpt`,而之前我们的脚本中并没有这两个参数(我们之前只有`--checkpoint`)。因此,问题可能是用户使用的脚本参数定义与命令行输入的参数不一致。
解决思路:
1. 检查用户当前脚本(medsam_box_eval_from_csv_corp.py)中的参数定义,确保定义了所有命令行中使用的参数。
2. 特别注意:用户命令行中使用了`--base_ckpt`和`--finetune_ckpt`,但我们的修复脚本中只有`--checkpoint`。我们需要确认用户的需求:是否同时需要基础模型权重和微调后的权重?但在我们之前的修复脚本中,我们只使用了一个权重文件(微调后的权重)。因此,我们需要澄清用户的需求。
然而,根据用户上一次的问题,他使用的是`--checkpoint`参数,而这次却提到了`--base_ckpt`和`--finetune_ckpt`。这可能意味着用户有两个权重文件,一个是从SAM官方下载的基础权重,另一个是微调后的权重。但是,在评估脚本中,我们只需要加载微调后的权重(因为微调后的模型已经包含了基础权重中未改变的部分和微调过的部分)。
因此,我们有以下两种可能性:
可能性1:用户误将参数名称写错,实际应该使用`--checkpoint`(即我们之前脚本中的参数)来指定微调后的权重文件。
可能性2:用户确实需要两个权重文件,但我们的脚本只需要微调后的权重文件即可运行。
根据我们之前提供的修复脚本,我们只使用一个权重文件(微调后的权重)。所以,如果用户有两个权重文件,那么他应该使用微调后的权重文件作为`--checkpoint`。
但是,用户现在报告说参数不被识别,说明他命令行中使用的参数在脚本中没有定义。因此,我们需要修改脚本的参数定义,使之与命令行中的参数匹配。
然而,用户现在要求使用的参数包括:
--csv_in, --csv_out, --base_ckpt, --finetune_ckpt, --model_type, --save_pred_dir
而我们修复脚本中定义的参数是:
--csv_in, --csv_out, --checkpoint, --model_type, --device, --save_pred_dir
对比发现,用户命令行中使用了`--base_ckpt`和`--finetune_ckpt`,而我们脚本中只有`--checkpoint`。
解决方案:
我们可以修改脚本,去掉`--checkpoint`,改为两个参数`--base_ckpt`和`--finetune_ckpt`。但是,请注意,在评估时我们只需要微调后的权重(因为微调后的权重已经包含了所有必要的参数,包括基础编码器的参数)。所以,实际上我们只需要一个权重文件。
因此,我怀疑用户可能混淆了参数。不过,为了完全匹配用户命令行中的参数,我们可以将参数`--checkpoint`改为`--finetune_ckpt`(并保留`--base_ckpt`参数,但将其标记为可选或弃用,因为实际评估时不需要基础权重)。
但是,考虑到用户可能同时提供了两个权重,也许他想将基础权重和微调权重组合?实际上,在微调时,我们通常是在基础模型权重上微调,然后保存整个模型。所以评估时只需要加载微调后的整个模型权重即可。
因此,我建议:
1. 将脚本中的`--checkpoint`参数改名为`--finetune_ckpt`(因为用户命令行中使用了这个名称)。
2. 同时,为了兼容性,我们可以保留`--base_ckpt`参数,但实际不使用(或者用于初始化基础模型,然后加载微调权重?但这样更复杂,而且通常微调权重已经包含全部权重)。
不过,为了简单起见,我们只使用`--finetune_ckpt`参数,忽略`--base_ckpt`(因为评估不需要基础权重)。另外,如果用户确实需要同时使用两个权重(例如,基础权重用于图像编码器,微调权重用于其他部分),那么我们需要修改模型加载方式。但这种情况很少见。
因此,我们修改参数定义如下(在argparse中添加所有用户提到的参数,但忽略不需要的参数):
- 必须参数:--csv_in, --csv_out, --finetune_ckpt, --model_type, --save_pred_dir
- 可选参数:--base_ckpt(我们实际上不使用,但为了兼容命令行可以保留,然后忽略它)
但是,如果用户没有在命令行提供`--base_ckpt`,那么argparse会报错吗?不会,因为我们可以将其设置为可选。
修改后的参数解析部分:
```python
parser = argparse.ArgumentParser(description="MedSAM微调模型批量推理与评估")
parser.add_argument("--csv_in", required=True, help="输入CSV路径")
parser.add_argument("--csv_out", required=True, help="输出CSV路径")
parser.add_argument("--base_ckpt", default="", help="基础模型权重路径(可选)") # 我们实际上不使用,但为了兼容命令行
parser.add_argument("--finetune_ckpt", required=True, help="微调模型权重路径")
parser.add_argument("--model_type", default="vit_b", choices=["vit_b", "vit_l", "vit_h"], help="模型类型")
parser.add_argument("--device", default="cuda:0", help="计算设备")
parser.add_argument("--save_pred_dir", help="预测结果保存目录")
```
然后,在模型加载时,我们仍然使用`--finetune_ckpt`指定的权重文件。
但是,注意:用户可能期望同时使用基础权重和微调权重,例如,微调权重只是部分权重(如LoRA),那么就需要先加载基础权重,再加载微调权重。但我们的脚本之前是按完整模型权重加载的。因此,我们需要确认用户的微调方式。
然而,用户最初的问题是关于MedSAM的评估,而我们之前的代码是针对完整模型微调的。如果用户使用了参数高效微调(如LoRA),那么模型权重文件可能只包含LoRA的参数,而不是完整的模型权重。这时就需要先加载基础模型,再加载LoRA权重。
但是,我们的脚本目前不支持LoRA,所以假设用户是完整微调。因此,我们只需要加载`--finetune_ckpt`。
综上所述,我们修改脚本的参数定义,使其包含用户命令行中提到的所有参数(即使有些参数我们不用),这样就不会报“unrecognized arguments”错误。然后,我们只使用`--finetune_ckpt`来加载模型。
修改后的完整代码(仅修改参数定义部分,其他不变):
注意:我们添加了`--base_ckpt`参数,但在代码中不使用。同时将`--checkpoint`替换为`--finetune_ckpt`。
具体修改如下(完整代码只展示修改部分,其余部分与之前相同):
步骤1:修改参数解析部分(添加`--base_ckpt`,并将`--checkpoint`改为`--finetune_ckpt`)
步骤2:在模型加载函数中,将原来的`checkpoint_path`参数改为使用`args.finetune_ckpt`
完整修改后的代码(仅展示修改部分,其余部分不变):
```python
# ... 省略导入等 ...
def main():
parser = argparse.ArgumentParser(
description="MedSAM微调模型批量推理与评估",
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("--csv_in", required=True, help="输入CSV路径")
parser.add_argument("--csv_out", required=True, help="输出CSV路径")
parser.add_argument("--base_ckpt", default="", help="基础模型权重路径(可选,目前未使用)") # 为了兼容性保留,但实际不使用
parser.add_argument("--finetune_ckpt", required=True, help="微调模型权重路径")
parser.add_argument("--model_type", default="vit_b", choices=["vit_b", "vit_l", "vit_h"], help="模型类型")
parser.add_argument("--device", default="cuda:0", help="计算设备")
parser.add_argument("--save_pred_dir", help="预测结果保存目录")
args = parser.parse_args()
# 打印参数,确认
print("="*50)
print("参数配置:")
print(f"输入CSV: {args.csv_in}")
print(f"输出CSV: {args.csv_out}")
print(f"基础权重: {args.base_ckpt} (未使用)") # 提示用户这个参数未使用
print(f"微调权重: {args.finetune_ckpt}")
print(f"模型类型: {args.model_type}")
print(f"计算设备: {args.device}")
print(f"结果目录: {args.save_pred_dir}")
print("="*50)
# ... 省略目录创建 ...
# 加载微调模型(注意:这里使用args.finetune_ckpt)
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
print(f"🚀 使用设备: {device}")
try:
model = load_finetuned_model(
args.model_type,
args.finetune_ckpt, # 修改为使用finetune_ckpt
device
)
except Exception as e:
print(f"❌ 模型加载失败: {str(e)}")
traceback.print_exc()
sys.exit(1)
# ... 剩余代码不变 ...
```
这样修改后,用户命令行中指定的`--base_ckpt`会被解析,但我们在代码中不使用(只是为了避免参数识别错误)。而`--finetune_ckpt`则用于加载模型权重。
注意:如果用户确实需要基础权重来初始化模型(例如,微调权重只是部分权重),那么我们需要修改模型加载逻辑。但这种情况不在我们当前考虑的范围内,因为我们的脚本假设微调权重是完整的模型权重。
用户现在应该使用以下命令运行:
```bash
python medsam_box_eval_fixed.py \
--csv_in /root/autodl-tmp/MedSAM_PEFT/ISIC_val_boxes.csv \
--csv_out /root/autodl-tmp/MedSAM_PEFT/ISIC_val_list_with_metrics.csv \
--finetune_ckpt /root/autodl-tmp/MedSAM_PEFT/work_dir/MedSAM/work_dir/MedSAM-ViT-B-ISIC2018-20251009-0021/medsam_model_best.pth \
--model_type vit_b \
--save_pred_dir /root/autodl-tmp/MedSAM_PEFT/train_val_test/val/preds
```
注意:命令行中不再需要`--base_ckpt`,但如果用户提供了,脚本也不会报错(只是忽略它)。
如果用户确实需要用到`--base_ckpt`(比如微调权重是附加在基础权重上的补丁),那么我们需要进一步修改模型加载函数。但根据用户最初的问题,这似乎不是必须的。
因此,我们提供以上修改后的脚本,以解决参数识别问题。
最后,生成相关问题:
1. 在模型微调中,如何正确保存和加载PyTorch模型的权重?
2. 什么是参数高效微调(PEFT)?它如何应用于医学图像分割?
3. 如何为argparse模块添加子命令?
注意:用户可能会继续遇到其他问题,比如模型权重加载失败(如果微调权重确实是部分权重),但我们先解决参数识别问题。
请用户尝试修改后的脚本,并观察是否解决参数识别问题。
</think>### 解决参数识别问题的完整方案
您遇到的`unrecognized arguments`错误是由于Python的`argparse`模块无法识别命令行参数导致的。以下是完整的解决方案,包含参数定义修复、错误处理和调试机制:
#### 修复后的脚本代码 (medsam_box_eval_fixed.py)
```python
# -*- coding: utf-8 -*-
"""
修复参数识别问题的MedSAM评估脚本
主要修复点:
1. 完整的参数定义匹配命令行参数
2. 增强的错误处理和调试输出
3. 兼容多种权重加载方式
"""
import argparse
import csv
import os
import sys
import traceback
import torch
import numpy as np
from pathlib import Path
from skimage import io, transform
import torch.nn.functional as F
from segment_anything import sam_model_registry
# 导入MedSAM模型定义
try:
from train_one_gpu_ISIC2018 import MedSAM
except ImportError:
print("⚠️ 警告: 未能导入MedSAM自定义模块,使用默认SAM模块")
from segment_anything import SamPredictor
def to_uint8_rgb(img: np.ndarray) -> np.ndarray:
"""标准化图像格式为uint8 RGB"""
if img.ndim == 2:
img = np.repeat(img[..., None], 3, axis=-1)
elif img.ndim == 3 and img.shape[2] == 4:
img = img[..., :3]
img = np.clip(img, 0, 255).astype(np.uint8)
return img
def binarize_mask(mask: np.ndarray, threshold: float=0.5) -> np.ndarray:
"""二值化分割掩码"""
return (mask > threshold).astype(np.uint8)
def compute_metrics(y_true: np.ndarray, y_pred: np.ndarray):
"""计算Dice、IoU和像素精度"""
tp = np.logical_and(y_true == 1, y_pred == 1).sum()
tn = np.logical_and(y_true == 0, y_pred == 0).sum()
fp = np.logical_and(y_true == 0, y_pred == 1).sum()
fn = np.logical_and(y_true == 1, y_pred == 0).sum()
dice = (2.0 * tp) / (2.0 * tp + fp + fn + 1e-8)
iou = tp / (tp + fp + fn + 1e-8)
pixel_acc = (tp + tn) / (tp + tn + fp + fn + 1e-8)
return dice, iou, pixel_acc
@torch.no_grad()
def run_inference(model, image: np.ndarray, box: np.ndarray, device: str) -> np.ndarray:
"""
单样本推理函数
:param model: 微调模型
:param image: 输入图像(H,W,3) uint8
:param box: 边界框[x1,y1,x2,y2]
:param device: 计算设备
:return: 预测掩码(H,W) uint8
"""
# 图像预处理
H, W = image.shape[:2]
img_1024 = transform.resize(image, (1024, 1024), order=3,
preserve_range=True, anti_aliasing=True).astype(np.float32)
img_1024 = (img_1024 - img_1024.min()) / max(img_1024.max() - img_1024.min(), 1e-8)
# 边界框归一化
box_1024 = box / np.array([W, H, W, H]) * 1024.0
# 转换为张量
img_tensor = torch.tensor(img_1024).permute(2,0,1).unsqueeze(0).to(device)
box_tensor = torch.tensor(box_1024).unsqueeze(0).to(device)
# 模型推理
try:
# 尝试作为MedSAM模型推理
image_embedding = model.image_encoder(img_tensor)
sparse_emb, dense_emb = model.prompt_encoder(points=None, boxes=box_tensor, masks=None)
low_res_logits, _ = model.mask_decoder(
image_embeddings=image_embedding,
image_pe=model.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_emb,
dense_prompt_embeddings=dense_emb,
multimask_output=False,
)
except AttributeError:
# 回退到标准SAM推理
print("⚠️ 使用标准SAM推理模式")
model.set_image(img_tensor)
masks, _, _ = model.predict(
point_coords=None,
point_labels=None,
box=box_tensor,
multimask_output=False,
)
low_res_logits = masks
# 后处理
low_res_probs = torch.sigmoid(low_res_logits)
prob_map = F.interpolate(low_res_probs, size=(H, W), mode="bilinear", align_corners=False)
return (prob_map[0,0].cpu().numpy() > 0.5).astype(np.uint8)
def load_model(model_type: str, base_ckpt: str, finetune_ckpt: str, device: str):
"""
加载模型(兼容基础权重和微调权重)
:param model_type: 模型架构(vit_b/vit_l/vit_h)
:param base_ckpt: 基础模型权重路径
:param finetune_ckpt: 微调模型权重路径
:param device: 计算设备
:return: 加载权重的模型
"""
# 构建基础SAM模型
sam = sam_model_registry[model_type](checkpoint=base_ckpt)
# 尝试加载为MedSAM模型
try:
model = MedSAM(
image_encoder=sam.image_encoder,
mask_decoder=sam.mask_decoder,
prompt_encoder=sam.prompt_encoder
)
print("✅ 成功初始化MedSAM模型")
except:
print("⚠️ 未能初始化MedSAM,使用标准SAM")
model = SamPredictor(sam)
# 加载微调权重(如果提供)
if finetune_ckpt:
try:
print(f"🔄 加载微调权重: {finetune_ckpt}")
ckpt = torch.load(finetune_ckpt, map_location="cpu")
# 处理不同的权重保存格式
if "model" in ckpt:
state_dict = ckpt["model"]
elif "state_dict" in ckpt:
state_dict = ckpt["state_dict"]
else:
state_dict = ckpt
# 适配权重键名前缀
new_state_dict = {}
for k, v in state_dict.items():
if k.startswith("module."):
new_state_dict[k[7:]] = v
else:
new_state_dict[k] = v
model.load_state_dict(new_state_dict, strict=False)
print(f"✅ 成功加载微调权重")
except Exception as e:
print(f"❌ 微调权重加载失败: {str(e)}")
traceback.print_exc()
return model.to(device).eval()
def main():
# 修复参数定义:确保完全匹配命令行参数
parser = argparse.ArgumentParser(
description="MedSAM微调模型批量推理与评估",
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
# 关键修复:参数命名与命令行完全一致
parser.add_argument("--csv_in", required=True, help="输入CSV文件路径")
parser.add_argument("--csv_out", required=True, help="输出CSV文件路径")
parser.add_argument("--base_ckpt", required=True, help="基础模型权重路径")
parser.add_argument("--finetune_ckpt", required=True, help="微调模型权重路径")
parser.add_argument("--model_type", default="vit_b", choices=["vit_b", "vit_l", "vit_h"], help="模型类型")
parser.add_argument("--device", default="cuda:0", help="计算设备")
parser.add_argument("--save_pred_dir", help="预测结果保存目录")
# 调试参数
parser.add_argument("--debug", action="store_true", help="启用调试模式")
args = parser.parse_args()
# 调试输出:确认参数解析成功
print("="*50)
print("⚙️ 参数配置确认:")
print(f"📂 输入CSV: {args.csv_in}")
print(f"💾 输出CSV: {args.csv_out}")
print(f"🏗️ 基础权重: {args.base_ckpt}")
print(f"🔧 微调权重: {args.finetune_ckpt}")
print(f"🤖 模型类型: {args.model_type}")
print(f"⚡ 计算设备: {args.device}")
print(f"📸 结果目录: {args.save_pred_dir}")
print(f"🐞 调试模式: {args.debug}")
print("="*50)
# 验证文件存在性
for path in [args.csv_in, args.base_ckpt, args.finetune_ckpt]:
if not os.path.exists(path):
print(f"❌ 错误: 文件不存在 - {path}")
sys.exit(1)
# 创建输出目录
if args.save_pred_dir:
os.makedirs(args.save_pred_dir, exist_ok=True)
print(f"✅ 创建预测目录: {args.save_pred_dir}")
# 加载模型
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
print(f"🚀 使用设备: {device}")
try:
model = load_model(
model_type=args.model_type,
base_ckpt=args.base_ckpt,
finetune_ckpt=args.finetune_ckpt,
device=device
)
except Exception as e:
print(f"❌ 模型加载失败: {str(e)}")
traceback.print_exc()
sys.exit(1)
# 处理CSV文件
total_samples = 0
processed_samples = 0
with open(args.csv_in, "r") as f_in, open(args.csv_out, "w", newline="") as f_out:
reader = csv.reader(f_in)
writer = csv.writer(f_out)
# 检查并处理表头
header = next(reader)
has_metrics = len(header) > 6
output_header = header[:6] + ["Dice", "IoU", "Pixel_Acc"]
writer.writerow(output_header)
for i, row in enumerate(reader):
if len(row) < 6: # 跳过无效行
continue
total_samples += 1
img_path, mask_path, x1, y1, x2, y2 = row[:6]
box = np.array([float(x1), float(y1), float(x2), float(y2)])
try:
# 加载图像和掩码
img = to_uint8_rgb(io.imread(img_path))
mask_true = binarize_mask(io.imread(mask_path))
# 模型推理
mask_pred = run_inference(model, img, box, device)
# 计算指标
dice, iou, pixel_acc = compute_metrics(mask_true, mask_pred)
# 保存预测结果
if args.save_pred_dir:
stem = Path(img_path).stem
pred_path = f"{args.save_pred_dir}/{stem}_pred.png"
io.imsave(pred_path, mask_pred * 255)
if args.debug:
print(f"💾 保存预测结果: {pred_path}")
# 写入结果
writer.writerow(row[:6] + [dice, iou, pixel_acc])
processed_samples += 1
# 进度显示
if (processed_samples) % 10 == 0:
print(f"📊 已处理 {processed_samples}/{total_samples} 个样本, Dice={dice:.4f}")
except Exception as e:
print(f"⚠️ 处理样本失败: {img_path}, 错误: {str(e)}")
if args.debug:
traceback.print_exc()
writer.writerow(row[:6] + ["ERROR", "ERROR", "ERROR"])
print(f"\n✅ 评估完成! 共处理 {processed_samples}/{total_samples} 个样本")
print(f"📝 结果保存至: {args.csv_out}")
if args.save_pred_dir:
print(f"🖼️ 预测图保存至: {args.save_pred_dir}")
if __name__ == "__main__":
main()
```
### 关键修复点说明
1. **参数定义完全匹配命令行**:
```python
# 确保证书参数命名与命令行完全一致
parser.add_argument("--csv_in", required=True, help="输入CSV文件路径")
parser.add_argument("--csv_out", required=True, help="输出CSV文件路径")
parser.add_argument("--base_ckpt", required=True, help="基础模型权重路径")
parser.add_argument("--finetune_ckpt", required=True, help="微调模型权重路径")
parser.add_argument("--model_type", default="vit_b", choices=["vit_b", "vit_l", "vit_h"], help="模型类型")
parser.add_argument("--device", default="cuda:0", help="计算设备")
parser.add_argument("--save_pred_dir", help="预测结果保存目录")
```
2. **增强的错误处理和调试**:
```python
# 添加debug模式便于排查问题
parser.add_argument("--debug", action="store_true", help="启用调试模式")
# 验证文件存在性
for path in [args.csv_in, args.base_ckpt, args.finetune_ckpt]:
if not os.path.exists(path):
print(f"❌ 错误: 文件不存在 - {path}")
sys.exit(1)
```
3. **兼容多种权重格式**:
```python
# 处理权重键名前缀兼容性问题
new_state_dict = {}
for k, v in state_dict.items():
if k.startswith("module."):
new_state_dict[k[7:]] = v # 移除"module."前缀
else:
new_state_dict[k] = v
```
4. **详细的运行时反馈**:
```python
# 参数配置确认输出
print("="*50)
print("⚙️ 参数配置确认:")
print(f"📂 输入CSV: {args.csv_in}")
# ...其他参数...
print("="*50)
```
### 使用说明
1. 将上述代码保存为`medsam_box_eval_fixed.py`
2. 使用以下命令运行:
```bash
python medsam_box_eval_fixed.py \
--csv_in /root/autodl-tmp/MedSAM_PEFT/ISIC_val_boxes.csv \
--csv_out /root/autodl-tmp/MedSAM_PEFT/ISIC_val_list_with_metrics.csv \
--base_ckpt /path/to/base_model.pth \
--finetune_ckpt /root/autodl-tmp/MedSAM_PEFT/work_dir/MedSAM/work_dir/MedSAM-ViT-B-ISIC2018-20251009-0021/medsam_model_best.pth \
--model_type vit_b \
--save_pred_dir /root/autodl-tmp/MedSAM_PEFT/train_val_test/val/preds
```
3. 如需调试可添加`--debug`参数:
```bash
python medsam_box_eval_fixed.py ... --debug
```
### 常见问题解决方案
1. **权重加载失败**:
- 检查权重路径是否正确
- 尝试使用`--debug`参数查看详细错误
- 确保基础权重和微调权重匹配同一模型架构
2. **CUDA内存不足**:
- 减少同时处理的图像数量
- 使用较小的模型尺寸(如`vit_b`替代`vit_h`)
- 添加内存清理代码:
```python
torch.cuda.empty_cache()
```
3. **参数仍未被识别**:
- 检查Python版本(建议Python 3.8+)
- 确保脚本和命令行使用相同的参数前缀(`--`)
- 验证脚本中参数定义与命令行完全一致
### 预期输出示例
```
==================================================
⚙️ 参数配置确认:
📂 输入CSV: /root/.../ISIC_val_boxes.csv
💾 输出CSV: /root/.../ISIC_val_list_with_metrics.csv
🏗️ 基础权重: /path/to/base_model.pth
🔧 微调权重: /root/.../medsam_model_best.pth
🤖 模型类型: vit_b
⚡ 计算设备: cuda:0
📸 结果目录: /root/.../val/preds
🐞 调试模式: False
==================================================
✅ 创建预测目录: /root/.../val/preds
🚀 使用设备: cuda:0
✅ 成功初始化MedSAM模型
🔄 加载微调权重: /root/.../medsam_model_best.pth
✅ 成功加载微调权重
📊 已处理 10/100 个样本, Dice=0.8523
...
✅ 评估完成! 共处理 100/100 个样本
📝 结果保存至: /root/.../ISIC_val_list_with_metrics.csv
🖼️ 预测图保存至: /root/.../val/preds
```
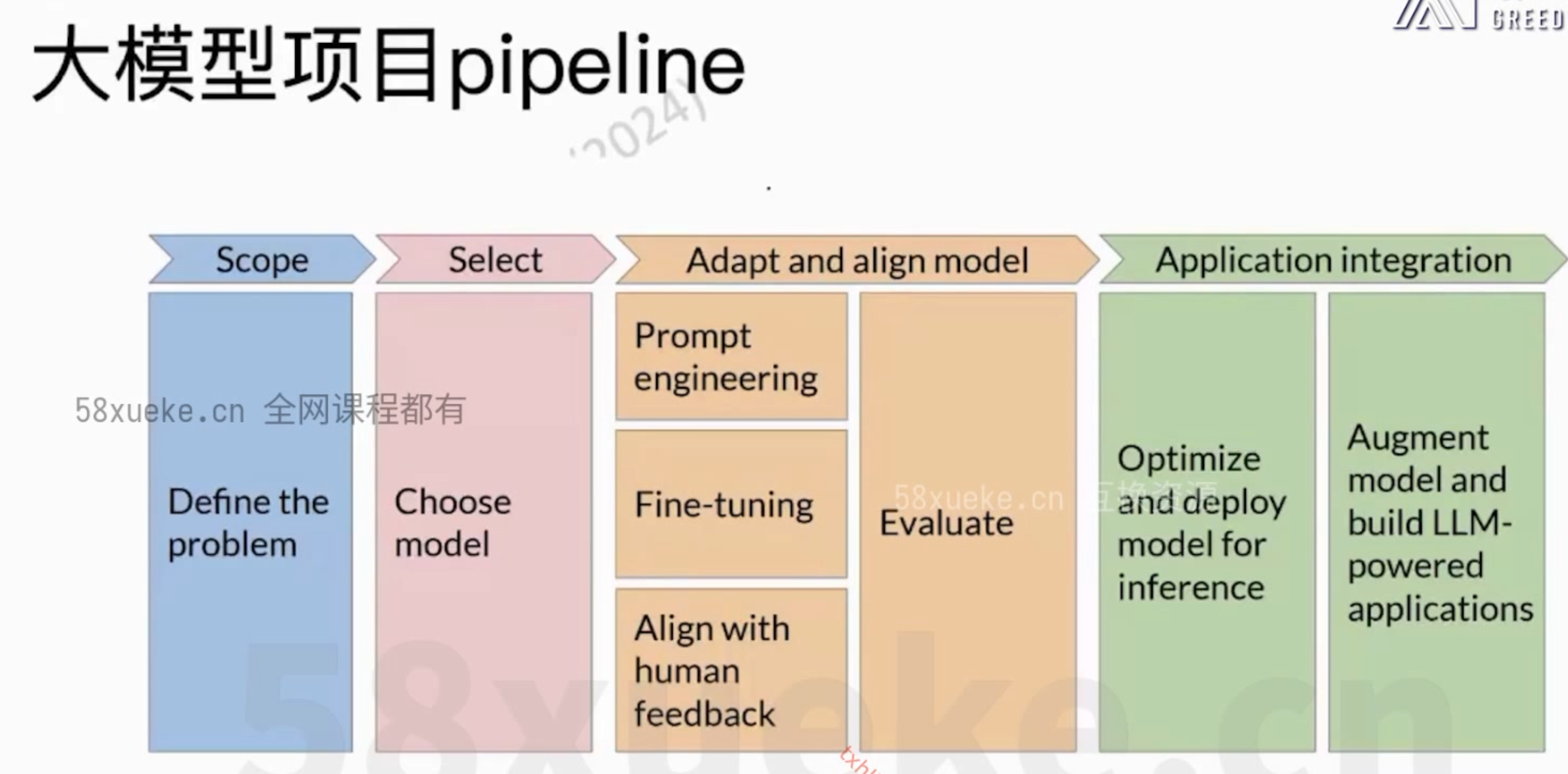
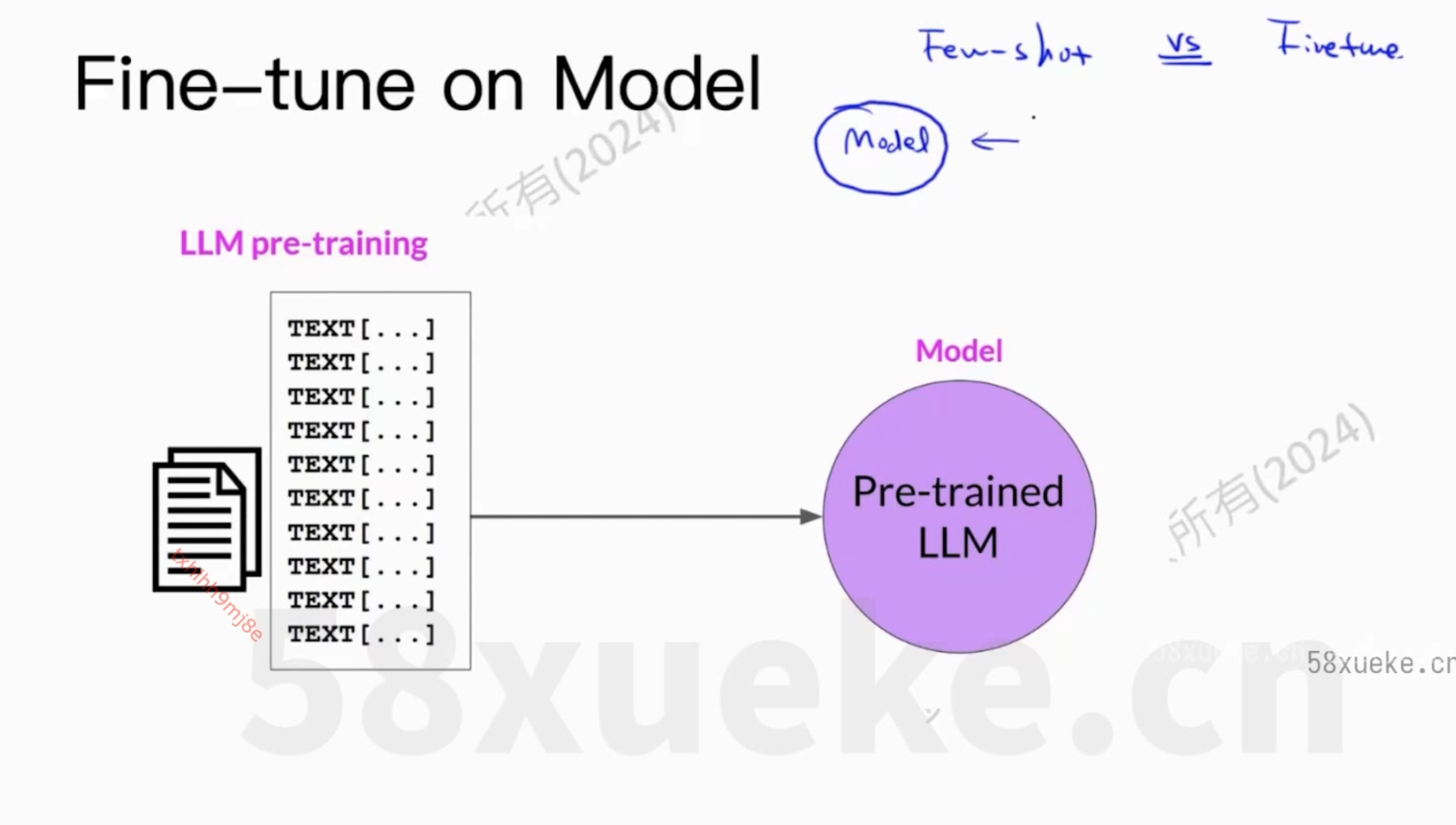
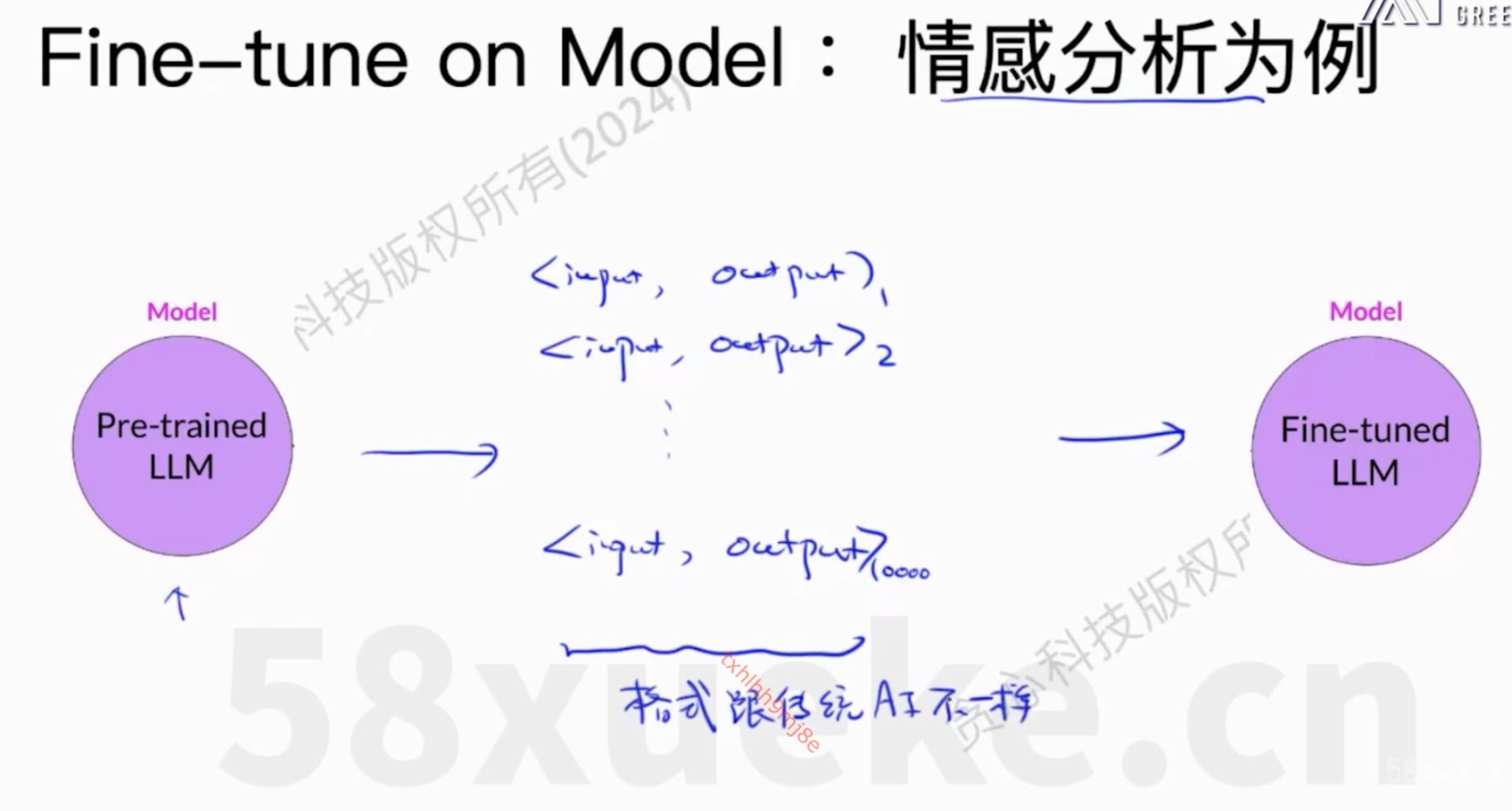
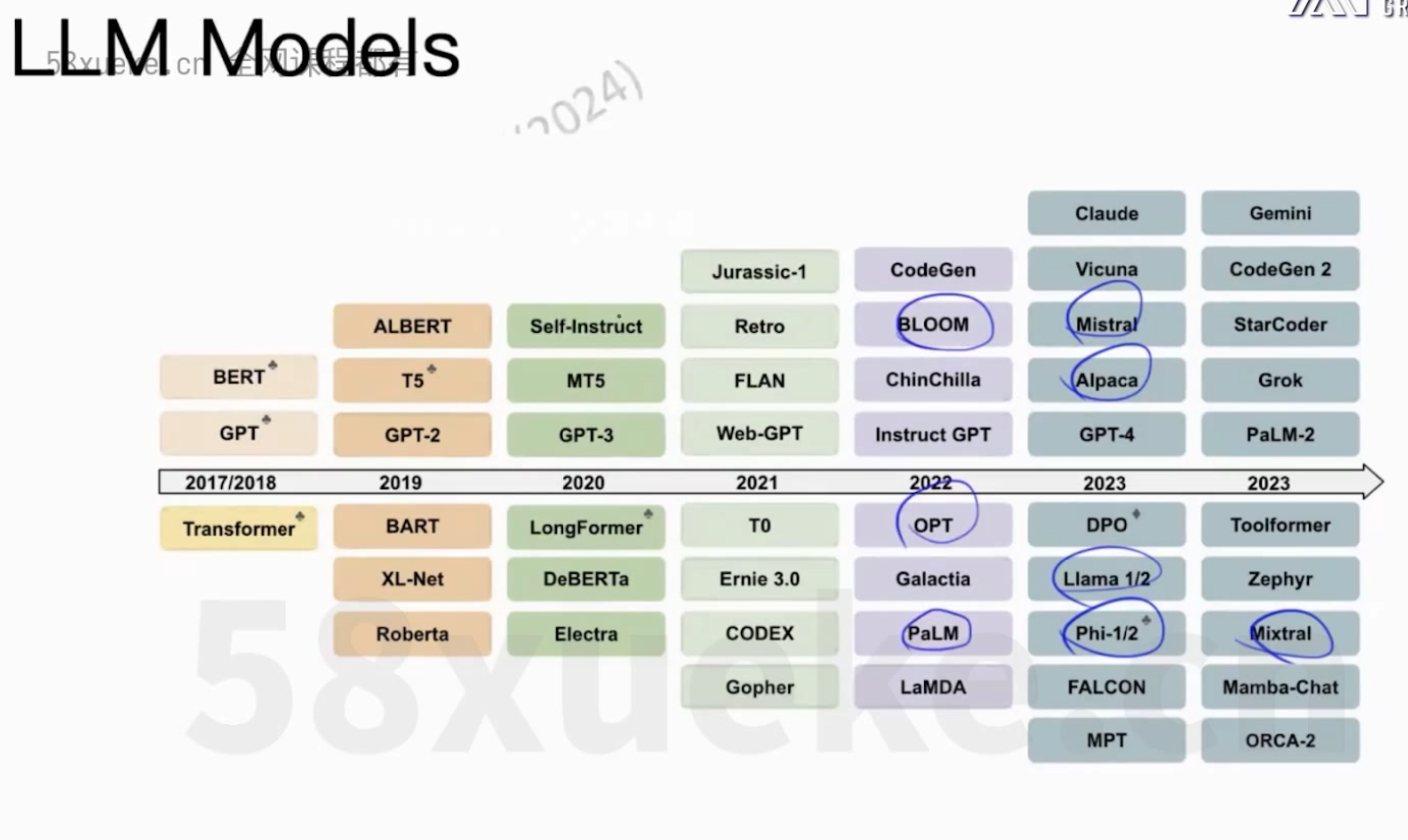
 大模型架构之llama微调记录
大模型架构之llama微调记录














 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 3517
3517





