




还在更新中……
一、Mastering-the-freeRTOS 书籍翻译
1. 编码风格:
1. 数据类型
TickType_t
freeRTOS内置内核系统周期滴答中断。
从任务开始走过滴答周期的个数,叫滴答数值,它用于测量时间。
两个相邻的系统滴答的时间,叫滴答周期。
描述任务时间的基本单位是滴答周期。
TickType_t 就是程序中任务时间变量的类型。
BaseType_t
这是内核中效率最高的数据类型。通常,这个类型在64-bit架构上就是64-bit的类型的数据;32位架构就是32位数据类型;16位架构就是16位数据类型;8位架构就是8位长度的数据类型。
BaseType_t 通常用于数值受限的返回值数据类型,以及 pdTRUE/pdFALSE 布尔类型。
2. 变量名称
变量名前缀有以下情形:
c 代表 char;
s 代表 short int16_t;
l 代表 long int32_t;
x 代表 BaseType_t 以及其他非标准数据类型(结构体、任务句柄、队列句柄等);
若变量是无符号整型,那么还要加上前缀 'u' ,若变量是指针变量,那么要加 'p'。
3. 函数名称
函数名称的前缀信息由含函数返回值数据类型信息和函数定义所在的文件信息组成。比如:
vTaskPrioritySet() 返回值是void类型,定义在 tasks.c 文件中。
xQueueReceive() 返回值是 BaseType_t 类型,定义在 queue.c 文件中。
pvTimerGetTimerID() 返回值是 void 指针类型,定义在 timer.c 文件中。
文件私有函数名称的前缀是'prv'.
4. 格式
Tab键用于demo应用程序中,一个tab键等于四个空格键。内核代码不再使用tab键。
5. 宏名称
大多数宏的名称由大写字母组成,前缀是小写字母,前缀暗示宏定义所在的文件。
前缀 定义文件位置
port (for example, portMAX_DELAY) portable.h or portmacro.h
task (for example, taskENTER_CRITICAL()) task.h
pd (for example, pdTRUE) projdefs.h
config (for example, configUSE_PREEMPTION) FreeRTOSConfig.h
err (for example, errQUEUE_FULL) projdefs.h
注意: 信号量(semaphore)函数APIs几乎全部以宏的形式编写的,但是遵循函数命名规则,而不是宏命名规则。
下表中的宏定义内核代码全文通用:
Macro Value (通用宏定义表)
pdTRUE 1
pdFALSE 0
pdPASS 1
pdFAIL 0
2. 堆内存管理
堆,用于分配任务栈空间,变量等。
动态内存分配,是C语言编程中的概念,而不是FreeRTOS也不是多任务系统中的概念。FreeRTOS内核中对象,可以存放在动态分配的内存空间中。但是标准C库的 malloc() free() 并不适合嵌入式系统。
pvPortMalloc() and vPortFree() 是公用函数,可以被应用层代码调用。
3.1 Heap_1
适用于绝不删除任务和其他内核对象的场景。
适用于商业高安全性禁止动态内存分配的场景。
FreeRTOSConfig.h 中的常亮 configTOTAL_HEAP_SIZE 定义了堆内存的总字节数.
Heap_1的 pvPortMalloc()策略是,每调用一次,都会将8位长度类型的数组内存堆空间再分成更小的数据块。
每次分配任务空间,都需要调用两次 pvPortMalloc() ,一次分配任务的 TCB ,一次分配任务的堆栈。
3.2 Heap_2
Heap_2 已经被功能更多的 Heap_4 方案替代了。Heap_2之所以保存在代码中,只是提供向前的兼容性,并不推荐在新方案中使用。
Heap_2 的策略也是内存堆空间的再划分,但它使用了best-fit 算法去分配空间,而不像Heap_1实实在在地分配。 best-fit算法会寻找最接近需求空间的空闲数据块。
不像 Heap_4, Heap_2不会把临近的空闲空间整合为一整个更大的空间。所以官方强烈不推荐再使用Heap_2! 推荐使用 Heap_4方案。
4. 任务管理
4.7 Expanding the Not Running State
An application may consist of many tasks. If the processor running the application includes a single core, then only one task may be executing at any given time. This implies that a task may exist in one of two states: Running and Not Running. This simplistic model is considered first. Later in this chapter we describe the several sub-states of the Not Running state.
All task that are not currently Running are in the Not Running state. Only one task can be in the Running state at any one time in a single core MCU.
翻译:
应用程序可能包含许多任务。如果运行应用程序的处理器包含单个核心,则在任何给定时间只能执行一个任务。这意味着任务可能存在于两种状态之一:正在运行和未运行。首先考虑这个简单的模型。在本章后面,我们将描述未运行状态的几个子状态。
所有当前未运行的任务都处于未运行状态。在单核 MCU 中,任何时候只能有一个任务处于运行状态。非运行状态包括:阻塞状态和挂起状态;
4.7.1 The Blocked State
A task waiting for an event is said to be in the 'Blocked' state, a sub-state of the Not Running state.(Blocked: event-driven)
Tasks can enter the Blocked state to wait for two different types of events:
等待事件的任务被称为处于“阻塞”状态,这是“未运行”状态的子状态。(阻塞:事件驱动)
1. Temporal (time-related) events— these events occur either when a delay period expires or an absolute time is reached. For example, a task may enter the Blocked state to wait for 10 milliseconds to pass.
2. Synchronization events— these events originate from another task or interrupt. For example, a task may enter the Blocked state to wait for data to arrive on a queue. Synchronization events cover a broad range of event types.
FreeRTOS queues, binary semaphores, counting semaphores, mutexes, recursive mutexes, event groups, stream buffers, message buffers, and direct to task notifications can all create synchronization events. Later chapters cover most of these features.
A task can block on a synchronization event with a timeout, effectively blocking on both types of event simultaneously. For example, a task may choose to wait for a maximum of 10 milliseconds for data to arrive on a queue. The task will leave the Blocked state if data arrives within 10 milliseconds or if 10 milliseconds pass without data arriving.
4.7.2 The Suspended State
Suspended is also a sub-state of Not Running. Tasks in the Suspended state are not available to the scheduler. The only way to enter the Suspended state is through a call to the vTaskSuspend() API function, and the only way out is through a call to the vTaskResume() or xTaskResumeFromISR() API functions. Most applications do not use the Suspended state.
4.7.3 The Ready State
Tasks that are in the Not Running state and are not Blocked or Suspended are said to be in the Ready state. They can run, and are therefore 'ready' to run, but are not currently in the Running state.
4.7.4 Completing the State Transition Diagram 完整的任务状态转换逻辑图
Figure 4.7 expands on the simplified state diagram to include all of the Not Running sub-states described in this section. 下图就是完整的所有任务状态的切换:

Each task requires two blocks of RAM: one to hold its Task Control Block (TCB) and one to store its stack.
5 队列管理
“队列”提供了任务到任务、任务到中断以及中断到任务的通信机制。
5.1.1 本章涵盖:
如何创建队列。
队列如何管理其包含的数据。
如何将数据发送到队列。
如何从队列接收数据。
在队列上阻塞意味着什么。
如何在多个队列上阻塞。
如何覆盖队列中的数据。
如何清除队列。
在写入和读取队列时任务优先级的影响。
本章仅介绍任务到任务的通信。第 7 章介绍任务到中断和中断到任务的通信。
5.2 队列的特征
5.2.1 数据存储
队列可以容纳有限数量的固定大小的数据项[^8]。队列容纳数据项的数量称为其“长度”。每个数据项的长度和大小都是在创建队列时设置的。
[^8]: FreeRTOS 消息缓冲区(在 TBD 章节中描述)为保存可变长度消息的队列提供了一种更轻量的替代方案。
队列通常用作先进先出 (FIFO) 缓冲区,其中数据被写入队列的末尾(尾部)并从队列的前面(头部)移除。图 5.1 演示了将数据写入和读取用作 FIFO 的队列。也可以将数据写入队列的前面,并覆盖队列前面已有的数据。
Figure 5.1 An example sequence of writes to, and reads from a queue
通常,有两种方法可以实现队列行为:
1. 数据复制方式 (复制队列)
复制方式,意味着发送到队列的数据被逐字节复制到队列中。
2. 数据指针方式 (指针队列)
数据指针方式,意味着队列仅保存指向发送数据的指针,而不是数据本身。
FreeRTOS 使用的是数据复制方式实现的队列。因为它比数据指针引用实现的队列更强大且更易于使用,因为:
-复制队列并不妨碍指针队列。无法执行复制队列时(比如数据无法复制时),则可以使用指针队列。
-任务栈区的局部变量,可直接发送到队列。即使任务被释放,意味着栈区也被释放,复制方式队列存的数据也不受影响。
-发送数据到队列,无需事先为数据分配存储空间。数据会被复制到队列内部的存储空间(pxQueue->pcWriteTo)。
-发送任务和接收任务彻底解耦:应用程序设计人员不需要关心哪个任务“拥有”数据,或者哪个任务负责发布数据。
-FreeRTOS 全权负责分配用于存储数据的内存。
-在具有内存保护的系统中,会限制对 RAM 的访问,只有当发送和接收任务都可以访问引用的数据时,才能使用指针队列。而复制队列则不存在这种问题。
5.2.2 队列的多任务访问
队列是内核中合法、独立存在的对象,可以被任何能够感知到队列存在的任务(any task)或者中断服务程序(ISR)访问。任何数量的任务都可以往同一个队列里写数据,并且任意数量的任务都可以从同一个队列里读取数据。在实际项目中,通常有相对较多的任务往同一个队列里写数据,且相对较少的任务从同一个队列里读取数据。
5.2.3 队列读取阻塞
任务从队列中读取数据时,可以设定一个阻塞时间。当任务读取到空队列时,这个时间用来阻塞任务,去等队列数据的到来。在限定时间内,若有其他任务或ISR将数据写入队列,则被阻塞的任务会自动切换成就绪态。如果超过规定的时间后,还没能获取队列数据,此任务也会自动由阻塞态切换为就绪态。
5.2.4 队列写入阻塞
跟队列读取阻塞情况类似,任务也可以在写入队列时,设定阻塞时间。若任务欲写入的队列中的数据已满,阻塞时间就是任务处于阻塞状态以等待队列可写入的最长时间。
队列允许多个任务写入,所以存在多个任务因队列空间已满而都被阻塞等待写入的情况。在这种情况下,当队列空间可写,只允许解除其中一个任务的阻塞状态(变为就绪态)。这个被解除阻塞态的任务是所有被阻塞任务中优先级最高的那个。如果阻塞任务中有多个同等最高优先级的任务,那么会选择等待时间最长的那个任务(被解除阻塞,进入就绪态)。
5.2.5 队列集的阻塞
多个队列可以组合成队列集,从而允许任务进入阻塞状态以等待集合中任何队列上的数据可用。第 5.6 节“从多个队列接收”将会详细介绍队列集。
5.2.6 创建队列: 队列存储空间的静态分配和动态分配
队列通过队列句柄来引用(使用)。队列句柄的数据类型是 QueueHandle_t. 在使用之前,必须先创建队列。
内核提供两个函数用于创建队列:xQueueCreate(), xQueueCreateStatic().
在创建时,每个队列都需要两块数据存储空间(RAM),其中一块存储空间用于存放队列数据结构体自身,另一块用于存放队列通信的消息数据。xQueueCreate() 从堆空间动态分配获取存储空间。 xQueueCreateStatic()则需要预先分配存储空间再以参数形式传入。
5.3 使用队列
5.3.1 The xQueueCreate() API 函数
函数原型:
QueueHandle_t xQueueCreate( UBaseType_t uxQueueLength, UBaseType_t uxItemSize );
xQueueCreateStatic() 则需要两个额外的参数:预先分配的存储空间用来存放队列结构体自身数据和存储通信消息数据。
xQueueCreate() 参数与返回值:
-uxQueueLength: 队列长度,创建队列时指定的队列最多可容纳消息的个数。
-uxItemSize: 消息长度,队列单个消息的字节数。
-Return value:
如果返回值=NULL,队列创建失败。内核可分配的空间不足导致。
如果返回值非空,队列创建成功。返回值是队列的句柄变量。
xQueueReset() 也是一个 API 函数,用来复位队列:把一个已经创建出来的队列恢复成它初始的“空”状态。
5.3.2 The xQueueSendToBack() and xQueueSendToFront() API Functions
可以猜的到, xQueueSendToBack() 发送数据到队列尾部, xQueueSendToFront() 发送数据到队列的头部.
xQueueSend() 与 xQueueSendToBack() 等效且完全相同。
注意:切勿从中断服务例程调用 xQueueSendToFront() 或 xQueueSendToBack()。应使用中断安全版本 xQueueSendToFrontFromISR() 和 xQueueSendToBackFromISR() 代替它们。这些内容在第 7 章中进行了描述。
BaseType_t xQueueSendToFront( QueueHandle_t xQueue,
const void * pvItemToQueue,
TickType_t xTicksToWait );
BaseType_t xQueueSendToBack( QueueHandle_t xQueue,
const void * pvItemToQueue,
TickType_t xTicksToWait );
xQueueSendToFront() 和 xQueueSendToBack() 函数参数及返回值:
-xQueue
数据被发送(写入)到的队列的句柄。队列句柄将从用于创建队列的 xQueueCreate() 或 xQueueCreateStatic() 调用中返回。
-pvItemToQueue
指向要复制到队列中的数据的指针。
队列的存储空间是在创建队列时设定的,因此许多字节会从 pvItemToQueue 复制到队列存储区域中。
-xTicksToWait
如果队列已满,则任务应保持阻塞状态以等待队列中有可用空间的最长时间。
如果 xTicksToWait 为零且队列已满,则 xQueueSendToFront() 和 xQueueSendToBack() 都将立即返回。
阻塞时间以内核的滴答周期为基本事件单位粒度,因此它所代表的绝对时间取决于滴答频率。宏 pdMS_TO_TICKS() 可用于将以毫秒为单位的时间转换为以滴答为单位的时间。
将 xTicksToWait 设置为 portMAX_DELAY 将导致任务无限期等待(不会超时),前提是 FreeRTOSConfig.h 中的 INCLUDE_vTaskSuspend 设置为 1。
-Return value
有两个可能的返回值:
pdPASS:
当数据成功发送到队列时,将返回 pdPASS。
如果指定了阻塞时间(xTicksToWait 不为零),则调用任务可能被置于阻塞状态,以等待队列中的空间在函数返回之前可用,且数据在阻塞时间到期之前已成功写入队列。
errQUEUE_FULL (same value as pdFAIL):
如果由于队列已满而无法将数据写入队列,则返回 errQUEUE_FULL。
任务由于等待队列的可用空间而切换为阻塞状态,但是在阻塞时间内仍然等不到队列的可用空间,也就是等待超时。
5.3.3 The xQueueReceive() API Function
xQueueReceive() 从队列中读取一个消息单元。 被读取的消息单元的队列存储空间将被释放,消息单元会从队列中删除。
注意:切勿从中断服务例程调用 xQueueReceive()。中断安全 xQueueReceiveFromISR() API 函数在第 7 章中描述。
BaseType_t xQueueReceive( QueueHandle_t xQueue,
void * const pvBuffer,
TickType_t xTicksToWait );
xQueueReceive() 函数的参数和返回值如下:
-xQueue
接收(读取)数据的队列句柄。队列句柄将从用于创建队列的 xQueueCreate() 或 xQueueCreateStatic() 调用中返回。
-pvBuffer
指向用于存放从队列读出数据的存储空间的指针。队列所保存的每个数据项的大小在创建队列时设置。
pvBuffer 指向的存储空间必须足够大以容纳从队列读出的数据。
-xTicksToWait
若队列无数据可读,xTicksToWait 就是任务因等待读取队列数据而被阻塞的最大时间。
如果 xTicksToWait 为零,则当队列已为空时 xQueueReceive() 将立即返回。
阻塞时间以内核的滴答周期为基本单位粒度,因此它所代表的绝对时间取决于滴答频率。宏 pdMS_TO_TICKS() 可用于将以毫秒为单位的时间转换为以滴答为单位的时间。
将 xTicksToWait 设置为 portMAX_DELAY 将导致任务无限期等待(不会超时),前提是 FreeRTOSConfig.h 中的 INCLUDE_vTaskSuspend 设置为 1。
-Return value
有两个可能的返回值:
pdPASS:
当成功从队列读取数据时,将返回 pdPASS。
在阻塞时间 (xTicksToWait 不为零)内, 由于等待队列消息属于而被阻塞的任务,获取到了队列消息数据.
errQUEUE_EMPTY (same value as pdFAIL):
如果由于队列已为空而无法从队列读取数据,则返回 errQUEUE_EMPTY。
如果指定了阻塞时间(xTicksToWait 不为零),则调用任务将处于阻塞状态以等待另一个任务或中断将数据发送到队列,但在阻塞时间内仍然等不到可用的队列信息数据,也就是等待超时。
5.3.4 The uxQueueMessagesWaiting() API Function
uxQueueMessagesWaiting() 查询队列中当下有多少个消息单元。
注意:切勿从中断服务例程调用 uxQueueMessagesWaiting()。应使用中断安全的 uxQueueMessagesWaitingFromISR() 代替它。
UBaseType_t uxQueueMessagesWaiting( QueueHandle_t xQueue );
uxQueueMessagesWaiting() 函数的参数和返回值如下:
-xQueue
欲查询的队列的句柄。队列句柄将从用于创建队列的 xQueueCreate() 或 xQueueCreateStatic() 调用中返回。
-Return value
欲查询队列中的信息单元的个数。如果返回零,则队列为空。
---------------------------------------------------------------
5.4 从多个源头接收数据
在 FreeRTOS 设计中,一个任务从多个源头接收数据的情况很常见。接收任务需要知道数据来自哪里,才能确定如何处理它。一种易于实现的设计模式是使用单个队列传输包含数据值和数据源的结构,如图 5.4 所示。

typedef struct{
ID_t eDateID;
int32_t lDateValue;
} Date_t;
-队列消息单元的数据类型是 Date_t. 这个数据类型包含了要传递的真实有效数据的 ID_t 类型和消息种类定义的枚举类型。
-中央控制器任务执行主要的系统功能。它必须对队列中传送给它的输入和系统状态变化作出反应。
-CAN 总线任务用于封装 CAN 总线接口功能。当 CAN 总线任务已接收并解码消息时,它会将已解码的消息以Data_t 结构的形式发送到控制器任务。传输结构的 eDataID 成员告诉控制器任务数据是什么。在此处显示的是电机速度值。传输结构的 lDataValue 成员告诉控制器任务实际的电机速度值。
-人机界面 (HMI) 任务用于封装所有 HMI 功能。机器操作员可能可以通过多种方式输入命令和查询值,这些方式必须在 HMI 任务中检测和解释。输入新命令时,HMI 任务会将命令发送到 Data_t 结构中的控制器任务。传输结构的 eDataID 成员告诉控制器任务数据是什么。在此处显示的情况下,它是一个新的设定点值。传输结构的 lDataValue 成员告诉控制器任务实际的设定点值。
章节 (RB-TBD) 展示了如何扩展此设计模式,以便控制器任务可以直接回复排队结构的任务。
Example 5.2 Blocking when sending to a queue, and sending structures on a queue
【代码例子,省略】
---------------------------------------------------------------
5.5 处理大型或可变大小的数据
如果队列要存储的数据很大,则最好使用数据指针传输,而不采用在队列中复制大量数据的方式。传输指针在处理时间和创建队列所需的 RAM 量方面都更有效率。但是,在对指针进行排队时,必须格外小心以确保:
-严格划分数据RAM空间的访问权限
当通过指针在任务之间共享内存时,必须确保两个任务不会同时修改内存内容,或采取任何其他可能导致内存内容无效或不一致的操作。理想情况下,在将指针发送到队列之前,只应允许发送任务访问内存,在从队列接收到指针之后,只应允许接收任务访问内存。
-保证数据RAM空间的有效性
如果指向的内存是动态分配的,或从预分配的缓冲区池中获取的,则只有一个任务应该负责释放该内存。在内存被释放后,任何任务都不应尝试访问该内存。
绝不应使用指针访问任务栈上分配的数据。任务释放后,堆区也释放,数据将不再有效。
---------------------------------------------------------------
5.6 从多个队列接收消息
5.6.1 队列集
应用程序设计通常需要单个任务来接收不同大小、不同含义、以及不同来源的数据。上一节演示了如何使用接收结构的单个队列以简洁高效的方式执行此操作。但是,有时应用程序的设计人员会遇到限制其设计选择的约束,因此必须对某些数据源使用单独的队列。例如,集成到设计中的第三方代码可能假定存在专用队列。在这种情况下,可以使用“队列集”。
队列集允许任务从多个队列接收数据,而无需任务依次轮询每个队列来确定哪个队列(如果有)包含数据。
使用队列集从多个源接收数据的设计不如使用接收结构的单个队列实现相同功能的设计简洁且效率较低。因此,建议仅在设计约束使其使用绝对必要时才使用队列集。
接下来阐述如何使用队列集:
-创建队列集
-将多个队列加入队列集
信号量也能加入队列集。本书后面将介绍信号量。
-从队列集合中读取以确定集合中的哪些队列包含数据。
当任务从队列集中读取数据时,队列集会把接收到消息数据的那条队列的句柄返回给任务,若队列句柄有效,任务可以直接从该队列读取数据。
注意:每次从队列集接收队列句柄时,都必须读取队列数据,并且不能还没从队列集获取队列句柄,就直接读取队列。
通过在 FreeRTOSConfig.h 中将 configUSE_QUEUE_SETS 编译时配置常量设置为 1,可以启用队列集功能。
5.6.2 The xQueueCreateSet() API 函数
使用前须先创建队列集。在撰写本文时,xQueueCreateSetStatic() 尚未实现。但是队列集本身就是队列,因此可以使用预分配的内存创建一个集合,方法是使用专门设计的 xQueueCreateStatic() 调用。
队列集由句柄引用,句柄是 QueueSetHandle_t 类型的变量。 xQueueCreateSet() API 函数创建一个队列集并返回一个引用所创建队列集的 QueueSetHandle_t。
QueueSetHandle_t xQueueCreateSet( const UBaseType_t uxEventQueueLength);
xQueueCreateSet() 参数和返回值:
-uxEventQueueLength 队列集的事件队列消息长度
When a queue that is a member of a queue set receives data, the handle of the receiving queue is sent to the queue set. uxEventQueueLength defines the maximum number of queue handles that the queue set being created can hold at any one time.
当队列集中的一条队列接收到了数据,这条队列就会被发送到队列集中。
uxEventQueueLength 定义正在创建的队列集可以同时容纳的最大队列句柄数。
Queue handles are only sent to a queue set when a queue within the set receives data.
当队列集中的队列接收到数据后,接收到数据的队列句柄只会被发送到队列集中。
A queue cannot receive data if it is full, so no queue handles can be sent to the queue set if all the queues in the set are full.
一条队列满了,就无法继续接收数据。所以,若队列集中每条队列都满,则没有队列句柄发送到队列集。
Therefore, the maximum number of items the queue set will ever have to hold at one time is the sum of the lengths of every queue in the set.
所以,队列集的消息容量就是每条队列集中的队列长度之和。
例如,如果集合中有三个空队列,每个队列的长度为 5,那么集合中的队列总共可以接收 15 个项目(三个队列乘以每个队列 5 个项目),然后集合中的所有队列才会满。在这个例子中,uxEventQueueLength 必须设置为 15,以保证队列集合可以接收发送给它的每条消息数据。
信号量也可以添加到队列集中。本书后面将介绍信号量。为了计算必要的 uxEventQueueLength,二进制信号量的长度为 1,互斥量的长度为 1,计数信号量的长度由信号量的最大计数值给出。
再举一个例子,如果一个队列集包含一个长度为 3 的队列和一个二进制信号量(长度为 1),则 uxEventQueueLength 必须设置为 4(3 加 1)。
-Return Value 返回值
如果返回 NULL,则无法创建队列集,因为 FreeRTOS 没有足够的堆内存来分配队列集数据结构和存储区域。第 3 章提供了有关 FreeRTOS 堆的更多信息。
如果返回非 NULL 值,则表示队列集创建成功,返回值为所创建队列集的句柄。
5.6.3 The xQueueAddToSet() API 函数
xQueueAddToSet() adds a queue or semaphore to a queue set. Semaphores are described later in this book.
xQueueAddToSet() 添加一个队列或信号量到队列集。信号量会在后续章节描述。
函数原型:
BaseType_t xQueueAddToSet( QueueSetMemberHandle_t xQueueOrSemaphore,
QueueSetHandle_t xQueueSet );
xQueueAddToSet() 参数和返回值:
-xQueueOrSemaphore
欲加入队列集的队列或信号量的句柄。
队列句柄或信号量句柄都可被转化为 QueueSetMemberHandle_t 类型。
-xQueueSet
队列集的句柄。
-Return Value
1. pdPASS:队列集创建成功。
2. pdFAIL:意味着队列或信号量,无法成功加入队列集。
Queues and binary semaphores can only be added to a set when they are empty. Counting semaphores can only be added to a set when their count is zero. Queues and semaphores can only be a member of one set at a time.
队列和二进制信号量只有当它们为空时才允许添加到集合中。计数信号量只有当它们的计数为零时才可以添加到集合中。队列和信号量一次只能成为一个集合的成员。一个队列或信号量“不能”同时成为多个队列集的成员。
5.6.4 The xQueueSelectFromSet() API 函数
xQueueSelectFromSet()用于从队列集中选取(读取)一个队列句柄。
当队列集中某条队列或信号量接收到数据以后,接收到数据的队列或信号量的句柄会被发送给队列集。
当任务调用 xQueueSelectFromSet() 后,接收到信息数据的队列句柄或信号量句柄便间接地会由队列集发送给调用的任务。
从 xQueueSelectFromSet() 函数中返回的队列或信号量句柄包含有效的消息数据,调用任务必须直接从相应的队列或信号量中读取数据。
Note: Do not read data from a queue or semaphore that is a member of a set unless the handle of the queue or semaphore has first been returned from a call to xQueueSelectFromSet(). Only read one item from a queue or semaphore each time the queue handle or semaphore handle is returned from a call to xQueueSelectFromSet().
注意: 严谨从队列集中的队列或信号量中读取数据,除非,队列或信号量句柄是第一次调用 xQueueSelectFromSet() 时返回的!
每次调用 xQueueSelectFromSet() 取得的队列集的队列或信号量后,只能从相应的队列或信号量中读取一个消息单元。
函数原型:
QueueSetMemberHandle_t xQueueSelectFromSet( QueueSetHandle_t xQueueSet,
const TickType_t xTicksToWait );
xQueueSelectFromSet() 参与与返回值:
-xQueueSet
要接收消息单元的队列集的句柄。
-xTicksToWait
当队列集为空时,调用任务用于等待队列集中有效数据而被阻塞的最大时间。
若队列集为空且阻塞时间为0(xTicksToWait=0),那么 xQueueSelectFromSet() 将立即返回。
阻塞时间以内核滴答周期为基本时间单位。所以任务的阻塞时间只取决于内核的滴答频率。
宏 pdMS_TO_TICKS() 可用于将以毫秒为单位的时间转换为以内核滴答频率为单位的时间。
将 xTicksToWait 设置为 portMAX_DELAY 将导致任务无限期等待(不会超时),前提是 FreeRTOSConfig.h 中的 INCLUDE_vTaskSuspend 设置为 1。
-Return Value
非空的返回值是包含有效消息数据队列或信号量的句柄。队列集中队列或信号量的有效数据在阻塞时间内已成功接收,返回队列集中队列或信号量的句柄,任务由阻塞态切换为就绪态。一次 xQueueSelectFromSet 函数的调用,任务只能从队列或信号量中获取一个消息单元,且必须获取,不能放弃。句柄以 QueueSetMemberHandle_t 类型返回,可以转换为 QueueHandle_t 类型或 SemaphoreHandle_t 类型。
如果返回值为 NULL,则无法从队列集合中读取句柄。在阻塞时间内,调用任务将处于阻塞状态且一直等待,但最后还是等不来结果(消息数据),被辜负了哈哈哈。
Example 5.3 *Using a Queue Set(省略)
5.6.5 More Realistic Queue Set Use Cases(省略)
---------------------------------------------------------------
5.7 基于队列实现的邮箱
嵌入式社区对术语没有共识,并且“邮箱”在不同的 RTOS 中含义不同。在本书中,邮箱一词用于指长度为 1 的队列。队列可能被描述为邮箱,因为它在应用程序中的使用方式,而不是因为它与队列有功能差异:
A queue is used to send data from one task to another task, or from an interrupt service routine to a task. The sender places an item in the queue, and the receiver removes the item from the queue. The data passes through the queue from the sender to the receiver.
队列用于任务到任务,中断到任务的数据信息传递。发送者将信息数单元据插入队列,接收者从队列中取走数据消息单元。数据消息通过队列传递,移入、移出。
A mailbox is used to hold data that can be read by any task, or any interrupt service routine. The data does not pass through the mailbox, but instead remains in the mailbox until it is overwritten. The sender overwrites the value in the mailbox. The receiver reads the value from the mailbox, but does not remove the value from the mailbox.
邮箱也存储数据,但是任何任务或中断都可以读取邮箱里的信息。邮箱并不像队列那样传输消息数据,邮箱只是保存信息数据,直到此信息数据空间被复写。发送者复写邮箱中的消息存储空间,接受者只从邮箱中的数据存储空间读取数据,并不会移出数据。
本章节描述基于队列实现的邮箱。
Listing 5.28 shows how a queue is created for use as a mailbox.
代码如下:
typedef struct xExampleStructure
{
TickType_t xTimeStamp;
uint32_t ulValue;
} Example_t;
QueueHandle_t xMailbox;
void vAFunction( void )
{
xMailbox = xQueueCreate( 1, sizeof( Example_t ) );
}
//Listing 5.28 A queue being created for use as a mailbox
5.7.1 The xQueueOverwrite() API 函数
与 xQueueSendToBack() API 函数一样,xQueueOverwrite() API 函数将数据发送到队列。
与 xQueueSendToBack() 不同,如果队列已满,则 xQueueOverwrite() 将覆盖队列中已有的数据。
xQueueOverwrite() 只能用于长度为 1 的队列。覆盖模式将始终写入队列的前端并更新队列前端指针,但不会更新等待的消息。如果定义了 configASSERT,则在队列长度 > 1 时将发生断言。
注意:切勿从中断服务例程调用 xQueueOverwrite()。应使用中断安全版本 xQueueOverwriteFromISR() 代替。
函数原型:
BaseType_t xQueueOverwrite( QueueHandle_t xQueue, const void * pvItemToQueue );
参数与返回值:
-xQueue
数据要发送(写入)到的队列的句柄。队列句柄将从用于创建队列的 xQueueCreate() 或 xQueueCreateStatic() 调用中返回。
-pvItemToQueue
指向要复制到队列中的数据的指针。
队列可以容纳的每个项目的大小是在创建队列时设置的,因此这么多的字节将从 pvItemToQueue 复制到队列存储区域中。
-Return value
即使队列已满,xQueueOverwrite() 也会写入队列,因此 pdPASS 是唯一可能的返回值。
Listing 5.30 shows how xQueueOverwrite() is used to write to the mailbox (queue) created in Listing 5.28.(省略)
5.7.2 The xQueuePeek() API 函数
xQueuePeek() 从队列中接收(读取)一个项目,但不从队列中删除该项目。
xQueuePeek() 从队列头部接收数据,但不修改存储在队列中的数据,也不修改数据在队列中的存储顺序。
注意:切勿从中断服务例程中调用 xQueuePeek()。应使用中断安全版本 xQueuePeekFromISR() 代替。
xQueuePeek()具有与xQueueReceive()相同的函数参数和返回值。
BaseType_t xQueuePeek( QueueHandle_t xQueue,
void * const pvBuffer,
TickType_t xTicksToWait );
Listing 5.32 shows xQueuePeek() being used to receive the item posted to the mailbox (queue) in Listing 5.30.(略)
6. 任务同步与通信
二值信号量
计数信号量
通常计数信号量用于两种场合:1. 事件的计数(counting events) 2. 资源管理(resource management)。
7. 中断管理
7.1 介绍
7.1.1 事件
嵌入式实时系统必须响应来自环境中的事件。比如,以太网外设接收到数据时(外部事件),需要(CPU软件代码)将数据传入 TCP/IP 协议栈中进行处理(响应)。
复杂的系统必须为来自多个来源的事件提供服务,所有这些事件都有不同的处理开销和响应时间要求。在每种情况下,都必须判断最佳的事件处理实施策略:
-如何感知事件?通常使用中断,但也可以轮询感知事件的输入。
-若使用中断,应在中断服务程序 (ISR) 内部执行什么处理,在外部执行哪些处理?通常保持每个 ISR 尽可能短。
-事件如何传达给主(非 ISR)代码,以及如何构造此代码以最好地适应潜在异步事件的处理?
FreeRTOS 不会对应用程序设计人员强加任何特定的事件处理策略,但确实提供了允许以简单且可维护的方式实现所选策略的功能(内核功能 features for sych and communication)。
区分任务的优先级和中断的优先级非常重要:
任务是一种软件功能,与 FreeRTOS 运行的硬件无关。任务的优先级由应用程序编写者在软件中分配,软件算法(调度程序)决定将哪个任务置于运行状态。
虽然中断服务例程是用软件编写的,但它是一种硬件功能,因为硬件控制哪个中断服务例程将运行以及何时运行。任务仅在没有 ISR 运行时运行,因此最低优先级的中断将中断最高优先级的任务,并且任务无法抢占 ISR。
所有运行 FreeRTOS 的MCU架构都能够处理中断,但与中断进入和中断优先级分配相关的细节因MCU的架构而异。
7.1.2 范围
本章讨论:
-可以在中断服务例程中使用特定的 FreeRTOS API 函数。
-推迟中断处理到任务中的方法。
-如何创建和使用二值信号量和计数信号量。
-二值信号量与计数信号量的区别。
-如何使用队列将数据传入ISR或使用队列从ISR中从传出数据。
-某些特定MCU架构上可使用的中断嵌套模型功能。
7.2 可在ISR中使用的内核 APIs 接口函数
7.2.1 中断安全的 APIs 接口函数
通常在ISR中使用 FreeRTOS 内核提供的服务是十分必不可少且不可避免的,但是绝大多数的内核APIs是不能运行于 ISR 中,这是非法的操作,会导致不可预知的错误。这种在ISR中运行非法的内核接口函数,是不能运行在ISR中的,它们通常会将调用此类APIs接口的任务阻塞。若这种APIs函数在ISR中调用就没有可以用来阻塞的任务。FreeRTOS内核为了解决此类问题,于是推出了针对此类功能的两种版本的APIs接口函数,一种版本就是通常任务中调用的,另一种版本是专供ISR中使用的版本。ISR中使用的此类APIs函数名后缀会加上“FromISR”字符。
注意:在ISR中,严禁使用不带有“FromISR”名称后缀的此类内核APIs接口函数。
7.2.2 使用中断版本的内核APIs接口的优点
将那些不得不在ISR中使用的内核功能单独开发出只在ISR中使用的APIs分支版本,可以提高任务代码的执行效率,也可以提升ISR代码的执行效率,同时中断入口也变得更加简单。想知道为什么这么做,可以假设此类函数仅存在单一版本,那么:
-API 函数需要额外的逻辑来确定它们是从任务还是 ISR 调用的。额外的逻辑会引入函数中的新路径,使函数更长、更复杂、更难测试。
-当从任务调用该函数时,某些 API 函数参数将会过时,而当从 ISR 调用该函数时,其他 API 函数参数将会过时。
-Each FreeRTOS port would need to provide a mechanism for determining the execution context (task or ISR).
-每种MCU架构需要提供一个额外的机制去实现上下文切换。
-Architectures on which it is not easy to determine the execution context (task or ISR) would require additional, wasteful, more complex to use, and non-standard interrupt entry code that allowed the execution context to be provided by software.
-在不同的MCU架构上实现上下文切换并不容易,且使用起来需要额外的多余的操作,使得使用过程更加复杂,还引入了非标准的中断入口代码。
7.2.3 使用中断版本的内核APIs接口的缺点
引入准备特定内核两种版本的APIs接口函数,虽然使得任务代码和中断服务代码更加高效,但是同时也引入了一些新的问题; 有时需要从任务和 ISR 调用不属于 FreeRTOS API 但使用FreeRTOS API 的函数。
这通常只是在集成第三方代码时才会出现的问题,因为这是软件设计唯一不受应用程序编写者控制的情况。如果这确实成为一个问题,那么可以使用以下技术之一来克服该问题:
-将中断处理推迟到任务[^12],因此 API 函数只能从任务上下文中调用。
-如果您使用的是支持中断嵌套的 FreeRTOS 端口,则请使用以“FromISR”结尾的 API 函数版本,因为该版本可以从任务和 ISR 中调用。(反之则不然,不以“FromISR”结尾的 API 函数不能从 ISR 中调用。)
-第三方代码通常包含一个 RTOS 抽象层,可以实现该层来测试调用该函数的上下文(任务或中断),然后调用适合该上下文的 API 函数。
[^12]: 延迟中断处理将在本书的下一部分中介绍。
7.2.4 The xHigherPriorityTaskWoken 参数
这里介绍 xHigherPriorityTaskWoken 参数的概念. 如果不能完全理解这个参数,请不必困惑,因为后续会有实际代码分析。
如果上下文切换是由中断执行的,那么中断退出时运行的任务可能与进入中断时运行的任务不是同一个任务——中断将中断一个任务,但返回到另一个任务。
一些 FreeRTOS API 函数可以将任务从阻塞状态移至就绪状态。这已经在 xQueueSendToBack() 等函数中得到体现,如果某个任务在阻塞状态下等待主题队列中的数据可用,该函数将解除对某个任务的阻塞。
如果由 FreeRTOS API 函数解除阻塞的任务的优先级高于处于运行状态的任务的优先级,则根据 FreeRTOS 调度策略,应该切换到优先级更高的任务。实际切换到优先级更高的任务的时刻取决于调用 API 函数的上下文环境:
-在任务中调用此API
If configUSE_PREEMPTION is set to 1 in FreeRTOSConfig.h then the switch to the higher priority task occurs automatically within the API function, in other words, before the API function has exited. This has already been seen in Figure 6.6, where a write to the timer command queue resulted in a switch to the RTOS daemon task before the function that wrote to the command queue had exited.
如果在 FreeRTOSConfig.h 中将 configUSE_PREEMPTION 设置为 1,则在 API 函数内(即在 API 函数退出之前)会自动切换到优先级更高的任务。这已在图 6.6 中看到,其中写入计时器命令队列导致在写入命令队列的函数退出之前切换到 RTOS 守护进程任务。
-在中断中调用此API
A switch to a higher priority task will not occur automatically inside an interrupt. Instead, a variable is set to inform the application writer that a context switch should be performed. Interrupt safe API functions (those that end in "FromISR") have a pointer parameter called pxHigherPriorityTaskWoken that is used for this purpose.
切换到更高优先级的任务不会在中断内自动发生。相反,会设置一个变量来通知应用程序编写者应执行上下文切换。中断安全 API 函数(以“FromISR”结尾的函数)有一个名为 pxHigherPriorityTaskWoken 的指针参数,用于此目的。
If a context switch should be performed, then the interrupt safe API function will set *pxHigherPriorityTaskWoken to pdTRUE. To be able to detect this has happened, the variable pointed to by pxHigherPriorityTaskWoken must be initialized to pdFALSE before it is used for the first time.
如果需要执行上下文切换,则中断安全 API 函数将设置 *pxHigherPriorityTaskWoken 为 pdTRUE。为了能够检测到这种情况,pxHigherPriorityTaskWoken 指向的变量必须在首次使用前初始化为 pdFALSE。
If the application writer opts not to request a context switch from the ISR, then the higher priority task will remain in the Ready state until the next time the scheduler runs, which in the worst case will be during the next tick interrupt.
如果应用程序编写者选择不从 ISR 请求上下文切换,则优先级较高的任务将保持就绪状态,直到调度程序下次运行,最坏的情况是在下一个滴答中断期间。
FreeRTOS API functions can only set *pxHighPriorityTaskWoken to pdTRUE. If an ISR calls more than one FreeRTOS API function, then the same variable can be passed as the pxHigherPriorityTaskWoken parameter in each API function call, and the variable only needs to be initialized to pdFALSE before it is used for the first time.
FreeRTOS API 函数只能将 *pxHighPriorityTaskWoken 设置为 pdTRUE。如果 ISR 调用多个 FreeRTOS API 函数,则可以在每个 API 函数调用中将同一个变量作为 pxHigherPriorityTaskWoken 参数传递,并且只需在第一次使用之前将该变量初始化为 pdFALSE。
There are several reasons why context switches do not occur automatically inside the interrupt safe version of an API function:
这里有几个原因解释为什么在中断安全版本的API函数中不自动执行上下文切换:
-避免不必要的上下文切换
An interrupt may execute more than once before it is necessary for a task to perform any processing. For example, consider a scenario where a task processes a string that was received by an interrupt driven UART; it would be wasteful for the UART ISR to switch to the task each time a character was received because the task would only have processing to perform after the complete string had been received.
在任务需要执行任何处理之前,中断可能会执行多次。例如,考虑这样一种情况,任务处理由中断驱动的 UART 接收的字符串;如果 UART ISR 每次收到一个字符就切换到该任务,那就太浪费了,因为该任务只有在收到完整的字符串后才需要执行处理。
-控制执行顺序
中断可能偶尔发生,并且发生的时间不可预测。FreeRTOS 专业用户可能希望暂时避免在应用程序中的特定点不可预测地切换到其他任务,尽管这也可以使用 FreeRTOS 调度程序锁定机制来实现。
-可移植性
It is the simplest mechanism that can be used across all FreeRTOS ports.
这是所有内核移植部分都可以使用的最简单的机制。
-效率
Ports that target smaller processor architectures only allow a context switch to be requested at the very end of an ISR, and removing that restriction would require additional and more complex code. It also allows more than one call to a FreeRTOS API function within the same ISR without generating more than one request for a context switch within the same ISR.
针对较小处理器架构的端口仅允许在 ISR 的最后请求上下文切换,而消除该限制将需要更多更复杂的代码。它还允许在同一 ISR 中多次调用 FreeRTOS API 函数,而无需在同一 ISR 中生成多个上下文切换请求。
-在 RTOS 滴答中断中执行
As will be seen later in this book, it is possible to add application code into the RTOS tick interrupt. The result of attempting a context switch inside the tick interrupt is dependent on the FreeRTOS port in use. At best, it will result in an unnecessary call to the scheduler.
正如本书后面将要介绍的那样,可以将应用程序代码添加到 RTOS 滴答中断中。尝试在滴答中断内进行上下文切换的结果取决于正在使用的 FreeRTOS 端口。充其量,它会导致对调度程序进行不必要的调用。
pxHigherPriorityTaskWoken 参数的使用是可选的。如果不需要,则将 pxHigherPriorityTaskWoken 设置为 NULL。
7.2.5 The portYIELD_FROM_ISR() 和 portEND_SWITCHING_ISR() 宏
本节介绍用于从 ISR 请求上下文切换的宏。如果您尚未完全理解本节,请不要担心,因为后面的章节提供了实际示例。
taskYIELD() 是一个宏,可以在任务中调用它以请求上下文切换。
portYIELD_FROM_ISR() 和 portEND_SWITCHING_ISR() 都是 taskYIELD() 的中断安全版本。portYIELD_FROM_ISR() 和 portEND_SWITCHING_ISR() 的使用方式相同,并且执行相同的操作[^13]。
一些 FreeRTOS端口仅提供两个宏中的一个。较新的 FreeRTOS 端口同时提供这两个宏。本书中的示例使用 portYIELD_FROM_ISR()。
[^13]: 从历史上看,portEND_SWITCHING_ISR() 是 FreeRTOS 端口中使用的名称,它要求中断处理程序使用汇编代码包装器,而 portYIELD_FROM_ISR() 是 FreeRTOS 端口中使用的名称,它允许整个中断处理程序用 C 语言编写。
portEND_SWITCHING_ISR( xHigherPriorityTaskWoken ); //Listing 7.1 The portEND_SWITCHING_ISR() macros
portYIELD_FROM_ISR( xHigherPriorityTaskWoken ); //Listing 7.2 The portYIELD_FROM_ISR() macros
从中断安全 API 函数中传递出来的 xHigherPriorityTaskWoken 参数可直接用作 portYIELD_FROM_ISR() 调用中的参数。
如果 portYIELD_FROM_ISR() xHigherPriorityTaskWoken 参数为 pdFALSE(零),则不会请求上下文切换,并且该宏无效。如果 portYIELD_FROM_ISR() xHigherPriorityTaskWoken 参数不是 pdFALSE,则请求上下文切换,并且运行状态中的任务可能会发生变化。中断将始终返回运行状态中的任务,即使运行状态中的任务在中断执行时发生变化。
大多数 FreeRTOS 端口允许在 ISR 中的任何位置调用 portYIELD_FROM_ISR()。一些 FreeRTOS 端口(主要是针对较小架构的端口)仅允许在 ISR 的最后调用 portYIELD_FROM_ISR()。
7.3 被延迟的中断处理 Deferred Interrupt Processing
被推迟到任务中执行的中断反馈代码:中断推迟任务
推迟中断处理:ISR中需记录中断源,并清除中断请求。其他对中断源必要的反馈操作可以放到任务中执行,这样ISR可以快入快出。这种中断反馈被推迟到任务中执行的情况,叫推迟中断处理。一般中断反馈同样比较重要,所以必要的话,理应连带调整推迟反馈所在任务的优先级。
若退出中断后,中断推迟任务的优先级高于其他所有任务的优先级,那么中断反馈操作将立即执行,就像在中断中执行一样的感觉。
中断推迟处理机制:就是中断中仅处理中断原生必要操作,比如清除中断标志位,避免持续触发中断。还有就是对任务发出事件信号,告诉任务发生了某某事件,最后在任务中处理本应在中断ISR中的响应操作。
7.4 二值信号量
Binary Semaphores are Used for Synchronization. 二进制信号量用于同步。
The interrupt safe version of the Binary Semaphore API can be used to unblock a task each time a particular interrupt occurs, effectively synchronizing the task with the interrupt. This allows the majority of the interrupt event processing to be implemented within the synchronized task, with only a very fast and short portion remaining directly in the ISR. As described in the previous section, the binary semaphore is used to 'defer' interrupt processing to a task[^14].
翻译:
每当特定中断发生后,可以在中断服务函数ISR中使用“中断安全版本的二进制信号量”解锁任务,高效地同步任务与中断。中断代码中仅包含给任务发送信号和必要的操作,中断需要处理的大部分操作可以放在同步任务中处理。这种处理模式效率高且中断代码短执行快。如上一节所述,二进制信号量用于将中断处理“推迟”给任务[^14]。
[^14]: It is more efficient to unblock a task from an interrupt using a direct to task notification than it is using a binary semaphore. Direct to task notifications are not covered until Chapter 10, Task Notifications.
翻译:在中断ISR中,直接任务通知功能比使用二进制信号量的效率更加高。直到第 10 章“任务通知”才涉及直接任务通知。
如之前图 7.1 所示,如果中断处理对时间要求特别严格,则可以设置延迟处理任务的优先级,以确保该任务始终抢占系统中的其他任务。然后可以在 ISR 中添加对 portYIELD_FROM_ISR() 的调用,确保 ISR 直接返回到中断处理被延迟到的任务。这可以确保整个事件处理连续(不间断)地执行,就像它全部在 ISR 本身内实现一样。图 7.2 重复了图 7.1 中所示的场景,但更新了文本以描述如何使用信号量控制延迟处理任务的执行。
Figure 7.2 Using a binary semaphore to implement deferred interrupt processing (略)
The deferred processing task uses a blocking 'take' call to a semaphore as a means of entering the Blocked
state to wait for the event to occur. When the event occurs, the ISR uses a 'give' operation on the same
semaphore to unblock the task so that the required event processing can proceed.翻译:
延迟处理任务使用对信号量的阻塞“take”调用作为进入阻塞状态以等待事件发生的方式。当事件发生时,ISR 使用同一信号量的“give”操作来解除任务阻塞,以便所需的事件处理可以继续进行。
'Taking a semaphore' and 'giving a semaphore' are concepts that have different meanings depending on their usage scenario. In this interrupt synchronization scenario, the binary semaphore can be considered
conceptually as a queue with a length of one. The queue can contain a maximum of one item at any time, so is always either empty or full (hence, binary). By calling xSemaphoreTake(), the task to which interruptprocessing is deferred effectively attempts to read from the queue with a block time, causing the task to enter the Blocked state if the queue is empty. When the event occurs, the ISR uses the xSemaphoreGiveFromISR() function to place a token (the semaphore) into the queue, making the queue full. This causes the task to exit the Blocked state and remove the token, leaving the queue empty once more. When the task has completed its processing, it once more attempts to read from the queue and, finding the queue empty, re-enters the Blocked state to wait for the next event. This sequence is demonstrated in Figure 7.3.
“获取信号量”和“发出信号量”在不同的使用场景中具有不同含义。在此中断同步场景中,二进制信号量在概念上可视为长度为 1 的队列。队列在任何时候最多可包含一个项目,因此始终为空或满(因此为二进制)。在阻塞期间,被委任处理中断大部分操作的任务通过调用 xSemaphoreTake() 函数来高效地读取队列,若队列为空,则进入(或保持)阻塞状态。当外部事件发生后,ISR 使用 xSemaphoreGiveFromISR() 函数在队列中放置一个令牌(信号量),使队列变满。这会导致任务退出阻塞状态并删除令牌,使队列再次变为空。当任务完成其处理后,它会再次尝试从队列中读取,并发现队列为空,因此重新进入阻塞状态以等待下一个事件。图 7.3 演示了此序列。
/* 实际项目代码分析 - xSemaphoreGiveFromISR() 和 xSemaphoreTake() 开始 */
/* 技术主题:二进制信号量的使用方法 */
/** @note: 此函数被 CAN 接收中断调用,属于中断ISR中的代码!
* @brief CAN接收完成回调函数
* @param argument:
* @retval None
*/
void HAL_CAN_RxCpltCallback(CAN_HandleTypeDef *CanHandle)
{
if(CanHandle == &hcan1)
{
osSemaphoreRelease(BinarySem_Rx_CAN1Handle);
}
if(CanHandle == &hcan2)
{
osSemaphoreRelease(BinarySem_Rx_CAN2Handle); //数据流 CAN2 接收,来自中断。
}
}
/**
* @brief Release a Semaphore token
* @param semaphore_id semaphore object referenced with \ref osSemaphore.
* @retval status code that indicates the execution status of the function.
* @note MUST REMAIN UNCHANGED: \b osSemaphoreRelease shall be consistent in every CMSIS-RTOS.
*/
osStatus osSemaphoreRelease (osSemaphoreId semaphore_id)
{
osStatus result = osOK;
portBASE_TYPE taskWoken = pdFALSE;
if (inHandlerMode()) { /* 在中断中 give ,这里是 semaphore give! */
if (xSemaphoreGiveFromISR(semaphore_id, &taskWoken) != pdTRUE) {
return osErrorOS;
}
portEND_SWITCHING_ISR(taskWoken);
}
else { //代码不走这里,因为在中断中调用
if (xSemaphoreGive(semaphore_id) != pdTRUE) {
result = osErrorOS;
}
}
return result;
}
void CAN2Receive_Task(void const * argument) -> [a freertos task]
osSemaphoreWait(BinarySem_Rx_CAN2Handle,osWaitForever); -> [cmsis_os.c]
xSemaphoreTake(semaphore_id, ticks) != pdTRUE -> [freertos native function @file smphr.h]
#define xSemaphoreTake( xSemaphore, xBlockTime ) \ /* 这里是 semaphore take! */
xQueueGenericReceive( ( QueueHandle_t ) ( xSemaphore ), NULL, ( xBlockTime ), pdFALSE )
/* 实际项目代码分析 - xSemaphoreGiveFromISR() 和 xSemaphoreTake() 结束 */Figure 7.3 shows the interrupt 'giving' the semaphore, even though it has not first 'taken' it, and the task 'taking' the semaphore, but never giving it back. This is why the scenario is described as being conceptually similar to writing to and reading from a queue. It often causes confusion as it does not follow the same rules as other semaphore usage scenarios, where a task that takes a semaphore must always give it back—such as the scenarios described in Chapter 8, Resource Management.翻译:
图 7.3 显示了中断“给出”信号量,即使它没有首先“获取”它,并且任务“获取”信号量,但从不归还它。这就是为什么该场景被描述为在概念上类似于写入和读取队列的原因。它经常引起混淆,因为它不遵循与其他信号量使用场景相同的规则,在这些场景中,获取信号量的任务必须始终归还它——例如第 8 章“资源管理”中描述的场景。
8 资源管理
8.1 章节介绍和学习范围
在多任务系统中,如果任务在访问资源的过程中转为阻塞态,且未能完整执行整个资源访问过程,则可能会出现错误。如果该任务使资源处于不一致的状态,则任何其他任务或中断对同一资源的访问都可能导致数据损坏或其他类似问题。
比如:
-访问外设:两个任务写LCD
1. 正在运行中的任务A开始往LCD写入字符串 "Hello world"。
2. 当写到"Hello w"时,任务B抢占任务A。
3. 在还没有进入阻塞状态前,任务B向LCD写入: "Abort, Retry, Fail?"
4. 任务A继续从上次被抢占的地方执行代码, 将剩余字符"orld"写入LCD.
此过程会显示损坏的异常字符串: "Hello wAbort, Retry, Fail?orld".
-读取、修改、写入操作 (单个变量的非原子访问)
下面展示了一段C代码和对应的汇编代码。PORTA是RAM中的C语言中的单个独立变量。
/* C代码. */
PORTA |= 0x01;
/* C代码对应的汇编代码 */
LOAD R1,[#PORTA] ; 变量PORTA的值被从内存加载到 R1 寄存器(右值操作);[读]
MOVE R2,#0x01 ; 字符常量从Flash或RAM代码段中加载到 R2 寄存器;[读]
OR R1,R2 ; R1 和 R2 执行或操作,结果存入 R1;[修改]
STORE R1,[#PORTA] ; 将计算结果从R1写入 PORTA (左值操作);[写]可以看到: PORTA变量和字符常量的值先从内存加载到CPU的寄存器,然后CPU计算后修改寄存器,最后将计算结果写回PORTA地址处。因为过程中需要执行多条汇编指令且能被打断,所以这种“读-改-写”过程是一个“非原子”的操作过程。
再分析如下剧情:两个任务试图更新内存中 PORTA 变量。
1. 任务A加载PORTA的值到寄存器-读取操作。
2. 任务A还没来得及修改和写操作就被任务B给抢占了。
3. 任务B更新完PORTA的值后,进入阻塞状态。
4. 任务A从被抢占的代码处继续运行,再次修改寄存器的值,再次回写结果到内存PORTA地址。
此过程,修改操作执行两次,而第二次的R1数据就是被污染的“错误”数据,最后错误数据会覆盖PORTA的值。
引申:如若 PORTA 是外设某个寄存器的值,同样会发生这种异常,且可能会更加致命。
-结构体变量的非原子访问
更新具有多个成员变量的结构体变量时,或者更新一个超过架构自然字长度的变量(比如32-bit/16bit机器架构)就是非原子操作。如果在访问这种资源的过程中被打断,就可能导致数据错乱或数据丢失。
引申:访问一个数组中的多个数据时,也是非原子操作(for循环操作的)。
-可重入函数
可重入函数的定义:若一个函数可被多个任务调用、或被多个任务和中断ISR调用时,数据不会出现错误,是安全的,那么这种函数就是可重入函数。可重入即“线程安全”,因为他们可被多个线程访问,且没有数据或操作逻辑错误。
每个任务各自维护自己的栈区和它自己一套的处理器寄存器值。如果某个函数不访问除堆栈上存储的数据或寄存器中保存的数据之外的任何数据,则该函数是可重入的,并且是线程安全的。清单 8.2 是可重入函数的示例。清单 8.3是不可重入函数的示例。
如果应用程序使用 newlib C 库,则必须在 FreeRTOSConfig.h 中将 configUSE_NEWLIB_REENTRANT 设置为 1,以确保正确分配 newlib 所需的线程本地存储。
如果应用程序使用 picolibc C 库,则必须在 FreeRTOSConfig.h 中将 configUSE_PICOLIBC_TLS 设置为 1,以确保正确分配 picolibc 所需的线程本地存储。
如果应用程序使用任何其他 C 库并且需要线程本地存储 (TLS),则必须在 FreeRTOSConfig.h 中将 configUSE_C_RUNTIME_TLS_SUPPORT 设置为 1,并且必须实现以下宏:
configTLS_BLOCK_TYPE - Type of the per task TLS block.
configINIT_TLS_BLOCK - Initialize per task TLS block.
configSET_TLS_BLOCK - Update current TLS block. Called during context switch to ensure that the correct TLS block is used.
configDEINIT_TLS_BLOCK - Free the TLS block.
/* A parameter is passed into the function. This will either be passed on the
stack, or in a processor register. Either way is safe as each task or interrupt that calls the function maintains its own stack and its own set
of register values, so each task or interrupt that calls the function will
have its own copy of lVar1. */
long lAddOneHundred( long lVar1 )
{
/* This function scope variable will also be allocated to the stack or a
register, depending on the compiler and optimization level. Each task
or interrupt that calls this function will have its own copy of lVar2.
*/
long lVar2;
lVar2 = lVar1 + 100;
return lVar2;
}
Listing 8.2 An example of a reentrant function
-------------------------------------------------------*/
/*-------------------------------------------------------
/* In this case lVar1 is a global variable, so every task that calls
lNonsenseFunction will access the same single copy of the variable. */
long lVar1;
long lNonsenseFunction( void )
{
/* lState is static, so is not allocated on the stack. Each task that
calls this function will access the same single copy of the variable.
*/
static long lState = 0;
long lReturn;
switch( lState )
{
case 0 : lReturn = lVar1 + 10;
lState = 1;
break;
case 1 : lReturn = lVar1 + 20;
lState = 0;
break;
}
}
Listing 8.3 An example of a function that is not reentrant8.1.1 互斥机制
为了时刻保持数据的一致性、完整性,在访问任务间或任务中断间共享的资源时,必须使用“互斥”机制。由于共享资源本身具有不可重入且非线程安全的属性,互斥机制是为了保证每次共享资源被访问过程的完整性一致性。也就是说,某个任务或中断一旦开始访问共享资源,此线程就可以独占访问该资源,直到该资源恢复到一致状态。
虽然FreeRTOS提供了数个特性用于实现互斥机制,但是实现互斥最好的方法仍然是,在项目代码设计中,资源不共享,每个独立资源只被一个任务访问。尽管绝对的资源不共享设计理念在实际项目设计中不可能、不现实、不存在,但是只要资源能不共享的地方,就设计成不共享。
8.1.2 范围
本章节讨论:
-什么时候需要、为什么需要资源管理和控制
-临界区的概念
-互斥的概念
-什么是调度器挂起
-如何使用互斥
-如何创建并使用看门(gatekeeper)任务
-什么是优先级反转,以及优先级继承如何减少(但不能消除)其影响。
8.2 临界区和调度器挂起
基本临界区基于开关中断实现;还有一种临界区基于调度器上锁实现。
8.2.1 基本的临界区
基本临界区是被宏 taskENTER_CRITICAL() 和 taskEXIT_CRITICAL()调用包围的代码区域。临界区也称为关键区域。
taskENTER_CRITICAL() 和 taskEXIT_CRITICAL() 不接受任何参数,也不返回值[^23]。它们的用法如清单 8.4 所示。
[^23]:类似函数的宏实际上并不像真正的函数那样“返回值”。本书将术语“返回值”应用于宏,因为最简单的方法是将宏视为一个函数。
/* Ensure access to the PORTA register cannot be interrupted by placing
it within a critical section. Enter the critical section. */
taskENTER_CRITICAL();
/* A switch to another task cannot occur between the call to
taskENTER_CRITICAL() and the call to taskEXIT_CRITICAL(). Interrupts may
still execute on FreeRTOS ports that allow interrupt nesting, but only
interrupts whose logical priority is above the value assigned to the
configMAX_SYSCALL_INTERRUPT_PRIORITY constant – and those interrupts are
not permitted to call FreeRTOS API functions. */
PORTA |= 0x01;
/* Access to PORTA has finished, so it is safe to exit the critical section. */
taskEXIT_CRITICAL();
//Listing 8.4 Using a critical section to guard access to a register本书附带的示例项目使用名为 vPrintString() 的函数将字符串写入标准输出,即使用 FreeRTOS Windows 端口时的终端窗口。vPrintString() 由许多不同的任务调用;因此,理论上,它的实现可以使用关键部分保护对标准输出的访问,如清单 8.5 所示。
// vPrintString 也使用临界区机制实现互斥访问
void vPrintString( const char *pcString )
{
/* Write the string to stdout, using a critical section as a crude method of
mutual exclusion. */
taskENTER_CRITICAL(); //临界区,粗暴的互斥机制
{
printf( "%s", pcString );
fflush( stdout );
}
taskEXIT_CRITICAL(); //临界区,粗暴的互斥机制
}
//Listing 8.5 A possible implementation of vPrintString()
以这种方式实现的临界区是一种非常粗暴的提供互斥的方法。它们的工作原理是完全禁用中断,或禁用到由configMAX_SYSCALL_INTERRUPT_PRIORITY 设置的中断优先级,具体取决于所使用的 FreeRTOS 端口。抢占式上下文切换只能在中断内发生,因此,只要中断保持禁用状态,调用 taskENTER_CRITICAL() 的任务就保证保持运行状态,直到退出临界区。
基本临界区必须保持非常短,否则将对中断响应时间产生不利影响。每次对 taskENTER_CRITICAL() 的调用都必须与对 taskEXIT_CRITICAL() 的调用紧密配对。因此,不应使用临界区保护标准输出(stdout,即计算机写入其输出数据的流)(如清单 8.5 所示),因为写入终端可能是一个相对较长的操作。本章中的示例探讨了替代解决方案。
临界区的嵌套是安全的,因为内核会保留嵌套深度的计数。只有当嵌套深度返回零时,才会退出关键部分,也就是在每次调用 taskENTER_CRITICAL() 后执行一次 taskEXIT_CRITICAL() 调用。
调用 taskENTER_CRITICAL() 和 taskEXIT_CRITICAL() 是任务改变 FreeRTOS 所运行处理器的中断启用状态的唯一合法方法。通过任何其他方式改变中断启用状态都将使宏的嵌套计数无效。
taskENTER_CRITICAL() 和 taskEXIT_CRITICAL() 不以 'FromISR' 结尾,因此不能从中断服务例程中调用。taskENTER_CRITICAL_FROM_ISR() 是 taskENTER_CRITICAL() 的中断安全版本,而 taskEXIT_CRITICAL_FROM_ISR() 是 taskEXIT_CRITICAL() 的中断安全版本。中断安全版本仅适用于允许中断嵌套的 FreeRTOS 端口 — 在禁止中断嵌套的端口中,它们将过时。
taskENTER_CRITICAL_FROM_ISR() 返回一个值,该值必须传递给对 taskEXIT_CRITICAL_FROM_ISR() 的匹配调用。清单 8.6 演示了这一点。
void vAnInterruptServiceRoutine( void )
{
/* Declare a variable in which the return value from
taskENTER_CRITICAL_FROM_ISR() will be saved. */
UBaseType_t uxSavedInterruptStatus;
/* This part of the ISR can be interrupted by any higher priority
interrupt. */
/* Use taskENTER_CRITICAL_FROM_ISR() to protect a region of this ISR.
Save the value returned from taskENTER_CRITICAL_FROM_ISR() so it can
be passed into the matching call to taskEXIT_CRITICAL_FROM_ISR(). */
uxSavedInterruptStatus = taskENTER_CRITICAL_FROM_ISR();
/* This part of the ISR is between the call to
taskENTER_CRITICAL_FROM_ISR() and taskEXIT_CRITICAL_FROM_ISR(), so can
only be interrupted by interrupts that have a priority above that set
by the configMAX_SYSCALL_INTERRUPT_PRIORITY constant. */
/* Exit the critical section again by calling taskEXIT_CRITICAL_FROM_ISR(),
passing in the value returned by the matching call to
taskENTER_CRITICAL_FROM_ISR(). */
taskEXIT_CRITICAL_FROM_ISR( uxSavedInterruptStatus );
/* This part of the ISR can be interrupted by any higher priority
interrupt. */
}
//Listing 8.6 Using a critical section in an interrupt service routine在临界区内执行非必要的代码是非常浪费内核效率的。临界区代码应非常短,快入快出,这才是临界区使用的正确方式。
8.2.2 调度器挂起(或上锁)
临界区也可以基于挂起调度器来实现。中断挂起有时也叫给调度器上锁。
基本临界区可以保护代码不受其他任务或中断影响。但是基于调度器上锁实现的临界区只能保护代码不受任务影响,但是中断可以打断临界区代码。
如果因临界区代码过长而不能使用基于开关中断的临界区,则可以用基于调度器上锁机制的临界区。然而,当调度器被锁,会导致中断活动中恢复(解锁)调度器的操作需要更长的时间。所以,具场景例具体分析,选出最适合的临界区。
8.2.3 The vTaskSuspendAll() API 函数
void vTaskSuspendAll( void );
调用 vTaskSuspendAll() 会暂停调度器。暂停调度程序可防止发生上下文切换,但会启用中断。如果调度器被锁期间有中断请求上下文切换,则该请求被挂起,并且仅在调度器解锁后执行。
调度器上锁期间,不允许调用 FreeRTOS 的 APIs 函数。
8.2.4 The xTaskResumeAll() API 函数
BaseType_t xTaskResumeAll( void );
调用 xTaskResumeAll() API函数会解锁调度器.
返回值:
在调度程序暂停期间发出的上下文切换请求会被挂起,只能在调度器解锁恢复后执行该请求。如果在 xTaskResumeAll() 返回之前执行了被挂起的上下文切换,则返回 pdTRUE。否则返回 pdFALSE。
嵌套调用 vTaskSuspendAll() and xTaskResumeAll() 是安全的,因为内核会跟踪嵌套深度的计数值。仅当嵌套深度返回零时,调度器才会恢复。
清单 8.9 显示了 vPrintString() 的实际实现,它锁定调度器以保护对终端输出的访问。
void vPrintString( const char *pcString )
{
/* Write the string to stdout, suspending the scheduler as a method of
mutual exclusion. */
vTaskSuspendScheduler();
{
printf( "%s", pcString );
fflush( stdout );
}
xTaskResumeScheduler();
} 8.3 互斥锁与二进制信号量
互斥锁是一种特殊类型的二进制信号量,用于控制对两个或多个任务之间共享的资源的访问。MUTEX 一词源于“MUTual EXclusion”。必须在 FreeRTOSConfig.h 中将 configUSE_MUTEXES 设置为 1,才能使用互斥锁。
在互斥场景中,互斥锁可以被认为是与共享资源关联的令牌。任务要合法访问资源,必须首先成功“获取”令牌(成为令牌持有者)。当令牌持有者使用完资源后,必须“归还”令牌。只有当令牌归还后,另一个任务才能成功获取令牌,然后安全地访问相同的共享资源。除非任务持有令牌,否则不允许其访问共享资源。此机制如图 8.1 所示。
虽然互斥量与二进制信号量有很多相似之处,但是图8.1所展示的互斥量与图7.6所展示的使用场景完全不一样。 不同之处在于获取信号量之后的操作:
-用于互斥的信号量必须始终返回。
-用于同步的信号量通常会被丢弃并且不会返回。
Figure 8.1 Mutual exclusion implemented using a mutex (图略)
该机制完全通过应用程序编写出的代码逻辑规则来工作。没有理由说任务不能随时访问资源,但每个任务都“同意”不这样做,除非它能够成为互斥锁持有者。
8.3.1 The xSemaphoreCreateMutex() API 函数
FreeRTOS 还包括 xSemaphoreCreateMutexStatic() 函数,该函数在编译时分配静态创建互斥锁所需的内存:互斥锁是一种信号量。所有不同类型的 FreeRTOS 信号量的句柄都存储在 SemaphoreHandle_t 类型的变量中。
在使用互斥锁之前,必须先创建它。要创建互斥锁类型信号量,请使用 xSemaphoreCreateMutex() API 函数。
SemaphoreHandle_t xSemaphoreCreateMutex( void );
xSemaphoreCreateMutex() 的返回值:
如果返回 NULL,则无法创建互斥锁,因为 FreeRTOS 没有足够的堆内存来分配互斥锁数据结构。第 3 章提供了有关堆内存管理的更多信息。
非 NULL 返回值表示互斥锁已成功创建。返回值应存储为所创建互斥锁的句柄。
Example 8.1 使用信号量机制重写 vPrintString() 函数
此示例创建了名为 prvNewPrintString() 的新版本的 vPrintString(),然后从多个任务调用新函数。prvNewPrintString() 在功能上与 vPrintString() 相同,但使用互斥锁而不是锁定调度程序来控制对标准输出的访问。prvNewPrintString() 的实现如清单 8.11 所示。
static void prvNewPrintString( const char *pcString )
{
/* The mutex is created before the scheduler is started, so already exists
by the time this task executes.
Attempt to take the mutex, blocking indefinitely to wait for the mutex
if it is not available straight away. The call to xSemaphoreTake() will
only return when the mutex has been successfully obtained, so there is
no need to check the function return value. If any other delay period
was used then the code must check that xSemaphoreTake() returns pdTRUE
before accessing the shared resource (which in this case is standard
out). As noted earlier in this book, indefinite time outs are not
recommended for production code. */
xSemaphoreTake( xMutex, portMAX_DELAY );
{
/* The following line will only execute once the mutex has been
successfully obtained. Standard out can be accessed freely now as
only one task can have the mutex at any one time. */
printf( "%s", pcString );
fflush( stdout );
/* The mutex MUST be given back! */
}
xSemaphoreGive( xMutex );
}
prvNewPrintString() 被 prvPrintTask() 实现的任务的两个实例重复调用。每次调用之间使用随机延迟时间。任务参数用于将唯一的字符串传递给任务的每个实例。prvPrintTask() 的实现如清单 8.12 所示。
static void prvPrintTask( void *pvParameters )
{
char *pcStringToPrint;
const TickType_t xMaxBlockTimeTicks = 0x20;
/* Two instances of this task are created. The string printed by the task
is passed into the task using the task's parameter. The parameter is
cast to the required type. */
pcStringToPrint = ( char * ) pvParameters;
for( ;; )
{
/* Print out the string using the newly defined function. */
prvNewPrintString( pcStringToPrint );
/* Wait a pseudo random time. Note that rand() is not necessarily
reentrant, but in this case it does not really matter as the code
does not care what value is returned. In a more secure application
a version of rand() that is known to be reentrant should be used -
or calls to rand() should be protected using a critical section. */
vTaskDelay( ( rand() % xMaxBlockTimeTicks ) );
}
}
//Listing 8.12 The implementation of prvPrintTask() for Example 8.1通常,main() 只是创建互斥锁、创建任务,然后启动调度程序。实现如清单 8.13 所示。
prvPrintTask() 的两个实例以不同的优先级创建,因此优先级较低的任务有时会被优先级较高的任务抢占。由于互斥锁用于确保每个任务都能互斥地访问终端,因此即使发生抢占,显示的字符串也将是正确的,并且不会受到任何损坏。可以通过减少任务在阻塞状态下所花费的最大时间来增加抢占的频率,该时间由 xMaxBlockTimeTicks 常数设置。
注意例子8.1使用FreeRTOS与windows接口细节:
-调用 printf()函数产生windows系统调用。windows系统调用不受FreeRTOS管理,可能引入不稳定因素。
-windows系统调用的方式本身就不会输出错乱的字符,即使没有使用FreeRTOS的互斥量。
int main( void )
{
/* Before a semaphore is used it must be explicitly created. In this
example a mutex type semaphore is created. */
xMutex = xSemaphoreCreateMutex();
/* Check the semaphore was created successfully before creating the
tasks. */
if( xMutex != NULL )
{
/* Create two instances of the tasks that write to stdout. The string
they write is passed in to the task as the task's parameter. The
tasks are created at different priorities so some pre-emption will
occur. */
xTaskCreate( prvPrintTask, "Print1", 1000,
"Task 1 ***************************************\r\n",
1, NULL );
xTaskCreate( prvPrintTask, "Print2", 1000,
"Task 2 ---------------------------------------\r\n",
2, NULL );
/* Start the scheduler so the created tasks start executing. */
vTaskStartScheduler();
}
/* If all is well then main() will never reach here as the scheduler will
now be running the tasks. If main() does reach here then it is likely
that there was insufficient heap memory available for the idle task to
be created. Chapter 3 provides more information on heap memory
management. */
for( ;; );
}
Listing 8.13 The implementation of main() for Example 8.1
The output produced when Example 8.1 is executed is shown in Figure 8.2. A possible execution sequence is
described in Figure 8.3.
Figure 8.2 shows that, as expected, there is no corruption in the strings that are displayed on the terminal. The
random ordering is a result of the random delay periods used by the tasks.
Figure 8.3 A possible sequence of execution for Example 8.1(图略)8.3.2 优先级反转
图 8.3 演示了使用互斥锁提供互斥的一个潜在缺陷。图示的执行顺序显示,优先级较高的任务 2 必须等待优先级较低的任务 1 放弃对互斥锁的控制。优先级较高的任务以这种方式被优先级较低的任务延迟称为“优先级反转”。如果在高优先级任务等待信号量时中优先级任务开始执行,这种不良行为将进一步加剧 - 结果是高优先级任务等待低优先级任务 - 而低优先级任务甚至无法执行。这通常被称为无限制优先级反转,因为中优先级任务可以无限期地阻止低优先级和高优先级任务。这种最坏情况如图 8.4 所示。
Figure 8.4 A worst case priority inversion scenario (图略)
优先级反转可能是一个严重的问题,但在小型嵌入式系统中,通常可以在系统设计时通过考虑如何访问资源来避免它。
8.3.3 优先级继承
FreeRTOS 互斥锁和二进制信号量非常相似 - 不同之处在于互斥锁包含基本的“优先级继承”机制,而二进制信号量则不包含。优先级继承是一种将优先级反转的负面影响降至最低的方案。它不会“修复”优先级反转,而只是通过确保反转始终受时间限制来减轻其影响。但是,优先级继承使系统时序分析变得复杂,因此依靠它来实现正确的系统操作并不是一个好的做法。
优先级继承的工作原理是将互斥锁持有者的优先级暂时提升为试图获取相同互斥锁的最高优先级任务的优先级。持有互斥锁的低优先级任务“继承”等待互斥锁的任务的优先级。图 8.5 演示了这一点。互斥锁持有者在归还互斥锁时,其优先级会自动重置为其原始值。
Figure 8.5 Priority inheritance minimizing the effect of priority inversion(图略)
正如刚才所见,优先级继承功能会影响使用互斥锁的任务的优先级。因此,不得在中断服务例程中使用互斥锁。
FreeRTOS 实现了一种基本的优先级继承机制,该机制的设计充分考虑了空间和执行周期的优化。完整的优先级继承机制需要更多的数据和处理器周期来确定随时继承的优先级,尤其是当一个任务同时持有多个互斥锁时。
需要牢记优先级继承机制的具体行为:
如果任务在未先释放其已持有的互斥锁的情况下获取互斥锁,则其继承优先级可以进一步提高。
任务将保持其最高继承优先级,直到它释放其持有的所有互斥锁。这与互斥锁的释放顺序无关。
如果持有多个互斥锁,则无论任务是否等待任何持有的互斥锁完成等待(超时),任务都将保持最高继承优先级。
8.3.4 死锁 (or Deadly Embrace)
“死锁”是使用互斥锁进行互斥的另一个潜在陷阱。死锁有时也被称为更戏剧性的名字“致命拥抱”。
当两个任务因都在等待对方持有的资源而无法继续时,就会发生死锁。考虑以下场景,其中任务 A 和任务 B 都需要获取互斥锁 X 和互斥锁 Y 才能执行操作:
1. 任务A开始运行,并成功获取互斥锁X;
2. 任务B把任务A抢占了;
3. 任务B先成功获取互斥锁Y,接着试图获取互斥锁X,但是互斥锁X已经被任务A占用,所以任务B无法成功获取互斥锁X。任务 B 选择进入阻塞状态,等待互斥锁 X 被释放。
4. 任务A继续运行,且试图获取互斥锁Y,但互斥锁Y被任务B占用,所以获取失败。任务 A 选择进入阻塞状态,等待互斥锁 Y 被释放。
狗血的剧情描述:此时,任务 A 正在等待任务 B 持有的互斥锁Y,而任务 B 也在等待任务 A 持有的互斥锁X。由于两个任务都无法继续,因此发生了死锁。
与优先级反转一样,避免死锁的最佳方法是在设计方案时逻辑规避。特别是,正如本书前面所述,任务无限期地(没有超时)等待获取互斥锁通常是一种不好的做法。相反,使用比预计等待互斥锁的最大时间稍长的超时时间——那么无法在该时间内获取互斥锁将是设计错误的征兆,这可能是死锁。
实际项目中,死锁在小型嵌入式系统中并不是一个大问题,因为系统设计人员非常了解整个应用项目程序,可以完全规避掉死锁。
8.3.5 递归互斥锁
任务也可能与自身发生死锁。如果任务尝试多次获取同一个互斥锁,而没有先返回该互斥锁,就会发生这种情况。请考虑以下场景:
1. 任务A成功获取互斥锁;
2. 拥有互斥锁后,任务调用一个库函数;
3. 这个库函数内部实现操作会再次试图获取同一个互斥锁,并且进入阻塞状态等待互斥锁。
这种狗血的剧情就是:同一个任务去二次获取已经到手的互斥锁,而进入阻塞状态。死锁已然发生。
可以使用递归互斥锁代替标准互斥锁来避免这种死锁。 递归互斥锁可以被同一任务多次“获取”,并且只有在对每个先前的“获取”递归互斥锁的调用执行了一次“给予”递归互斥锁的调用后,才会返回。
标准互斥锁和递归互斥锁的创建和使用方式类似:
-使用 xSemaphoreCreateMutex() 创建标准互斥锁。使用xSemaphoreCreateRecursiveMutex() 创建递归互斥锁。这两个 API 函数具有相同的原型。
-使用 xSemaphoreTake() 可以“获取”标准互斥锁。使用xSemaphoreTakeRecursive() 可以“获取”递归互斥锁。这两个 API 函数具有相同的原型。
-使用 xSemaphoreGive() 可以“提供”标准互斥锁。使用xSemaphoreGiveRecursive() 可以“提供”递归互斥锁。这两个 API 函数具有相同的原型。
8.3.6 互斥锁和任务调度
如果两个优先级不同的任务使用同一个互斥锁,那么 FreeRTOS 调度策略会明确任务的执行顺序;能够运行的最高优先级任务将被选为进入运行状态的任务。例如,如果高优先级任务处于阻塞状态以等待低优先级任务持有的互斥锁,那么一旦低优先级任务返回互斥锁,高优先级任务就会抢占低优先级任务。然后高优先级任务将成为互斥锁持有者。图 8.5 中已经看到了这种情况。
但是,当任务具有相同的优先级时,通常会对任务的执行顺序做出错误的假设。如果任务 1 和任务 2 具有相同的优先级,并且任务 1 处于阻塞状态以等待任务 2 持有的互斥锁,那么当任务 2“给予”互斥锁时,任务 1 将不会抢占任务 2。相反,任务 2 将保持运行状态,而任务 1 将简单地从阻塞状态移动到就绪状态。图 8.6 显示了这种情况,其中垂直线标记发生滴答中断的时间。
Figure 8.6 A possible sequence of execution when tasks that have the same priority use the same mutex
在图 8.6 所示的场景中,FreeRTOS 调度程序不会在互斥锁可用时立即将任务 1 设为运行状态任务,因为:
-任务 1 和任务 2 具有相同的优先级,因此除非任务 2 进入阻塞状态,否则直到下一个滴答中断才会切换到任务 1(假设 FreeRTOSConfig.h 中的 configUSE_TIME_SLICING 设置为 1)。
-如果某个任务在紧密循环中使用互斥锁,并且每次任务“gave”互斥锁时都会发生上下文切换,则该任务只会在短时间内保持运行状态。如果两个或多个任务在紧密循环中使用相同的互斥锁,则在任务之间快速切换会浪费处理时间。
如果多个任务在紧密循环中使用互斥锁,并且使用互斥锁的任务具有相同的优先级,则必须小心确保这些任务获得大致相等的处理时间。图 8.7 演示了这些任务可能未获得相等处理时间的原因,该图显示了如果以相同优先级创建清单 8.15 中所示的两个任务实例时可能发生的执行序列。
/* The implementation of a task that uses a mutex in a tight loop. The task
creates a text string in a local buffer, then writes the string to a display.
Access to the display is protected by a mutex. */
void vATask( void *pvParameter )
{
extern SemaphoreHandle_t xMutex;
char cTextBuffer[ 128 ];
for( ;; )
{
/* Generate the text string – this is a fast operation. */
vGenerateTextInALocalBuffer( cTextBuffer );
/* Obtain the mutex that is protecting access to the display. */
xSemaphoreTake( xMutex, portMAX_DELAY );
/* Write the generated text to the display–this is a slow operation. */
vCopyTextToFrameBuffer( cTextBuffer );
/* The text has been written to the display, so return the mutex. */
xSemaphoreGive( xMutex );
}
}
//Listing 8.15 A task that uses a mutex in a tight loop清单 8.15 中的注释指出,创建字符串是一个快速操作,而更新显示是一个缓慢操作。因此,由于在更新显示时会持有互斥锁,因此任务将在其运行的大部分时间内持有互斥锁。
In Figure 8.7, the vertical lines mark the times at which a tick interrupt occurs.
Figure 8.7 A sequence of execution that could occur if two instances of the task shown by Listing 8.15 are created
at the same priority
图 8.7 中的步骤 7 显示任务 1 重新进入阻塞状态 - 这发生在 xSemaphoreTake() API 函数内部。
图 8.7 说明,任务 1 将被阻止获取互斥锁,直到时间片的开始与任务 2 不是互斥锁持有者的短暂时间段之一相重合为止。
通过在调用 xSemaphoreGive() 后添加对 taskYIELD() 的调用,可以避免图 8.7 中所示的情况。清单 8.16 演示了这一点,其中,如果任务持有互斥锁时滴答计数发生变化,则会调用 taskYIELD()。
void vFunction( void *pvParameter )
{
extern SemaphoreHandle_t xMutex;
char cTextBuffer[ 128 ];
TickType_t xTimeAtWhichMutexWasTaken;
for( ;; )
{
/* Generate the text string – this is a fast operation. */
vGenerateTextInALocalBuffer( cTextBuffer );
/* Obtain the mutex that is protecting access to the display. */
xSemaphoreTake( xMutex, portMAX_DELAY );
/* Record the time at which the mutex was taken. */
xTimeAtWhichMutexWasTaken = xTaskGetTickCount();
/* Write the generated text to the display–this is a slow operation. */
vCopyTextToFrameBuffer( cTextBuffer );
/* The text has been written to the display, so return the mutex. */
xSemaphoreGive( xMutex );
/* If taskYIELD() was called on each iteration then this task would
only ever remain in the Running state for a short period of time,
and processing time would be wasted by rapidly switching between
tasks. Therefore, only call taskYIELD() if the tick count changed
while the mutex was held. */
if( xTaskGetTickCount() != xTimeAtWhichMutexWasTaken )
{
taskYIELD();
}
}
}
//Listing 8.16 Ensuring tasks that use a mutex in a loop receive a more equal amount of processing time, while also ensuring processing time is not wasted by switching between tasks too rapidly8.4 Gatekeeper Tasks
守门人任务提供了一种实现互斥的简洁方法,并且不存在优先级反转或死锁的风险。
守门人任务是拥有资源唯一所有权的任务。只有守门人任务才被允许直接访问资源——任何其他需要访问资源的任务只能通过使用守门人服务来间接访问。
二、内核代码解析
先介绍了创建任务,在介绍了任务切换细节PendSV,紧密围绕StackPointer/R13栈寄存器怎么在任务间切换;为任务创建栈。
// FreeRTOS Kernel V10.5.1 代码示例
1. 创建任务
BaseType_t xTaskCreate( TaskFunction_t pxTaskCode, //任务函数
const char * const pcName, //任务字符串名字
const configSTACK_DEPTH_TYPE usStackDepth, //栈深度
void * const pvParameters,
UBaseType_t uxPriority, //优先级
TaskHandle_t * const pxCreatedTask ) //TCB句柄指针
{
TCB_t * pxNewTCB;
BaseType_t xReturn;
/* 如果栈向下生长,先分配栈空间stack再分配TCB空间;
** 如果栈向上生长先分配TCB空间,再分配栈空间;
** 避免栈空间长进TCB空间里去了。
** Cortex-M3 使用的是“向下生长的满栈”模型。
*/
// 先分配 Stack 的空间;这里 portSTACK_GROWTH < 0 的情况;
StackType_t * pxStack;
pxStack = pvPortMallocStack( ( ( ( size_t ) usStackDepth ) * sizeof( StackType_t ) ) );
// 再分配 TCB 空间;
pxNewTCB = ( TCB_t * ) pvPortMalloc( sizeof( TCB_t ) );
//给 TCB 空间初始化为0;
memset( ( void * ) pxNewTCB, 0x00, sizeof( TCB_t ) );
// 将Stack空间地址赋值给TCB->stack域
pxNewTCB->pxStack = pxStack;
//在TCB里标记Stack和TCB的内存分配方式是动态分配的;
pxNewTCB->ucStaticallyAllocated = tskDYNAMICALLY_ALLOCATED_STACK_AND_TCB;
//初始化新任务,怎么初始化的?在下面的函数中有介绍
prvInitialiseNewTask( pxTaskCode, pcName, ( uint32_t ) usStackDepth, pvParameters, uxPriority, pxCreatedTask, pxNewTCB, NULL );
//将新任务添加进任务就绪列表,后续也有介绍
prvAddNewTaskToReadyList( pxNewTCB );
xReturn = pdPASS;
return xReturn;
}
static void prvInitialiseNewTask( TaskFunction_t pxTaskCode, //任务函数,传入PC(R15)
const char * const pcName, //任务字符串名字
const uint32_t ulStackDepth, //栈深度
void * const pvParameters, //函数参数传入R0
UBaseType_t uxPriority, //优先级
TaskHandle_t * const pxCreatedTask, //TCB句柄指针
TCB_t * pxNewTCB, //分配的TCB句柄指针
const MemoryRegion_t * const xRegions ) //针对MPU的,可忽略
{
StackType_t * pxTopOfStack;
UBaseType_t x;
// 栈向下生长的情况 portSTACK_GROWTH < 0 ;
pxTopOfStack = &( pxNewTCB->pxStack[ ulStackDepth - ( uint32_t ) 1 ] );
pxTopOfStack = ( StackType_t * ) ( ( ( portPOINTER_SIZE_TYPE ) pxTopOfStack ) & ( ~( ( portPOINTER_SIZE_TYPE ) portBYTE_ALIGNMENT_MASK ) ) );
//赋值TCB的优先级
pxNewTCB->uxPriority = uxPriority;
//若配置了使用互斥信号量 configUSE_MUTEXES == 1
pxNewTCB->uxBasePriority = uxPriority;
vListInitialiseItem( &( pxNewTCB->xStateListItem ) );
vListInitialiseItem( &( pxNewTCB->xEventListItem ) );
/* Set the pxNewTCB as a link back from the ListItem_t. This is so we can get
* back to the containing TCB from a generic item in a list. */
listSET_LIST_ITEM_OWNER( &( pxNewTCB->xStateListItem ), pxNewTCB );
/* Event lists are always in priority order. */
listSET_LIST_ITEM_VALUE( &( pxNewTCB->xEventListItem ), ( TickType_t ) configMAX_PRIORITIES - ( TickType_t ) uxPriority );
listSET_LIST_ITEM_OWNER( &( pxNewTCB->xEventListItem ), pxNewTCB );
// 初始化任务堆栈,更新 pxTopOfStack, pxTaskCode, pvParameters 芯片架构相关
pxNewTCB->pxTopOfStack = pxPortInitialiseStack( pxTopOfStack, pxTaskCode, pvParameters );
*pxCreatedTask = ( TaskHandle_t ) pxNewTCB;
}
StackType_t * pxPortInitialiseStack( StackType_t * pxTopOfStack,
TaskFunction_t pxCode,
void * pvParameters )
{
pxTopOfStack--;
*pxTopOfStack = portINITIAL_XPSR; /* xPSR */
pxTopOfStack--;
*pxTopOfStack = ( ( StackType_t ) pxCode ) & portSTART_ADDRESS_MASK; /* PC */
pxTopOfStack--;
*pxTopOfStack = ( StackType_t ) prvTaskExitError; /* LR */
pxTopOfStack -= 5; /* R12, R3, R2 and R1. */
*pxTopOfStack = ( StackType_t ) pvParameters; /* R0保存函数入参 */
pxTopOfStack -= 8; /* R11, R10, R9, R8, R7, R6, R5 and R4. */
return pxTopOfStack;
}
2. 任务切换 与 任务调度
2.1 任务切换
若要深入思考,需关注 stack pointer (R13)的变化衔接,还有PC(R15)和LR(R14)在出PendSV中断时,硬件依据最新的SP进行恢复。
/*
** 当CM3开始响应一个中断时,会在它小小的体内奔涌起三股暗流:
** 入栈: 把8个寄存器的值压入栈
** 取向量:从向量表中找出对应的服务程序入口地址
** 选择堆栈指针MSP/PSP,更新堆栈指针SP,更新连接寄存器LR,更新程序计数器PC
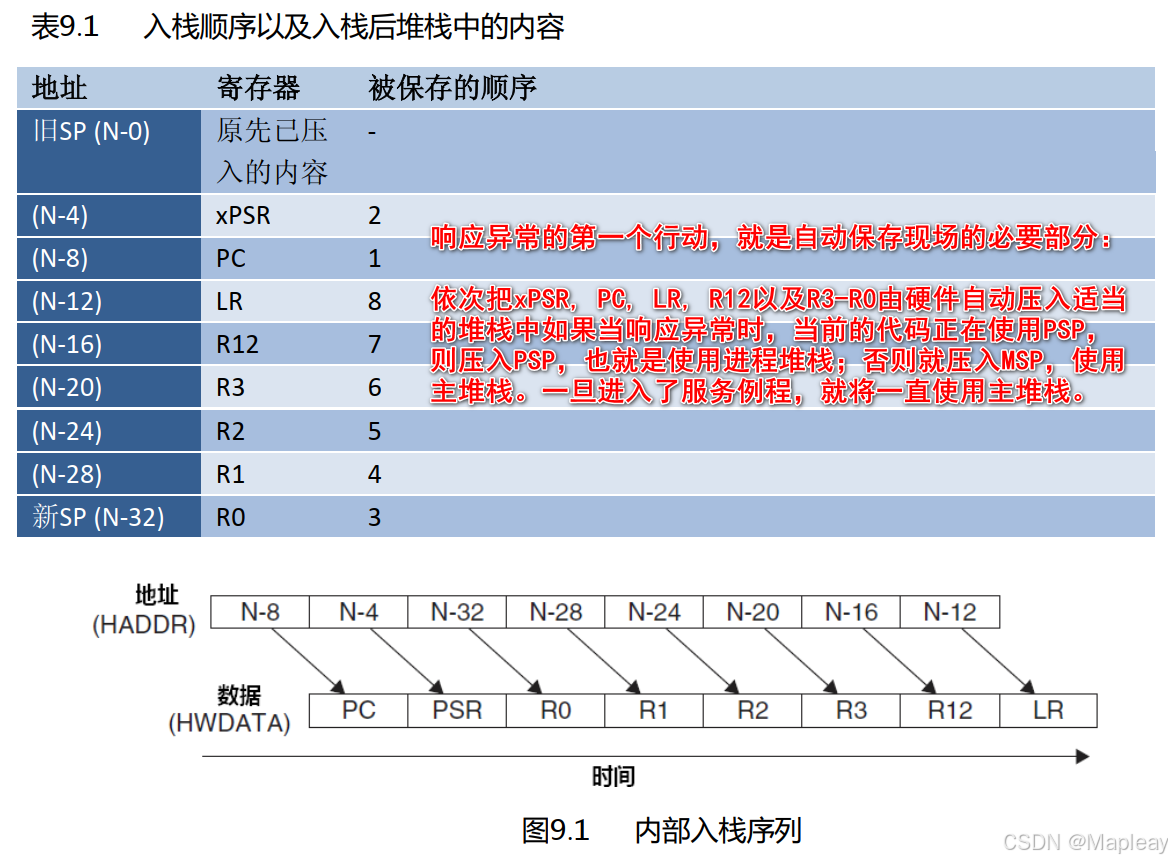
** 初始化任务是把栈区制作成好像从真正的中断PendSV任务切换过来的一样。
** 响应异常的第一个行动,就是自动保存现场的必要部分:依次把xPSR, PC, LR, R12以及R3-R0由硬
** 件自动压入适当的堆栈中:如果当响应异常时,当前的代码正在使用PSP,则压入PSP,也就是使用
** 进程堆栈;否则就压入MSP,使用主堆栈。** PC(R15) LR(14) 由硬件在出PendSV中断时,硬件自动恢复,依据新的SP(R13).
*/
/* xPortPendSVHandler 汇编函数中,从始至终使用的是中断Main_SP,
** 其中 { r3, r14 } 压栈出栈也是 Main_SP ,而r3保存了 pxCurrentTCB ,
** 且中途经过 vTaskSwitchContext 更新了 pxCurrentTCB 的值,所以
** 出栈 r3 获取 新的 pxCurrentTCB, 并继续出栈其他寄存器 即可。
** 其实,Main_SP也是一个变量空间,可以存储 pxCurrentTCB 。
** PC(R15) LR(14) 由硬件在出PendSV中断时,硬件自动恢复,依据新的SP(R13).
*/
__asm void xPortPendSVHandler( void )
{
extern uxCriticalNesting;
extern pxCurrentTCB;
extern vTaskSwitchContext;
/* *INDENT-OFF* */
PRESERVE8
mrs r0, psp ;把 process_SP 的值存入R0;
isb
ldr r3, =pxCurrentTCB ;获取 pxCurrentTCB 的位置
ldr r2, [ r3 ] ;把 pxCurrentTCB 存入 R2
stmdb r0 !, { r4 - r11 } ;保存剩余的寄存器
str r0, [ r2 ] ;保存psp到该任务TCB->sp指针里,即保存旧任务的sp。
stmdb sp !, { r3, r14 } ;压栈操作(MSP),保存全局变量pxCurrentTCB到R3里。
mov r0, #configMAX_SYSCALL_INTERRUPT_PRIORITY
msr basepri, r0 ;屏蔽中断
dsb ;数据同步隔离,清洗三级流水线的意思,硬件特性,不用管
isb ;指令同步隔离,清洗三级流水线的意思,硬件特性,不用管
bl vTaskSwitchContext ;更新最高优先级就绪任务的TCB,pxCurrentTCB;
mov r0, #0
msr basepri, r0 ;写0,使能中断
ldmia sp !, { r3, r14 } ;出栈操作(MSP),取出全局变量pxCurrentTCB从R3里。
;r3使用的是MSP,在PendSV中的MSP,进入 vTaskSwitchContext 函数之前有压栈,
;这里出栈后同样保存的是 pxCurrentTCB 的位置,但是其中的值已经被 vTaskSwitchContext 函数刷新过了。
ldr r1, [ r3 ]
ldr r0, [ r1 ] /* The first item in pxCurrentTCB is the task top of stack. */
ldmia r0 !, { r4 - r11 } /* Pop the registers and the critical nesting count. */
msr psp, r0 ;恢复 pxCurrentTCB 的栈,即恢复新任务的sp。
isb
bx r14
nop
/* *INDENT-ON* */
};********************************************************************************************************
; uC/OS-II
; HANDLE PendSV EXCEPTION
; void OS_CPU_PendSVHandler(void)
;
; Note(s) : 1) PendSV is used to cause a context switch. This is a recommended method for performing
; context switches with Cortex-M. This is because the Cortex-M auto-saves half of the
; processor context on any exception, and restores same on return from exception. So only
; saving of R4-R11 & R14 is required and fixing up the stack pointers. Using the PendSV exception
; this way means that context saving and restoring is identical whether it is initiated from
; a thread or occurs due to an interrupt or exception.
;
; 2) Pseudo-code is:
; a) Get the process SP
; b) Save remaining regs r4-r11 & r14 on process stack;
; c) Save the process SP in its TCB, OSTCBCur->OSTCBStkPtr = SP;
; d) Call OSTaskSwHook();
; e) Get current high priority, OSPrioCur = OSPrioHighRdy;
; f) Get current ready thread TCB, OSTCBCur = OSTCBHighRdy;
; g) Get new process SP from TCB, SP = OSTCBHighRdy->OSTCBStkPtr;
; h) Restore R4-R11 and R14 from new process stack;
; i) Perform exception return which will restore remaining context.
;
; 3) On entry into PendSV handler:
; a) The following have been saved on the process stack (by processor):
; xPSR, PC, LR, R12, R0-R3
; b) Processor mode is switched to Handler mode (from Thread mode)
; c) Stack is Main stack (switched from Process stack)
; d) OSTCBCur points to the OS_TCB of the task to suspend
; OSTCBHighRdy points to the OS_TCB of the task to resume
;
; 4) Since PendSV is set to lowest priority in the system (by OSStartHighRdy() above), we
; know that it will only be run when no other exception or interrupt is active, and
; therefore safe to assume that context being switched out was using the process stack (PSP).
;
; 5) Increasing priority using a write to BASEPRI does not take effect immediately.
; (a) IMPLICATION This erratum means that the instruction after an MSR to boost BASEPRI
; might incorrectly be preempted by an insufficient high priority exception.
;
; (b) WORKAROUND The MSR to boost BASEPRI can be replaced by the following code sequence:
;
; CPSID i
; MSR to BASEPRI
; DSB
; ISB
; CPSIE i
;********************************************************************************************************
/*
** 问题1,OS_CPU_PendSVHandler中的OSPrioCur、OSPrioHighRdy和OSTCBHighRdy是不是就绪的准备切换的新任务的?
** 看代码调用的时间顺序:结论是进入 OS_CPU_PendSVHandler 之前,OSPrioCur、OSPrioHighRdy和OSTCBHighRdy是即将切换的最新值。
** OS_Sched() -> OS_SchedNew() -> OS_TASK_SW() -> OSCtxSw(汇编触发PendSV中断)OS_CPU_PendSVHandler
**
** 问题2,是否需要在切换任务时,保存旧任务的SP,并更新新任务的SP?
** 答案:需要。而且在stm32的PendSV中断里,需要手动编写汇编代码,因为中断时,SP不会硬件自动入栈。
** 当CM3开始响应一个中断时,会在它小小的体内奔涌起三股暗流:
** 入栈: 把8个寄存器的值压入栈
** 取向量:从向量表中找出对应的服务程序入口地址
** 选择堆栈指针MSP/PSP,更新堆栈指针SP,更新连接寄存器LR,更新程序计数器PC
** 问题3,任务切换时需要切换SP,切换StackPointer就是任务切换时对SP的更新,仅此足矣。
** 问题4,LR/PC寄存器在任务切换时需要更新吗?当然需要更新。
** 只不过在stm32f103里是硬件依据stackPointer,进行自动push-pop操作,不再需要代码.
** 由于硬件依据StackPointer寄存器恢复栈区,所以千万不能把StackPointer给搞错了。
*/
OS_CPU_PendSVHandler
CPSID I ; Cortex-M7 errata notice. See Note #5
MOV32 R2, OS_KA_BASEPRI_Boundary ; Set BASEPRI priority level required for exception preemption
LDR R1, [R2]
MSR BASEPRI, R1
DSB
ISB
CPSIE I
MRS R0, PSP ; PSP is process stack pointer
STMFD R0!, {R4-R11, R14} ; Save remaining regs r4-11, R14 on process stack
LDR R5, =OSTCBCur ; OSTCBCur->OSTCBStkPtr = SP;
LDR R1, [R5]
STR R0, [R1] ; R0 is SP of process being switched out
; At this point, entire context of process has been saved
MOV R4, LR ; Save LR exc_return value
BL OSTaskSwHook ; Call OSTaskSwHook() for FPU Push & Pop
LDR R0, =OSPrioCur ; OSPrioCur = OSPrioHighRdy;
LDR R1, =OSPrioHighRdy
LDRB R2, [R1]
STRB R2, [R0]
LDR R1, =OSTCBHighRdy ; OSTCBCur = OSTCBHighRdy;
LDR R2, [R1]
STR R2, [R5]
ORR LR, R4, #0x04 ; Ensure exception return uses process stack
LDR R0, [R2] ; R0 is new process SP; SP = OSTCBHighRdy->OSTCBStkPtr;
LDMFD R0!, {R4-R11, R14} ; Restore r4-11, R14 from new process stack
MSR PSP, R0 ; Load PSP with new process SP
MOV32 R2, #0 ; Restore BASEPRI priority level to 0
CPSID I
MSR BASEPRI, R2
DSB
ISB
CPSIE I
BX LR ; Exception return will restore remaining context
ALIGN ; Removes warning[A1581W]: added <no_padbytes> of padding at <address>
END2.2 任务调度
/* issue5: 任务调度器,系统滴答中断服务函数,任务切换,时间片轮转 */
/*
** 任务调度:
** 调度策略:基于优先级可抢占+同优先级时间片轮转;
** 调度算法:
** 可抢占:软件判空链表(软件实现) or 前置导零指令(硬件实现)
** 时间片轮转:使用链表的标记变量++,轮流指向链表里的节点
** 任务调度器是否支持上锁:支持
** 任务切换:
** 内核时脉滴答服务的实现:基于stm32的systick硬件时钟(CMSIS兼容)
** xPortSysTickHandler 函数;
** 若必要,则触发PendSV中断,执行切换。
** 内核任务切换的实现:在PendSV ISR中执行:xPortPendSVHandler 函数;
*/
/* 从链表里获取下一个节点对应的内核对象,这里是 TCB 任务控制块;
** 这个功能正是实现 time-slicing 时间片轮转的地方,
** The list member pxIndex is used to walk through a list.
** pxIndex++;(C++伪代码描述)实现时间片轮转
** List_t->pxIndex 类似迭代器或鼠标的针头,用于遍历 walk through the list.
** List_t->xListEnd 只作为标记用,貌似无实际使用场景。
*/
#define listGET_OWNER_OF_NEXT_ENTRY( pxTCB, pxList ) \
{ \
List_t * const pxConstList = ( pxList ); \
\
/* Increment the index to the next item and return the item */ \
( pxConstList )->pxIndex = ( pxConstList )->pxIndex->pxNext; /* 换下一个节点执行 */ \
/* ensuring that we don't return the marker used at the end of the list. */ \
if( ( void * ) ( pxConstList )->pxIndex == ( void * ) &( ( pxConstList )->xListEnd ) ) \
{ \
( pxConstList )->pxIndex = ( pxConstList )->pxIndex->pxNext; \
} \
( pxTCB ) = ( pxConstList )->pxIndex->pvOwner; /* 返回新节点的owner对象,即 TCB; */ \
}
vTaskSwitchContext 函数中调用了 taskSELECT_HIGHEST_PRIORITY_TASK(); vTaskSwitchContext 函数被 xPortPendSVHandler 函数调用;
/* issue5: 任务调度器,系统滴答中断服务函数,任务切换,时间片轮转 */
/* 此函数为内核心跳服务函数,更新内核状态,涉及任务切换, */
BaseType_t xTaskIncrementTick( void )
{
TCB_t * pxTCB;
TickType_t xItemValue;
BaseType_t xSwitchRequired = pdFALSE;
// The scheduler is suspended if uxSchedulerSuspended is non-zero.
// uxSchedulerSuspended == 0 ,调度器正常运行;
if( uxSchedulerSuspended == ( UBaseType_t ) pdFALSE )
{
const TickType_t xConstTickCount = xTickCount + ( TickType_t ) 1;
xTickCount = xConstTickCount;
if( xConstTickCount >= xNextTaskUnblockTime )
{
for( ; ; )
{
if( listLIST_IS_EMPTY( pxDelayedTaskList ) != pdFALSE )
{ //pxDelayedTaskList链表为空;
xNextTaskUnblockTime = portMAX_DELAY;
break;
}
else
{ //pxDelayedTaskList链表非空;
pxTCB = listGET_OWNER_OF_HEAD_ENTRY( pxDelayedTaskList );
xItemValue = listGET_LIST_ITEM_VALUE( &( pxTCB->xStateListItem ) );
if( xConstTickCount < xItemValue )
{
xNextTaskUnblockTime = xItemValue;
break;
}
//将任务的状态节点和事件节点移除相应的链表
listREMOVE_ITEM( &( pxTCB->xStateListItem ) );
if( listLIST_ITEM_CONTAINER( &( pxTCB->xEventListItem ) ) != NULL )
{
listREMOVE_ITEM( &( pxTCB->xEventListItem ) );
}
//将阻塞的任务移入就绪列表;
prvAddTaskToReadyList( pxTCB );
}
}
}
#if ( ( configUSE_PREEMPTION == 1 ) && ( configUSE_TIME_SLICING == 1 ) )
{
if( listCURRENT_LIST_LENGTH( &( pxReadyTasksLists[ pxCurrentTCB->uxPriority ] ) ) > ( UBaseType_t ) 1 )
{
xSwitchRequired = pdTRUE;
}
else
{
mtCOVERAGE_TEST_MARKER();
}
}
#endif
}
else // 若 uxSchedulerSuspended != 0 ,调度器被锁;
{
++xPendedTicks;
}
return xSwitchRequired;
}
#define prvAddTaskToReadyList( pxTCB ) \
taskRECORD_READY_PRIORITY( ( pxTCB )->uxPriority ); \
listINSERT_END( &( pxReadyTasksLists[ ( pxTCB )->uxPriority ] ), &( ( pxTCB )->xStateListItem ) ); \
/* A port optimised version is provided. Call the port defined macros. */
#define taskRECORD_READY_PRIORITY( uxPriority ) portRECORD_READY_PRIORITY( ( uxPriority ), uxTopReadyPriority )
/* Store/clear the ready priorities in a bit map. */
#define portRECORD_READY_PRIORITY( uxPriority, uxReadyPriorities ) ( uxReadyPriorities ) |= ( 1UL << ( uxPriority ) )
#define portRESET_READY_PRIORITY( uxPriority, uxReadyPriorities ) ( uxReadyPriorities ) &= ~( 1UL << ( uxPriority ) )
#define listINSERT_END( pxList, pxNewListItem ) \
{ \
ListItem_t * const pxIndex = ( pxList )->pxIndex; \
\
( pxNewListItem )->pxNext = pxIndex; \
( pxNewListItem )->pxPrevious = pxIndex->pxPrevious; \
\
pxIndex->pxPrevious->pxNext = ( pxNewListItem ); \
pxIndex->pxPrevious = ( pxNewListItem ); \
\
( pxNewListItem )->pxContainer = ( pxList ); \
\
( ( pxList )->uxNumberOfItems )++; \
}
/*************************************************************************/
// 软件找寻最高就绪优先级任务的链表;
#define taskSELECT_HIGHEST_PRIORITY_TASK() \
{ \
UBaseType_t uxTopPriority = uxTopReadyPriority; \
\
/* Find the highest priority queue that contains ready tasks. */ \
while( listLIST_IS_EMPTY( &( pxReadyTasksLists[ uxTopPriority ] ) ) ) \
{ \
configASSERT( uxTopPriority ); \
--uxTopPriority; \
} \
\
/* listGET_OWNER_OF_NEXT_ENTRY indexes through the list, so the tasks of \
* the same priority get an equal share of the processor time. */ \
listGET_OWNER_OF_NEXT_ENTRY( pxCurrentTCB, &( pxReadyTasksLists[ uxTopPriority ] ) ); \
uxTopReadyPriority = uxTopPriority; \
} /* taskSELECT_HIGHEST_PRIORITY_TASK */
// 硬件前置导零指令,执行找寻最高就绪优先级的链表;
#define taskSELECT_HIGHEST_PRIORITY_TASK() \
{ \
UBaseType_t uxTopPriority; \
\
/* Find the highest priority list that contains ready tasks. */ \
portGET_HIGHEST_PRIORITY( uxTopPriority, uxTopReadyPriority ); \
configASSERT( listCURRENT_LIST_LENGTH( &( pxReadyTasksLists[ uxTopPriority ] ) ) > 0 ); \
listGET_OWNER_OF_NEXT_ENTRY( pxCurrentTCB, &( pxReadyTasksLists[ uxTopPriority ] ) ); \
} /* taskSELECT_HIGHEST_PRIORITY_TASK() */
// 这就是前置导零汇编指令:
#define portGET_HIGHEST_PRIORITY( uxTopPriority, uxReadyPriorities ) \
uxTopPriority = ( 31UL - ( uint32_t ) __clz( ( uxReadyPriorities ) ) )
/* 从链表里获取下一个节点对应的内核对象,这里是 TCB 任务控制块;
** 这个功能正是实现 time-slicing 时间片轮转的地方,
** The list member pxIndex is used to walk through a list.
** pxIndex++;(C++伪代码描述)实现时间片轮转
*/
#define listGET_OWNER_OF_NEXT_ENTRY( pxTCB, pxList ) \
{ \
List_t * const pxConstList = ( pxList ); \
\
/* Increment the index to the next item and return the item */ \
( pxConstList )->pxIndex = ( pxConstList )->pxIndex->pxNext; /* 换下一个节点执行 */ \
/* ensuring that we don't return the marker used at the end of the list. */ \
if( ( void * ) ( pxConstList )->pxIndex == ( void * ) &( ( pxConstList )->xListEnd ) ) \
{ \
( pxConstList )->pxIndex = ( pxConstList )->pxIndex->pxNext; \
} \
( pxTCB ) = ( pxConstList )->pxIndex->pvOwner; /* 返回新节点的owner对象,即 TCB; */ \
}
/* vTaskSwitchContext 函数中调用了 taskSELECT_HIGHEST_PRIORITY_TASK();
** vTaskSwitchContext 函数被 xPortPendSVHandler 函数调用;
*/
__asm void xPortPendSVHandler( void )
{
extern uxCriticalNesting;
extern pxCurrentTCB;
extern vTaskSwitchContext; /* vTaskSwitchContext 引入 */
/* *INDENT-OFF* */
PRESERVE8
mrs r0, psp ;把 process_SP 的值存入R0;
isb
ldr r3, =pxCurrentTCB ;获取 pxCurrentTCB 的位置
ldr r2, [ r3 ] ;把 pxCurrentTCB 存入 R2
stmdb r0 !, { r4 - r11 } ;保存剩余的寄存器
str r0, [ r2 ] ;保存psp到该任务TCB->sp指针里,即保存旧任务的sp。
stmdb sp !, { r3, r14 } ;压栈操作(MSP),保存全局变量pxCurrentTCB到R3里。
mov r0, #configMAX_SYSCALL_INTERRUPT_PRIORITY
msr basepri, r0 ;屏蔽中断
dsb ;数据同步隔离,清洗三级流水线的意思,硬件特性,不用管
isb ;指令同步隔离,清洗三级流水线的意思,硬件特性,不用管
bl vTaskSwitchContext ;更新最高优先级就绪任务的TCB,pxCurrentTCB;
mov r0, #0
msr basepri, r0 ;写0,使能中断
ldmia sp !, { r3, r14 } ;出栈操作(MSP),取出全局变量pxCurrentTCB从R3里。
;r3使用的是MSP,在PendSV中的MSP,进入 vTaskSwitchContext 函数之前有压栈,
;这里出栈后同样保存的是 pxCurrentTCB 的位置,但是其中的值已经被 vTaskSwitchContext 函数刷新过了。
ldr r1, [ r3 ]
ldr r0, [ r1 ] /* The first item in pxCurrentTCB is the task top of stack. */
ldmia r0 !, { r4 - r11 } /* Pop the registers and the critical nesting count. */
msr psp, r0 ;恢复 pxCurrentTCB 的栈,即恢复新任务的sp。
isb
bx r14
nop
/* *INDENT-ON* */
}
/*-----------------------------------------------------------*/
void xPortSysTickHandler( void ) //FreeRTOS内核的系统时基滴答服务函数;
{
vPortRaiseBASEPRI();
{/* Increment the RTOS tick. */
if( xTaskIncrementTick() != pdFALSE ) //执行滴答服务,刷新系统状态;
{
//如需切换任务,由于任务上下文切换在 PendSV 中执行,所以这里仅触发 PendSV 中断;
portNVIC_INT_CTRL_REG = portNVIC_PENDSVSET_BIT;
}
}
vPortClearBASEPRIFromISR();
}
/*-----------------------------------------------------------*/
void vTaskSwitchContext( void )
{
if( uxSchedulerSuspended != ( UBaseType_t ) pdFALSE )
{
//任务调度器被锁,不允许任务切换;
xYieldPending = pdTRUE;
}
else // 任务调度器没有上锁;
{
xYieldPending = pdFALSE;
/* Check for stack overflow, if configured. */
taskCHECK_FOR_STACK_OVERFLOW();
taskSELECT_HIGHEST_PRIORITY_TASK();
}
}
/*-----------------------------------------------------------*/3. FreeRTOS的链表
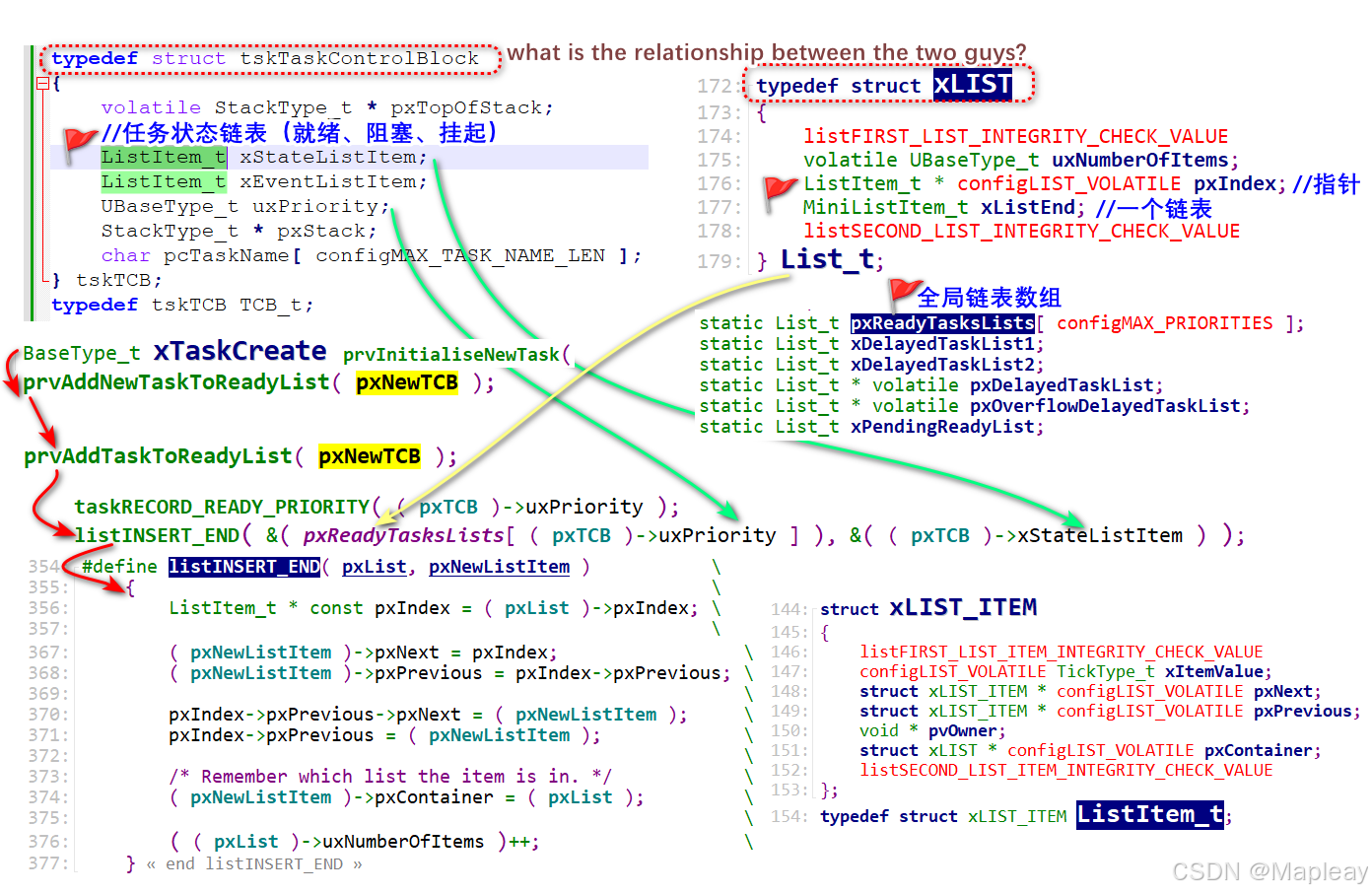
虽说链表很容易理解,但是要彻底弄清 FreeRTOS ,仍需详细分析这部分代码,关联到任务、事件消息。
[todo]
//重要的全局链表;
static List_t pxReadyTasksLists[ configMAX_PRIORITIES ]; /*< Prioritised ready tasks. */
static List_t xDelayedTaskList1; /*< Delayed tasks. */
static List_t xDelayedTaskList2; /*< Delayed tasks (two lists are used - one for delays that have overflowed the current tick count. */
static List_t * volatile pxDelayedTaskList; /*< Points to the delayed task list currently being used. */
static List_t * volatile pxOverflowDelayedTaskList; /*< Points to the delayed task list currently being used to hold tasks that have overflowed the current tick count. */
static List_t xPendingReadyList; /*< Tasks that have been readied while the scheduler was suspended. They will be moved to the ready list when the scheduler is resumed. */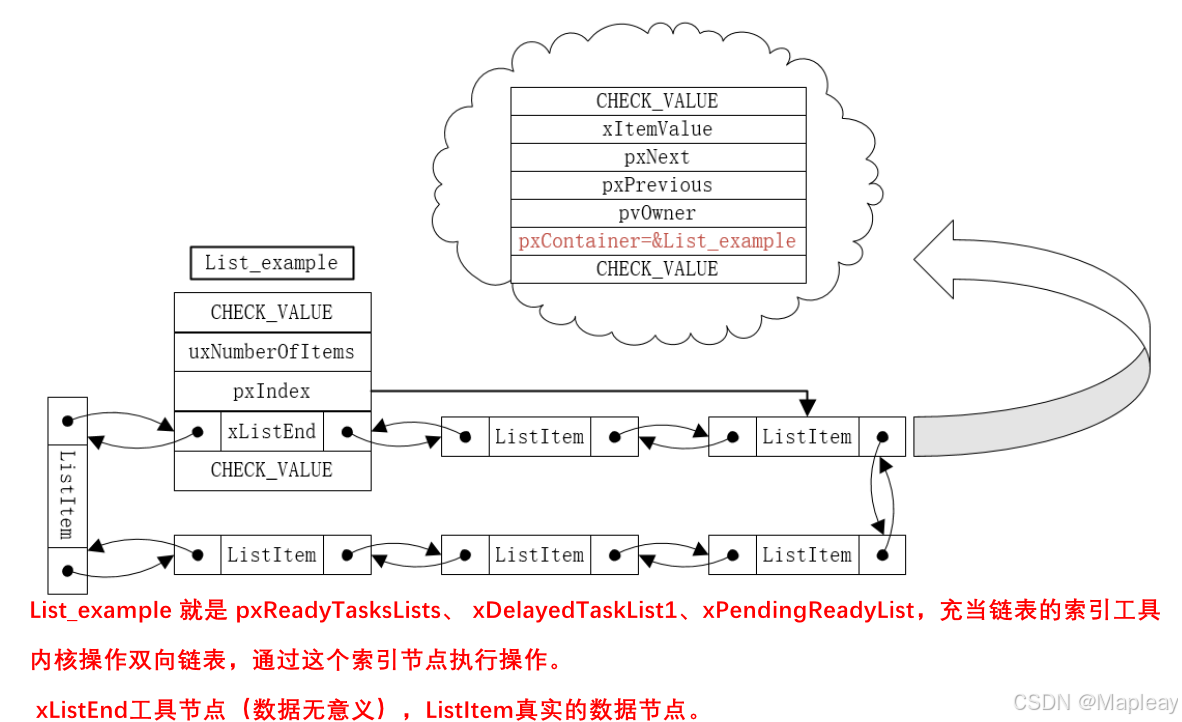
这几个链表挂载点-pxReadyTasksLists、xDelayedTaskList1、xPendingReadyList,是全局变量,是内核管理的索引点(List_t),贯穿着内核对象(TCB_t)的链表节点(ListItem_t)。
内核办公室在管理运作时,依据这几个全局链表索引点(List_t),相当于内核管理的功能的挂载点,遍历其下的 ListItem_t 双向循环链表,更进一步地获取 ListItem_t 对应的 内核对象(比如TCB_t)。也就是说,内核要访问链表上任意节点,都需要通过一个特殊的节点(比如 pxReadyTasksLists、xDelayedTaskList1 等)去间接操作。这种特殊节点的特殊之处:对比结构体定义就知道了,都有节点定义(可能是mini类型的),且它的节点仅仅用于标记,还多了一个指针,用来指向其他实际节点成员,总之这个全局变量相当于一个工具(类似指针/探针/迭代器),是内核管理操作实际链表上所有节点数据的工具节点。
4. 任务间通信(事件消息)
FreeRTOS的任务间通信是消息队列。信号量和邮箱都是基于队列实现的。
/* issues6: 任务间通信:消息队列 */
4.1 重要的全局链表;
static List_t pxReadyTasksLists[ configMAX_PRIORITIES ]; /*< Prioritised ready tasks. */
static List_t xDelayedTaskList1; /*< Delayed tasks. */
static List_t xDelayedTaskList2; /*< Delayed tasks (two lists are used - one for delays that have overflowed the current tick count. */
static List_t * volatile pxDelayedTaskList; /*< Points to the delayed task list currently being used. */
static List_t * volatile pxOverflowDelayedTaskList; /*< Points to the delayed task list currently being used to hold tasks that have overflowed the current tick count. */
static List_t xPendingReadyList; /*< Tasks that have been readied while the scheduler was suspended. They will be moved to the ready list when the scheduler is resumed. */队列的特征参数:
/* For internal use only. */
#define queueSEND_TO_BACK ( ( BaseType_t ) 0 )
#define queueSEND_TO_FRONT ( ( BaseType_t ) 1 )
#define queueOVERWRITE ( ( BaseType_t ) 2 )
/* For internal use only. These definitions *must* match those in queue.c. */
#define queueQUEUE_TYPE_BASE ( ( uint8_t ) 0U )
#define queueQUEUE_TYPE_SET ( ( uint8_t ) 0U )
#define queueQUEUE_TYPE_MUTEX ( ( uint8_t ) 1U )
#define queueQUEUE_TYPE_COUNTING_SEMAPHORE ( ( uint8_t ) 2U )
#define queueQUEUE_TYPE_BINARY_SEMAPHORE ( ( uint8_t ) 3U )
#define queueQUEUE_TYPE_RECURSIVE_MUTEX ( ( uint8_t ) 4U )4.2 特殊函数关系图
4.2.1 xQueueGenericSend 函数:

/*
xTaskDelayUntil 函数
vTaskDelay 函数
vTaskPlaceOnEventList 函数
vTaskPlaceOnUnorderedEventList 函数
vTaskPlaceOnEventListRestricted 函数
ulTaskGenericNotifyTake 函数
xTaskGenericNotifyWait 函数
上面这些函数调用了 prvAddCurrentTaskToDelayedList 函数。
消息相关代码执行流1:
xQueueReceive( QueueHandle_t xQueue, void * const pvBuffer, TickType_t xTicksToWait ) ->调用
vTaskPlaceOnEventList( &( pxQueue->xTasksWaitingToReceive ), xTicksToWait ) ->调用
void prvAddCurrentTaskToDelayedList( xTicksToWait, pdTRUE )
{
//其中,pxDelayedTaskList 是全局非运行状态链表!
vListInsert( pxDelayedTaskList, &( pxCurrentTCB->xStateListItem ) );
}
----------------------------------------------------------------------
----------------------------------------------------------------------
*/
三、项目代码分析
3.1 数据接收:从中断到内核
demo1
//CAN数据从中断到FreeRTOS内核
void CAN1_RX0_IRQHandler(void)
{
HAL_CAN_IRQHandler(&hcan1);
}
void HAL_CAN_IRQHandler(CAN_HandleTypeDef* hcan)
{
/* Check End of transmission flag */
if(__HAL_CAN_GET_IT_SOURCE(hcan, CAN_IT_TME))
{
if((__HAL_CAN_TRANSMIT_STATUS(hcan, CAN_TXMAILBOX_0)) ||
(__HAL_CAN_TRANSMIT_STATUS(hcan, CAN_TXMAILBOX_1)) ||
(__HAL_CAN_TRANSMIT_STATUS(hcan, CAN_TXMAILBOX_2)))
{
/* Call transmit function */
CAN_Transmit_IT(hcan);
}
}
/* Check End of reception flag for FIFO0 */
if((__HAL_CAN_GET_IT_SOURCE(hcan, CAN_IT_FMP0)) &&
(__HAL_CAN_MSG_PENDING(hcan, CAN_FIFO0) != 0))
{
/* Call receive function */
CAN_Receive_IT(hcan, CAN_FIFO0);
}
/* Check End of reception flag for FIFO1 */
if((__HAL_CAN_GET_IT_SOURCE(hcan, CAN_IT_FMP1)) &&
(__HAL_CAN_MSG_PENDING(hcan, CAN_FIFO1) != 0))
{
/* Call receive function 分析1 */
CAN_Receive_IT(hcan, CAN_FIFO1);
}
}
static HAL_StatusTypeDef CAN_Receive_IT(CAN_HandleTypeDef* hcan, uint8_t FIFONumber)
{
/* Get the Id */
hcan->pRxMsg->IDE = (uint8_t)0x04 & hcan->Instance->sFIFOMailBox[FIFONumber].RIR;
if (hcan->pRxMsg->IDE == CAN_ID_STD)
{
hcan->pRxMsg->StdId = (uint32_t)0x000007FF & (hcan->Instance->sFIFOMailBox[FIFONumber].RIR >> 21);
}
else
{
hcan->pRxMsg->ExtId = (uint32_t)0x1FFFFFFF & (hcan->Instance->sFIFOMailBox[FIFONumber].RIR >> 3);
}
hcan->pRxMsg->RTR = (uint8_t)0x02 & hcan->Instance->sFIFOMailBox[FIFONumber].RIR;
/* Get the DLC */
hcan->pRxMsg->DLC = (uint8_t)0x0F & hcan->Instance->sFIFOMailBox[FIFONumber].RDTR;
/* Get the FMI */
hcan->pRxMsg->FMI = (uint8_t)0xFF & (hcan->Instance->sFIFOMailBox[FIFONumber].RDTR >> 8);
/* Get the data field */
hcan->pRxMsg->Data[0] = (uint8_t)0xFF & hcan->Instance->sFIFOMailBox[FIFONumber].RDLR;
hcan->pRxMsg->Data[1] = (uint8_t)0xFF & (hcan->Instance->sFIFOMailBox[FIFONumber].RDLR >> 8);
hcan->pRxMsg->Data[2] = (uint8_t)0xFF & (hcan->Instance->sFIFOMailBox[FIFONumber].RDLR >> 16);
hcan->pRxMsg->Data[3] = (uint8_t)0xFF & (hcan->Instance->sFIFOMailBox[FIFONumber].RDLR >> 24);
hcan->pRxMsg->Data[4] = (uint8_t)0xFF & hcan->Instance->sFIFOMailBox[FIFONumber].RDHR;
hcan->pRxMsg->Data[5] = (uint8_t)0xFF & (hcan->Instance->sFIFOMailBox[FIFONumber].RDHR >> 8);
hcan->pRxMsg->Data[6] = (uint8_t)0xFF & (hcan->Instance->sFIFOMailBox[FIFONumber].RDHR >> 16);
hcan->pRxMsg->Data[7] = (uint8_t)0xFF & (hcan->Instance->sFIFOMailBox[FIFONumber].RDHR >> 24);
/* Release the FIFO */
/* Release FIFO0 */
if (FIFONumber == CAN_FIFO0)
{
__HAL_CAN_FIFO_RELEASE(hcan, CAN_FIFO0);
/* Disable FIFO 0 message pending Interrupt */
__HAL_CAN_DISABLE_IT(hcan, CAN_IT_FMP0);
}
/* Release FIFO1 */
else /* FIFONumber == CAN_FIFO1 */
{
__HAL_CAN_FIFO_RELEASE(hcan, CAN_FIFO1);
/* Disable FIFO 1 message pending Interrupt */
__HAL_CAN_DISABLE_IT(hcan, CAN_IT_FMP1);
}
if(hcan->State == HAL_CAN_STATE_BUSY_RX)
{
/* Disable interrupts: */
/* - Disable Error warning Interrupt */
/* - Disable Error passive Interrupt */
/* - Disable Bus-off Interrupt */
/* - Disable Last error code Interrupt */
/* - Disable Error Interrupt */
__HAL_CAN_DISABLE_IT(hcan, CAN_IT_EWG |
CAN_IT_EPV |
CAN_IT_BOF |
CAN_IT_LEC |
CAN_IT_ERR );
}
if(hcan->State == HAL_CAN_STATE_BUSY_TX_RX)
{
/* Disable CAN state */
hcan->State = HAL_CAN_STATE_BUSY_TX;
}
else
{
/* Change CAN state */
hcan->State = HAL_CAN_STATE_READY;
}
/* Receive complete callback 分析1 */
HAL_CAN_RxCpltCallback(hcan);
/* Return function status */
return HAL_OK;
}
/** @file 用户自定义文件 task_can1_Receive.c
* @brief CAN接收完成回调函数
* @param argument:
* @retval None
*/
void HAL_CAN_RxCpltCallback(CAN_HandleTypeDef *CanHandle)
{
if(CanHandle == &hcan1)
{//BinarySem_Rx_CAN1Handle 内核任务关联
osSemaphoreRelease(BinarySem_Rx_CAN1Handle);
}
if(CanHandle == &hcan2)
{//BinarySem_Rx_CAN2Handle 内核任务关联
osSemaphoreRelease(BinarySem_Rx_CAN2Handle);
}
}
/** @file 用户自定义文件 task_can1_Receive.c
* @brief CAN1接收任务
* @param argument:
* @retval None
*/
void CAN1Receive_Task(void const * argument)
{
// HAL_StatusTypeDef status;
int32_t Bin_Status;
CAN1Receive_Init();
for(;;)
{
osMutexWait(Mutex_Can1Handle,osWaitForever);
hcan_1.pRxMsg->ExtId = 0;
if(hcan_1.State == HAL_CAN_STATE_TIMEOUT)
{
/* Change CAN state */
hcan_1.State = HAL_CAN_STATE_READY;
}
HAL_CAN_DeInit(&hcan_1);
MX_CAN1_Init();
CAN1Receive_Init();
HAL_CAN_Receive_IT(&hcan_1,CAN_FIFO1); //再次使能CAN接收
osMutexRelease(Mutex_Can1Handle);
// BinarySem_Rx_CAN1Handle 重要关联CAN receive ISR
Bin_Status = osSemaphoreWait(BinarySem_Rx_CAN1Handle,500);
if(Bin_Status == osOK)
{
CAN1_Decode(hcan_1.pRxMsg);
Gun_Com_Decode(hcan_1.pRxMsg);
}
}
}
void CAN2Receive_Task(void const * argument)
{
CAN2Receive_Init();
for(;;)
{
osSemaphoreWait(BinarySem_Rx_CAN2Handle,osWaitForever);
CAN2_Decode(hcan_2.pRxMsg);
HAL_CAN_Receive_IT(&hcan_2,CAN_FIFO0);
}
}demo2:
/* 实际项目代码分析 - xSemaphoreGiveFromISR() 和 xSemaphoreTake() 开始 */
/* 技术主题:二进制信号量的使用方法 */
/** @note: 此函数被 CAN 接收中断调用,属于中断ISR中的代码!
* @brief CAN接收完成回调函数
* @param argument:
* @retval None
*/
void HAL_CAN_RxCpltCallback(CAN_HandleTypeDef *CanHandle)
{
if(CanHandle == &hcan1)
{
osSemaphoreRelease(BinarySem_Rx_CAN1Handle);
}
if(CanHandle == &hcan2)
{
osSemaphoreRelease(BinarySem_Rx_CAN2Handle); //数据流 CAN2 接收,来自中断。
}
}
/**
* @brief Release a Semaphore token
* @param semaphore_id semaphore object referenced with \ref osSemaphore.
* @retval status code that indicates the execution status of the function.
* @note MUST REMAIN UNCHANGED: \b osSemaphoreRelease shall be consistent in every CMSIS-RTOS.
*/
osStatus osSemaphoreRelease (osSemaphoreId semaphore_id)
{
osStatus result = osOK;
portBASE_TYPE taskWoken = pdFALSE;
if (inHandlerMode()) { /* 在中断中 give ,这里是 semaphore give! */
if (xSemaphoreGiveFromISR(semaphore_id, &taskWoken) != pdTRUE) {
return osErrorOS;
}
portEND_SWITCHING_ISR(taskWoken);
}
else { //代码不走这里,因为在中断中调用
if (xSemaphoreGive(semaphore_id) != pdTRUE) {
result = osErrorOS;
}
}
return result;
}
void CAN2Receive_Task(void const * argument) -> [a freertos task]
osSemaphoreWait(BinarySem_Rx_CAN2Handle,osWaitForever); -> [cmsis_os.c]
xSemaphoreTake(semaphore_id, ticks) != pdTRUE -> [freertos native function @file smphr.h]
#define xSemaphoreTake( xSemaphore, xBlockTime ) \ /* 这里是 semaphore take! */
xQueueGenericReceive( ( QueueHandle_t ) ( xSemaphore ), NULL, ( xBlockTime ), pdFALSE )
/* 实际项目代码分析 - xSemaphoreGiveFromISR() 和 xSemaphoreTake() 结束 */
/* 代码分析 from FreeRTOS 书籍描述 Mastering_FreeRTOS
“获取信号量”和“发出信号量”在不同的使用场景中具有不同含义。在此中断同步场景中,二进制信号量在概念上可视为长度为 1 的队列。队列在任何时候最多可包含一个项目,因此始终为空或满(因此为二进制)。在阻塞期间,被委任处理中断大部分操作的任务通过调用 xSemaphoreTake() 函数来高效地读取队列,若队列为空,则进入(或保持)阻塞状态。当外部事件发生后,ISR 使用 xSemaphoreGiveFromISR() 函数在队列中放置一个令牌(信号量),使队列变满。这会导致任务退出阻塞状态并删除令牌,使队列再次变为空。当任务完成其处理后,它会再次尝试从队列中读取,并发现队列为空,因此重新进入阻塞状态以等待下一个事件。图 7.3 演示了此序列。
图 7.3 显示了中断“给出”信号量,即使它没有首先“获取”它,并且任务“获取”信号量,但从不归还它。这就是为什么该场景被描述为在概念上类似于写入和读取队列的原因。它经常引起混淆,因为它不遵循与其他信号量使用场景相同的规则,在这些场景中,获取信号量的任务必须始终归还它——例如第 8 章“资源管理”中描述的场景。
翻译:在中断ISR中,直接任务通知功能比使用二进制信号量的效率更加高。直到第 10 章“任务通知”才涉及直接任务通知。
*/demo3
/*
信息流:
1. 收到CAN2数据: CAN中断将CAN消息存入全局变量 hcan_BMS中,(hcan_BMS=hcan2)。
2. 根据 hcan_BMS 变量,解析报文。
3. 发送响应的CAN消息
使用的内核服务:
1. 时钟:osKernelSysTick
2. 计数信号量
3. 消息队列
4. 多任务
*/
uint8_t BMS_Receive_MultiPacket_New(Channel_TypeDef *hChannel, uint8_t Packet, uint32_t Time_Out)
{
uint32_t time = osKernelSysTick();
for(;;)
{
if(osKernelSysTick() - time > Time_Out)
{
return ERROR;
}
BMS_Receive_CAN(); //使能CAN接收,打开中断,准备接受CAN数据。
if(osSemaphoreWait(BinarySem_Rx_CAN2Handle,Time_Out) != osOK) //是否等待超时
{
return ERROR;
}
switch (hcan_BMS.pRxMsg->ExtId) //hcan_BMS=hcan2。 是全局变量,CAN2接收数据的指针指向它 hcan2。
{
case 0x1CEC56F4: //多帧请求报文
BMS_Receive_MultiRequire(hChannel);
break;
case 0x1CEB56F4: //多帧数据报文
BMS_Receive_MultiData(hChannel);
break;
default:
break;
}
if(hcan_BMS.pRxMsg->ExtId == 0X1CEB56F4 && hcan_BMS.pRxMsg->Data[0] == Packet) //接收完成
{
return SUCCESS;
}
}
}
//打包数据,发送数据。CAN2加入队列。
void BMS_Receive_MultiData(Channel_TypeDef *hChannel)
{
uint8_t *pData,i,length,packet;
length = hcan_BMS.pRxMsg->DLC;
packet = hcan_BMS.pRxMsg->Data[0];
TxMessage_BMS.ExtId = 0X1CECF456;
TxMessage_BMS.DLC = 8;
TxMessage_BMS.Data[0] = 0x13;
TxMessage_BMS.Data[4] = 0xff;
TxMessage_BMS.Data[5] = 0x00;
TxMessage_BMS.Data[6] = BMS_Charge_Length.Which_Packet;
TxMessage_BMS.Data[7] = 0x00;
switch(BMS_Charge_Length.Which_Packet)
{
case 0x02: //车辆辨识报文
pData = (uint8_t*)&BMS_CMD_BRM;
if(packet > 7)
{
return;
}
for(i=0;i<length;i++)
{
pData[i + (packet - 1)*7] = hcan_BMS.pRxMsg->Data[i+1];
}
if(hcan_BMS.pRxMsg->Data[0] == BMS_Charge_Length.BRM_Packet) //数据接收完成
{
TxMessage_BMS.Data[1] = (uint8_t)BMS_Charge_Length.BRM_Length;
TxMessage_BMS.Data[2] = (uint8_t)(BMS_Charge_Length.BRM_Length>>8);
TxMessage_BMS.Data[3] = BMS_Charge_Length.BRM_Packet;
BMS_Transmit_CAN(); //发送数据
hChannel->Modbus_Channel->BMS_Info.BMS_Version = (uint16_t)BMS_CMD_BRM.BMS_Version[1]<<8 | BMS_CMD_BRM.BMS_Version[0];
hChannel->Modbus_Channel->BMS_Info.Battery_Type = BMS_CMD_BRM.Battery_type;
hChannel->Modbus_Channel->BMS_Info.Battery_Rated_Capacity = BMS_CMD_BRM.Rated_Capacity;
hChannel->Modbus_Channel->BMS_Info.Battery_Rated_U = BMS_CMD_BRM.Rated_U;
}
break;
case 0x06: //电池充电参数报文
pData = (uint8_t*)&BMS_CMD_BCP;
if(packet > 2)
{
return;
}
for(i=0;i<length;i++)
{
pData[i + (packet - 1)*7] = hcan_BMS.pRxMsg->Data[i+1];
}
if(hcan_BMS.pRxMsg->Data[0] == BMS_Charge_Length.BCP_Packet) //数据接收完成
{
TxMessage_BMS.Data[1] = (uint8_t)BMS_Charge_Length.BCP_Length;
TxMessage_BMS.Data[2] = (uint8_t)(BMS_Charge_Length.BCP_Length>>8);
TxMessage_BMS.Data[3] = BMS_Charge_Length.BCP_Packet;
BMS_Transmit_CAN(); //发送数据
hChannel->Modbus_Channel->BMS_Info.Single_Battery_Allow_Highest_U = BMS_CMD_BCP.Single_Battery_Highest_U;
hChannel->Modbus_Channel->BMS_Info.Single_Battery_Allow_Highest_Temp = BMS_CMD_BCP.Highest_Temp - 50;
hChannel->Modbus_Channel->BMS_Info.Battery_Allow_Highest_U = BMS_CMD_BCP.Charge_Highest_U;
}
break;
case 0x11: //电池充电总状态
pData = (uint8_t*)&BMS_CMD_BCS;
if(packet > 2)
{
return;
}
for(i=0;i<length;i++)
{
pData[i + (packet - 1)*7] = hcan_BMS.pRxMsg->Data[i+1];
}
if(hcan_BMS.pRxMsg->Data[0] == BMS_Charge_Length.BCS_Packet)
{
TxMessage_BMS.Data[1] = (uint8_t)BMS_Charge_Length.BCS_Length;
TxMessage_BMS.Data[2] = (uint8_t)(BMS_Charge_Length.BCS_Length>>8);
TxMessage_BMS.Data[3] = BMS_Charge_Length.BCS_Packet;
BMS_Transmit_CAN(); //发送数据
hChannel->Modbus_Channel->Display_Info.Remain_Time = BMS_CMD_BCS.Remaining_Time;
hChannel->Modbus_Channel->Display_Info.SOC = BMS_CMD_BCS.Battery_SOC;
hChannel->Modbus_Channel->BMS_Info.Single_Battery_Highest_U = BMS_CMD_BCS.Max_U_And_Num.Max_U;
hChannel->Modbus_Channel->BMS_Info.BMS_Measure_U = BMS_CMD_BCS.Charge_U_Measure;
hChannel->Modbus_Channel->BMS_Info.BMS_Measure_I = BMS_CMD_BCS.Charge_I_Measure - 4000;
}
break;
case 0x15: //单体蓄电池电压 BMV
// pData = (uint8_t *)test_receive_U;
pData = NULL;
if(packet > BMS_Charge_Length.BMV_Packet)
{
return;
}
for(i=0;i<length;i++)
{
if(pData != NULL)
{
pData[i + (packet - 1)*7] = hcan_BMS.pRxMsg->Data[i+1];
}
}
if(hcan_BMS.pRxMsg->Data[0] == BMS_Charge_Length.BMV_Packet)
{
TxMessage_BMS.Data[1] = (uint8_t)BMS_Charge_Length.BMV_Length;
TxMessage_BMS.Data[2] = (uint8_t)(BMS_Charge_Length.BMV_Length>>8);
TxMessage_BMS.Data[3] = BMS_Charge_Length.BMV_Packet;
BMS_Transmit_CAN(); //发送数据
}
break;
case 0x16: //蓄电池温度 BMT
// pData = test_receive_Temp;
pData = NULL;
if(packet > BMS_Charge_Length.BMT_Packet)
{
return;
}
for(i=0;i<length;i++)
{
if(pData != NULL)
{
pData[i + (packet - 1)*7] = hcan_BMS.pRxMsg->Data[i+1];
}
}
if(hcan_BMS.pRxMsg->Data[0] == BMS_Charge_Length.BMT_Packet)
{
TxMessage_BMS.Data[1] = (uint8_t)BMS_Charge_Length.BMT_Length;
TxMessage_BMS.Data[2] = (uint8_t)(BMS_Charge_Length.BMT_Length>>8);
TxMessage_BMS.Data[3] = BMS_Charge_Length.BMT_Packet;
BMS_Transmit_CAN(); //发送数据
}
break;
case 0x17:
pData = NULL;
if(packet > BMS_Charge_Length.BSP_Packet)
{
return;
}
for(i=0;i<length;i++)
{
if(pData != NULL)
{
pData[i + (packet - 1)*7] = hcan_BMS.pRxMsg->Data[i+1];
}
}
if(hcan_BMS.pRxMsg->Data[0] == BMS_Charge_Length.BSP_Packet)
{
TxMessage_BMS.Data[1] = (uint8_t)BMS_Charge_Length.BSP_Length;
TxMessage_BMS.Data[2] = (uint8_t)(BMS_Charge_Length.BSP_Length>>8);
TxMessage_BMS.Data[3] = BMS_Charge_Length.BSP_Packet;
BMS_Transmit_CAN(); //发送数据
}
break;
default:
break;
}
}
//发送数据,把打包好的数据,放入队列,被读出,由CAN2发出。
void BMS_Transmit_CAN()
{
osMessagePut(Queue_CAN2_TransmitHandle,(uint32_t)&TxMessage_BMS,5); //通过CAN2发送
}3.2 生产者任务写入数据到队列
接收CAN消息的任务写入数据流供其他任务使用:
Queue_CAN1_TransmitHandle: osMessagePut -> xQueueSend
Queue_CAN2_TransmitHandle: osMessagePut -> xQueueSend
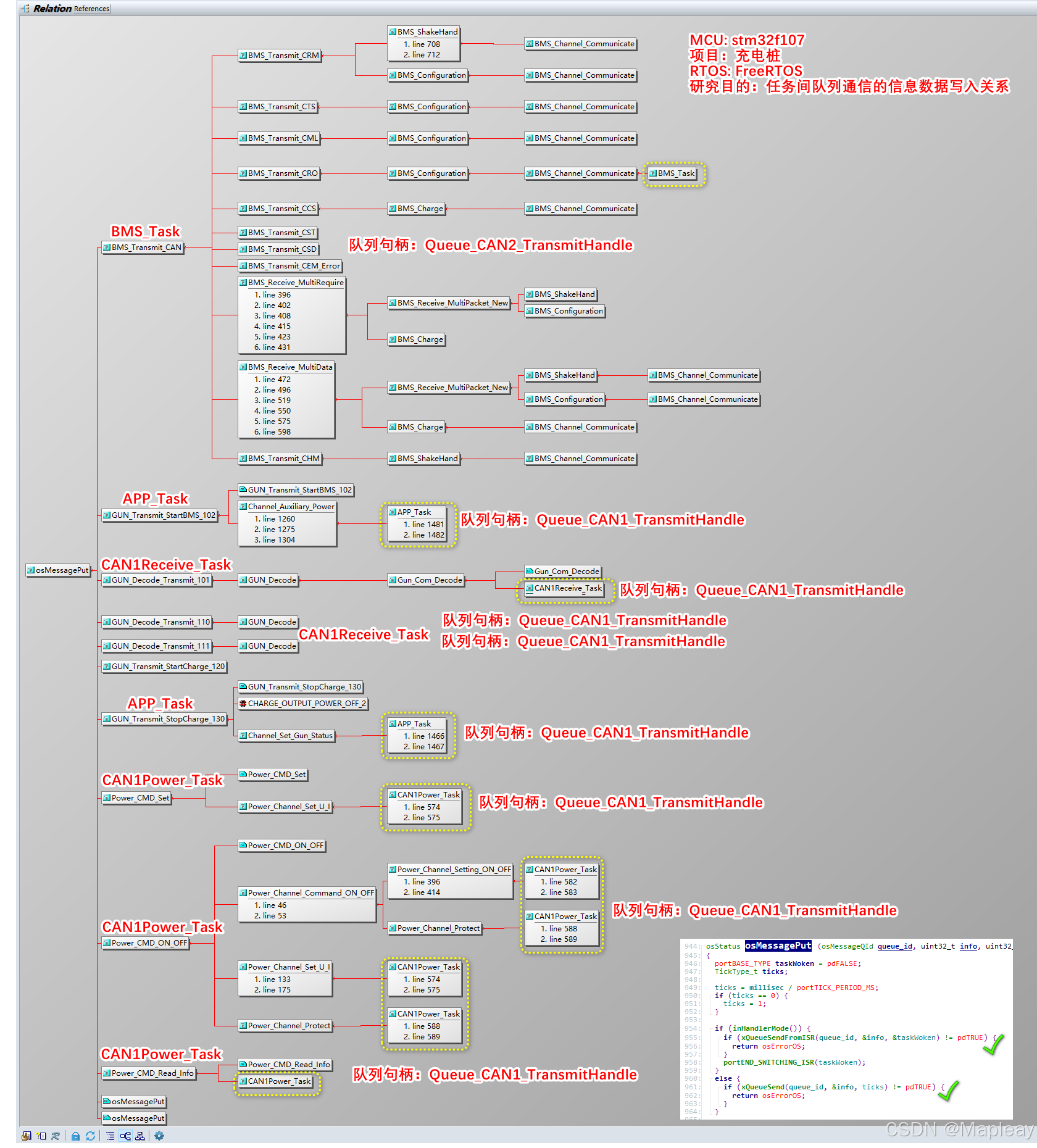
3.3 消费者任务读取队列中的消息数据单元
读取数据流:
Queue_CAN1_TransmitHandle: osMessageGet -> xQueueReceive
Queue_CAN2_TransmitHandle: osMessageGet -> xQueueReceive
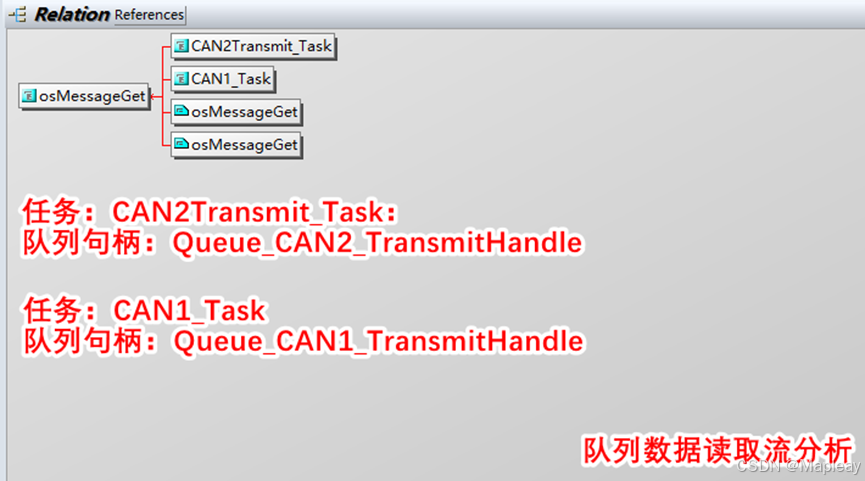
四、其他学手段
4.1 Tracealyzer for FreeRTOS

FreeRTOS is a popular real-time operating system (RTOS) often used on devices such as STM32, Renesas RA, NXP iMX, Microchip PIC32, Nordic nRF and ESP32.
FreeRTOS
Deep Observability for FreeRTOS Software
Tracealyzer provides many views for different perspectives of your runtime system. All view are connected for a streamlined workflow. Spot anomalies in high-level overviews and then drill down into the details to see the cause.
The trace view provides a detailed timeline of task scheduling and interrupts, FreeRTOS API calls as well as custom “user event” logging in the application code. This is helps you debug your code and lets you verify that your code executes as intended. You can also learn how to improve the software design for better performance.
The large set of visual overviews includes for example CPU load, task execution times, stack usage and heap memory allocation (malloc/free). Such overviews provides a profile of the resource usage over time, which helps you see the big picture, spot anomalies and optimize the system.
Trace your Tasks
The core of a FreeRTOS system is the concept of tasks, which are threads scheduled by the FreeRTOS kernel to provide multitasking. Each task has its own stack and a fixed scheduling priority, which is very important for functional correctness and performance. Tracealyzer lets you analyze the behavior and performance of different priority assignments, as well as the stack usage of the tasks. If your stacks are too small, you risk nasty bugs due to stack overflow. If they are too large, you are wasting precious RAM that might be needed elsewhere in your application.
The trace view shows both the task scheduling and calls to FreeRTOS API functions. This allows you to see exactly when tasks are activated, when they actually execute, and why they sometimes don’t execute as intended. You can also see an overview showing which tasks are consuming the processor time, as shown in the “CPU Load Graph”. Detailed statistics is also available, like task execution times and response times.
Trace Kernel API Calls
FreeRTOS offers several APIs for passing data between tasks and for protecting shared resources, such as queues, semaphores and mutexes. These API functions may block the calling task’s execution until another task has performed a matching operation. Such API calls may form a network of dependencies between the tasks that is not apparent in the source code. Tracealyzer can visualize the task interactions, which makes it far easier to understand, debug and optimize FreeRTOS applications. Some examples are provided below.
Queue Events
Queues allow FreeRTOS tasks to communicate by sending and receiving messages. Queues have a fixed number of slots and messages are normally buffered in FIFO order. The sender calls xQueueSend to add a message in the queue. The receiver task calls xQueueReceive to fetch the next message from the queue.
Queue operations might block if trying to send a message to a full queue, or trying to read a message from an empty queue. The screenshot shows how Tracealyzer displays queue usage and blocking. The TX task sends two messages to the queue. This wakes up the RX task (hence the green label) and it receives the two messages. Finally, the task is blocked (red label) by xQueueReceive since the queue is now empty.
The queue forms a dependency between TX and RX, that can be seen in the Communication Flow graph below. The direction of the arrows show the usage, i.e. that TX is sending to the queue and RX is receiving from it. Double-clicking on any of the nodes shows the corresponding events.
Blocking may also result in a timeout, depending on the timeout argument for xQueueReceive and xQueueSend. These are displayed as orange labels in Tracealyzer. Timeouts are possible on many FreeRTOS API calls, not just for queues, and are really important to keep track of. Some might be intentional, while other may indicate serious errors.
Semaphore Events
Semaphores allow for waking up tasks on a particular event. A semaphore can be regarded as a signal, which is sent by calling xSemaphoreGive and received by calling xSemaphoreTake. An example screenshot is shown below. Note that the RX task is blocked by a previous call to xSemaphoreTake and only wakes up after TX has called xSemaphoreGive.
Semaphores may also be used to protect critical sections in the code, i.e. mutual exclusion. However, when using a regular semaphore for this purpose there is a risk for priority inversion, meaning that high-priority tasks are delayed by lower-priority tasks. Tracealyzer makes it easy to spot issues like this, for example using the “Actor Instance Graph” showing the task response times.
Mutex Events
FreeRTOS offers Mutex objects to allow critical sections without the risk for priority inversion. Mutexes are used in almost the same way as semaphores and use the same API functions, xSemaphoreTake and xSemaphoreGive. However, mutexes are typically locked (taken) and released (given) in sequence and by the same task, as shown below, to provide mutual exclusion.
Mutex objects implement the priority inheritance protocol to avoid priority inversion. The below example shows how Mutexes appear in Tracealyzer. The blue labels show the priority inheritance, where the priority of the holding task is raised (inherited) to the same level as the waiting task to avoid unsuitable preemptions.
This trace view, combined with a large set of visual overviews, makes it easy to understand the real-time behavior of your FreeRTOS system. You can verify that task priorities are suitable and that the system works as designed. If something seems to be wrong, you can isolate and debug the real-time behavior without halting the system, especially in combination with application logging (see below). You can also profile the system to ensure it runs in an efficient manner, so you get the most out of your hardware.
Application Logging
Tracealyzer provides advanced logging capabilities. Log custom events and data in your application code and display it in Tracealyzer, together with the FreeRTOS kernel trace and as graphical plots. This provides deeper observability into the application code at runtime.
Unlike printf-calls, the Tracealyzer logging does not slow down your code by several milliseconds. The efficient logging functions can eliminate over 99% of the logging overhead compared to printf over a UART. This low-impact logging ensures you get the right picture in your debugging, without probe effects from slow logging calls.
For example, state transitions can be logged and displayed in a “logic analyzer” view and as a state diagram. The result can be shown within the trace view (as shown on the left) or summarized as a state graph (on the right), making it easy to spot incorrect behavior.
Learn more how Tracealyzer simplifies debugging with advanced, low-impact logging capabilities.
五、FreeRTOS的移植-stm32f407vet6
5.1 移植初步版本,能跑
RTOS的内核移植,将硬件资源注入内核,也可以说是内核与硬件(MCU/RAM等)彼此资源的耦合,比如内核接口中需要实现任务上下文切换、开关中断、任务堆栈初始化、内核滴答时钟中断,这些就是内核移植,也就是根据MCU等硬件资源去实现内核预留的接口函数。内核滴答时钟中断ISR是已经用c语言写好的,直接放入stm32f407vet6的systick时钟中断ISR中即可,因此有些官方rtos不认为这部分属于移植范畴。
关于内核本身的配置,ucos/freertos都有内核配置 “xxx.h” 的头文件。
在stm32f407ve上移植FreeRTOS:
1. 裸机文件:
1.1 启动汇编文件 startup_stm32f40_41xxx.s
1.2 系统基本配置文件:system_stm32f4xx.c 配置系统NVIC/RCC/等基本必要功能
1.3 中断服务函数文件:stm32f4xx_it.c
2. FreeRTOS文件:
2.1 无需移植的源代码
2.2 需要移植的源代码: portable 文件夹里面的:
2.2.1 内存管理代码:使用heap_4.c
2.2.2 移植代码:任务堆栈初始化、任务切换、开关中断等,也就是复制俩文件:
C:\FreeRTOSv202212.01\FreeRTOS\Source\portable\RVDS\ARM_CM4F\port.c
C:\FreeRTOSv202212.01\FreeRTOS\Source\portable\RVDS\ARM_CM4F\portmacro.h
相关的主要函数是: xPortPendSVHandler 函数; xPortSysTickHandler 函数; vPortSVCHandler 函数;
2.3 遇到的问题:
2.3.1 问题描述:..\FreeRTOS\source\portable\RVDS\ARM_CM4F\port.c(788): error: #20: identifier "SystemCoreClock" is undefined
解决方案: 这是一个条件编译,只有定义了__ICCARM__以后下边的代码才有效。 需要修改条件编译,让 extern uint32_t SystemCoreClock; 生效。
修改后为: #if defined(__ICCARM__) || defined(__CC_ARM) || defined(__GNUC__) 即可。
2.3.2 问题描述:
.\Objects\FreeRTOS-stm32f407ve.axf: Error: L6200E: Symbol SVC_Handler multiply defined (by port.o and stm32f4xx_it.o).
.\Objects\FreeRTOS-stm32f407ve.axf: Error: L6200E: Symbol PendSV_Handler multiply defined (by port.o and stm32f4xx_it.o).
.\Objects\FreeRTOS-stm32f407ve.axf: Error: L6200E: Symbol SysTick_Handler multiply defined (by port.o and stm32f4xx_it.o).
解决方案:
port.c和stm32f4xx_it.c两个文件中有重复定义的函数:PendSV_Handler(), SVC_Handler(), SysTick_Handler()。
屏蔽掉stm32f4xx_it.c中的PendSV_Handler(), SVC_Handler(), SysTick_Handler()三个函数。再次编译,发现如下未定义错误。
预定义的两个字符串是完全等价的。
3. 移植:将裸机与内核耦合
FreeRTOSConfig.h文件中已经做了。具体内容是:
/* Definitions that map the FreeRTOS port interrupt handlers to their CMSIS standard names. */
#define vPortSVCHandler SVC_Handler
#define xPortPendSVHandler PendSV_Handler
#define xPortSysTickHandler SysTick_Handler
4. FreeRTOS内核配置文件:
把官方demo配置文件 FreeRTOSConfig.h 放入工程文件夹中。 官方路径在:
路径 FreeRTOS\FreeRTOSv202212.01\FreeRTOS\Demo\CORTEX_M4F_STM32F407ZG-SK 下的 FreeRTOSConfig.h 文件。严格讲它只是内核配置文件,但是通常也可以把它归类于整个项目配置文件夹中。
5.2 配置FreeRTOS内核的时基功能
内核滴答周期,时间管理都需要时基。
/**************************************** 【Mark: iuuse-rots-systick-1ms】开始 **********************************************************/
FreeRTOS的时间问题:
1. rtos是否需要精确的硬件定时器产生的时间?
2. rtos的时间主要单位是tick,也就是一个系统滴答周期。
3. ucosiii的时分秒延时函数也是基于ucos内核使用的tick为基本计时单位设计的。
4. 基本可以判定内核的时间单位就是tick内核滴答周期。
5. 所以,CortexM3内核中的timer-systick,才是rtos内核的时钟源头。
@prot.c 移植文件
void xPortSysTickHandler( void )
{
xTaskIncrementTick();
}
@task.c 内核文件
BaseType_t xTaskIncrementTick( void )
{
// xTickCount 是全局变量。
++xTickCount;
……
}
6. 所以进一步往上摸索,找到时钟树配置 SYSCLK 和 systick 配置参数进行分析。
7. 在时钟树图里,SYSCLK最大72MHz经过AHB的预分频器(可以设为1分频或2分频等)后,称这段时钟信号为 HCLK,给 MCU_Core、RAM 提供时钟信号。
【st公司的代码到底如何配置时钟树的呢?】
8.
/**
******************************************************************************
* @文件 system_stm32f4xx.c
* @作者 MCD 应用组
* @版本 V1.8.0
* @日期 2016年11月4日
* @简介 CMSIS Cortex-M4 Device Peripheral Access Layer System Source File.
* 此文件讲解 STM32F4xx MCU 的系统时钟配置
*
* 1. 此文件提供两个函数和一个全局变量供用户应用程序调用:
* - SystemInit(): 根据时钟配置xls工具(Excel文件),设置系统时钟,包含系统时钟源、
* PLL倍频系数、AHB/APBx分频系数和Flash的配置。
* 此函数在启动复位函数后跳入main函数之前执行。
* 此函数的调用发生在 "startup_stm32f4xx.s" 中。
*
* - SystemCoreClock 全局变量: 经过分频产生 core clock (HCLK), 被应用程序用来设置
* SysTick 定时器模块等其他参数
*
* - SystemCoreClockUpdate(): 用于更新全局变量 SystemCoreClock 。
* 在程序执行期间内,若 core clock 改变,那么必须调用此函数来更新。
*
* 2. After each device reset the HSI (16 MHz) is used as system clock source.
* Then SystemInit() function is called, in "startup_stm32f4xx.s" file, to
* configure the system clock before to branch to main program.
*
* 3. If the system clock source selected by user fails to startup, the SystemInit()
* function will do nothing and HSI still used as system clock source. User can
* add some code to deal with this issue inside the SetSysClock() function.
*
* 4. 在 "stm32f4xx.h" file 文件中有默认配置HSE_VALUE,默认外部高速晶振HSE的值设置为 25MHz,
* 不管是直接使用 HSE 作为系统时钟源,还是使用 HSE 经过 PLL 倍频后作为时钟源,
* 假设实际外部晶振源的频率是 8MHz,不是25MHz,那么就需要修改 HSE_VALUE 的值为实际外部晶振频率 8Mhz。
*
* 5. This file configures the system clock as follows:
* 省略
******************************************************************************
*/
@file stm32f4xx.h
/* Uncomment the line below according to the target STM32 device used in your
application
*/
#if !defined(STM32F40_41xxx) && !defined(STM32F427_437xx) && !defined(STM32F429_439xx) && !defined(STM32F401xx) && !defined(STM32F410xx) && \
!defined(STM32F411xE) && !defined(STM32F412xG) && !defined(STM32F413_423xx) && !defined(STM32F446xx) && !defined(STM32F469_479xx)
/* #define STM32F40_41xxx */ /*!< STM32F405RG, STM32F405VG, STM32F405ZG, STM32F415RG, STM32F415VG, STM32F415ZG,
STM32F407VG, STM32F407VE, STM32F407ZG, STM32F407ZE, STM32F407IG, STM32F407IE,
STM32F417VG, STM32F417VE, STM32F417ZG, STM32F417ZE, STM32F417IG and STM32F417IE Devices */
/* #define STM32F427_437xx */ /*!< STM32F427VG, STM32F427VI, STM32F427ZG, STM32F427ZI, STM32F427IG, STM32F427II,
STM32F437VG, STM32F437VI, STM32F437ZG, STM32F437ZI, STM32F437IG, STM32F437II Devices */
…………
@file stm32f4xx.h 修改实际使用的外部晶振频率
#define HSE_VALUE ((uint32_t)8000000) /* 需要根据实际外部晶振的频率修改 HSE_VALUE 的值,单位是Hz。实际是8MHz */
int main(void)
{
/* Reset of all peripherals, Initializes the Flash interface and the Systick. */
HAL_Init(); //其中包括systick定时器的配置。
/* Configure the system clock */
SystemClock_Config(); //这里配置时钟树,包括systick定时器的配置。
/* 外设初始化 */
;
/* RTOS内核对象初始化: 信号量创建、任务创建、互斥量创建等 */
;
/* 启动内核调度 */
osKernelStart();
}
/** @file hal层库文件
* @brief Initializes the System Timer and its interrupt, and starts the System Tick Timer.
* Counter is in free running mode to generate periodic interrupts.
* @param TicksNumb: Specifies the ticks Number of ticks between two interrupts.
* @retval status: - 0 Function succeeded.
* - 1 Function failed.
*/
uint32_t HAL_SYSTICK_Config(uint32_t TicksNumb)
{
return SysTick_Config(TicksNumb);
}
/** \brief System Tick Configuration 这是 CMSIS 规范部分 @core_cm4.h
The function initializes the System Timer and its interrupt, and starts the System Tick Timer.
Counter is in free running mode to generate periodic interrupts.
\param [in] ticks Number of ticks between two interrupts.
\return 0 Function succeeded.
\return 1 Function failed.
\note When the variable <b>__Vendor_SysTickConfig</b> is set to 1, then the
function <b>SysTick_Config</b> is not included. In this case, the file <b><i>device</i>.h</b>
must contain a vendor-specific implementation of this function.
调用这里的代码设置 systick timer 嗯。20240918
*/
__STATIC_INLINE uint32_t SysTick_Config(uint32_t ticks)
{
if ((ticks - 1UL) > SysTick_LOAD_RELOAD_Msk) { return (1UL); } /* Reload value impossible */
SysTick->LOAD = (uint32_t)(ticks - 1UL); /* set reload register */
NVIC_SetPriority (SysTick_IRQn, (1UL << __NVIC_PRIO_BITS) - 1UL); /* set Priority for Systick Interrupt */
SysTick->VAL = 0UL; /* Load the SysTick Counter Value */
SysTick->CTRL = SysTick_CTRL_CLKSOURCE_Msk |
SysTick_CTRL_TICKINT_Msk |
SysTick_CTRL_ENABLE_Msk; /* Enable SysTick IRQ and SysTick Timer */
return (0UL); /* Function successful */
}
/* 第二阶段的思考:
void SystemInit(void) 里设置了 RCC->PLLCFGR = 0x24003010;
0x24003010 转换位二进制数值是 -0010 0100 0000 0000 0011 0000 0001 0000-
PLL_M Bits 5:0 的寄存器值是 -010000- 对应的分频系数是 -16- 官方要求 2 ≤ PLLM ≤ 63.
PLL_N Bits 14:6 的寄存器值是 -011000000- 对应的倍频系数是 -192- 官方要求 50 ≤ PLLN ≤ 432.
PLL_P Bits 17:16 的寄存器值是 -00- 对应的分频系数是 -2- 官方要求 PLLP = 2, 4, 6, or 8.
SystemCoreClock 的时钟源频率计算公式为:
寄存器版本:
pllm = RCC->PLLCFGR & RCC_PLLCFGR_PLLM;
plln = (RCC->PLLCFGR & RCC_PLLCFGR_PLLN) >> 6;
pllp = (((RCC->PLLCFGR & RCC_PLLCFGR_PLLP) >>16) + 1 ) *2;
pllvco = (HSE_VALUE / RCC->PLLCFGR & RCC_PLLCFGR_PLLM) * ((RCC->PLLCFGR & RCC_PLLCFGR_PLLN) >> 6);
SystemCoreClock = pllvco/pllp;
数学公式版本:
f(VCO clock) = f(PLL clock input) × (PLLN / PLLM)
f(PLL general clock output) = f(VCO clock) / PLLP
f(USB OTG FS, SDIO, RNG clock output) = f(VCO clock) / PLLQ
SystemCoreClock = PLL_VCO / PLL_P = SYSCLK. (数学公式)
实际开发板的 HSE 是 8MHz.
SystemCoreClock = 8000000*192/16/2=48MHz
最后修改 SystemCoreClock 定义的数值为真实数值。
#if defined(STM32F40_41xxx)
uint32_t SystemCoreClock = 48000000; //原值:168000000; 因为实际计算值为 48MHz
也就是说只要保证 SystemCoreClock 的值是它真实值,那么
这样以后,默认情况下,FreeRTOS 的 1 个 tick 就是 1ms. 实际上也就是把 systick timer 设置成为1ms的中断。
下载验证看了,1s的闪烁灯光,应该是对的。
再补充下 FreeRTOS 是怎么处理 systick timer 的设置细节:
1. 在 prot.c 移植文件中有 systick timer 的参数配置代码如下:
// SystemCoreClock == configSYSTICK_CLOCK_HZ; configTICK_RATE_HZ == 1000; 默认配置。
__weak void vPortSetupTimerInterrupt( void )
{
/* Configure SysTick to interrupt at the requested rate. */
portNVIC_SYSTICK_LOAD_REG = ( configSYSTICK_CLOCK_HZ / configTICK_RATE_HZ ) - 1UL;
portNVIC_SYSTICK_CTRL_REG = ( portNVIC_SYSTICK_CLK_BIT_CONFIG | portNVIC_SYSTICK_INT_BIT | portNVIC_SYSTICK_ENABLE_BIT );
}
//由于systick timer是 CMSIS 标准的一部分,所以,所有CM4/CM3等 CortexM 内核的 MCU 都具有同样的 systick timer 硬件定时器。
//所以,FreeRTOS 可以直接操作,不必担心兼容性问题。
BaseType_t xPortStartScheduler( void )
{
/* Start the timer that generates the tick ISR. Interrupts are disabled here already. */
vPortSetupTimerInterrupt();
}
*/
/**
* @brief Setup the microcontroller system
* Initialize the Embedded Flash Interface, the PLL and update the
* SystemFrequency variable.
* @param None
* @retval None
*/
void SystemInit(void)
{
/* FPU settings ------------------------------------------------------------*/
#if (__FPU_PRESENT == 1) && (__FPU_USED == 1)
SCB->CPACR |= ((3UL << 10*2)|(3UL << 11*2)); /* set CP10 and CP11 Full Access */
#endif
/* Reset the RCC clock configuration to the default reset state ------------*/
/* Set HSION bit */
RCC->CR |= (uint32_t)0x00000001;
/* Reset CFGR register */
RCC->CFGR = 0x00000000;
/* Reset HSEON, CSSON and PLLON bits */
RCC->CR &= (uint32_t)0xFEF6FFFF;
/* Reset PLLCFGR register */
RCC->PLLCFGR = 0x24003010;
/* Reset HSEBYP bit */
RCC->CR &= (uint32_t)0xFFFBFFFF;
/* Disable all interrupts */
RCC->CIR = 0x00000000;
#if defined(DATA_IN_ExtSRAM) || defined(DATA_IN_ExtSDRAM)
SystemInit_ExtMemCtl();
#endif /* DATA_IN_ExtSRAM || DATA_IN_ExtSDRAM */
/* Configure the System clock source, PLL Multiplier and Divider factors,
AHB/APBx prescalers and Flash settings ----------------------------------*/
SetSysClock();
/* Configure the Vector Table location add offset address ------------------*/
#ifdef VECT_TAB_SRAM
SCB->VTOR = SRAM_BASE | VECT_TAB_OFFSET; /* Vector Table Relocation in Internal SRAM */
#else
SCB->VTOR = FLASH_BASE | VECT_TAB_OFFSET; /* Vector Table Relocation in Internal FLASH */
#endif
}
/* SystemCoreClockUpdate 函数的作用是 可以看清如何配置时钟源 */
void SystemCoreClockUpdate(void)
{
uint32_t tmp = 0, pllvco = 0, pllp = 2, pllsource = 0, pllm = 2;
#if defined(STM32F412xG) || defined(STM32F413_423xx) || defined(STM32F446xx)
uint32_t pllr = 2;
#endif /* STM32F412xG || STM32F413_423xx || STM32F446xx */
/* Get SYSCLK source -------------------------------------------------------*/
/* 从 RCC->CFGR 里取出 RCC_CFGR_SWS 字段(bit3:2),Bits 3:2 SWS: System clock switch status
** 00:HSI , 01:HSE , 10:PLL , 11:not allowed. (选取时钟源的字段值) time:20240918
*/
tmp = RCC->CFGR & RCC_CFGR_SWS;
switch (tmp)
{
case 0x00: /* 选 HSI 作为系统时钟源 */
SystemCoreClock = HSI_VALUE;
break;
case 0x04: /* 选 HSE 作为系统时钟源 */
SystemCoreClock = HSE_VALUE;
break;
case 0x08: /* 选 PLL 作为系统时钟源 */ /* PLL P used as system clock source */
/*
** added by mapleay 20240918 stm32f407 RM 手册 page228.
7.3.2 RCC PLL configuration register (RCC_PLLCFGR)
RCC_PLLCFGR 寄存器的值按照下列公式配置时钟信号源:
f(VCO clock) = f(PLL clock input) × (PLLN / PLLM) // Bits 14:6 PLLN: Main PLL (PLL) multiplication factor for VCO
// Bits 5:0 PLLM: Division factor for the main PLL (PLL) and audio PLL (PLLI2S) input clock
f(PLL general clock output) = f(VCO clock) / PLLP // Bits 17:16 PLLP:Main PLL (PLL) division factor for main system clock
f(USB OTG FS, SDIO, RNG clock output) = f(VCO clock) / PLLQ //不是core的分频因子,可以不考虑。
*/
/* PLL_VCO = (HSE_VALUE or HSI_VALUE / PLL_M) * PLL_N
SYSCLK = PLL_VCO / PLL_P
*/
pllsource = (RCC->PLLCFGR & RCC_PLLCFGR_PLLSRC) >> 22; // Bit 22 PLLSRC 的值为1,则选HSE作为PLL的时钟源输入
pllm = RCC->PLLCFGR & RCC_PLLCFGR_PLLM; //确定PLL的M分频因子的数值,这个公式的结果就是答案。
#if defined(STM32F40_41xxx) || defined(STM32F427_437xx) || defined(STM32F429_439xx) || defined(STM32F401xx) || defined(STM32F412xG) || defined(STM32F413_423xx) || defined(STM32F446xx) || defined(STM32F469_479xx)
if (pllsource != 0)
{
/* 若 HSE 作为 PLL 的输入时钟源。 先与运算再右移6位才是PLLN寄存器的值,就是真实的倍频二进制系数 */
pllvco = (HSE_VALUE / pllm) * ((RCC->PLLCFGR & RCC_PLLCFGR_PLLN) >> 6);
}
else
{
/* HSI used as PLL clock source */
pllvco = (HSI_VALUE / pllm) * ((RCC->PLLCFGR & RCC_PLLCFGR_PLLN) >> 6);
}
#endif /* STM32F40_41xxx || STM32F427_437xx || STM32F429_439xx || STM32F401xx || STM32F412xG || STM32F413_423xx || STM32F446xx || STM32F469_479xx */
pllp = (((RCC->PLLCFGR & RCC_PLLCFGR_PLLP) >>16) + 1 ) *2; //根据寄存器的值,计算出 PLL_p的分频系数。 PLLP = 2, 4, 6, or 8.
SystemCoreClock = pllvco/pllp; //综上,SystemCoreClock 取决于 HSE_VALUE PLL_m PLL_n PLL_p 的数值。20240918
break;
default:
SystemCoreClock = HSI_VALUE; //默认选取 HSI 为时钟源
break;
}
/* Compute HCLK frequency --------------------------------------------------*/
/* Get HCLK prescaler */
tmp = AHBPrescTable[((RCC->CFGR & RCC_CFGR_HPRE) >> 4)];
/* HCLK frequency */
SystemCoreClock >>= tmp;
}
/**************************************** 【Mark: iuuse-rots-systick-1ms】结束 **********************************************************/ 将 SystemCoreClock 调整到 168MHz 的过程:
实际开发板的 HSE 是 8MHz.
void SystemInit(void) 里设置了 RCC->PLLCFGR = 0x24003010;
0x24003010 转换位二进制数值是 -0010 0100 0000 0000 0011 0000 0001 0000-
SystemCoreClock = 8000000*192/16/2=48MHz
通过修改 RCC->PLLCFGR 的值调整为:具体修改 PLLN 的值为 336, PLLM的值为 8。
SystemCoreClock = 8000000*336/8/2=168MHz
得到最终 RCC->PLLCFGR 应该为:
0x24003010 转换位二进制数值是 -0010 0100 0000 0000 0011 0000 0001 0000- (48MHz的配置)
修改M为8:
PLL_M Bits 5:0 的寄存器值是 -001000- 对应的分频系数是 -8- 官方要求 2 ≤ PLLM ≤ 63.
修改N为336:
PLL_N Bits 14:6 的寄存器值是 -101010000- 对应的倍频系数是 -336- 官方要求 50 ≤ PLLN ≤ 432.
P保持不变:
PLL_P Bits 17:16 的寄存器值是 -00- 对应的分频系数是 -2- 官方要求 PLLP = 2, 4, 6, or 8.
得到:
0010 0100 0000 00 000101010000001000
-00100100000000000101010000001000- = 0x24005408. (168MHz的配置)
所以 RCC->PLLCFGR = 0x24005408;
修改代码:
0. 保持不变: #define HSE_VALUE ((uint32_t)8000000) /* 需要根据实际外部晶振的频率修改 HSE_VALUE 的值,单位是Hz。实际是8MHz */
1. uint32_t SystemCoreClock = 168000000; //168MHz版本 with 8MHz HSE晶振。
2. void SystemInit(void) 里设置 RCC->PLLCFGR = 0x24005408;
3. void RCC_DeInit(void) 里设置 RCC->PLLCFGR = 0x24005408;
4. PLL_M PLL_N PLL_P PLL_Q 参数更新 被应用于 static void SetSysClock(void) 函数中。
RCC->PLLCFGR = 0x24005408;
RCC_PLLCFGR:Bits 31:28 Reserved, must be kept at reset value.
000101010000001000
实际值:0x07405408 0111010000000101010000001000
设置值:0x24005408 00100100000000000101010000001000

















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









