






前向传播
以一个简单的神经网络模型为例:
向前传播即是按顺序输入-->输出-->输入-->输出Output的过程,所构建的SimpleNet模型可以看成是一个有多层嵌套的复合函数:
Output = fc2(ReLU(fc1(x)))

import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(3, 5) # 输入层3维,隐藏层5维
self.relu = nn.ReLU() # 推荐ReLU缓解梯度消失
self.fc2 = nn.Linear(5, 1) # 输出层1维
def forward(self, x):
x = self.fc1(x)
x = self.relu(x) # 非线性激活
return self.fc2(x)
model = SimpleNet()
x = torch.randn(1,3, requires_grad=True)
y = model(x)
# 损失函数
criterion = nn.MSELoss()
# 反向传播演示,
y_true = torch.randn(1,1)
loss = criterion(y, y_true)
loss.backward() # 自动计算梯度
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 梯度更新(优化器完成)
optimizer.step() #根据梯度更新参数
optimizer.zero_grad() #清空历史梯度反向传播
通过loss函数计算预测值和真实值的差异,通过![]() ,对W1和W2求梯度(偏导),然后更新W1,W2,如果模型更加复杂,节点更多,那么所有的权重都会通过此方法进行更新:
,对W1和W2求梯度(偏导),然后更新W1,W2,如果模型更加复杂,节点更多,那么所有的权重都会通过此方法进行更新:
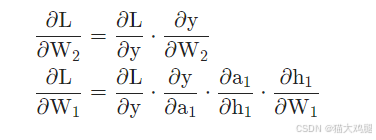
通过前向和反向的循环,最终达成梯度最小化状态,预测值最接近真实值的状态,获得最终的W1,W2。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









