







 本文详细介绍了JavaScript中Rest参数和Spread运算符在ES6及ES9中的应用,包括如何使用它们处理对象和数组。同时,深入探讨了正则表达式的扩展,如命名捕获分组、反向断言和dotAll模式,这些特性在处理字符串时提供了更强大的功能。通过实例解析了如何利用这些新特性进行有效的字符串匹配和处理。
本文详细介绍了JavaScript中Rest参数和Spread运算符在ES6及ES9中的应用,包括如何使用它们处理对象和数组。同时,深入探讨了正则表达式的扩展,如命名捕获分组、反向断言和dotAll模式,这些特性在处理字符串时提供了更强大的功能。通过实例解析了如何利用这些新特性进行有效的字符串匹配和处理。
Rest 参数与spread 扩展运算符
Rest 参数与spread 扩展运算符在ES6中已经引入,不过 ES6中只针对于数组,在ES9中为对象提供了像数组一样的rest参数和扩展运算符.
rest参数
格式:...参数名
一般放在函数的最后一个参数,接收所有传过来的剩下的实参
function connect ({host,port,...user}){
console.log(host)
console.log(port)
console.log(user)
}
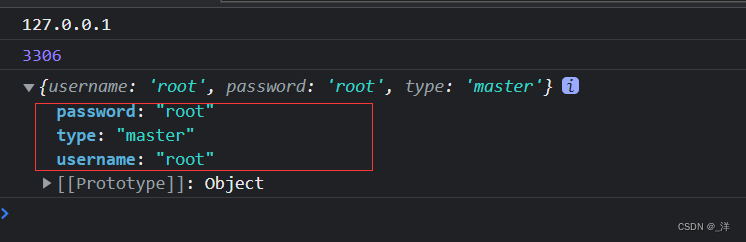
connect({
host:'127.0.0.1',
port:3306,
username:'root',
password:'root',
type:'master'
})
扩展运算符
扩展运算符可以将对象展开形成一个参数序列。(和去掉对象外面的{}效果一样)
const sun={
name:'孙悟空',
// age:18,
}
console.log(...sun)
const zhu={
name:'猪八戒',
// age:20,
}
const sha={
name:'沙和尚',
age:25,
}
const tang ={
name:'唐僧',
age:22
}
const xiyouji = {...sun,...zhu,...sha,...tang}
console.log(xiyouji)
正则扩展
命名捕获分组
即对分组捕获的结果做一个命名,方便我们的处理。
没有命名捕获分组时:
let str ='<a href="http://www.baidu.com">百度</a>'
// 提取url与标签文本
const reg = /<a href="(.*)">(.*)<\/a>/
// 执行
const result = reg.exec(str)
console.log(result)
console.log(result[1])
console.log(result[2])

命名方式 ?<分组名>
eg:
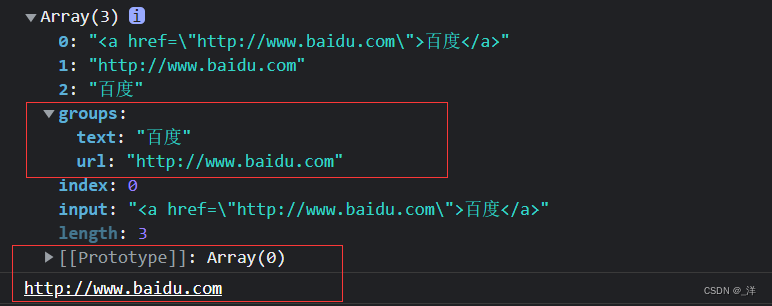
let str ='<a href="http://www.baidu.com">百度</a>'
const reg = /<a href="(?<url>.*)">(?<text>.*)<\/a>/
const result = reg.exec(str)
console.log(result)
console.log(result.groups.url)
console.log(result.groups.text)
反向断言
断言:根据所需提取字符串前面或后面的内容来提取字符串。
- 正向断言:根据提取内容的后面的内容来判断提取的内容是否是合法的。
eg:需求:提取123aa456bb789cc中的789
分析:我们要提取数字,并且数字后面必须是c才能提取到789。
纳闷正则表达式应该是/\d+(?=c)/
?=n表示后面紧跟着n
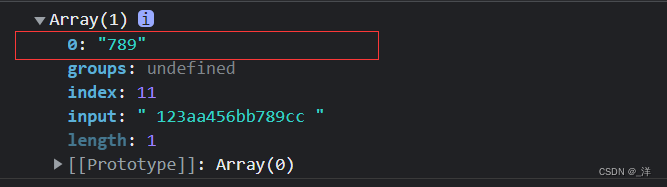
let str =" 123aa456bb789cc ";
const reg = /\d+(?=c)/
const result = reg.exec(str)
console.log(result)
输出:
- 正向断言:根据提取内容的前面的内容来判断提取的内容是否是合法的。
?<=n:表示前面紧跟着n,这是ES9新加的
需求:需求:提取 123aa456bb789cc 中的789
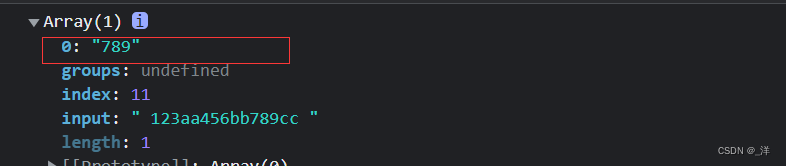
let str =" 123aa456bb789cc ";
const reg = /(?<=b)\d+/
const result = reg.exec(str)
console.log(result)
正则dotAll模式
dot 代表.,.是正则里面的元字符,代表的是除换行符以外的任意单个字符
dotAll代表的是.可以代表任意单个字符包括换行
eg:
需求:提取如下字符串的电影名和上映时间
let str=`
<ul>
<li>
<a>肖生克的救赎</a>
<p>上映时间:1994-09-10</p>
</li>
<li>
<a>阿甘正传</a>
<p>上映时间:1994-07-06</p>
</li>
</ul>
`
- 没有dotAll之前我们提取一个带换行的元素:
let str=`
<ul>
<li>
<a>肖生克的救赎</a>
<p>上映时间:1994-09-10</p>
</li>
<li>
<a>阿甘正传</a>
<p>上映时间:1994-07-06</p>
</li>
</ul>
`
// 遇到一个换行就要写一个\s
const reg = /<li>\s+<a>(.*?)<\/a>\s+<p>(.* ?)<\/p>/
const result = reg.exec(str)
console.log(result)
- 使用dotAll
使用方式:就是在正则表达式后面添加s,此时.可以代表任意单个字符包括换行
这样 两行之间包括空格在内的所有内容就都可以使用.*?表示了
let str=`
<ul>
<li>
<a>肖生克的救赎</a>
<p>上映时间:1994-09-10</p>
</li>
<li>
<a>阿甘正传</a>
<p>上映时间:1994-07-06</p>
</li>
</ul>
`
// 加?禁止贪婪
const reg = /<li>.*?<a>(.*?)<\/a>.*?<p>(.*?)<\/p>/s
const result = reg.exec(str)
console.log(result)
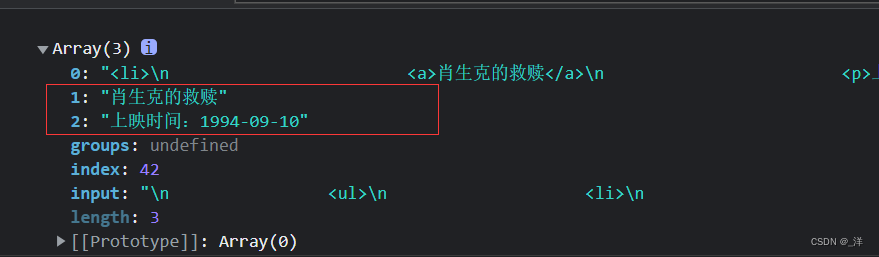
全局匹配:
let str=`
<ul>
<li>
<a>肖生克的救赎</a>
<p>上映时间:1994-09-10</p>
</li>
<li>
<a>阿甘正传</a>
<p>上映时间:1994-07-06</p>
</li>
</ul>
`
// 加?禁止贪婪
const reg = /<li>.*?<a>(.*?)<\/a>.*?<p>(.*?)<\/p>/gs
let result
while(result = reg.exec(str)) {
console.log(result)
}
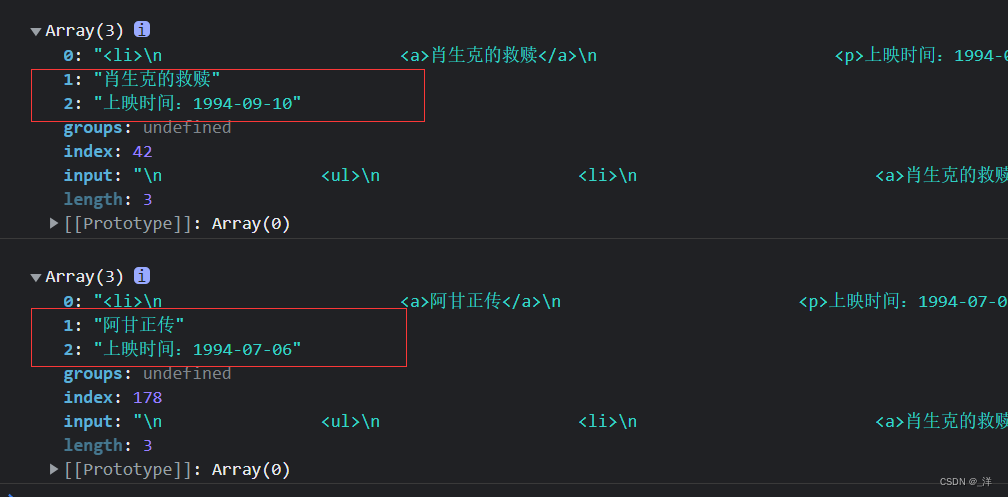
.*?
正则表达式中一般.*后面会加一个?表示禁止贪婪,否则就会一直向后读取。

















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









