




 YOLOv2通过BatchNormalization、HighResolutionClassifier等技术改进YOLOv1的不足,引入Darknet-19基网络加速检测过程,实现更精准、更快、更强的目标检测效果。
YOLOv2通过BatchNormalization、HighResolutionClassifier等技术改进YOLOv1的不足,引入Darknet-19基网络加速检测过程,实现更精准、更快、更强的目标检测效果。
YOLO9000: Better, Faster, Stronger
一、改进点
Yolo_v1相比其他目标检测算法主要的缺点是位置框预测不准确、召回率低。因此Yolo_v2引入了很多新的idea,主要是在保证检测精度的前提下解决这两个问题。主要是分为三个方面:Better、Faster和Stronger。
1、Better
Batch Normalization。
在所有卷积层后加BN层,能加快训练收敛,并防止网络过拟合。MAP提升2%。
High Resolution Classifier
yolo_v1先使用224*224输入训练分类任务后改为448*448输入训练检测任务,yolo_v2直接使用448*448输入训练分类任务。MAP提升4%。
Convolutional With Anchor Boxes.
yolo_v1使用全连接层直接预测bounding box的框坐标及置信读得分,yolo_v2采用anchor box预测bounding box位置及得分。
具体网络结构上的改变:去掉一个max pooling层,增大featue map size(由7*7增大为13*13),为得到奇数大小的feature map size,将网络输入大小由448*448改为416*416。网络整体的stride=32。
对每个anchor box,预测 5+C 个值,C表示C个类别出现在框内预测概率,5 表示anchor box中心点坐标、框高、框长、ground truth box与proposed box的IOU值。
使用anchor box后MAP会有弱微降低,但召回率有明显提升。
Dimension Clusters
使用K-Means聚类训练集中目标框,得到anchor box的初始值,而不是由人为的设置。为兼顾模型复杂度和召回率,实验表明K=5时其每个位置取5个anchor box。
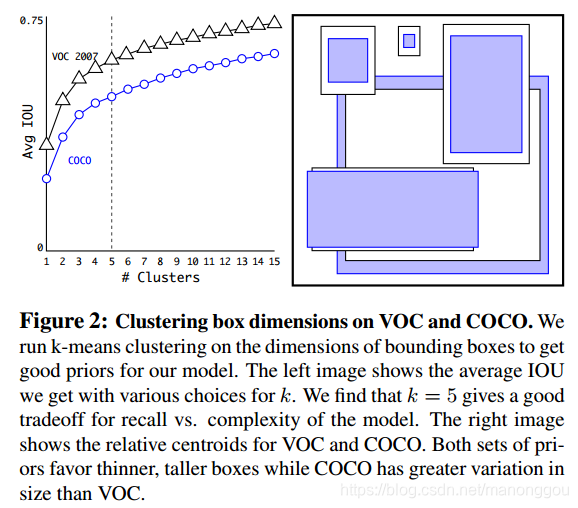
K-means计算框距离使用的指标是bounding box框与中心框的IOU值,这样的指标不受框本身的尺寸大小影响。即:
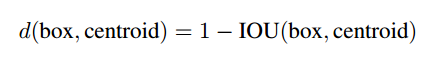
Direct location prediction
在RPN网络预测tx和ty值,anchor box中心点坐标预测值为(文中公式应该有误,把加号写成了减号)
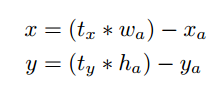
补充:anchor的预测公式来自Faster-RCNN,具体计算公式如下:


计算的坐标偏移量 没有做限定,预测值
和
可以在图像任意位置,很可能偏离了该anchor box原始的像素点(grid cell),导致网络需要经过较长时间才能趋于稳定。在yolo_v2中将anchor box的预测框中心点限定在原始的grid cell中,这是通过使用logistic 函数实现。
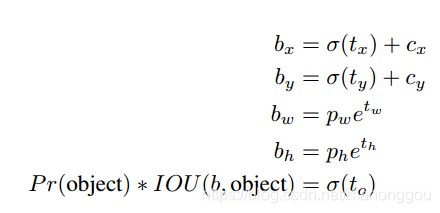
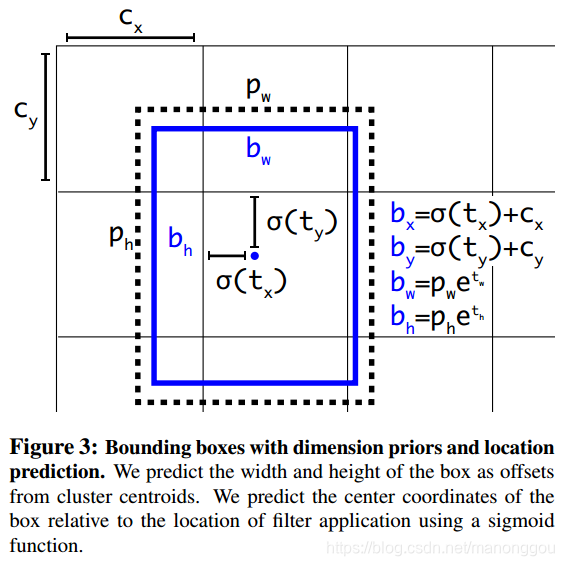
Fine-Grained Features
在yolo_v1中只基于最高层的特征做预测,在本文中引入了特征融合思想,将低层特征(featuren map size:26×26×512)使用类似ResNet模块的分支与最高层特征(featuren map size:13×13×1024)拼接,提取更精确的特征。MAP提升1%。
Multi-Scale Training.
在训练过程中将输入图片resize到不同的大小(32的倍数),文中为{320,352,,,,,608}。每10个batch换一个size。
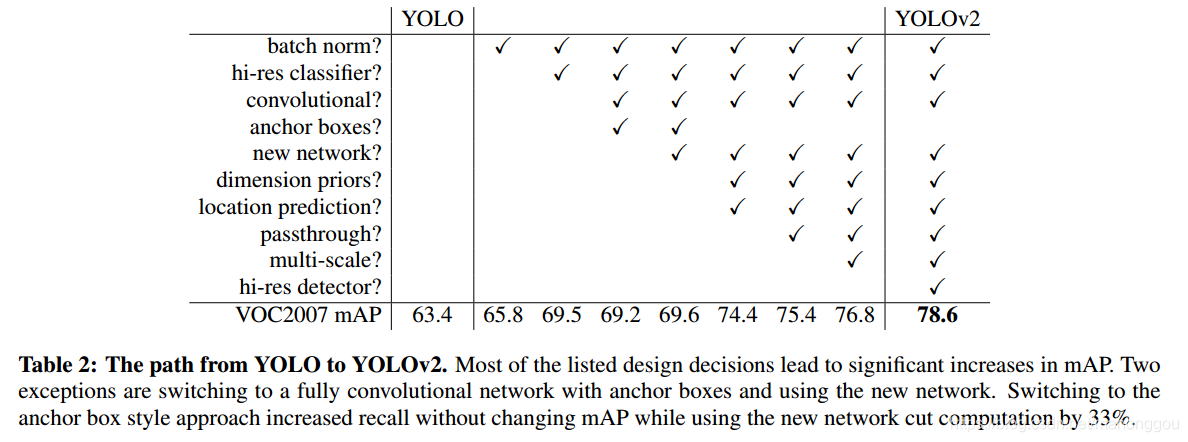
Better 的实验结果
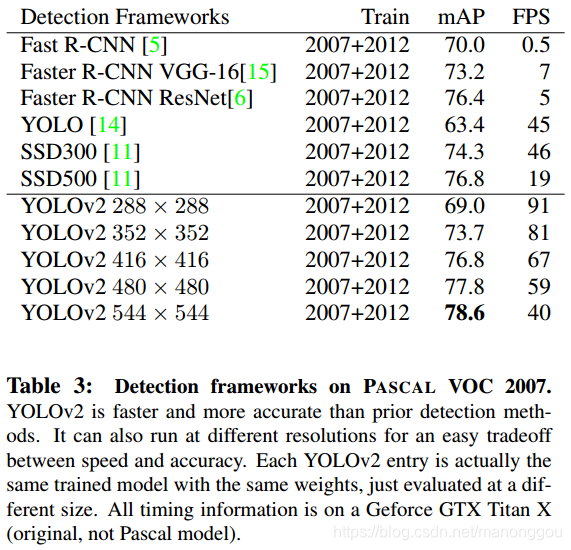
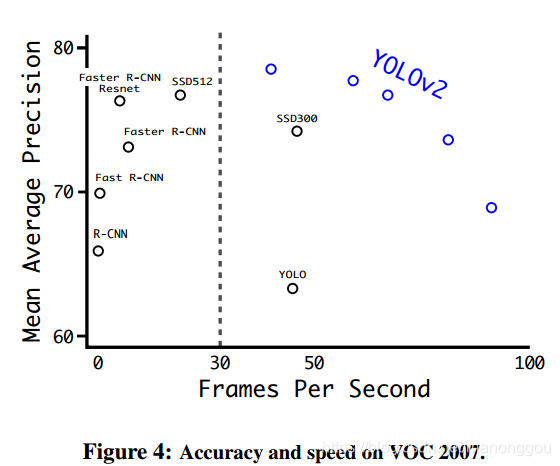
2、Faster
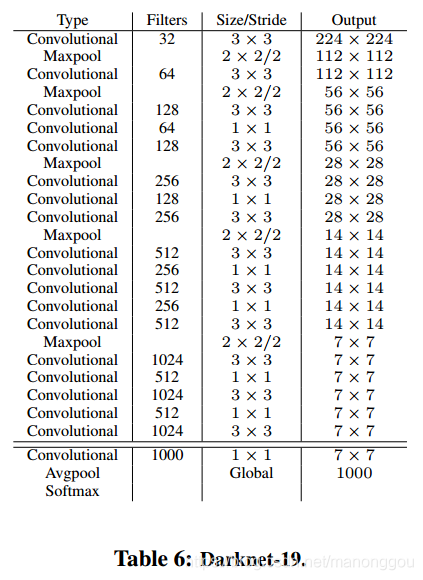
主要是提出一个新的基网络Darknet-19。包含19层卷积和5层maxpooling。在训练检测任务时,去掉最后的卷积层,添加3个3*3*1024卷积及1个1*1*(5*(5+C))的卷积用于得到预测值。并且从最后的3*3*512层引出一个旁路与倒数第二层feature map拼接。
3、Stronger
略


















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









