




 介绍PSENet,一种结合文本实例分割与渐进尺寸扩张算法的场景文本检测方法,有效解决任意形状文本检测难题。
介绍PSENet,一种结合文本实例分割与渐进尺寸扩张算法的场景文本检测方法,有效解决任意形状文本检测难题。
一、背景
场景文本检测一般采用两种方法:
1、基于锚框的回归,缺点是不能定位任意形状的文本,特别是形状弯曲的文本;
2、基于分割,缺点是距离较近的文本不能单独分割开来。

二、网络结构
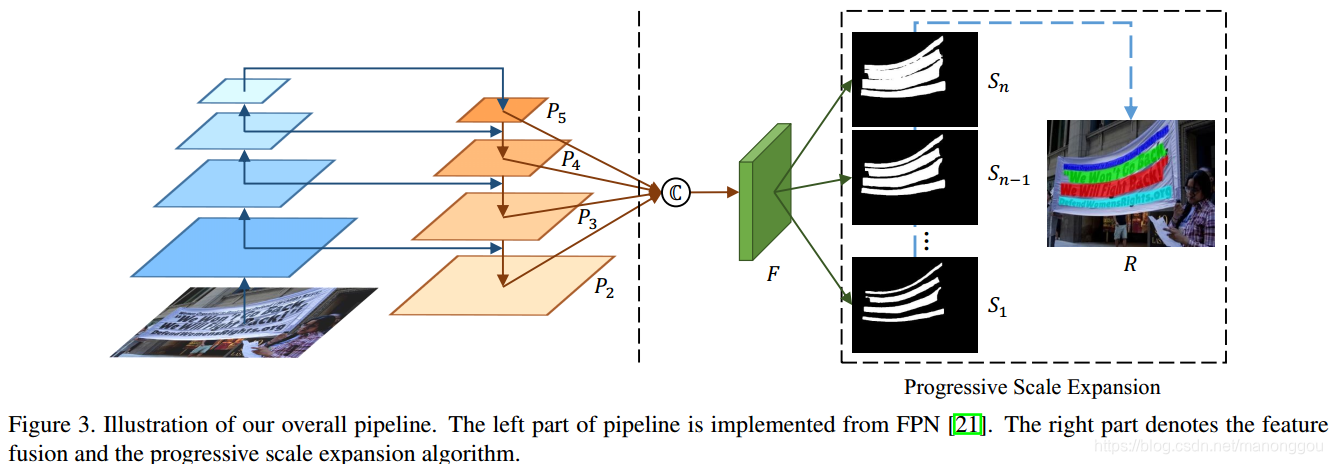
如图所示,网络包括两种步骤:1、文本实例分割 ----> 2、后处理算法PSE
2.1 文本实例分割
基网络采用FPN结构的ResNet,选取feature map {P2、P3、P4、P5},4个不同尺寸的feature map通道数都为256,P3、P4、P5分别上采样2、4、8倍(与P2尺寸一致),P2、P3、P4、P5拼接后接conv_3*3卷积将维为256通道,得到融合后特征F,将F经过n个 conv_1*1卷积 + upsampling + sigmoid 操作得到对应n个分割mask,计为S1、S2、...、Sn。需注意的是S1、S2、...、Sn表示文本实例的不同尺寸分割mask,在论文中简称为“kernel”。同一个文本实例,网络会输出n个"kernel"大小不同的分割mask,即S1、S2、...、Sn(尺寸由小到大)。每个内核与原始的整个文本实例共享相似的形状,并且它们都位于相同的中心点但在比例上不同。
2.2 后处理算法 PSE
为解决相邻文本实例不能单独分割开的问题,引入渐进式尺寸扩张算法用于后处理网络输出的分割mask。
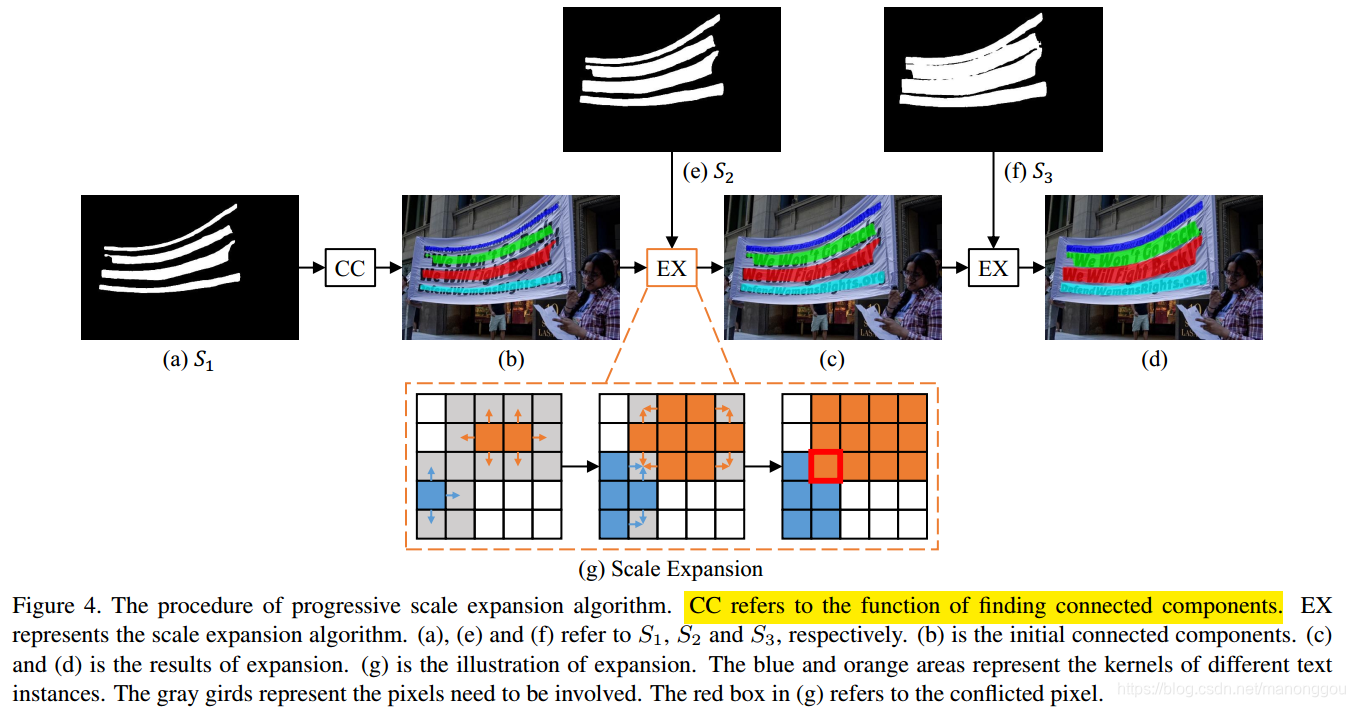
对于预测的n个分割实例S1......Sn ,为了得到最终的检测结果,我们采用了渐进的尺度扩展算法。 它基于广度优先搜索(BFS), 由三个步骤组成:
1、从具有最小尺度的核S1开始(在此步骤中可以区分实例,不同实例有不同的连通域);
2、通过逐步在较大的核中加入更多的像素来扩展它们的区域;
3、完成直到发现最大的核。

三、训练标签生成方法及损失函数
3.1 标签生成
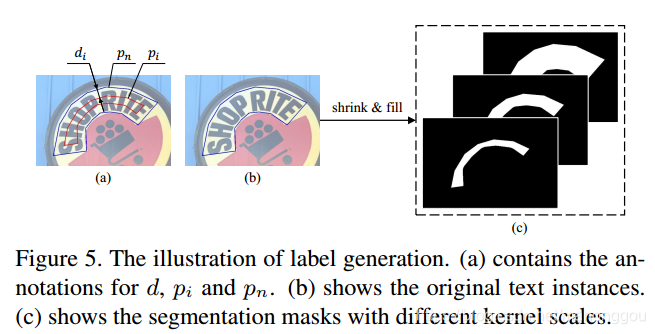
由于PSENet对某一文本实例输出n个不同尺寸的分割mask,训练时需要生成对应的n个不同尺寸的ground truth label map。对应于Sn,ground truth label map为文本实例的原始外轮廓多边形(如下图中pn所示),而S1、S2、...、Sn-1对应的ground truth label map(如下图中pi所示)是在pn上做shrink处理(Vatti clipping algorithm)。ground truth label map都是0/1二值化的分割图。
3.2 损失函数
用到了多任务损失函数:

由于正负样本比例失衡(一般而言文本区域在图片中只占较小的区域),采用交叉熵损失会导致由负样本主导,训练难以收敛,因此训练采用dice coefficient。
四、PSE代码实现
void growing_text_line(vector<Mat> &kernals, vector<vector<int>> &text_line, float min_area) {
// step 1: 先处理最小尺寸的分割图
Mat label_mat;
int label_num = connectedComponents(kernals[kernals.size() - 1], label_mat, 4);// 寻找连通区域
int area[label_num + 1];//统计每个文字块像素的个数即面积
memset(area, 0, sizeof(area));
for (int x = 0; x < label_mat.rows; ++x) {
for (int y = 0; y < label_mat.cols; ++y) {
int label = label_mat.at<int>(x, y);
if (label == 0) continue;
area[label] += 1;
}
}
queue<Point> queue, next_queue;//重要:队列,先进先出
for (int x = 0; x < label_mat.rows; ++x) {
vector<int> row(label_mat.cols);
for (int y = 0; y < label_mat.cols; ++y) {
int label = label_mat.at<int>(x, y);
if (label == 0) continue;
if (area[label] < min_area) continue;
Point point(x, y);
queue.push(point);//重要:队列保存非0位置
row[y] = label;//非0的label保存
}
text_line.emplace_back(row); // text_line: 传出去的text_line先保存了最瘦的那个分割图各个像素label
}
// step1 end:处理完最小尺寸分割图,每个像素标签保存在text_line中,label非0的像素保存在queue队列中
// step2: 开始遍历其他尺寸分割图(kernel),将queue中像素作上下左右的扩展,并判断被扩展出来的像素label
//4邻域
int dx[] = {-1, 1, 0, 0};
int dy[] = {0, 0, -1, 1};
// 从倒数第二个开始,因为是以倒数第一个最瘦的为基础的
for (int kernal_id = kernals.size() - 2; kernal_id >= 0; --kernal_id) {
while (!queue.empty()) {
Point point = queue.front(); queue.pop();
int x = point.x;
int y = point.y;
int label = text_line[x][y];
bool is_edge = true;
for (int d = 0; d < 4; ++d) {
int tmp_x = x + dx[d];
int tmp_y = y + dy[d];
if (tmp_x < 0 || tmp_x >= (int)text_line.size()) continue;
if (tmp_y < 0 || tmp_y >= (int)text_line[1].size()) continue;
if (kernals[kernal_id].at<char>(tmp_x, tmp_y) == 0) continue;
if (text_line[tmp_x][tmp_y] > 0) continue;
// 能够下来的需要满足两个条件: 1. (kernals[kernal_id].at<char>(tmp_x, tmp_y) != 0) 2. (text_line[tmp_x][tmp_y] == 0)
// 即:1. 上一个较大尺寸分割图对应位置上有东西 2. 本位置无东西
// 满足这两个条件就放到队列最后(queue.push(point));,同时把该位置归化为自己的label( text_line[tmp_x][tmp_y] = label;)
Point point(tmp_x, tmp_y);
queue.push(point);
text_line[tmp_x][tmp_y] = label;
is_edge = false;
}
if (is_edge) {//注:当前点都是有东西的 如果当前点任一邻域有东西(文字块内)或者当前点任一邻域对应的上一个分割图位置上没有东西(文字块边界)
next_queue.push(point);
}
}
swap(queue, next_queue);
}
}

















 1642
1642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









