




 CUDA的多流技术允许并发执行主机计算、设备计算和数据拷贝,提高性能。通过创建非默认流,可以实现计算和数据传输的流水线,减少等待时间。在numba中,可以通过设置核函数和数据拷贝的流参数实现多流操作,从而提升大规模向量运算的效率。
CUDA的多流技术允许并发执行主机计算、设备计算和数据拷贝,提高性能。通过创建非默认流,可以实现计算和数据传输的流水线,减少等待时间。在numba中,可以通过设置核函数和数据拷贝的流参数实现多流操作,从而提升大规模向量运算的效率。
numba使用多流
之前我们讨论的并行,都是线程级别的,即CUDA开启多个线程,并行执行核函数内的代码。GPU最多就上千个核心,同一时间只能并行执行上千个任务。当我们处理千万级别的数据,整个大任务无法被GPU一次执行,所有的计算任务需要放在一个队列中,排队顺序执行。CUDA将放入队列顺序执行的一系列操作称为流(Stream)。
由于异构计算的硬件特性,CUDA中以下操作是相互独立的,通过编程,是可以操作他们并发地执行的:
- 主机端上的计算
- 设备端的计算(核函数)
- 数据从主机和设备间相互拷贝
- 数据从设备内拷贝或转移
- 数据从多个GPU设备间拷贝或转移

针对这种互相独立的硬件架构,CUDA使用多流作为一种高并发的方案:把一个大任务中的上述几部分拆分开,放到多个流中,每次只对一部分数据进行拷贝、计算和回写,并把这个流程做成流水线。因为数据拷贝不占用计算资源,计算不占用数据拷贝的总线(Bus)资源,因此计算和数据拷贝完全可以并发执行。如图所示,将数据拷贝和函数计算重叠起来的,形成流水线,能获得非常大的性能提升。实际上,流水线作业的思想被广泛应用于CPU和GPU等计算机芯片设计上,以加速程序。
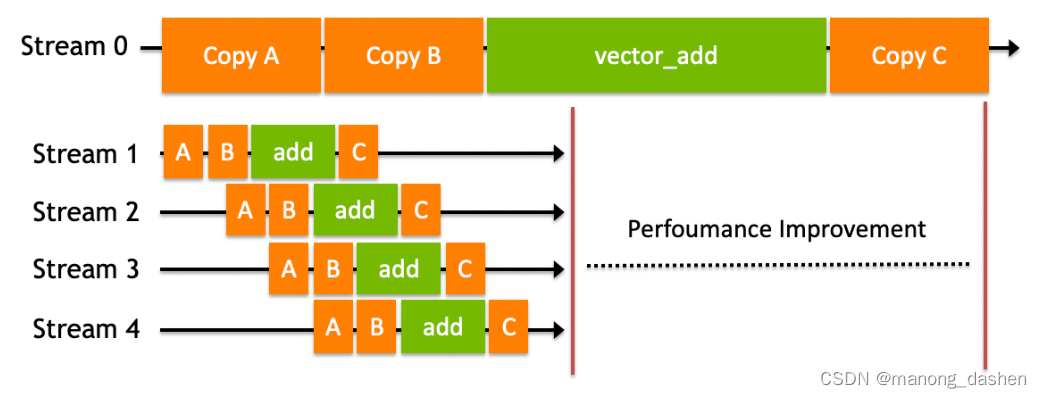
以向量加法为例,上图中第一行的Stream 0部分是我们之前的逻辑,没有使用多流技术,程序的三大步骤是顺序执行的:先从主机拷贝初始化数据到设备(Host To Device);在设备上执行核函数(Kernel);将计
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1942
1942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









