






解析Cobot SCA采用的同源分析技术,深刻剖析其原理,便于我们了解工具背后的技术。
Cobot SCA对代码库中的软件代码提取特征值,特征值的提取分为五个级别,具体包括函数级、类级、文件级、包级和项目级。根据识别粒度的精度选项,系统可以根据不同的特征值算法建立起相应的特征值索引库,这些特征值索引库为同源分析提供源指纹。
采用多特征分级提取技术,如图1所示。根据产品参数设定,可以实现函数级、类级、文件级、包级和项目级等多级别的精确匹配和相似匹配,需要分级提取特征值;为支持精确匹配,需要对代码仓库中的代码在每个级别都进行文本摘要,生成特征值,存储为各个级别的特征值库;为支持相似匹配,若是非代码文件,则在文件级别做模糊哈希并建立指纹库;若是代码文件,则需要拆分为函数/方法,在函数/方法级别进行相似匹配;较高级别的相似匹配结果由低一级别的相似匹配结果汇总得到,汇总时采取归一化匹配算法。
基于建立的分布式存储代码指纹库,代码特征库生成技术从函数、类、文件、包、项目五个方面提取相应级别的特征,提取的特征具有很好的区分性,称为代码指纹。
一、函数级特征提取
在函数级别抽取的特征包括:函数编号、函数代码的摘要值、函数包含的词法标识、函数的抽象语法树的特征向量、函数的程序依赖图的特征向量、对应源文件开始的行号、对应源文件结束的行号、函数描述文本。原始代码会首先经过词法分析器,提取标识符、常量、关键字、运算符等标识单元,然后利用符号表进行规范化处理,以此生成函数级别指纹。
二、类级特征提取
在类级别抽取的特征包括:类编号、类代码的摘要值、类包含的词法标识、类的抽象语法树的特征向量、类的程序依赖图的特征向量、对应源文件开始的行号、对应源文件结束的行号、类描述文本生成类级别的指纹。
第三、文件级特征提取
在文件级别抽取的特征包括:文件编号、文件代码的摘要值、文件包含的词法标识、文件的程序依赖图的特征向量、文件的描述文本。
第四、包级特征提取
包是一个汇总特征,在包级别抽取的特征包括包编号、包下属的文件、类和函数特征,以及包的描述文本。
第五、项目级特征提取
项目也是一个汇总特征,在项目级别抽取的特征包括项目编号、项目下属的包级别的特征,以及项目的描述文本。
函数是代码相似匹配算法的逻辑单元,对函数进行变换,转化为代码的中间表示,进而提取特征值或特征向量,并建立索引库。为了更准确地进行代码的相似匹配,可在词法层、语法层和语义层等三个层次对代码进行分析,提取特征。具体而言,在这三个层次上,源代码的中间表示可以是符号(序列或袋)、抽象语法树(AST)和程序依赖图(PDG)。针对各个不同的代码中间表示需要设计不同的特征提取算法,并和相应的特征匹配算法共同决定特征值的存储、索引形式。
若没有得到精确的匹配,对于非代码文件,利用模糊哈希等手段在文件级别实现相似性检测;对于代码文件,则在函数级别进行相似性检测,即在代码的相似性匹配算法中,函数是逻辑单元。在函数级别的相似性检测过程中,根据语言选择不同的解析器,得到多种代码中间表示,进而在词法、语法和语义等多个层次实现代码近似性检测。在这一过程中,往往会利用索引等技术首先得到特征值相似的备选结果,需要进一步验证得到最终的匹配结果。
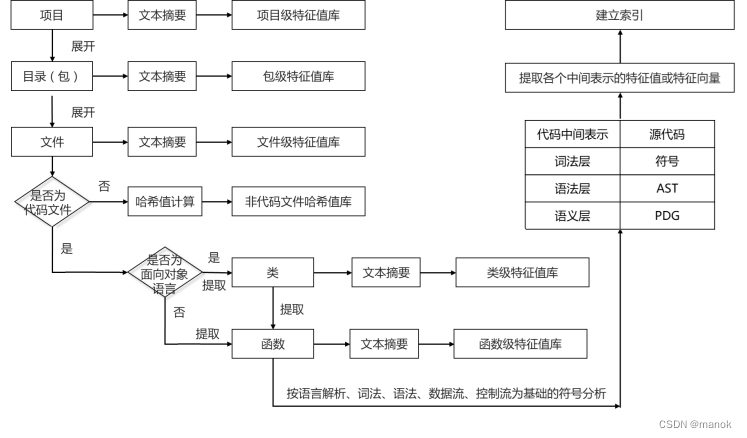
图1:软件成分多特征分级提取
在函数级别的相似性检测完成之后,需要按照从函数级别到项目级别的顺序,逐一汇总。具体地,根据某级别相似性匹配的结果和上一级精确匹配的结果,判定上一级的相似性。特别地,要判定两个包、两个项目、项目和包之间的引用关系,需要先判定所包含文件的相似性,然后再根据如下特征进行分析:文件名数目、相同文件名数目、相似文件名数目、内容相同文件数目、内容相似文件数目等。这里的特征区分代码文件和非代码文件,分别统计。
本项目对开源代码进行分级特征提取,具体包括函数、类、文件、包、项目等五级对象,以及文本、标识、语法、语义等四类特征提取方法。各个级别对象所使用的特征提取方法如表1所示。
其中对应级别对象直接使用的特征提取方法用“√”表示,通过推导方式来提取特征的用“〇”表示,不适用相应级别对象的特征提取方法用“×”表示。如下表所示:
表1:各级别对象的特征提取方法
|
对象 |
文本 |
标识 |
语法 |
语义 |
|
函数 |
× |
√ |
√ |
√ |
|
类 |
× |
〇 |
〇 |
〇 |
|
文件 |
√ |
〇 |
〇 |
〇 |
|
包 |
〇 |
〇 |
〇 |
〇 |
|
项目 |
〇 |
〇 |
〇 |
〇 |
(1)函数级别的特征提取
函数级别的特征通过标识、语法和语义等特征提取方法提取,下面分别描述。
首先通过标识计算函数特征。需要将源代码仓库中的代码片段解析为<符号,频数>的集合并存储。每个代码片段有全局唯一的ID,通过统计所有的符号,生成全局符号频数表。接着利用子块重叠过滤的思想,建立部分索引,具体过程如下:
①设相似度为θ,为平衡精确度和召回率,θ可取70%;
②查询全局符号频数表,将代码片段中的符号按全局频数升序排列;
③设代码片段中总符号数为N,选取前N - θN + 1个符号,建立符号-代码片段的反向索引。
其次通过语法计算函数特征。通过构建源代码函数级别的抽象语法树以及控制流图,构建语法级别的特征向量,并将特征向量存入数据库。抽象语法树上的特征分为树的节点个数、深度以及树的前向遍历顺序等类别,函数控制流图上的特征分为如下两类:
①跳转指令。具体地,本项目将跳转指令分为个数、位置与跳转目标位置三个维度,其中位置和跳转目标位置使用相对位置进行编码,能够较为准确地抽象控制流图中的控制流特征。
②函数调用指令。该特征能够一定程度刻画函数的功能,例如如果仅调用字符串拼接函数,可能执行的是字符串操作功能。基于控制流图中的跳转指令特征和函数调用特征,以函数为单位计算特征值。这一步将特征向量计算为局部敏感的哈希值。
最后通过语义计算函数特征。首先对源代码进行值依赖分析,计算常量值并去除不可达路径,从而将代码进一步归一化,按照值依赖的依赖关系(即依赖图中的指向关系),构建各依赖子图上的特征向量,存入数据库。
(2)类级别的特征提取
如果分析的是面向对象语言的源代码,则类级特征通过函数特征推导得出。同时计算匹配到的函数占类中所有函数的比例,根据阈值决定类级
的推导结果。
(3)文件级别的特征提取
文件级别的特征通过文本特征提取方法提取。具体而言,首先将该项目分解为包和文件,并将包进一步分解为多个文件。文本特征通过MD5的方式求得。
此外,通过类和函数级别的特征推导文件级别的特征。通过计算匹配到的类和函数占文件中所有类与函数的比例,根据阈值决定文件级的推导结果。
(4)包与项目级别的特征提取
包和项目级别的特征通过文件特征推导得出。根据上一级别得到匹配的文件的个数,计算匹配的相似度。根据预设的阈值决定包与项目级别的推导结果。
(结束)
了解Cobot SCA产品更多的信息,可添加微信manokle


















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











