






 本文介绍了一种从wear.tw网站批量下载图片的方法,通过分析网页翻页规律和源代码,提取图片链接并进行批量下载。适用于对图片数据有需求的数据分析师。
本文介绍了一种从wear.tw网站批量下载图片的方法,通过分析网页翻页规律和源代码,提取图片链接并进行批量下载。适用于对图片数据有需求的数据分析师。
BULLSHIT
非“数据科学家”(挺烦别人自称数据科学家的,分析师就分析师,哪来这么多科学家)的我,还得负责数据这块,好辛苦。?
对我来说爬虫是玄学,写起来坎坎坷坷,于是自己想笨办法下载图片数据。
目标网站:wear.tw(很多人分享自己的穿衣)
讲一下思路。
翻页
首先切换到MEN分类下面的能够翻页的页面:
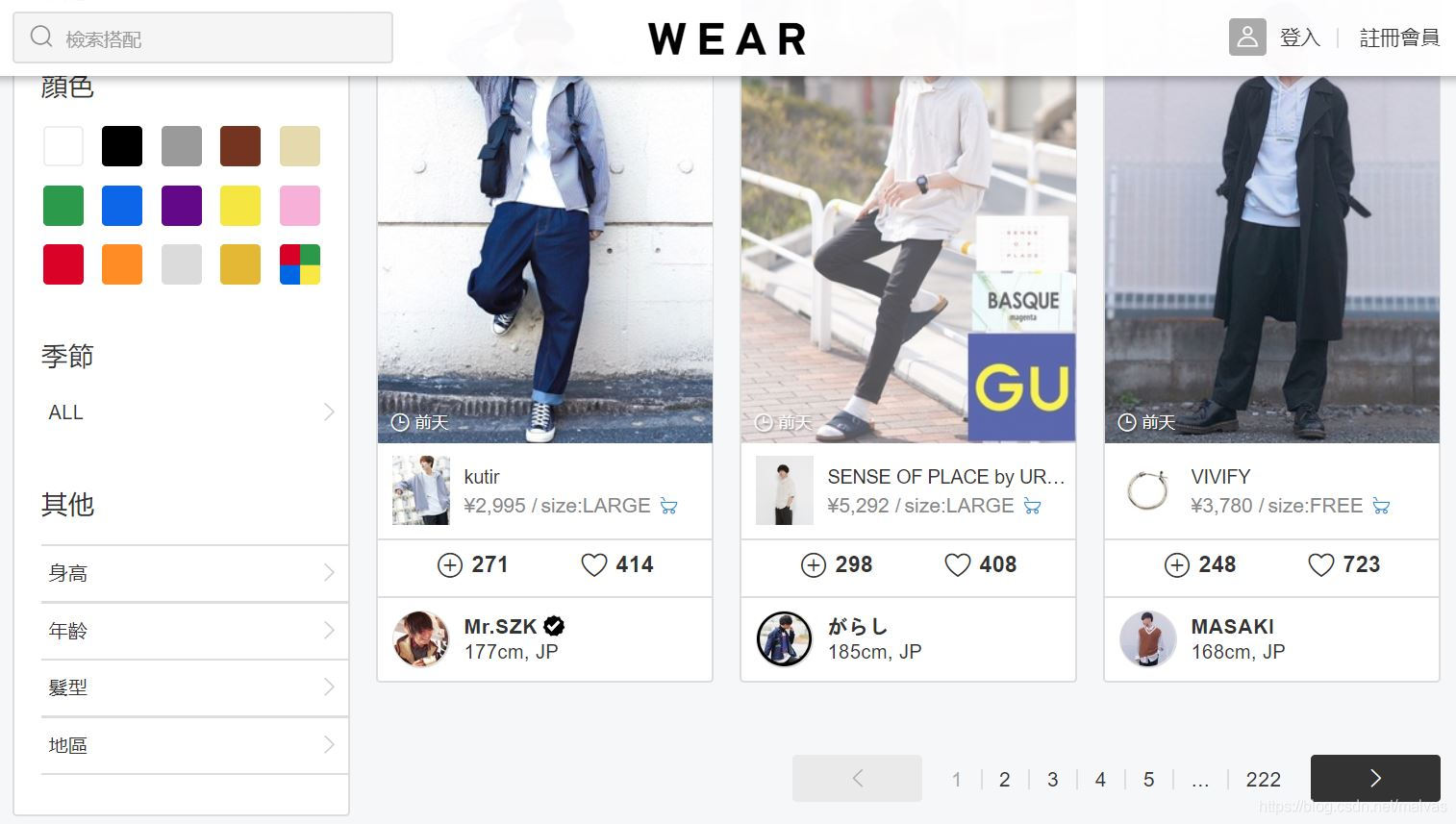
see?最下面有翻页按钮。
翻页试试,盯住浏览器的地址栏,发现页面地址变化规律:
https://wear.tw/men-coordinate/?pageno=1
https://wear.tw/men-coordinate/?pageno=2
https://wear.tw/men-coordinate/?pageno=3
······
ez to find out the law ?
这个规律可以帮助我们在批量获取网页内容的时候做循环。
网页源代码
停留在想要爬取的页面,鼠标右键查看网页源代码,u’ll see things like:

然后我找啊找,心中默念xxxxx.jpg,于是找到了好多嘿嘿:
<p class="img"><img src="/common/img/blank.gif" data-original="//cdn.wimg.jp/coordinate/e4rj3i/20190421084936004/20190421084936004_276.jpg" data-originalRetina="//cdn.wimg.jp/coordinate/e4rj3i/20190421084936004/20190421084936004_500.jpg" alt="Suzu使用「INTER FACTORY(WEARISTA KEI × INTER FACTORY ロングスリーブコーチジャケット)」的時尚穿搭" width="232" height="310"></p>
看到中间的data-originalRetina关键字没?它的值cdn.wimg.jp/coordinate/e4rj3i/20190421084936004/20190421084936004_500.jpg就是我们需要的图片链接。打开链接会出现一张对应的照片:

这样的链接在一个页面里面一共有45个,也就是说每张页面包含45张我们需要的图片。
思路
有了这些信息,获取图片就很简单鸟:
- 做一个网页翻页的循环
- 对每一个页面获取网页源代码,保存所有的网页源代码到一个txt文件
- 对txt文件做特定字符提取,也就是提取我们需要的图片链接
- 批量对所有链接的图片进行下载
代码示例
根据以上思路,我们可以down下很多网站的图片,比如有货:
#encoding=utf-8
import re
import os
import urllib.request
import urllib
from urllib.request import urlretrieve
import sys
import requests
from bs4 import BeautifulSoup
def read_pageHtml(url):# 获取网页源代码
htmlr=requests.get(url)
bsObjHtml=BeautifulSoup(htmlr.text, features="lxml")
return bsObjHtml
imglist = []
c=1
for a in range(1, 336):# 设置网页循环
url = 'https://www.yohobuy.com/list/ci78.html?page='+str(a)# 网址规律
data = read_pageHtml(url).__str__()
rule = r'data-src="(.*?)?image'# 图片链接的提取规则
imglist = re.findall(rule, data)# 查找所有图片链接
for each in imglist:# 对每个图片链接进行下载
try:
urlretrieve('https:'+each, './yh/dp/dp'+str(c)+'.jpg')
c=c+1
except:
pass
hope it helps ?

















 9242
9242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









