







 本文介绍了机器学习在计算机代码问题中的应用,如检测漏洞、修补代码等。阐述了代码向量的必要性及构造方法,涉及降维技术、自动编码器等。还介绍了代码的多种数据源,以及code2vec模型生成代码向量的方式。最后提及SEI中代码向量的应用领域和未来前景。
本文介绍了机器学习在计算机代码问题中的应用,如检测漏洞、修补代码等。阐述了代码向量的必要性及构造方法,涉及降维技术、自动编码器等。还介绍了代码的多种数据源,以及code2vec模型生成代码向量的方式。最后提及SEI中代码向量的应用领域和未来前景。
这篇博文提供了关于计算机代码问题的机器学习(ML)的轻量技术介绍,例如检测源代码中的恶意可执行文件或漏洞。代码向量使ML从业者能够解决以前只有高度专业化的软件工程知识才能解决的代码问题。相反,代码向量可以帮助软件分析师利用一般的,现成的ML工具,而无需成为ML专家。
在这篇文章中,我介绍了ML代码的一些用例。我还解释了为什么代码向量是必要的以及如何构造它们。最后,我将介绍SEI中代码矢量研究的当前和未来挑战。
从代码中学习的代码
这里有一些ML如何从源代码,可执行文件和其他代码表示中学习以对代码进行推断的示例:
-
检测源代码中的漏洞(Russell等,2018 ; Sestili等,2018)
-
修补源代码(Chen et.al.,2018)
-
判断可执行文件的恶意程度(Saxe和Berlin,2015 ; Fleshman et.al。,2019)
-
识别导致程序崩溃的输入或“模糊测试”(Cheng et.al.,2019)
-
自动化逆向工程(Katz et.al.,2019)
-
检测设计模式(Zanoni et.al。,2015)
-
根据源代码命名函数(Alon et.al.,2019)
-
基于自然语言代码描述生成代码(Yin和Neubig,2017 ; Sun等,2019)
这些引用只是上述每个主题快速增长的工作的一小部分。这篇论文提要和这个“令人敬畏的名单”是该领域最新的两个观点。下一节将介绍一些为代码提供支持的技术。
向量,机器学习的货币
通用ML算法,例如线性模型或梯度增强机,要求用户以数字矢量的形式输入每个数据点。这种输入格式意味着我们需要将每个感兴趣的对象表示为数字列表。例如,当使用ML来预测公司收入时,感兴趣的对象是公司,并且可以通过定义公司在前N个月的收入数字的长度为N的向量来开始。
为每个对象定义相关数值数据的难度取决于应用程序。测量初始位置,速度和与风阻相关的一些因素可能足以估计抛射物的着陆位置。但是大多数ML应用程序没有简单的物理规则列表来指示哪些特征是相关的。人类产生的对象,如电影或散文,是独创性和混乱的中间体,本质上抵制了简洁的科学解释。
当科学无法告诉我们哪些特征最相关时,一个自然的策略是尽可能多地生成特征。要为文章创建数字向量,可以计算每个不同的单词和字符,以及所有n-gram和n-skip-gram直到某些n。然而,这种策略导致极长的向量,这在计算上既麻烦又在统计上效率低下。
因此,数据分析中的规范问题是降维,或者如何最好地将大量最小信息特征融合到更少的最大信息特征中。在他1934年的心理测量学经典心灵矢量图(这是该帖的标题)中,路易斯莱昂瑟斯顿收集了长度为60的人格特质向量,并使用因子分析将这个大向量减少到长度为5的较小向量,足以大约恢复原始长度-60矢量。同样,现代的“人格 - 矢量”工具,如Myer-Briggs类型指标,依赖于某种形式的降维来总结一个人对冗长问卷的回答。
直到最近,大多数降维方法(包括因子分析和主成分分析)都是谱嵌入的特殊情况,通过分解所有数据点对之间或所有对之间的距离矩阵或相关性来学习数据集的图形结构。的功能。尽管存在快速近似方法,但是这些方法往往不是可缩放的,并且通常比数据点的数量或特征的数量更差O(n 2)。
20世纪80年代,一个独立的研究领域开始应用神经网络来降低尺寸。虽然它们在特殊情况下近似于光谱嵌入方法,但神经网络方法更容易扩展,无数外来架构用于矢量嵌入。最简单的神经网络嵌入,主要用于教学法,是一个带有单个隐藏层的自动编码器:
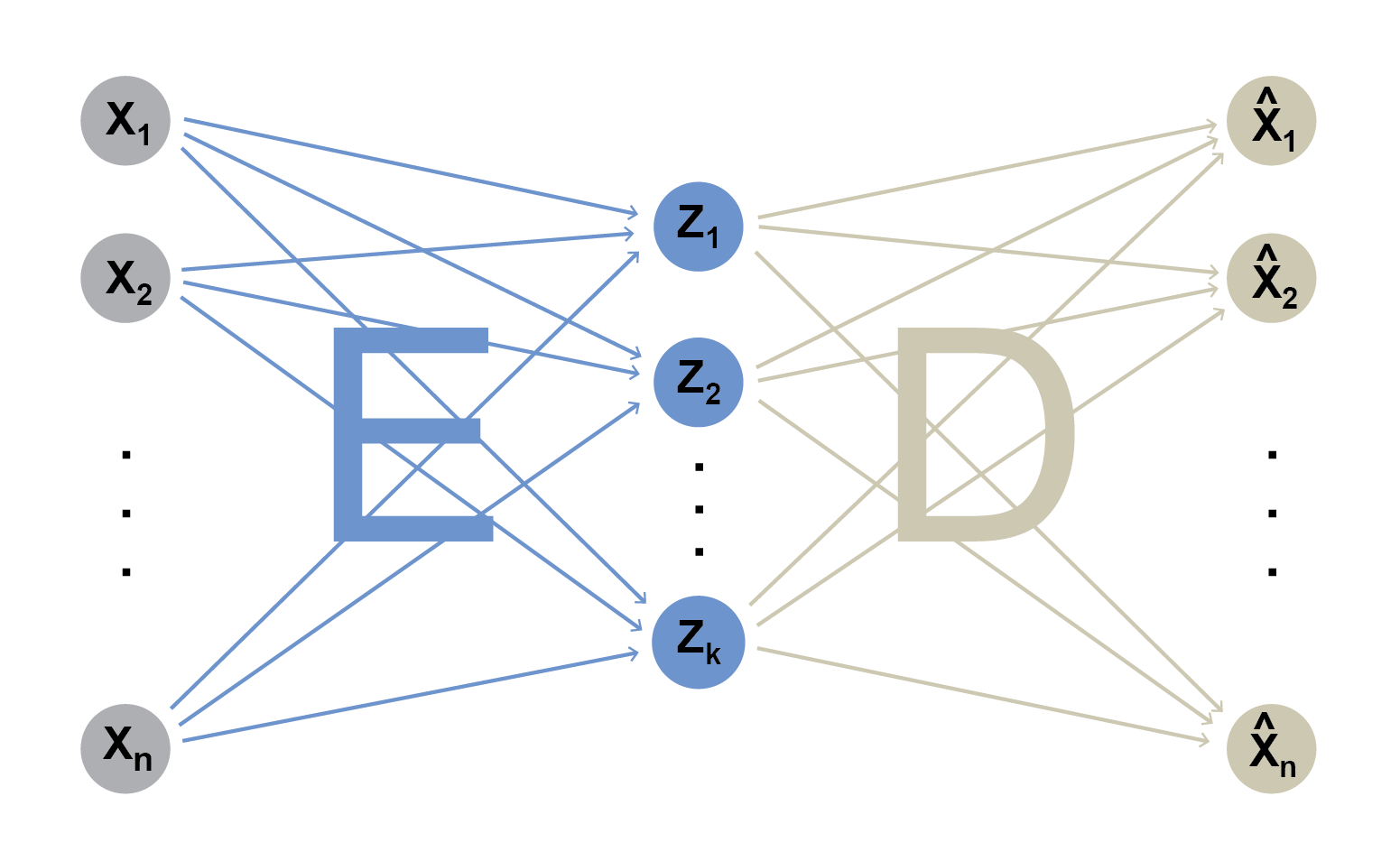
Schematic illustration of an autoencoder.
Given a long raw input vector x=(x1,...,xn)x=(x1,...,xn), the goal of an autoencoder is to produce a much shorter vector z=(z1,...,zk)z=(z1,...,zk) such that the output vector x̂ =(x̂ 1,...,x̂ n)x^=(x^1,...,x^n) is as similar to the input xx as possible. The arrows pointing to each zjzj on the diagram above represent the weights eijeij in the sum zj:=∑ni=1eijxizj:=∑i=1neijxi. Similarly, the arrows on the right represent the weighted sum x̂ i:=∑ki=1dijzjx^i:=∑i=1kdijzj. The weights eijeij can be arranged as an encoding matrix EE and the weights dijdij as a decoding matrix DD such that z=x′Ez=x′E and x̂ =DExx^=DEx. If x̂ ≈xx^≈x, we say that zz successfully encodes xx, since we can approximately reconstruct xx from zz. Gradient descent (included in any deep learning package) on training examples can lead to approximately-optimal encoder and decoder matrices. This simplest autoencoder can be extended to use a nonlinear link function ff as x̂ =Df(Ex)x^=Df(Ex), include additional hidden layers, or vary the network architecture in myriad other ways.
自动编码器的一个缺点是,当天真地应用时,它们无法捕获对象之间的关系。在自然语言处理(NLP)中,通常希望将单词表示为数字向量。假设语料库包含100,000个唯一单词的词汇表。如果“hello”是词汇表中的第i个单词,那就是热门词汇“hello”的向量是长度为100,000的向量[0,...,0,1,0,...,0],其中“1”位于向量的第i个位置,所有其他条目为0这种向量表示除了非常稀疏之外,没有提供关于单词之间关系的信息。试图用自动编码器减少这些长向量的维数是没有用的; 也许这种自动编码器唯一能编码的是关于k个最常用词的相对频率。
具有里程碑意义的word2vec论文(Mikolov et.al.,2012)引入了第一个以捕捉关系的方式嵌入单词的架构之一]:

Skip-gram模型架构。资料来源:Mikolov等人的单词和短语的分布式表示及其组合性。al。,2012。
这里输入(左)是单热字矢量wŤw ^Ť通过编码层(中心),而不是训练编码器恢复wŤw ^Ť(在右侧,输出侧),目标是恢复w的最近邻居Ťw ^Ť在语料库中出现的训练句子中所有单词用法的实例。这个看似简单的架构,在数十亿个单词实例上训练,足以创建信息量很大的单词向量,只需要50个元素(与单热矢量相比,长度减少了一千倍)。
使用编码器 - 解码器神经网络嵌入单词(或其他对象)的一般策略是生成代码向量的肥沃基础。下一节将确定用于生成此类向量的一些潜在数据输入。
代码的东西
代码是众所周知的古怪。具有相同行为的两个脚本可能看起来非常不同。相反,两个看起来非常相似的脚本可以以截然不同的方式运行。脚本的行为甚至可以取决于运行它的操作系统或编译它时设置的精确标志。
这些类型的问题并不完全是代码所特有的。代码的ML大量借用NLP,其中一些相同的问题以类似的形式存在。源代码和自然语言之间最明确的联系之一是它们的分段层次结构:
|
| 分割层次 |
| 自然语言 | 字符→单词→句子→段落→文档→语料库 |
| 源代码 | character→token→line / statement→method→class / file→repository |
但是,源代码在重要方面与自然语言不同。对于自然语言,word2vec运作良好,部分原因是密切相关的单词通常位于一起。对于源代码来说,这不太正确,因为编码语言的语法更容易决定相距很远的令牌之间的强关系。例如,长度功能上的开口支架与闭合支架的连接非常牢固,即使支架丢失,功能也完全不可编,即使支架相距数百行也是如此。
与自然语言不同,自然语言至少可以用最少的语法知识进行弱理解,实现对代码的部分理解需要至少完全理解其语法。例如,这是python语法。语法是生产规则的列表。只有两条规则的玩具语法说明了这个概念:
-
S→SS
-
S→Sa
以任意顺序重复应用规则会导致形式为“S ... Sa .... a”的字符串,并且任何这样的字符串都是由语法规则“有效”的。类似地,根据一些训练的概率模型迭代地应用编码语言的语法规则是产生概念上合理的合成代码的一种方式,该合成代码也保证编译。
当我们想到代码时,源代码和语法可能是第一个想到的东西,但是ML有更多的东西要看。
-
一些自然语言源提供了有关代码的期望含义和行为的线索:变量名称,代码文档,问答论坛,问题跟踪器和版本控制注释。
-
版本控制系统提供存储库的编辑历史记录。对数据源进行建模可能是在代码开发中实现机器与人类合作的关键(语法突出显示和基本代码完成是一个值得尊敬的开端)。尹等人 人。(2018)介绍了这样的模型。
-
编译通过一系列编译表示推送源代码。每个表示都为代码结构提供了一个独特的窗口:
-
-
扩展源代码,基于执行宏替换
-
所述抽象语法树(AST) ,它解释的源代码在其语法方面,很像句子图表用于代码
-
中间表示(IR),编译器从AST作为其自动代码优化的一部分派生的各种文本表示
-
汇编语言
-
二进制可执行文件
-
-
静态程序分析产生几种类型的代码功能:
-
-
警告潜在的代码缺陷
-
像cppdepend这样的工具可以计算可解释的代码度量,例如函数中的行数
-
像SciTools Understanding这样的工具可以生成(代码实体,关系,代码实体)元组的实例列表,例如(公共方法,定义,变量)。类似地,控制流图(CFG)或程序依赖图(PDG)以更细粒度的级别表征代码中的关系。
-
-
动态程序分析执行代码并收集有关代码运行时发生的各种类型的数据。
-
源代码元数据,包括项目试图遵循的约定(超出代码语法)。例如,许多Java项目遵循Spring Model-View-Controller框架,该框架限制了某些类组之间发生的交互类型。
据我们所知,没有任何已发表的作品试图同时对几乎所有这些数据源进行建模。但是,一些模型已经开始包含多个来源。例如,Sun等。人。(2018)将部分AST,语法规则,功能范围和自然语言程序描述融合为单个神经网络的输入。
现在我们已经看到了代码的构成,我们可以准确地询问我们希望代码向量表示的实体是什么。可以根据分段级别(可能导致每个方法或每个文件的向量)或者根据编译流水线的阶段(可能导致每个AST或每个可执行文件的向量)来指定代码实体。下一节将重点介绍为某些代码实体训练矢量表示的模型。
隐藏层中隐藏的潜力
Chen和Monperrus(2019)回顾了几十种最近生成代码向量的方法。其中之一是code2vec。(尽管它的名称和强大的表现,但code2vec既不是生成代码向量的第一个例子,也不是理解现有技术的唯一来源。)
Code2vec仅从代码中的许多数据源中抽取两个。它使用每种方法的名称(如源代码中所示)作为监督学习模型中的训练标签。模型的输入来自每个方法的抽象语法树(AST)的随机采样路径:
-
AST的叶子引用标记(例如,源代码中出现的单词/运算符/命令)。训练语料库上的令牌集确定令牌词汇表。
-
最短的路径(不包括叶子)连接AST的每对叶子。训练语料库中的一组唯一路径确定路径词汇。
-
甲路径上下文的形式(叶1,连接路径,叶2)的元组。
-
AST中的路径上下文的数量是O(n ^ 2),其中n是叶子的数量,其在各种方法之间变化很大。例如,随机抽样,这些上下文路径中的200个为模型提供恒定长度的输入。
code2vec模型使用AST来预测每个方法的名称。以下是code2vec文件中提供的神经架构的快照:
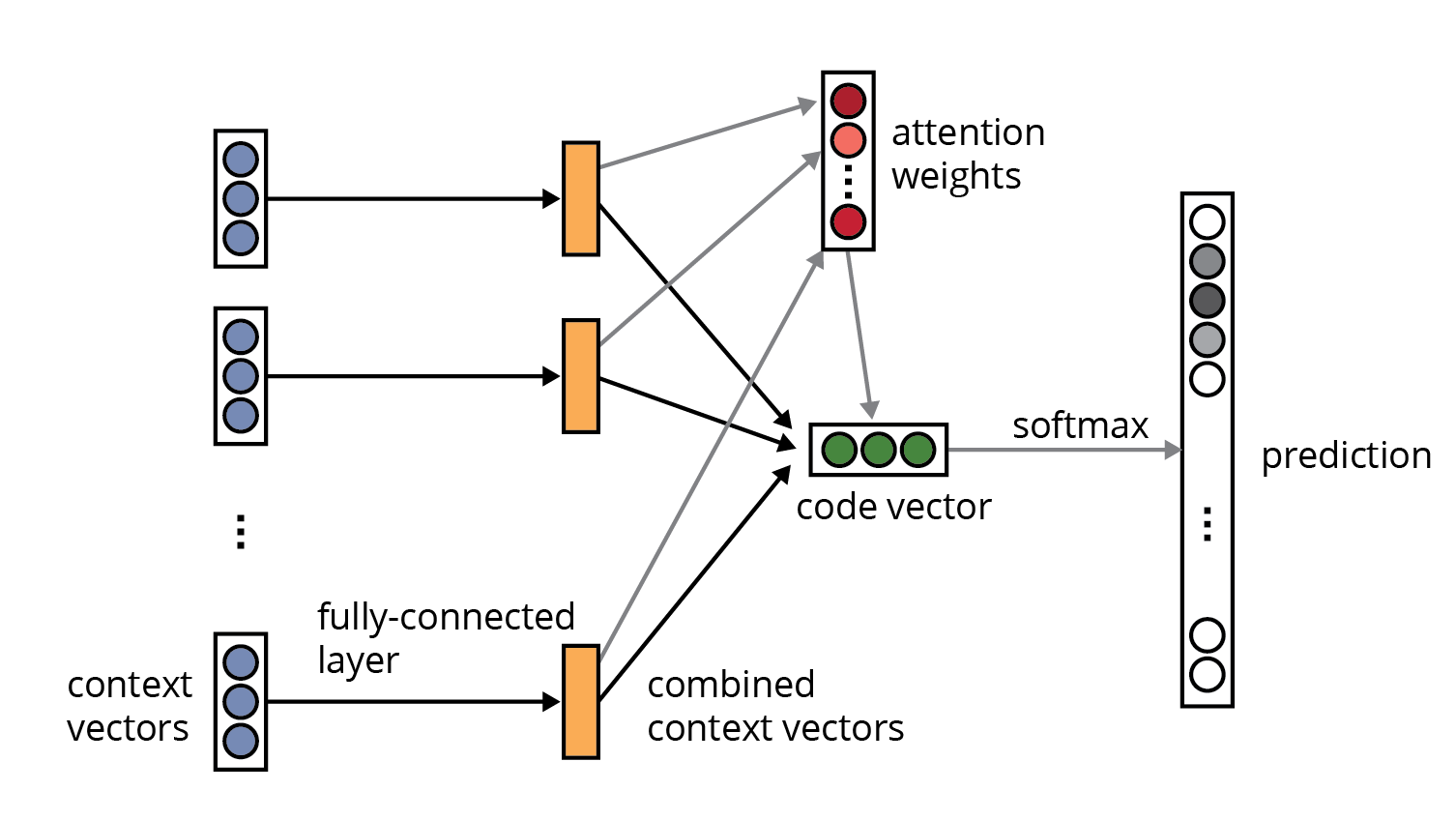
code2vec的神经网络架构。资料来源:code2vec: Alon et。的学习分布式代码表示。al。,2018。
这个网络起初看起来令人生畏,但就我上面提到的自动编码器示例来说,这是很容易理解的。具体地,图的入口节点中的每个蓝色圆圈表示编码矩阵的应用(例如自动编码器中的“E”)。code2vec中有两个独立的编码器,一个用于令牌词汇表(行数与训练语料库中的不同令牌一样多,大约数万个),一个用于路径词汇表。更具体地,如果“foo”是路径上下文节点,则对应于令牌词汇表中的foo的索引的令牌编码矩阵的行表示foo的向量编码。我们同样获得另一个标记的向量和包含foo的路径上下文中的路径,产生3个编码的串联(即
网络的其余部分是相当通用的神经架构组件的拼凑而成,包括标准激活功能,密集连接层和注意机制。softmax输出层产生先前在训练语料库中遇到的方法名称的概率分布。
在向网络输入代码方法之后,该方法的“代码矢量”是最后隐藏层(绿色)的激活值。但我们也可以将注意力权重向量作为自己写入的代码向量。通常,用于读取代码向量的网络的哪个部分的选择不是先验的并且依赖于实验或直觉。
一个预训练的模型,如code2vec甚至什么都没有做预测方法名ML问题是潜在有用的。给定一个新方法和一个AST解析器,可以将方法的上下文路径的样本输入到预训练模型,并从指定的隐藏层中提取代码矢量。然后,代码矢量可以作为用于新预测任务的通用ML算法中的预测特征,通过消除构建和训练高度定制的任务特定神经网络的需要而节省大量分析员的努力。
如上定义的代码向量并不总是对于任意预测任务最有用的特征,但是一般方法具有很大的前景。下一部分以一些应用领域结束,其中代码向量在SEI中获得相关性。
SEI的代码向量
SEI的几个工作领域可能很快会受益于代码矢量方法的应用。这些包括检测技术债务工件,代码修复,检测静态分析警报中的误报,以及从编译的可执行文件中反向设计源代码,以及许多其他应用程序。
SEI在代码上使用ML才刚刚开始。目前可用的模型包含一小部分代码。未来的模型能够智能地融合来自越来越多样化的代码层的代码向量,这肯定会导致ML在代码应用中取得前所未有的成功。
其他参考

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









