








如果我们有些功能要给别人用,但是又不想公开代码实现,比如高德地图、第三方登录分享等等,这时候我们就要打包成库了。库分静态库和动态库两种:
静态库:以
.a和.framework为文件后缀名。
动态库:以.tbd(之前叫.dylib) 和.framework为文件后缀名。
静态库与动态库的区别
静态库:链接时会被完整的复制到可执行文件中,被多次使用就有多份拷贝。
动态库:链接时不复制,程序运行时由系统动态加载到内存,系统只加载一次,多个程序共用(如系统的UIKit.framework等),节省内存。但是苹果不让使用自己的动态库,否则审核就无法通过。
我们先来看一下iOS设备有哪些架构,因为下面要用到:
模拟器:
iPhone4s-iPnone5:i386
iPhone5s-iPhone7 Plus:x86_64真机:
iPhone3gs-iPhone4s:armv7
iPhone5-iPhone5c:armv7s
iPhone5s-iPhone7 Plus:arm64支持armv7的静态库可以在armv7s上正常运行。
.a静态库的制作
1、先创建一个新的Xcode工程Test,需要选择下面这个模板:
创建完成后是这个样子的:
2、我们把默认生成的Test.h和Test.m删掉,重新创建一个类PrintString,在这个类里面添加一个单纯打印字符串的简单方法:
3、选择添加公开头文件
为了让使用者知道有哪些方法可以用,我们需要公开头文件,这里我们公开PrintString.h:
4、修改配置Build Active Architecture Only
我们需要把Build Active Architecture Only修改为NO,否则生成的静态库就只支持当前选择设备的架构。
6、然后编译
我们分别选择Generic iOS Device和任意一个模拟器各编译一次,编译完后,我们会看到工程中Products文件夹下的libTest.a由红色变成了黑色,然后show in finder,看看生成的文件:
我们看到它为真机和模拟器都生成了.a静态库。里面都包含我们选择公开的头文件。
7. 我们来看看静态库支持的框架:命令为lipo -info 静态库名字
Debug-iphoneos里面的静态库支持的架构有armv7和arm64所以它只能用于真机,在模拟器上会报错。Debug-iphonesimulator里面的静态库支持的架构有i386和x86_64,所以它只能用于模拟器,在真机上会报错。
8.如果lipo -info 没有查看查看到一些架构, 就在Architectures中添加,如下图

9. 如果想要让模拟器和真机通用一个静态库,我们可以使用终端命令来实现。命令格式:lipo -create 第一个.a文件的绝对路径 第二个.a文件的绝对路径 -output 最终的.a文件路径:
libTest.a文件。这个静态库就支持所有模拟器和所有真机了。然后我们创建一个文件夹,把.a和头文件都放进去,我们最终需要使用的就是这个文件夹:注意:为了开发方便,我们可以使用生成的通用静态库,但是最终上线的使用我们可以只导入真机的,这样工程的体积也会小一些。
使用生成的.a静态库
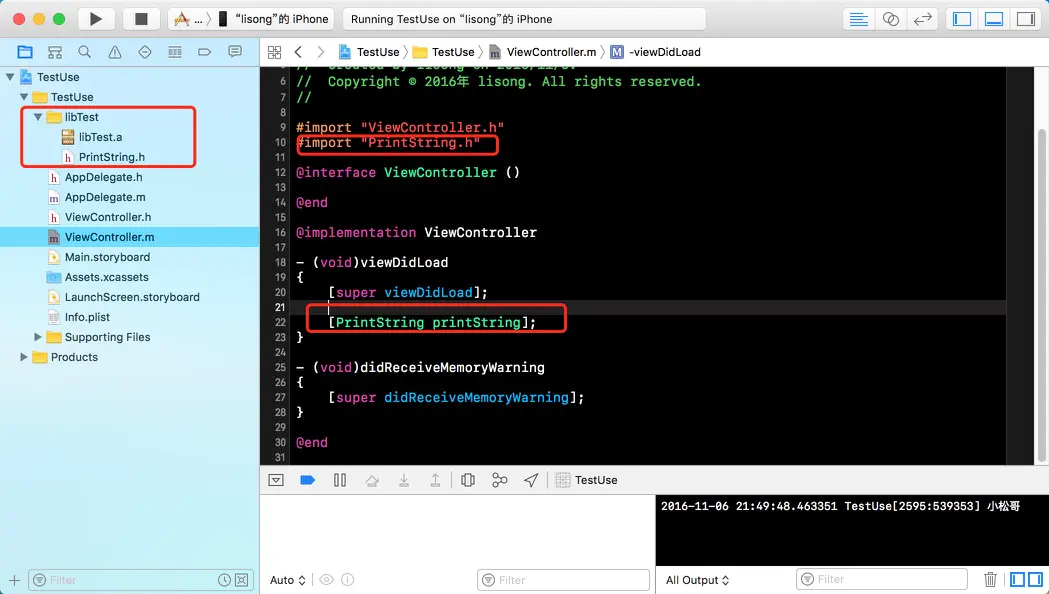
新建一个工程,将上面的通用静态库拖进去,导入头文件,就可以使用里面的方法了。经过试验,我们生成的静态库在真机上和模拟器上都能成功打印字符串:

















 2149
2149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









