






参考资料:农作物品种试验数据管理和分析
1、单点试验数据分析的目的和步骤
通过多年多点的品种试验,才能对优良品种进行可靠的鉴别和选择,而点单试验数据对品种评价的能力有限。但是,多年多点数据的有效性又是以单点试验的数据为基础。所以,单点试验数据分析是品种试验数据分析的重要组成部分。
品种试验数据分析究竟采用一步法还是两步法是有争议的。一步分析策略就是一步完成多环境试验数据的分析,而两步分析策略是先分析单个实验,再对所有环境进行联合分析。但两步策略与一步法相比的优点是更容易操作,需要的计算强度和时间较少,同时让研究人员有机会实时检查和矫正数据中可能存在的人为错误。
单点试验数据分析的主要目的并不是给参试基因型得出最后的结论,而是对试验数据进行质量控制,包括对可能存在人为误差和田间空间变异进行检查和纠正。
单点试验数据分析的步骤包括:①对数据进行方差分析,以确定试验的数据质量;②检查和纠正任何人为误差;③检查和纠正由田间空间变异引起的误差。
2、品种试验的鉴别力和精确度
检查试验数据质量的一个简单方法就是先对实验记载性状逐个进行方差分析。下图是2012年加拿大安大略省渥太华试点32个燕麦品种籽粒产量示范数据的方差分析结果。
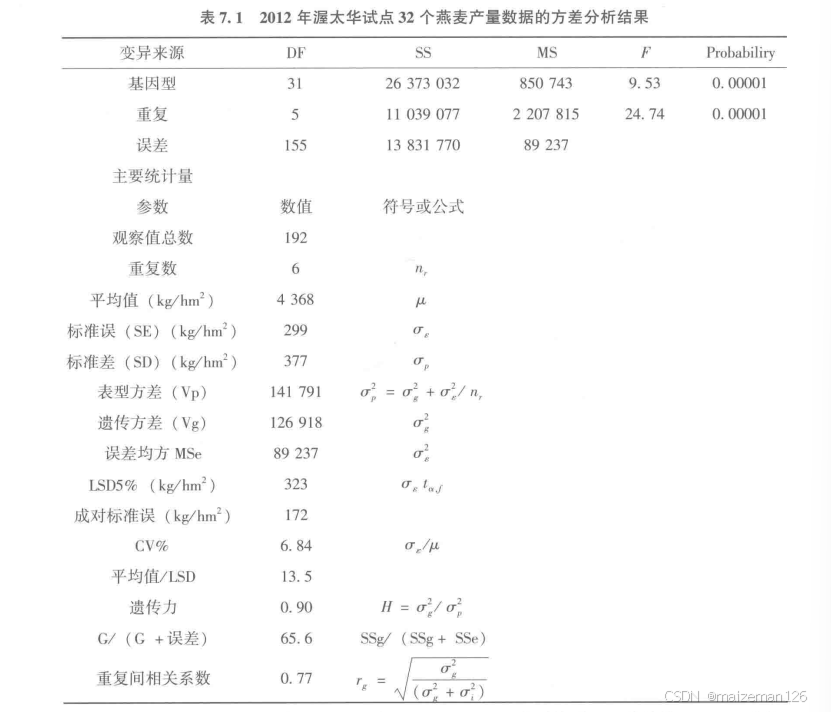
上表中的第一部分为方差分析报告的常规内容,包括各变异来源的自由度(DF)、平方和(SS)、均方(MS)、F值及其显著概率水平。试验采用完全随机区组设计,共32个品种、6个区组(重复)。因此,试验共有3个变异来源:基因型、重复(区组)和随机误差。这里的数据分析主要是检验基因型效应的显著性。结果显示基因型效应极显著。
表中下部列出了试验数据的主要统计量,包括观察值数、重复数、试验平均值、标准误差(SE)、标准差(SD)、5%水平的最小显著差异(LSD5%)、两两比较的标准误、变异系数(CV%)、平均值与LSD5%比率、遗传力(H)、G/(G+误差)的平方和比率,以及重复间的相关系数r_g。
通常检测试验数据质量的参数包括:(1)基因型效应的F值及其相应的显著概率水平;(2)遗传力;(3)变异系数。这些参数通过误差方差相互关联。
基因型效应的F值()是遗传方差(
)对误差方差(
)的相对值,计算如下:
由上式可见,只要遗传方差不等于0,F值就总是大于1,而且F值越大表示基因型效应越显著。
遗传力包含了与F值同样的信息,只是用另一种方法表达遗传方差对误差方差的相对大小:
由此式可见,只要误差方差不为0,H值总是小于0 。H值比F值更加直观,因为其取值范围总是在0和1之间。F值虽然可能是任何大于1的数值,但有与其对应的概率水平,可作为其不确定性的度量。高H值和F值得试验可以更有效地揭示试验基因型间的差异,因而含有关于品种间差别的更多信息量(或鉴别力)。反之,那些低H值和F值不显著的试验不能鉴别基因型间的差异,因而是无用的。
试验标准误(SE)合一衡量试验的精度。但是,即使试验精度很好,仍可能会出现低H值和F值不显著的问题。例如,当试验的所有基因型在遗传上一样时。当然这种情况极罕见。这种情况下,即使SE很低(表示试验精度高),期望遗传方差也将是0,而期望的H和F将分别为0和1.
试验标准误(SE)不是一个关于试验精确度的直观指标。CV是更通用的试验精确度指标,由SE与试验均值的比值确定:
简而言之,H(或F)体现试验对基因型的鉴别力,而CV表示试验的精确度。H和CV是检验实验数据质量的互作方法,彼此通过SE相互关联,但又各具独立性。可见理解CV和H值之间的关系是很重要的。
在实践中,CV比H更常用于评判试验质量,而H很少受到品种试验人员的关注。加拿大安大略麦类作物委员会(OCCC)将籽粒产量的CV小于16%的试验视为有效试验;CV超标的试验视为不合格试验,在多点试验汇总时将被剔除,而H并没有用于评价试验数据质量。
这样的做法显然是不完善的。如果试验的H值较高或G值在统计上显著,即使CV值较高,其在品种评价上仍然是有应用价值的。标准误SE较高,或平均值低都可以导致CV值偏高,而遗传方法高或误差方差小都会导致H值较高。CV值较高的试验,只要其H值高就可以揭示遗传方差,因而仍然是有价值的。对于给定的一组基因型,试验实施质量好的情况下应当具有较高的H值和低CV值,而实施质量差的试验应当具有低H值和高CV值。当H值低或CV值高是,试验数据的质量就可能存在疑问,应当采取措施检查和纠正可能存在的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









