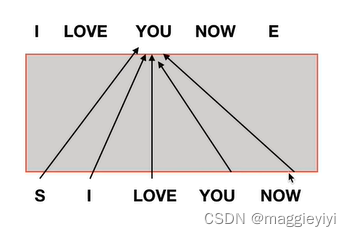
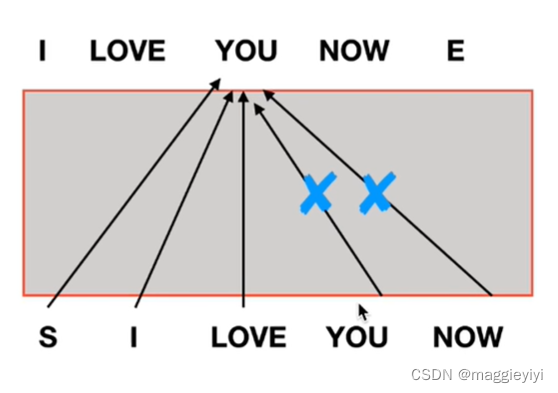
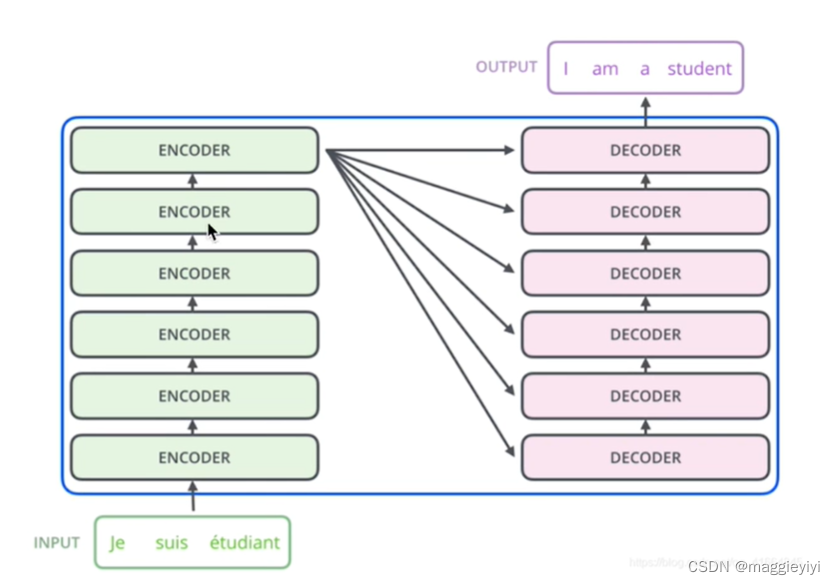
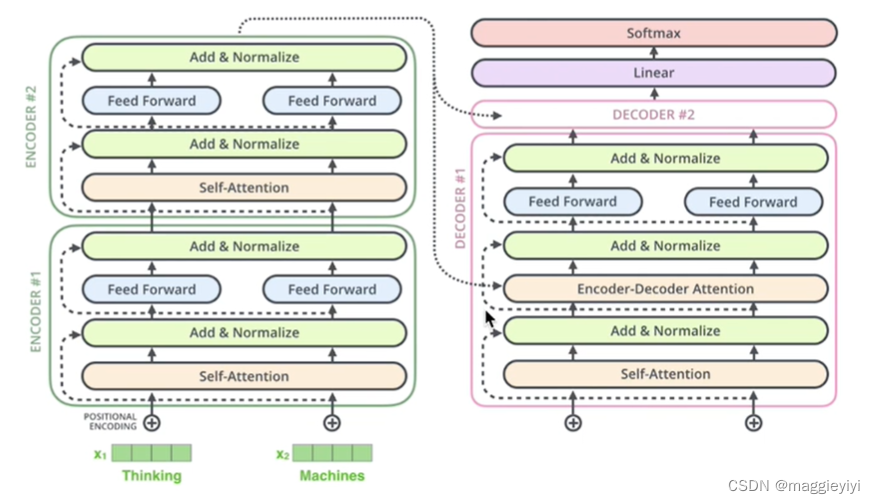
目录 1 多头注意力机制 1.1 mask 2 交互层 1 多头注意力机制 1.1 mask ques:为什么需要mask? ans:如果没有mask,那么在训练的时候存在you和know。如下图,但是在测试的时候,没有mask,会出现误差,模型效果不好。 需要mask 如图: 训练的时候将you和know mask掉,保证一致性。 2 交互层 所有的encoder输出和每一个decoder去做交互。 具体交互如下: encoder生成K、V矩阵;decoder提高Q矩阵,即多有注意力机制计算K、Q、K的值。公式如下:








 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 本文主要介绍了多头注意力机制在训练过程中的应用及其重要性,特别是mask的作用,以确保模型训练与测试的一致性。此外,还详细阐述了交互层的工作原理,包括encoder和decoder之间的具体交互方式。
本文主要介绍了多头注意力机制在训练过程中的应用及其重要性,特别是mask的作用,以确保模型训练与测试的一致性。此外,还详细阐述了交互层的工作原理,包括encoder和decoder之间的具体交互方式。

















 9189
9189





