




背景
上次说道小H利用python语法和外部api调用完成了一个简单的ReAct Agent搭建,但是感觉好麻烦啊,如果都是自己写的话,是不是应该有什么成型的框架能够省略这些繁琐的构建过程呢?
这时候同学给他推荐了一个LangGraph的框架,那么就一起来试试吧!
概念
LangGraph 的核心思想是:将复杂的AI交互建模为有向图(Graph),每个节点代表一个处理步骤,边代表执行流程。
利用成型的框架,我们可以快速搭建出一个有向图,此处的目标还是完成一个chatbot,同时给出一个搜索引擎的工具。
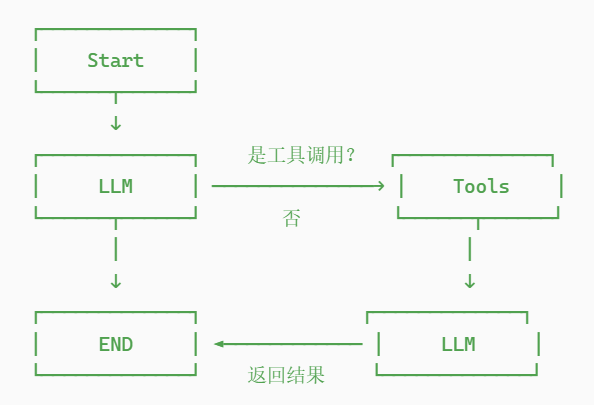
(流程图有一点错误,否应该直接走向END)
基本组件
State(状态)
State状态是我们这个流程的核心,他囊括了当前节点的状态,得到的数据、上下文等内容,通过在节点中流动修改更新状态,传递数据。
class AgentState(TypedDict):
messages: Annotated[list[AnyMessage], MessagerManager(max_woking_memory=100,max_history=500)]
其中,主要就是这个messages,用来记录我们需要的东西。我们用StateGraph来注册一个图来管理整个流程。
Node(节点)
每一个节点可以是大模型调用、也可以是工具执行,它代表着流程中的一处操作,我们通过节点和边构成了这个有向图。
当然还有特殊节点,例如Start和End这种节点。
在langgraph中我们可以简单通过add_node来添加节点。
Edge(边)
边代表了节点间的关系,可以是直接的流水线关系,代表执行完一步就走到下一步,也可以是带有条件判断的方式,进行创建不同的路径。
# 1. 普通边:固定流程
graph.add_edge("node_a", "node_b")
# 2. 条件边:根据条件选择路径
def route_logic(state) -> str:
if condition_a(state):
return "path_a"
else:
return "path_b"
graph.add_conditional_edges(
"current_node",
route_logic,
{
"path_a": "node_a",
"path_b": "node_b"
}
)
代码
首先是给出一份缺少MessageManager的Agent类代码,我们使用Agent类来管理我们这个图,init部分注册进行初始化,在循环中使用graph.invoke和大模型进行问询,大模型开启我们上面的流程,再进行回复。
import os
from langchain_openai import ChatOpenAI
from typing import TypedDict
from typing_extensions import Annotated
from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage, AIMessage, ToolMessage # 添加 ToolMessage
import operator
from langgraph.graph import StateGraph, END
from langchain_community.tools.tavily_search import TavilySearchResults
from MessageManager import MessagerManager
class AgentState(TypedDict):
messages: Annotated[list[AnyMessage], MessagerManager(max_woking_memory=100,max_history=500)]
class Agent:
def __init__(self, model, tools, system=""):
self.system = system
self.model = model
self.tools = {t.name: t for t in tools}
self.message_manager = MessagerManager(max_woking_memory=100, max_history=500)
# 绑定工具到模型
self.model = self.model.bind_tools(tools)
# 构建工作流图
graph = StateGraph(AgentState)
graph.add_node("llm", self.call_openai)
graph.add_node("action", self.take_action)
graph.add_conditional_edges(
"llm",
self.exists_action,
{
True: "action",
False: END
}
)
graph.add_edge("action", "llm")
graph.set_entry_point("llm") # 正确的入口点设置
self.graph = graph.compile()
def exists_action(self,state:AgentState):
"""
检查工具调用
"""
if not state["messages"]:
return False
last_message = state["messages"][-1]
if isinstance(last_message,AIMessage):
return hasattr(last_message,'tool_calls') and len(last_message.tool_calls) > 0
if isinstance(last_message, ToolMessage):
return False
return False
def call_openai(self, state:AgentState):
messages = state["messages"]
if self.system:
# 确保系统消息在最前面
system_msg = [SystemMessage(content=self.system)]
non_system_msgs = [msg for msg in messages if not isinstance(msg, SystemMessage)]
messages = system_msg + non_system_msgs
print(f"发送给模型的消息数量: {len(messages)}")
response = self.model.invoke(messages)
return {"messages": [response]}
def take_action(self , state:AgentState):
tool_calls = state["messages"][-1].tool_calls
results = []
for t in tool_calls:
print(f"Calling: {t}")
if not t['name'] in self.tools:
print("\n ....bad tool name....")
result = "bad tool name, retry"
else:
result = self.tools[t['name']].invoke(t['args'])
results.append(ToolMessage(tool_call_id=t['id'], name=t['name'], content=str(result)))
print("Back to the model!")
return {'messages': results}
if __name__ == "__main__":
os.environ["TAVILY_API_KEY"] = "***"
tool = TavilySearchResults(max_results=2)
tools = [tool]
prompt ="""
你是一名聪明的科研助理。可以使用搜索引擎查找信息。
你可以多次调用搜索(可以一次性调用,也可以分步骤调用)。
只有当你确切知道要找什么时,才去检索信息。
如果在提出后续问题之前需要先检索信息,你也可以这样做!
""".strip()
model = ChatOpenAI(
model = "Qwen/Qwen3-Coder-480B-A35B-Instruct",
api_key = '***',
base_url = '***'
)
abot = Agent(model, tools, prompt)
print("🤖 AI助手已启动!输入 'quit' 或 'exit' 退出对话\n")
state = {"messages":[]}
while True:
try:
user_input = input("👤 用户: ").strip()
if user_input.lower() in ['quit', 'exit','q']:
print("👋 再见!")
break
if not user_input:
continue
state["messages"].append(HumanMessage(content=user_input))
result = abot.graph.invoke(state)
ai_res = result['messages'][-1].content
print(f"🤖 AI: {ai_res}")
state["messages"] = result['messages']
except KeyboardInterrupt:
print("\n\n👋 收到中断信号,再见!")
break
except Exception as e:
print(f"❌ 发生错误: {e}")
print("请重试或输入 'quit' 退出")
最小运行只要修改MessageManager为operator.add,使用默认的消息策略,进行追加即可,小H总觉得这样不太合理,会太导致上下文什么的越来越长吧,于是使用了一个简陋的策略,MessageManager的实现如下:
from langchain_core.messages import SystemMessage,HumanMessage,AnyMessage,AIMessage,ToolMessage
class MessagerManager:
"""
分层消息管理器
"""
def __init__(self, max_woking_memory=10, max_history=100):
self.max_woking_memory = max_woking_memory
self.max_history = max_history
self.history = []
def __call__(self, current_messages: list, new_messages: list) -> list:
"""
主要调用接口
"""
# 添加到历史记录
self.history.extend(new_messages)
# 保持历史记录长度
if len(self.history) > self.max_history:
self.history = self.history[-self.max_history:]
# 合并当前消息和新消息
all_messages = current_messages + new_messages
# 准备工作内存
working_memory = self._prepare_working_memory(all_messages)
return working_memory
def _prepare_working_memory(self, all_messages: list) -> list:
"""
准备工作内存 - 保留最重要的消息
"""
# 按类型分类并保持原始顺序
system_msgs = []
human_msgs = []
ai_msgs = []
tool_msgs = []
# 分类消息但保持顺序信息
for i, msg in enumerate(all_messages):
if isinstance(msg, SystemMessage):
system_msgs.append((i, msg))
elif isinstance(msg, HumanMessage):
human_msgs.append((i, msg))
elif isinstance(msg, AIMessage):
ai_msgs.append((i, msg))
elif isinstance(msg, ToolMessage):
tool_msgs.append((i, msg))
working_memory = []
# 始终保留系统消息(通常只需要最新的一个)
if system_msgs:
working_memory.append(system_msgs[-1][1])
# 找出AI消息和对应的工具消息配对
message_pairs = []
# 按时间顺序重组消息
all_sorted = sorted(
system_msgs + human_msgs + ai_msgs + tool_msgs,
key=lambda x: x[0]
)
# 保持工具调用链的完整性:AIMessage -> ToolMessage 的顺序
i = 0
while i < len(all_sorted):
msg = all_sorted[i][1]
# 如果是 AIMessage 且包含工具调用,寻找对应的 ToolMessage
if isinstance(msg, AIMessage) and hasattr(msg, 'tool_calls') and msg.tool_calls:
working_memory.append(msg)
i += 1
# 寻找紧随其后的 ToolMessage
while i < len(all_sorted) and isinstance(all_sorted[i][1], ToolMessage):
working_memory.append(all_sorted[i][1])
i += 1
# 如果是 HumanMessage,添加最近的几个
elif isinstance(msg, HumanMessage):
# 只保留最近的5个 HumanMessage
recent_humans = [m[1] for m in human_msgs[-5:]]
if msg in recent_humans:
working_memory.append(msg)
i += 1
# 其他消息直接添加(但要考虑数量限制)
else:
working_memory.append(msg)
i += 1
# 如果工作内存过长,智能裁剪
if len(working_memory) > self.max_woking_memory:
# 保留系统消息
final_memory = [msg for msg in working_memory if isinstance(msg, SystemMessage)]
# 按类型分组
humans = [msg for msg in working_memory if isinstance(msg, HumanMessage)]
ais = [msg for msg in working_memory if isinstance(msg, AIMessage)]
tools = [msg for msg in working_memory if isinstance(msg, ToolMessage)]
# 保留最近的消息
final_memory.extend(humans[-2:]) # 最近2个用户消息
final_memory.extend(ais[-2:]) # 最近2个AI消息
final_memory.extend(tools[-2:]) # 最近2个工具消息
# 去重并保持顺序
seen = set()
unique_memory = []
for msg in final_memory:
msg_id = id(msg)
if msg_id not in seen:
seen.add(msg_id)
unique_memory.append(msg)
working_memory = unique_memory[:self.max_woking_memory]
# 确保最终顺序正确
working_memory = self._maintain_proper_order(working_memory)
return working_memory
def _maintain_proper_order(self, messages: list) -> list:
"""
确保消息顺序正确:System -> Human -> AI -> Tool 的循环
"""
# 移除重复消息
seen_ids = set()
unique_messages = []
for msg in messages:
if id(msg) not in seen_ids:
seen_ids.add(id(msg))
unique_messages.append(msg)
return unique_messages
def get_statistics(self) -> dict:
"""
获取消息统计
"""
return {
"total_history": len(self.history),
"system_messages": len([m for m in self.history if isinstance(m, SystemMessage)]),
"human_messages": len([m for m in self.history if isinstance(m, HumanMessage)]),
"ai_messages": len([m for m in self.history if isinstance(m, AIMessage)]),
"tool_messages": len([m for m in self.history if isinstance(m, ToolMessage)])
}
if __name__ == "__main__":
mm = MessagerManager(max_woking_memory=10, max_history=10)
# 测试1: 空消息
print("测试1 - 空消息:")
result = mm([], [])
print(f"结果: {result}") # []
# 测试2: 系统消息 + 用户消息
print("\n测试2 - 系统 + 用户消息:")
current = [SystemMessage(content="你是助手")]
new = [HumanMessage(content="你好")]
result = mm(current, new)
print(f"结果数量: {len(result)}")
for msg in result:
print(f" - {type(msg).__name__}: {msg.content}")
# 测试3: 多轮对话模拟
print("\n测试3 - 多轮对话:")
current = [
SystemMessage(content="你是助手"),
HumanMessage(content="问题1"),
AIMessage(content="回答1"),
HumanMessage(content="问题2"),
AIMessage(content="回答2")
]
new = [HumanMessage(content="新问题")]
result = mm(current, new)
print(f"结果数量: {len(result)}")
for msg in result:
print(f" - {type(msg).__name__}: {msg.content}")
主要就是按照小H认为的消息重要程序进行添加,给不同类型的消息保存一定长度的内容,具体可以看看代码中的注释。
运行结果如下:可以看到calling tool就是调用了我们给出的搜索引擎api,如果没有的话就是使用已有的知识进行回答。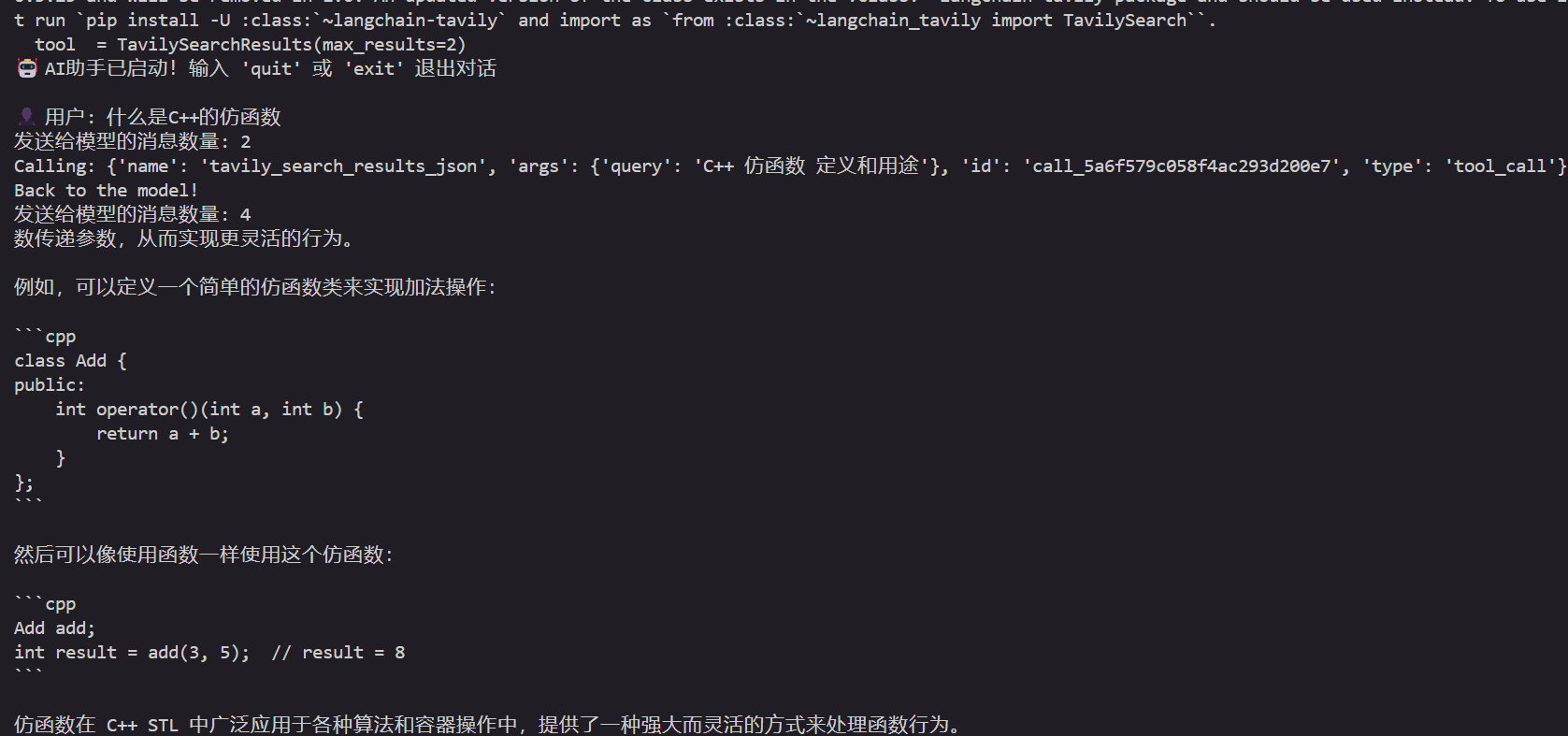
结语
一个基础的框架就是这样了,小H可以和自己的chatbot进行聊天了,但是还存在很多的不足,例如我们提到的消息管理,是否可以引入新的大模型来进行这一步呢?还有提示词的写法太不专业了、是不是可以引入更多的工具呢······前面还有许多东西等着小H去探索。




















 159
159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











