




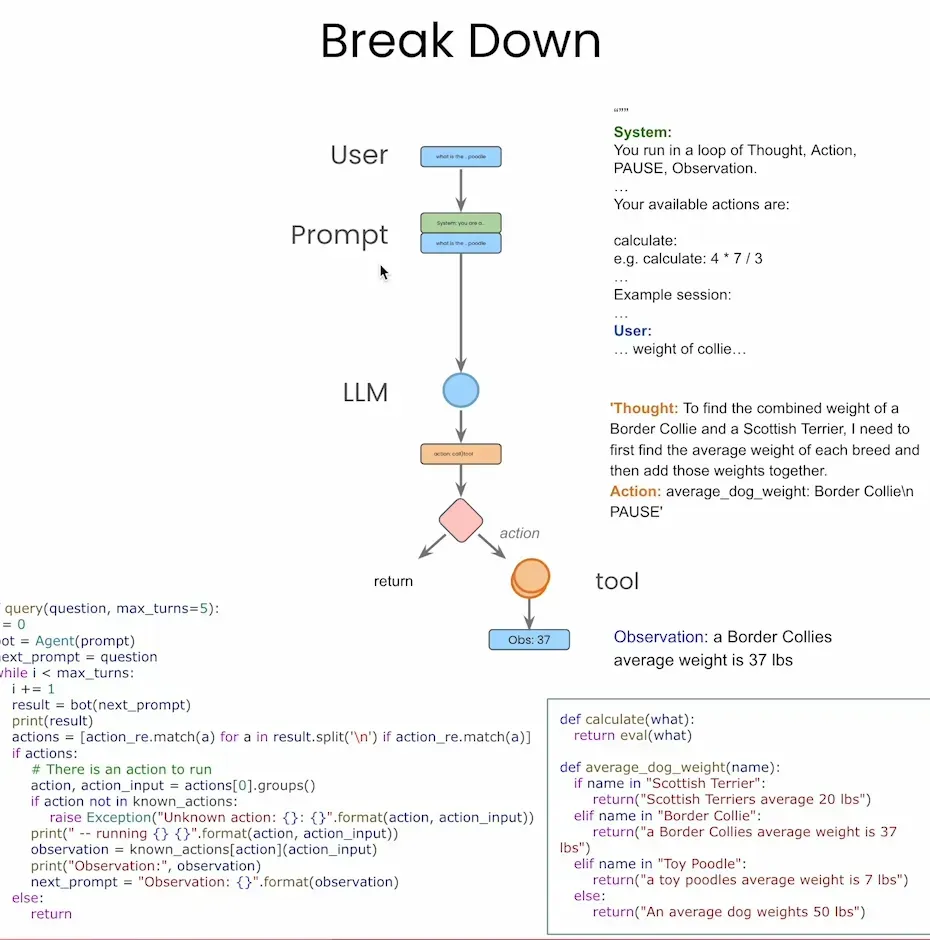
因此本节课中,我们将迈出关键一步,引入当前 Agent 生态中非常热门的框架——LangGraph。它基于“有向图”模型,将 Agent 的运行流程抽象为“节点 + 状态流转”,具备结构清晰、易扩展、原生支持多工具/多轮调用等显著优势。通过与上一节手写 Agent 的对比学习,你将切实体会到:借助 LangGraph,我们可以用更高效、更优雅的方式构建复杂智能体系统。
LangGraph 简介
LangGraph 最核心的设计理念就是将智能体流程图形化建模。在 LangGraph 中,每一个操作单元(比如大模型调用、函数执行、判断逻辑)都是一个 节点(Node),节点之间通过 边(Edge) 相连接,构成了完整的智能体工作流。特别是,它支持 条件边(Conditional Edges),可以根据状态决定分支路径,类似于传统的 if-else 语句。这样构建出来的智能体,就像画流程图一样简单、直观,极大地增强了结构可视性与逻辑解耦能力。
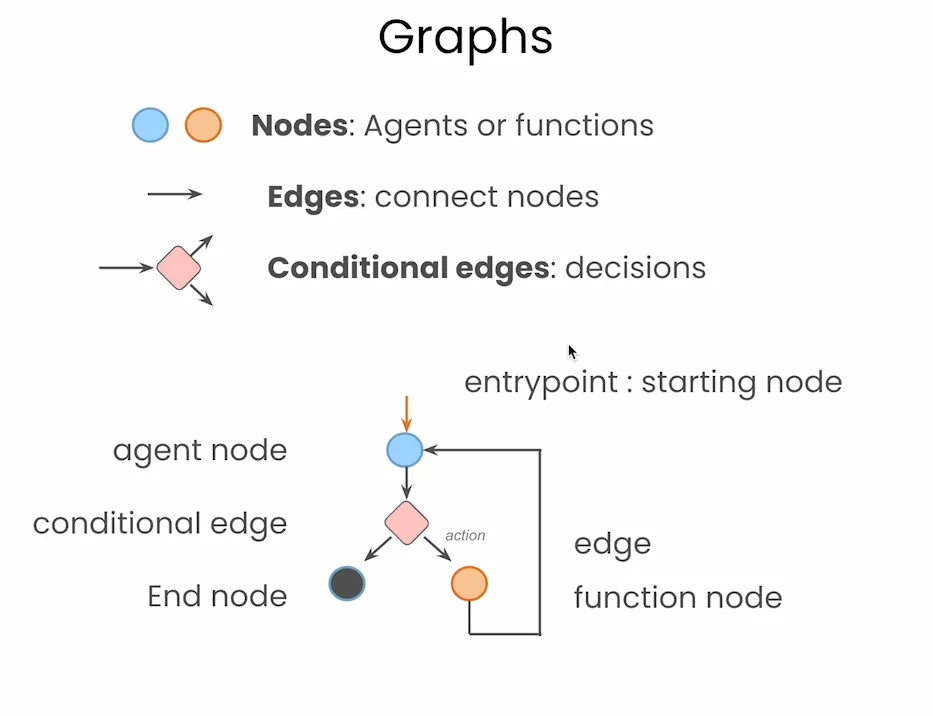
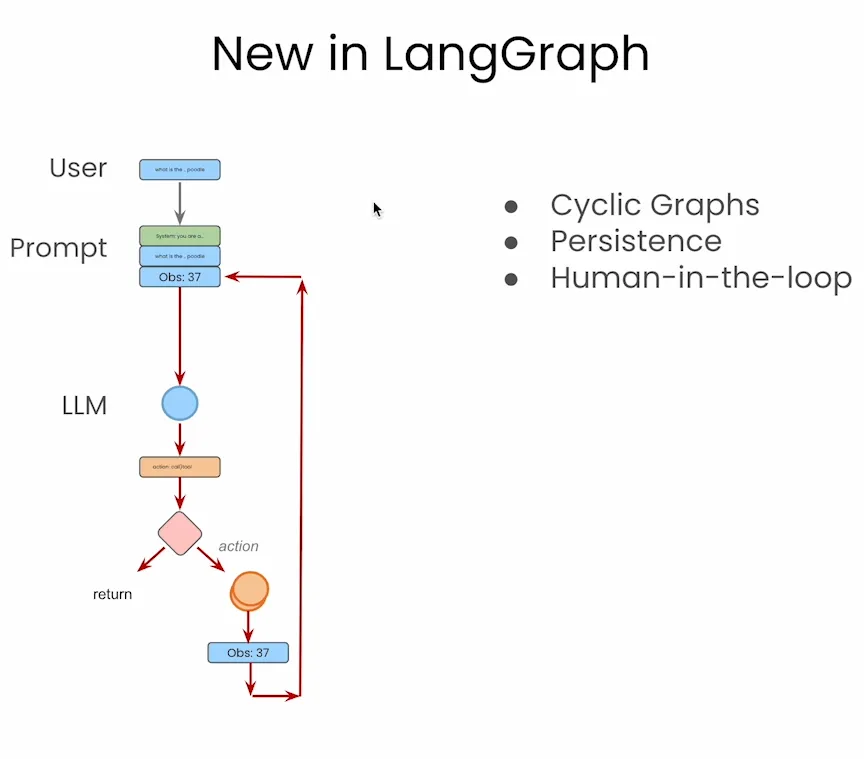
另外,LangGraph 并不只是“把流程画出来”这么简单,它还原生支持三个非常重要的功能:
-
✅ Cyclic Graphs(循环图):支持智能体在不同节点之间循环跳转,方便实现多轮思考与行动;
-
✅ Persistence(状态持久化):图中状态可以随时保存、恢复,支持断点续跑与回溯;
-
✅ Human-in-the-loop(人类参与环节):支持在流程中插入人工确认、反馈或干预节点,增强系统可控性。
这些功能,若在传统实现中靠代码维护会非常复杂,而 LangGraph 提供了图层级的原生支持,几乎开箱即用。
代码实战
前期准备
首先我们可以沿用上一节课创建的环境(没看过的小伙伴可以点击链接查阅一下),但是我们需要额外在终端安装以下这些库:
pip install langgraph langchain langchain-openai langchain-community pygraphviz
然后我们还可以配置好大模型的环境,我们只需要写入api_key的信息即可:
from langchain_openai import ChatOpenAI
aliyun_api_key = '你的api_key'
model = ChatOpenAI(
model="qwen-plus", # 或其他你在 DashScope 控制台启用的模型名
openai_api_key=aliyun_api_key,
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
假如在国外的朋友可以照着原本教程的代码配置Tavily Search,这个API密钥我们可以通过链接((https://www.tavily.com/)去获取。
from langchain_community.tools.tavily_search import TavilySearchResults
import os
os.environ["TAVILY_API_KEY"] = "你的api_key"
tool = TavilySearchResults(max_results=4) #increased number of results
print(type(tool))
print([tool.name](http://tool.name/))
但是由于国内无法直接使用,因此这里我们可以替换成国内可用的一个搜查工具——博查。博查算是我发现国内可用里面比较方便快捷的网络搜索工具了,其他百度啊Bing这种用起来都比较复杂,博查算是充值就能用的了。我们可以在博查的官网(https://open.bochaai.com/)注册一个账号(可以直接微信登录)。
进去后就可以点击右上角的控制台找到账号充值的位置,然后充值10块钱进去尝试一下。
然后再点击右边的API KEY管理生成一个属于我们自己的API KEY。
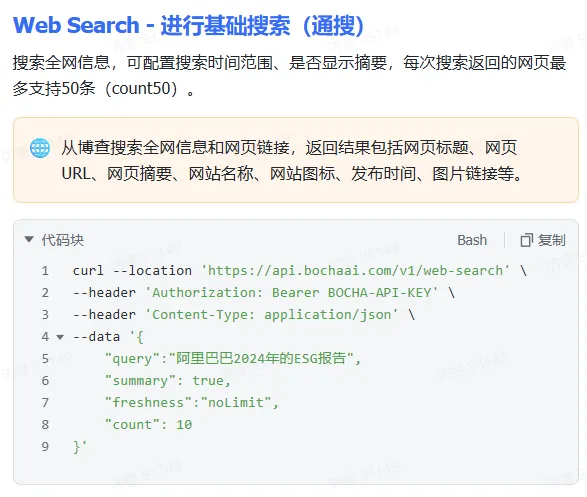
拿到这个API KEY以后呢,我们再点击开发文档(https://bocha-ai.feishu.cn/wiki/HmtOw1z6vik14Fkdu5uc9VaInBb)里看看怎么去获取到对应的信息和内容。博查里面其实有好几种不同的搜索方式,这里演示我就使用最普通的Web Search好了。
拿到了这个代码内容以后呢,我们其实就要把这个调用的方式封装成LangGraph支持的格式了。这里其实我们就可以去求助一下AI,让其帮我们改一下。那AI哐哧哐哧就写了一个工具出来(当然这里也要几轮的交互,最重要的其实是要把返回的数据结构给到AI,就是真正的通过上面的代码调用一次,把返回的数据结构传给AI,那AI就知道要怎么写了)。我们只需要在最下面写入API_KEY并看看返回的结果即可。
from typing import Type
from pydantic import BaseModel, Field, PrivateAttr
from langchain_core.tools import BaseTool
import requests
# 输入参数定义
class BoChaSearchInput(BaseModel):
query: str = Field(..., description="搜索的查询内容")
# LangChain Tool 定义
class BoChaSearchResults(BaseTool):
name: str = "bocha_web_search"
description: str = "使用博查API进行网络搜索,可以用来查找实时信息或新闻"
args_schema: Type[BaseModel] = BoChaSearchInput
# 私有属性,用于保存调用参数
_api_key: str = PrivateAttr()
_count: int = PrivateAttr()
_summary: bool = PrivateAttr()
_freshness: str = PrivateAttr()
# 初始化方法
def __init__(self, api_key: str, count: int = 5, summary: bool = True, freshness: str = "noLimit", **kwargs):
super().__init__(**kwargs)
self._api_key = api_key
self._count = count
self._summary = summary
self._freshness = freshness
# Tool 实际运行逻辑
def _run(self, query: str) -> str:
url = "https://api.bochaai.com/v1/web-search"
headers = {
"Authorization": f"Bearer {self._api_key}",
"Content-Type": "application/json"
}
payload = {
"query": query,
"summary": self._summary,
"freshness": self._freshness,
"count": self._count
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=10)
response.raise_for_status()
data = response.json()
# ✅ 正确解析返回值中的搜索结果位置
results = data.get("data", {}).get("webPages", {}).get("value", [])
ifnot results:
returnf"未找到相关内容。\n[DEBUG] 返回数据:{data}"
# 格式化输出结果
output = ""
for i, item in enumerate(results[:self._count]):
title = item.get("name", "无标题")
snippet = item.get("snippet", "无摘要")
url = item.get("url", "")
output += f"{i+1}. {title}\n{snippet}\n链接: {url}\n\n"
return output.strip()
except Exception as e:
returnf"搜索失败: {e}"
tool = BoChaSearchResults(api_key="你的博查API Key", count=4)
# 单次使用(模拟 Agent 工具调用)
result = tool.invoke({"query": "阿里巴巴2024年的ESG报告"})
print(result)
测试完没问题以后,我们下面就正式开始关于LangGraph的Agent构件了!

温馨提示一下,大家测试完记得把单次使用的代码删掉或者注释掉,不然每运行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









