




 本文介绍了一种名为FoveaBox的新型目标检测网络,该网络摒弃了传统的锚框机制,直接在FPN网络的不同层级上预测目标存在的概率与检测框坐标。FoveaBox在COCO数据集上达到了42.1的AP,展现出对不同形状和比例目标的鲁棒性。网络结构包括主干网络、分类分支和检测框预测分支,采用FPN网络并利用尺度分配策略处理不同大小的目标。
本文介绍了一种名为FoveaBox的新型目标检测网络,该网络摒弃了传统的锚框机制,直接在FPN网络的不同层级上预测目标存在的概率与检测框坐标。FoveaBox在COCO数据集上达到了42.1的AP,展现出对不同形状和比例目标的鲁棒性。网络结构包括主干网络、分类分支和检测框预测分支,采用FPN网络并利用尺度分配策略处理不同大小的目标。
代码地址:暂无
1. 概述
导读:这篇文章提出了一种基于非anchor机制的检测网络FoveaBox,这个网络在没有anchor的条件下直接学习目标存在的概率与检测框坐标,对于不同大小的目标是在FPN网络的不同层上预测实现的。目标概率与检测框回归是通过下面两点来实现的:
1)backbone的输出特征图上输出对应分类类别的分类结果特征图;
2)对可能包含目标的位置(既是在文中规定的搜索区域内)生成与分类数目对应的检测框(训练时直接与GT计算偏移);
文章提出的FoveaBox在COCO数据集上获得了42.1的AP。由于没有anchor带来的限制,这样就可以使得网络对任意长宽比例与形状的目标更加鲁棒。
RefineNet通过增加anchor的数量会带来一定的性能提升,但是随着anchor的增加带来的性能提升也趋近与饱和,而这片文章的方法性能却超过了它。
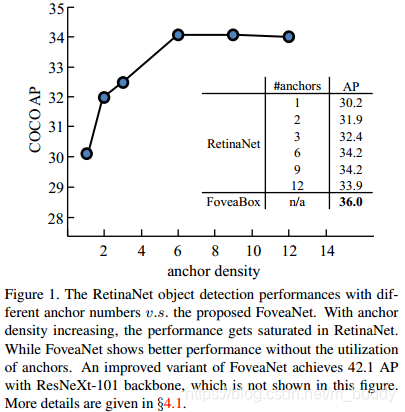
2 方法设计
2.1 网络结构
FoveaBox的网络结构由3个部分组成:主干网络、分类分支、检测框预测分支。主干网络用于从输入图像中抽取出特征,分类分支用于在主干网络输出上逐像素预测分类结果,检测框预测分支用于预测对应位置上的检测框。
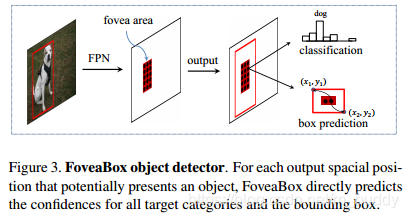
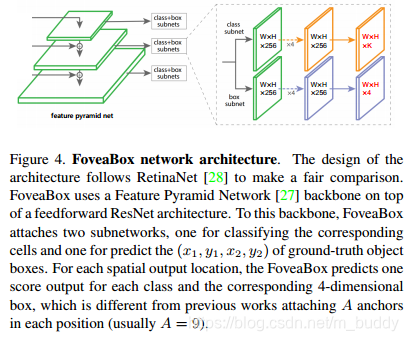
2.2 FPN的主干网络
这篇文章的算法采用FPN网络,构建了一个金字塔层级
{
P
l
}
,
l
=
3
,
4
,
…
,
7
\{P_l\},l=3,4,\dots,7
{Pl},l=3,4,…,7,其中
P
l
P_l
Pl代表大小为原始输入
1
2
l
\frac{1}{2^l}
2l1的特征图,每个金字塔层的通道数为
C
=
256
C=256
C=256。在每个塔层上使用分类与检测框分支,它们都是逐像素预测的。其结构见下图所示:
2.3 尺度分配
基础网络使用的是FPN网络,文中就将不同大小的目标划归到这些不同层级的网络中去,对于FPN的特征层
P
3
,
P
7
P_3,P_7
P3,P7他们对应的基础面积范围是
3
2
2
,
51
2
2
32^2,512^2
322,5122,则对应的基础面积可以使用下面的关系表示:
S
l
=
4
l
⋅
S
0
S_l=4^l\cdot S_0
Sl=4l⋅S0
其中,
S
0
=
16
S_0=16
S0=16。此外还引入一个参数
η
\eta
η来控制每个金字塔的尺度表达范围,超过这个范围的就会被忽略掉:
[
S
l
η
2
,
S
l
⋅
η
2
]
[\frac{S_l}{\eta^2},S_l\cdot \eta^2]
[η2Sl,Sl⋅η2]
对于
η
\eta
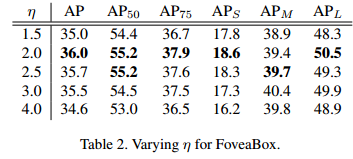
η对于性能的影响见表2所示:
2.4 Object Fovea
对于一个GT框其在金字塔层
P
l
P_l
Pl(stride为
2
l
2^l
2l)上的坐标计算为:
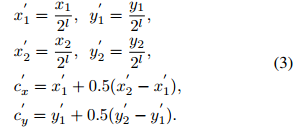
对于fovea的正样本区域
R
p
o
s
=
(
x
1
′
′
,
y
1
′
′
,
x
2
′
′
,
y
2
′
′
)
R^{pos}=(x_1^{''},y_1^{''},x_2^{''},y_2^{''})
Rpos=(x1′′,y1′′,x2′′,y2′′),是比标注小的一个区域,其收缩的比例使用
σ
1
=
0.3
\sigma_1=0.3
σ1=0.3去控制,在这个区域内的会被划分为正样本,并分配对应的类别标签,参与到检测框的预测中去,其关系见公式4所示:
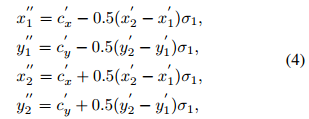
对于负样本引入另外一个收缩参数
σ
2
=
0.4
\sigma_2=0.4
σ2=0.4去生成
R
n
e
g
R^{neg}
Rneg,使用也是公式4,没有在这个区域内的就是负样本,对于那些没有被分配到的区域就不会参与训练,正负样本使用Focal Loss进行调和。
2.5 检测框预测
在object fovea只是表示了存在目标的可能性,对于实际的位置就需要网络对每个可能的位置使用边界框回归。对于给定的GT框,那么网络检测框的预测目标就是在每个cell
(
x
,
y
)
(x,y)
(x,y)处预测对应4为坐标定位输出:
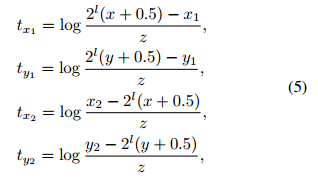
其中,
z
=
S
l
z=\sqrt{S_l}
z=Sl归一化因子将输出空间映射到1附近,是的网络能够稳定学习。对于边界框的损失函数是使用Smooth L1损失函数。
3. 实验结果
基础网络的深度与输入图像分辨率对网络检测性能的影响:
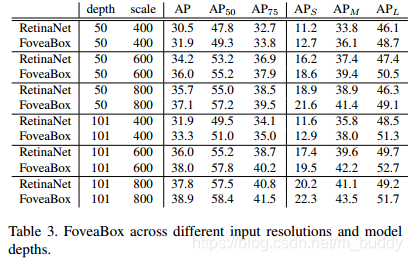
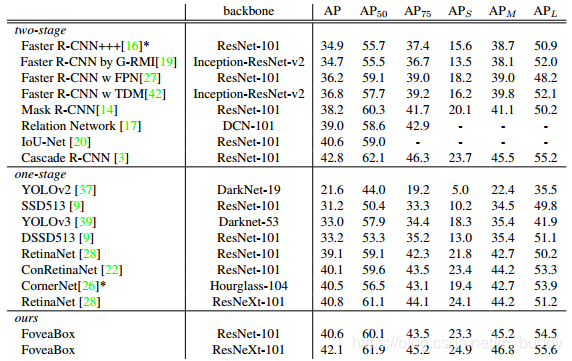
与其它方法的一些对比:


















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









