




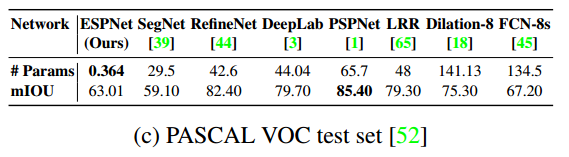
 ESPNet v1是针对高分辨率图像的快速语义分割模型,采用Efficient Spatial Pyramid(ESP)模块,通过pointwise convolutions和dilated convolutions提高效率。在GPU上,它比PSPNet快22倍,实现了112FPS的运行速度,并在VOC-2012数据集上达到63.01的IoU。ESPNet包含四种变体结构,通过不同设计提升性能。
ESPNet v1是针对高分辨率图像的快速语义分割模型,采用Efficient Spatial Pyramid(ESP)模块,通过pointwise convolutions和dilated convolutions提高效率。在GPU上,它比PSPNet快22倍,实现了112FPS的运行速度,并在VOC-2012数据集上达到63.01的IoU。ESPNet包含四种变体结构,通过不同设计提升性能。
代码地址:ESPNet v1
1. 概述
导读:这篇文章提出了在有限资源环境下对高分辨率图像进行快速高效分割的卷积网络ESPNet。ESPNet是基于一个新型的卷积模块(Efficient Spatial Pyramid,ESP),该模块高效且强大。在(标准?)GPU上比PSPNet快22倍,体积却小了180倍,在GPU上可以飚到112FPS。在VOC-2012数据集上达到了63.01的IoU,对效果要求比较高的可以考虑换个方法了。
ESP模块基于卷积因式分解准则将标准的卷积操作分解为两步:pointwise convolutions与spatial pyramid of dilated convolutions,其过程如下图所示:
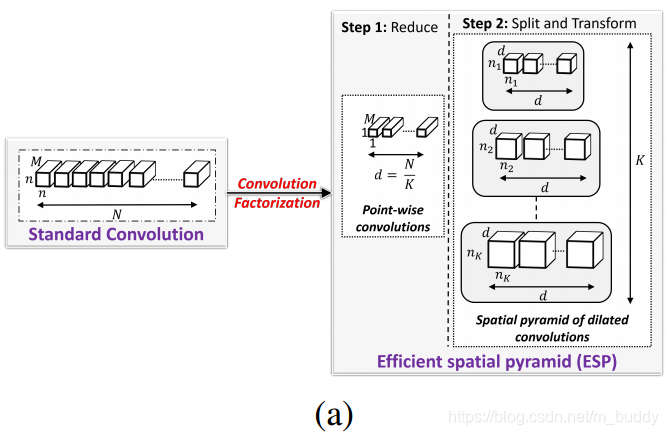
- 第一步:使用pointwise convolutions减少了计算量;
- 第二步:使用spatial pyramid of dilated convolutions使用不同的膨胀系数去采样特征,增大网络的感受野。这样的结构相比其他的因式分解的方法,如Inception与ResNet,更加高效。
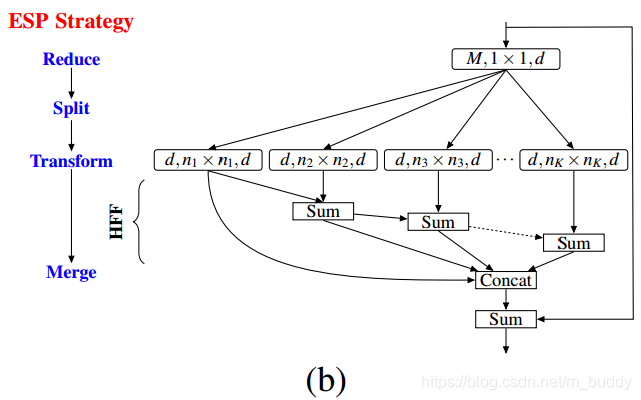
- 第三步:(主要为HFF特征融合部分)将分组之后卷积得到的结果在相邻组间使用Sum方式融合,之后再将这K个特征Concat起来,再与原始输入Sum得到最后的模块输出。其结构见下图的(b)图;
2. 方法设计
这篇文章的方法主要是围绕提出的ESP模块展开的,这里首先对ESP模块进行分析。
2.1 ESP module
输入的特征图首先经过mobilenet中的depthwise卷积将高维度的特征映射到低维度上。之后空间膨胀卷积金字塔在不同的分组(每个组的特征数量:
d
=
N
K
d=\frac{N}{K}
d=KN)上使用不同感受野的膨胀卷积,膨胀卷积在不同组上感受野为
[
(
n
−
1
)
⋅
2
K
−
1
+
1
]
2
[(n-1)\cdot 2^{K-1}+1]^2
[(n−1)⋅2K−1+1]2。

在spatial pyramid of dilated步骤中使用不同膨胀系数的卷积运算是会产生网格效应的,如图2(b)第二列结果图,为了解决这个问题文中引入了HFF特征融合步骤,经过这个模块处理之后得到的结果如图2(b)中第三列所示。
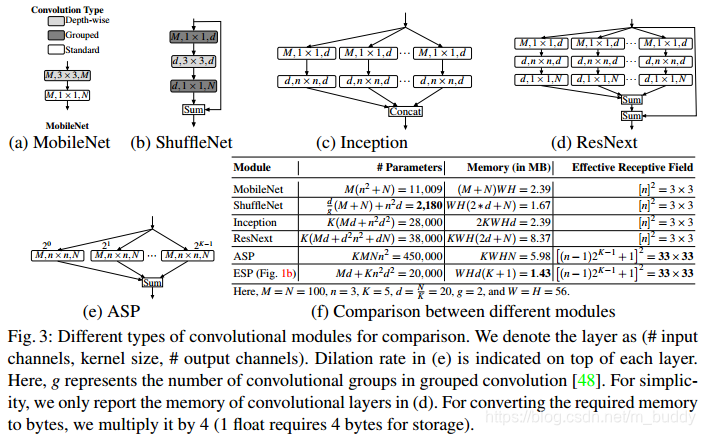
ESP模块与当前的轻量级网络的对比:
2.2 ESP网络结构
文章中提出了如下四种ESP的网络结构,其包含了ESPNet的4个变体结构,如图4所示:
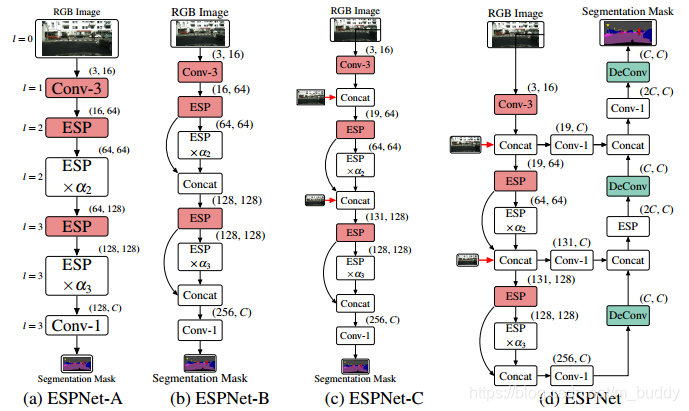
- 1)ESPNet-A:使用的是标准的串联式网络结构,输出的预测结果为原始图的1/8;
- 2)ESPNet-B:在A的基础上加入shortcut连接,预测结果也为原始图的1/8;
- 3)ESPNet-C:在B的基础上在不同stride上添加原始图的信息,使得网络中的信息更加丰富,预测结果也为原始图的1/8;
- 4)ESPNet-D,在C结构的基础上添加了decoder部分,使用不同stride的信息不断校准预测的结果;
它们的性能比较:
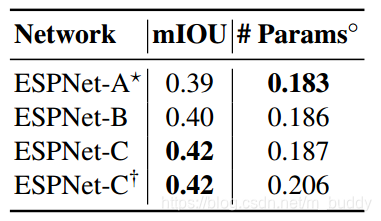
3. 实验结果
VOC 2012数据集上:
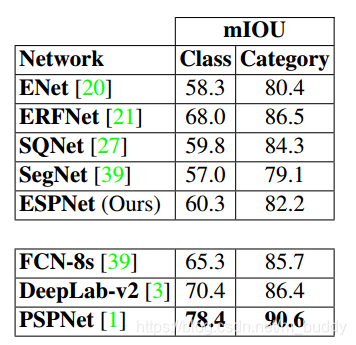
CityScapes数据集上:

















 1606
1606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









