






 本文介绍了TiG-BEV方法,通过目标内在几何(TIG)知识蒸馏提升相机的3D物体检测性能。该方法在深度估计分支中加入相对约束,并在BEV特征图上进行inter-keypoint和inter-channel的知识蒸馏,以增强相机的深度感知能力。
本文介绍了TiG-BEV方法,通过目标内在几何(TIG)知识蒸馏提升相机的3D物体检测性能。该方法在深度估计分支中加入相对约束,并在BEV特征图上进行inter-keypoint和inter-channel的知识蒸馏,以增强相机的深度感知能力。
参考代码:TiG-BEV
1. 概述
介绍:由于相机的BEV感知算法缺少或较难预测准确深度信息,导致下游任务性能掉点。对此,文章提出了一种基于目标内在几何信息(TIG:Target Inner-Geometry)的知识蒸馏信息约束载体,其可以有效将Lidar准确的3D感知信息迁移给图像,进而实现camera下性能提升。文章使用的是基于LSS的方法,其知识迁移的主要是在BEV特征图上完成的,也就是提出了一种基于object(检测目标)inter-keypoints和inter-channel的知识迁移。除此之外,还对LSS中深度估计部分做了优化,增加了object中相对深度约束。
对于给camera提供深度感知能力,可以将现有不同的方法划分为如下几种类型:

- 1)深度监督:类似于LSS中添加深度预测分支,直接通过网络有监督或是无监督形式得到深度表达。
- 2)BEV特征图知识迁移:使用Lidar数据去获取BEV特征,之后将其于camera获得的BEV特征进行逐点近似。这样的方法缺点也很明显,引入太多噪声,没有对其中的目标着力关注。
- 3)文章的TIG方法:在深度估计部分出了LSS自带的深度监督约束,还增加object内部相对深度约束。在BEV特征蒸馏部分,在object内部采用inter-keypoint和inter-channel近似的方式实现知识蒸馏。
2. 方法设计
2.1 网络pipeline
文章的方法流程图见下图所示:

其主要优化便是对深度估计部分和BEV特征蒸馏部分做了优化。
2.2 深度估计分支添加相对约束
深度估计除了LSS中采用深度bins预测损失之外,还考虑目标本身内在的相对深度信息。如下图展示了object目标中不同部分深度是不一样的:

对此,对于需要检测的目标设置了目标内部相对深度约束,其实这点类似于深度估计方法中structrual-loss。对于相对深度的参考点文章是通过预测过程中选择于GT深度差异最小的点(
j
j
j代表object的索引):
(
x
r
,
y
r
)
=
arg min
(
x
,
y
)
∈
S
^
j
(
S
j
g
t
(
x
,
y
)
−
S
^
j
(
x
,
y
)
)
(x_r,y_r)=\argmin_{(x,y)\in\hat{S}_j}(S_j^{gt}(x,y)-\hat{S}_j(x,y))
(xr,yr)=(x,y)∈S^jargmin(Sjgt(x,y)−S^j(x,y))
之后便是目标中所有的像素计算与参考点的深度差异(预测结果和GT中分别进行):
r
d
j
(
x
,
y
)
=
d
j
(
x
,
y
)
−
d
j
(
x
r
,
y
r
)
rd_j(x,y)=d_j(x,y)-d_j(x_r,y_r)
rdj(x,y)=dj(x,y)−dj(xr,yr)
r
d
j
g
t
(
x
,
y
)
=
d
j
g
t
(
x
,
y
)
−
d
j
g
t
(
x
r
,
y
r
)
rd_j^{gt}(x,y)=d_j^{gt}(x,y)-d_j^{gt}(x_r,y_r)
rdjgt(x,y)=djgt(x,y)−djgt(xr,yr)
之后便是对上述深度相对差异进行约束:
L
d
e
p
t
h
R
=
∑
j
=
1
M
∣
∣
R
^
j
−
R
j
g
t
∣
∣
2
L_{depth}^R=\sum_{j=1}^M||\hat{R}_j-R_j^{gt}||_2
LdepthR=j=1∑M∣∣R^j−Rjgt∣∣2
这里也可采用ranking-loss替代,效果应该会更好。
不同的相对深度约束方式对性能带来的影响:
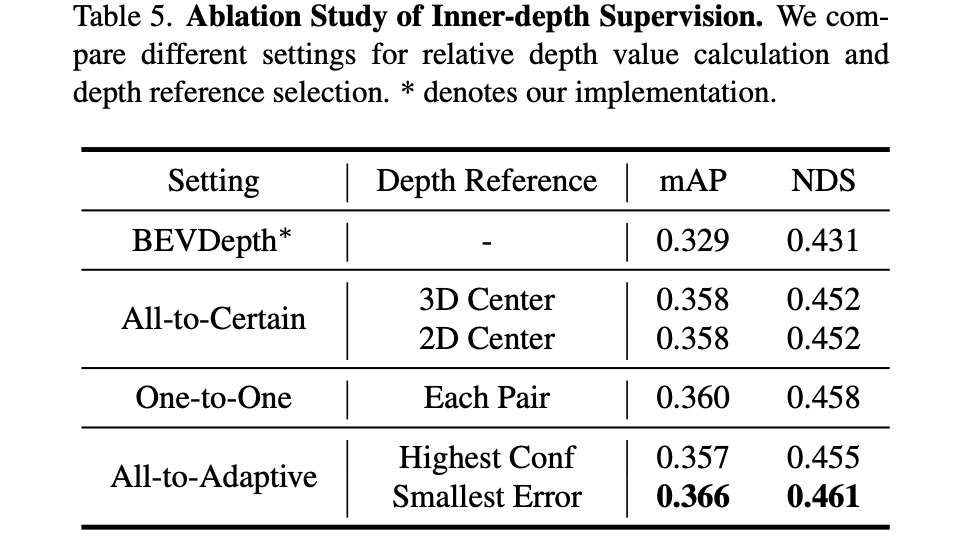
2.3 BEV特征图上的蒸馏
同样这里采用了object上实现特征图对齐,不过对齐的方式采用了inter-keypoints和inter-channel的形式,其实也就是特征图在不同空间下的表达。这里对于首先对于BEV上object对应的区域采用均匀采样
N
N
N个点,并通过双线性插值得到camera和Lidar对应的特征表达:
f
j
2
d
,
f
j
3
d
∈
R
N
∗
C
f_j^{2d},f_j^{3d}\in R^{N*C}
fj2d,fj3d∈RN∗C。那么接下来便是去最小化它们的特征表达,也就是在下图所示的空间上实现:
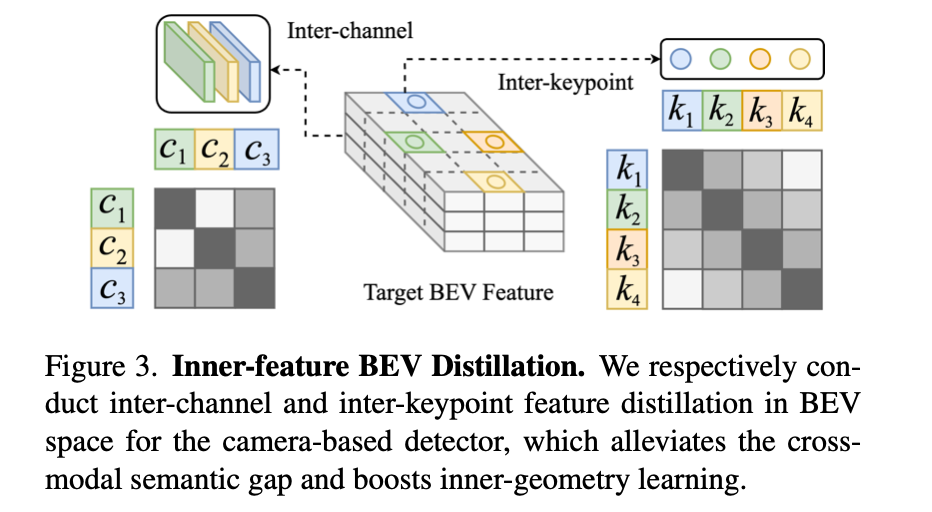
inter-channel上:
定义camera和Lidar特征表达:
A
j
2
d
=
f
j
2
d
f
j
2
d
T
,
A
j
3
d
=
f
j
3
d
f
j
3
d
T
A_j^{2d}=f_j^{2d}{f_j^{2d}}^T,\ A_j^{3d}=f_j^{3d}{f_j^{3d}}^T
Aj2d=fj2dfj2dT, Aj3d=fj3dfj3dT
通过L2范数约束:
L
b
e
v
I
C
=
∑
j
=
1
M
∣
∣
A
j
2
d
−
A
j
3
d
∣
∣
2
L_{bev}^{IC}=\sum_{j=1}^M||A_j^{2d}-A_j^{3d}||_2
LbevIC=j=1∑M∣∣Aj2d−Aj3d∣∣2
inter-keypoints上:
定义camera和Lidar特征表达:
B
j
2
d
=
f
j
2
d
T
f
j
2
d
,
B
j
3
d
=
f
j
3
d
T
f
j
3
d
B_j^{2d}={f_j^{2d}}^Tf_j^{2d},\ B_j^{3d}={f_j^{3d}}^Tf_j^{3d}
Bj2d=fj2dTfj2d, Bj3d=fj3dTfj3d
通过L2范数约束:
L
b
e
v
I
K
=
∑
j
=
1
M
∣
∣
B
j
2
d
−
B
j
3
d
∣
∣
2
L_{bev}^{IK}=\sum_{j=1}^M||B_j^{2d}-B_j^{3d}||_2
LbevIK=j=1∑M∣∣Bj2d−Bj3d∣∣2
这两个改进对性能带来的影响:
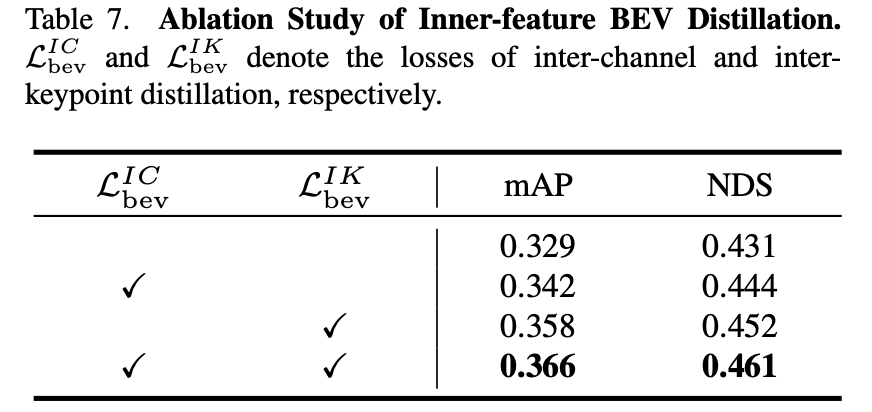
3. 实验结果
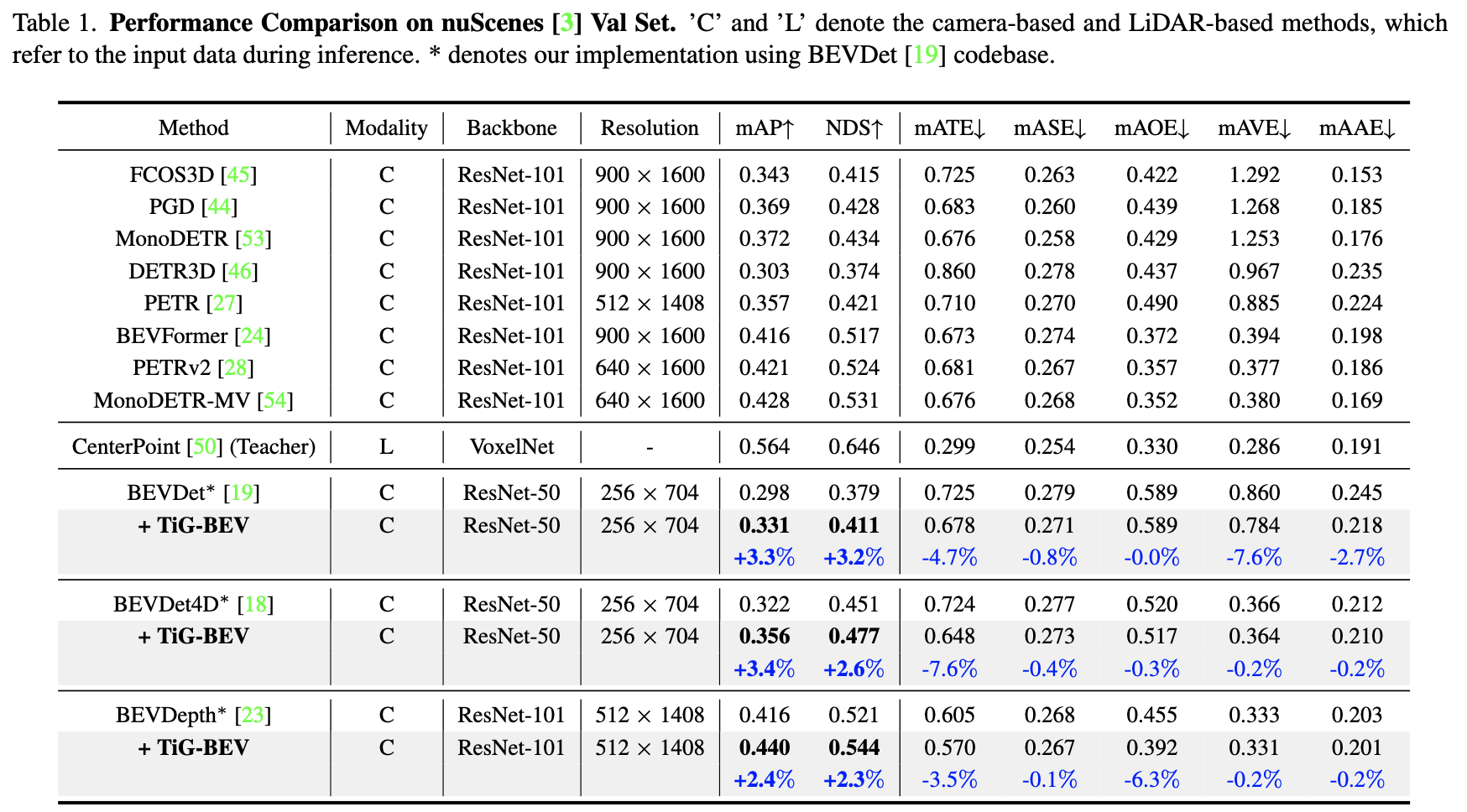
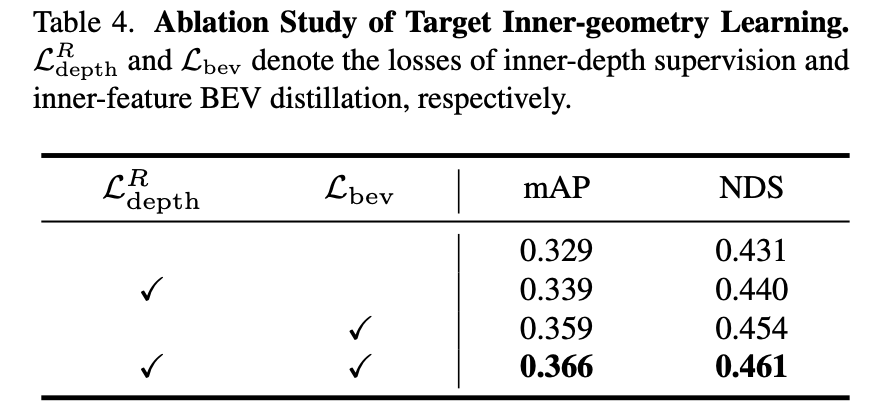
上述2.2和2.3节方法对性能带来的影响:


















 1752
1752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









