




 本文介绍了BEVFusion,一种在鸟瞰视图(BEV)空间中融合LiDAR和Camera数据的方法,旨在结合图像的丰富语义信息和雷达的深度信息。通过改进LSS的‘splat’操作,提高了运算效率,并提出了BEVPool-V1和BEVPool-V2来优化内存使用和计算速度。实验表明,这种方法在3D检测和分割任务中表现出色。
本文介绍了BEVFusion,一种在鸟瞰视图(BEV)空间中融合LiDAR和Camera数据的方法,旨在结合图像的丰富语义信息和雷达的深度信息。通过改进LSS的‘splat’操作,提高了运算效率,并提出了BEVPool-V1和BEVPool-V2来优化内存使用和计算速度。实验表明,这种方法在3D检测和分割任务中表现出色。
参考代码:bevfusion
1. 概述
介绍:在这篇文章中提出一种Lidar和Camera在BEV空间下实现特征融合的方法,有效利用了图像丰富语义信息和雷达深度信息,构建一个不同模态数据融合的范式。对于图像部分生成BEV特征采用的是LSS的方案,不过这里对“splat”这个操作进行了改进(这个操作在原版实现中比较耗时,距离实际工程化又近了一步),也就是通过GPU多线程的特性直接在不同的深度bins下求和,而不需要累加求和之后再相减,这样便可极大提升运算的效率(文中指出大概快了40倍)。
Lidar数据和Camera数据他们的局限如下图:

将Lidar的点云投影到图像上是一种前融合策略,但是实际中能正确匹配上图像的Lidar点其实只占很少的一部分,对此最右边就是文章提出的在BEV空间下的特征融合。
2. 方法设计
2.1 网络结构
下图展示的是文章方法的结构:

从上图中可以看到文章的方法采取的是不同传感器中融合的结构,融合是在BEV空间下完成的,同时还设计了一个BEV Encoder。这个模块的作用是弥补LSS中深度估计不准带来的影响,使用encoder参数自适应拟合的方式实现Lidar和Camera特征有效融合。最后融合的特征变用于各种任务头了。
2.2 BevPool-V1
这里把这篇文章对LSS中的“splat”进行改进版本称为V1版本,其原理是使用GPU中的并行计算机制直接在不同的深度bins下求和(这些不同的深度bins是可以通过之前设置的超参数提前计算得到),如下图中的(b)图所示:
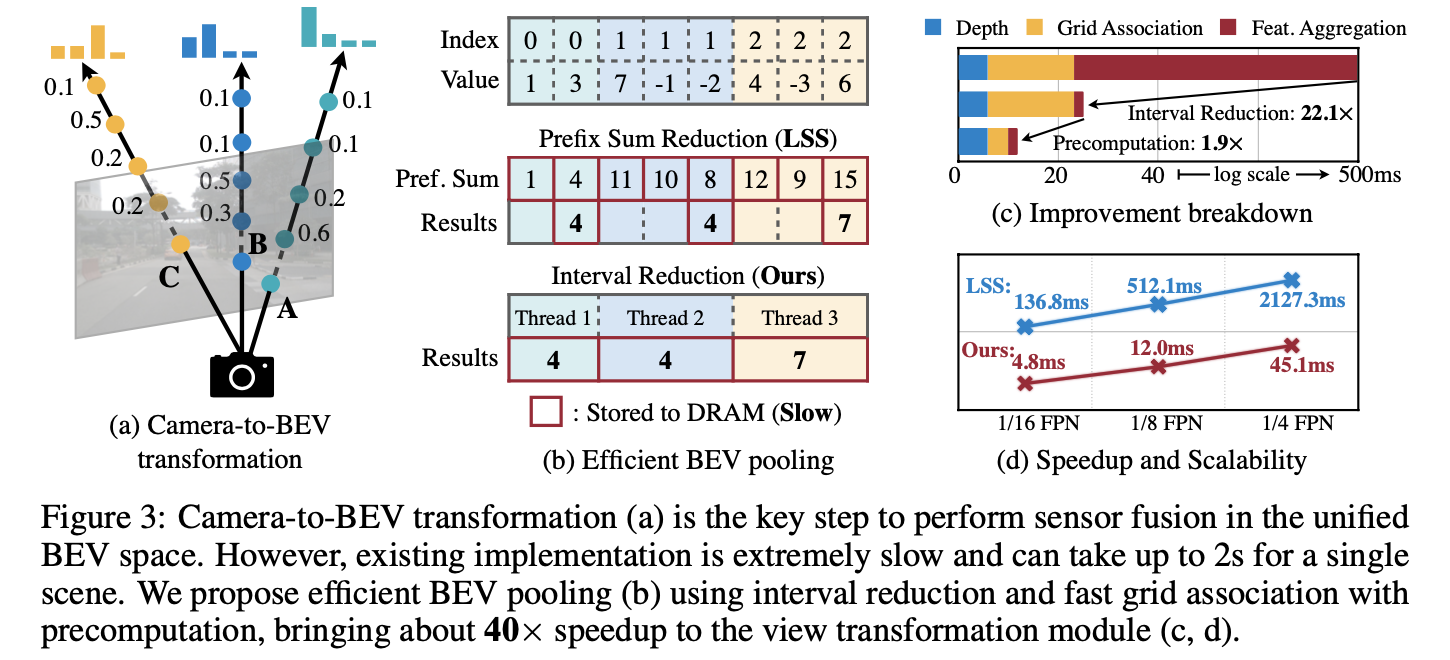
从(c)(d)图中可以看到改进之后的计算方法在计算时间上有了较大压缩。
2.3 BevPool-V2
论文:BEVPoolv2: A Cutting-edge Implementation of BEVDet Toward Deployment
参考代码:BEVDet
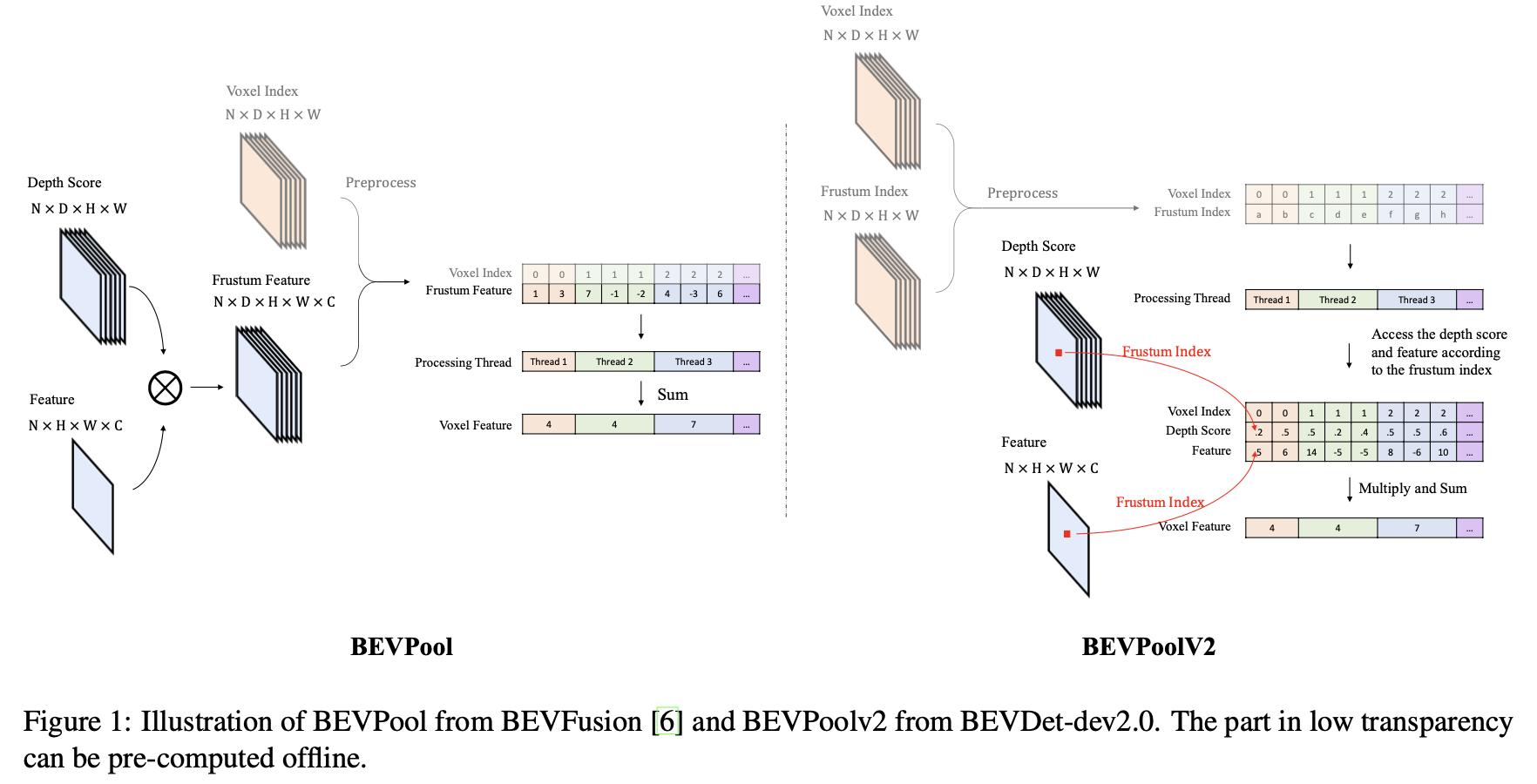
在LSS中“lift”操作是矩阵外积操作,因而会需要存储一个高维度的矩阵,这就导致显存消耗比较严重,这里参考BevPool-V1中的思路将“lift”操作也适用并行化实现。其原理便是将深度特征和图像特征直接通过索引访问和并行求和得到最终BEV特征,在这样的操作下显存消耗可以节省约95%,其操作示意图见下图所示:
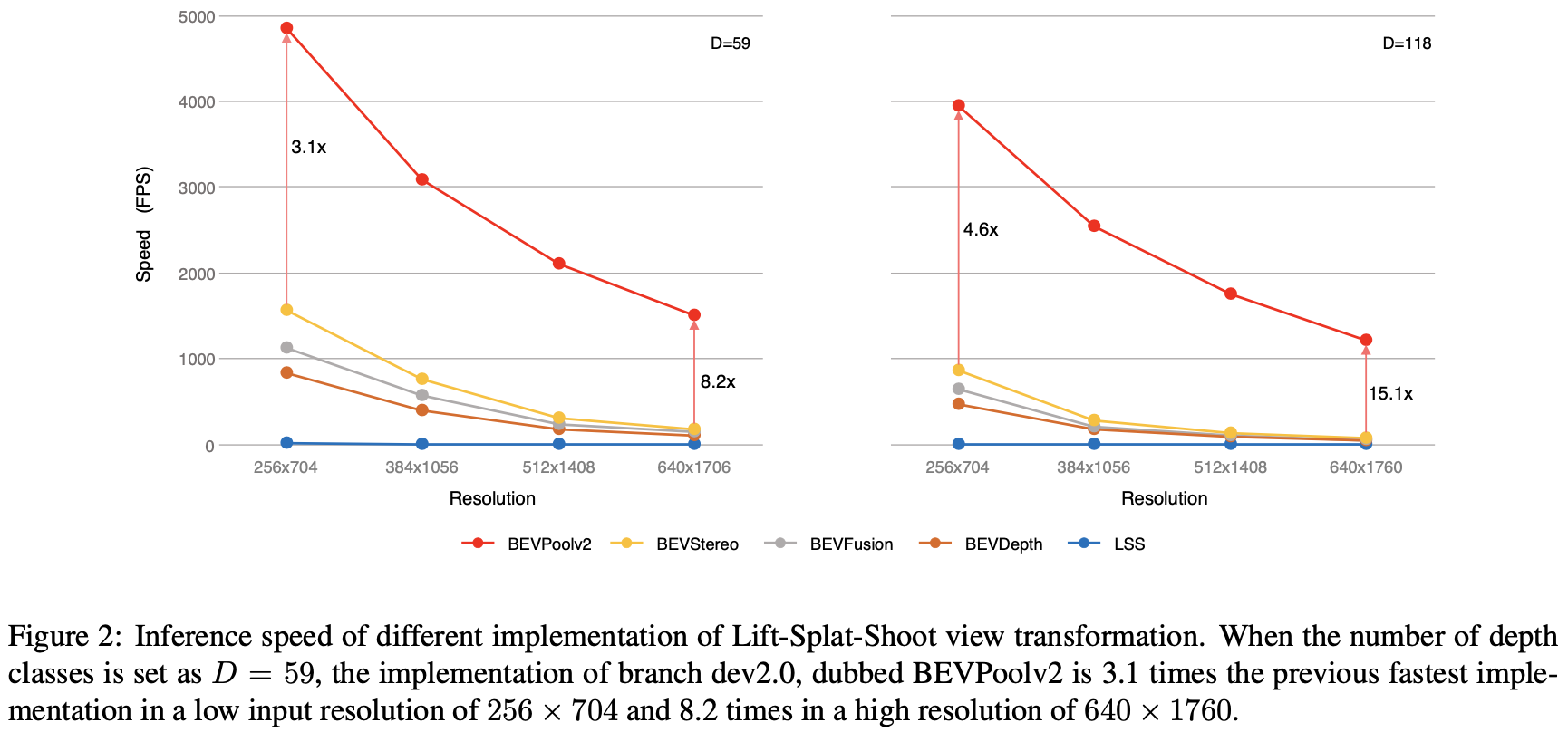
推理速度比较:
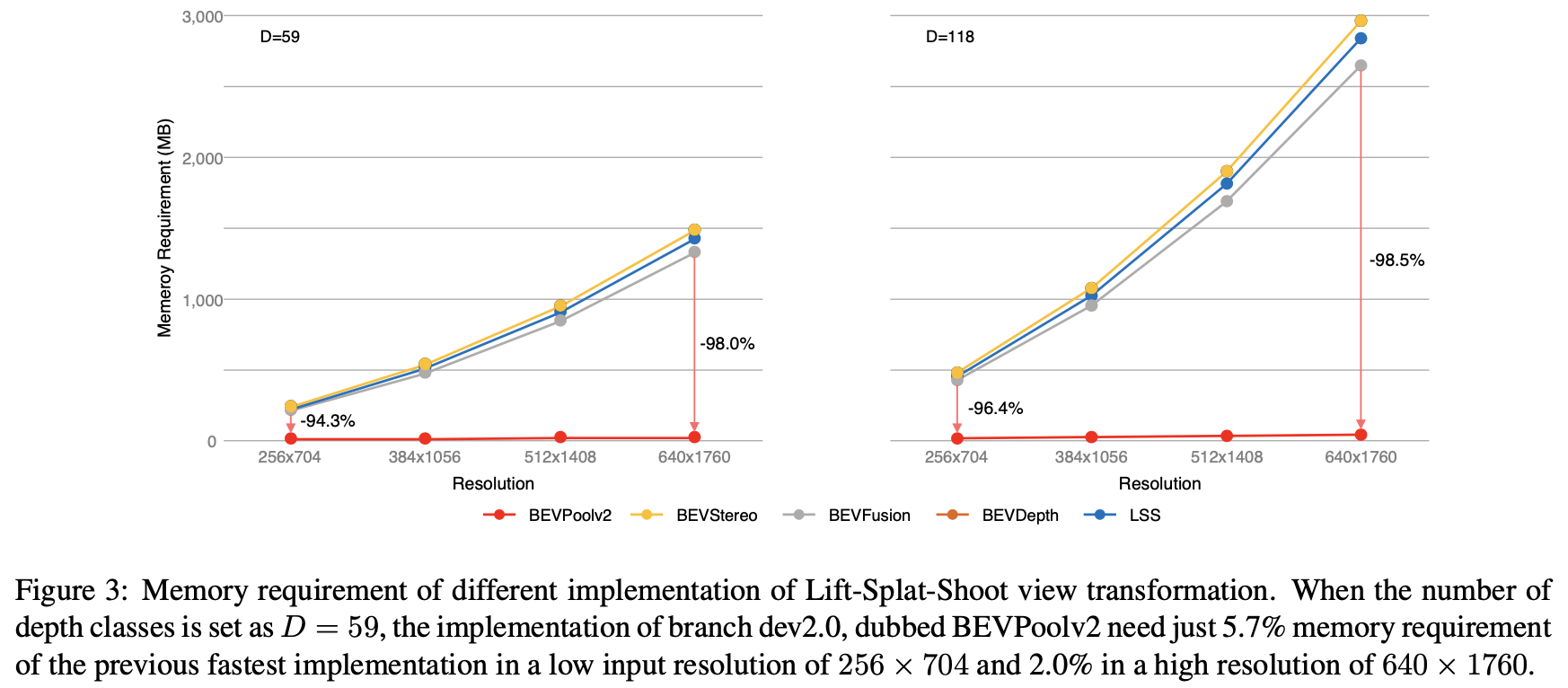
显存占用比较:
3. 实验结果
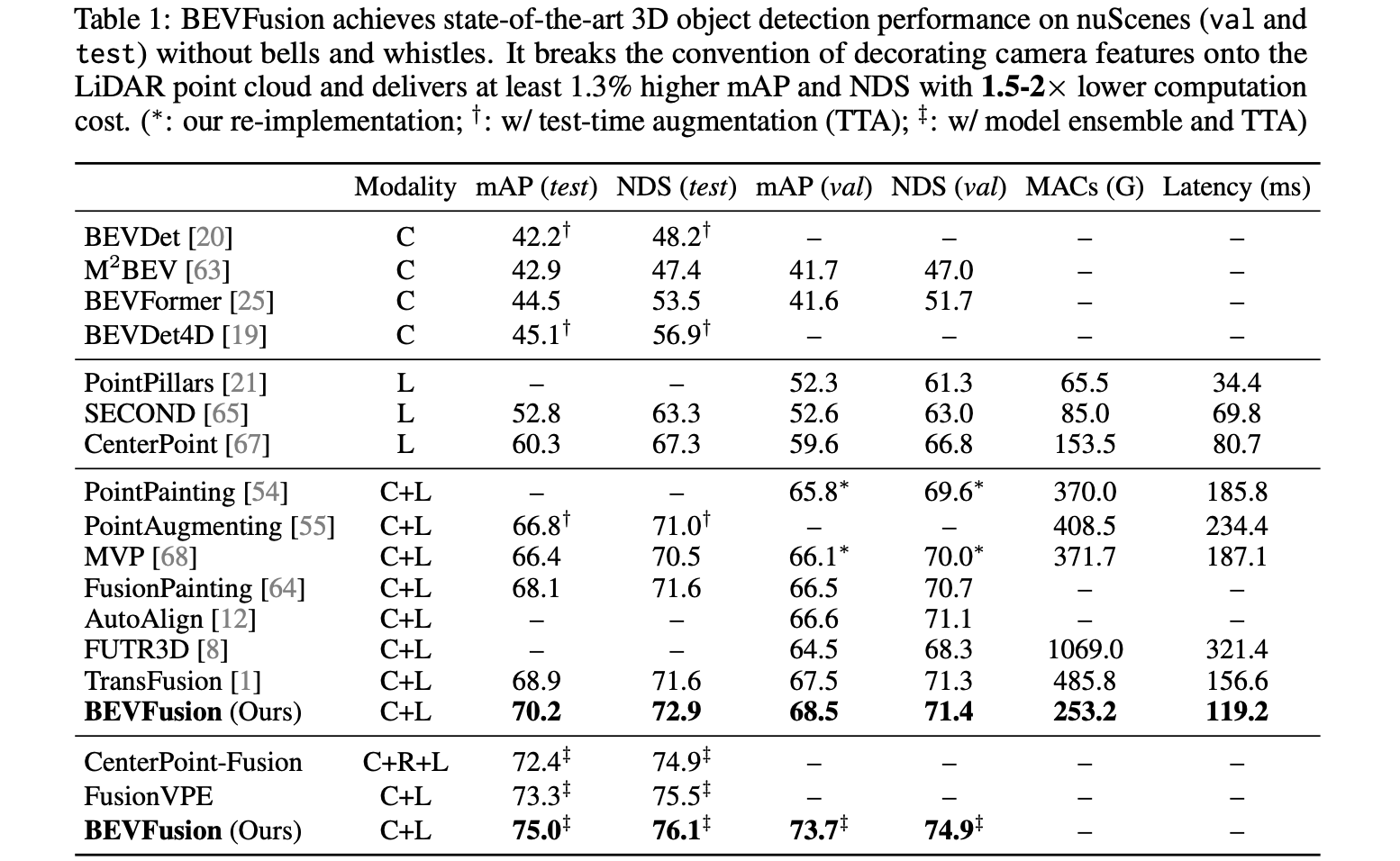
nuScenes 3D检测性能:
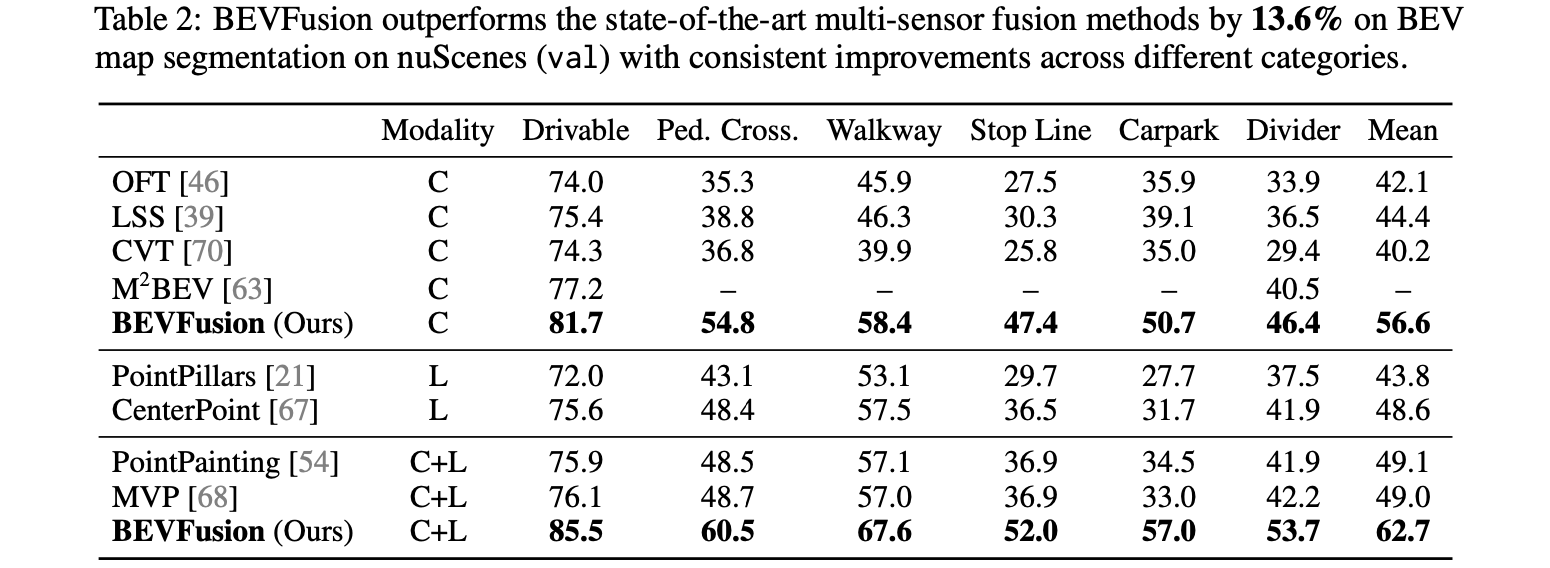
nuScenes分割性能:


















 2416
2416




 到【灌水乐园】发言
到【灌水乐园】发言







