







 本文探讨了一种在自监督深度估计算法中同时估计相机内参的方法,以增强模型对不同相机设置的泛化能力。通过在位姿网络中加入内参估计并整合到自监督流程,尽管初期训练可能较慢,但最终效果在某些情况下优于预设内参。文章还介绍了使用学习型上采样(PixelShuffle)改进解码器细节表现,以及权重加权的光度重构误差最小化策略。实验结果显示,这些改进提高了网络性能。
本文探讨了一种在自监督深度估计算法中同时估计相机内参的方法,以增强模型对不同相机设置的泛化能力。通过在位姿网络中加入内参估计并整合到自监督流程,尽管初期训练可能较慢,但最终效果在某些情况下优于预设内参。文章还介绍了使用学习型上采样(PixelShuffle)改进解码器细节表现,以及权重加权的光度重构误差最小化策略。实验结果显示,这些改进提高了网络性能。
参考代码:None
1. 概述
介绍:在之前的一些自监督深度估计算法中,往往需要知道相机的内参数作为预先输入。在某些实际场景下为了获得模型对场景的泛化能力,需要有效利用网络上的视频资源,但是其内参是各不相同的。为了使得这些数据能够被有效利用,一种直接的方法便是对相机内参也采用估计的形式得到,具体就是在位姿网络上添加对内参的估计,并参与到整个自监督网络中。这篇文章的工作正是验证该方法的可行性,并对深度估计的解码器部分使用“学习型上采样”进行优化,使得估计出的结果更加精准。
PS:文章的方法核心在于位姿估计网络中添加相机内参估计,并添加到整体自监督pipeline中去。这里本人在实际的数据集上进行测试确实也证明了该方案可行性,不过需要注意的是相比内参前期给出的方案,其在训练前期的收敛性是不如内参给定的场景的,不过在相同epoch训练完成之后,自测效果在一些case下更好一点。
2. 方法设计
2.1 整体pipeline
文章方法的整体pipeline见下图所示:
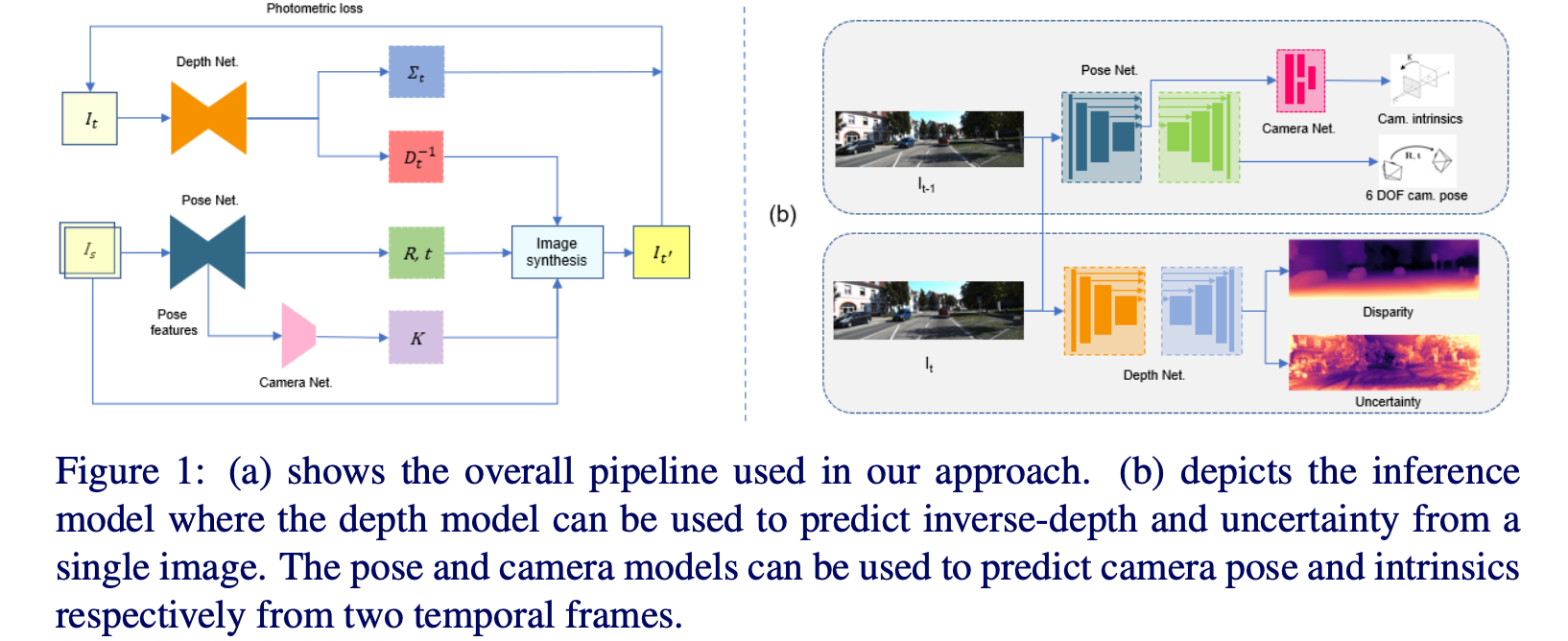
在上图中展示了文章方法pipeline,其深度估计网络输出inverse的深度和像素重要性权重,位姿估计网络输出相机位姿与相机内参,之后通过光度重构误差最小化完成自监督训练过程。
对于深度估计网络部分文章对其解码器部分中的上采样操作使用学习的方式实现,从而提升深度在细节的表达能力,该方法对应到Pytorch中便是nn.PixelShuffe()操作,可以参考:
TORCH.NN.MODULES.PIXELSHUFFLE
下图展示的是便是pixelshuffle在做超分辨率任务过程中像素重排列的过程:
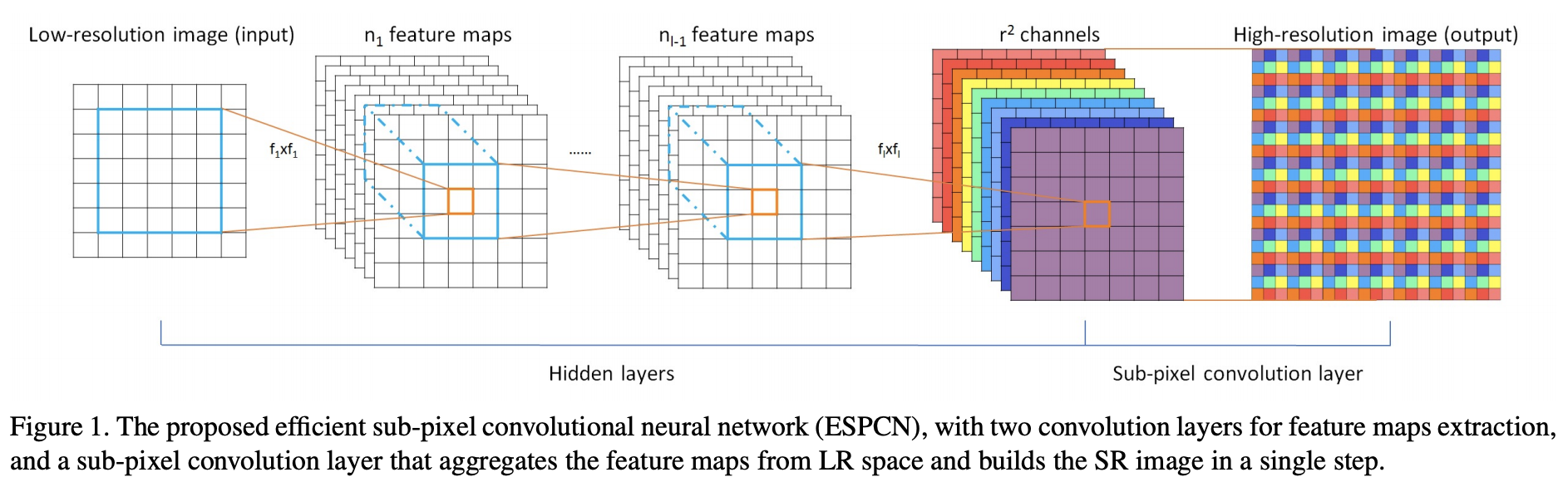
ref:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
此外,对应对应部分网络的初始化也是需要注意的细节,否则会产生较为明显地棋盘格效应,对此在参数初始化的时候需要格外注意,可以采用下面链接中的初始化方式进行缓解:
ICNR
其原理也是比较简单的也就是将之前参数在随机位置处初始化换成了对应超分方格使用同一参数初始化,也就是如下图中的样子:
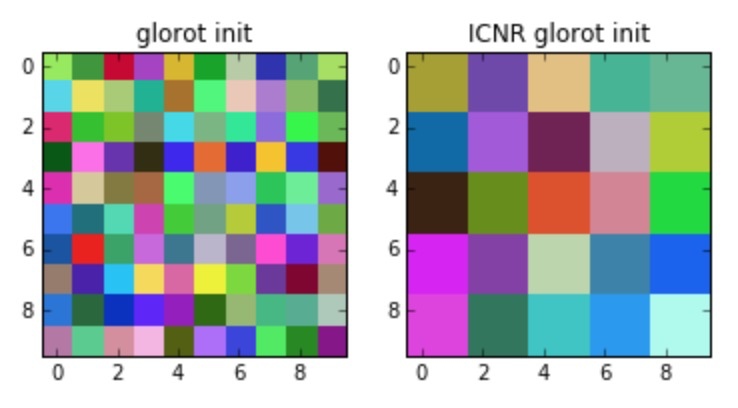
ref:Checkerboard artifact free sub-pixel convolution
上述图中的参数初始化过程在numpy环境下可以使用repeat()实现:
kernel_data_np = np.random.random((2, 1, 3, 3))
kernel_data_np_r = np.repeat(kernel_data_np, 2, axis=0)
print(kernel_data_np)
print(kernel_data_np_r)
那么在Pytorch环境下可以使用下面的这个函数实现:
TORCH.REPEAT_INTERLEAVE
2.2 自监督约束
在自监督的过程中为了避免光照问题对自监督过程带来影响,这里通过预测每个像素权重的形式对自监督光度重构误差进行加权,该加权mask可以描述
∑
t
∈
[
0
,
1
]
\sum_t\in[0,1]
∑t∈[0,1],则这里的光度重构误差可以描述为:
L
p
(
I
t
,
I
s
)
∗
=
min
I
s
L
p
(
I
t
,
I
t
′
)
2
∑
t
2
+
1
2
l
o
g
∑
t
+
1.5
L_p(I_t,I_s)^*=\frac{\min_{I_s}L_p(I_t,I_{t^{'}})}{2\sum_t^2}+\frac{1}{2}log\sum_t+1.5
Lp(It,Is)∗=2∑t2minIsLp(It,It′)+21logt∑+1.5
对于其它的automask机制、深度平滑约束也是参考MonoDepth2的实现。
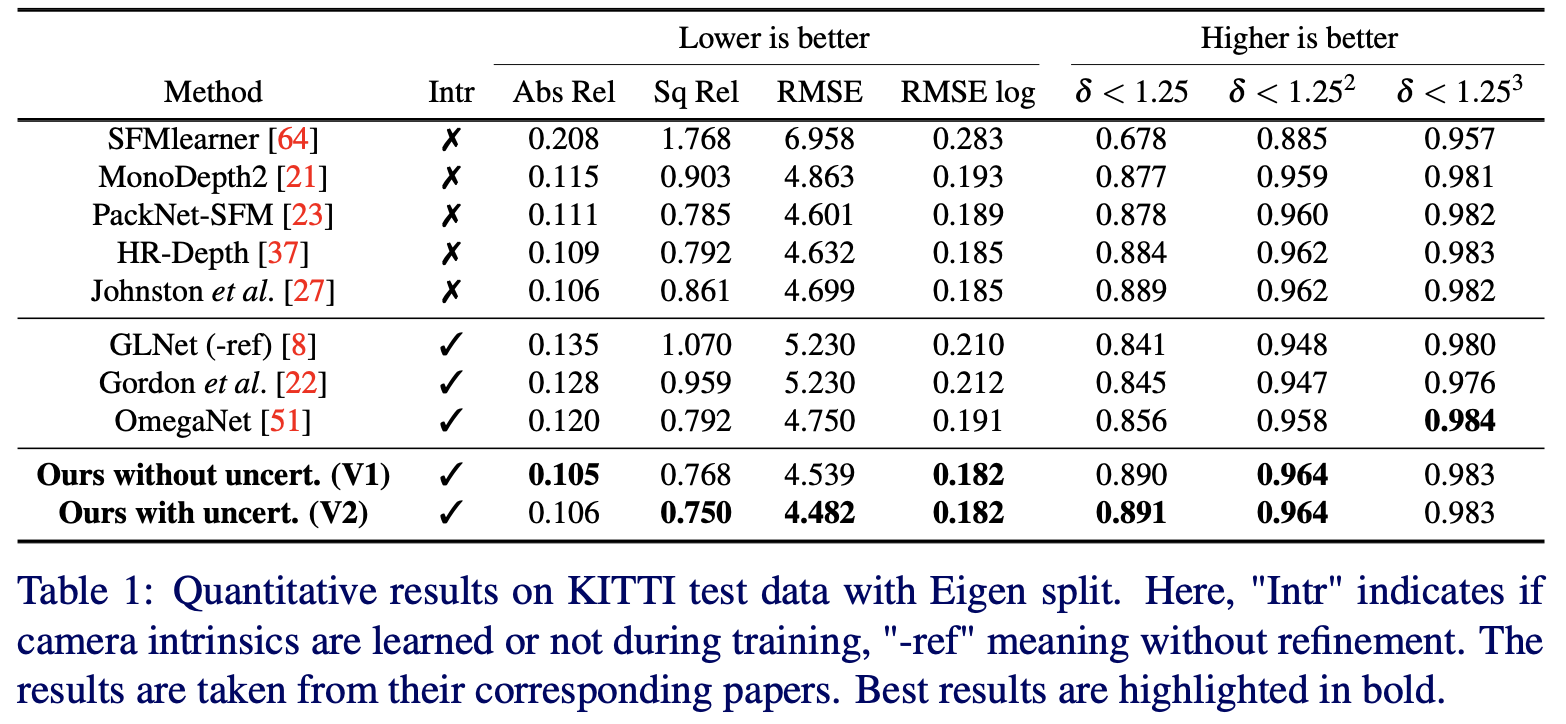
则文章的几点改进(相机内参学习、pixelshuffle上采样、像素损失加权)给网络带来的性能影响见下表:
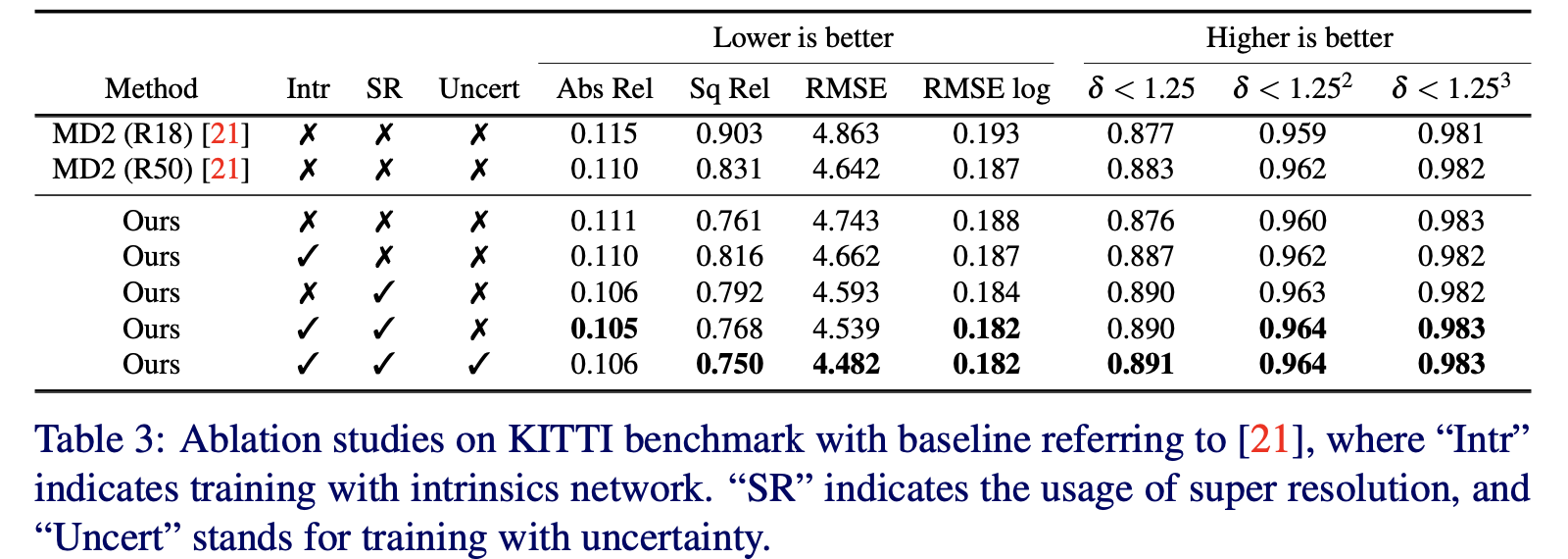
3. 实验结果
文章的方法在相同分辨率条件下与其它一些方法的性能比较:
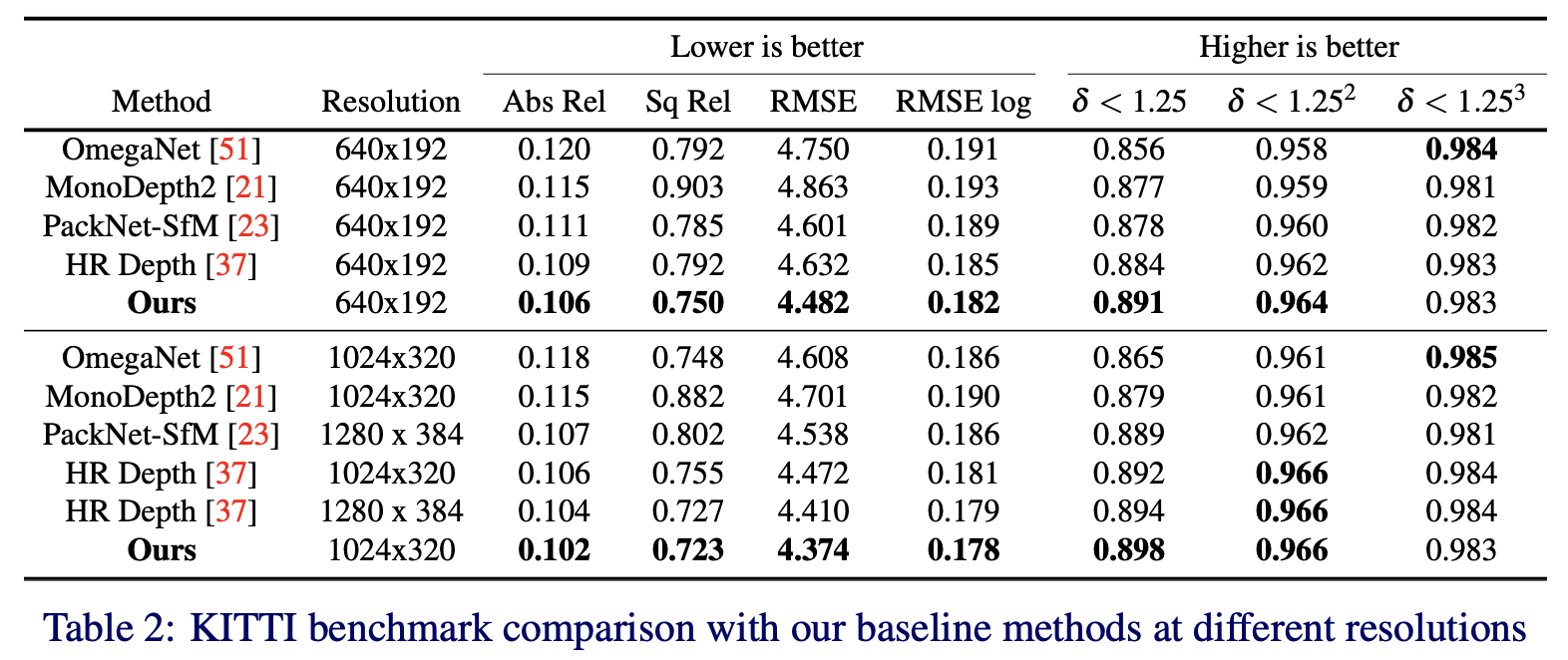
不同分辨率下的性能:

















 6311
6311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









