




 本文介绍了基于2D Haar小波分解的单图像深度预测方法,利用频域分析关注深度图的高频特征,减少计算量。网络在低分辨率下预测深度和小波分量,然后通过mask优化高频分量,实现深度恢复。这种方法在自监督和全监督场景下均表现出色,并在KITTI和NYU数据集上得到验证。
本文介绍了基于2D Haar小波分解的单图像深度预测方法,利用频域分析关注深度图的高频特征,减少计算量。网络在低分辨率下预测深度和小波分量,然后通过mask优化高频分量,实现深度恢复。这种方法在自监督和全监督场景下均表现出色,并在KITTI和NYU数据集上得到验证。
参考代码:wavelet-monodepth
1. 概述
导读:对一幅深度图进行分析可以观察到其是由一些平滑区域和边缘区域组合起来的,对应的可以参考频域中的低频和高频分量。而这篇文章正是提出一种基于频域分析(2D haar小波分析)的深度估计算法,不同于直接监督深度图的频域分解分量,文章的方法通过对分辨率最小的深度图进行监督,之后通过在网络的不同层级上预测频域的分量,使得可以从分辨率最小尺度下进行逆频域变换得到对应的深度结果(也就是深度的频域分量不直接参与回归,而是通过将不同频域的不同分量组合得到的深度图进行监督)。此外,文章还提出了一种稀疏预测的策略,通过频域分析重点关照深度图中的高频部分,对于低频部分就使用上采样操作进行实现,从而可以通过重点关照的形式减少计算量。在文章中将该方法运用到了自监督和全监督的方法中,也取得了一定的成效。文章的方法将频域分析的思路引进CNN网络中,或许会对后期其它任务带来一些启发作用,但是其本质带来的性能提升相比较起来并没有那么突出。
2. 方法设计
2.1 网络结构
对于2D小波分析文章使用的是下面的工具:
下面这图幅展示的便是深度图经过2D小波分解之后得到的结果:
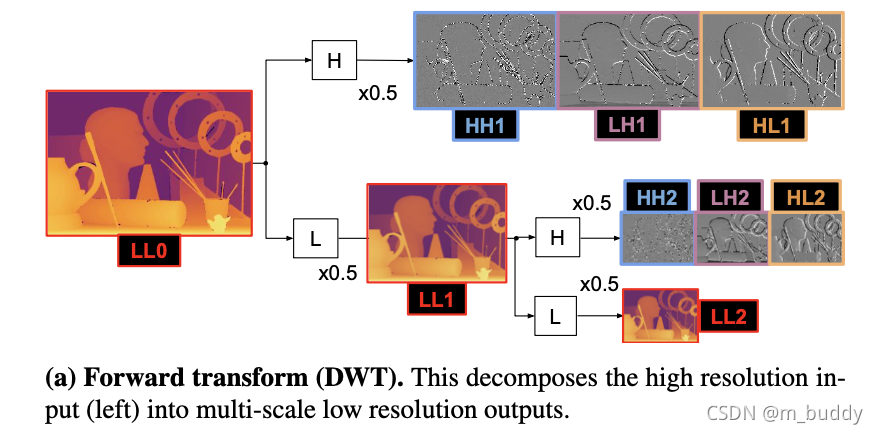
同样的经过小波逆变换之后可以恢复原来的深度结果:
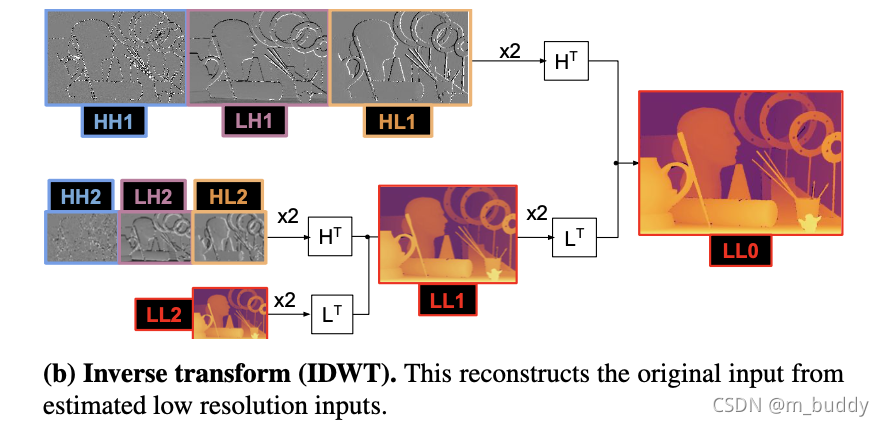
对此,文章将方法设计成为一个编解码形式的结构,见下图所示:
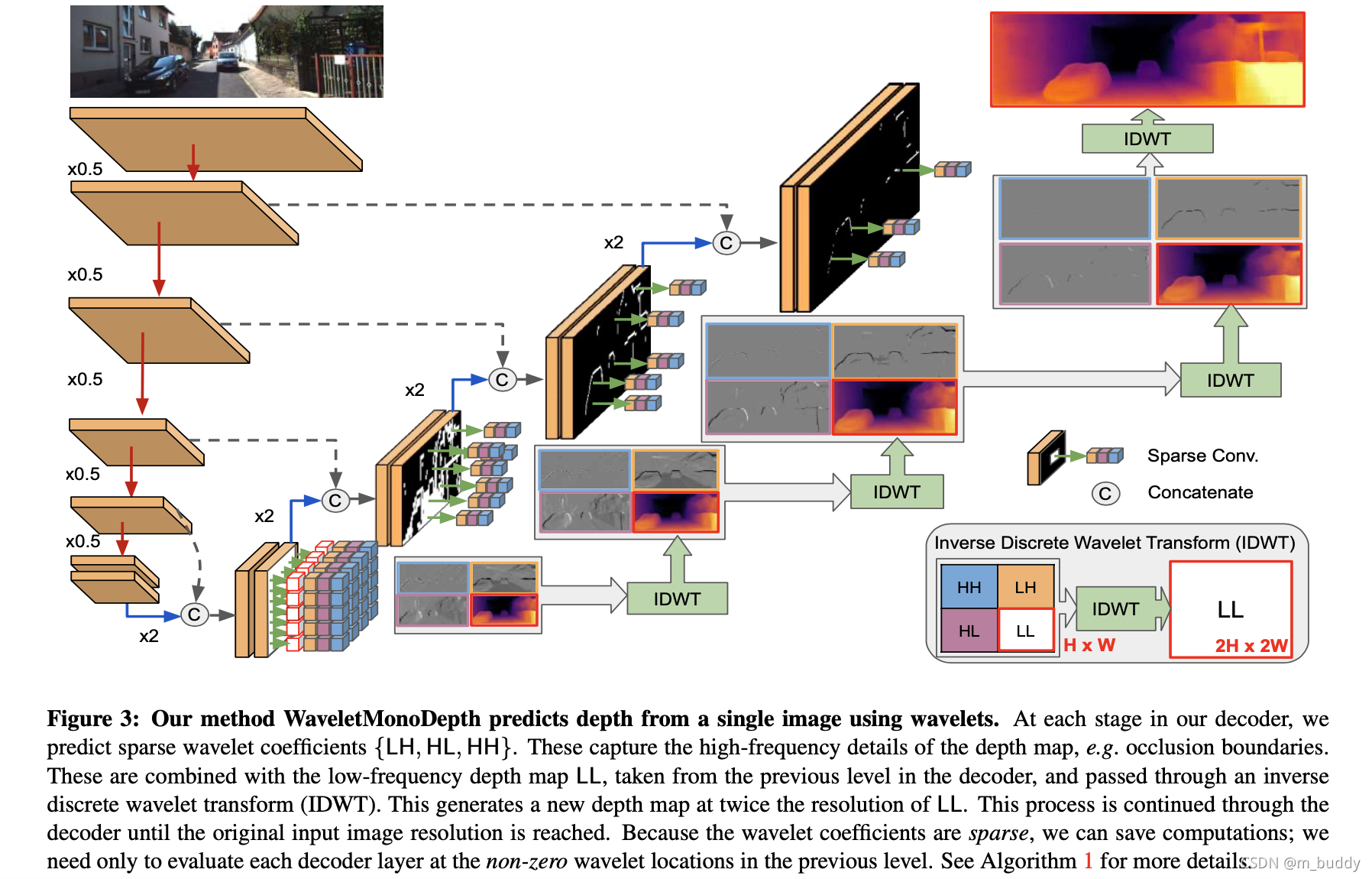
从上面的可以看出该方法是在低分辨率下预测深度和小波分量,之后在更大的尺度上通过mask选择的形式对高频分量进行优化,从而得到最后的深度结果。
2.2 实现细节
其具体的实现过程可以参考下面位置处的代码实现:
# NYUv2/networks/decoders/densedepth_decoder.py#L224
class SparseDecoderWave(nn.Module):
…
在深度图的预测阶段采用的是稀疏过滤的形式,整体的流程可以参考下面的算法:

对于上述算法中mask的确定参考:
# NYUv2/networks/decoders/densedepth_decoder.py#L316
thresh = (ll.max() - ll.min()) * thresh_ratio
mask = (torch.abs(h).max(2)[0] > thresh).float()
在得到阈值确定的mask之后,接下来就是对高频的稀疏点进行细化预测(同时会带来文章提到的减少MAC的作用):
# NYUv2/networks/decoders/densedepth_decoder.py#L344
xvals, xchn, ops = sparse_conv3x3(self.up2.convA, xvals, conva_idxmap,
wave_mask, nonlin=self.leakyreluA,
padding=self.sparse_padding, make_result=False)
total_ops += ops
h, ops = sparse_conv3x3(self.wave2, xvals, wave_idxmap,
wavelet_mask, nonlin=nn.Identity(), padding=self.sparse_wave_pad, make_result=True)
对于网络的损失函数全部是在对应尺度上进行L1损失。
3. 实验结果
除了上述文章提到的监督的深度估计网络,文章还将其运用到自监督领域,其在KITTI数据集上使用相互映射形式自监督得到的结果为:
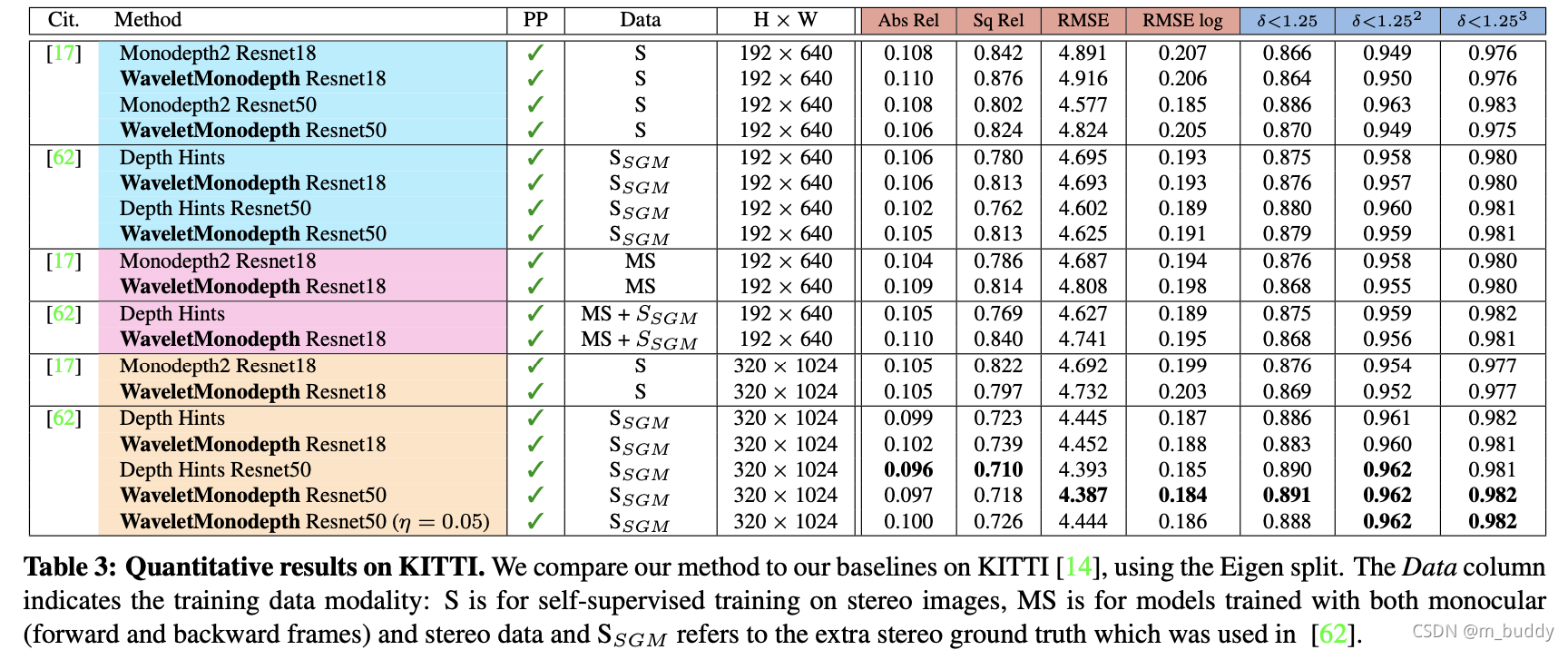
NYU数据集:



















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









