




 本文深入探讨了MGMatting论文,该方法通过额外的引导信息和逐步细化网络提高图像细化效果。文章介绍了Pipeline、Progressive Refinement Network、数据增强和前景预测等关键设计,并展示了实验结果。
本文深入探讨了MGMatting论文,该方法通过额外的引导信息和逐步细化网络提高图像细化效果。文章介绍了Pipeline、Progressive Refinement Network、数据增强和前景预测等关键设计,并展示了实验结果。
参考代码:MGMatting
1. 概述
导读:在这篇文章中提出了基于引导(guidance)的matting方法,其引导主要体现为extra-guidance和self-guidance。其中extra-guidance是通过在输入端添加三色图/分割mask/低质量alpha图,从而给网络以先验知识。对于self-guidance是在decoder的不同stage上通过添加PRN(Progressive Refinement Network)实现的,其中会将上一个stage的输出作为当前stage的guidance从而去引导不透明区域的回归。对于matting中的另外一个前景问题,文章通过另外的编解码网络去预测,从而将alpha和前景预测解耦从而得到更好的效果,此外还通过Random Alpha Blending (RAB)融合操作,得到更好更丰富的合成数据,帮助前景预测性能进一步提升。在文章的git仓库中提到可能会开源所使用的额外matting数据,有兴趣的朋友可以继续留意看看。
文章的方法并没有直接在原始图像上直接做matting,而是给予了mask引导(extra-guidance)从而提供了更好的先验知识,使得最后的结果更加鲁棒。通过self-guidance似的模型可以更加关注半透明区域,从而提升细节上的表现力。下图是其效果展示:

2. 方法设计
2.1 pipline
文章的方法pipline见下图所示:
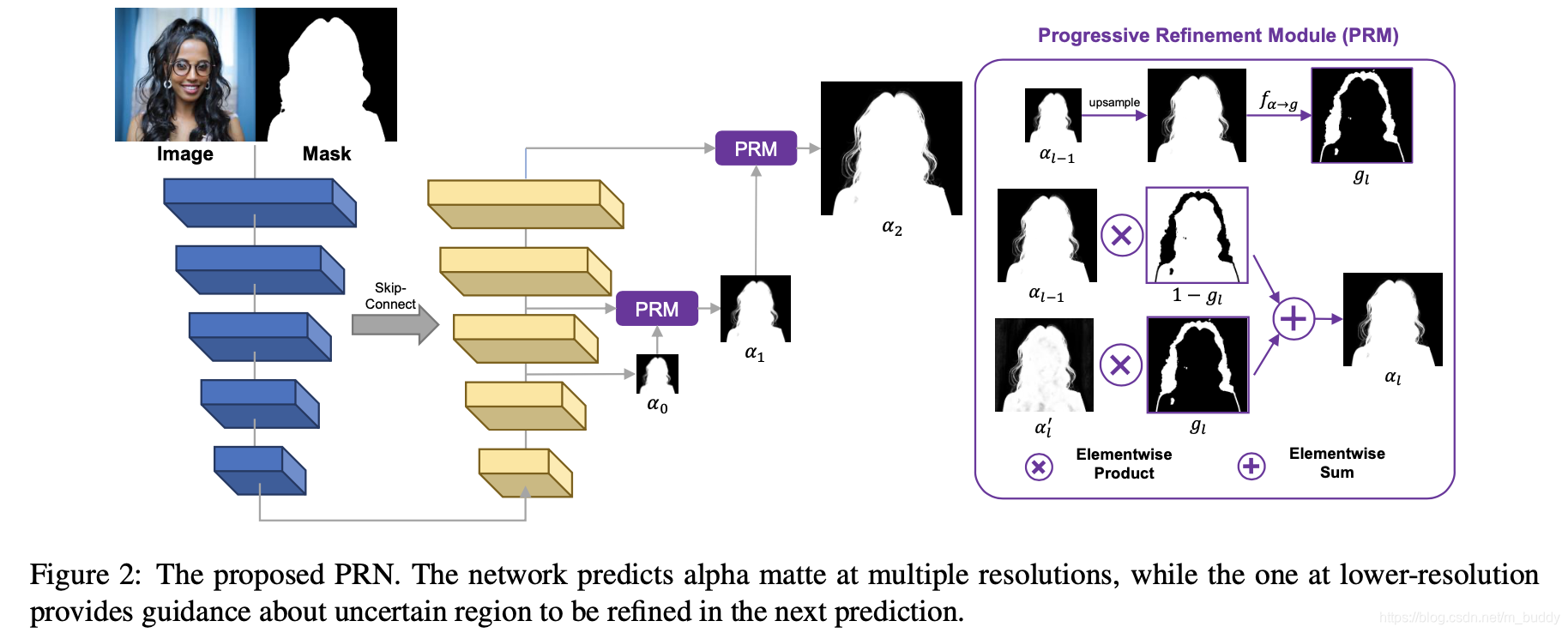
其结构是一个典型的U型网络结构,输入是原始数据加上extra-guidance,在decoder的部分使用PRN进行半透明区域进一步挖取。
2.2 Progressive Refinement Network
这部分网络在整个pipline里面作为self-guidance的存在。它是在decoder中通过前一层的输出与当前层的输出进行融合处理,得到更加半透明区域更加精细的预测结果。在decoder中的输出表示为
α
l
\alpha_{l}
αl,其会通过下面的计算过程得到引导
g
l
g_l
gl:
f
α
l
−
1
→
g
l
(
x
,
y
)
=
{
1
,
i
f
0
<
α
l
−
1
(
x
,
y
)
<
1
0
,
o
t
h
e
r
w
i
s
e
f_{\alpha_{l-1}\to g_l}(x,y) = \begin{cases} 1, & if\ 0\lt\alpha_{l-1}(x,y)\lt 1\\ 0, & otherwise \end{cases}
fαl−1→gl(x,y)={1,0,if 0<αl−1(x,y)<1otherwise
记当前层的alpha输出为
α
‘
\alpha^{‘}
α‘,则当前层的alpha输出描述为:
α
l
=
α
l
‘
g
l
+
α
l
−
1
(
1
−
g
l
)
\alpha_l=\alpha_l^{‘}g_l+\alpha_{l-1}(1-g_l)
αl=αl‘gl+αl−1(1−gl)
在文中这样的PRN有两个,最初始的
g
0
g_0
g0是全1的,也就是结果的全部都会去参与损失的计算。
对于decoder的每一层其输出的损失函数描述为:
L
α
^
,
α
=
L
l
1
(
α
^
,
α
)
+
L
c
o
m
p
(
α
^
,
α
)
+
L
l
a
p
(
α
^
,
α
)
L_{\hat{\alpha},\alpha}=L_{l1}(\hat{\alpha},\alpha)+L_{comp}(\hat{\alpha},\alpha)+L_{lap}(\hat{\alpha},\alpha)
Lα^,α=Ll1(α^,α)+Lcomp(α^,α)+Llap(α^,α)
则多个层的损失函数合起来为:
L
f
i
n
a
l
=
∑
l
w
l
L
(
α
^
⋅
g
l
,
α
⋅
g
l
)
L_{final}=\sum_lw_lL(\hat{\alpha}\cdot g_l,\alpha\cdot g_l)
Lfinal=l∑wlL(α^⋅gl,α⋅gl)
其中,
w
0
:
w
1
:
w
2
=
1
:
2
:
3
w_0:w_1:w_2=1:2:3
w0:w1:w2=1:2:3。
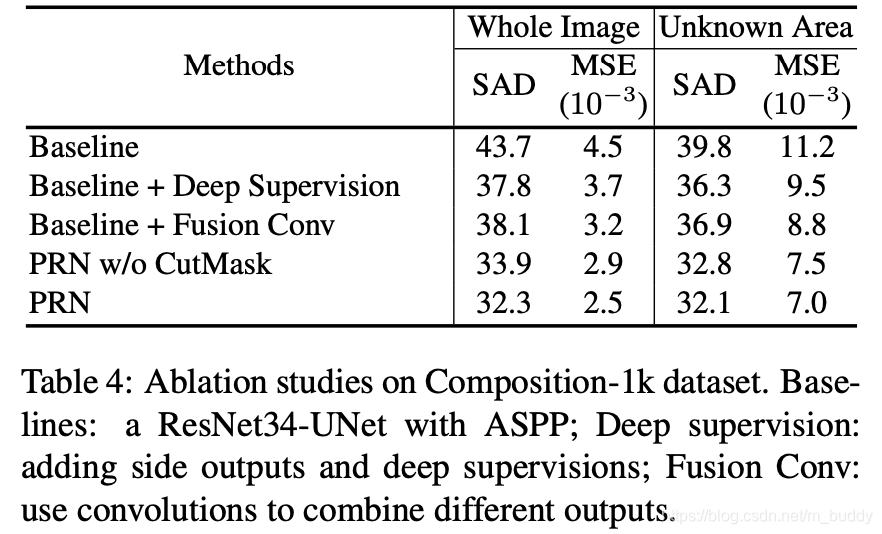
文章的PRN网络与其它类型的融合方法的比较:
2.3 数据增广
输入图片数据增广:
这里采用随机两张前景组合/随机缩放/随机采样方法/随机仿射变换/随机512剪裁/添加COCO背景。
guidance的数据增广:
extra部分:
文章为了网络能够适应各式各样的guidance,文章提出一些数据增强的措施:
- 1)将输入的GT alpha图按照随机阈值进行二值化,之后对得到的二值化mask进行kernel为1~30随机大小的膨胀腐蚀操作;
- 2)参考CutMix的数据增广策略,剪裁出两个原图大小1/4到1/2的小块进行交叠融合,文章将其取名为CutMask;
self部分:
对于self-guidance部分为了增强其鲁棒性,文章也对其进行了数据增广,对于stride=8处生成的alpha图采样kernel为
K
1
∈
[
1
,
30
]
K_1\in [1,30]
K1∈[1,30]的腐蚀操作,在stride为4处采用kernel为
K
2
∈
[
1
,
15
]
K_2\in [1,15]
K2∈[1,15]的腐蚀操作。而在infer的时候将
K
1
=
15
,
K
2
=
7
K_1=15,K_2=7
K1=15,K2=7。
2.4 前景预测
在matting任务中除了要预测alpha还需要得到前景图,这里文章单独使用了一个编解码网络进行预测,虽然同一个网络可以同时预测前景和alpha图,文章指出这样会使得matting的性能下降。对于现有的前景图预测却面临如下的困难:
- 1)可使用的数据量较少;
- 2)现有使用Photoshop工具生成的前景区域是存在噪声和边界不准确的,如图3:

这就会导致产生彩色块和其他认为因素的引入,因而导致训练的不稳定; - 3)现有的前景预测都是在alpha图中值大于0的区域进行的,而那些未被监督区域的结果是未定义的;
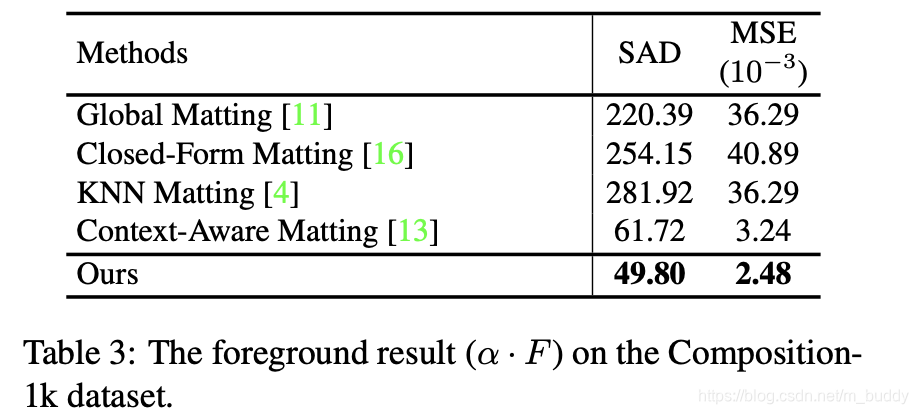
对此文章首先通过随机选择前景和背景,之后在alpha图上进行随机选取,从而去丰富训练数据,从而增强其泛化能力,这里使用到的损失函数与alpha图监督的损失函数是一致的。而且文章是在整图上进行前景预测。下图4比较了文章的方法和之前一些方法:

性能比较:
3. 实验结果
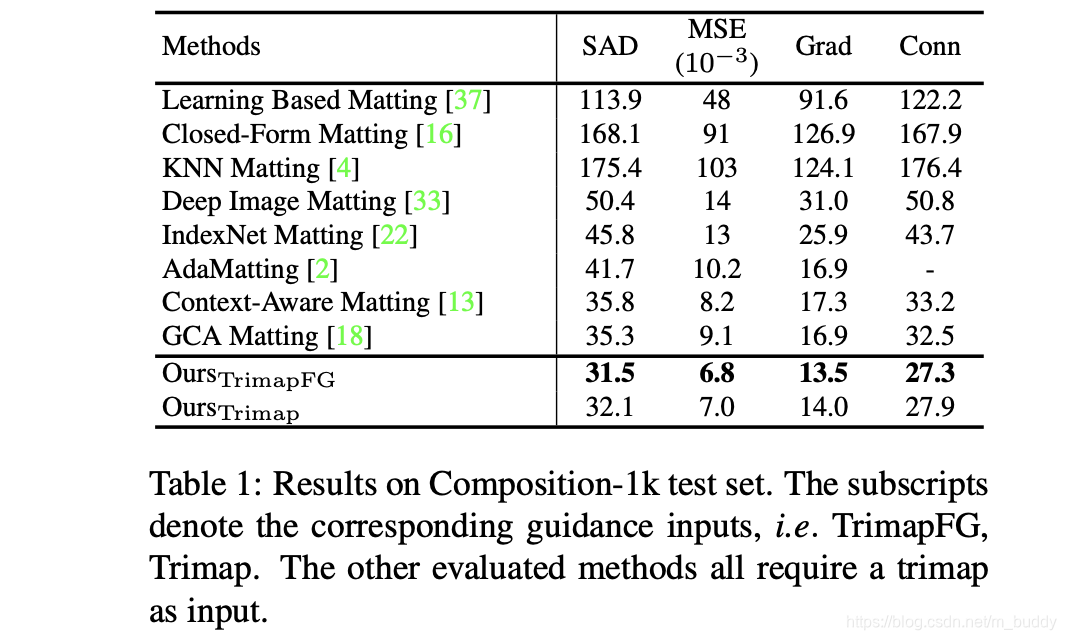
Composition-1k test性能:
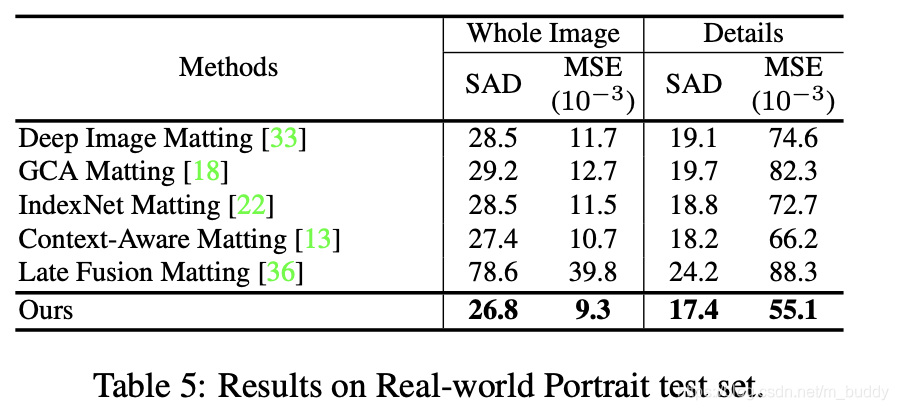
人像分割性能比较:


















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









