




 本文介绍了《SELF-ADAPTIVE NETWORK PRUNING》论文,提出了一种新的通道剪枝算法。通过嵌入SPM模块,计算特征图的显著性并确定重要通道,结合二值化函数和损失函数,动态调整网络结构,以数据驱动的方式优化剪枝比例。实验结果显示,该方法在CIFAR-10和CIFAR-100数据集上取得了良好的效果。
本文介绍了《SELF-ADAPTIVE NETWORK PRUNING》论文,提出了一种新的通道剪枝算法。通过嵌入SPM模块,计算特征图的显著性并确定重要通道,结合二值化函数和损失函数,动态调整网络结构,以数据驱动的方式优化剪枝比例。实验结果显示,该方法在CIFAR-10和CIFAR-100数据集上取得了良好的效果。
参考代码:无
1. 概述
导读:这篇文章提出了一种channel剪枝的算法,在网络中通过嵌入SPM(Saliency-and-Pruning Module )模块得到卷积过程中重要的channel,之后通过一个阈值得到一个二值标志序列,之后通过将其中为0的位置“置0”从而达到网络剪枝的目的。CNN中重要的channel是通过计算特征图自身的特性(文章中为均值)之后连接一个fc得到的,之后给定一个期待的计算量开销目标,之后在训练的过程中将网络现有的开销与期望的开销计算损失,从而约束CNN网络中的channel数量。
文章的作者在一些基于分类的任务中发现了如下的亮点规律:
- 1)对于CNN网络中的每一层卷积其适用的剪裁比例是不一致的,因而使用固定比例的方式进行剪枝是次优的,应该以数据驱动;
- 2)在CNN分类网络中其实卷积中只有很少的一部分channel对某一类别有较强的反应(特征图的统计意义上),那么这就说明其中是存在较大的冗余的,是存在剪枝的空间的;
上述的两点观察可以从下图看出:

2. 方法设计
2.1 网络结构
文章提出的剪枝整体pipline见下图所示:

在上图中文章通过在每个卷积层上添加SPM模块提取出显著性(重要)的channel:
s
l
(
x
l
−
1
)
=
S
a
l
i
e
n
c
y
P
r
e
d
i
c
t
i
o
n
(
x
l
−
1
,
W
)
s^l(x^{l-1})=SaliencyPrediction(x^{l-1},W)
sl(xl−1)=SaliencyPrediction(xl−1,W)
其中,
x
l
−
1
x^{l-1}
xl−1是上一层卷积输出的特征图。之后将这些显著性channel(经过阈值)得到需要剪除的部分:
b
l
(
x
l
−
1
)
=
B
i
n
a
r
i
z
e
(
x
l
−
1
)
b^l(x^{l-1})=Binarize(x^{l-1})
bl(xl−1)=Binarize(xl−1)
在得到上述的二值序列掩膜之后,便是与之前的重要性置信度组合起来,从而这一层的卷积输出描述为:
x
l
=
s
l
(
x
l
−
1
)
⋅
b
l
(
x
l
−
1
)
⋅
B
a
t
c
h
N
o
r
m
(
f
l
∗
x
l
−
1
)
x^l=s^l(x^{l-1})\cdot b^l(x^{l-1})\cdot BatchNorm(f^l*x^{l-1})
xl=sl(xl−1)⋅bl(xl−1)⋅BatchNorm(fl∗xl−1)
其中,
f
l
f^l
fl是当前层的卷积参数。之后通过二值化的结果计算一个开销损失,从而与原本的损失函数进行联合训练。
2.2 channel重要性度量函数
在文章中对于channel重要性的度量是通过计算特征图在channel上的均值,之后经过一个FC层得到的,首先计算其均值:
d
=
1
H
l
−
1
∗
W
l
−
1
∑
i
=
1
H
l
−
1
∑
j
=
1
W
l
−
1
x
l
−
1
(
i
,
j
)
d=\frac{1}{H_{l-1}*W_{l-1}}\sum_{i=1}^{H_{l-1}}\sum_{j=1}^{W_{l-1}}x^{l-1}(i,j)
d=Hl−1∗Wl−11i=1∑Hl−1j=1∑Wl−1xl−1(i,j)
之后再将其与一个FC连接得到预测结果:
s
l
(
x
l
−
1
)
=
S
a
l
i
e
n
c
y
P
r
e
d
i
c
t
i
o
n
(
x
l
−
1
,
W
)
=
W
2
δ
(
W
1
d
)
s^l(x^{l-1})=SaliencyPrediction(x^{l-1},W)=W_2\delta(W_1d)
sl(xl−1)=SaliencyPrediction(xl−1,W)=W2δ(W1d)
其中,
δ
\delta
δ是ReLU。
2.3 重要性二值函数
通过上面的内容得到重要性置信度之后,文章引入了一个二值函数用以区分那些channel是需要保留的,反之就需要被剪枝。在训练的过程中文章引入了高斯噪声
ξ
∼
N
(
0
,
1
)
C
l
\xi\sim N(0,1)^{C_l}
ξ∼N(0,1)Cl,从而得到:
s
1
=
m
a
x
(
0
,
m
i
n
(
1
,
a
⋅
σ
(
s
l
(
x
l
−
1
)
+
ξ
)
−
b
)
)
s_1=max(0,min(1,a\cdot\sigma(s^l(x^{l-1})+\xi)-b))
s1=max(0,min(1,a⋅σ(sl(xl−1)+ξ)−b))
其中,
σ
\sigma
σ是sigmoid函数,
a
,
b
a,b
a,b是超参数。之后通过一个设定的阈值得到二值化的掩膜序列:
s
2
=
1
(
s
1
>
0.5
)
s_2=\mathcal{1}(s_1\gt0.5)
s2=1(s1>0.5)
2.4 网络损失函数
除了分类网络自身的分类损失之外,文章还对网络的开销进行损失监督(这部分监督可以看作是在网络channel上去做L1正则化,使其稀疏化),其损失函数描述为:
L
m
u
l
t
i
=
L
c
l
s
+
λ
1
N
c
∑
l
=
1
L
∣
∣
s
l
∣
∣
1
L_{multi}=L_{cls}+\lambda\frac{1}{N_c}\sum_{l=1}^L||s^l||_1
Lmulti=Lcls+λNc1l=1∑L∣∣sl∣∣1
其中,
λ
\lambda
λ是通过
p
t
p_t
pt(网络估计出来剪枝之后的开销)
p
0
p_0
p0(网络的总开销)
p
p
p(目标开销)参数组合得到的,其是一个变化的比例,其表示为:
λ
=
λ
0
⋅
(
p
t
−
p
)
p
0
\lambda=\lambda_0\cdot\frac{(p_t-p)}{p_0}
λ=λ0⋅p0(pt−p)
3. 实验结果
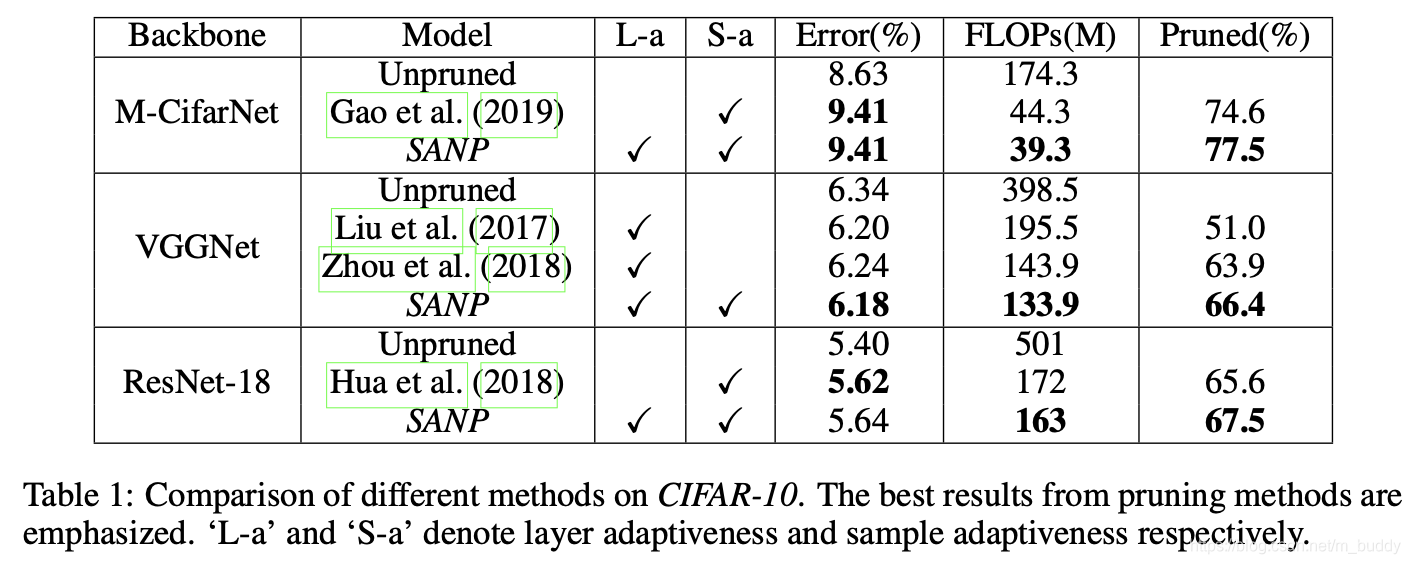
CIFAR-10:
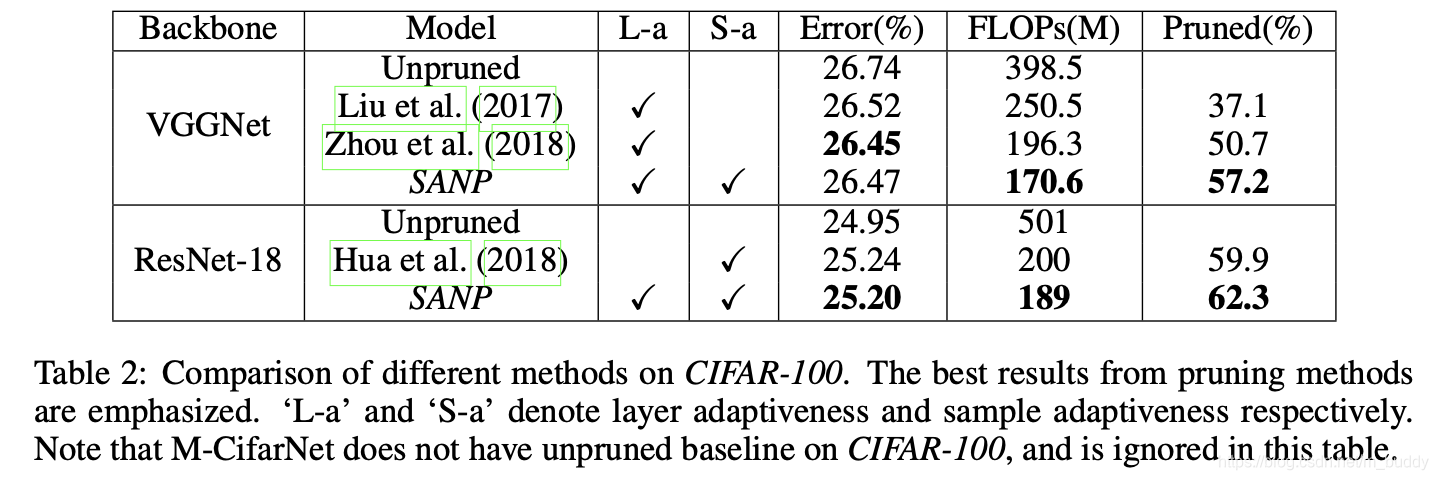
CIFAR-100:

















 2521
2521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









