




 本文详细解析了DFC-Net,一种利用深度学习和光流信息进行视频修复的方法。DFC-Net通过估计和级联优化光流,引导视频中已知区域的信息填补缺失部分,实现了视频的连续性修复。网络结构包括Deep Flow Completion Subnetwork(DFC-S),采用ResNet-50作为编码器,并通过困难样本挖掘优化损失函数,提升了修复效果。
本文详细解析了DFC-Net,一种利用深度学习和光流信息进行视频修复的方法。DFC-Net通过估计和级联优化光流,引导视频中已知区域的信息填补缺失部分,实现了视频的连续性修复。网络结构包括Deep Flow Completion Subnetwork(DFC-S),采用ResNet-50作为编码器,并通过困难样本挖掘优化损失函数,提升了修复效果。
参考代码:DFC-Net
1. 概述
导读:这篇文章分析的是视频领域的inpainting,这篇文章充分使用了视频内在的空间(指一帧图像中的内容)与时序(不同视频帧)信息,以及视频帧之间生成的光流信息实现了一个保持视频内在连续的修补方法,文章将其称为DFC-Net(Deep Flow Completion network)。该方法首先通过前后视频帧之间的光流关系推断缺失区域的合成光流估计信息(估计光流信息比直接估计缺失部分的RGB信息更为简单)。之后后续的pipline根据这个合成光流估计信息引导视频中与缺失区域相关的信息去进行填充,并且光流估计这个过程通过一个coarse-to-fine的逐渐优化过程的(后面包含两个级连优化),其中还会使用类似困难样本挖掘的hard flow example mining方法去进一步优化生成的结果。文章的方法整体上采用CNN的pipline从而避免了填充过程中进行优化的问题,并且inpainting的效果也能得到保证,兼顾了速度与修补质量。
在之前的工作中,对于视频缺失目标的处理采用的方法有:
- 1)采样之后最小化问题:这是通过在spatial与spatial-temporal上进行采样之后将已知区域的信息贴到位置区域上之后再通过优化算法进行优化,但是这样的方法处理起来计算量大并且对于视频场景复杂的时候效果就很差,见图1的b图所示;
- 2)基于单图inpainting的迁移:这类方法是使用单张图像的inpainting算法引入到视频领域中,一方面直接使用图片的方法会导致修复的效果较差。另一方面通过3D卷积实现的修补方式对于视频序列而言在显存上就不存在计算可行性,这类方法的效果见图1的c图所示;

而在这篇文章中将光流信息引入,使用一个光流信息估计网络去估计缺失的光流信息(相对来说容易),之后进而使用估计出来的光流信息去引导缺失部分信息的补全,这个过程是级连coarse-to-fine的,并且还引入了hard flow example mining的方法进一步提升补全的性能,其结果见图1的d图所示。
2. 方法设计
2.1 网络pipline
文章的算法流程主要包含两个步骤:
- 1)由帧间的光流信息与缺失区域的mask信息得到较为粗略的stage1光流估计;
- 2)通过基于flow propagation guided方式可以将已知区域的信息迁移到未知区域实现补全,这个过程是在stage2和stage3中逐渐优化的;
经过上面两个步骤之后,若是还存在未被不全的区域,那么便会使用基于学习的方法进行补全(基于GAN的)。算法的整体流程见下图所示:
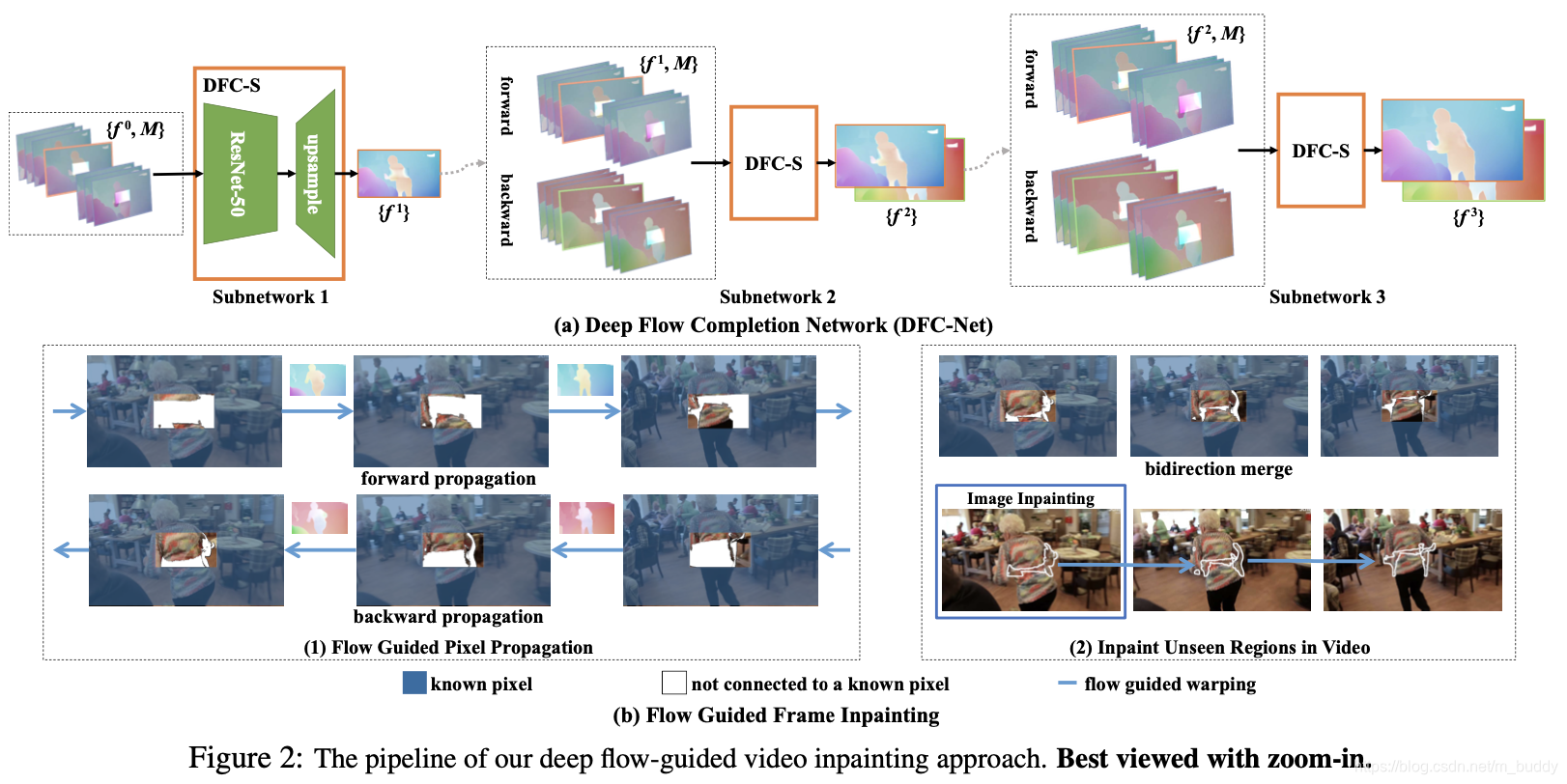
2.2 DFC-S(Deep Flow Completion Subnetwork)模块
这部分网络适用于使用视频中的已知光流信息去估计缺失区域的光流信息。为了提升对缺失部分光流信息的估计精度,这里使用了多个视频帧的形式,其输入包含两个部分:
- 1)连续视频帧中抽取出来的光流信息,每个光流信息包含x和y两个方向;
- 2)指示未知区域的二值mask图,用于标注未知区域;
其具体的输入构成为:若使用 f i → ( i + 1 ) 0 f_{i\to(i+1)}^0 fi→(i+1)0表示索引为第 i i i帧到第 i + 1 i+1 i+1的光流信息(包含x和y两个方向,为两个通道的信息), M i → ( i + 1 ) M_{i\to(i+1)} Mi→(i+1)表是对应的缺失二值掩膜,对于缺失区域的光流信息 f ∗ 0 f_{*}^0 f∗0是通过向内通过已知边缘部分的光流信息插值得到的。那么对于第 i i i帧的光流信息估计是通过前后 k = 5 k=5 k=5帧的信息组合求解的,那么即是将 f ( i − k ) → ( i − k + 1 ) 0 , … , f i → ( i + 1 ) 0 , … , f ( i + k ) → ( i + k + 1 ) 0 f_{(i-k)\to(i-k+1)}^0,\dots,f_{i\to(i+1)}^0,\dots,f_{(i+k)\to(i+k+1)}^0 f(i−k)→(i−k+1)0,…,fi→(i+1)0,…,f(i+k)→(i+k+1)0和 { M i − k , … , M i , … , M i + k } \{M_{i-k},\dots,M_i,\dots,M_{i+k}\} {Mi−k,…,Mi,…,Mi+k}在channel维度进行concat,从而便得到了33(11个x和y方向的光流信息,11个缺失区域的二值掩膜信息)个channel的输入数据。
对于编码器,文章选择ResNet-50作为编码器,在backbone的stage1部分对输入的channel数进行了扩充,为了提高后面特征图分辨率,文章在backbone的stage4和stage5的下采样换成膨胀卷积的形式。之后经过由3个(卷积/ReLu/上采样)构成的模块去增大预测结果的分辨率,在最后一个上采样中去掉了激活层。
2.3 光流的级联优化
文章提出的DFC-Net由3个stage的DFC-S子网络构成,他们完成缺失部分光流信息coarse-to-fine的补全过程。在光流估计的过程中,缺失区域越小,那么网络就越容易完成缺失区域的补全,因而在级联优化的过程中其补全的分辨率也是逐渐增大的,具体来讲文章的3个stage它们的分辨率分别是原始输入尺寸的 1 2 , 2 3 , 1 \frac{1}{2},\frac{2}{3},1 21,32,1,因而可以产生更加精准和鲁棒的光流预估结果,其流程见图2的a图所示。
在第一个stage完成小分辨率下的光流估计之后,后面会经过2个stage的光流进行一步优化,只不过后面的两个模块有所区别,即是增加了双向的数据输入(正反序的视频)。在stage 1中生成的coarse光流信息表示为
f
1
f^1
f1,在第二stage输入的时候会将两个方向的光流信息进行输入,正向的光流序列
{
f
(
i
−
k
)
→
(
i
−
k
+
1
)
1
,
…
,
f
i
→
(
i
+
1
)
1
,
…
,
f
(
i
+
k
)
→
(
i
+
k
+
1
)
1
}
\{f_{(i-k)\to(i-k+1)}^1,\dots,f_{i\to(i+1)}^1,\dots,f_{(i+k)\to(i+k+1)}^1\}
{f(i−k)→(i−k+1)1,…,fi→(i+1)1,…,f(i+k)→(i+k+1)1},以及反向序列
{
f
(
i
−
k
)
←
(
i
−
k
+
1
)
1
,
…
,
f
i
←
(
i
+
1
)
1
,
…
,
f
(
i
+
k
)
←
(
i
+
k
+
1
)
1
}
\{f_{(i-k)\leftarrow(i-k+1)}^1,\dots,f_{i\leftarrow(i+1)}^1,\dots,f_{(i+k)\leftarrow(i+k+1)}^1\}
{f(i−k)←(i−k+1)1,…,fi←(i+1)1,…,f(i+k)←(i+k+1)1},还有正反向对应的mask二值掩膜区域
{
M
i
−
k
,
…
,
M
i
,
…
,
M
i
+
k
}
\{M_{i-k},\dots,M_i,\dots,M_{i+k}\}
{Mi−k,…,Mi,…,Mi+k}和
{
M
i
−
k
+
1
,
…
,
M
i
+
1
,
…
,
M
i
+
k
+
1
}
\{M_{i-k+1},\dots,M_{i+1},\dots,M_{i+k+1}\}
{Mi−k+1,…,Mi+1,…,Mi+k+1}。其生成的结果也是代表正反两个方向的光流信息
{
f
i
→
(
i
+
1
)
2
,
f
i
←
(
i
+
1
)
2
}
\{f_{i\to(i+1)}^2,f_{i\leftarrow(i+1)}^2\}
{fi→(i+1)2,fi←(i+1)2}。这里便要对输入的channel进行修改变为66个了,后面的stage3也是与stage2类似的结构,只是分辨率发生的变化,三个stage得到的结果可见下图所示:
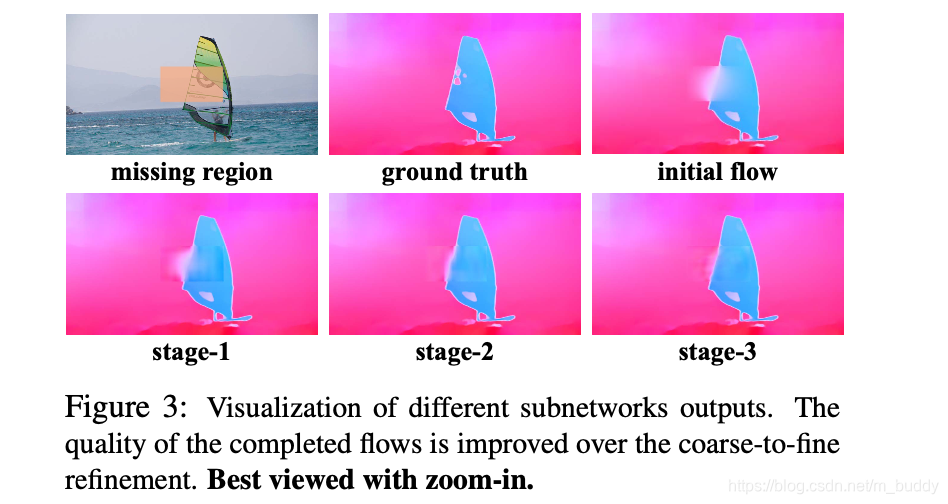
上面的网络在训练过程中是在视频序列中随机生成缺失区域,之后使用
L
1
L_1
L1距离作为损失函数,开始的时候三个stage的网络分别开始训练得到pretrain,之后再将其结合起来进行finetune。因而对应的损失函数描述为:
L
i
=
∣
∣
M
⊙
(
f
i
−
f
^
)
∣
∣
1
∣
∣
M
∣
∣
1
L_i=\frac{||M\odot(f^i-\hat{f})||_1}{||M||_1}
Li=∣∣M∣∣1∣∣M⊙(fi−f^)∣∣1
其中,
f
^
\hat{f}
f^代表对应的光流GT,
⊙
\odot
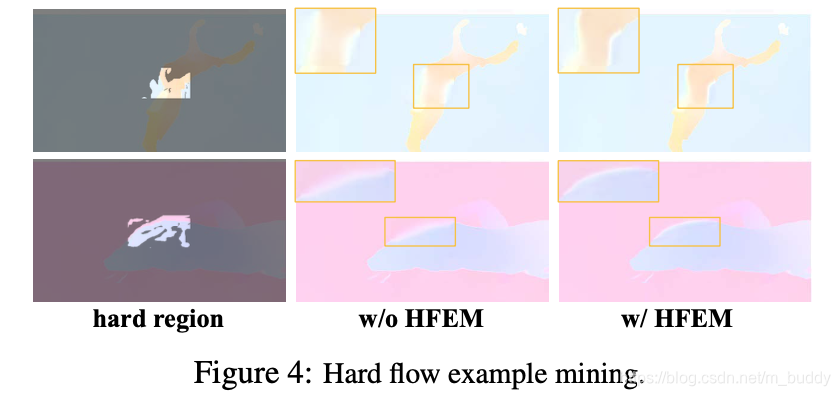
⊙代表element-wise乘积。在使用上诉的损失函数进行训练过程中,其是存在较大的偏向性的(这是由边界区域像素和平滑区域像素的数量差异导致的),因而为了能够更好地训练网络,引入了类似苦难样本挖掘的机制。在计算损失的过程中计算所有像素的损失函数值,之后将其降序排序,之后选择
t
o
p
−
p
top-p
top−p百分比的像素,之后通过加权系数
λ
\lambda
λ进行加权结合,因而新的损失函数可以描述为:
L
i
=
∣
∣
M
⊙
(
f
i
−
f
^
)
∣
∣
1
∣
∣
M
∣
∣
1
+
λ
∗
∣
∣
M
h
⊙
(
f
i
−
f
^
∣
∣
1
)
∣
∣
M
h
∣
∣
1
L_i=\frac{||M\odot(f^i-\hat{f})||_1}{||M||_1}+\lambda * \frac{||M^h\odot(f^i-\hat{f}||_1)}{||M^h||_1}
Li=∣∣M∣∣1∣∣M⊙(fi−f^)∣∣1+λ∗∣∣Mh∣∣1∣∣Mh⊙(fi−f^∣∣1)
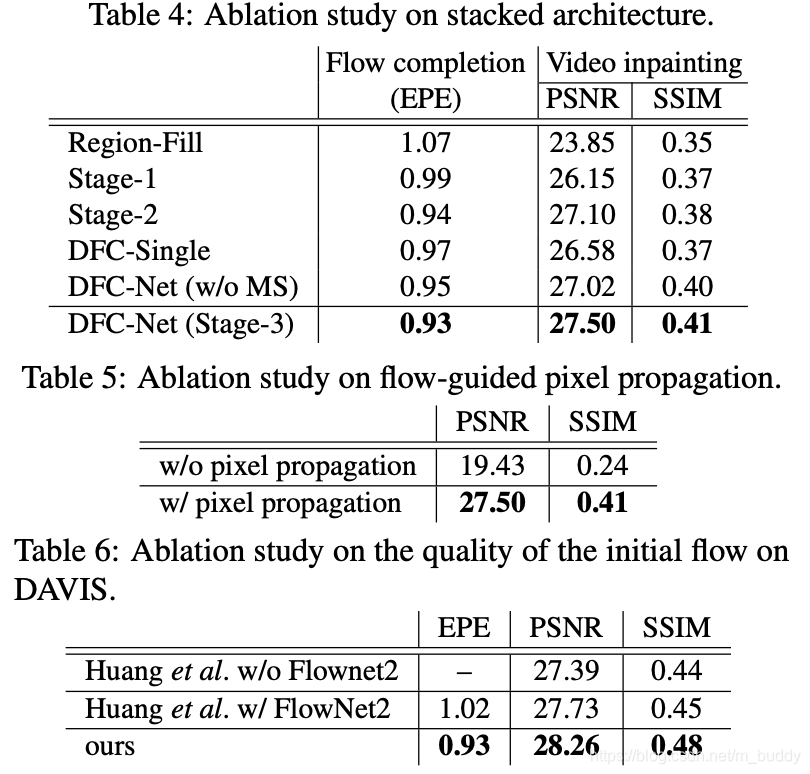
有无困难样本挖掘的对比见下图所示:
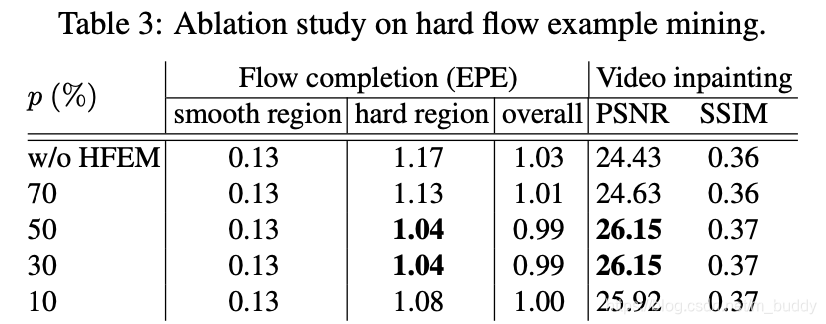
具体的消融实验结果:
2.4 基于光流引导的inpainting
通过之前的DFC-S网络生成预估光流信息之后,便建立起了像素在不同视频帧之间的联系,从而为后面基于光流的inpainting打下基础,对于补全的过程可以分为两种情况,一个是建立了可信的光流引导的,一个是没有建立的,对于前一个可以使用光流信息进行补全,第二个就得使用GAN网络进行生成了。
基于光流的像素传导:
在stage 3生成的光流信息
f
i
→
(
i
+
1
)
3
f_{i\to(i+1)}^3
fi→(i+1)3在
x
i
x_i
xi处的光流信息是可信的,那么其前后顺序下根据光流信息可以满足如下的变化条件:
∣
∣
(
x
i
+
1
+
f
i
→
(
i
+
1
)
3
(
x
i
+
1
)
)
−
x
i
∣
∣
2
<
η
||(x_{i+1}+f_{i\to(i+1)}^3(x_{i+1}))-x_i||_2\lt\eta
∣∣(xi+1+fi→(i+1)3(xi+1))−xi∣∣2<η
其中,
x
i
+
1
=
x
i
+
f
i
→
(
i
+
1
)
3
(
x
i
)
x_{i+1}=x_i+f_{i\to(i+1)}^3(x_i)
xi+1=xi+fi→(i+1)3(xi),代表的是在前后顺序传播的过程中,像素是可以回归到原位的。在当上面的条件不满足的时候那么这个点在
f
i
→
(
i
+
1
)
1
f_{i\to(i+1)}^1
fi→(i+1)1的时候就会被抛弃。
在图2的b图1部分展示了使用光流信息进行前后两个顺序像素传递的过程,一个未知区域像素点若是在前后传播过程中与已知区域建立了联系,那么就可以根据前后的传播过程计算权值,从而对其进行差值计算。
视频中“未知”区域:
在缺失部分的修补过程中可能存在无法修补的区域(缺失的区域与已知的区域之间无法建立联系),这里是通过GAN的方式去生成(在其中选择一帧使用GAN去补全)之后再将其放入到前后传导过程,实现序列的补全,若是之后还存在未知区域,那么就再来一次迭代,直到未知区域都被补全。
3. 实验结果
性能比较:
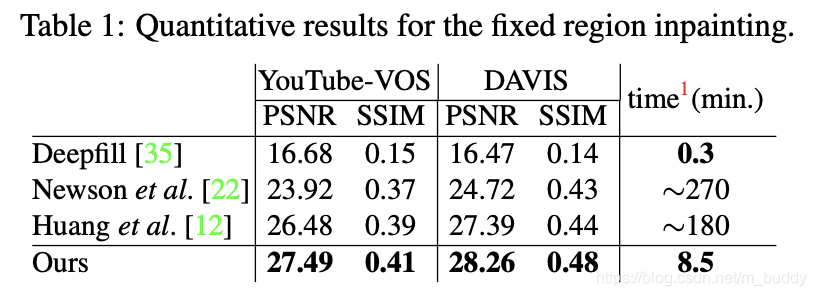
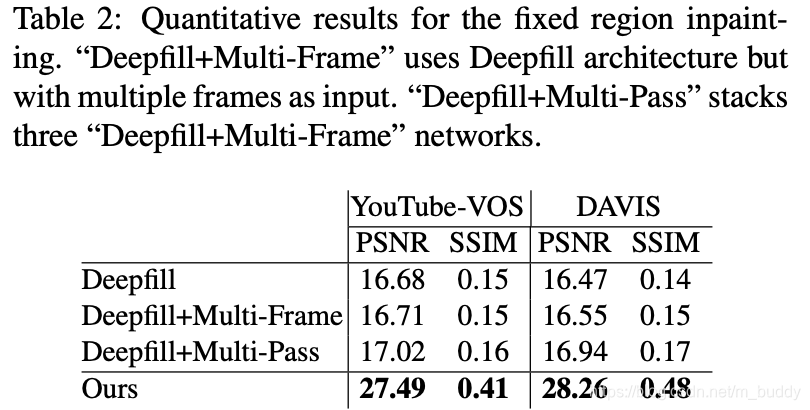
文章不同的结构对性能的影响:


















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









