




 《OSVOS:One-Shot Video Object Segmentation》是一篇经典论文,介绍了一种半监督的视频目标分割方法。该方法通过逐帧分割,利用初始帧的标注进行finetune,结合前景分割和轮廓预测,实现了对特定目标的精确分割。虽然未充分利用帧间关系,但即使目标被遮挡也能保持分割效果。网络结构包括前景分割和轮廓预测分支,通过加权交叉熵损失函数优化。实验结果显示,通过调整finetune时间和多帧标注,可在性能和实时性之间取得平衡。
《OSVOS:One-Shot Video Object Segmentation》是一篇经典论文,介绍了一种半监督的视频目标分割方法。该方法通过逐帧分割,利用初始帧的标注进行finetune,结合前景分割和轮廓预测,实现了对特定目标的精确分割。虽然未充分利用帧间关系,但即使目标被遮挡也能保持分割效果。网络结构包括前景分割和轮廓预测分支,通过加权交叉熵损失函数优化。实验结果显示,通过调整finetune时间和多帧标注,可在性能和实时性之间取得平衡。
代码地址:OSVOS-PyTorch
1. 概述
导读:这篇文章是视频分割领域的一篇比较经典的文章,该文章的方法是一种半监督离线化训练的方法,从前景分割分支与轮廓检测分支的结果上获取分割的结果。这篇文章的方法是逐帧进行分割的,因而帧与帧之前相互关系这里并没有运用。总的来说其实现的效果在那个时候还是不错的。下面是其对应的分割效果展示:

文章算法流程图:
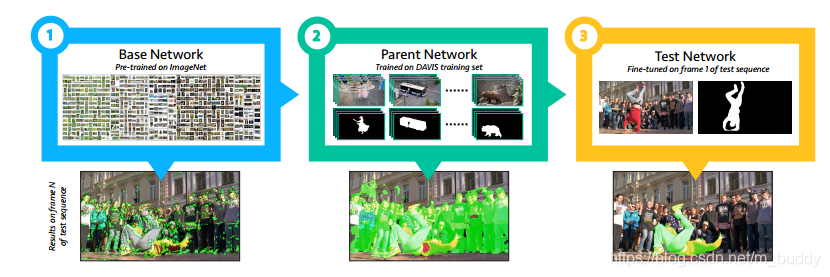
这篇文章的主要贡献可以归纳为:
- 1)在只给定一个初始图像目标标注的情况下,使得CNN网络适应这个特定的目标。文章的方法首先在类似于ImageNet这样的分类数据集上进行训练得到Base Network;之后在传统分割数据进行训练得到Parent Network;之后在测试的时候就使用第一帧的数据进行finetune得到test network。具体流程见图2所示。这样就有效运用了类别的语义信息、物体或目标的轮廓信息以及特定目标的专有特性信息。
- 2)文章的另外一个鲜明特点是对目标区域的分割是逐帧分割的,这里是有相邻帧时间差异并不大的前提假设的。这个方法中并没有很好运用到帧间的关系。但是却可以在目标被遮挡之后还能继续分割目标,也算是一个优势;
- 3)文章的网络可以在性能与实时性方面进行权衡,文章指出有两种可以采取的策略:文章的方法可以在181ms每帧的情况下达到71.5%的性能,而咋7.83s的时候就可以达到79.7%;可以使用多帧的标注数据进行优化,单帧数据标注输入的时候为79.8%,两帧的时候为84.6%,四帧的时候为86.9%。
2. 方法设计
2.1 网络结构
这篇文章的方法在拿到ImageNet预训练模型之后运算过程可以分为两部分:
- 1)使用DAVIS数据集进行分割网络训练(离线训练),从而使得网络知道“这是目标”,既是区分前景背景;
- 2)在得到离线训练的模型之后在给定帧与对应的标注基础上进行finetune,从而使得网络知道这是“需要分割的目标”;
总的来讲文章使用到的网络结构有两个(分支),一个负责前景的分割,另外一个负责轮廓的查找。具体见图4所示:
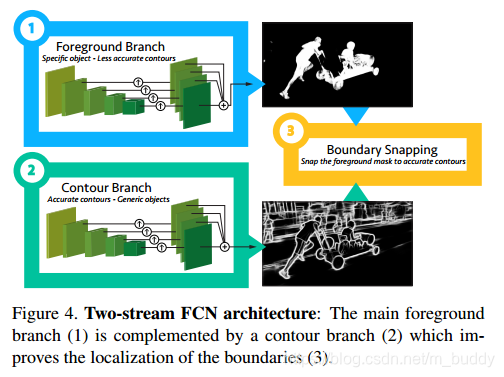
2.2 端到端的前景分割分支
这里使用的是VGG作为分割网络的backbone,之后再将不同stage上的特征图经过采样到同样尺度融合,从而再在融合的结果上得到分割的结果,其结构见图4中的1部分。
这里使用到的损失函数是2值交叉熵损失函数,但是为了照顾样本不平衡的情况,这里在原始交叉熵的基础按照正负比例进行了加权处理:
L
W
=
−
β
∑
j
∈
Y
+
l
o
g
P
(
y
j
=
1
∣
X
)
−
(
1
−
β
)
∑
j
∈
Y
−
l
o
g
(
y
j
=
0
∣
X
)
L_{W}=-\beta \sum_{j\in Y_+}logP(y_j=1|X)-(1-\beta)\sum_{j\in Y_-}log(y_j=0|X)
LW=−βj∈Y+∑logP(yj=1∣X)−(1−β)j∈Y−∑log(yj=0∣X)
其中,
β
=
∣
Y
−
∣
/
∣
Y
∣
\beta=|Y_-|/|Y|
β=∣Y−∣/∣Y∣。
2.2 轮廓预测分支
文章中为了提升最后分割的性能还引入了轮廓算子,这里文章提供了两个策略的方法:双边算子与轮廓分割网络。
双边算子
双边算子能够平滑输入的图像数据(同一物体内部,边缘会被保留),这个方法的优势是速度快(60ms每帧),并且是可微的。但是这个方法文章说到他会保留原始的图像梯度信息(难道是轮廓的信息没有模型的好?)而被舍弃掉。
轮廓分割网络
这里使用前景分割分支一样的结构去检测图像中的轮廓信息,这里需要注意的是其与前景分割分支并不共用网络层,而是单独一套(文章说到是为了不使性能下降),因而单独进行离线训练。之后得到轮廓结果之后是通过多数选择的策略进行匹配(与前景的重叠超过50%)。
2.3 finetune阶段
在完成前景分割与轮廓检测网络的训练之后就需要对在给定先验的基础上进行finetune从而实现精细化目标分割。
最后分割结果的输出时间主要取决于两个部分:finetune本身消耗的时间与迭代优化需要的时间。自然迭代优化之后能够获得效果更优的分割结果,但是却需要消耗更多的时间,这个在用的时候可以进行权衡,下图3就是在10秒与1分钟优化之后的结果对比:

3. 实验结果
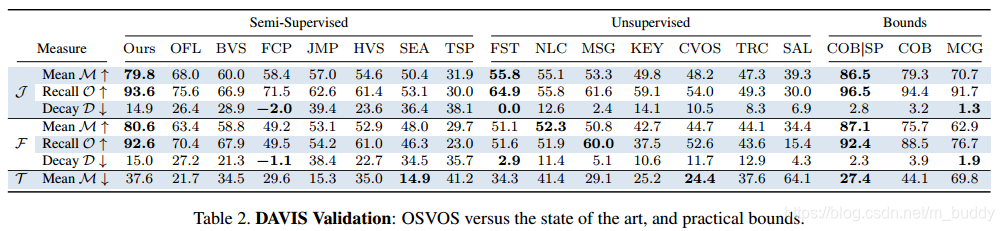
DAVIS上的性能表现:
消融实验:
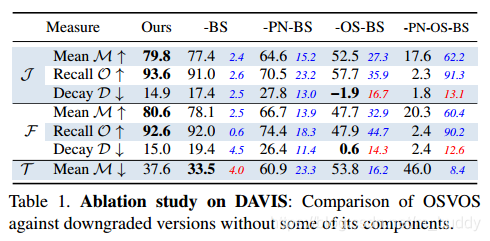
其中,BS是轮廓分支,PN是ImageNet预训练模型,OS给定第一帧进行finetune。


















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









