



一、了解
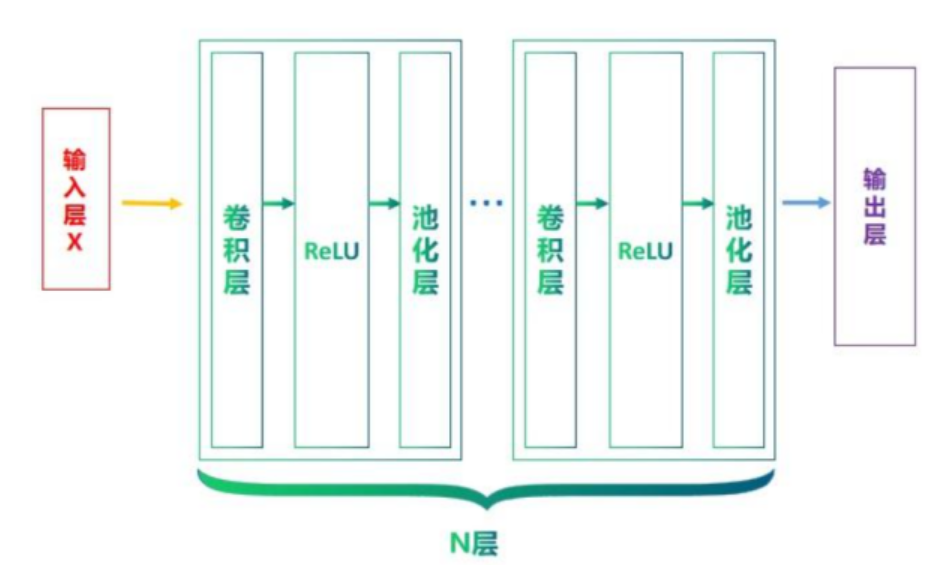
深度学习通常都会从学习卷积神经网络(Convolutional Neural Network, 简称CNN)开始。很大程度上,是由于CNN的基本组成部分与前馈神经网络有很紧密的关联,甚至可以说,CNN就是一种特殊的前馈神经网络。
这两者的主要区别在于,CNN在前馈神经网络的基础上加入了卷积层和池化层,以便更好地处理图像等具有空间结构的数据。
全连接:
1.模型参数过多,容易发生过拟合。
2.难以提取图像中的局部不变性特征。
卷积神经网络有三个结构上的特性:局部连接、权重共享和池化;
这些特性使得卷积神经网络具有一定程度上的平移、缩放和旋转不变性。和前馈神经网络相比,卷积神经网络的参数也更少。因此,通常会使用卷积神经网络来处理图像信息。
卷积神经网络(CNN)在处理数据时,特别是图像数据时,利用了三个关键特性:局部连接、权重共享和池化(有时称为汇聚)。
1.局部连接
-
定义:局部连接指的是每个神经元只与输入数据的一个局部区域相连,而不是全连接。例如,在图像处理中,这意味着每个神经元仅关注图像的一小部分(比如一个5x5像素的区域),而不是整个图像。
-
作用:这种设计模仿了人类视觉系统中的感受野机制,即视觉皮层中的神经元对视野中特定位置的小区域敏感。局部连接极大地减少了模型参数的数量,从而降低了计算成本,并帮助网络专注于学习局部特征,如边缘或纹理。
2. 权重共享
-
定义:权重共享是指同一卷积层中的所有神经元使用相同的权重向量来检测输入数据的不同局部区域。换句话说,卷积核(滤波器)在整个输入上滑动时,其内部的权重保持不变。
-
作用:这一机制不仅进一步减少了模型参数的数量,提高了计算效率,还赋予了模型平移不变性(translation invariance),意味着无论某个特征出现在图像的哪个位置,模型都能识别它。这使得CNN非常适合处理具有平移不变性的任务,如图像分类。
3. 池化(Pooling)
-
定义:池化操作通常用于减少特征图的空间尺寸,从而降低计算复杂度并控制过拟合。最常见的形式是最大池化(Max Pooling),它通过取每个固定大小子区域的最大值来缩小特征图的尺寸。
-
作用:除了减少维度外,池化还能提供某种程度的位置不变性,因为它减少了输出对输入中小变化的敏感性。这意味着即使输入有轻微的变化(如物体位置稍微移动),池化后的特征图也能保持相对稳定。此外,池化还有助于提取主要特征,去除冗余信息。
二、卷积
2.1定义
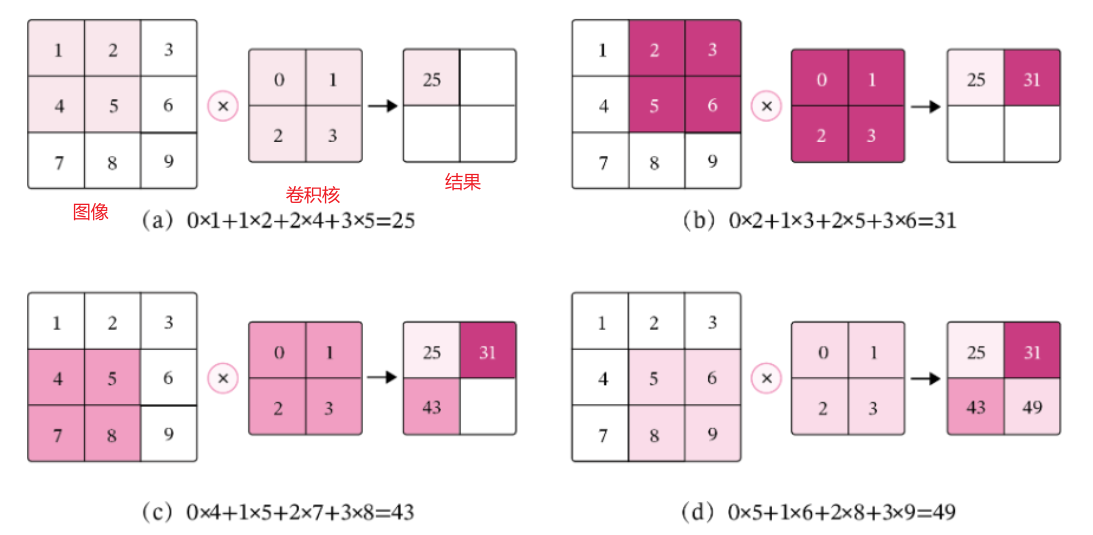
在机器学习和图像处理领域,卷积的主要功能是在一个图像(或特征图)上滑动一个卷积核,通过卷积操作得到一组新的特征。在计算卷积的过程中,需要进行卷积核的翻转,而这也会带来一些不必要的操作和开销。因此,在具体实现上,一般会以数学中的互相关(Cross-Correlatio)运算来代替卷积。 在神经网络中,卷积运算的主要作用是抽取特征,卷积核是否进行翻转并不会影响其特征抽取的能力。特别是当卷积核是可学习的参数时,卷积和互相关在能力上是等价的。因此,很多时候,为方便起见,会直接用互相关来代替卷积。
用一句话总结: 卷积操作是通过滑动卷积核,在每个局部区域上进行“先乘再和”的运算,最终生成一个特征图,每个输出值是一个标量。
权值共享
权值共享是卷积神经网络(CNN)中一个非常核心的概念,理解它可以帮助你更好地掌握CNN的精髓。
权值共享指的是同一个卷积核(或滤波器)在输入数据不同位置上重复使用,而不仅仅是在一个位置上使用。这个卷积核包含了一组权重,用于从输入数据中提取特征。通过权值共享,网络能够在不同的输入位置之间共享计算和参数,从而大大减少模型参数的数量,提高网络的泛化能力。
权值共享有两个关键好处。首先,它显著减少了模型的参数数量,降低了过拟合的风险。其次,由于所有卷积核都使用相同的权重和偏置,CNN实现了平移不变性。这意味着,即使物体在图像中移动了位置,只要其特征保持不变,网络仍能准确识别它。
权值共享是卷积神经网络的一项重要特性。它使得模型更加简洁,提高了模型的泛化能力。理解权值共享不仅有助于深入理解CNN本身,还有助于更好地利用这个强大的机器学习工具。
举个简单的例子,把图像想象成一个有很多小格子(像素)的棋盘,卷积核就像是一个印章。印章在棋盘上移动,每次印章覆盖到的位置,就对这些位置的数值进行一些计算(通常是乘法和加法),得到一个新的数值,这些新数值组成一个新的矩阵,这个过程就是卷积操作。印章的形状(权值)在整个棋盘(图像)上盖章的时候是不会改变的。无论印章滑动到棋盘的哪个位置,印章的形状都是一样的。这样做的好处是大大减少了需要学习的参数数量。
2.2代码实现
卷积步骤:
1.准备数据
输入数据:
卷积核:
2.创建卷积层
定义:conv_layer = nn.Conv2d(in_channels=1,out_channels=1,stride=1,kernel_size=3,padding=1,)
初始化:conv_layer.weight.data = a.view(1, 1, 3, 3)
3.应用卷积层
output_data = conv_layer(input_data)
import torch
import torch.nn as nn
import numpy as np
# 卷积步骤:
# 1.准备数据
# 输入数据:torch.randn(1, 1, 5, 5)
# 卷积核:
# 2.创建卷积层
# 定义:conv_layer = nn.Conv2d(in_channels=1,out_channels=1,stride=1,kernel_size=3,padding=1,)
# 初始化:conv_layer.weight.data = a.view(1, 1, 3, 3)
# 3.应用卷积层
# output_data = conv_layer(input_data)
# 1.数据准备
# 随机生成输入数据
input_data = torch.randn(1, 1, 5, 5)
# torch.randn(1, 1, 5, 5) :卷积层的输入要求(批量大小、输入通道数、高度、宽度)
# 创建卷积核的数据
a = torch.tensor([[1,0,-1],[2,0,-2],[1,0,-1]],dtype=torch.float32)
# 2.创建卷积层
# 创建卷积层nn.Conv2d(in_channels=1, out_channels=1, kernel_size=2x2)
# # 参数
# in_channels=1:输入特征图的通道数(与输入数据的通道数一致)
# out_channels=1:输出特征图的通道数(等于卷积核的数量)
# kernel_size=3:卷积核大小为 3x3
# stride=1:步长为 1(每次滑动 1 个像素)
# padding=1:边缘填充 1 圈(保持输出尺寸与输入一致,5x5 → 5x5)
conv_layer = nn.Conv2d(
in_channels=1,
out_channels=1,
stride=1,
kernel_size=3,
padding=1,
)
# 卷积核初始化:将 卷积核数据 给卷积层的weight参数
conv_layer.weight.data = a.view(1, 1, 3, 3)
# 应用卷积
output_data = conv_layer(input_data)
print(output_data.shape)
print('卷积结果:',output_data.data)
代码解释:
在 PyTorch 中,torch.randn(1, 1, 5, 5) 生成的是一个 4 维张量(Tensor),这四个数字分别对应张量的维度大小,具体含义通常与深度学习中的数据格式相关:
- 第一个
1:表示 样本数量(batch size),这里表示有 1 个样本。 - 第二个
1:表示 通道数(channels),这里表示该样本是单通道的(类似灰度图像)。 - 第三个
5:表示 高度(height),这里表示特征图或图像的高度为 5 个像素。 - 第四个
5:表示 宽度(width),这里表示特征图或图像的宽度为 5 个像素。
这种 (batch_size, channels, height, width) 的格式是卷积神经网络(CNN)中最常用的数据格式(PyTorch 默认的卷积层输入格式),非常适合处理图像类数据。
conv_layer = nn.Conv2d(in_channels=1, out_channels=1,stride=1,kernel_size=3, padding=1)
定义了一个 PyTorch 中的 2D 卷积层(nn.Conv2d),各参数的含义如下:
-
通道数不理解可以与后面的‘单卷积核多通道、多卷积核多通道’比较更好理解, 这里是‘单卷积核单通道’;如果输入的数据是图片,一张RGP的图就是三通道。三通道如下in_channels=1:
输入数据的通道数。这里设为 1,要与输入的数通道数一致,表示输入是单通道数据(例如灰度图像)。
out_channels=1: 输出数据的通道数。这里设为 1,表示卷积层会输出 1 个通道的特征图。-
kernel_size=3:
卷积核的大小。这里是 3×3 的正方形卷积核(也可通过元组(h, w)设置非正方形卷积核)。 -
stride=1:
卷积操作的步长。设为 1 表示卷积核每次移动 1 个像素,这是最常用的设置。 -
padding=1:
在输入数据的边缘填充 1 圈像素(通常填充 0)。
对于 3×3 卷积核和步长 1,不填充的输出尺寸比输入的尺寸小,padding=1可以保持输入输出的尺寸一致(例如 5×5 输入 → 5×5 输出);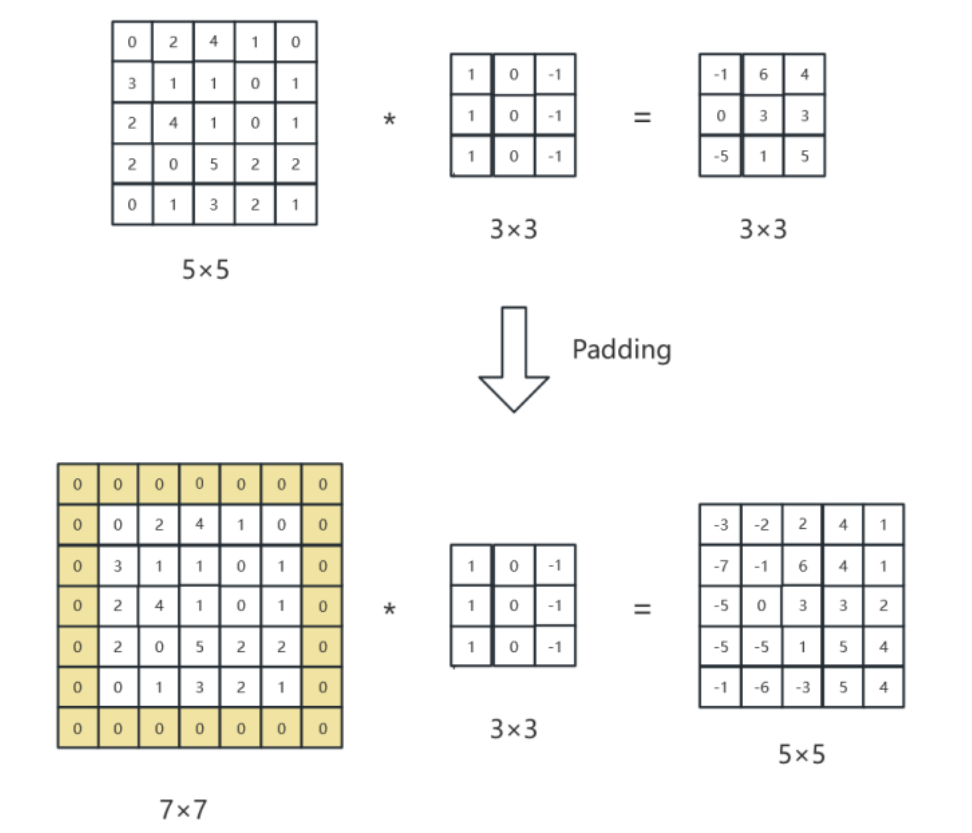 输出特征图的尺寸 W×H 可以通过以下公式计算:
输出特征图的尺寸 W×H 可以通过以下公式计算: 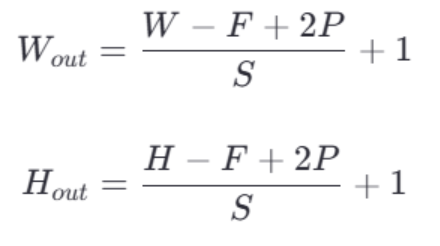
conv_layer.weight.data = a.view(1, 1, 3, 3)
这句话的作用是将变量 a 的数据重塑为 (1, 1, 3, 3) 的形状后,赋值给卷积层 conv_layer 的权重参数。
具体解释如下:
-
a.view(1, 1, 3, 3):view()是 PyTorch 中用于重塑张量形状的方法- 重塑后的形状
(1, 1, 3, 3)对应卷积核的维度:(输出通道数, 输入通道数, 卷积核高度, 卷积核宽度) - 这里表示:1 个输出通道、1 个输入通道、3×3 大小的卷积核
-
conv_layer.weight.data:conv_layer是一个卷积层(如nn.Conv2d)weight是卷积层的权重参数(即卷积核).data用于直接访问参数存储的数据(不跟踪梯度)
-
整体作用:
手动设置卷积层的权重参数,将自定义的张量a作为卷积核使用,适用于需要固定卷积核参数的场景(如实现特定的图像滤波操作)。
需要注意的是,使用 .data 可能会绕过 PyTorch 的自动梯度系统,在大多数情况下,更推荐使用 .detach() 来获取不含梯度的张量。
卷积核为什么总是选取奇数
在深度学习中,卷积核的大小一般选择奇数是为了方便处理和避免引入不必要的对称性。当卷积核的大小是奇数时,它具有唯一的一个中心像素,这个中心像素点可以作为滑动的默认参考点,即锚点。这使得在进行卷积操作时,卷积核可以在输入图像的每个像素周围均匀地取样。这样的好处是,在进行卷积操作时,可以保持对称地处理图像的每个位置,从而避免引入额外的偏差和不对称性。相反,如果卷积核的大小是偶数,那么在某些位置上,中心像素会落在两个相邻的像素之间,这可能导致对称性问题。
此外,选择奇数大小的卷积核还有一个重要的优点是,在进行空间卷积时,可以确保卷积核有一个明确的中心像素,这有助于处理图像的边缘和边界像素,避免模糊和信息损失。当然,并不是所有情况下都必须选择奇数大小的卷积核。在某些特定情况下,偶数大小的卷积核也可以使用,并且在某些特定任务中可能表现得更好。但是在大多数情况下,奇数大小的卷积核是一种常见且推荐的选择,因为它可以简化卷积操作,并有助于保持图像处理的对称性和一致性。
三、池化
3.1定义
池化层的主要作用是对非线性激活后的结果进行降采样,以减少参数的数量,避免过拟合,并提高模型的处理速度,提高计算速度,同时提高所提取特征的鲁棒性。特征提取得到缩小的特征图。
3.2池化操作
池化操作(也称为下采样,Subsampling)类似卷积操作,使用的也是一个很小的矩阵,叫做池化核,但是池化核本身没有参数,只是通过对输入特征矩阵本身进行运算,它的大小通常是2x2、3x3、4x4等,其中2x2使用频率最高。然后将池化核在卷积得到的输出特征图中进行池化操作,需要注意的是,池化的过程中也有Padding方式以及步长的概念,与卷积不同的是,池化的步长往往等于池化核的大小。
最常见的池化操作为最大值池化(Max Pooling)和平均值池化(AveragePooling)两种。
-
最大池化是从每个局部区域中选择最大值作为池化后的值,这样可以保留局部区域中最显著的特征。最大池化在提取图像中的纹理、形状等方面具有很好的效果。
-
平均池化是将局部区域中的值取平均作为池化后的值,这样可以得到整体特征的平均值。平均池化在提取图像中的整体特征、减少噪声等方面具有较好的效果。
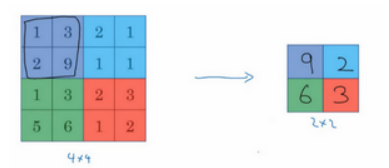
先举一个池化层的例子,然后再讨论池化层的必要性。假如输入是一个4×4矩阵,用到的池化类型是最大池化(max pooling)。执行最大池化的树池是一个2×2矩阵。执行过程非常简单,把4×4的输入拆分成不同的区域,把这个区域用不同颜色来标记。对于2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。
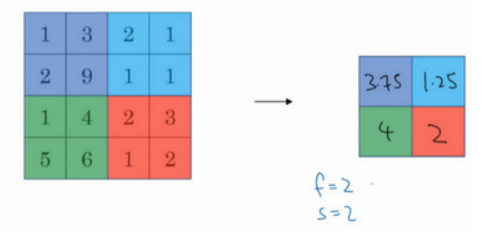
另外还有一种类型的池化,平均池化。简单介绍一下,这种运算顾名思义,选取的不是每个过滤器的最大值,而是平均值。示例中,紫色区域的平均值是3.75,后面依次是1.25、4和2。这个平均池化的超级参数 f=2,s=2,也可以选择其它超级参数。
下面是最大池化(Max Pooling)的计算过程的动画演示,左侧图像池化运算得到右侧图像。
3.3作用
池化操作的优势有:
-
通过降低特征图的尺寸,池化层能够减少计算量,从而提升模型的运行效率。
-
池化操作可以带来特征的平移、旋转等不变性,这有助于提高模型对输入数据的鲁棒性。
-
池化层通常是非线性操作,例如最大值池化,这样可以增强网络的表达能力,进一步提升模型的性能。
但是池化也有缺点:
-
池化操作会丢失一些信息,这是它最大的缺点。
3.4代码实现
import torch
import torch.nn as nn
import numpy as np
# 1. 卷积层
# 定义输入张量
input_tensor = torch.randn(1, 1, 5, 5) # 形状为 [batch_size, channels, height, width]
# 创建一个 NumPy 数组
# 定义特征数据
matrix_np = np.array([[[[1.0, 0.0, 0.0, 0.0, 1.0],
[0.0, 1.0, 0.0, 1.0, 0.0],
[0.0, 0.0, 1.0, 0.0, 0.0],
[0.0, 1.0, 0.0, 1.0, 0.0],
[1.0, 0.0, 0.0, 0.0, 1.0]]]])
# 卷积核
kernel = torch.tensor([
[0., 0., 1.],
[0., 1., 0.],
[1., 0., 0.]
], dtype=torch.float32)
matrix_np = np.array(matrix_np).astype(np.float32) # 转换为 float32
input_data = torch.from_numpy(matrix_np) #作用: 将numpy数组转换为tensor张量
conv_layer = nn.Conv2d(in_channels=1, out_channels=1, stride=1, kernel_size=3, padding=1)
conv_layer.weight.data = kernel.view(1, 1, 3, 3)
output_data = conv_layer(input_data)
print("卷积结果")
print(torch.round(output_data)) #round()函数用于对张量中的元素进行四舍五入
# 2. 池化层
# 定义池化层
#最大池化
max_pool_layer = nn.MaxPool2d(kernel_size=2, stride=3)
#平均池化
avg_pool_layer = nn.AvgPool2d(kernel_size=2, stride=3)
# 应用最大池化
max_pooled = max_pool_layer(output_data)
print("最大池化:\n", torch.round(max_pooled))
# 应用平均池化
avg_pooled = avg_pool_layer(output_data)
print("平均池化:\n", torch.round(avg_pooled))

四、多通道卷积
4.1定义
所谓多通道卷积 就是分别对每个通道进行卷积,然后把结果加起来。
-
灰度图像:只有一个通道(亮度)。
-
彩色图像:有三个通道(红、绿、蓝,简称 RGB)。
多通道卷积 的核心思想是:对每个通道分别进行卷积,然后把结果加起来。
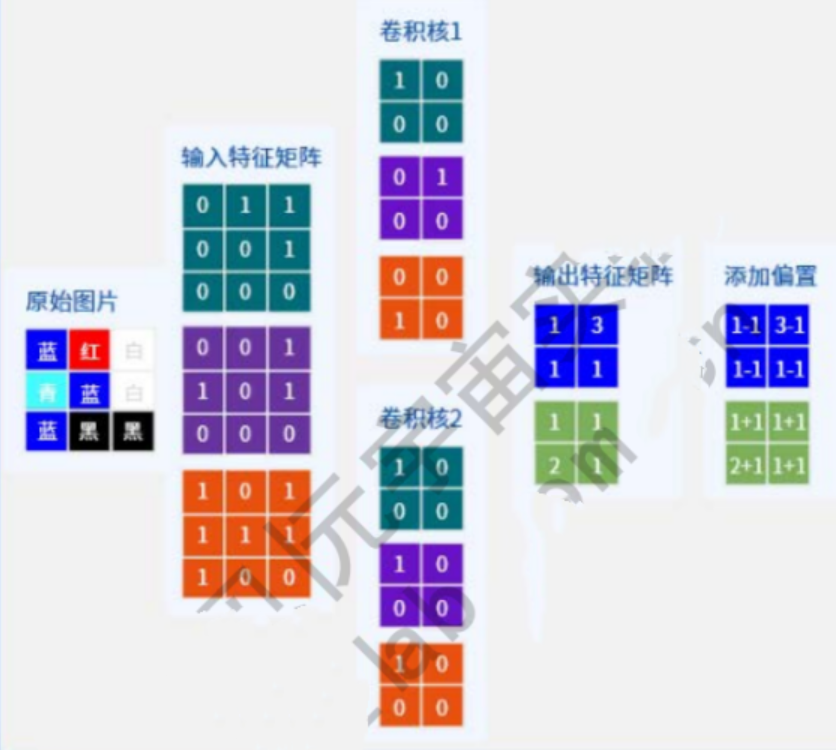
以彩色图像为例,包含三个通道,分别表示RGB三原色的像素值,输入为(3,5,5),分别表示3个通道,每个通道的宽为5,高为5。假设卷积核只有1个,卷积核通道为3,每个通道的卷积核大小仍为3x3,padding=0,stride=1。
卷积过程如下,每一个通道的像素值与对应的卷积核通道的数值进行卷积,因此每一个通道会对应一个输出卷积结果,三个卷积结果对应位置累加求和,得到最终的卷积结果(这里卷积输出结果通道只有1个,因为卷积核只有1个。卷积多输出通道下面会继续讲到)。
可以这么理解:最终得到的卷积结果是原始图像各个通道上的综合信息结果。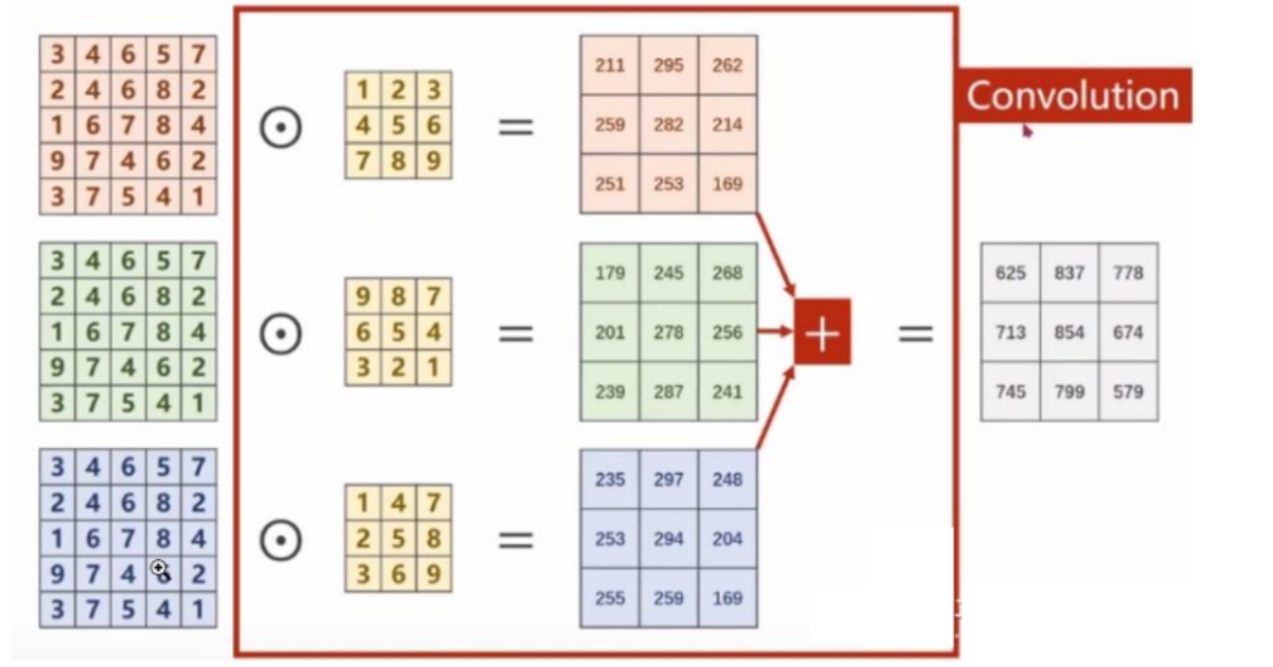
每一个卷积核的通道数量,必须要求与输入通道数量一致,因为要对每一个通道的像素值要进行卷积运算,所以每一个卷积核的通道数量必须要与输入通道数量保持一致
4.2单卷积核多通道
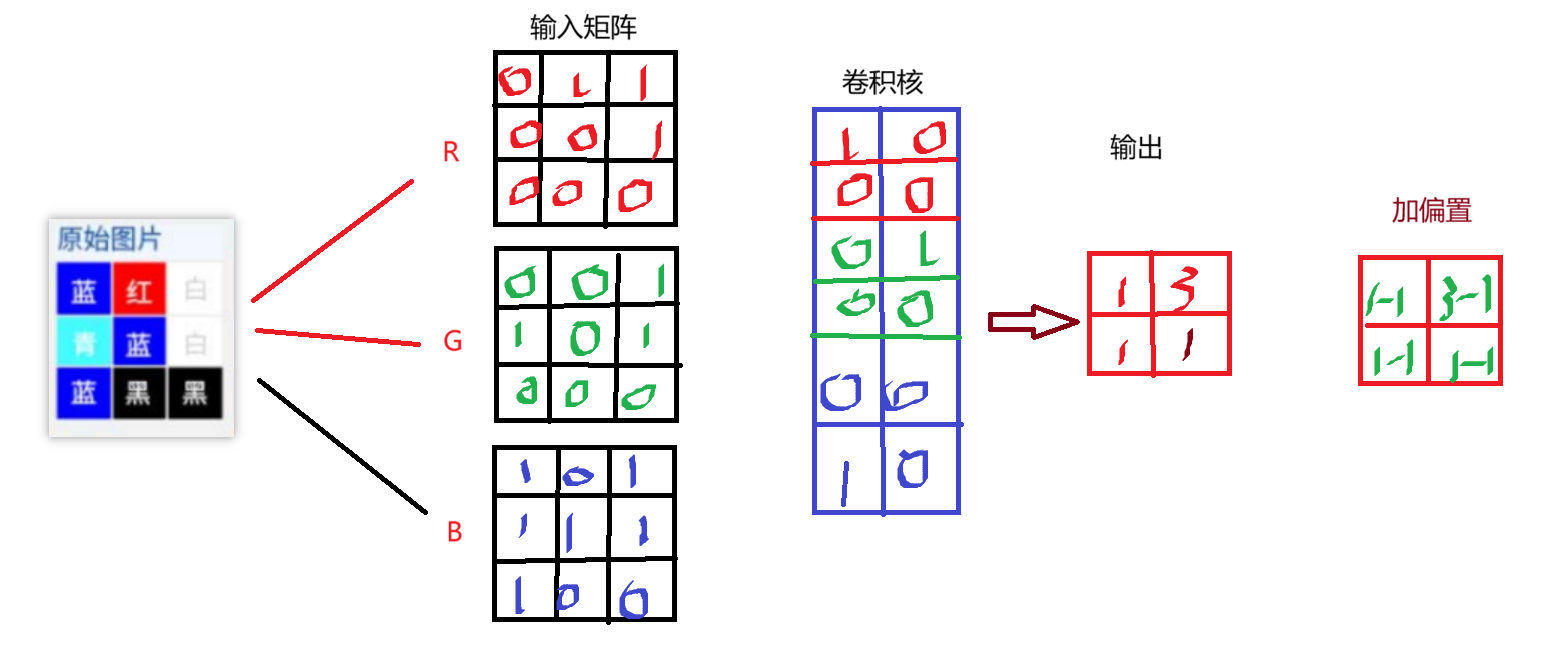
import torch
import torch.nn as nn
import numpy as np
# 创建一个大小为 28*28 的单通道图像
# input_data = torch.randn(1, 3, 3, 3) # 一个大小为28x28的单通道图像
# 创建一个 NumPy 数组
matrix_np = np.array([[[[0.0, 1.0, 1.0],
[0.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[0.0, 0.0, 1.0],
[1.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[1.0, 0.0, 1.0],
[1.0, 1.0, 1.0],
[1.0, 0.0, 0.0]]
]])
kernel = torch.tensor([
[
[1., 0.],
[0., 0.]
]
,
[
[0., 1.],
[0., 0.]
]
,
[
[0., 0.],
[1., 0.]
]
], dtype=torch.float32)
matrix_np = np.array(matrix_np).astype(np.float32)
# 转换为 PyTorch 张量
input_data = torch.from_numpy(matrix_np)
print(input_data)
# 默认没有偏置项 bias=False
#conv_layer = nn.Conv2d(in_channels=3, out_channels=1, stride=1, kernel_size=2, padding=0,bias=True)
conv_layer = nn.Conv2d(in_channels=3, out_channels=1, stride=1, kernel_size=2, padding=0,bias=False)
# 手动设置卷积核权重(权重形状:[out_channels, in_channels, height, width])
conv_layer.weight.data = kernel.view(1, 3, 2, 2)
# 手动设置卷积核偏置项(偏置项形状:[out_channels])
#conv_layer.bias.data.fill_(-1.0)
# 对输入数据进行卷积操作
output_data = conv_layer(input_data)
# 输出结果
print(output_data.shape)
print(torch.round(output_data))
4.3多卷积核多通道
import torch
import torch.nn as nn
import numpy as np
# 创建一个大小为 28*28 的单通道图像
# input_data = torch.randn(1, 3, 3, 3) # 一个大小为28x28的单通道图像
# 创建一个 NumPy 数组
matrix_np = np.array([[[[0.0, 1.0, 1.0],
[0.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[0.0, 0.0, 1.0],
[1.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[1.0, 0.0, 1.0],
[1.0, 1.0, 1.0],
[1.0, 0.0, 0.0]]
]])
kernel = torch.tensor([
[
[
[1., 0.],
[0., 0.]
]
,
[
[0., 1.],
[0., 0.]
]
,
[
[0., 0.],
[1., 0.]
]
],
[
[
[1., 0.],
[0., 0.]
]
,
[
[1., 0.],
[0., 0.]
]
,
[
[1., 0.],
[0., 0.]
]
]
], dtype=torch.float32)
matrix_np = np.array(matrix_np).astype(np.float32)
# 转换为 PyTorch 张量
input_data = torch.from_numpy(matrix_np)
print(input_data)
# 创建卷积层,输入通道数为 3
# 输出通道数1
# 步长默认是1
# 卷积核大小2*2
# 0个0填充
# 默认没有偏置项 bias=False
conv_layer = nn.Conv2d(in_channels=3, out_channels=2, stride=1, kernel_size=2, padding=0, bias=True)
# conv_layer = nn.Conv2d(in_channels=3, out_channels=2, stride=1, kernel_size=2, padding=0, bias=True)
# 手动设置卷积核权重(权重形状:[out_channels, in_channels, height, width])
conv_layer.weight.data = kernel.view(2, 3, 2, 2)
# 手动设置卷积核偏置项(偏置项形状:[out_channels])
# conv_layer.bias.data.fill_(-1.0)
# 对输入数据进行卷积操作
output_data = conv_layer(input_data)
# 输出结果
print(output_data.shape)
print(torch.round(output_data))
两个结论:
-
输入特征的通道数决定了卷积核的通道数(卷积核通道个数=输入特征通道个数)。
-
卷积核的个数决定了输出特征矩阵的通道数与偏置矩阵的通道数(卷积核个数=输出特征通道数=偏置矩阵通道数)。
CNN提取图片特征案例
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt
# 定义简单的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 特征提取层
self.features = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=1), # 输入3通道,输出16通道
nn.ReLU(),
nn.MaxPool2d(2, 2), # 尺寸减半
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
def forward(self, x):
return self.features(x)
# 图像预处理
def preprocess_image(image_path):
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整图像尺寸
transforms.ToTensor(), # 转为Tensor
transforms.Normalize( # 标准化
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
image = Image.open(image_path).convert('RGB')
return transform(image).unsqueeze(0) # 增加batch维度
# 可视化特征图
def visualize_feature_maps(feature_maps, layer_name):
# 将特征图从GPU转到CPU并转为numpy
features = feature_maps.squeeze(0).detach().cpu().numpy()
# 创建子图
fig, axes = plt.subplots(8, 8, figsize=(12, 12))
fig.suptitle(f'Feature Maps: {layer_name}', fontsize=16)
# 绘制前64个特征图
for i, ax in enumerate(axes.flat):
if i < features.shape[0]:
ax.imshow(features[i], cmap='viridis')
ax.set_title(f'Ch {i+1}')
ax.axis('off')
plt.tight_layout()
plt.show()
# 主程序
if __name__ == "__main__":
# 1. 创建模型
model = SimpleCNN()
print("模型结构:\n", model)
# 2. 加载并预处理图像
image_tensor = preprocess_image('example.jpg') # 替换为你的图片路径
print("输入图像尺寸:", image_tensor.shape)
# 3. 前向传播提取特征
with torch.no_grad():
feature_maps = model(image_tensor)
# 4. 输出特征图信息
print("\n提取的特征图尺寸:", feature_maps.shape) # [batch, channels, height, width]
print("特征图数量:", feature_maps.size(1))
# 5. 可视化特征图
visualize_feature_maps(feature_maps, "Final Conv Layer")


















 2321
2321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









