






1.某个人进入一个八列五行的棋盘中,要求从左上角开始走,最后从右下角出来,(要求只能前进,不能后退),问题:共有多少种走法?
代码:
def count_ways(n, m):
# 初始化一个二维数组,表示从左上角到每个位置的走法
ways = [[0] * m for _ in range(n)]
# 初始化第一行和第一列的走法为1
for i in range(n):
ways[i][0] = 1
for j in range(m):
ways[0][j] = 1
# 计算每个位置的走法
for i in range(1, n):
for j in range(1, m):
ways[i][j] = ways[i - 1][j] + ways[i][j - 1]
return ways[n - 1][m - 1]
if __name__ == '__main__':
n = int(input("请输入棋盘的行数:"))
m = int(input("请输入棋盘的列数:"))
ways = count_ways(n, m)
print("共有", ways, "种走法")
运行结果:

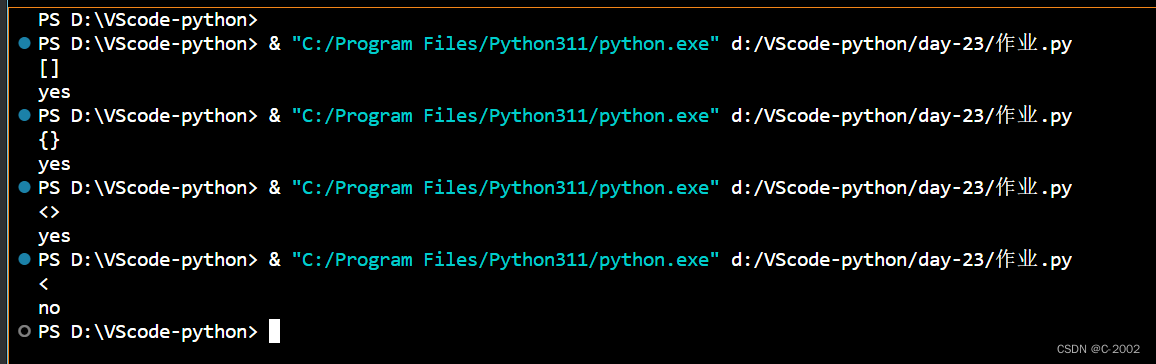
2.输入一行符号,以#结束,判断其中的对称符号是否匹配。 对称符号包括:“{}、[]、<>” 如果对称符号能够实现中间对称,则输出yes否则输出no
代码:
def is_match(s):
"""
判断字符串s中的对称符号是否能够实现中间对称。
Args:
s: 输入字符串。
Returns:
True,如果字符串s中的对称符号能够实现中间对称;False,否则。
"""
stack = []
for c in s:
if c in ["{", "[", "<"]:
stack.append(c)
elif c in ["}", "]", ">"]:
if len(stack) == 0:
return False
top = stack.pop()
if top == "{" and c != "}":
return False
elif top == "[" and c != "]":
return False
elif top == "<" and c != ">":
return False
return len(stack) == 0
if __name__ == "__main__":
s = input()
if is_match(s):
print("yes")
else:
print("no")运行结果:
3.给定一个包含n+1个整数的数组nums,其数字在1到n之间(包含1和n),可知至少存在一个重复的整数,假设只有一个重复的整数。请找出这个重复的数
可以使用哈希表来优化这段代码。哈希表是一种数据结构,它可以将键映射到值。在本例中,我们可以将数字映射到它们在数组中的位置。这样,我们就可以在 O(1) 的时间内查找数字是否已经出现过。
代码:
def find_duplicate(nums):
"""
找出数组中重复的数字。
Args:
nums: 一个包含n+1个整数的数组,其数字在1到n之间(包含1和n)。
Returns:
重复的数字。
"""
n = len(nums)
for i in range(n):
if nums[i] == i + 1:
continue
while nums[i] != i + 1:
if nums[i] == nums[nums[i] - 1]:
return nums[i]
nums[i], nums[nums[i] - 1] = nums[nums[i] - 1], nums[i]
return nums[n - 1]
if __name__ == "__main__":
nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 2]
print(find_duplicate(nums))运行结果:

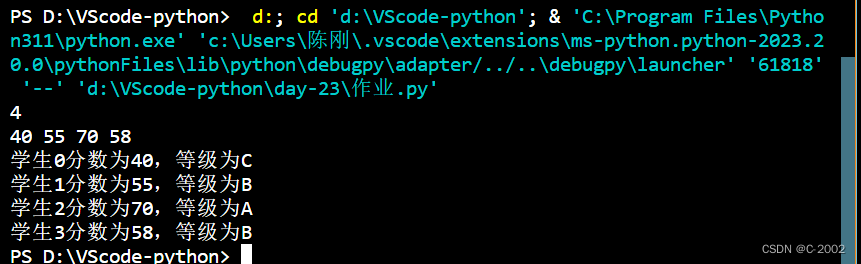
4.读入学生成绩,获取最高分best,然后根据下面的规则赋等级值:
(1)如果分数≥best-10,等级为A
(2)如果分数≥best-20,等级为B
(3)如果分数≥best-30,等级为C
(4)如果分数≥best-40,等级为D
(5)其他情况,等级为F
**输入输出描述**
输入两行,第一行输入学生人数n,第二行输入n个学生的成绩
输入n行,表示每个学生的成绩等级
代码:
def get_grade(scores):
# 计算最高分
best = max(scores)
grades = []
for i, score in enumerate(scores):
if score >= best - 10:
grade = "A"
elif score >= best - 20:
grade = "B"
elif score >= best - 30:
grade = "C"
elif score >= best - 40:
grade = "D"
else:
grade = "F"
grades.append(grade)
print(f"学生{i}分数为{score},等级为{grade}")
if __name__ == "__main__":
# 输入学生人数
n = int(input())
# 输入学生成绩
scores = list(map(int, input().split()))
# 获取成绩等级并输出
get_grade(scores)运行结果:
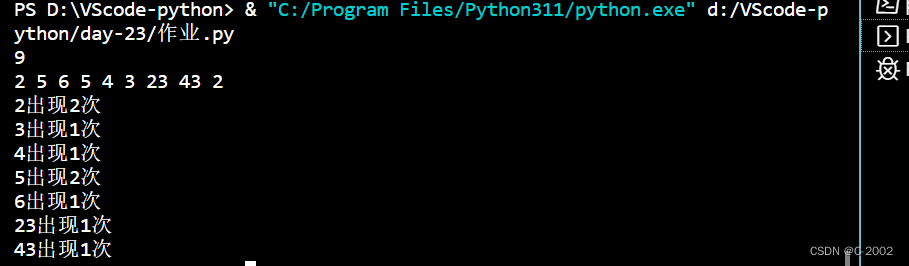
5.读取1到100之间的整数,然后计算每个数出现的次数
**输入输出描述**
输入两行,第一行为整数的个数n,第二行为n个整数
输出多行,每行表示某数及其出现的次数,顺序按照数字从小到大
代码:
def count_occurrences(nums):
occurrence = {}
for num in nums:
if num in occurrence:
occurrence[num] += 1
else:
occurrence[num] = 1
return occurrence
if __name__ == "__main__":
n = int(input())
nums = list(map(int, input().split()))
occurrences = count_occurrences(nums)
for num, count in sorted(occurrences.items()):
print(f"{num}出现{count}次")运行结果:
6.读入n个数字,并显示互不相同的数(即一个数出现多次,但仅显示一次),数组包含的都是不同的数
**输入输出描述**
输入两行,第一行为数字的个数n,第二行为n个数字
输出数组,包含的都是不同的数
定义了一个 get_unique_numbers 函数,用于获取互不相同的数。我们使用 set 数据结构来去除重复的数字,并将其转换为列表。然后,我们逐个输出列表中的数字。
代码:
def get_unique_numbers(nums):
unique_nums = list(set(nums))
return unique_nums
if __name__ == "__main__":
n = int(input())
nums = list(map(int, input().split()))
unique_nums = get_unique_numbers(nums)
for num in unique_nums:
print(num, end=" ")输出结果:

7.输入n个数字,求该n个数字的最大公约数
**输入输出描述**
输入两行,第一行为数字个数n,第二行为n个整数
输出最大公约数
定义了一个 gcd 函数,用于计算两个数的最大公约数。我们使用辗转相除法来求解最大公约数。 然后,我们定义了一个 get_gcd 函数,用于求解输入数字列表的最大公约数。我们初始化最大公约数为列表中的第一个数字,然后遍历列表,依次求解最大公约数。 最后,我们读取输入的数字个数和数字列表,并调用 get_gcd 函数来获取最大公约数,并输出结果。
代码:
def gcd(a, b):
# 辗转相除法求最大公约数
while b != 0:
a, b = b, a % b
return a
def get_gcd(nums):
# 初始化最大公约数为第一个数字
result = nums[0]
# 遍历数组,依次求最大公约数
for i in range(1, len(nums)):
result = gcd(result, nums[i])
return result
if __name__ == "__main__":
n = int(input())
nums = list(map(int, input().split()))
gcd = get_gcd(nums)
print(gcd)输出结果:

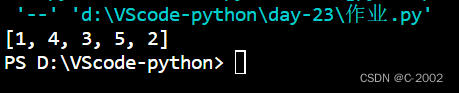
8.编程程序,对给定的数组进行随机打乱,并输出打乱后的结果
定义了一个 shuffle_array 函数,该函数接受一个数组作为输入,并使用 random.shuffle 函数对数组进行随机打乱。然后,我们返回打乱后的数组。 在主函数中,我们定义了一个示例数组 nums ,并调用 shuffle_array 函数对其进行随机打乱。最后,我们输出打乱后的结果。
代码:
import random
def shuffle_array(nums):
random.shuffle(nums)
return nums
if __name__ == "__main__":
nums = [1, 2, 3, 4, 5]
shuffled_nums = shuffle_array(nums)
print(shuffled_nums)运行结果:
9.编写程序,对给定的数组进行判断,判断其数组元素是否非单调递减
**输入输出描述**
第一行输入测试数据组数T,接下来有2T行,每第一行表示数组长度n,每第二行有n个元素
输出T行,表示该数组是否有序
定义了一个 is_array_sorted 函数,用于判断给定数组是否非单调递减。我们遍历数组中的元素,如果发现任何一个元素小于前一个元素,则该数组不是非单调递减,返回"NO";否则,返回"YES"。 在主函数中,我们首先读取测试数据的组数 T 。然后,我们使用一个循环读取每组测试数据,其中每组测试数据的第一行为数组长度 n ,第二行为数组的元素。我们调用 is_array_sorted 函数判断数组是否非单调递减,并将结果保存在 results 列表中。 最后,我们逐行输出 results 列表中的结果。
代码:
def is_array_sorted(nums):
for i in range(1, len(nums)):
if nums[i] < nums[i-1]:
return "NO"
return "YES"
if __name__ == "__main__":
t = int(input())
results = []
for _ in range(t):
n = int(input())
nums = list(map(int, input().split()))
result = is_array_sorted(nums)
results.append(result)
for result in results:
print(result)运行结果:

10.输入两个英文单词,判断其是否为相似词,所谓相似词是指两个单词包含相同的字母
**输入输出描述**
输入两行,分别表示两个单输出结果,为相似词输出YES,否则输出NO
定义了一个 is_similar_word 函数,用于判断两个英文单词是否为相似词。首先,我们将两个单词转换为集合,这样可以去除重复的字母。然后,我们判断两个集合是否相等,如果相等,则说明两个单词包含相同的字母,返回"YES";否则,返回"NO"。 在主函数中,我们先读取两个单词作为输入,然后调用 is_similar_word 函数判断它们是否为相似词,并将结果输出。
代码:
def is_similar_word(word1, word2):
# 将单词转换为集合,去除重复的字母
set1 = set(word1)
set2 = set(word2)
# 判断两个集合是否相等
if set1 == set2:
return "YES"
else:
return "NO"
if __name__ == "__main__":
word1 = input()
word2 = input()
result = is_similar_word(word1, word2)
print(result)运行结果:

11.豆机器,也称为梅花或高尔顿盒子,它是一个统计实验的设备,它是由一个三角形直立板和均匀分布的钉子构成,如下图所示:
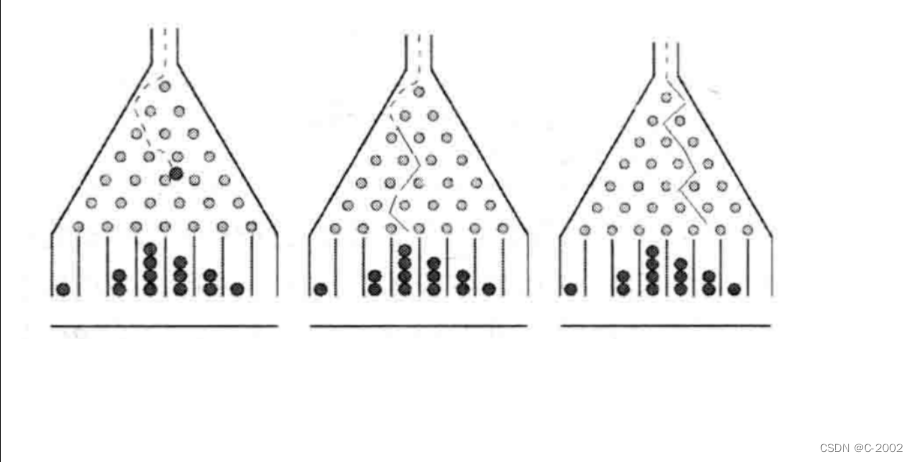
小球从板子的开口处落下,每次小球碰到钉子,它就是50%的可能掉到左边或者右边,最终小球就堆积在板子底部的槽内
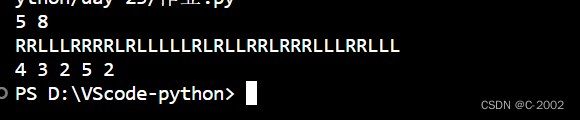
编程程序模拟豆机器,提示用户输入小球的个数以及机器的槽数,打印每个球的路径模拟它的下落,然后打印每个槽子中小球的个数
**输入输出描述**
输入两个数据,分别表示小球个数和槽子的个数
输出每个小球经过的路径,和最终每个槽子里小球的个数(因为牵扯随机数,程序结果不唯一,示例仅用于表明题意)
代码:
import random
def simulate_bean_machine(balls, slots):
random_directions = [random.choice(["L", "R"]) for _ in range(balls * (slots - 1))]
path = [random_directions[i:i+slots-1] for i in range(0, len(random_directions), slots-1)]
counts = [path.count("R") for path in path]
return path, counts
if __name__ == "__main__":
balls, slots = map(int, input().split())
path, counts = simulate_bean_machine(balls, slots)
print(''.join(direction for sublist in path for direction in sublist))
print(' '.join(str(count) for count in counts))运行结果:
12.一个学校有100个更衣室和100个学生。所有的更衣室在开学第一天都是锁着的。随着学生进入,第一个学生表示为S1,打开每个更衣室;然后第二个学生S2,从第二个更衣室开始,用L2表示,关闭所有其他更衣室;学生S3从第三个更衣室L3开始,改变每三个更衣室(如果打开则关闭,如果关闭则打开);学生S4从更衣室L4开始,改变每四个更衣室;学生S5开始从更衣室L5开始,改变每五个更衣室。依次类推,直到学生S100改变L100。
在所有学生都经过了操作后,哪些更衣室是打开的?编程找出答案。
代码:
def find_open_lockers():
lockers = [False] * 100 # 初始时所有更衣室都是关闭的
for student in range(1, 101):
for locker in range(student - 1, 100, student):
lockers[locker] = not lockers[locker] # 改变更衣室的状态
open_lockers = [i + 1 for i, status in enumerate(lockers) if status] # 找出打开的更衣室的编号
return open_lockers
if __name__ == "__main__":
open_lockers = find_open_lockers()
print("打开的更衣室编号:")
print(open_lockers)运行结果:

13.给定两个有序递增的数组A和数组B,将其进行合并成一个新的数组C,且保持有序递增,并输出数组
**输入输出描述**
第一行输入数组A的长度n,第二行输入n个元素,第三行输入数组B的长度m,第四行输入m个元素
输出数组C的n+m个元素
定义了一个 merge_arrays 函数,用于合并两个有序递增的数组并保持有序递增。我们使用双指针方法,分别初始化指针 i 和 j 为数组 A 和数组 B 的起始位置。然后,我们比较指针所指的元素,将较小的元素添加到合并后的数组 merged 中,并将相应指针后移。最后,我们处理剩余的元素,将其添加到合并后的数组中。 在主函数中,我们读取输入的数组长度和元素,并调用 merge_arrays 函数进行合并。最后,我们将合并后的数组输出。
代码:
def merge_arrays(a, b):
merged = []
i, j = 0, 0
while i < len(a) and j < len(b):
if a[i] <= b[j]:
merged.append(a[i])
i += 1
else:
merged.append(b[j])
j += 1
while i < len(a):
merged.append(a[i])
i += 1
while j < len(b):
merged.append(b[j])
j += 1
return merged
if __name__ == "__main__":
n = int(input())
a = list(map(int, input().split()))
m = int(input())
b = list(map(int, input().split()))
merged_array = merge_arrays(a, b)
print(" ".join(str(num) for num in merged_array))运行结果:

14.给定一个数组A,将第一个元素$A_0$作为枢纽,并把数组划分成三个区间,第一个区间所有元素$<A_0$,第二个区间所有元素$==A_0$,第三个区间所有元素$>A_0$
例如数组[5,2,9,3,6,8],划分后的结果为[3,2,5,9,6,8],第一个区间[3,2],第二个区间[5],第三个区间[9,6,8]
结果不唯一,只要保证划分后三个区间的元素特性即可,[2,3,5,9,8,6]、[3,2,5,6,8,9]都可作为上述划分的结果
**输入输出描述**
第一行输入数组的长度n,第二行输入n个元素
输出划分后的结果
定义了一个 partition_array 函数,用于将数组划分为三个区间。我们选择第一个元素作为枢纽,然后遍历数组,根据元素与枢纽的大小关系将其放入相应的区间中。 在主函数中,我们读取输入的数组长度和元素,并调用 partition_array 函数进行划分。最后,我们将划分后的结果输出。请注意,划分后的结果可能不唯一,只要保证三个区间的元素特性即可。
代码:
def partition_array(nums):
pivot = nums[0]
left = []
middle = []
right = []
for num in nums:
if num < pivot:
left.append(num)
elif num == pivot:
middle.append(num)
else:
right.append(num)
return left + middle + right
if __name__ == "__main__":
n = int(input())
nums = list(map(int, input().split()))
result = partition_array(nums)
print(" ".join(str(num) for num in result))运行结果:


















 1504
1504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









