






Abstract
- 大语言并不是总能在第一次生成内容时就产生最佳输出,作者从人类改进他们的写作的方式获得启发,提出了self-refine,一种通过迭代反馈和细化来改进llm的初始输出的方法。
- 主要思想是:先让大语言模型生成一个初始输出,然后,用相同的大语言模型对其输出进行反馈,并同时迭代和完善自己。
- self-refine不需要任何有监督的训练数据,额外的训练或者强化学习,而是使用一个LLM作为生成器、细化器和反馈提供者。我们使用使用最先进的LLM,评估了7个不同的任务,从对话响应到数学推理,比使用相同LLM生成的任务,在任务性能上平均提高了20%。我们的工作表明,即使是像GPT-4这样的最先进的LLM,也可以在测试时使用我们简单的、独立的方法进行进一步改进。
Introduction
- self-refine:在两个步骤间交替进行:反馈和改进。
给定一个由模型M生成的初始输出,我们将其传回相同的模型M以获得反馈,然后,反馈传递回相同的模型,以细化之前生成的方案,这个过程会持续一定的次数,直到M确定不需要进一步地细化。我们使用few-shot指导M产生反馈,并将反馈纳入了改进的草案之中。
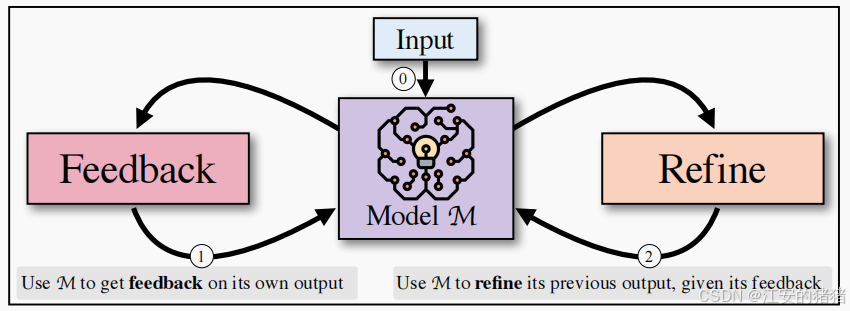
结果表明,即使LLM在第一次尝试时不能生成最优输出,LLM通常也可以提供有用的反馈,并相应地改进自己的输出。反过来,自我优化提供了一种有效的方法,通过迭代(自)反馈和细化,不需要任何额外的训练,从单个模型中获得更好的输出。




















 1482
1482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











