






高贵如我, 总被刁民盯上... 【B站最好的OpenCV课程推荐】OpenCV从入门到实战 全套课程(附带课程课件资料+课件笔记)图像处理|深度学习人工智能计算机视觉python+AI
【B站最好的OpenCV课程推荐】OpenCV从入门到实战 全套课程(附带课程课件资料+课件笔记)图像处理|深度学习人工智能计算机视觉python+AI
中间有一些不懂的地方
一些相关实验
模板匹配
import cv2
img = cv2.imread("image/tori.png", 0)
template = cv2.imread("image/tori2.png", 0)
print("img.shape: {}".format(img.shape))
print("template.shape: {}".format(template.shape))
res = cv2.matchTemplate(img, template, cv2.TM_SQDIFF)
print("res.shape: {}".format(res.shape))
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
print("min_val: {}".format(min_val))
print("max_val: {}".format(max_val))
print("min_loc: {}".format(min_loc))
print("max_loc: {}".format(max_loc))
## 运行结果 ===================================================
img.shape: (1080, 1920)
template.shape: (410, 578)
res.shape: (671, 1343)
min_val: 1360896.0
max_val: 174203904.0
min_loc: (599, 321)
max_loc: (415, 348)画出效果图
// 其他代码不变...
def show_img(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
h, w = template.shape[:2]
top_left = min_loc
bottom_right = top_left[0] + w, top_left[1] + h
cv2.rectangle(img, top_left, bottom_right, 255, 2)
show_img("标记后的图片", img)
模板多匹配
import cv2
import numpy as np
def show_img(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img = cv2.imread("image/cpu.png", 0)
template = cv2.imread("image/house.png", 0)
h, w = template.shape[:2]
res = cv2.matchTemplate(img, template, cv2.TM_CCOEFF_NORMED)
threshold = 0.4
loc = np.where(res >= threshold)
for p in zip(*loc[::-1]):
bottom_right = (p[0]+w, p[1] + h)
cv2.rectangle(img, p, bottom_right, (0, 0, 255), 2)
show_img("img", img)
傅里叶变化
低通滤波
.. 这里太难了, 先不写
信用卡识别
- 引入number图片并进行灰度处理
- 反向二值化处理---因为轮廓检测输入的都是二值图像

- 外轮廓检测

- 排序轮廓
这是因为轮廓并不是按照从左上到右下检测, 而是从右下到左上 - 引入card图片并进行灰度处理

- 做顶帽操作, 突出更明亮的区域

- 做梯度检测

- 将图片模糊化

- 二值处理

- 通过二值画轮廓

- 通过逐个遍历轮廓信息, 找出适合号码的有用信息, 比如长宽比, 高度取值范围

- 找到合适的值之后, 用灰度图像裁剪取值

- 再对图片进行二值化处理, 然后可以得到轮廓从而获取每一个数字

- 通过轮廓截取数字

- 将拿到的数字和标准数字进行比对, 得到的最大的值就是匹配到的值
突出明亮的区域
可以使用顶帽操作, 假设有一个边界值m(0<m<255), 当大于m的时候, 将m识别为白色, 低于m识别为黑色, 这个m值由卷积核的宽高决定, 宽高越大, m值越小
轮廓检测方法
- 先将图片二值化, 只有二值化的图片才能画出轮廓
- 指出画出轮廓的策略, 比如只画外部轮廓
- 得到一个数组, 保存轮廓位置信息
利用轮廓, 截取图片
opencv中, 灰度图片的格式是二维数组, , 截取矩形时, 只需要用左上角和右下角标出边界值
小票检测
- 边缘检测
因为小票是随便拍出来的, 需要先将小票框起来
- 提取轮廓
通过排序找到最大的轮廓, 并用近似的方式找到四个点, 将四个点画到原始图像中并连接起来
- 通过透视变换, 将轮廓中的小票提取出来

- 通过灰度处理和二值化处理, 得到黑白图片, 方便pytesseract识别

- pytesseract
文字识别的工具包
灰度处理的错误理解
灰度处理不只是将图片变为灰色, 而是将原来的多通道变为了单通道, 因此才是灰色
角点检测

卷积理解
温馨提示: 链接打开需要魔法
再一次理解, 无论是之前的信用卡识别, 还是小票检测, 似乎都是在利用某种方法, 提取检测对象的特征, 这些并不真正算是深度学习
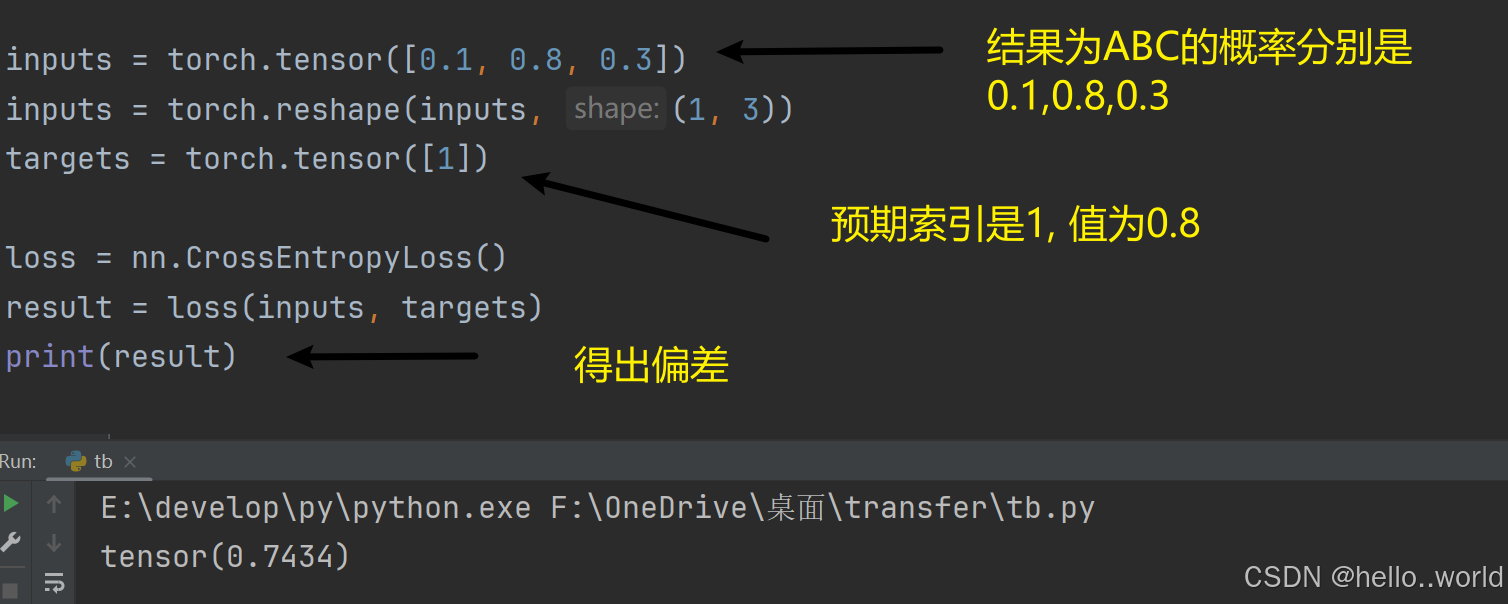
偏差函数
用来计算实际的输出和预期的输出上产生的偏差, 但并不是说输出和预期相同偏差就为0, 最后结果的输出是输出各个可能的结果概率最大的哪个结果, 假设概率为0.8的值是最大的, 那么这个概率要和其他可能结果的概率进行偏差函数运算
初めまして,模型训练です
训练模型以及保存模型
训练代码
import torch.optim
import torchvision.datasets
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("data1", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=2)
class T(nn.Module):
def __init__(self):
super(T, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
t = T()
optim = torch.optim.SGD(t.parameters(), lr=0.01)
loss = nn.CrossEntropyLoss()
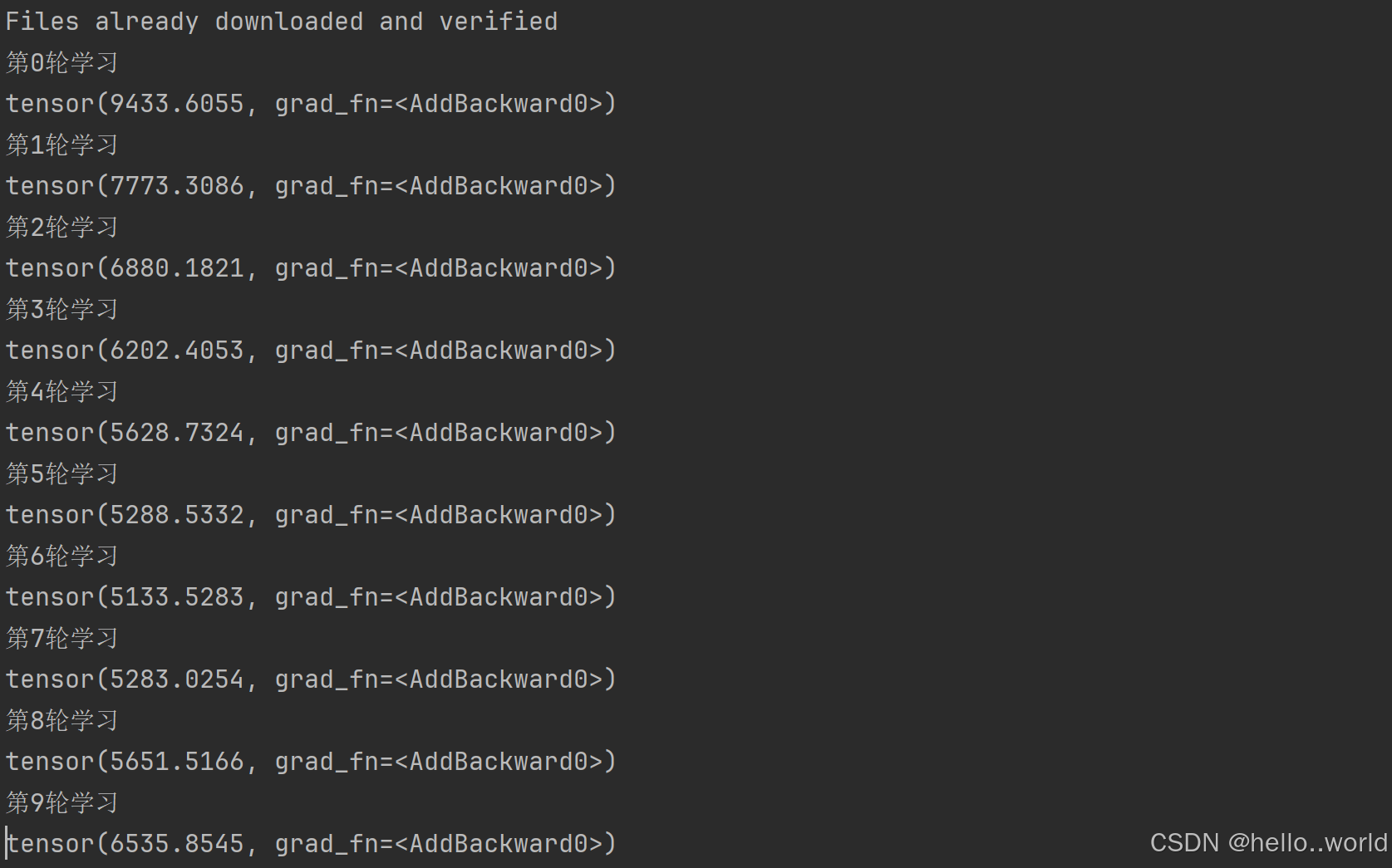
for epoch in range(10):
print("第{}轮学习".format(epoch))
result_epoch = 0.0
for data in dataloader:
imgs, targets = data
outputs = t(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
result_epoch += result_loss
# print(result_loss)
print(result_epoch)
torch.save(t, "t.pth")
使用模型, 我这里只循环了10次
import torch
import torch.optim
import torchvision.datasets
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
class T(nn.Module):
def __init__(self):
super(T, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
model = torch.load("t.pth")
dataset = torchvision.datasets.CIFAR10("data1", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=2)
num = 0
for data in dataloader:
imgs, target = data
outputs = model(imgs)
_, predicted = torch.max(outputs, 1)
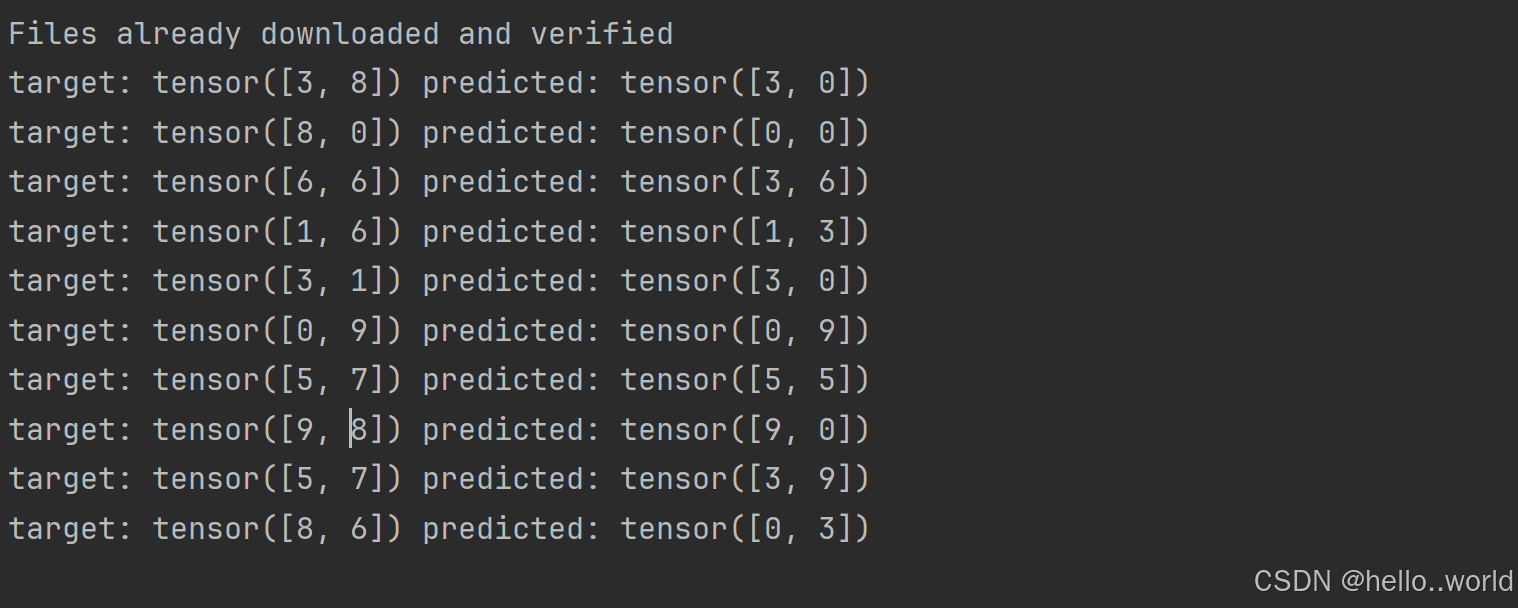
print("target: {}".format(target), "predicted: {}".format(predicted))
num += 1
if num == 10:
break
从结果来看, 和预期的契合度并不是特别高 , 但其实也可以理解, 毕竟网上稍微好一点的模型都是以G起步的

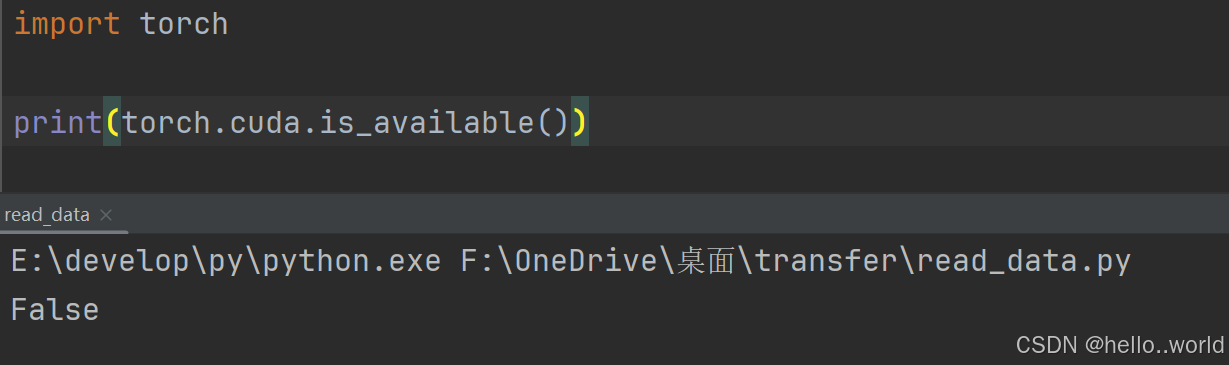
GPU训练
使用GPU训练的话会快一点, 一定要判断一下电脑有没有GPU驱动, 我电脑上就没有
可以访问Google的远程python IDE
 默认情况下, 是没用GPU加速的, 点击修改, 修改笔记本设置, 使用GPU加速 , 每周30个小时免费使用
默认情况下, 是没用GPU加速的, 点击修改, 修改笔记本设置, 使用GPU加速 , 每周30个小时免费使用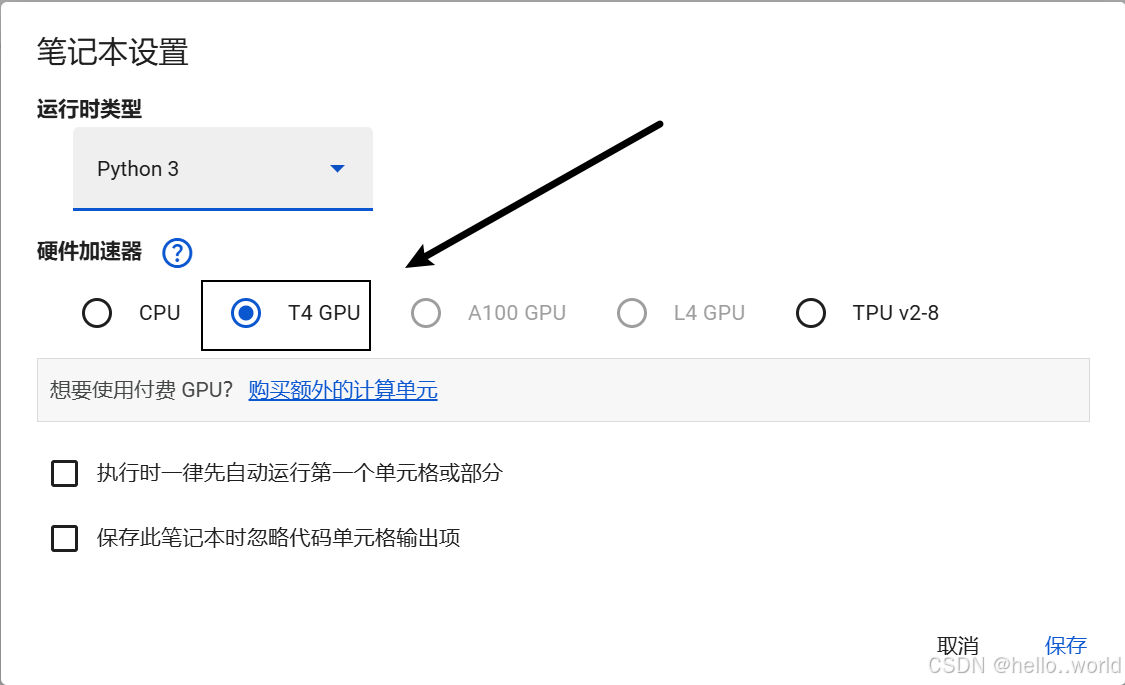
这样就可以使用GPU加速了

模型的使用
使用训练好的图片模型之前, 一定要查看模型适合的图片信息, 这里就是3通道,大小为32x32的图片,放入其他类型的图片会报错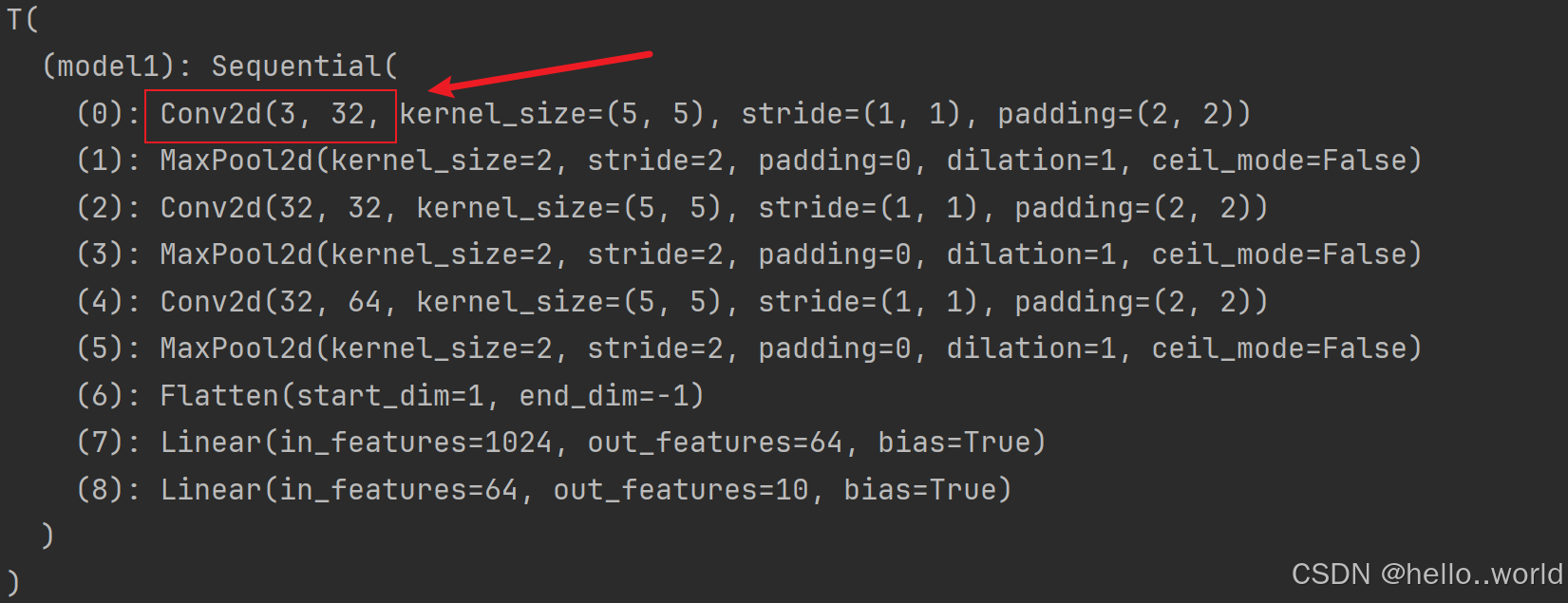
可以使用代码进行格式的调整
import torchvision.transforms
from PIL import Image
image = Image.open("image/tori.png")
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()
])
image = image.convert('RGB')
image = transform(image)
image = torch.reshape(image, (1, 3, 32, 32))
print(image.shape)训练完时用的模型如果是GPU或其他设备, 再使用这个模型的时候, 如果用CPU, 那么要指定设备类型
model = torch.load("xx_gpu.pth",map_location=torch.device('cpu'))卷积核? 滤波器 ?
多个卷积核可以提取一个图像的多种特征
特征匹配
匹配两个图片的相同特征

图像拼接
这个视频逻辑讲的比较清楚, 好多检测代码都是手搓的






答题卡识别
- 图片灰度处理

- 边缘检测

- 按照边缘检测的结果画出最边缘的框

- 透视变换

- 二值处理

- 将拿到的二值再次进行边缘检测, 通过测试图中圆的基本属性来定位范围
- 逐个遍历符合的边缘值并画出图像

- 将得到的图像和答题卡二值后的图像进行掩码操作, 将mask白色的区域和原来图像相应的区域进行比较, 计算差值, 差值越大, 表明这个值是被选中的值
- 最后计算得分, 并将得分在图像中标记出来

- 源码
判卷系统源码


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









