




说明:本文章参考的代码仓库来自此处,文章来源自此处。
一、主要问题
交通流预测的目的是在给定历史观测值的情况下,预测未来交通系统的交通流。形式上,给定在交通系统上观测到的交通流张量X(X表示所有节点在在总T个时间片上的交通流
张量),我们的目标是从之前T步的流量观测值中学习映射函数f来预测未来T步的交通流。
![]()
二、模型框架
PDFormer的框架如下图所示,由数据嵌入层、堆叠L个的时空编码器层和输出层组成。下面我们对每个模块及其实现代码进行了详细的描述。
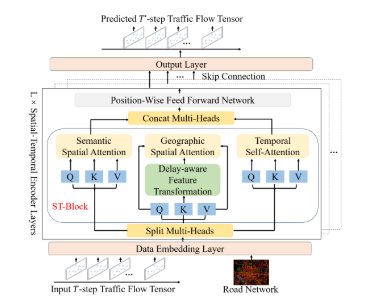
2.1数据嵌入层
第一步。数据嵌入层将输入转换为高维表示。首先,将原始输入X通过全连通层转换为X_data∈RT (N×d), d为嵌入维数。在这一步我们将维度为R(N×C)原始交通流张量(其中C是交通流的维数,在这里一般为2)转换成RT (N×d)这个大小。具体实现代码如下:
class TokenEmbedding(nn.Module):
def __init__(self, input_dim, embed_dim, norm_layer=None):
super().__init__()
self.token_embed = nn.Linear(input_dim, embed_dim, bias=True) #input_dim输入特征维度, embed_dim输出嵌入向量维度,bias=True 表示包含偏置项
self.norm = norm_layer(embed_dim) if norm_layer is not None else nn.Identity() #如果提供了 norm_layer(如 nn.LayerNorm),则使用该归一化层,否则使用恒等映射 nn.Identity()(即不做任何处理)
def forward(self, x): #前向传播逐个应用
x = self.token_embed(x)
x = self.norm(x)
return x
第二步。设计了一个时空嵌入机制,将必要的知识纳入模型,包括空间图拉普拉斯嵌入对路网结构进行编码,时间周期嵌入对交通流的周期性进行建模。
路网结构的编码。
经过拉普拉斯变在化之前我们先对原始向量X进行了正余弦位置编码,然后我们通过拉普拉斯特征化处理可以生成空间图的拉普拉斯嵌入Xspe∈R(N×d)。拉普拉斯特征向量将图嵌入欧氏空间,并保留全局图结构信息。具体代码实现如下:
class PositionalEncoding(nn.Module):
def __init__(self, embed_dim, max_len=100):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, embed_dim).float() #创建形状为 (max_len, embed_dim) 的零张量,用于存储位置编码
pe.require_grad = False #设置不需要梯度计算(位置编码是固定的,不参与训练)
position = torch.arange(0, max_len).float().unsqueeze(1) #创建位置索引 [0, 1, 2, ..., max_len-1] 并通过unsqueeze(1)添加一个维度 -> (max_len, 1)
# 计算除数项(用于生成不同频率的正弦/余弦波):
# 1. 创建 [0, 2, 4, ..., embed_dim-2] 的序列
# 2. 应用公式:exp(-(2i)/d_model * ln(10000)) = (10000)^(-2i/d_model)
div_term = (torch.arange(0, embed_dim, 2).float() * -(math.log(10000.0) / embed_dim)).exp()
pe[:, 0::2] = torch.sin(position * div_term) # 对偶数索引位置应用正弦函数
pe[:, 1::2] = torch.cos(position * div_term) # 对奇数索引位置应用余弦函数
pe = pe.unsqueeze(0) # 添加批次维度 -> (1, max_len, embed_dim)
self.register_buffer('pe', pe)
def forward(self, x):
# 1. 选择前 x.size(1) 个位置编码(根据输入序列长度)sequence_len
# 2. 添加维度使其与输入 x 维度匹配
# 3. 扩展为与 x 相同的形状
# 4. 分离计算图(确保不参与梯度计算)
return self.pe[:, :x.size(1)].unsqueeze(2).expand_as(x).detach()
"""
维度变换:
pe初始: (max_len, embed_dim)
unsqueeze(0) -> (1, max_len, embed_dim)
forward中:
[:, :seq_len] -> (1, seq_len, embed_dim)
unsqueeze(2) -> (1, seq_len, 1, embed_dim) # 添加节点维度
expand_as(x) -> (batch, seq_len(即x.size(1)), num_nodes, embed_dim)
"""
class LaplacianPE(nn.Module):
def __init__(self, lape_dim, embed_dim):
super().__init__()
self.embedding_lap_pos_enc = nn.Linear(lape_dim, embed_dim) # 线性变换层:将拉普拉斯特征向量映射到嵌入空间
def forward(self, lap_mx):
# 1. 应用线性变换:(num_nodes, lape_dim) -> (num_nodes, embed_dim)
# 2. 添加序列维度:(num_nodes, embed_dim) -> (1, num_nodes, embed_dim)
# 3. 添加批次维度:(1, num_nodes, embed_dim) -> (1, 1, num_nodes, embed_dim)
lap_pos_enc = self.embedding_lap_pos_enc(lap_mx).unsqueeze(0).unsqueeze(0)
return lap_pos_enc
"""
维度变换:
输入: (num_nodes, lape_dim)
线性层: (num_nodes, embed_dim)
unsqueeze(0) -> (1, num_nodes, embed_dim)
unsqueeze(0) -> (1, 1, num_nodes, embed_dim)
"""
时间周期嵌入。
引入两个嵌入分别覆盖每周和每日的周期性,记为tw(t), td(t)∈R(d)。这里w(t)和d(t)是将时间t分别转换为周指数(1到7)和分钟指数(1到1440)的函数。通过将所有T个时间片的嵌入连接起来,得到了时序周期嵌入Xw,Xd∈R(T×d)。继最初的Transformer (Vaswani et al. 2017)之后,我们还采用了一个时间位置编码xtype∈R(T ×d)【这个时间位置编码在代码中并没有发现在哪体现】来引入输入序列的位置信息。最后,我们通过简单地将上述嵌入向量求和得到数据嵌入层的输出:
![]()
具体的代码实现如下:
class DataEmbedding(nn.Module): #这个类实现了多模态数据嵌入,结合了多种嵌入技术来处理时空图数据。
def __init__(
self, feature_dim, embed_dim, lape_dim, adj_mx, drop=0.,
add_time_in_day=False, add_day_in_week=False, device=torch.device('cpu'),
):
super().__init__()
# 保存时间特征标志即每周和每日的周期性
self.add_time_in_day = add_time_in_day
self.add_day_in_week = add_day_in_week
self.device = device
self.embed_dim = embed_dim
self.feature_dim = feature_dim
self.value_embedding = TokenEmbedding(feature_dim, embed_dim) # 1. 核心特征嵌入层,应用到了前面的TokenEmbedding类
self.position_encoding = PositionalEncoding(embed_dim) # 2. 序列位置编码(处理时间序列顺序)
if self.add_time_in_day: # 3. 时间特征嵌入(一天中的时间)
self.minute_size = 1440
self.daytime_embedding = nn.Embedding(self.minute_size, embed_dim)
if self.add_day_in_week: # 4. 时间特征嵌入(一周中的天)
weekday_size = 7
self.weekday_embedding = nn.Embedding(weekday_size, embed_dim)
self.spatial_embedding = LaplacianPE(lape_dim, embed_dim) # 5. 空间位置编码(基于图结构)
self.dropout = nn.Dropout(drop) # 6. Dropout层防止过拟合,在这里的池化概率设置为0
def forward(self, x, lap_mx): #这一步对应了论文中各个特征的向量直接相加。公式二
origin_x = x # 保存原始输入(包含特征和时间信息)
x = self.value_embedding(origin_x[:, :, :, :self.feature_dim]) # 1. 核心特征嵌入:仅处理原始特征部分(排除时间特征)
x += self.position_encoding(x) # 2. 添加序列位置编码(时间顺序)
if self.add_time_in_day: # 3. 添加一天中的时间信息
x += self.daytime_embedding((origin_x[:, :, :, self.feature_dim] * self.minute_size).round().long()) # 提取并转换时间特征(归一化时间 -> 分钟索引)
if self.add_day_in_week: # 4. 添加一周中的天信息
x += self.weekday_embedding(origin_x[:, :, :, self.feature_dim + 1: self.feature_dim + 8].argmax(dim=3))
x += self.spatial_embedding(lap_mx) # 5. 添加空间位置编码(图结构信息)
x = self.dropout(x) # 6. 应用Dropout
return x
Droppath模块。
class DropPath(nn.Module):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
为什么需要droppath
1、解决深度网络问题
| 问题 | DropPath 的作用 |
|---|---|
| 过拟合 | 强制网络学习冗余表示 |
| 梯度消失 | 创建更短的路径 |
| 协同适应 | 打破神经元间的过度依赖 |
- 与传统 Dropout 对比
| 特性 | Dropout | DropPath |
|---|---|---|
| 丢弃单位 | 神经元 | 整个模块分支 |
| 适用场景 | 全连接层 | 残差连接 |
| 保持结构 | ❌ 破坏特征图 | ✅ 保持空间结构 |
| 对CNN效果 | 一般 | 优秀 |
| 对Transformer效果 | 中等 | 优秀 |
Chomp2d模块。
核心功能:裁剪多余填充。
解决卷积填充问题:在因果卷积或非对称卷积中,我们经常需要在输入的一侧添加填充
裁剪多余部分:移除由于填充导致的输出中的无效部分
保持尺寸一致:确保输出尺寸与预期一致
class Chomp2d(nn.Module):
def __init__(self, chomp_size):
super(Chomp2d, self).__init__()
self.chomp_size = chomp_size # 保存需要裁剪的尺寸
def forward(self, x):
# 裁剪输入张量x的第2维(高度维度)
# 保留从开始到 (总高度 - chomp_size) 的部分
return x[:, :, :x.shape[2] - self.chomp_size, :].contiguous()
Chomp2d 是一个简单但关键的设计,特别在实现因果卷积和保持特征图尺寸一致时必不可少。它通过精确定位并裁剪卷积操作产生的多余填充,确保网络能够正确处理序列数据的时间依赖关系,同时保持特征图的空间尺寸符合预期。
2.2时空编码层
这里设计了一个基于自注意机制的时空编码器层,对复杂的动态时空依赖关系进行建模。编码器层的核心包括三个组件。第一个是空间自注意模块,由地理空间自注意模块和语义空间自注意模块组成,用于同时捕获短程和远程动态空间依赖关系。二是延迟感知特征转换模块,对地理空间自注意模块进行扩展,明确建模空间信息传播中的时间延迟。此外,第三个是捕获动态和远程时间模式的时间自注意模块。
空间自注意模块。
这里设计了一个空间自我注意模块来捕捉交通数据中的动态空间依赖关系。形式上,在时刻t,我们首先获得自注意操作的查询、键和值矩阵为:
![]()
然后应用空间维度上的自注意操作对节点之间的相互作用进行建模,并获得时间t时所有节点之间的空间依赖关系(注意分数)为:
![]()
可以看出,节点之间的空间依赖关系A(S)t∈RN×N在不同的时间片上是不同的,即动态的。因此,SSA模块可以用于捕获动态空间依赖关系。最后,可以通过将注意分数与值矩阵相乘,得到空间自注意模块的输出:
![]()
下面代码是对于空间自注意模块的实现,并且在空间自注意模块中加入了关于时间的延迟感知特征变换,将延迟信息融入到了地理空间自注意模块的关键矩阵中去。
class STSelfAttention(nn.Module): #定义了一个三合一的自注意力模块,包含地理(geo)、语义(sem)和时间(t)三种注意力机制
def __init__(
self, dim, s_attn_size, t_attn_size, geo_num_heads=4, sem_num_heads=2, t_num_heads=2, qkv_bias=False,
attn_drop=0., proj_drop=0., device=torch.device('cpu'), output_dim=1,
):
"""
dim: 输入特征维度
s_attn_size / t_attn_size: 空间 / 时间注意力范围(代码中未直接使用)
*_num_heads: 三种注意力的头数
qkv_bias: 是否在QKV变换中添加偏置
attn_drop / proj_drop: 注意力权重和输出层的dropout率,在这里均是0
output_dim: 模式注意力的输出分支数
"""
super().__init__()
assert dim % (geo_num_heads + sem_num_heads + t_num_heads) == 0 #验证总头数能整除特征维度,确保多头注意力可分割。%在这里是取余操作。
self.geo_num_heads = geo_num_heads
self.sem_num_heads = sem_num_heads
self.t_num_heads = t_num_heads
self.head_dim = dim // (geo_num_heads + sem_num_heads + t_num_heads) #计算每个注意力头的维度
self.scale = self.head_dim ** -0.5 #设置注意力缩放因子(1/√d_k),核心作用是解决点积计算结果数值稳定性问题,确保梯度有效传播并提升模型表达能力。
self.device = device
self.s_attn_size = s_attn_size
self.t_attn_size = t_attn_size
#计算三种注意力所占的特征比例:
self.geo_ratio = geo_num_heads / (geo_num_heads + sem_num_heads + t_num_heads)
self.sem_ratio = sem_num_heads / (geo_num_heads + sem_num_heads + t_num_heads)
self.t_ratio = 1 - self.geo_ratio - self.sem_ratio
self.output_dim = output_dim
#1. 通过列表推导式 [nn.Linear(...) for _ in range(output_dim)] 创建了 output_dim 个独立的线性层,这些层被封装在 ModuleList 中,支持按索引迭代或访问。
#2. 代码中的三组线性层分别对应注意力机制中的 Query(Q)、Key(K)、Value(V)投影:pattern_q_linears:生成查询向量(Query)的投影矩阵;pattern_k_linears:生成键向量(Key)的投影矩阵;pattern_v_linears:生成值向量(Value)的投影矩阵
#3. 设计目的:并行多头处理:每个注意力头拥有独立的Q/K/V投影矩阵,使不同头能学习不同的语义特征(如语法、语义、上下文)。;维度灵活性:通过 geo_ratio 控制每个头的隐空间维度,平衡模型容量与计算效率。
self.pattern_q_linears = nn.ModuleList([
nn.Linear(dim, int(dim * self.geo_ratio)) for _ in range(output_dim)
])
self.pattern_k_linears = nn.ModuleList([
nn.Linear(dim, int(dim * self.geo_ratio)) for _ in range(output_dim)
])
self.pattern_v_linears = nn.ModuleList([
nn.Linear(dim, int(dim * self.geo_ratio)) for _ in range(output_dim)
])
#这段代码定义了几何感知注意力(Geometry-Aware Attention)主要是地理信息中的查询(Q)、键(K)、值(V)投影层,核心特点是通过 1×1 卷积(不改变向量的维度)替代传统线性层,适用于处理具有几何结构(如2D特征图)的视觉数据。
self.geo_q_conv = nn.Conv2d(dim, int(dim * self.geo_ratio), kernel_size=1, bias=qkv_bias)
self.geo_k_conv = nn.Conv2d(dim, int(dim * self.geo_ratio), kernel_size=1, bias=qkv_bias)
self.geo_v_conv = nn.Conv2d(dim, int(dim * self.geo_ratio), kernel_size=1, bias=qkv_bias)
self.geo_attn_drop = nn.Dropout(attn_drop)
#语义注意力的QKV卷积层和dropout
self.sem_q_conv = nn.Conv2d(dim, int(dim * self.sem_ratio), kernel_size=1, bias=qkv_bias)
self.sem_k_conv = nn.Conv2d(dim, int(dim * self.sem_ratio), kernel_size=1, bias=qkv_bias)
self.sem_v_conv = nn.Conv2d(dim, int(dim * self.sem_ratio), kernel_size=1, bias=qkv_bias)
self.sem_attn_drop = nn.Dropout(attn_drop)
#时间注意力的QKV卷积层和dropout
self.t_q_conv = nn.Conv2d(dim, int(dim * self.t_ratio), kernel_size=1, bias=qkv_bias)
self.t_k_conv = nn.Conv2d(dim, int(dim * self.t_ratio), kernel_size=1, bias=qkv_bias)
self.t_v_conv = nn.Conv2d(dim, int(dim * self.t_ratio), kernel_size=1, bias=qkv_bias)
self.t_attn_drop = nn.Dropout(attn_drop)
#输出的线性层和池化层
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, x_patterns, pattern_keys, geo_mask=None, sem_mask=None):
B, T, N, D = x.shape #B\T\N\D分别表示:批大小, 时间步, 节点数, 特征维度
# permute函数相当于维度转换(B, T, N, D).permute(0, 3, 2, 1) -> (B, D, T, N) ->卷积(特征维度D会变)-> (B, D*t_ratio, T, N).(0, 3, 2, 1) -> (B, N, T, D*t_ratio),t_q,t_k,t_v最终维度相同.相当于在时间维度上进行注意力
t_q = self.t_q_conv(x.permute(0, 3, 1, 2)).permute(0, 3, 2, 1)
t_k = self.t_k_conv(x.permute(0, 3, 1, 2)).permute(0, 3, 2, 1)
t_v = self.t_v_conv(x.permute(0, 3, 1, 2)).permute(0, 3, 2, 1)
# 重塑时间注意力向量形状为多头形式。(B, N, T, D*t_ratio) -> (B, N, t_num_heads, T, head_dim)
t_q = t_q.reshape(B, N, T, self.t_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
t_k = t_k.reshape(B, N, T, self.t_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
t_v = t_v.reshape(B, N, T, self.t_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
t_attn = (t_q @ t_k.transpose(-2, -1)) * self.scale # 这部分是对论文中的公式(4)实现。self.scale=1/√d_k 防止softmax梯度消失。t_k.transpose(-2, -1)表示将t_k张量最后一维和倒数第二维进行转置方便后续的矩阵乘法。最终输出维度(B, N, t_num_heads, T, T)
t_attn = t_attn.softmax(dim=-1)
t_attn = self.t_attn_drop(t_attn)
t_x = (t_attn @ t_v).transpose(2, 3).reshape(B, N, T, int(D * self.t_ratio)).transpose(1, 2) #论文中公式(5)的实现, 加权聚合。时间感知特征 t_x 输出形状为 [B,T,N,D*t_ratio]
geo_q = self.geo_q_conv(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1) # 输出维度:[B,T,N,D*geo_ratio]
geo_k = self.geo_k_conv(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1) # 同上
for i in range(self.output_dim): #循环遍历每个输出维度(多个注意力头)
pattern_q = self.pattern_q_linears[i](x_patterns[..., i]) #因为前面的pattern__linears通过ModuleList堆叠了output_dim个线性层,所以我们对第i个模式的输入特征x_patterns[..., i]使用第i个可学习线性变换(查询投影)
pattern_k = self.pattern_k_linears[i](pattern_keys[..., i])
pattern_v = self.pattern_v_linears[i](pattern_keys[..., i])
pattern_attn = (pattern_q @ pattern_k.transpose(-2, -1)) * self.scale #模式注意力计算,和上面时间注意力计算公式一致
pattern_attn = pattern_attn.softmax(dim=-1)
geo_k += pattern_attn @ pattern_v #实现了地理键的模式增强。pattern_attn @ pattern_v:注意力加权求和;+=:将模式注意力结果累加到地理键表示上
geo_v = self.geo_v_conv(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1) #使用独立卷积核生成值(value)表示,维度处理方式与geo_q/geo_k相同
#多头查询准备。reshape:将特征维度拆分为多头;permute:调整维度顺序为[B, T, geo_num_heads, N, head_dim]
geo_q = geo_q.reshape(B, T, N, self.geo_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
geo_k = geo_k.reshape(B, T, N, self.geo_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
geo_v = geo_v.reshape(B, T, N, self.geo_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
#上面是计算模式的注意力,这里计算模式增强后的地理键的注意力,计算公式对应论文中的(4)(5)
geo_attn = (geo_q @ geo_k.transpose(-2, -1)) * self.scale
if geo_mask is not None:
geo_attn.masked_fill_(geo_mask, float('-inf'))
geo_attn = geo_attn.softmax(dim=-1)
geo_attn = self.geo_attn_drop(geo_attn)
geo_x = (geo_attn @ geo_v).transpose(2, 3).reshape(B, T, N, int(D * self.geo_ratio)) #合并多头输出维度为:[B,T,N,D*geo_ratio]
#下面是对语义注意力的计算流程和上面两个注意力的计算流程相似
sem_q = self.sem_q_conv(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
sem_k = self.sem_k_conv(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
sem_v = self.sem_v_conv(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
sem_q = sem_q.reshape(B, T, N, self.sem_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
sem_k = sem_k.reshape(B, T, N, self.sem_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
sem_v = sem_v.reshape(B, T, N, self.sem_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
sem_attn = (sem_q @ sem_k.transpose(-2, -1)) * self.scale
if sem_mask is not None:
sem_attn.masked_fill_(sem_mask, float('-inf'))
sem_attn = sem_attn.softmax(dim=-1)
sem_attn = self.sem_attn_drop(sem_attn)
sem_x = (sem_attn @ sem_v).transpose(2, 3).reshape(B, T, N, int(D * self.sem_ratio)) #合并多头输出维度为:[B,T,N,D*sem_ratio]
x = self.proj(torch.cat([t_x, geo_x, sem_x], dim=-1)) #沿最后一个维度(特征维度)拼接三个不同来源的特征张量,[B, T, N, D*geo_ratio+D*t_ratio+D*sem_ratio=D]。self.proj将拼接后的高维特征融合并映射到目标维度
x = self.proj_drop(x)
return x
MLP类。
实现了一个标准的两层全连接前馈神经网络(Feed-Forward Network),这是Transformer架构中的核心组件之一。它的主要作用包括:
- 特征变换与增强:对输入特征进行非线性变换,增强模型表达能力
- 维度调整:通过隐藏层扩展特征维度(通常扩大4倍),再压缩回原始维度
- 正则化:通过Dropout防止过拟合
- 非线性引入:使用GELU等激活函数引入非线性关
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
"""
in_features:输入特征维度
hidden_features:隐藏层维度(默认None表示使用in_features)
out_features:输出特征维度(默认None表示输出维度与输入相同)
act_layer:激活函数类型(默认GELU)
drop:Dropout概率
"""
super().__init__()
#设置默认值.如果未指定,则与输入维度相同
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features) #第一层全连接:输入维度 → 隐藏层维度.实现特征维度扩展
self.act = act_layer() #激活函数实例化(默认GELU)
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
"""
前向传播流程:
通过第一线性层扩展维度
应用激活函数引入非线性
第一次Dropout正则化
通过第二线性层压缩维度
第二次Dropout正则化
"""
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
时间自我注意(TSA)模块。
不同时间片的交通状况之间存在依赖关系(例如,周期性、趋势),并且依赖关系在不同的情况下有所不同。因此,我们采用时间自我注意模块来发现动态的时间模式。
与前文模块的对比:
| 模块 | 关注维度 | 主要功能 | 适用场景 |
|---|---|---|---|
| STSelfAttention | 时空联合 | 地理+语义+时间三合一 | 复杂时空依赖建模 |
| TemporalSelfAttention | 纯时间 | 节点独立的时间演变 | 强时间依赖性任务 |
| Mlp | 特征空间 | 特征变换与增强 | 所有场景的后续处理 |
实现代码和STSelfAttention类中对于时间注意力的实现类似,不过这里只关注节点本身的时间演变并没有结合地理空间特征。
class TemporalSelfAttention(nn.Module):
#这个类实现了纯时间维度的自注意力机制,专注于在时间序列数据中捕获时间步之间的依赖关系。适用于处理时空数据中的时间动态模式。
def __init__(
self, dim, dim_out, t_attn_size, t_num_heads=6, qkv_bias=False,
attn_drop=0., proj_drop=0., device=torch.device('cpu'),
):
super().__init__()
assert dim % t_num_heads == 0
self.t_num_heads = t_num_heads
self.head_dim = dim // t_num_heads
self.scale = self.head_dim ** -0.5
self.device = device
self.t_attn_size = t_attn_size
self.t_q_conv = nn.Conv2d(dim, dim, kernel_size=1, bias=qkv_bias)
self.t_k_conv = nn.Conv2d(dim, dim, kernel_size=1, bias=qkv_bias)
self.t_v_conv = nn.Conv2d(dim, dim, kernel_size=1, bias=qkv_bias)
self.t_attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim_out)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, T, N, D = x.shape
t_q = self.t_q_conv(x.permute(0, 3, 1, 2)).permute(0, 3, 2, 1)
t_k = self.t_k_conv(x.permute(0, 3, 1, 2)).permute(0, 3, 2, 1)
t_v = self.t_v_conv(x.permute(0, 3, 1, 2)).permute(0, 3, 2, 1)
t_q = t_q.reshape(B, N, T, self.t_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
t_k = t_k.reshape(B, N, T, self.t_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
t_v = t_v.reshape(B, N, T, self.t_num_heads, self.head_dim).permute(0, 1, 3, 2, 4)
t_attn = (t_q @ t_k.transpose(-2, -1)) * self.scale
t_attn = t_attn.softmax(dim=-1)
t_attn = self.t_attn_drop(t_attn)
t_x = (t_attn @ t_v).transpose(2, 3).reshape(B, N, T, D).transpose(1, 2)
x = self.proj(t_x)
x = self.proj_drop(x)
return x
时空编码器模块。
将时空注意力机制和前馈网络组合成完整的Transformer块。将时空注意力机制和前馈网络组合成完整的Transformer块。关键特性:
1、双残差结构:每个子层都有独立的残差连接,缓解梯度消失。
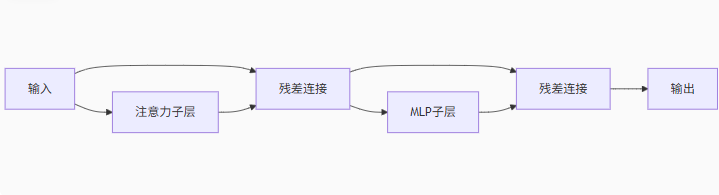
2、归一化策略对比:
| 类型 | 计算顺序 | 优点 | 缺点 |
|---|---|---|---|
| Pre-LN | Norm → Attn/MLP → Add | 训练稳定,不易梯度爆炸 | 理论一致性稍弱 |
| Post-LN | Attn/MLP → Add → Norm | 原始Transformer设计 | 需要小心初始化 |
3、模式注意力集成:
通过x_patterns和pattern_keys参数
将外部知识注入地理注意力机制
增强模型对复杂空间关系的理解
具体实现代码如下:
class STEncoderBlock(nn.Module):
def __init__(
self, dim, s_attn_size, t_attn_size, geo_num_heads=4, sem_num_heads=2, t_num_heads=2, mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, device=torch.device('cpu'), type_ln="pre", output_dim=1,
):
super().__init__()
self.type_ln = type_ln #type_ln: 归一化位置选择("pre"=前置,"post"=后置)
self.norm1 = norm_layer(dim) #第一层归一化
#初始化时空自注意力模块(复用之前定义的STSelfAttention)
self.st_attn = STSelfAttention(
dim, s_attn_size, t_attn_size, geo_num_heads=geo_num_heads, sem_num_heads=sem_num_heads, t_num_heads=t_num_heads, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop, device=device, output_dim=output_dim,
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() #当drop_path>0时启用,否则使用恒等映射
self.norm2 = norm_layer(dim) # 第二层归一化
mlp_hidden_dim = int(dim * mlp_ratio) # 计算MLP隐藏层维度
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) #初始化前馈网络(MLP)
def forward(self, x, x_patterns, pattern_keys, geo_mask=None, sem_mask=None):
if self.type_ln == 'pre': #前置归一化模式 (Pre-LN)
x = x + self.drop_path(self.st_attn(self.norm1(x), x_patterns, pattern_keys, geo_mask=geo_mask, sem_mask=sem_mask)) # 残差连接1: 时空注意力
x = x + self.drop_path(self.mlp(self.norm2(x))) # 残差连接2: 前馈网络
elif self.type_ln == 'post': #后置归一化模式 (Post-LN)
x = self.norm1(x + self.drop_path(self.st_attn(x, x_patterns, pattern_keys, geo_mask=geo_mask, sem_mask=sem_mask)))
x = self.norm2(x + self.drop_path(self.mlp(x)))
return x
三、模型搭建
我们将上面的模块进行组合搭建成PDFormer类,具体配置代码如下:
class PDFormer(AbstractTrafficStateModel):
def __init__(self, config, data_feature):
super().__init__(config, data_feature)
self._scaler = self.data_feature.get('scaler') # 数据标准化器
self.num_nodes = self.data_feature.get("num_nodes", 1) # 交通节点数
self.feature_dim = self.data_feature.get("feature_dim", 1) # 输入特征维度
self.ext_dim = self.data_feature.get("ext_dim", 0)
self.num_batches = self.data_feature.get('num_batches', 1)
self.dtw_matrix = self.data_feature.get('dtw_matrix') # 动态时间规整矩阵(语义相似度计算)
self.adj_mx = data_feature.get('adj_mx') # 空间邻接矩阵(物理拓扑)
sd_mx = data_feature.get('sd_mx') # 空间距离矩阵(地理距离)
sh_mx = data_feature.get('sh_mx')
self._logger = getLogger() #初始化日志记录器
self.dataset = config.get('dataset') #从配置中获取数据集名称
self.embed_dim = config.get('embed_dim', 64) #嵌入维度,默认为64
self.skip_dim = config.get("skip_dim", 256) #跳跃连接的维度,默认256
lape_dim = config.get('lape_dim', 8) #拉普拉斯特征向量维度,默认为8
geo_num_heads = config.get('geo_num_heads', 4) #地理注意力头数,默认 4
sem_num_heads = config.get('sem_num_heads', 2) #语义注意力头数,默认2
t_num_heads = config.get('t_num_heads', 2) #时间注意力头数,默认2
mlp_ratio = config.get("mlp_ratio", 4) #MLP扩展比例。指多层感知器(MLP)中隐藏层神经元数量相对于输入/输出层神经元数量的缩放系数,通常用于平衡模型复杂度与计算效率
qkv_bias = config.get("qkv_bias", True) # QKV是否使用偏置
drop = config.get("drop", 0.)
attn_drop = config.get("attn_drop", 0.)
drop_path = config.get("drop_path", 0.3)
self.s_attn_size = config.get("s_attn_size", 3) # 空间注意力窗口大小
self.t_attn_size = config.get("t_attn_size", 3)
enc_depth = config.get("enc_depth", 6) # 编码器层数
type_ln = config.get("type_ln", "pre") # 层归一化类型(pre/post)
self.type_short_path = config.get("type_short_path", "hop") # 邻居定义方式(距离/跳数)
self.output_dim = config.get('output_dim', 1) # 输出特征维度
self.input_window = config.get("input_window", 12) # 输入时间步长
self.output_window = config.get('output_window', 12) # 输出预测步长
add_time_in_day = config.get("add_time_in_day", True) # 是否添加一天内时间特征
add_day_in_week = config.get("add_day_in_week", True)
self.device = config.get('device', torch.device('cpu'))
self.world_size = config.get('world_size', 1) # 分布式训练进程数
self.huber_delta = config.get('huber_delta', 1) # Huber损失参数
self.quan_delta = config.get('quan_delta', 0.25) # 分位数损失参数
self.far_mask_delta = config.get('far_mask_delta', 5) # 距离掩码阈值
self.dtw_delta = config.get('dtw_delta', 5) # DTW邻居数量
self.use_curriculum_learning = config.get('use_curriculum_learning', True)
self.step_size = config.get('step_size', 2500) # 更新预测长度的步数
self.max_epoch = config.get('max_epoch', 200)
self.task_level = config.get('task_level', 0)
if self.max_epoch * self.num_batches * self.world_size < self.step_size * self.output_window: # 检查步长设置是否合理
self._logger.warning('Parameter `step_size` is too big with {} epochs and '
'the model cannot be trained for all time steps.'.format(self.max_epoch))
if self.use_curriculum_learning:
self._logger.info('Use use_curriculum_learning!')
# 根据邻居定义方式创建空间掩码
if self.type_short_path == "dist": # 基于距离的掩码
# 计算距离标准差
distances = sd_mx[~np.isinf(sd_mx)].flatten()
std = distances.std()
# 高斯归一化距离矩阵
sd_mx = np.exp(-np.square(sd_mx / std))
# 创建距离掩码(超过阈值的为True)
self.far_mask = torch.zeros(self.num_nodes, self.num_nodes).to(self.device)
self.far_mask[sd_mx < self.far_mask_delta] = 1
self.far_mask = self.far_mask.bool()
else: # 基于跳数的掩码
sh_mx = sh_mx.T # 转置跳数矩阵
# 地理掩码(跳数超过阈值的为True)
self.geo_mask = torch.zeros(self.num_nodes, self.num_nodes).to(self.device)
self.geo_mask[sh_mx >= self.far_mask_delta] = 1
self.geo_mask = self.geo_mask.bool()
# 语义掩码(DTW相似度最低的节点为True)
self.sem_mask = torch.ones(self.num_nodes, self.num_nodes).to(self.device)
sem_mask = self.dtw_matrix.argsort(axis=1)[:, :self.dtw_delta]
for i in range(self.sem_mask.shape[0]):
self.sem_mask[i][sem_mask[i]] = 0 # 相似节点设为False
self.sem_mask = self.sem_mask.bool()
self.pattern_keys = torch.from_numpy(data_feature.get('pattern_keys')).float().to(self.device) # 预定义交通模式
self.pattern_embeddings = nn.ModuleList([
TokenEmbedding(self.s_attn_size, self.embed_dim) for _ in range(self.output_dim)
]) # 为每个输出维度创建独立的嵌入层
self.enc_embed_layer = DataEmbedding(
self.feature_dim - self.ext_dim, self.embed_dim, lape_dim, self.adj_mx, drop=drop,
add_time_in_day=add_time_in_day, add_day_in_week=add_day_in_week, device=self.device,
) # 时空数据嵌入层
enc_dpr = [x.item() for x in torch.linspace(0, drop_path, enc_depth)]
# 创建多层时空编码器
self.encoder_blocks = nn.ModuleList([
STEncoderBlock(
dim=self.embed_dim, s_attn_size=self.s_attn_size, t_attn_size=self.t_attn_size, geo_num_heads=geo_num_heads, sem_num_heads=sem_num_heads, t_num_heads=t_num_heads,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop, attn_drop=attn_drop, drop_path=enc_dpr[i], act_layer=nn.GELU,
norm_layer=partial(nn.LayerNorm, eps=1e-6), device=self.device, type_ln=type_ln, output_dim=self.output_dim,
) for i in range(enc_depth)
])
# 跳跃连接层(每层编码器一个)。对应论文中输出层部分的设计
self.skip_convs = nn.ModuleList([
nn.Conv2d(
in_channels=self.embed_dim, out_channels=self.skip_dim, kernel_size=1,
) for _ in range(enc_depth)
])
# 输出卷积层1(调整时间维度)
self.end_conv1 = nn.Conv2d(
in_channels=self.input_window, out_channels=self.output_window, kernel_size=1, bias=True,
)
# 输出卷积层2(调整特征维度)
self.end_conv2 = nn.Conv2d(
in_channels=self.skip_dim, out_channels=self.output_dim, kernel_size=1, bias=True,
)
def forward(self, batch, lap_mx=None):
x = batch['X'] # 输入数据 [B, T, N, C]
T = x.shape[1] # 时间步长
x_pattern_list = [] # 创建历史流量模式窗口
for i in range(self.s_attn_size):
# 滑动截取历史窗口
x_pattern = F.pad(
x[:, :T + i + 1 - self.s_attn_size, :, :self.output_dim],
(0, 0, 0, 0, self.s_attn_size - 1 - i, 0),
"constant", 0,
).unsqueeze(-2)
x_pattern_list.append(x_pattern)
x_patterns = torch.cat(x_pattern_list, dim=-2) # (B, T, N, s_attn_size, output_dim)
x_pattern_list = []
pattern_key_list = []
for i in range(self.output_dim):
x_pattern_list.append(self.pattern_embeddings[i](x_patterns[..., i]).unsqueeze(-1))
pattern_key_list.append(self.pattern_embeddings[i](self.pattern_keys[..., i]).unsqueeze(-1))
x_patterns = torch.cat(x_pattern_list, dim=-1)
pattern_keys = torch.cat(pattern_key_list, dim=-1)
enc = self.enc_embed_layer(x, lap_mx)
skip = 0
for i, encoder_block in enumerate(self.encoder_blocks):
enc = encoder_block(enc, x_patterns, pattern_keys, self.geo_mask, self.sem_mask)
skip += self.skip_convs[i](enc.permute(0, 3, 2, 1))
skip = self.end_conv1(F.relu(skip.permute(0, 3, 2, 1)))
skip = self.end_conv2(F.relu(skip.permute(0, 3, 2, 1)))
return skip.permute(0, 3, 2, 1)
def get_loss_func(self, set_loss):
if set_loss.lower() not in ['mae', 'mse', 'rmse', 'mape', 'logcosh', 'huber', 'quantile', 'masked_mae',
'masked_mse', 'masked_rmse', 'masked_mape', 'masked_huber', 'r2', 'evar']:
self._logger.warning('Received unrecognized train loss function, set default mae loss func.')
if set_loss.lower() == 'mae':
lf = loss.masked_mae_torch
elif set_loss.lower() == 'mse':
lf = loss.masked_mse_torch
elif set_loss.lower() == 'rmse':
lf = loss.masked_rmse_torch
elif set_loss.lower() == 'mape':
lf = loss.masked_mape_torch
elif set_loss.lower() == 'logcosh':
lf = loss.log_cosh_loss
elif set_loss.lower() == 'huber':
lf = partial(loss.huber_loss, delta=self.huber_delta)
elif set_loss.lower() == 'quantile':
lf = partial(loss.quantile_loss, delta=self.quan_delta)
elif set_loss.lower() == 'masked_mae':
lf = partial(loss.masked_mae_torch, null_val=0)
elif set_loss.lower() == 'masked_mse':
lf = partial(loss.masked_mse_torch, null_val=0)
elif set_loss.lower() == 'masked_rmse':
lf = partial(loss.masked_rmse_torch, null_val=0)
elif set_loss.lower() == 'masked_mape':
lf = partial(loss.masked_mape_torch, null_val=0)
elif set_loss.lower() == 'masked_huber':
lf = partial(loss.masked_huber_loss, delta=self.huber_delta, null_val=0)
elif set_loss.lower() == 'r2':
lf = loss.r2_score_torch
elif set_loss.lower() == 'evar':
lf = loss.explained_variance_score_torch
else:
lf = loss.masked_mae_torch
return lf
def calculate_loss_without_predict(self, y_true, y_predicted, batches_seen=None, set_loss='masked_mae'):
lf = self.get_loss_func(set_loss=set_loss)
y_true = self._scaler.inverse_transform(y_true[..., :self.output_dim])
y_predicted = self._scaler.inverse_transform(y_predicted[..., :self.output_dim])
if self.training:
if batches_seen % self.step_size == 0 and self.task_level < self.output_window:
self.task_level += 1
self._logger.info('Training: task_level increase from {} to {}'.format(
self.task_level - 1, self.task_level))
self._logger.info('Current batches_seen is {}'.format(batches_seen))
if self.use_curriculum_learning:
return lf(y_predicted[:, :self.task_level, :, :], y_true[:, :self.task_level, :, :])
else:
return lf(y_predicted, y_true)
else:
return lf(y_predicted, y_true)
def calculate_loss(self, batch, batches_seen=None, lap_mx=None):
y_true = batch['y']
y_predicted = self.predict(batch, lap_mx)
return self.calculate_loss_without_predict(y_true, y_predicted, batches_seen)
def predict(self, batch, lap_mx=None):
return self.forward(batch, lap_mx)


















 3826
3826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











