




LLM学习
本篇文章大部分内容来自一文读懂LLM API应用开发基础(万字长文)-优快云博客(如果您是以学习知识为目的,请直接观看链接博客),本篇博客仅供个人学习使用,如侵权请联系删除。
LLM基本概念
token
在 LLM 中,token代表模型可以理解和生成的最小意义单位,是模型的基础单元。根据所使用的特定标记化方案,token可以表示单词、单词的一部分,甚至只表示字符。token被赋予数值或标识符,并按序列或向量排列,并被输入或从模型中输出,是模型的语言构件。
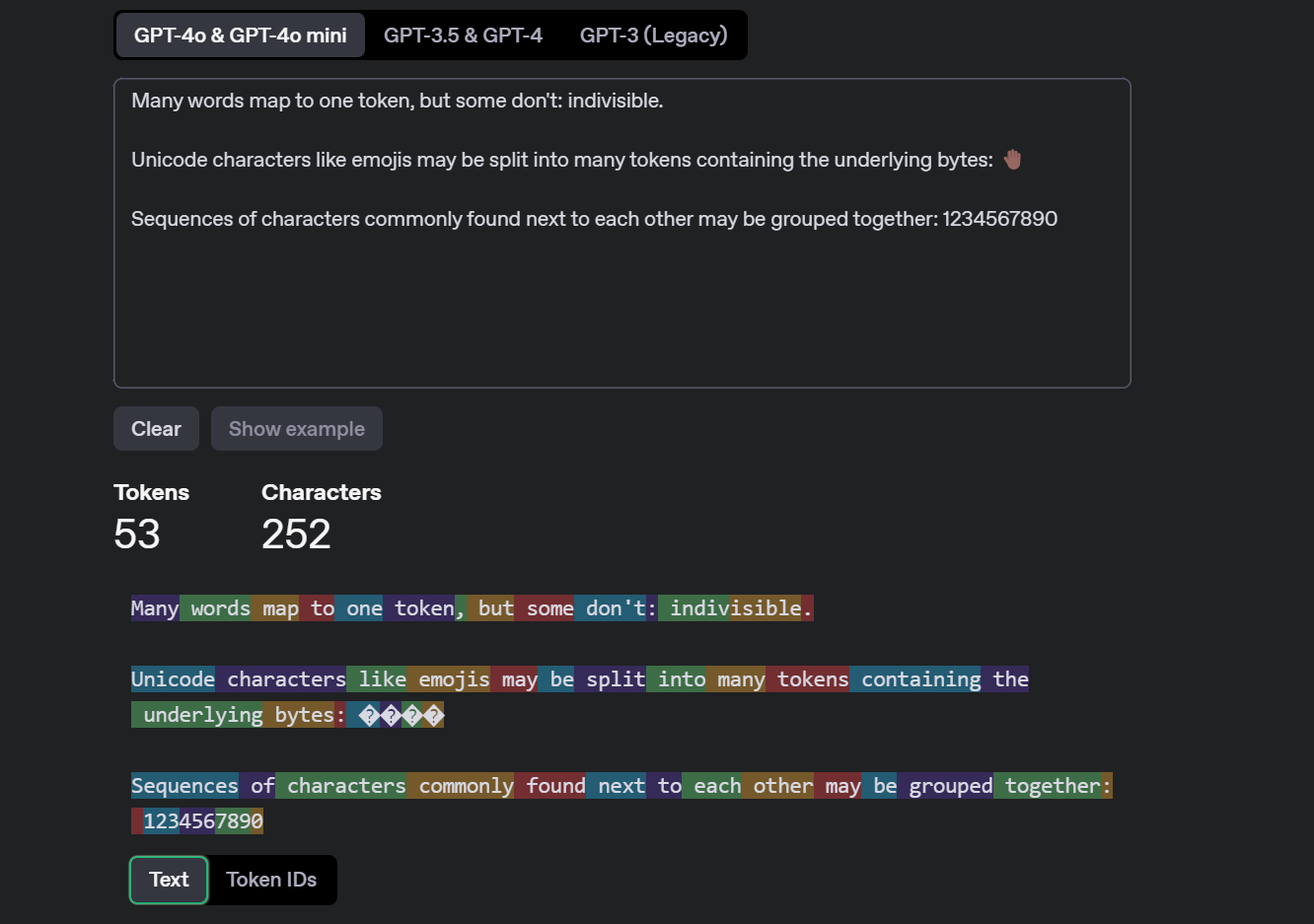
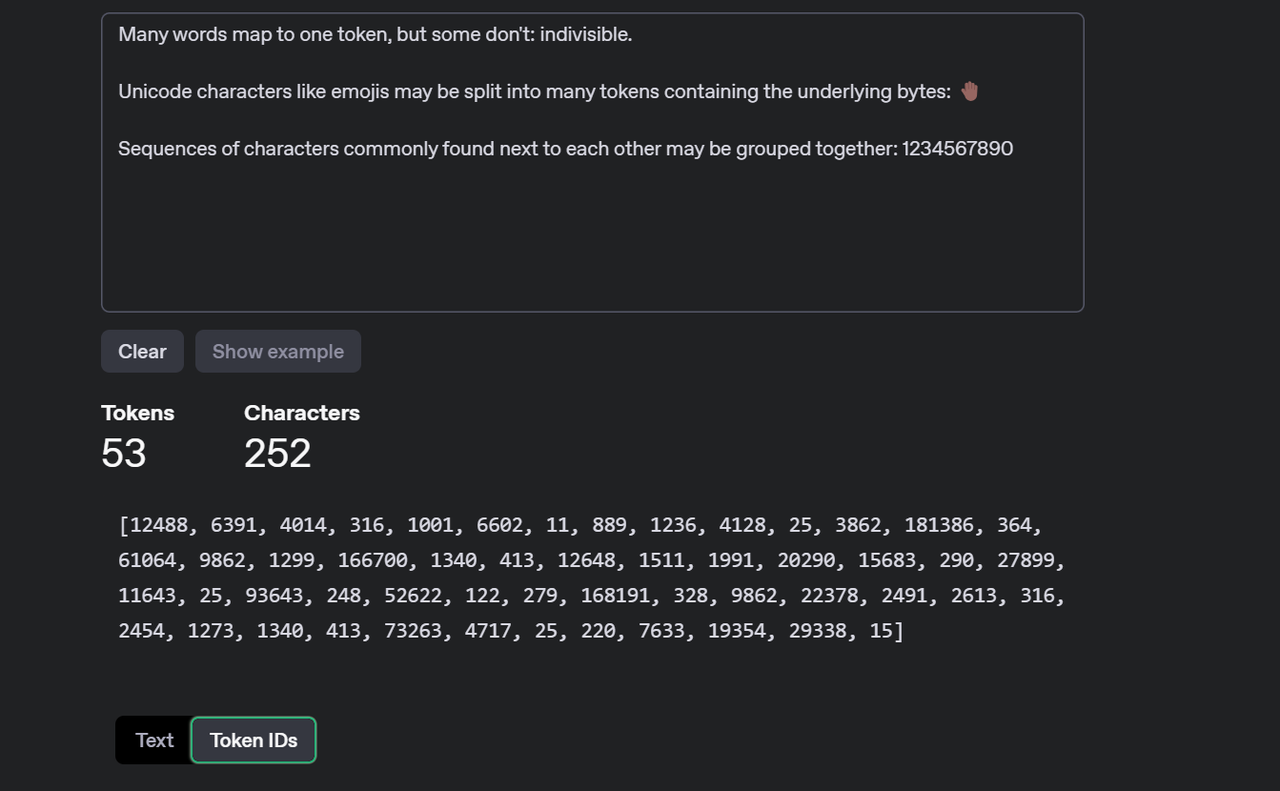
词汇表将token映射到唯一的数值表示,token编码技术可以捕获token之间的语义关系,使 LLM 能够理解和生成连贯的和上下文相关的文本
将文本划分为不同token的正式过程称为 tokenization。tokenization捕获文本的含义和语法结构,从而需要将文本分割成重要的组成部分。 tokenization是将输入和输出文本分割成更小的单元,由 LLM AI 模型处理的过程。tokenization可以帮助模型处理不同的语言、词汇表和格式,并降低计算和内存成本,还可以通过影响token的意义和语境来影响所生成文本的质量和多样性。根据文本的复杂性和可变性,可以使用不同的方法进行tokenization,比如基于规则的方法、统计方法或神经方法。
OpenAI 以及 Azure OpenAI 为其基于 GPT 的模型使用了一种称为“字节对编码(Byte-Pair Encoding,BPE)”的子词tokenization方法。BPE 是一种将最频繁出现的字符对或字节合并到单个标记中的方法,直到达到一定数量的标记或词汇表大小为止。BPE 可以帮助模型处理罕见或不可见的单词,并创建更紧凑和一致的文本表示。BPE 还允许模型通过组合现有单词或标记来生成新单词或标记。词汇表越大,模型生成的文本就越多样化并富有表现力。但是,词汇表越大,模型所需的内存和计算资源就越多。因此,词汇表的选择取决于模型的质量和效率之间的权衡。
Temperature
Temperature 是控制语言模型生成文本时的随机性和多样性的参数。
较高的温度值(如 1.0 以上)会使生成的文本更具多样性和创造性,但也可能包含更多的随机性和不确定性,适合用于文学、艺术创作等创造性工作;
较低的温度值(如 0.2 或 0.3)则会使生成的文本更加保守和确定性,但可能缺乏创造性。通过调节 temperature,可以在生成文本的多样性和稳定性之间找到平衡,适合科研写作、学习思考等严谨的工作。
Prompt
prompt是每次给模型的输入,completion是大模型返回的输出
System prompt
System Prompt 是一种特殊的提示,用于指导语言模型的行为和输出格式。在对话开始时设置系统提示,可以确定模型在整个对话过程中的基调、角色和响应风格。例如,可以在系统提示中指定模型扮演特定角色,或要求模型以正式或非正式的语气回答问题。
API使用初体验
使用python代码编写
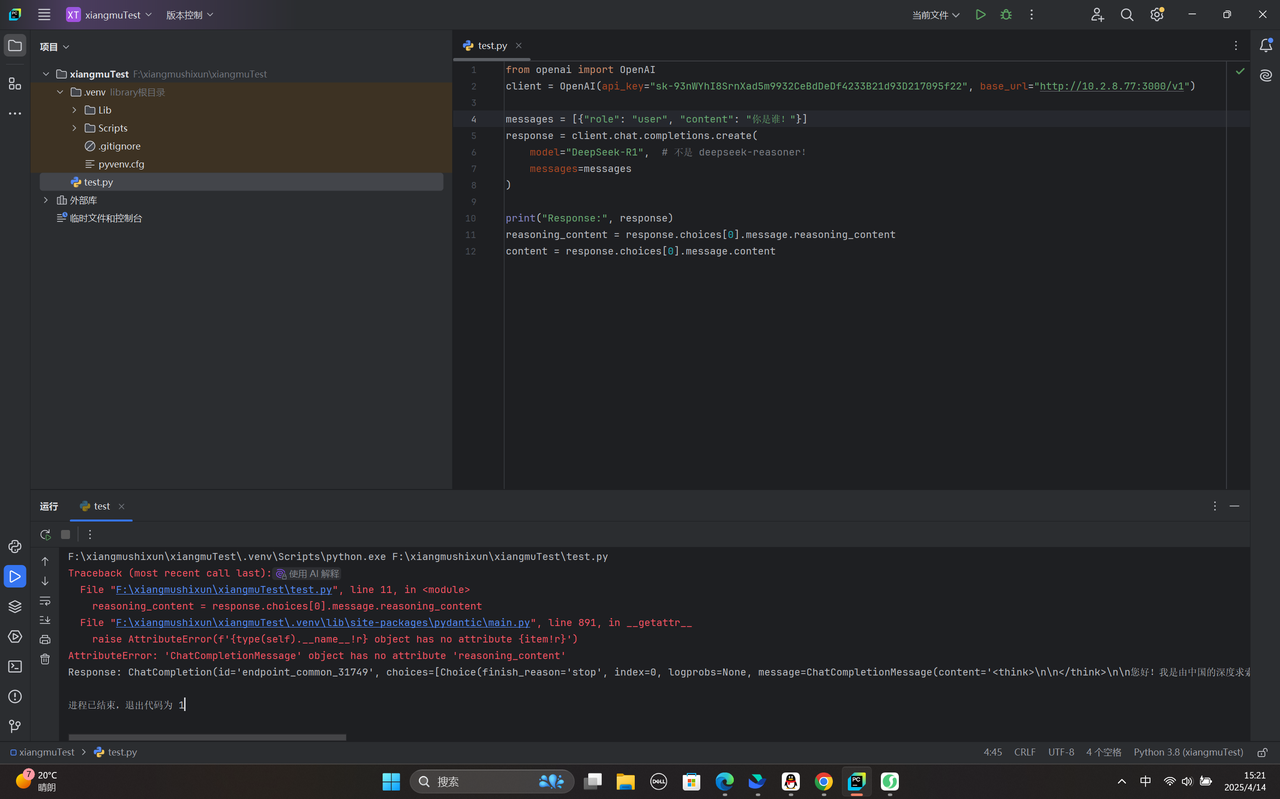
没有reasoning_content这个参数,去掉之后即不会报错
Embedding
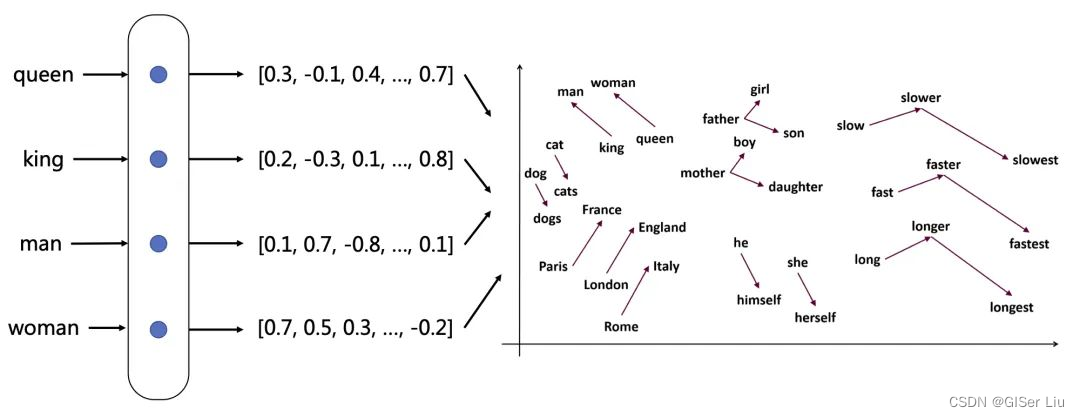
Embedding 是一种将数据(如文本)转化为向量形式的表示方法。这种表示方式确保了在某些特定方面相似的数据在向量空间中彼此接近,而与之不相关的数据则相距较远。通过将文本字符串转换为向量,使得数据能够有效用于搜索、聚类、推荐系统、异常检测和分类等应用场景。
Prompt Engine
对提示词prompt进行优化
明确性:给出的提示词清晰明了,没有歧义
具体性:给出具体的上下文信息,限定知识领域,LLM可以输出更加专业的内容,关注哪些特征,可以具体强调。细节越丰富,给出的输出越高质量。
添加分隔符
通过指定分隔符号或标识符来区分信息,可以保证模型能准确区分用户输入的Prompt中提供的辅助内容和用户需求,保证模型正确理解用户需求;主要的应用场景如下:
在某些情况下,我们输入的提示词Prompt很长,其中辅助内容也包含了某些需求(非用户需求),此时LLM可能会混淆辅助内容和用户需求,反而去回答辅助内容中的问题,忽略了真正的用户需求;
此时我们就需要通过指定分隔符,帮助LLM 区分哪一部分是辅助内容,哪一部分是用户需求;分隔符可以是空行、分割线、三引号、或者标识符;
除此之外,使用分隔符号能在一定程度上避免提示词注入攻击。
结构化输出
传统开发中,我们常用结构化的数据,如Json格式来进行 业务开发 ,而对于LLM生成的字符串,不可以直接用于生产;需要转化为对应的格式才可使用;而通过要求LLM生成结构化的回答,并通过正则方式提取是一个很好的方法,这样通过提取出规范的数据,我们就可以将LLM生成的json内容保存到数据库,再通过与传统互联网后端进行对接,就可以将LLM集成到到传统开发的工作流WorkFlow中。
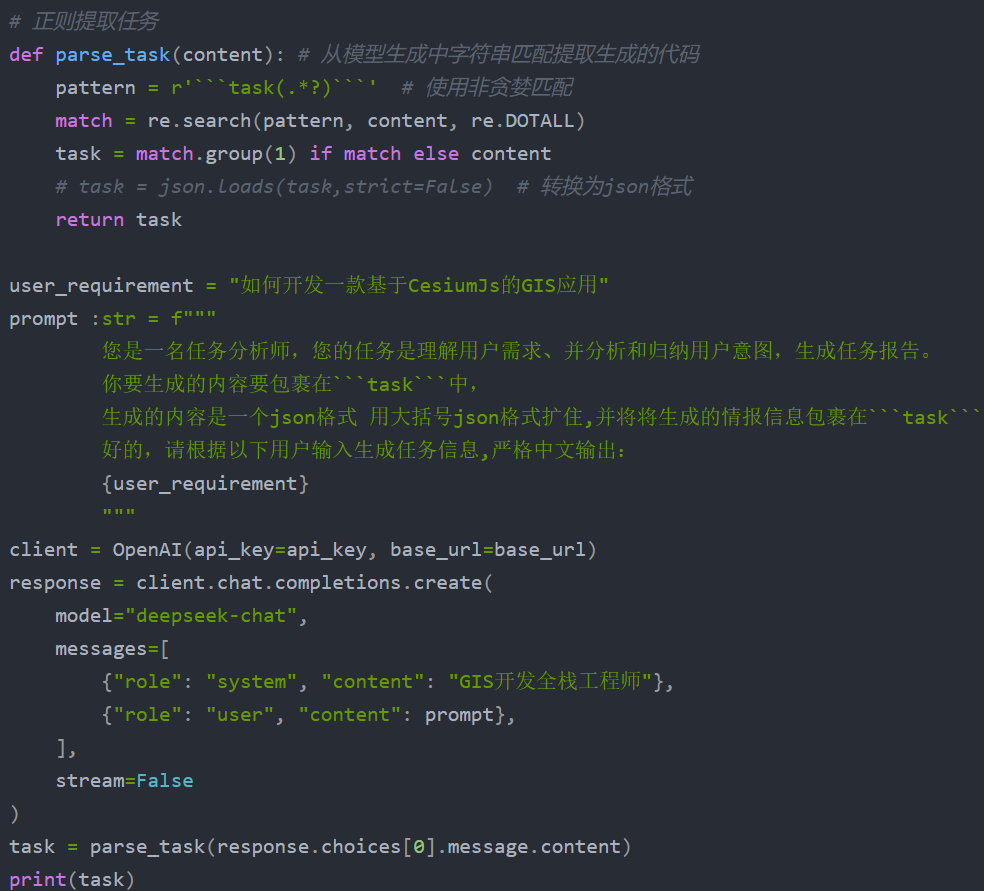
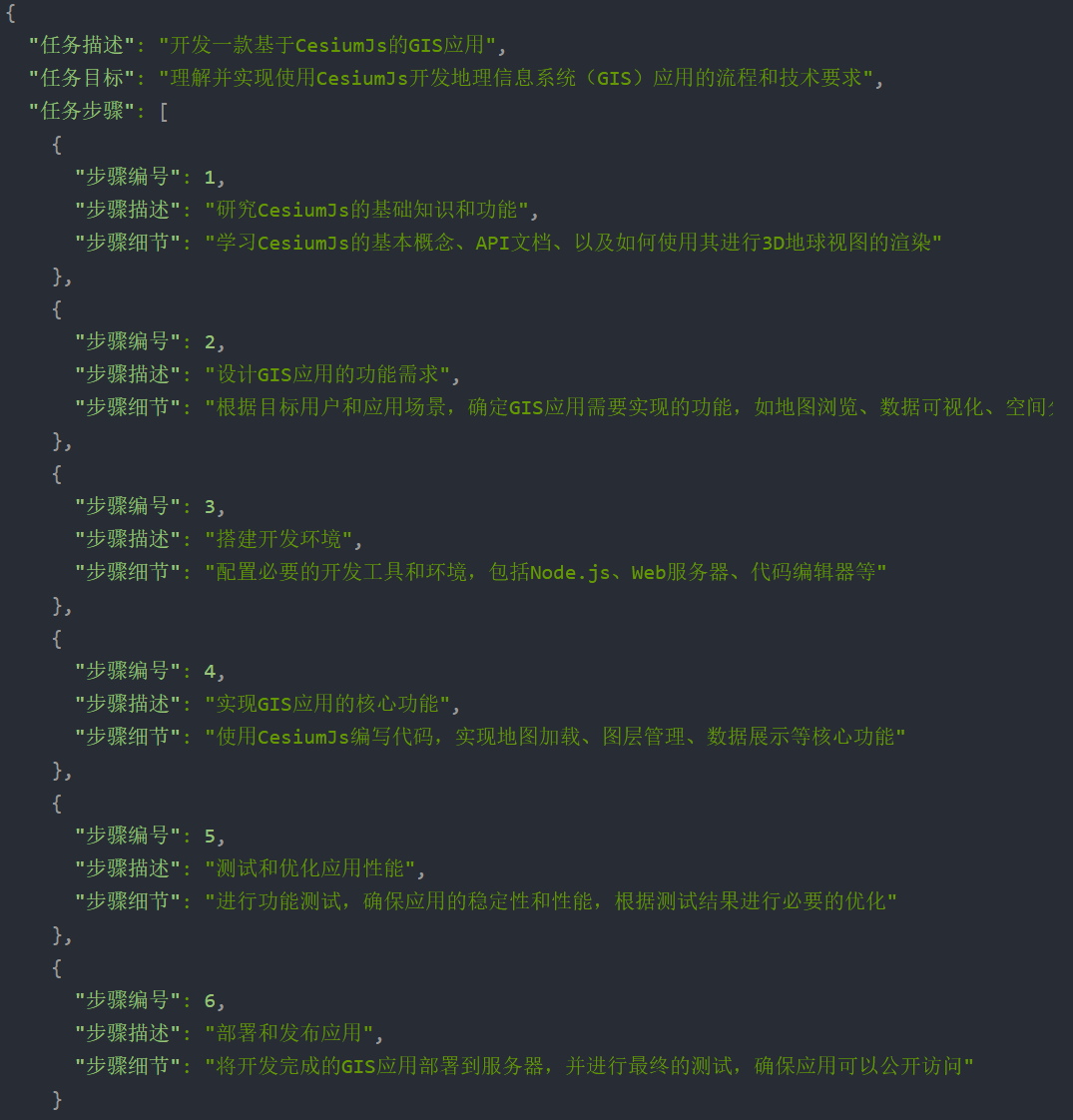
提供少量示例

防范模型幻觉现象
请求引用来源

分阶段提问,减少幻觉:通过逐步提问的方式,减少模型生成幻觉的风险,引导模型生成更可靠的内容。

















 1471
1471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









