






本文提出了一种名为MambaIRv2的图像恢复模型,该模型通过引入类似于视觉变换器(vision transformers (ViTs))的非因果建模能力,即引入注意力机制,允许模型在单次扫描中关注整个图像,解决了Mamba模型在图像恢复任务中因因果建模限制而无法充分利用图像像素的问题。
存在的问题:
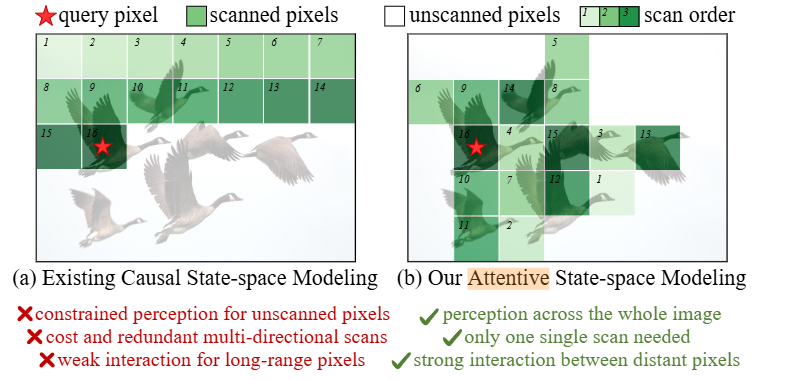
1,Mamba模型的因果建模限制使得每个像素仅依赖于扫描序列中的前序像素,这导致查询像素无法感知后续像素,从而造成像素信息的利用不足。
existing methods unfold the 2D image with a predefined scanning rule to generate the 1D token sequence. However, in Mamba, each pixel is modeled based solely on its preceding pixels in the scanned sequence.
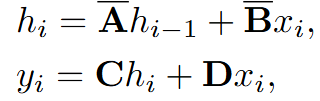
the i-th token completely depends on its previous i − 1 tokens, i.e., the state-space modeling possesses causal properties.
2,为了减少像素信息的损失,研究者提出了许多方法,大多需要多方向扫描,但这样会增加计算复杂度。并且不同的扫描有高关联,因此有很大的冗余度。
(我记得有篇论文就说了多方向扫描但是没怎么增加计算复杂度啊)
(VmambaIR: Visual State Space Model for Image Restoration这篇,好像是增加了计算复杂度,但仍然是线性的,等会再看一下)
the inherent causal property leads to the necessity of multi-directional scans, which is widely adopted by existing approaches for mitigating information loss. Yet, this multi-scanning inevitably increases the computational complexity, particularly for high-resolution inputs.
the similarity of different scanned sequences on all testing datasets reaches even above 0.7, indicating a high correlation with large redundancy
3,Mamba容易出现长距离衰减,即序列中距离较远的标记之间的交互作用减弱,导致即使先前扫描过的、但距离较远的相关像素也无法被查询像素有效利用。
Mamba is prone to longrange decay in token interaction, meaning distant tokens in the sequence have diminished interactions. Consequently, even previously scanned pixels that are distant yet relevant cannot be effectively utilized by the query pixel.
解决:
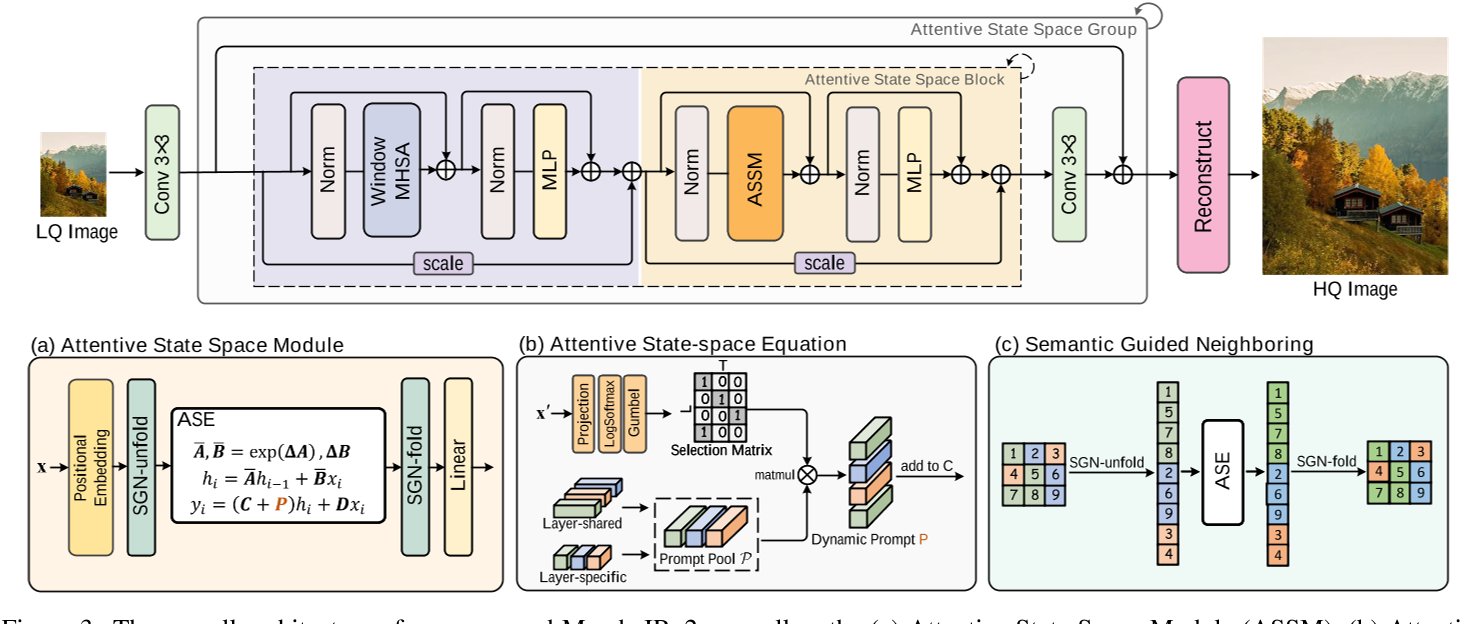
1,Attentive State-space Equation (ASE)
引入注意力机制来解决mamba的因果模型限制,使得每个像素不仅仅依赖于扫描序列中的前序像素,第一个问题解决了。并且此时就不需要多方向扫描了,没有第二个问题了。
那为什么能引入注意力机制来解决mamba的因果模型的限制?
(1)attention mechanism possesses non-causal properties
(2)the output matrix of the statespace equation resembles the query in the attention mechanism. This similarity inspires us to utilize the output matrix to "query" relevant pixels in the unscanned sequence
2,Semantic Guided Neighboring (SGN)
restructure the image to place similar pixels spatially closer within the 1D sequence. In this way, it allows for semantic rather than spatial sequence modeling, thus mitigating the impact of long-range decay.
不是直接解决了mamba的长距离衰减问题,而是间接的解决。具体做法是在展开为1D的时候,让语义上更接近的token更近一点,而不是位置上更近的近一些,这样能让长距离衰减带来的影响小一些。
first assign the corresponding semantic label to each pixel. Then restructure the image based on these labels to generate the semantic-neighboring 1D sequence, where semantically similar pixels are also spatially close to each other.
此外:
1,window multi-head self-attention (MHSA) to enhance local interactions within the window
本文的框架:
MHSA :to enhance local interactions within the window
(Mamba captures the global dependencies,so modeling local interactions is crucial for Mamba-based approaches.)
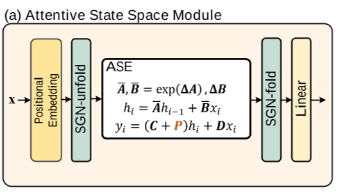
对于Attentive State Space Module:
1,首先对输入特征x应用位置编码,以保留原始结构信息。输入特征x的维度为H×W×C。
2,语义引导邻接展开(Semantic Guided Neighboring Unfold,SGN-unfold):将2D图像展开为1D序列,x'的维度为L*C(L=H*W),以便进行后续的注意力状态空间方程(ASE)建模。
(1)first determine the semantic label of each pixel (通过routing matrix R,将在下面介绍)
(2)Then restructure the image based on these labels to generate the semantic-neighboring 1D sequence, where semantically similar pixels are also spatially close to each other.
3,对于Attentive State-space Equation模块我的理解是:

这里的C就类似注意力机制中的Q(query),但是注意力机制中query全部token(因为Si包含了全部token的信息),而hi只包含了the information of scanned sequence,不包含全部token的信息。所以C就没办法像Q一样query所有token。
一种方法是多做几个拥有不同scan方向的block,让不同block中的hi包含的Information不同。从而弥补信息的损失。但这样会增加计算量,且不同block中的hi的信息冗余度很高。
本文采用的方法是让C包含the information of the unscanned sequence(其实C中也包含了the information of scanned sequence),而由于hi本身包含the information of scanned sequence,从而实现类似query全部token的机制。(thus allowing C to attentively "query" unseen pixels)
注意力机制中Qi<->Si,当前token<->全部token。ASSE中(C+P)<->hi,全部token<->scanned token
实现:
从 prompt pool ![]() (有T个prompt)(T*d)选出来L个,得到L个instance-specific prompts P(L*d),加到C(L*d)中。(L>T,每一个xi'对应一个prompt,因为有L个xi',所以有L个prompt,但这L个prompt中有相同的prompt,prompt一共只有T种)
(有T个prompt)(T*d)选出来L个,得到L个instance-specific prompts P(L*d),加到C(L*d)中。(L>T,每一个xi'对应一个prompt,因为有L个xi',所以有L个prompt,但这L个prompt中有相同的prompt,prompt一共只有T种)
“选的过程”:我的理解是,首先把x'(L*C)->x'(L*T),x'的特征是T维,每维特征都对应了一个提示,然后采用对数似然看哪一个prompt跟xi'的关系最大。从而对于每个xi'都选出一个prompt(prompt pool中共有T个prompt)(x'为L*C即有L个xi')。这样的话就产生了一个矩阵R(L*T),R包含的内容是每一个xi'对应的prompt(the routing matrix R in the ASE, which has learned the prompt category of each pixel),P=R![]() 。
。
4,最后使用另一个SGN作为前一操作的逆操作,将序列重新折叠回图像(利用到了位置编码),并通过线性投影得到块输出。(都折叠回图像了,还要线性投影得到块输出干啥?)
我的问题:
1,本文提出的方法Attentive state-space function虽然能让每个像素点跟其它所有像素点产生交互并且是单方向扫描,但是它提出的方法会不会极大增加计算量啊?
因为要计算每个xi'跟每个prompt的相关度->L*T>L*L(L*L是transform的计算复杂度)
它还说会降低由于多方向扫描带来的计算复杂度的增加,可是这篇文章VmambaIR: Visual State Space Model for Image Restoration说其计算复杂度还是线性的呢(六个扫描方向)。但是这篇的计算复杂度都大于L平方了。
不对不对,T不是大于L的这里的计算复杂度为o(LT)<o(L*L),应该还是线性的
[引入注意力机制可能会减慢推理速度
It enables parallelization, which speeds up training tremendously! However When generating the next token, we need to re-calculate the attention for the entire sequence.This need to recalculate the entire sequence is a major bottleneck of the Transformer architecture.
A Visual Guide to Mamba and State Space Models - Maarten Grootendorst]
2,确定一下长距离衰减问题的由来
看一下这个:
mamba论文的一作Albert Gu在YouTube上关于S4论文的解读
https://www.youtube.com/watch?v=luCBXCErkCs
还要了解一下Hippo
重温SSM(一):线性系统和HiPPO矩阵 - 科学空间|Scientific Spaces
HiPPO: Recurrent Memory with Optimal Polynomial Projections
好像就是由于Hippo才导致的吧?it more accurately reconstructs newer signals (recent tokens) compared to older signals (initial tokens).
hh现在是4.12,晚上接近九点,不太想看啦。明天再看这个吧
hh现在是4.13,早上九点:HiPPO尝试将当前看到的所有输入信号压缩为一个系数向量(HiPPO attempts to compress all input signals it has seen thus far into a vector of coefficients)。
通俗理解的话:毕竟使用固定维度的系数去拟合输入信号,所以肯定会面临"分辨率"的问题,如果要拟合的输入信号短一些,那么可以做到很好的拟合(”分辨率“高)。如果要拟合的输入信号较长,那么分辨率就低一些,不过可以选择是 更好的拟合最近时刻的输入信号,衰减最开始时刻的输入信号 还是 对于当前时刻和开始时刻的输入信号的拟合都同等的对待。mamba采用的是前者。也就是对最近时刻的输入信号拟合的效果更好,所以本文才会有让语义更近的pixel更近一些从而削弱长程依赖问题的影响。(没有从根本上解决长程依赖问题,因为对于更远的pixel拟合效果仍然不好,只不过让不重要的pixel离得更远一些,重要的近一些。从而削弱不利影响)
3,mamba的选择机制到底是什么?具体怎么实现的啊
老师说,如果看文字描述不太懂的话就去看代码!
代码网址:
mamba/mamba_ssm/modules/mamba2.py at v2.2.4 · state-spaces/mamba
这里的选择性机制是指B,C,detla与输入有关,使得模型能够根据不同输入token的特点进行有区别的对待。即 Mamba可根据不同的输入数据动态计算矩阵B、C和步长Δ的值(推理过程中不会对模型的参数进行重新训练或调整,而是简单地应用训练阶段学到的方式——决定如何计算这些矩阵和步长的函数或映射,来生成预测) 。
与其相关的代码如下
zxbcdt = self.in_proj(u)z0, x0, z, xBC, dt = torch.split(
zxbcdt,
[d_mlp, d_mlp, self.d_ssm, self.d_ssm + 2 * self.ngroups * self.d_state, self.nheads],
dim=-1
) if causal_conv1d_fn is None or self.activation not in ["silu", "swish"]:
assert seq_idx is None, "varlen conv1d requires the causal_conv1d package"
xBC = self.act(
self.conv1d(xBC.transpose(1, 2)).transpose(1, 2)[:, :-(self.d_conv - 1)]
) # (B, L, self.d_ssm + 2 * ngroups * d_state)
else:
xBC = causal_conv1d_fn(
xBC.transpose(1, 2),
rearrange(self.conv1d.weight, "d 1 w -> d w"),
bias=self.conv1d.bias,
activation=self.activation,
seq_idx=seq_idx,
).transpose(1, 2) x, B, C = torch.split(xBC, [self.d_ssm, self.ngroups * self.d_state, self.ngroups * self.d_state], dim=-1)可以大概这样理解:其中u是输入,zxbcdt与输入有关,把他分成五部分,其实的dt即是detla。把其中的xBC经过一个卷积之后分成三部分,其中两部分分别为B和C。
4,我知道![]() ,但是prompt pool怎么来的?或者说M,N是怎么来的啊?
,但是prompt pool怎么来的?或者说M,N是怎么来的啊?
代码:
https://github.com/csguoh/MambaIR/blob/main/basicsr/archs/mambairv2_arch.py#L464
代码我跑通了,遇到了几个问题写了一篇博客,可以参考一下:
配置MambaIRv2: Attentive State Space Restoration的环境-优快云博客
运行MambaIRv2: Attentive State Space Restoration代码时遇到的问题-优快云博客
1,基础工具类:
index_reverse & semantic_neighbor
-
功能:实现张量的索引逆操作和语义邻居重排。
-
说明:用于
ASSM模块中的SGN-unfold/fold操作,对特征图按语义相似性分组和还原。
dwconv
-
功能:深度可分离卷积(Depthwise Conv + GELU)。
-
说明:在
ConvFFN中用于局部特征提取,减少计算量。
PatchEmbed & PatchUnEmbed
-
功能:将图像分块嵌入(Patchify)和还原(Unpatchify)
2,核心模块类:
ConvFFN
-
功能:带深度卷积的前馈网络(MLP + DWConv)。
-
说明:
AttentiveLayer使用了,用在 每个分支的输出之后(Attentivelayer有两个分支),作为特征细化层。
Gate & GatedMLP
-
功能:门控机制(Split→Conv→Multiply)。
-
说明:若需进一步减少参数量,可用
GatedMLP替换ConvFFN。(当前并没有用到)
WindowAttention
-
功能:基于窗口的多头自注意力(Shifted Window-MHSA)。
Selective_Scan
-
功能:Mamba风格的选择性状态空间扫描(SSM)。
-
说明:用在了ASSM中(ASE)
ASSM (Attentive State Space Module)
说明:用到了Selective_Scan, semantic_neighbor, index_reverse等
3. 网络骨干类
AttentiveLayer
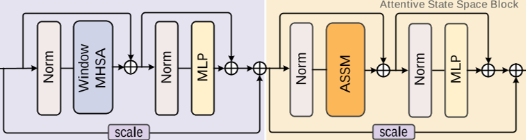
-
功能:整合Window-MHSA和ASSM的双分支结构
BasicBlock
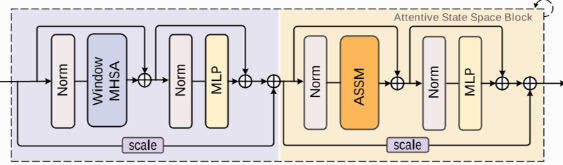
-
功能:堆叠多个
AttentiveLayer构成一个阶段(Stage)。
ASSB
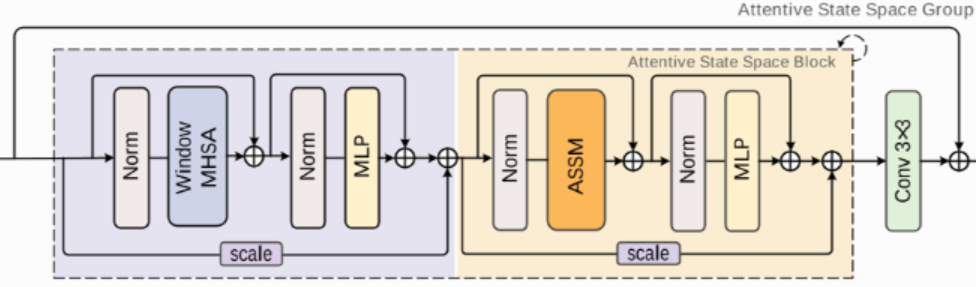
-
功能:完整的特征处理块(包含Patch嵌入/还原 +
BasicBlock)。

















 161
161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









