






1、RISC与CISC的比较,那种指令集更快?
RISC(精简指令集计算机)和CISC(复杂指令集计算机)是两种不同的计算机指令集架构,各有其优缺点。
RISC(精简指令集计算机):
- RISC指令集的设计理念是通过减少指令的数量和复杂度来提高处理器的执行效率。
- RISC指令通常在一个时钟周期内完成,这意味着指令执行速度更快。
- 由于指令简单,RISC处理器的硬件设计相对简单,可以提高时钟频率。
- RISC架构更适合流水线处理,因为每条指令执行时间较短,减少了流水线中的停顿。
- 常见的RISC处理器包括ARM、MIPS、PowerPC等。
CISC(复杂指令集计算机):
- CISC指令集的设计理念是通过增加指令的数量和复杂度来减少程序的指令数量,从而减少内存使用和程序长度。
- CISC指令可能需要多个时钟周期来完成,因为它们往往更加复杂。
- 由于指令复杂,CISC处理器的硬件设计也更复杂,通常时钟频率较低。
- CISC架构中,单条指令可以执行更多的操作,这在某些情况下可以提高编程效率。
- 常见的CISC处理器包括x86架构的Intel和AMD处理器。
比较与性能:
- 速度:RISC处理器通常更快,因为它们的指令集简单、指令执行时间短,适合高频率流水线操作。CISC处理器由于指令复杂,单条指令执行时间较长,但在某些复杂操作中可能更高效。
- 功耗:RISC处理器一般功耗较低,因为其指令集简单,硬件设计相对简单。CISC处理器由于复杂的硬件设计,通常功耗较高。
- 应用场景:RISC处理器常用于移动设备和嵌入式系统,强调低功耗和高效率。CISC处理器常用于桌面计算机和服务器,强调指令丰富性和编程便利性。
总的来说,在执行简单指令时,RISC处理器通常更快,而CISC处理器在执行复杂指令或需要复杂操作时可能具有优势。具体哪种指令集更快,取决于实际应用场景和工作负载。
2. Cache和程序访问的局部性原理及分析
Cache是一种用于缓解处理器和主存之间速度差异的小而快速的存储器。它临时存储最近使用或频繁使用的数据和指令,以提高计算机系统的整体性能。Cache的工作原理依赖于程序访问的局部性原理,包括时间局部性和空间局部性。
-
时间局部性(Temporal Locality):
- 时间局部性指的是程序中某些数据或指令在短时间内被多次访问。例如,程序中的循环结构中,循环变量在每次迭代中都会被多次使用。
- 例子:考虑一个简单的循环:
for (int i = 0; i < 1000; i++) { sum += array[i]; } - 在这个循环中,变量
i和sum会在每次迭代中频繁访问,因此具有高时间局部性。如果这些变量存储在Cache中,可以显著提高访问速度。
-
空间局部性(Spatial Locality):
- 空间局部性指的是程序访问的地址在空间上彼此接近。例如,当访问数组元素时,通常会连续访问相邻的元素。
- 例子:继续上述例子中的数组访问:
在这个循环中,for (int i = 0; i < 1000; i++) { sum += array[i]; }array[i]的访问具有高空间局部性,因为array[i]、array[i+1]等元素在内存中是连续存储的。如果将这些连续的内存块加载到Cache中,可以减少访问主存的次数,提高访问效率。
分析Cache工作原理:
- Cache将主存的数据块(称为Cache行)复制到Cache中。每个Cache行通常包含多个连续的字节(例如64字节)。
- 当处理器需要访问数据时,首先检查Cache。如果数据在Cache中(称为Cache命中),则直接从Cache中读取。如果数据不在Cache中(称为Cache未命中),则从主存中读取,并将其加载到Cache中以备后用。
- Cache的性能取决于命中率,即访问数据时Cache命中的频率。高命中率表示大多数数据访问都可以在Cache中找到,从而减少访问主存的时间。
举例说明: 假设有一个程序频繁访问一个较小的数组和一个较大的数组:
int small_array[10];
int large_array[10000];
for (int i = 0; i < 10000; i++)
{ small_array[i % 10] += 1;
large_array[i] += 1; }
在这个程序中,small_array的访问具有高时间局部性,因为每个元素会频繁被访问多次。而large_array的访问具有高空间局部性,因为每次访问的元素是连续的。由于small_array较小,很容易被整个加载到Cache中,因此访问会非常快速。large_array较大,可能不能完全被加载到Cache中,但由于访问模式是连续的,Cache仍然能提高访问速度。
总的来说,Cache利用程序的局部性原理,通过减少对主存的频繁访问,提高了系统的整体性能。
3. Cache的映射方式,命中率,平均访问时间
Cache映射方式指的是如何将主存中的数据块映射到Cache中的特定位置。常见的Cache映射方式有三种:直接映射、全相联映射和组相联映射。
-
直接映射(Direct Mapping):
- 在直接映射中,主存中的每个块只能映射到Cache中的一个特定位置。这个位置通过取模运算确定。
- 优点:实现简单,硬件成本低。
- 缺点:可能会导致冲突问题,如果多个内存块映射到同一个Cache位置,会频繁发生替换。
- 例子:假设Cache大小为64个块,主存地址通过取64的模(mod 64)来确定Cache位置。
-
全相联映射(Fully Associative Mapping):
- 在全相联映射中,主存中的任何块可以映射到Cache中的任何位置。
- 优点:避免了直接映射中的冲突问题,提高命中率。
- 缺点:硬件实现复杂,成本高,需要更多的比较器来查找每个块。
- 例子:如果Cache有64个块,任意主存块可以放置在这64个块中的任何一个位置。
-
组相联映射(Set Associative Mapping):
- 组相联映射是直接映射和全相联映射的折中方案。Cache被分为若干个组,每个组包含若干个块。主存块首先映射到一个特定的组,然后可以放置在该组内的任何块中。
- 优点:减少冲突,提高命中率,同时硬件实现复杂度介于直接映射和全相联映射之间。
- 缺点:组数越少,冲突越多;组数越多,硬件实现越复杂。
- 例子:假设Cache有64个块,分为4个组,每组16个块。主存块先通过取4的模(mod 4)确定组,然后可以放置在该组内的任何一个块。
命中率(Hit Rate): 命中率是指Cache访问中找到所需数据的次数占总访问次数的比例。高命中率意味着大多数数据访问可以在Cache中找到,从而提高系统性能。
命中率公式: Hit Rate=Cache HitsTotal Cache Accesses\text{Hit Rate} = \frac{\text{Cache Hits}}{\text{Total Cache Accesses}}Hit Rate=Total Cache AccessesCache Hits
平均访问时间(Average Access Time): 平均访问时间考虑了Cache命中和未命中两种情况。假设Cache命中的时间为tct_ctc,未命中时需要访问主存,主存访问时间为tmt_mtm,命中率为hhh,则平均访问时间TTT计算公式如下:
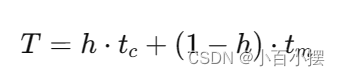
解释:
- tct_ctc 是Cache命中时的数据访问时间,通常很短。
- tmt_mtm 是Cache未命中时,从主存中读取数据的时间,通常较长。
- hhh 是Cache命中率。
举例说明: 假设某系统中,Cache命中时间为2纳秒,主存访问时间为50纳秒,Cache命中率为90%(即0.9),则平均访问时间为:
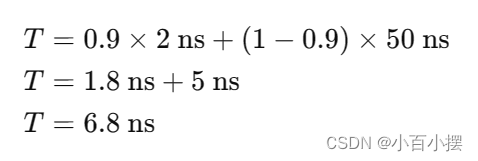
因此,平均访问时间为6.8纳秒。
通过提高Cache的命中率,可以显著减少平均访问时间,从而提升系统的整体性能。
4、中断屏蔽字 CPU程序运行轨迹
中断屏蔽字
中断屏蔽字(Interrupt Mask)是用于控制处理器响应中断信号的一个位掩码。通过设置中断屏蔽字,可以启用或禁用特定的中断请求,从而控制中断的优先级和处理顺序。
中断屏蔽字的作用:
- 控制中断的启用和禁用:中断屏蔽字的每一位对应一个特定的中断源。设置为1表示屏蔽(禁用)该中断,设置为0表示允许(启用)该中断。
- 优先级管理:通过设置中断屏蔽字,可以优先处理高优先级中断,延迟处理低优先级中断,确保系统的关键任务得到及时响应。
- 防止嵌套中断:在处理一个中断时,可以临时屏蔽其他中断,防止中断嵌套导致的复杂性和资源竞争问题。
举例说明: 假设有一个8位的中断屏蔽字寄存器,其中每一位分别对应一个中断源。
- 初始状态:中断屏蔽字为
00001111,表示第0到第3号中断源被屏蔽,第4到第7号中断源被启用。 - 如果需要启用第2号中断,将中断屏蔽字改为
00000111,将第2位从1改为0。
CPU程序运行轨迹
CPU程序运行轨迹(CPU Program Execution Trace)是指CPU在执行程序时的指令流,即CPU在一段时间内执行的指令序列。这些指令包括各种操作,如数据处理、控制流操作、内存访问等。
程序运行轨迹的分析:
- 指令执行顺序:了解程序的指令执行顺序,可以帮助分析程序的逻辑流和控制流,找出潜在的性能瓶颈或逻辑错误。
- 内存访问模式:分析内存访问模式,可以优化Cache使用,提高程序运行效率。例如,了解程序是否具有良好的时间局部性和空间局部性。
- 性能分析和优化:通过跟踪CPU的程序执行轨迹,可以识别和消除性能瓶颈,进行代码优化和调整。
- 调试和测试:在软件调试过程中,运行轨迹可以帮助发现和解决bug,确保程序按预期运行。
举例说明: 假设一个简单的程序如下:
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += i;
}
1. MOV sum, 0 ; sum = 0
2. MOV i, 0 ; i = 0
3. CMP i, 10 ; 比较i和10
4. JGE end_loop ; 如果i >= 10,跳转到end_loop
5. ADD sum, i ; sum += i
6. ADD i, 1 ; i++
7. JMP loop_start ; 跳转到loop_start
8. end_loop: ; 循环结束
在这个简单的例子中,CPU执行了从初始化变量到循环操作的指令序列。分析这样的执行轨迹,可以帮助理解程序的执行逻辑,并进行优化和调试。
4、扩展操作码



5、机器字长 指令字长 存储字长
机器字长、指令字长和存储字长是计算机体系结构中的三个重要概念,它们分别指的是不同的系统特性。下面对它们进行详细区分和解释:
机器字长(Machine Word Length)
- 定义:机器字长是指计算机处理器在一次操作中能够处理的二进制数据的位数。它通常由处理器的内部寄存器、数据总线和ALU(算术逻辑单元)的位宽决定。
- 作用:机器字长影响计算机的计算能力和数据处理速度。较长的机器字长意味着处理器可以在一次操作中处理更多的数据,从而提高性能。
- 常见值:现代计算机的机器字长通常为32位或64位。例如,32位处理器的机器字长为32位,64位处理器的机器字长为64位。
指令字长(Instruction Word Length)
- 定义:指令字长是指一条机器指令所占用的位数。指令字长决定了指令的编码方式和复杂性。
- 作用:指令字长影响指令集架构的设计和执行效率。较长的指令字可以包含更多的信息和操作码,但也会增加指令存储和传输的开销。
- 常见值:指令字长可以是固定长度或可变长度。固定长度指令集(如RISC架构)通常采用统一的指令字长(例如32位),而可变长度指令集(如x86架构)则可以有不同的指令字长(例如8位到120位不等)。
存储字长(Storage Word Length)
- 定义:存储字长是指计算机存储系统(例如主存、Cache)中数据单元的位数。存储字长决定了每个存储单元可以存储的数据量。
- 作用:存储字长影响内存地址空间和数据存取效率。较长的存储字长可以提高数据传输速度,但也可能增加存储器的复杂性和成本。
- 常见值:存储字长通常与机器字长一致,但也可以不同。例如,一个64位处理器的存储字长通常为64位,但某些系统中可能使用32位或更小的存储字长以节省内存。
区分与联系
- 机器字长:决定处理器一次操作能够处理的数据量,影响计算性能。
- 指令字长:决定每条指令的长度,影响指令集设计和执行效率。指令字长可以与机器字长一致或不同。
- 存储字长:决定存储单元的数据容量,影响内存的存取速度和效率。存储字长通常与机器字长一致,但可以根据需求有所不同。
举例说明
假设有一台计算机系统,其处理器的机器字长为32位,指令字长为16位,存储字长为32位:
- 机器字长为32位意味着处理器在一次操作中可以处理32位的数据,例如进行32位整数的加法运算。
- 指令字长为16位意味着每条机器指令占用16位,例如指令“LOAD R1, 1000”可以用16位编码。
- 存储字长为32位意味着每个存储单元可以存储32位的数据,例如内存地址0x1000处存储了一个32位整数。
通过区分这三个概念,可以更好地理解计算机系统的设计和工作原理,从而优化程序的性能和效率。
6、区分各种周期:指令周期 机器周期 CPU周期 时钟周期
在计算机体系结构中,指令周期、机器周期、CPU周期和时钟周期是四个关键的时间概念,它们描述了计算机执行指令时的不同时间间隔。理解这些周期对于优化计算机系统性能和设计高效的程序至关重要。
1. 指令周期(Instruction Cycle)
定义:指令周期是指处理器从内存中取出并执行一条指令所需的完整时间,包括取指、译码、执行和写回等阶段。
组成部分:
- 取指阶段(Fetch Cycle):从内存中取出指令。
- 译码阶段(Decode Cycle):解析指令并生成相应的控制信号。
- 执行阶段(Execute Cycle):执行指令操作,如算术运算、逻辑运算或数据传输。
- 写回阶段(Writeback Cycle):将结果写回寄存器或内存(可选)。
例子:假设指令周期包含4个机器周期:取指、译码、执行和写回,那么执行一条指令的完整时间就是这4个机器周期的总和。
2. 机器周期(Machine Cycle)
定义:机器周期是指处理器执行一个基本操作(如内存访问、寄存器访问或ALU操作)所需的时间。一个指令周期通常包含多个机器周期。
组成部分:
- 内存读取周期:从内存读取数据或指令。
- 内存写入周期:将数据写入内存。
- I/O操作周期:与输入/输出设备进行数据交换。
- 执行周期:在ALU中进行算术或逻辑运算。
例子:如果处理器需要从内存中读取一个数据,这个操作可能需要一个内存读取周期,而这个周期本身可能包含若干个CPU周期。
3. CPU周期(CPU Cycle)
定义:CPU周期是指处理器完成一次基本操作(如从寄存器读取数据或执行一次ALU操作)所需的时间,也称为处理器周期或处理器时钟周期。
关系:一个机器周期通常包含多个CPU周期。例如,取指操作可能需要几个CPU周期来完成。
例子:假设CPU时钟频率为2 GHz,那么一个CPU周期的时间为0.5纳秒。在这个周期内,处理器可以完成一次基本操作。
4. 时钟周期(Clock Cycle)
定义:时钟周期是指系统时钟的一个完整振荡周期,它是处理器所有操作的基本时间单位。处理器时钟的频率(时钟速率)决定了时钟周期的长度。
关系:时钟周期与CPU周期通常是同义的,因为处理器的操作是同步于系统时钟的。
例子:如果处理器的时钟频率为3 GHz,那么时钟周期为1/3 GHz,即约0.333纳秒。在这个时钟周期内,处理器可以进行基本操作的最小单位。
关系与区别
- 时钟周期是最基本的时间单位,决定了处理器操作的基本速率。
- CPU周期通常等同于时钟周期,表示处理器完成一次基本操作所需的时间。
- 机器周期包含多个CPU周期,表示处理器完成一个基本任务(如内存读取)的时间。
- 指令周期包含多个机器周期,表示处理器完成一条指令所需的完整时间。
通过理解和区分这些周期,可以更好地分析处理器的性能和优化程序。例如,通过减少指令周期或机器周期的数量,可以提高程序的执行速度。
7、寻址方式
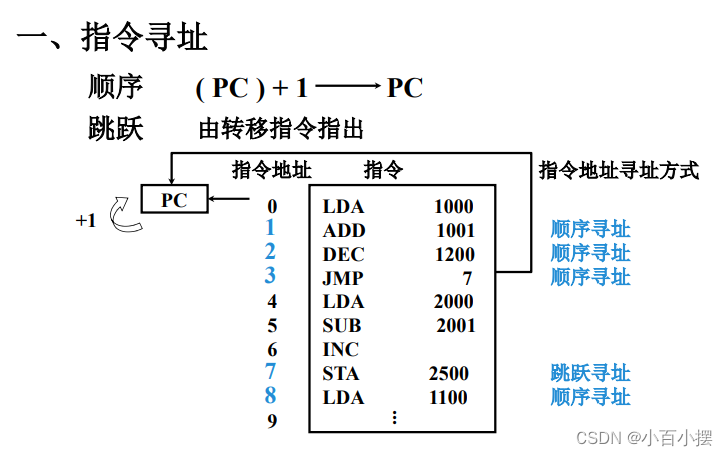
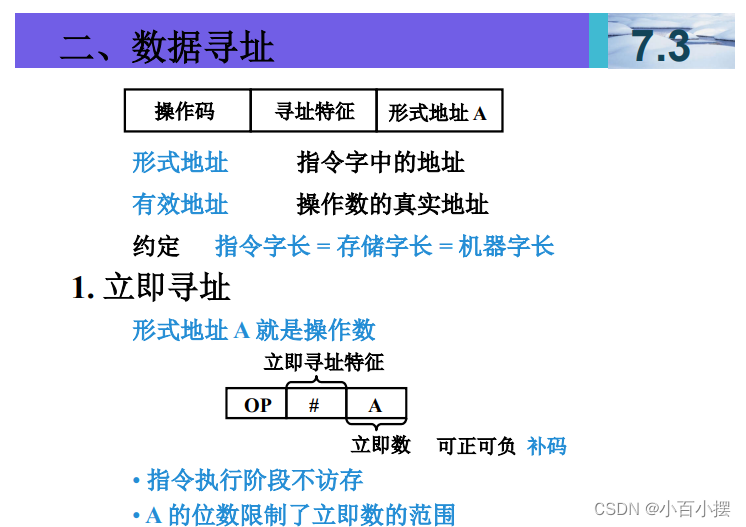
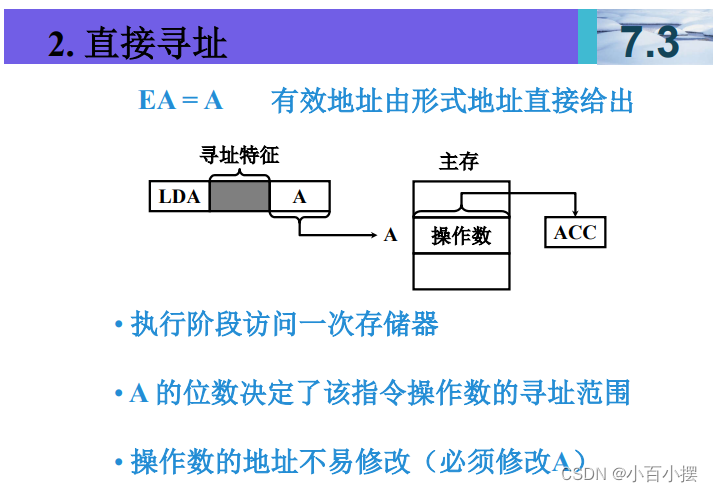
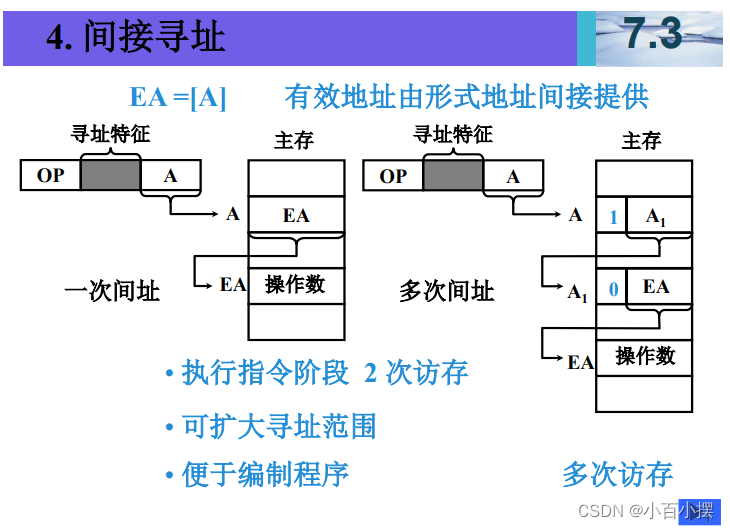
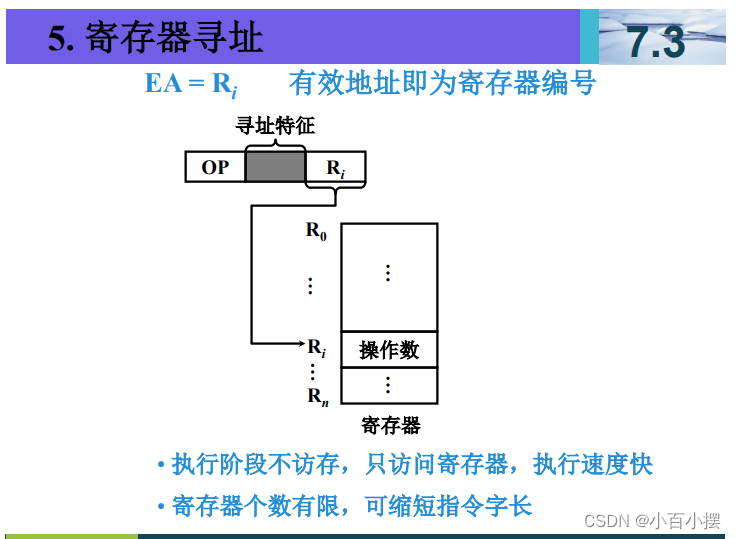
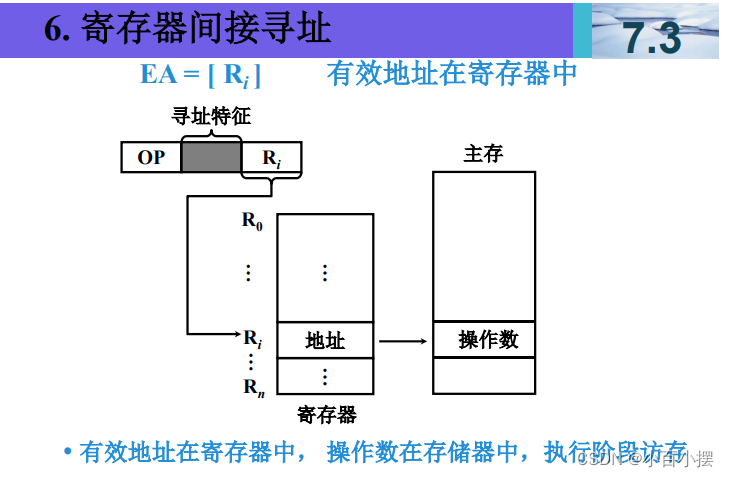
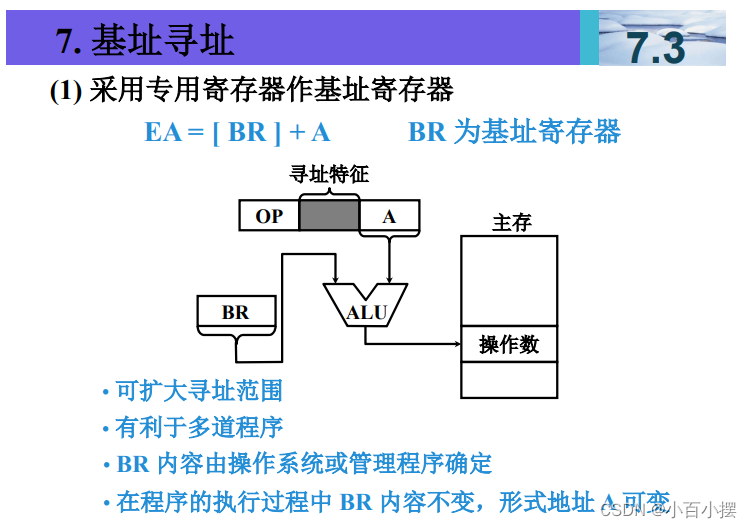
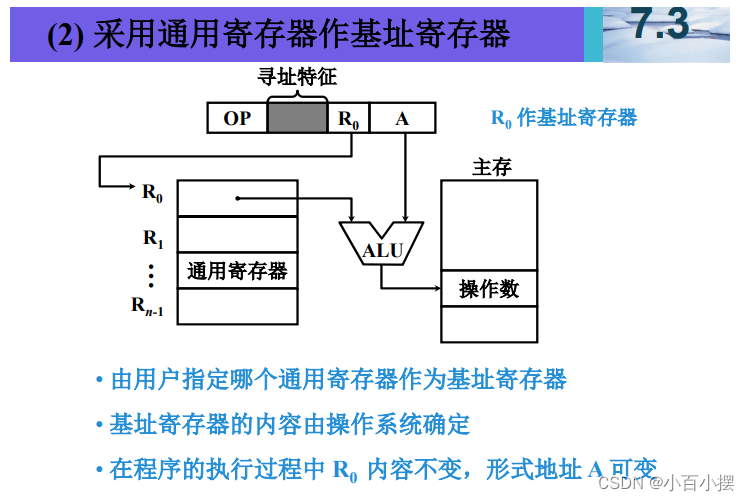
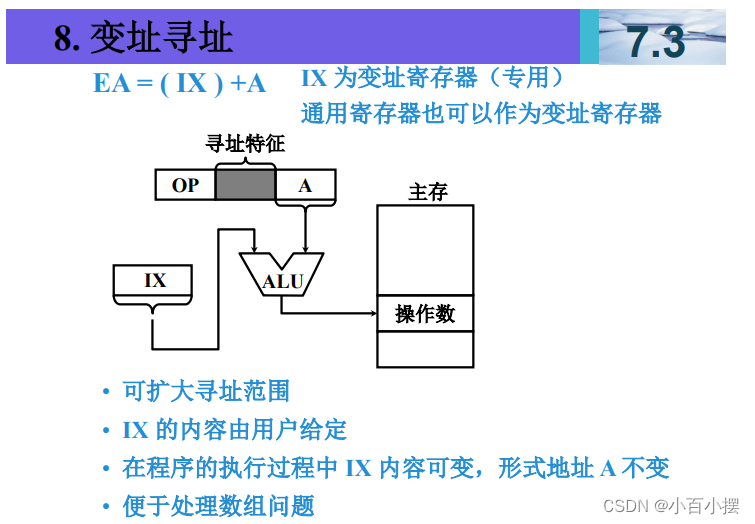
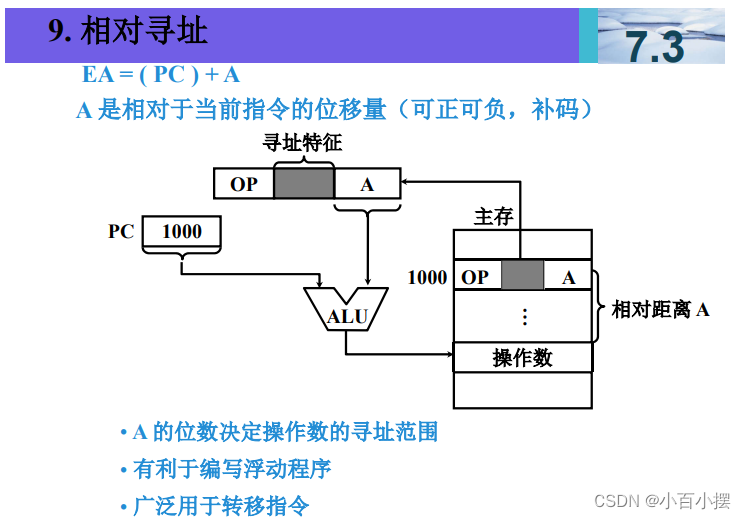

假设(R)=1000,(1000)=2000,(2000)=3000, (3000)=5000,(PC)=4000,则以下寻址方式下访 问到的指令操作数的值是多少 (1) 直接寻址 2000 (2) 间接寻址 1000 (3) 寄存器间接寻址 R (4) 相对寻址 -1000
前提条件
- R=1000R = 1000R=1000
- 内存地址 100010001000 的值是 200020002000
- 内存地址 200020002000 的值是 300030003000
- 内存地址 300030003000 的值是 500050005000
- 程序计数器 PC=4000PC = 4000PC=4000
寻址方式和计算
1. 直接寻址 2000
直接寻址是指直接使用给定的内存地址访问数据。
操作数值 = 内存地址 2000 的值
- 已知内存地址 2000 的值是 3000。
- 因此,直接寻址 2000访问到的操作数值是 3000。
2. 间接寻址 1000
间接寻址是指首先访问给定的内存地址,从该地址读取另一个地址,再从该新地址读取数据。
操作数值 = 内存地址 1000 的值指向的地址的值
- 已知内存地址 1000 的值是 2000。
- 然后访问内存地址 2000,读取其值,即 3000。
- 因此,间接寻址 1000访问到的操作数值是 3000。
3. 寄存器间接寻址 R
寄存器间接寻址是指使用寄存器的值作为地址,从该地址读取数据。
操作数值 = 寄存器 R 的值指向的地址的值
- 已知 R=1000R = 1000R=1000。
- 然后访问内存地址 1000,读取其值,即 2000。
- 因此,寄存器间接寻址 R访问到的操作数值是 2000。
4. 相对寻址 -1000
相对寻址是指使用当前程序计数器(PC)的值加上一个偏移量来确定操作数的地址。
操作数值 = PC+偏移量PC + \text{偏移量}PC+偏移量 指向的地址的值
- 已知 PC=4000PC = 4000PC=4000。
- 偏移量是 -1000,因此新的地址是 4000−1000=30004000 - 1000 = 30004000−1000=3000。
- 然后访问内存地址 3000,读取其值,即 5000。
- 因此,相对寻址 -1000访问到的操作数值是 5000。

这里进入子程序后,PC要更新为子程序入口地址,接着执行子程序代码!
8、CPU中数据通路及控制信号的分析与设计
在CPU中,数据通路和控制信号是实现指令执行的两个关键部分。数据通路负责数据的传输和处理,而控制信号则控制数据通路的操作,以确保指令按照正确的顺序执行。下面是关于数据通路和控制信号的分析与设计的一般步骤:
数据通路(Data Path)
-
确定数据通路所需的功能模块:
- 寄存器:用于存储数据和指令。
- ALU(算术逻辑单元):用于执行算术和逻辑操作。
- 数据存储器:用于存储数据。
- 数据选择器:用于选择需要传输的数据。
- 数据传输路径:连接各功能模块的数据传输线路。
-
设计数据通路的结构:
- 确定数据通路中各功能模块的连接方式和数据传输路径。
- 确定数据通路的宽度,即数据的位数。
-
实现数据通路的控制:
- 设计控制信号,用于控制数据通路的操作。
- 将控制信号与数据通路的各功能模块相连,以实现指令的执行。
控制信号(Control Signals)
-
确定所需的控制信号:
- 时钟信号:用于同步各部件的操作。
- 读写信号:用于指示数据的读取或写入操作。
- ALU操作码:用于指示ALU执行的操作类型。
- 数据选择信号:用于选择需要传输的数据。
- 状态信号:用于表示CPU的状态,如运行、停止等。
-
设计控制信号的产生逻辑:
- 根据指令集的要求,确定控制信号的产生逻辑。
- 使用逻辑门电路或者程序控制的方式产生控制信号。
-
实现控制信号的传输:
- 将控制信号与数据通路的各功能模块相连。
- 确保控制信号能够正确地控制数据通路的操作。
设计流程
- 确定CPU的指令集和功能要求。
- 设计数据通路的结构,包括功能模块和数据传输路径。
- 设计控制信号的产生逻辑,确保能够满足指令执行的要求。
- 将数据通路和控制信号结合起来,实现完整的CPU设计。
- 进行仿真和验证,确保CPU能够正确地执行指令。
以上是数据通路和控制信号分析与设计的一般步骤,具体的实现方式会根据CPU的具体要求和设计目标而有所不同。
9、指令周期 取值 间址 执行周期 数据通路
在计算机体系结构中,指令周期是指处理器执行一条指令所需的时间,包括取指、译码、执行和写回等阶段。指令周期的具体取值取决于处理器的设计和实现,通常在纳秒级别。间址是一种寻址方式,用于指示指令中的操作数地址存放在另一个地址中。执行周期是指处理器执行指令操作的时间段,包括算术逻辑操作、数据传输等。数据通路是指连接处理器内部各功能模块的路径,用于传输数据和控制信号。
10、微程序 微指令 机器指令 下一条微指令地址怎么找
在计算机系统中,微程序是一种将机器指令分解为一系列微指令的技术,用于控制处理器内部的操作。微指令是微程序中的最小控制单位,每条微指令控制处理器的一个具体操作,例如读取数据、执行算术运算等。机器指令则是用户编写的高级指令,通过微程序转换为微指令来实际执行。
当处理器执行微程序时,会根据当前微指令的执行情况来确定下一条微指令的地址。这个过程通常由微程序计数器(Micro-PC)来控制。微程序计数器存储当前微指令的地址,每当一条微指令执行完毕后,根据微指令中的控制信号和条件,微程序控制器会计算出下一条微指令的地址,并将该地址加载到微程序计数器中,以便执行下一条微指令。
微程序的设计使得处理器的控制逻辑可以更灵活地实现,因为微指令的执行顺序和控制条件可以根据需要灵活调整,而无需改变硬件电路。这种灵活性对于实现复杂的指令集和流水线处理器非常有用。
举个例子
假设有一条机器指令需要执行加法操作,对应的微程序可能包含以下几条微指令:
- 从指定的地址读取第一个操作数到寄存器A。
- 从指定的地址读取第二个操作数到寄存器B。
- 将寄存器A和寄存器B中的数据送入算术逻辑单元(ALU)执行加法操作。
- 将ALU的结果写回到指定的地址。
在这个例子中,微程序的设计将机器指令的执行过程分解为了四个微指令,每个微指令控制着处理器的一个具体操作。当处理器执行第一条微指令时,微程序控制器会计算出下一条微指令的地址,并将其加载到微程序计数器中,以便执行下一条微指令。这样,通过一系列微指令的执行,处理器最终完成了机器指令对应的加法操作。
个人总结:
数量关系这块,一条指令对应一个微程序,一个微程序对应多个微指令,一个微指令对应多个微命令,微命令与微操作一一对应,存放微指令的控制存储器单元地址是微地址。微命令有相容和互斥。
控制存储器用ROM实现,与CPU结构相似,将PC和MAR结合为CMAR,IR和MDR结合为CMDR,CMAR和μPC,CMDR和μIR是同一个寄存器。
微程序控制器的工作流程,公共取指阶段,通过微地址形成部件找微程序入口,执行微指令。
微指令的编码方式:直接编码,n个微命令操作字段就有n位,字段直接编码,将互斥的形成字段,通过指令译码发出微命令,需要一个全0来表示空操作,可能会考操作码需要多少位,这时要加一。
如何找下一条地址,由微指令的下地址字段指出(断定方式)
微指令格式:水平型微指令和垂直型微指令的关系,水平型定义多个并行微命令,微程序短,速度快,但是微指令长,编写微程序较麻烦。垂直型微指令微指令短,简单规整,但是微程序长,速度慢效率低。
微程序控制器和硬布线控制器的区别,微程序控制器CISC CPU,硬布线RISC,而且硬布线扩充修改困难,微程序控制器易修改扩充。
在微程序控制器中,形成微程序入口地址的是机器指令的操作码字段
11、解释程序查询 程序中断 DMA方式 向量中断 中断隐指令
这些概念都与计算机系统中的中断处理相关:
-
程序查询(Programmed I/O):是一种数据传输方式,通常用于与外部设备进行数据交换。在程序查询方式下,CPU通过轮询的方式检查外部设备是否准备好进行数据传输,如果准备好了就开始数据传输,否则继续等待。这种方式的缺点是效率低下,因为需要大量的CPU时间来检查外部设备的状态。
-
程序中断(Program Interrupt):是一种CPU中断处理机制,用于处理外部事件或异常。当发生中断时,CPU会暂停当前执行的程序,并跳转到相应的中断处理程序,处理完中断后再返回原来的程序继续执行。
-
DMA方式(Direct Memory Access):是一种数据传输方式,用于高速数据传输,减少CPU的干预。在DMA方式下,外部设备可以直接访问内存中的数据,而不需要通过CPU。CPU只需设置好DMA控制器的参数,然后可以继续执行其他任务,大大提高了数据传输的效率。
-
向量中断(Vectored Interrupt):是一种中断处理方式,用于区分不同的中断源。在向量中断中,每个中断源被分配一个唯一的中断向量,当发生中断时,CPU会根据中断向量跳转到相应的中断处理程序,以处理该中断。
-
中断隐指令(Interrupt Hiding Instructions):是一种指令执行方式,用于在处理中断时保护关键数据。当发生中断时,CPU会执行中断隐指令,将关键数据保存到堆栈或其他地方,以防止数据丢失或损坏。处理完中断后再恢复这些数据,继续执行原来的程序。
这里我有个错过的地方,就是中断向量地址指向中断向量,中断向量再指向中断服务程序入口!
12、流水线中多发技术 超标量 超流水线 超长指令字
这些概念都涉及到提高处理器性能的技术:
-
流水线中多发技术(Pipeline Parallelism):是指在流水线中同时处理多个指令的技术。流水线中的不同阶段可以同时处理不同的指令,从而提高了指令的执行效率。例如,在一个五段流水线中,可以同时执行五条指令的不同阶段。
-
超标量(Superscalar):是指一种处理器架构,具有多个执行单元和多个指令发射单元,可以同时执行多条指令。超标量处理器可以在一个时钟周期内执行多条指令,从而提高了指令级并行度。
-
超流水线(Superpipelining):是指在流水线中增加更多的阶段,以进一步细化指令的执行过程,从而提高时钟频率和性能。超流水线增加了流水线的深度,使得处理器可以在更短的时间内执行指令。
-
超长指令字(Very Long Instruction Word,VLIW):是一种指令集架构,通过一条指令同时指定多个操作,利用编译器静态调度指令,以提高指令级并行度。在VLIW架构中,一条指令被编码为一个很长的字,包含多个操作和操作数,由硬件负责并行执行这些操作。
这些技术都是为了提高处理器的性能和效率,通过增加并行度和细化指令执行过程来实现。不同的技术有不同的特点和适用场景,可以根据需求选择合适的技术来优化处理器设计。
13、流水线中结构 数据 控制冒险
在流水线处理器中,结构冒险、数据冒险和控制冒险是指在指令执行过程中可能发生的三种冒险情况,它们会影响流水线的性能和效率。
-
结构冒险(Structural Hazard):结构冒险发生在流水线中,由于硬件资源有限而导致的问题。例如,在一个五段流水线中,如果某一时刻同时需要访问存储器和执行算术逻辑运算,但流水线中只有一个存储器访问单元和一个算术逻辑单元,就会发生结构冒险。结构冒险可以通过增加硬件资源或者重新设计流水线来解决。
-
数据冒险(Data Hazard):数据冒险发生在指令之间存在数据依赖关系的情况下。例如,一条指令需要使用另一条指令的结果作为操作数,但该结果尚未计算完成,就会导致数据冒险。数据冒险可以通过插入空操作(nop)或者使用数据前推(data forwarding)来解决。
-
控制冒险(Control Hazard):控制冒险发生在分支指令(如条件跳转或无条件跳转)的目标地址未知时,流水线上的后续指令已经开始执行。如果分支指令的条件判断需要花费较长时间,那么在分支指令的结果确定前,后续指令的执行就会出现问题。控制冒险可以通过预测分支方向和延迟槽等技术来解决。
这些冒险情况都会影响流水线的性能和效率,处理器设计者需要采取相应的措施来减少冒险的发生,从而提高流水线的效率。
13、静态RAM 动态RAM
静态RAM(SRAM)和动态RAM(DRAM)都是计算机内存中常见的存储器类型,它们有一些重要的区别:
-
静态RAM(Static RAM):
- SRAM是一种内存存储技术,用于存储数据以供CPU使用。
- SRAM的存储单元由触发器(flip-flop)构成,每个存储单元需要多个晶体管来实现,因此SRAM的存取速度比较快,且不需要刷新操作。
- 由于每个存储单元需要较多的晶体管,SRAM的集成度较低,成本相对较高,通常用于高速缓存等对速度要求较高的场合。
-
动态RAM(Dynamic RAM):
- DRAM也是一种内存存储技术,用于存储数据以供CPU使用。
- DRAM的存储单元由一个存储电容和一个访问晶体管构成,存储电容的电荷表示数据的值,需要定期刷新以保持数据的有效性。
- 由于存储单元较简单,DRAM的集成度较高,成本相对较低,但存取速度较慢。
总的来说,SRAM适用于需要高速存取的场合,如CPU的高速缓存;而DRAM适用于需要大容量内存且速度要求不那么严格的场合,如系统内存。这里可能考三种刷新方式的问题。
14、超算
超算(Supercomputing)是指利用大规模并行处理器系统或者多个处理器协同工作来解决复杂科学、工程和计算问题的计算机系统。超级计算机通常具有以下特点:
-
高性能处理器:超级计算机通常采用高性能的处理器,如多核处理器、GPU(图形处理器)等,以实现高性能的计算能力。
-
大规模并行处理:超级计算机通常采用大规模并行处理技术,将计算任务分配给多个处理器并行执行,以加快计算速度。
-
大规模存储系统:超级计算机通常配备大规模的存储系统,用于存储大量的数据和计算结果。
-
高速互联网络:超级计算机通常采用高速互联网络,用于连接各个处理器和存储节点,以实现高效的通信和数据传输。
-
专门设计的操作系统和软件:超级计算机通常配备专门设计的操作系统和软件,以实现对大规模并行计算的支持和优化。
超级计算机在科学研究、工程设计、天气预报、物理模拟等领域发挥着重要作用,能够加速科学研究和工程创新的进程。
15、补码
补码是一种表示有符号整数的方法,常用于计算机中。在补码表示法中,最高位表示符号位,0表示正数,1表示负数,其余位表示数值部分。具体表示方法如下:
-
正数的补码:正数的补码与其原码相同,最高位为0。
-
负数的补码:负数的补码是其原码取反(即0变1,1变0)后加1得到的结果。例如,-1的原码为10000001,取反得到11111110,加1得到11111111,即-1的补码为11111111。
补码的一个重要性质是,补码加法可以统一处理正数和负数的加法,而不需要特殊处理符号位。例如,计算3 + (-2)时,可以将3的补码00000011和-2的补码11111110相加,得到补码00000001,即1,表示结果为1。

最后考试问答题考了DMA方式中断和程序方式中断有什么区别,RISC为什么比CISC快。 。

















 4112
4112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









