









第 2 页
- Objectives(目标/学习目的):
- 回顾哈希(hashing)的关键原则和概念。
- 建立对冲突(collisions)中随机性的模型。
- 计算期望性能(expected performance)。
- 如果有时间,可以看经典算法教材 CLRS(《算法导论》)的第 11 章。
为什么看不懂?
- “冲突”“随机性”“期望性能”都是哈希表里常见概念,但如果之前不了解哈希表,就比较抽象。后面会具体解释。

第 3 页
- Goal(目标):给定 n 个不同的键(keys),设计一个数据结构满足:
add(k), delete(k)的时间复杂度是 \(O(1)\)。search(k)的平均时间复杂度是 \(O(1)\)。
- 下面举了例子:在 Python 中有字典
dict(键-值对)和集合set(只有键,没有值),它们的插入、删除、查找一般都很快(平均情况下可以近似认为是常数时间)。
为什么看不懂?
- 这里在讲“哈希表”的典型应用:它能让插入、删除和查找在平均情况下都非常快。
哈希表的核心原理
哈希表(Hash Table)是一种基于哈希函数和数组实现的数据结构,其核心目标是通过直接访问内存位置(而非遍历)来实现快速操作。
其设计思想与图片中提到的基数排序类似,都依赖“键的分布”和“分治策略”,但哈希表更侧重于快速定位键的位置。
哈希表如何满足题目要求?
题目要求:
add(k)和delete(k)的时间复杂度为 O(1)。search(k)的平均时间复杂度为 O(1)。
1. 哈希函数(Hash Function)
- 作用:将任意键(整数、字符串、对象等)映射到一个固定范围的整数,作为数组索引。
- 例如:
hash("apple") = 3→ 键"apple"存储在数组下标3的位置。
- 例如:
- 理想特性:
- 均匀性:不同键的哈希值应均匀分布在数组中,减少冲突。
- 确定性:同一键的哈希值始终相同。
2. 数组存储(Buckets)
- 哈希表的底层是一个数组,每个位置称为“桶”(Bucket)。
- 插入(add):
- 计算键的哈希值 → 得到数组索引。
- 直接在该位置插入键(或键值对)。
- 时间复杂度:假设哈希计算为 O(1),插入到数组指定位置也为 O(1)。
3. 冲突处理(Collision Resolution)
当不同键映射到同一索引时(称为“冲突”),需要额外处理。常见方法:
- 链地址法(Chaining):每个桶用链表存储冲突的键。
- 查找时遍历链表,但若哈希函数设计良好且负载因子(Load Factor)低,链表的平均长度为 O(1)。
- 开放寻址法(Open Addressing):冲突时探测下一个可用位置(如线性探测)。
- 平均探测次数在负载因子较低时也为 O(1)。

为什么哈希表的操作是 O(1) 平均复杂度?
-
哈希函数的均匀性:
- 理想情况下,每个键映射到不同的桶,直接访问无需遍历。
- 即使有冲突,只要冲突较少(通过扩容控制负载因子),链表的平均长度仍为常数。
-
均摊分析(Amortized Analysis):
- 动态扩容的代价虽然单次可能为 O(n),但均摊到每次插入操作后,总时间为 O(1)。
-
对比基数排序:
- 基数排序的复杂度依赖位数 d 和基数 k(如 O(d⋅(n+k))),而哈希表的复杂度仅依赖哈希函数的分布和冲突概率。
Python 中的 dict 和 set 为何高效?
- 底层实现:基于哈希表。
dict存储键值对,set仅存储键,但两者都通过哈希函数快速定位键的位置。
- 操作示例:
# 插入(add) my_dict["key"] = value # O(1) my_set.add("key") # O(1) # 删除(delete) del my_dict["key"] # O(1) my_set.remove("key") # O(1) # 查找(search) if "key" in my_dict: # O(1) if "key" in my_set: # O(1)
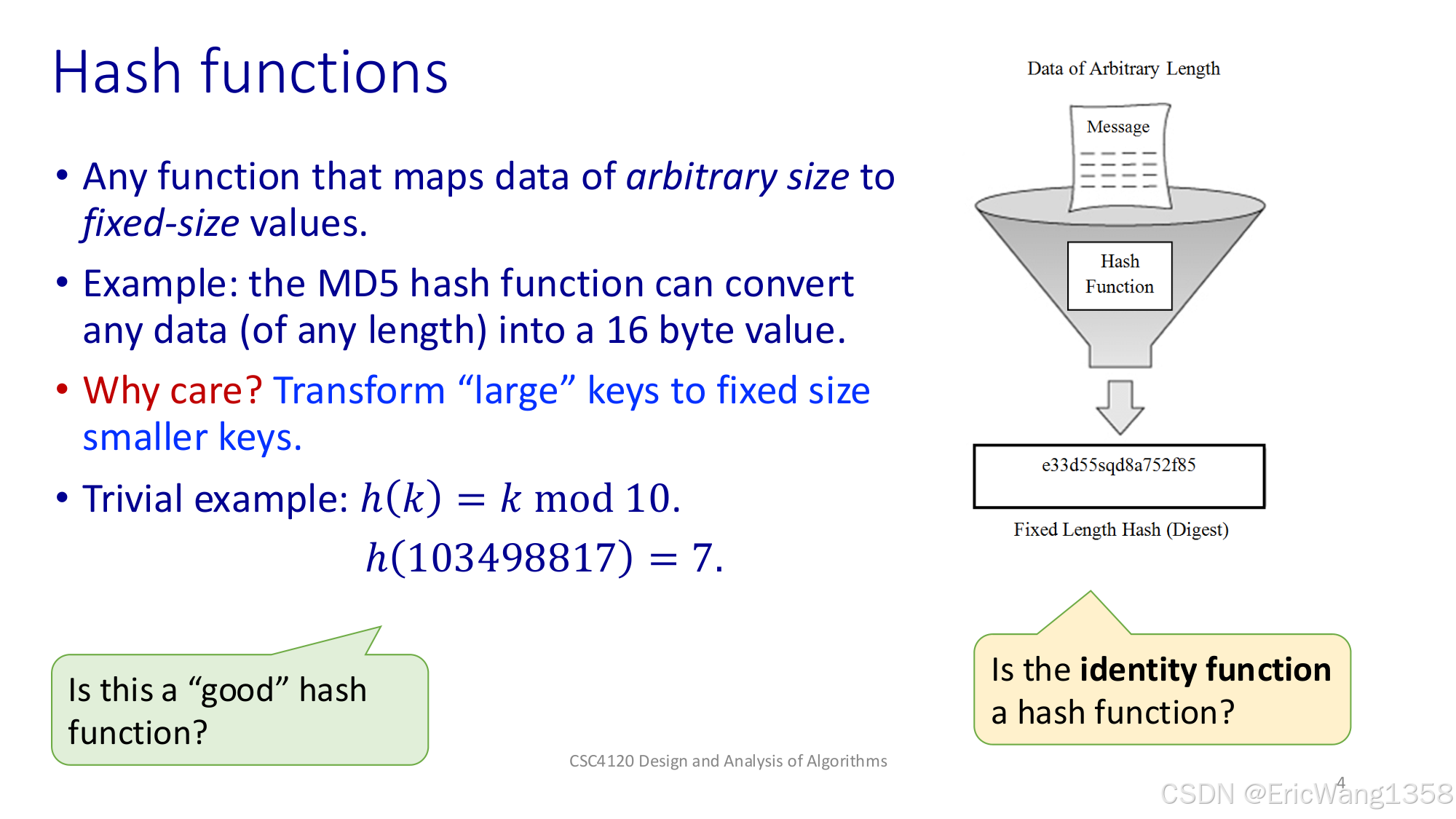 Hash functions(哈希函数):
Hash functions(哈希函数):
- 是一种把“任意大小的数据”映射为“固定大小数值”的函数。
- 例子:MD5 可以把任意长度的数据变成 16 字节的“哈希值”。
- 为什么要关心?因为可以把“很大的数据”转化成“相对较小的数字”,方便存在数组或者表里。
- 一个简单的例子:\(h(k) = k \bmod 10\),相当于对 10 取模。
- “Is the identity function a hash function?”(用恒等函数\(h(k)=k\) 算不算哈希函数?)——从原理上它也能算是一种哈希,但在实际使用里通常不理想。

第 5 页
- A “mixing-well” hash function(一个“混合性好”的哈希函数示例):
- Mid-square method(中间平方法):先把数字平方,然后把结果中间的一部分(若干位)取出来作为哈希值。
- 例子:4567 \(\times\) 4567 = 20857489,从中间拿两位,变成 57,这就是哈希值(如果表大小为 100,就取两位足够)。
- 原理:这样做会让原数字的各个部分(各个位)都对结果有影响,尽量让输出均匀分布。
为什么看不懂?
- 如果没有写过哈希函数,可能不知道为什么要“取平方再取中间”。它的好处在于“高位、低位”都会混合在一起,让冲突概率更低。
为什么“中间平方法”是一个“混合性好”的哈希函数?
1. 什么是“混合性好”(Mixing Well)?
在哈希函数中,“混合性好”意味着:
- 输入的所有部分(如数字的每一位)都对输出(哈希值)有贡献。
- 输出分布均匀:不同输入得到的哈希值应尽可能分散,减少冲突概率。
类比:就像搅拌一杯咖啡,糖和咖啡粉充分混合,每一口都能尝到甜味。
- 如果“混合性不好”,糖可能沉在底部,某些部分特别甜,其他部分无味。
- 如果“混合性好”,每一口味道均匀。
2. 中间平方法的工作原理
步骤:
- 平方:将输入数字平方,得到一个更长的数字。
- 例如:
4567平方后得到20857489。
- 例如:
- 取中间部分:从平方结果中提取中间若干位作为哈希值。
- 例如:从
20857489中取中间两位57。
- 例如:从
为什么这样做?
- 平方的作用:将输入数字的每一位(高位、低位)都“混合”到结果中。
- 例如:
4567的每一位(4、5、6、7)在平方后都会影响20857489的每一位。
- 例如:
- 取中间部分:平方结果的高位和低位可能受到输入高位或低位的过度影响,而中间部分更能反映输入的整体特征。
3. 为什么“中间平方法”混合性好?
-
高位和低位的混合:
- 平方操作会将输入的高位和低位“交叉相乘”,例如:
- 输入:
4567 - 平方:
4567 × 4567 = 20857489 - 这里的
20857489是由4×4、4×5、4×6、4×7、5×4、5×5、5×6、5×7、6×4、6×5、6×6、6×7、7×4、7×5、7×6、7×7等多个部分相加得到的。
- 输入:
- 因此,输入的高位和低位都会影响平方结果的每一位。
- 平方操作会将输入的高位和低位“交叉相乘”,例如:
-
均匀分布:
- 取中间部分可以避免平方结果的高位或低位对哈希值的过度影响。
- 例如:如果取平方结果的高位,可能只反映输入的高位特征;如果取低位,可能只反映输入的低位特征。
- 取中间部分则能更好地平衡高位和低位的影响,使哈希值更均匀。
5. 为什么“取平方再取中间”能降低冲突概率?
-
平方操作扩大了输入的影响范围:
- 输入的每一位都会影响平方结果的每一位,使得输入的小幅变化可能导致哈希值的大幅变化。
-
取中间部分避免了局部偏差:
- 平方结果的高位可能只反映输入的高位特征,低位可能只反映输入的低位特征,而中间部分更能反映输入的整体特征。
-
均匀分布:
- 通过平方和取中间部分,哈希值更均匀地分布在可能的范围内,减少了冲突概率。
 Hashing with non-numerical key values(对非数值型键进行哈希):
Hashing with non-numerical key values(对非数值型键进行哈希):
- 文字(比如 ASCII 编码)也可以看作数字的序列。
- ASCII 是一种标准,把字符 'A'、'B'、'C' 等分别用数字表示(比如 A=65,B=66,……)。
- 如果我们把字符串当成一个“进制数”(base-128),那就能把它转化成一个大整数,再进行哈希。
- 例子:‘ABC’ => 65 \(\times 128^2 + 66 \times 128^1 + 67\) = 1,073,475。再对这个大整数使用哈希函数即可。
2. 专业知识点总结
-
哈希/散列(Hashing)
- 用途:实现快速的查找、插入、删除。
- 关键:把大数据(比如一个很大的整数或字符串)用某个“哈希函数”变成一个相对短的数字,用作索引。
-
哈希函数(Hash Function)
- 性质:把“任意大小的数据”映射到“固定范围的整数”上。
- 要求:尽量让不同输入有不同结果(减少冲突),且分布比较随机/均匀。
- 示例:取模(mod 方法)、中间平方法(mid-square)、一些安全散列(如 MD5、SHA 等)。
-
冲突(Collision)
- 当两个不同的输入对应到同一个哈希值时,就产生了冲突。
- 冲突处理策略:链地址法(拉链法)、开放地址法等。
-
平均时间复杂度(Average Case Time Complexity)
- 在哈希表里,如果冲突不多,查找、插入、删除可以做到 \(O(1)\) 平均。
- 但是最坏情况(Worst Case)可能退化到 \(O(n)\)(当所有键都冲突在同一个地方时)。
-
字符串哈希
- 把每个字符用 ASCII(或 Unicode)数字表示,然后把它们视为“某种进制”的一串数字,再进行哈希函数处理。
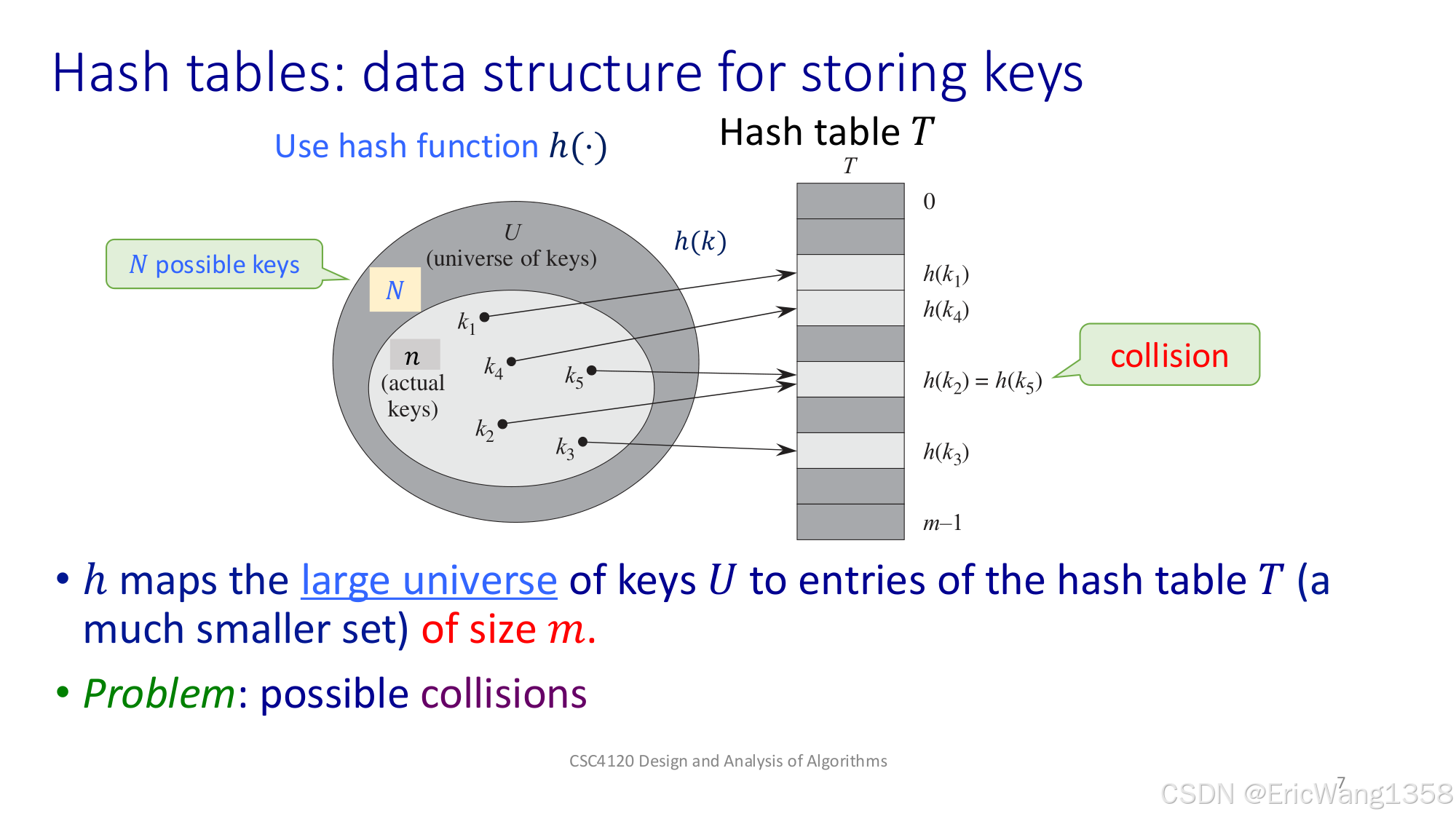
第 7 页
- Hash tables: data structure for storing keys
- 有一个巨大的「键的集合」\(U\),其中的大小(\(|U| = N\))可能非常大,但我们只用到了其中的部分键(实际数量是 \(n\))。
- 哈希函数 \(h(k)\) 把这些键(k)映射到哈希表 \(T\) 的某个槽位(slot)。哈希表大小是 \(m\),比 \(N\)(潜在的键数量)通常要小得多。
- 问题:有可能多个键哈希到同一个槽位,就会发生“碰撞(collision)”。
通俗理解:想象一个很大的班级有上千名学生,但教室只有 100 个座位(m=100)。我们要把学生分配到座位时,需要一个“分配规则”(哈希函数)。难免可能很多人都排到同一个座位,形成冲突。
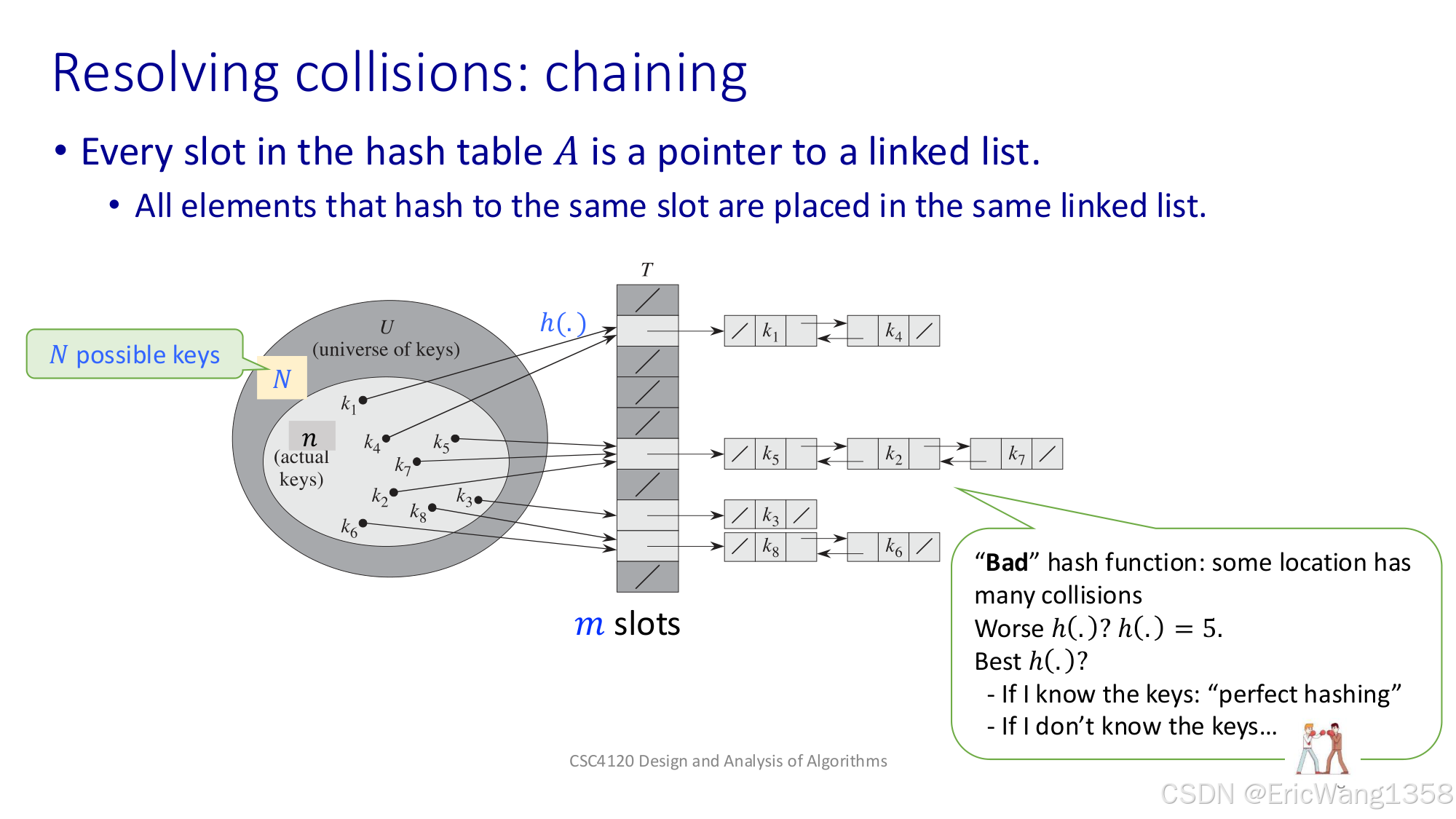
第 7 页
- Hash tables: data structure for storing keys
- 有一个巨大的「键的集合」\(U\),其中的大小(\(|U| = N\))可能非常大,但我们只用到了其中的部分键(实际数量是 \(n\))。
- 哈希函数 \(h(k)\) 把这些键(k)映射到哈希表 \(T\) 的某个槽位(slot)。哈希表大小是 \(m\),比 \(N\)(潜在的键数量)通常要小得多。
- 问题:有可能多个键哈希到同一个槽位,就会发生“碰撞(collision)”。
通俗理解:想象一个很大的班级有上千名学生,但教室只有 100 个座位(m=100)。我们要把学生分配到座位时,需要一个“分配规则”(哈希函数)。难免可能很多人都排到同一个座位,形成冲突。
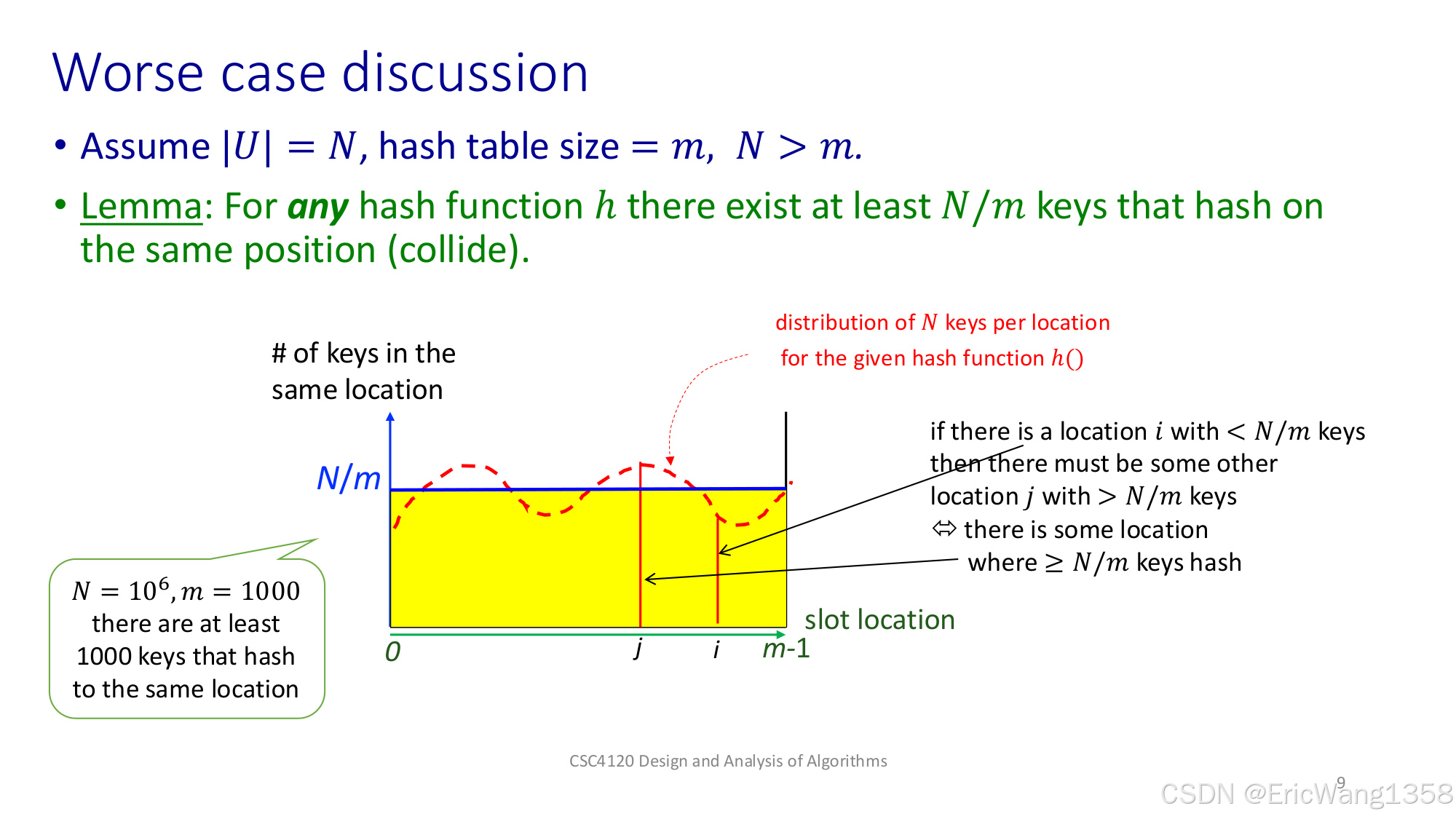
- Worse case discussion(最坏情况的讨论)
- 假设 \(|U| = N\),哈希表大小是 \(m\),并且 \(N > m\)。
- 提出一个引理(lemma):无论什么哈希函数,总会有至少 \(N/m\) 个键落在同一个槽位上(碰撞在一起)。
- 直观解释:如果有些槽位的键数少于 \(N/m\),那一定会有其他槽位的键数超过 \(N/m\),总之必然存在一个槽位挤着不少键。
通俗理解:就像开头那个“100 个座位,1000 人”的例子。如果有的座位只有 3 个人坐,就必定有别的座位超过 3 个人,否则坐不下 1000 人。你怎么排,都无法避免至少有一个槽位特别挤。
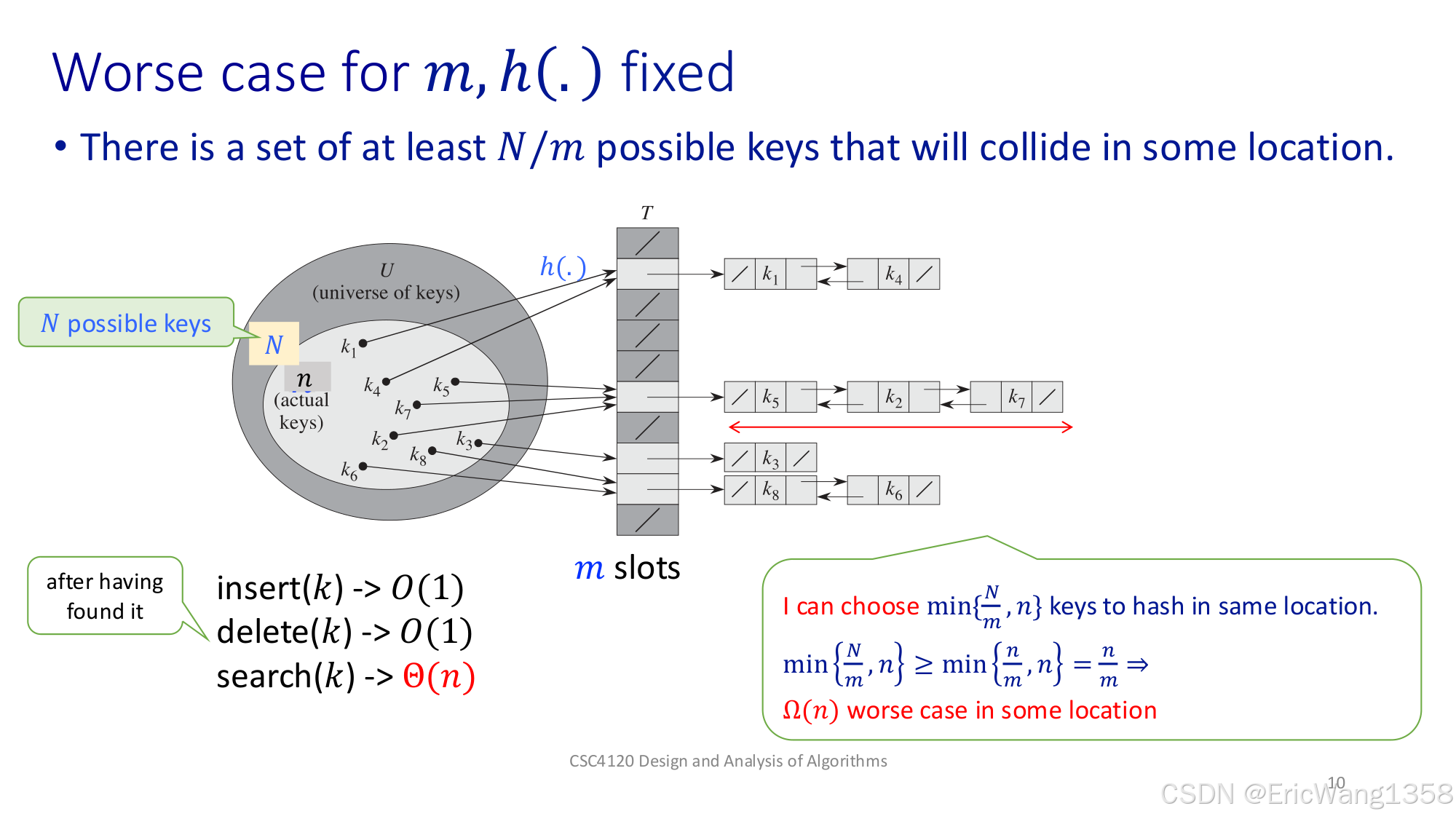
通俗解释为什么查找会退化到 Ω(n) 级别
1. Ω(n) 的含义
- 大Ω符号(Omega Notation) 表示算法运行时间的下界(至少需要多少时间)。
- 若查找时间为 Ω(n),表示存在某些输入,使得查找操作的时间至少与 n 成线性关系(即最坏情况下必须遍历所有元素)。
类比:
- 假设你有一筐苹果,最坏情况下(所有苹果都藏在最底层),你至少需要翻遍整个筐才能找到目标苹果,这就是 Ω(n)。
- 但大部分情况下(苹果分散在各层),可能只需要翻几次就能找到,这就是平均 O(1)。
2. 哈希表的最坏情况
当所有 N 个键都映射到同一个槽位时:
- 链表长度:槽位中的链表长度为 N。
- 查找操作:必须遍历整个链表,每次比较一个键,直到找到目标。
- 最坏情况:需要比较所有 N 个键,时间为 Ω(N)(即线性时间)。
例子:
- 假设哈希表大小为 m=10,但黑客故意构造 1000 个键,它们的哈希值全部为
3。 - 此时,槽位
3的链表长度为 1000,查找任意键都需要遍历这 1000 个键。
3. 插入和删除为何仍是 O(1)?
- 插入:只需将新键添加到链表头部(或尾部),操作时间为常数 O(1)。
- 删除:若已知键的位置(例如通过指针直接指向链表节点),删除操作也是 O(1)。
- 关键点:
- 插入和删除的 O(1) 不包含查找键的时间(查找需要 Ω(n))。
- 如果题目中说“插入和删除的时间为 O(1)”,通常默认已经找到槽位,后续操作是常数时间。
4. 为什么说“最大是 n,但这里用 Ω(n)”?
- **O(n)** 是上界,表示“时间复杂度不超过线性时间”。
- **Ω(n)** 是下界,表示“存在某些输入,时间复杂度至少是线性时间”。
- 结论:
- 查找的最坏情况时间复杂度是 Ω(n)(存在线性时间的输入)。
- 同时,它也是 O(n)(不会超过线性时间)。
- 因此,**查找的时间复杂度是 Θ(n)**(既是 Ω(n) 也是 O(n))。
总结
- 哈希表的性能依赖于哈希函数的均匀性。如果所有键冲突到同一槽位,查找退化为线性时间(Ω(n))。
- 插入和删除的 O(1) 是局部操作,不包含查找槽位的时间。
- 防御最坏情况的方法:
- 使用抗冲突的哈希函数(如加密哈希函数)。
- 动态调整哈希表大小(如当负载因子过高时扩容)。
终极理解:
- 哈希表像分拣快递:
- 正常情况下,快递按区域分拣,快速找到目标(平均 O(1))。
- 如果所有快递被恶意贴上同一区域标签,分拣员不得不逐个检查,速度退化为线性时间(Ω(n))。
 How to think of hashing experiments(如何思考哈希实验)
How to think of hashing experiments(如何思考哈希实验)
- 先固定一个哈希函数,随机选 n 个键,看看冲突大不大?
- 或者先固定 n 个键,随机换不同的哈希函数,看看它们撞在同一个槽位的概率是多少?
- 问题:给定 2 个随机键,撞的概率?给定 2 个固定键,随机哈希函数时碰撞的概率?等等。
- 这些实验能帮我们从概率角度理解“哈希冲突”的发生。
2. 专业知识点总结
-
Collision resolution by chaining(用链表解决碰撞)
- 哈希表中常见的一种策略:把冲突的元素放到同一个链表里。
- 查找时,就在对应的链表里顺序搜索,平均情况下长度不长,但最坏情况下可能很长。
-
Worst-case scenario(最坏情况)
- 无论多巧妙的哈希函数,如果有人刻意构造输入,都能让大量键撞在同一个槽位,导致操作时间退化到 \(O(n)\)。
- 这是因为我们没有任何事先信息可以保证完美分布。
-
Lemma: \(N/m\) collisions
- 在大小为 \(m\) 的哈希表里,若总共有 \(N\) 个可能的键,必然存在一个槽位至少有 \(\lceil N/m\rceil\) 个键,这就是抽屉原理(pigeonhole principle)。
-
Hashing experiments(哈希试验)
- 固定哈希函数,随机选键(或者反之),看冲突率。
- 研究碰撞分布的随机性,有助于估算哈希表性能。
3. 英文练习题与参考解答
下面是基于幻灯片内容的英文问题及简要解答:
Q1. What is collision resolution by chaining in a hash table?
Answer:
Chaining means that each slot in the hash table points to a linked list (or chain) of entries that share the same hash value. When multiple keys hash to the same slot, they are inserted into the corresponding linked list. To search for an element, we traverse that list until we find the item or reach the end.
Q2. Why can we never fully avoid collisions with a fixed hash function?
Answer:
Because if there are \(N\) possible keys and only \(m\) slots, by the pigeonhole principle, there must be at least one slot that holds \(\lceil N/m\rceil\) keys. Also, adversarial inputs can be chosen to force many keys into one slot, creating collisions.
Q3. What happens in the worst case of a hash table that uses chaining?
Answer:
In the worst case, many or all of the keys collide in the same slot, forming a long linked list. Searching for a key then requires traversing this entire list, taking \(O(n)\) time in the worst case (where \(n\) is the number of keys stored).
Q4. When we do hashing experiments, what two factors can we vary randomly?
Answer:
- We can fix a specific hash function \(h(.)\) and pick a random set of \(n\) keys from the universe \(U\).
- We can fix the set of \(n\) keys and randomly choose a hash function from a family of possible hash functions.
Q5. In the case of chaining, why are the insert and delete operations still considered \(O(1)\) after we find the right slot?
Answer:
Once we know the key hashes to slot \(i\), we only need to add or remove the key from the front (or any known position) of the linked list, which is a constant-time pointer operation, provided we already have a pointer to the correct node (or to the start of the list).
4. 中文进一步解释
-
为什么“链表法”可以解决碰撞?
- 因为同一个槽位要容纳多个元素,就要“排队”。用链表存放可以灵活地扩展——多一个键就加在链表尾部。
-
最坏情况真的会发生吗?
- 如果有人专门制造“碰撞输入”,就可能让哈希表退化到很慢的情况。实际应用里,通常假设数据“比较随机”,所以平均情况依然很快。
-
“\(N/m\)”个键碰撞在同一个槽位是什么意思?
- 如果有 1000 个键(\(N=1000\))而槽位只有 10 个(\(m=10\)),理论上有一个槽位会分配到至少 100 个键(\(1000/10 = 100\))。在最坏情况下,这些键全挤在同一个地方。
-
随机试验为什么有用?
- 因为哈希函数的效果很多时候要看统计分布。固定哈希函数、随机选键,可以观察碰撞率的期望值;或者固定一组键,随机换哈希函数,也可以看平均表现是否更好。
-
现实中的防碰撞方法
- 有些编程语言在哈希表中引入红黑树等结构,当链表过长时自动转为平衡树,避免链表过长导致最坏情况。
- 也可以使用一些随机化策略,或者在已知全部键的场景下做“完美哈希”(perfect hashing)。
1. 什么是“键”(Key)?
- 键是哈希表的输入元素,可以是任意数据类型(整数、字符串、对象等)。
- 核心作用:通过哈希函数将键映射到哈希表的某个槽位(Bucket),用于后续的插入、删除和查找操作。
- 示例:
- 在字典
dict中,键是用于查找值的唯一标识(如my_dict["name"] = "Alice",键是"name")。 - 在集合
set中,键是存储的唯一元素(如my_set = {1, 2, 3},键是1, 2, 3)
- 在字典
为什么要做哈希实验?——通俗解析
哈希实验的核心目标是量化分析哈希函数的性能,尤其是它在不同场景下产生冲突的概率。以下是两种实验的直观解释和实际意义:
1. 实验一:固定哈希函数,随机选键
操作:选择一个固定的哈希函数 h(.),然后随机生成大量键(比如随机数字或字符串),观察这些键的分布情况。
问题:这些随机键中有多少会发生碰撞(即映射到同一槽位)?
实际意义:
- 测试哈希函数的“均匀性”:
- 好的哈希函数应该像“公平的抽签”,每个槽位被选中的概率均等。
- 如果随机键的碰撞次数远高于理论值(例如生日问题中的概率),说明哈希函数设计有问题。
- 应用场景:
- 数据库设计:确保用户随机输入的数据能均匀分布,避免某些槽位链表过长。
- 负载均衡:类似哈希表,将请求均匀分配到服务器集群中。
例子:
假设哈希表有 100 个槽位,插入 10 个随机键。
- 理想情况:每个槽位平均有 0.1 个键,实际冲突很少。
- 糟糕情况:某几个槽位被多次选中,导致链表过长,查找变慢。
2. 实验二:固定键,随机换哈希函数
操作:固定一组键(比如特定数据),然后随机选择不同的哈希函数,观察这些键的碰撞情况。
问题:同一组键在不同哈希函数下,碰撞概率如何变化?
实际意义:
- 测试哈希函数的“抗攻击性”:
- 如果攻击者知道哈希函数,可能故意构造大量碰撞的键(哈希洪水攻击)。
- 通过随机更换哈希函数(如全域哈希),即使键固定,攻击者也无法预测碰撞。
- 应用场景:
- 网络安全:防止恶意用户通过制造冲突拖慢服务器。
- 动态优化:根据数据特征选择最适合的哈希函数。
例子:
假设黑客知道你的哈希函数是“取键的最后两位”,他可以构造 1000 个以 00 结尾的键,全部碰撞到同一槽位。
- 解决方案:改用随机化的哈希函数,让黑客无法预测槽位。
为什么这些实验重要?
-
理解冲突概率:
- 哈希表的性能依赖于“冲突概率越低,操作越快”。
- 实验帮助量化理论(如生日问题)是否符合实际。
-
防御最坏情况:
- 通过实验发现哈希函数的弱点,避免实际系统中出现性能骤降。
-
优化设计:
- 选择适合数据分布的哈希函数(如对字符串用多项式哈希,对整数用取模哈希)。
生活化类比
-
实验一:测试抽奖公平性
- 固定一个抽奖箱(哈希函数),让 1000 人随机抽奖(键)。
- 如果某些奖品(槽位)被抽中次数远超预期,说明抽奖箱有问题。
-
实验二:动态更换门锁
- 假设你家门锁(哈希函数)被小偷研究透了,他们能用万能钥匙(碰撞键)开锁。
- 每天随机换一种锁(随机哈希函数),小偷的万能钥匙就失效了。
总结
- 实验一:验证哈希函数对随机输入的公平性。
- 实验二:确保即使输入被恶意构造,哈希函数也能通过随机化避免灾难性冲突。
- 核心目标:让哈希表在随机数据和恶意攻击下都能高效稳定运行!

第 12 页
- 平均情形分析:两种随机模型(Models for randomness)
- Model 1:哈希函数 \(h\) 固定,但是每次实验里,键 \(k\) 都是从整个宇宙 \(U\) 里随机(均匀)地选出来。
- 若 \(h\) 能让所有槽位被均匀访问到(对所有 \(i\),\(P[h(k)=i] = 1/m\)),就说 \(h\) “分布好”(good)。
- 这也叫 SUHA(Simple Uniform Hashing Assumption, 简单均匀哈希假设)。
- Model 2:键集合(要存的键)固定,但我们随机(均匀)地从一个“哈希函数家族”\(H\) 中选一个 \(h\)。
- 如果对所有不同的 \(k_1\) 和 \(k_2\),碰撞概率 \(P_h[h(k_1)=h(k_2)] \le 1/m\),则说这整个家族 \(H\) “分布好”(good)。
- 这种家族 \(H\) 称作 universal hash functions(通用哈希家族)。
- 两种模型虽然不一样,但在平均情况下得出的结论往往相似。
- Model 1:哈希函数 \(h\) 固定,但是每次实验里,键 \(k\) 都是从整个宇宙 \(U\) 里随机(均匀)地选出来。
通俗解释:要想让哈希“平均分布”有两种思路:
- 假设你事先选定了一个哈希函数 \(h\),但是所要插入的键是随机的。
- 或者反过来,键是定好的,但你每次使用时都随机换一个哈希函数。
这两种方式都会带来一些“随机性”,从而让碰撞在平均意义上被稀释。
关于哈希表中的参数 m 的详细解释
1. m 的定义
在哈希表(Hash Table)中,**m 始终表示哈希表的大小**,即哈希表中槽位(Bucket)的数量。
- 无论哪种模型,
m的核心意义是:哈希表有多少个槽位用于存放键。 - 示例:若
m = 100,则哈希表有 100 个槽位,键会被映射到0到99的某个位置。

- Discussion(讨论)
- 如果用 SUHA(Model 1),我们假设:对哈希表的任意槽位 \(i\),随机选择一个键 \(k\) 落到槽位 \(i\) 的概率都是 \(1/m\)。
- 如果用 universal hashing(Model 2),不看每个槽位具体概率,而是关心“任意两个不同键发生碰撞的概率 \(\le 1/m\)”。
- 所以 SUHA 和通用哈希并不完全等价,但都能在平均情形下给我们相似的结论。
- 实际上,为了直观理解,人们常常假设 SUHA;为了严格的数学分析,人们倾向用通用哈希做模型。
通俗解释:SUHA 是一种“简单直接”的均匀假设:好像每个键都“等概率”落到每个槽里。Universal hashing 更偏向“构造可证明的哈希函数家族”,可以保证“任何两个键”碰撞概率不大。一个偏想象/假设,一个更偏实际/理论上的家庭构造,但平均性能都不错。


为什么实际分析中 SUHA 用于直观,通用哈希用于严格证明?
**(1) SUHA 的优势与局限**
- 优势:
- 直观易懂:假设键是随机的,符合大多数自然场景(如用户随机输入)。
- 便于教学:无需复杂数学,即可解释哈希表的平均性能。
- 局限:
- 假设过强:现实中键可能非均匀分布(例如恶意构造的键)。
- 无法防御攻击:如果键不随机,SUHA 的结论可能失效。
**(2) 通用哈希的优势与适用场景**
- 优势:
- 数学严谨:通过函数族设计,严格保证冲突概率上限。
- 抗攻击性:即使键是固定的或恶意的,也能确保性能。
- 适用场景:
- 安全关键系统(如网络协议、密码学)。
- 需要理论证明的场景(如算法论文中的严格分析)。

第 14 页
- The Simple Uniform Hashing Assumption (model 1)(SUHA 细节)
- 具体地:随机选一个键 \(k\)(均匀分布在 \(U\) 里),\(P[h(k)=i] = 1/m\)。
- 举了一些例子:
- 理论例子:\(k \in {0,\ldots,2^{10}-1}\),\(h(k) = k \bmod 2^2\),等价于“只取 \(k\) 的末 2 位”。
- 现实中常用的一种方式:\(h(k) = \lfloor m \times ((k \times A) \bmod 1)\rfloor\),其中 \(A = (\sqrt5 - 1)/2 \approx 0.618\ldots\),也称“乘法散列法 (multiplicative hashing)”。实践里常取 \(m=2^p\)。
通俗解释:只要能把键“随机地”分到 \(m\) 个槽中,使得每个槽中概率都差不多,你就算满足了 SUHA。这种假设方便我们做期望计算。







- Probability questions (under SUHA)(SUHA 下的一些概率问题)
- 我们把 \(n\) 个项目均匀分配到 \(m\) 个槽位。
- 用 \(x_i\) 表示槽位 \(i\) 的元素数量,那么期望 \(E[x_i] = n/m\)。
- 用 \(y_i\) 表示槽位 \(i\) 是否最终为空(1 表示空,0 表示不空),可以算出期望多少个槽为空。
- 碰撞数(number of collisions):如果某个槽位被一个以上的元素占用,那就发生了碰撞。可以用公式计算期望碰撞数 \(E[C]\)。
通俗解释:这是“把 n 个球随机放进 m 个盒子”的经典问题。每个盒子平均放 \(n/m\) 个球,也会有概率算出“碰撞球数”或者“空盒数量”。很多离散概率或“Balls and Bins”模型都用同样原理。

- Universal hashing (model 2 for randomness)(通用哈希)
- 假设有个“对手(adversary)”可以选择键来让你的哈希表崩溃。如果对手知道你的 \(h\),他就可以挑一堆键都落同一个槽。
- 解决办法:随机化!从一个足够大的哈希函数家族 \(H\) 里随机选一个 \(h\)。
- 对手或许知道 \(H\) 的存在,但并不知道你这次具体选的哪一个函数,就很难“精准打击”。
- 这样就使得“碰撞率”大概率保持低水平,对手没法专门制造最坏情况。
通俗解释:如果你的哈希函数是明摆着的,比如 \(h(k)=k \bmod 10\),那对手想让所有键都落到余数=3 的地方就很容易。但如果你在一堆函数里随机选一个,对手不知道你选的哪一个,那他就没法有针对性地制造大批碰撞。这就是“通用哈希”思路。

- Universal hashing(通用哈希的定义)
- 给定一个函数家族 \(H\),如果对于任意两个不同的键 \(k, r\),满足碰撞的哈希函数数量 \(\le |H|/m\),就说 \(H\) 是“通用的 (universal)”。
- 换言之,随机从 \(H\) 中选一个 \(h\),任意两键碰撞的概率 \(\le 1/m\)。
- 这可以保证你拿任意一对不同键,撞到一起的机会都不超过 \(1/m\)。
- 我们可以“可证明地”构造这样的哈希函数家族。
通俗解释:通用哈希的精髓是:不要把所有鸡蛋放在一个篮子(单一函数)里,而是准备一篮子“多样化”的函数。只要随机挑其中一个,对任意两不同键,都不会“很大几率”撞在一起。这样就能规避被人刻意利用的风险。
2. 专业知识点总结
-
SUHA(Simple Uniform Hashing Assumption)
- 模型 1:固定 \(h\),键随机。
- 假设每个键落到任意槽位的概率相等为 \(1/m\)。
- 方便做期望分析(如期望冲突数、期望空槽数等)。
-
Universal Hashing(通用哈希)
- 模型 2:键集合固定,但哈希函数是从一个大集合 \(H\) 随机选择。
- 定义:对所有 \(k_1 \neq k_2\),碰撞概率 \(\le 1/m\)。
- 目的是防范对手刻意选键制造大范围碰撞。
-
碰撞概率与期望碰撞数
- 在 SUHA 下,可以得到碰撞概率 \(= 1/m\);在通用哈希下,对任意两键也能保证 \(\le 1/m\)。
- 由此可以推导出哈希表的平均查找时间为 \(O(1)\)。
-
实际意义
- SUHA 在实际中可能是理想化的假设,但写分析时很常见。
- Universal Hashing 则是偏理论的严谨方案,一些编程语言在对安全性要求较高时也会考虑这种策略。
3. 英文练习题与参考解答
Q1. What is the Simple Uniform Hashing Assumption (SUHA)?
Answer:
SUHA assumes that for a fixed hash function \(h\), every key \(k\) in the universe \(U\) has an equal probability \(1/m\) of being mapped to each slot in a hash table of size \(m\). In other words, keys are chosen randomly from \(U\), and \(h\) distributes them uniformly among the \(m\) slots.
Q2. How does universal hashing help thwart an adversary who tries to cause collisions?
Answer:
With universal hashing, we randomly pick \(h\) from a large family of hash functions. Since the adversary does not know which specific function is used, they cannot reliably craft a set of keys that all collide. Formally, for any two distinct keys \(k_1\) and \(k_2\), the probability \(P[h(k_1) = h(k_2)]\) is at most \(1/m\).
Q3. In the context of hash tables, what does it mean for a family of hash functions \(H\) to be universal?
Answer:
A family \(H\) of hash functions is universal if, for any pair of distinct keys \(k, r\) in the universe \(U\), the fraction of hash functions in \(H\) that cause \(k\) and \(r\) to collide is at most \(1/m\). Equivalently, if you pick a hash function \(h\) at random from \(H\), then the probability that \(k\) and \(r\) map to the same slot is \(\le 1/m\).

第 18 页
- Analysis: 想分析在哈希表中查找一个键
k的期望时间。 - 时间 \(T = T_1 + T_2\):
- 最坏情况:要检查这个槽位的所有元素(链表长度 \(L\))。
- 如果搜索成功,需要看 1 个本身(就是
k)+ 另外所有键的比较次数。 - 如果搜索失败,需要看这个槽里的所有键。
- 如果搜索成功,需要看 1 个本身(就是
- 所以对于成功搜索,链表长度为“1 + 其他键数”;对于失败搜索,链表长度为“该槽里的所有键数”。
- 后面将计算 \(E[T_2]\):也就是该链表在平均情况下有多长。
大白话:
要查找的步骤就是:先算“k 到底被分到哪个槽”(这步时间固定忽略),然后在那个槽位的链表里一一对比。平均来说,这个链表有多少元素,决定了搜索要花多少时间。


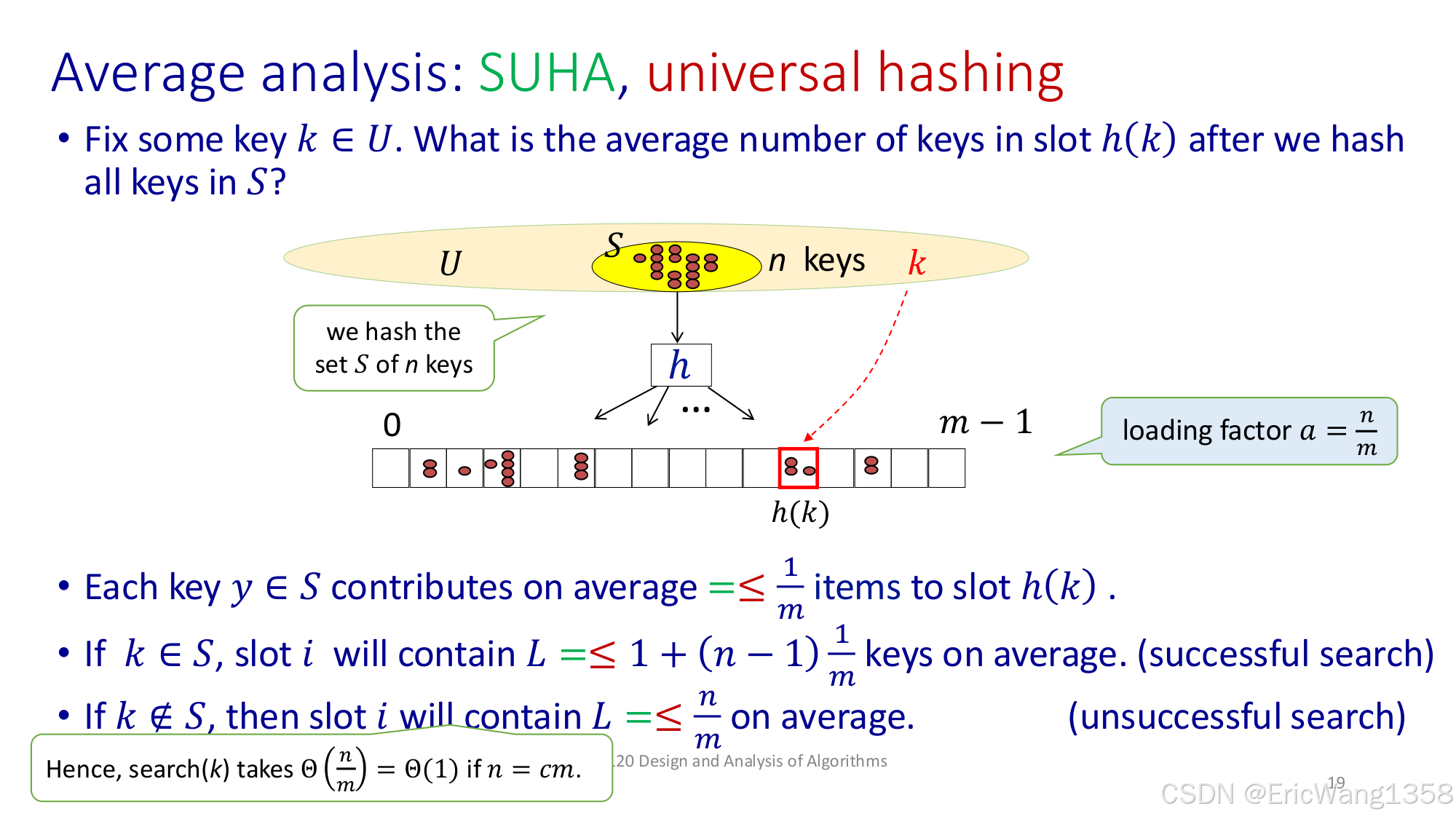
第 19 页
- Average analysis: SUHA, universal hashing
- 固定一个键
k,想知道平均地看,被放进同一槽位的键有多少个? - 如果哈希表有 \(m\) 个槽、\(n\) 个键,负载因子 \(\alpha = n/m\)。
- 成功搜索:若
k确实在表里,那么它所在的槽平均还会有 \((n-1)/m\) 其他键。链表长度大约是 \(1 + (n-1)/m\)。 - 失败搜索:若
k不在表里,但我们还要去那个槽看看,有大约 \(n/m\) 个键在那个槽里。
- 固定一个键
大白话:
假设平均每个槽装 \(n/m\) 个元素,那么找一个真正存在的键,需要比较 1(它自己)+ \(n/m - 1\)(其他的) ≈ \(n/m\) 次。若键不在表里,也要比较该槽里 \(n/m\) 个键。总之 \(\alpha = n/m\) 是决定平均链表长度的关键。

第 19 页
- Average analysis: SUHA, universal hashing
- 固定一个键
k,想知道平均地看,被放进同一槽位的键有多少个? - 如果哈希表有 \(m\) 个槽、\(n\) 个键,负载因子 \(\alpha = n/m\)。
- 成功搜索:若
k确实在表里,那么它所在的槽平均还会有 \((n-1)/m\) 其他键。链表长度大约是 \(1 + (n-1)/m\)。 - 失败搜索:若
k不在表里,但我们还要去那个槽看看,有大约 \(n/m\) 个键在那个槽里。
- 固定一个键
 Average analysis (universal hashing)
Average analysis (universal hashing)
- 现在不再假设键随机,而是假设我们从一个大的哈希函数家族 \(H\) 中随机选 \(h\)。
- 同样分两种情况:
k在 \(S\) 里,碰撞的期望数 \(\le (n-1)/m\)。k不在 \(S\) 里,碰撞的期望数 \(\le n/m\)。
- 链接长度同理也 \(\le 1 + (n-1)/m\) 或 \(n/m\)。





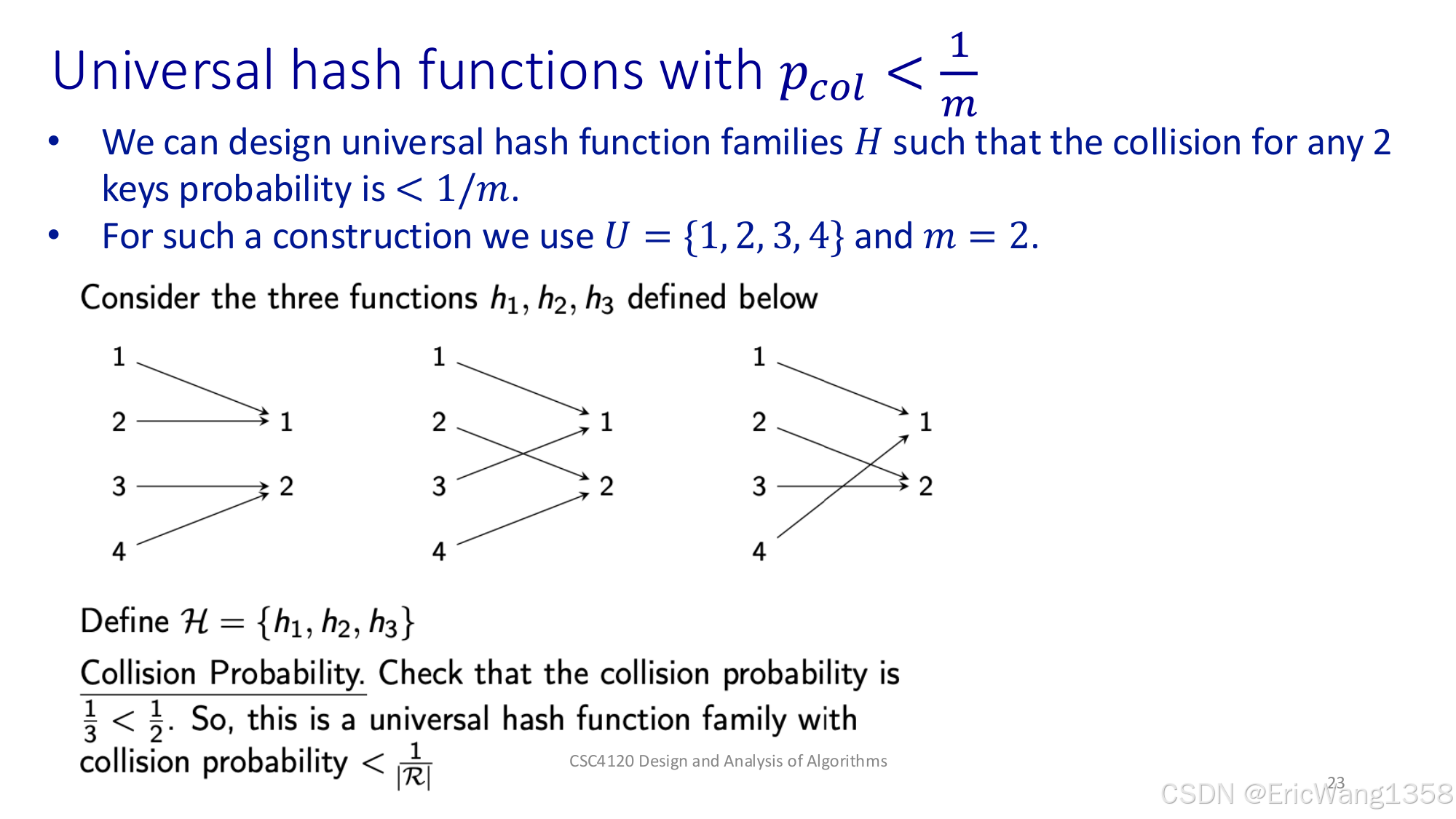
第 23 页
- Universal hash functions with \(p_{col} < 1/m\)
- 给了一个简单的例子:\(U = {1,2,3,4}\), \(m=2\)。
- 列出 3 个函数 \(h_1,h_2,h_3\),构造出一个函数家族 \(H\)。
- 可以检查任意两键碰撞概率 < \(1/m = 1/2\)。
- 说明我们确实能设计出一个碰撞率很小(满足 universal)的哈希家族。
大白话:
举个迷你例子来展示“通用哈希”是怎么构造的。让你看到在小范围里怎么保证“两键同时落同一个槽”的概率不大于 1/2。

第 24 页
- Conclusions
- 哈希是一个非常有用的技术,它在平均情况下能让“查找、插入、删除”都达到 \(O(1)\)。
- 这种结论基于一个假设:我们用“好的”哈希函数,让任意两键碰撞概率大约是 \(1/m\)。
- 两种方法:
- SUHA:假设键是随机的;
- 通用哈希:我们自己随机选择哈希函数以对抗恶意输入。
- 通用哈希在概念上更深入,因为它不要求键随机,只要我们能随机化哈希函数,就能达到好效果。
大白话:
课程总结:哈希能在平均或者期望的情况下获得非常好的性能,前提是要使用合适的(分布均匀的)哈希函数。
2. 专业知识点总结
-
查找时间的期望值
- 主要取决于同槽内的链表长度。成功搜索多 1 次比较(因为要比较到
k自己),失败搜索少比较 1 次。 - 在平均情况(SUHA 或通用哈希)下,这个链表长度大约是 \(\alpha = n/m\),所以查询是 \(O(1)\)。
- 主要取决于同槽内的链表长度。成功搜索多 1 次比较(因为要比较到
-
成功搜索与失败搜索的期望长度
- 成功搜索:平均链表长度是 \(1 + (n-1)/m\)。
- 失败搜索:平均链表长度是 \(n/m\)。
-
负载因子 (load factor) \(\alpha = n/m\)
- 表示“每个槽位平均存多少元素”。
- 当 \(\alpha\) 保持常数级别时,哈希表查找插入都能 \(O(1)\) 平均。
-
通用哈希函数的存在性
- 可以通过构造一整族哈希函数,让两个不同键碰撞的概率不超过 \(1/m\)。
- 这样即便对手故意选键,还是难以集中到某一槽里。
-
结论
- 利用这两种随机模型(SUHA 或通用哈希),我们就能得到哈希表的“平均 \(O(1)\) 性能”结论。
3. 英文练习题与参考解答
Q1. In a hash table using chaining, what is the expected time to search for a key under the Simple Uniform Hashing Assumption?
Answer:
Under SUHA, each slot has about \(n/m\) keys on average. For a successful search, you expect to check \(1 + (n-1)/m\) elements in the slot (one for the key itself plus the other keys). For an unsuccessful search, you check \(n/m\) elements. If the load factor \(\alpha = n/m\) is constant, both cases yield \(O(1)\) expected time.
Q2. Why do we separate the analysis into “successful” and “unsuccessful” searches?
Answer:
Because when the target key is in the table, we have to account for the extra comparison that finds the key itself. In a successful search, the key is among the colliding keys in the slot, so the chain length is effectively one more. In an unsuccessful search, the key is not there, so we only compare against those keys that do exist in the slot.
Q3. What is the load factor \(\alpha\), and why is it important?
Answer:
The load factor \(\alpha = n/m\) measures the average number of keys per slot in the hash table. It is important because it determines the average chain length: a smaller \(\alpha\) implies fewer collisions per slot, thus \(O(1)\) average search time. If \(\alpha\) becomes large, chain lengths grow, and performance can degrade.
Q4. How does universal hashing ensure a low probability of collisions?
Answer:
Universal hashing involves defining a large family of hash functions \(H\) and selecting one function \(h\) at random each time we build the table. For any pair of distinct keys \(k_1, k_2\), only a small fraction (at most \(|H|/m\)) of functions in \(H\) cause them to collide. So, randomly choosing \(h\) means \(P[h(k_1)=h(k_2)]\le1/m\).
Q5. What is the main takeaway from these final slides?
Answer:
The main takeaway is that hashing provides an \(O(1)\)-time average solution for search, insert, and delete operations, provided we use a “good” hashing mechanism. Whether we assume keys are randomly chosen (SUHA) or we randomly choose the hash function (universal hashing), the expected chain length remains around \(\alpha = n/m\), ensuring constant average lookup time.
4. 中文进一步解释
-
为何在哈希表中,查找时间和“链表长度”相关?
- 因为碰撞时,多个键占同一个槽,就需要在该槽对应的链表里逐个比较,链表长度越大,比较越多。
-
为什么要区分“成功”和“失败”查找?
- 成功时,我们肯定要在列表中找到目标键,相当于多一次匹配比较;失败时只要把所有元素都比对完却没找到就结束。
-
负载因子 (\(\alpha\)) 的作用
- 理解负载因子最直观的方法:当 \(\alpha\) 很小(比如 \(\alpha \approx 1\) 或更小),就意味着每个槽位基本不会超过 1~2 个元素,查找就非常快。
- 当 \(\alpha\) 变得很大(远大于 1),就说明很多元素挤在一个槽里,链表会变长,查找性能下降。
-
如何保持负载因子稳定?
- 在实际实现中,我们常常在插入元素后,检查是否 \(\alpha\) 超过了某个阈值(如 0.75)。如果超过,就把哈希表大小 \(m\) 扩充,进行 rehash(重新散列),这样 \(\alpha\) 又降下来了。
-
总结
- 整个课程最后的结论就是:哈希表之所以能在各种编程语言、库里如此常用,正是因为在“平均情况下”有近乎常数时间的效率。
- 要想真的用好哈希表,需要:
- 选择或设计“好的”散列函数(减小碰撞),
- 让负载因子不过大(按需扩容),
- 在安全场景下可以考虑通用哈希,防止恶意碰撞。
希望这些能帮助你对哈希表查找时间的平均分析、成功/失败查找的差别、以及通用哈希的概念有更清晰的认识。祝学习愉快!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









