






3.垃圾回收机制(GC)
C语言中动态内存管理,malloc申请内存,free释放内存。
此处申请到的内存,生命周期是跟随整个过程的,这点对于服务器程序不太友好。服务器每个申请去malloc一块内存,如果不free释放,就会使申请的内存越来越多,后续要想申请内存就无法申请了。 => 内存泄漏问题
实际开发中,很容易出现free不小心忘记调用,或因为一些情况没有执行到。例如:函数中间if return /抛出异常了。
Java就属于早期就引入了垃圾回收这样的语言。
引入这样的机制之后,就不需要手动来释放了,程序会自动判定,某个内存是否会继续使用;如果后续不用了,就会自动释放掉。
垃圾回收中的一个重要的问题:STW(stop the world)
触发垃圾回收的时候,很可能会使当前程序的其他业务逻辑被暂停。
Java有办法把STW的时间控制在1ms之内(1个服务器请求/响应处理时间,典型的时间几毫秒-几十毫秒)
垃圾回收主要工作场所
垃圾回收时回收内存,JVM中内存有好几块:
1.程序计数器(不需要GC)
2.元数据区/方法去(不需要GC)一般涉及到“类加载”,很少涉及到“类卸载”
3.栈(不需要GC)局部变量在代码块执行结束后自动销毁(栈自己的特点,和垃圾回收无关)
4.堆 垃圾回收主要工作场所
这里的垃圾回收,更准确的是“回收对象”,每次垃圾回收的时候,释放的若干个对象(实际的单位都是对象)

对象涉及到的内存正在使用,不能进行释放。“骑墙派”也暂时不释放。
不再使用的内存范围为内的对象是需要进行释放的。
垃圾回收的过程
第一步:识别出垃圾
哪些对象是垃圾(不再使用),哪些对象不是垃圾。
判断这个对象后续是否要继续使用。
在Java中,使用对象,一定要通过引用的方式来使用(例如:匿名对象 => new MyThread().start() 但是执行完后,对应的MyThread对象做垃圾)
如果一个对象没有任何引用指向它,则无法被代码选中,为垃圾。

通过new Test就是在堆上创建了对象。
执行到“}”后,此时的局部变量t就直接被释放掉了,此时再进一步,上述new Test()对象,也就没有引用指向他了。此时这个代码就无法访问使用这个对象,这个对象就是垃圾了。
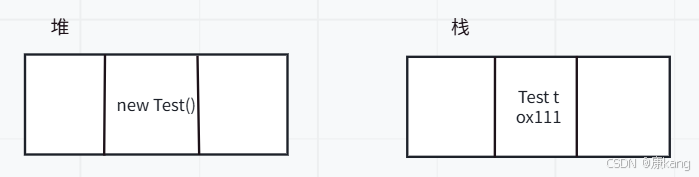
如果代码更复杂一点,这里的判定过程就更复杂了。

此时就会有很多引用指向new Test同一个对象(此时有很多引用,均保存了Test对象的地址) 此时通过任意的引用均能访问Test对象,需要确保所有的指向Test对象的引用都销毁了,才能把Test视为垃圾。 如果代码比较复杂,上述这些引用的生命周期均不同,情况就复杂了。
1.引用计数
这种思想并没有在JVM中使用,但是广泛应用于其他主流语言的垃圾回收机制中(Python,PHP)
给每个对象安排一个额外空间,空间里要保存当前这个对象有几个引用。

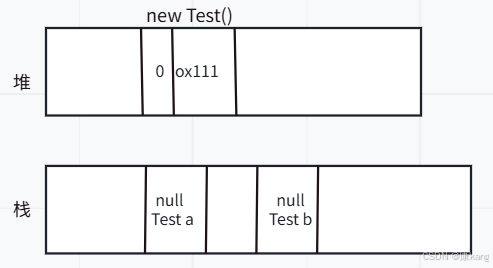
此时垃圾回收机制,有专门的扫描线程去获取到当前每个对象的引用计数的情况,发现对象计数为0,说明这个对象就可以释放了(为垃圾)
引用计数机制是一个简单有效的机制,但是会存在两个关键的问题。
①消耗额外的内存空间
要给每个对象都安排一个计数器(如果计数器按照两个字节),如果整个程序中对象数目很多,总的消耗的空间就会很多。 尤其是如果每个对象体积比较小(假设每个对象为4字节),计数器消耗的空间已经达到了对象的空间的一半。
②“循环引用”
引入计数可能会产生“循环引用”的问题。此时,计数器就无法正确的工作了。

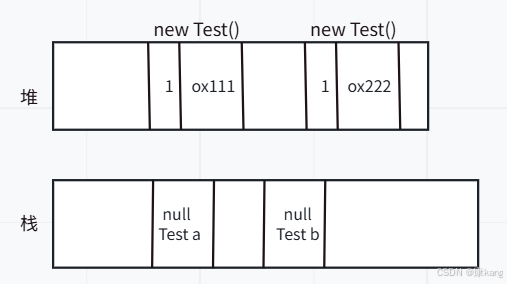
上述代码中出现了问题!此时两个对象,引用计数不是0!!不能被GC回收掉,但这两个对象又无法使用!!
2.可达性分析(JVM使用该方法)
本质上是“时间换空间”相比于引用计数,需要消耗更多的额外时间。但是总体来说,还是可控的,不会产生类似于“循环引用”这样的问题。
在写代码的过程中,会定义很多的变量。比如:栈上的局部变量/方法区中静态类型的变量/常量池中引用的对象,就可以从这些变量作为起点出发,尝试去进行“遍历”。
所谓的“遍历”就是会沿着这些变量中持有的引用类型的成员,再进一步的往下访问。所有能被访问到的对象,自然就不是垃圾了,剩下的遍历一圈也访问不到的对象,自然就是垃圾了。

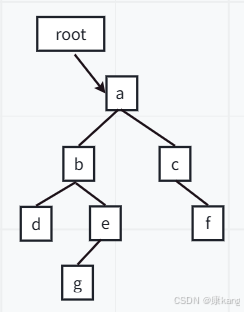
上述代码中,如果执行这个代码,root.right.right = null;
出现断开之后,此时f这个对象就被孤立了,按照上述从root出发进行遍历,就无法访问到f了。f这个节点对象就为“不可达”。
JVM中存在扫描线程,会不停的尝试对代码中已有的这些变量进行遍历,尽可能多的去访问到对象。Node root = buildTree(); => 虽然这个代码中,只有一个root这样的引用了,但实际上7个节点对象为“可达的”。
如果代码中出现:root.right = null;此时c就不可达了,由于f的访问必须通过c,c不可达也就会导致f不可达,c和f为垃圾。
第二步:把标识为垃圾的对象的内存空间进行释放
主要的释放方式有三种。
①标识-清除
把标识为垃圾的对象,直接释放掉(最朴素的方法) 一般不会使用这个方法,内存碎片问题(致命)
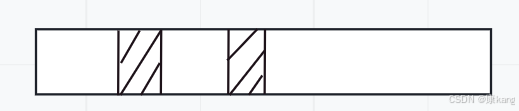
此时就是把标记为垃圾的对象对应的内存空间直接释放。
上述释放的方式,就可能会产生很多的小的,但是是离散的空闲内存空间(内存碎片),就可能导致后续申请内存失效!
内存申请 => 一次申请一个连续的内存空间
如果存在很多内存碎片,就可能导致总的空闲空间,远远超过申请的空间大小,但是并不是连续的空间,此时,申请内存空间就会失败!
②复制算法
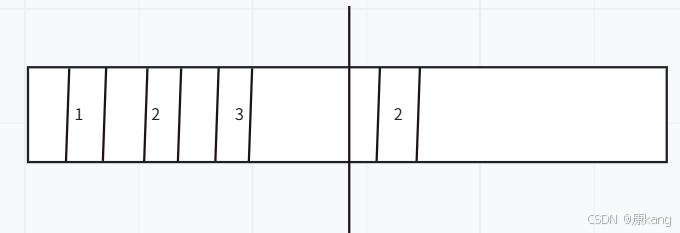
核心为不直接释放内存,而是把不是垃圾的对象,复制到内存的另一半里,接下来把左侧空间整体释放掉。
确实能规避内存碎片问题,但是也有缺点:
1.总的可用内存变少了
2.如果每次要复制的对象比较多,此时复制开销也就很大了。
需要是当前这一轮GC的过程中,大部分对象都被释放了,少数对象存活,这时适合使用复制。
③标记-整理
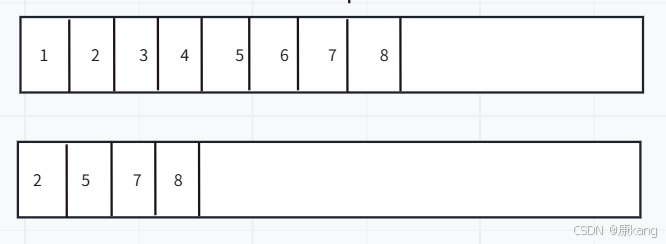
类似于顺序表删除中间元素(搬运)
通过这个过程,也能有效解决内容碎片问题。并且这个过程不像复制算法一样,需要浪费过多的内存空间。但是,这里的搬运内存开销很大
因此JVM没有直接使用上述方案,而是结合上述,使用“综合性”方案。
分代回收
依据不同种类的对象,采取不同的方式。
引入概念:对象的年龄。
JVM中有专门的线程负责周期性扫描/释放。
一个对象,如果被线程扫描了一次,可达了(不是垃圾),年龄+1(初始为0)JVM就会根据对象年龄的差异,把整个堆内存分成两个大的部分。
新生代(年龄小的对象) / 老年代(年龄大的对象)
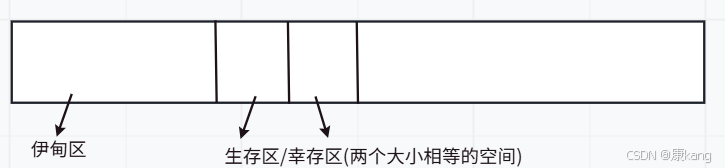
1)当代码中new出一个新对象,这个对象就是被创建在伊甸区的
伊甸区就会有很多的对象。
伊甸区中的对象,大部分都活不过第一轮GC,这些对象都是生命周期非常短。
2)第一轮GC扫描完成后,少数伊甸区中幸存的对象,就会通过复制算法拷贝到生存区
后续GC的扫描线程还会持续进行扫描,不仅要扫描伊甸区,也要扫描生存区的对象。生存区的大部分对象也会在扫描中被标记为垃圾,少数存活的就会继续使用复制算法,拷贝到另一个生存区中。
只要这个对象能够在生存区中继续存活,就会被复制算法继续拷贝到另一个生存区中。每次经历一轮GC的扫描,对象的年龄就会+1。
3)如果这个对象在生存区中,经历了若干轮GC仍然健在。
JVM就会认为,这个对象生命周期大概率很长,就把这个对象从生存区拷贝到老年代。
4)老年代的对象,也要被GC扫描,但扫描频次大大降低了
这些对象的生命周期应该很长,频繁GC扫描意义不大,白白浪费了时间,不如放到老年代,降低扫描频次。
5)对象在老年代,此时JVM就会按照标记整理的方式,释放内存。
上述分代回收是JVM GC中的核心思想,但是JVM实际的垃圾回收的实现细节上,还会存在一些变数和优化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









