







6.拥塞控制
总的原则:流量控制和拥塞控制,谁产生的窗口大小更小,谁说了算。
1.慢启动
刚开始传输的数据,速率是比较小的,采用的拥塞窗口也就比较小,此时,网络的拥堵情况未知,如果一上来就采用很大的拥塞窗口,可能让本就不富裕的网络带宽更难。
2.指数增长
如果上述传输的数据没有出现丢包,说明网络还是畅通的,要增大窗口大小,此时,增大方式就是按照指数来增长(*2)
由于使用慢启动,开始的时候,窗口大小非常小,也有可能网络上很通畅。通过指数增长可以让上述的窗口大小快速变大,就可以保证传输的效率。
3.线性增长
指数增长不会一直持续保持的,可能会增长太快,一下就导致网络拥堵。这里引入了一个“阈值”,当拥塞窗口达到了阈值之后,指数增长就成了线性增长。
线性增长能够使当下的窗口持久的保持在一个比较高的速率,不会一下就丢包。
4.慢启动
线性增长也是一直在增长的,积累一段时间后,传输的速率可能太快了,此时就会引起丢包。一旦丢包,就把拥塞窗口重置为较小的值,回到慢启动。
并且这里会根据刚才丢包时的窗口大小,重新设置指数增长到线性增长的阈值
动态平衡,拥塞窗口始终是在变的(主要是因为中间路径拥堵情况也是在不停的发生变化的)
7.延时应答
也是基于滑动窗口,要尽可能的再提高一点速率。
结合滑动窗口以及流量控制,能够通过延时应答ack的方式,把反馈的窗口大小增大一些(核心在于在允许范围内,让窗口尽可能大)
接收方在收到数据后,不会立即返回ack,而是稍等一下,等一会再返回ack。等这一会,相当于给接收方的应用程序腾出更多的时间来消费这里的数据。
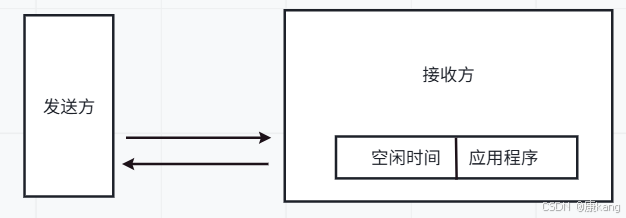
如果立即返回ack,此时接收缓冲区的大小相对较小的(典型场景:发送发不停的发,接收方不停的取)。
如果不是立即返回,若延时100ms,接收方应用程序会再多消费掉一些数据。剩余的空间就更大了,返回的窗口大小就是一个相对更大的值了
通过滑动窗口来传输数据。滑动窗口下,如果ack丢了没啥影响。
延时应答不是单纯的按照时间,而是可以按照“ack丢了”的方式处理。正常每个数据都有ack,此时就可以每隔几个数据再返回一个ack了。(每隔几个数据,能起到延时应答的效果)另外也能减少ack传输的数量,节省开销。
不仅仅和数据的数量,也和时间有关。这个情况如果延时应答达到一定程度了,即使个数没够,也会返回ack了。
8.捎带应答
基于延时应答引入的机制,能够提升传输效率。
修改窗口大小,确实是提升速率的有效途径,
捎带应答走另一条路,尽可能的把能合并的数据包合并起来,提高效率
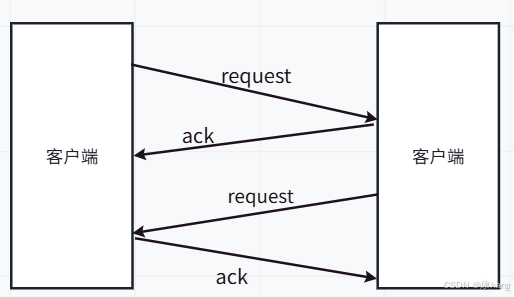
正常情况下,2和3之间有一定的间隔,此时就得分两个包发送了,由于有了延时应答。
服务器收到了请求之后要进行业务逻辑,根据请求计算响应。
有点像四次挥手,这里通信的数据,请求,响应都是带有载荷的,具有一定实际意义的数据。
ack延时的这段时间里,响应数据刚好准备好了,此时就i可以把ack和应答的响应数据合并成一个tcp数据报。
本身ack也不携带载荷,只是把报头中的ack标志位设为1,并且设置确认序号以及窗口大小。(这几个属性本身一个正常的response报文也用不到,不会冲突)
注:很多时候,客户端和服务器之间是长连接的,要进行若干次请求的。
在捎带应答的加持下,后续每次传输请求响应,都可能触发捎带应答(也不一定触发,具体是否触发,取决于代码如何写,取决于下一个数据来的快不快)都可能把接下来要传输的业务数据和上次的ack合二为一。
如果下一个数据来的很快,在延时应答的延时时间内,就可以触发合并,若下个数据来的很慢,就无法触发了。

















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









