






下载hadoop
去Apach下载3.3.4版本
(国外网站,下载速度慢)
安装部署hadoop(node1节点 root身份)
- 将安装包上传到node1节点上
- 解压缩安装包到 /export/server/ 中
指令如下
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server - 构建软连接
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop - 进入hadoop 安装包内
cd hadoop
配置workers文件
进入
cd etc/hadoop
编辑workers
vim workers
如果里面有local删除就可以,如果没有就直接追加
node1
node2
`node3
然后保存就好
配置hadoop使用时候用到的一些环境变量
指令vim hadoop-env.sh
在最上面进行追加 就可以

export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
要进入这个路径下后在进行配置哈
路径为/export/server/hadoop/etc/hadoop
配置我们的core-site.xml文件
输入以下指令进行编辑
vim core-site.xml
在最后插入以下内容即可

然后
编辑文件
在node1执行如下指令
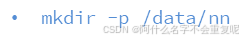

在node2node3执行

然后在node1执行 注意你的Hadoop是什么版本你就修改成什么版本。

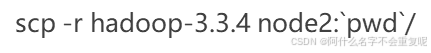
scp -r hadoop-3.3.4 node3:`pwd`/
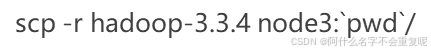
在node2执行
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
在node3执行
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
配置环境变量
执行
vim /etc/profile
在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
在node123均执行以下指令
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
然后在node1格式化namenode
确保以Hadoop用户执行
# 确保以hadoop用户执行
su - hadoop
# 格式化namenode
hadoop namenode -format
启动hdfs
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh
# 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
启动完成后,可以在浏览器打开:
http://node1:9870,即可查看到hdfs文件系统的管理网页

















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









