






 本文介绍了如何使用PaddlePaddle2.5库进行经典MNIST手写数字识别,包括数据预处理、构建CNN模型、训练过程、模型评估以及单个数据测试。作者详细展示了如何使用卷积神经网络结构、优化器和损失函数进行训练和模型性能验证。
本文介绍了如何使用PaddlePaddle2.5库进行经典MNIST手写数字识别,包括数据预处理、构建CNN模型、训练过程、模型评估以及单个数据测试。作者详细展示了如何使用卷积神经网络结构、优化器和损失函数进行训练和模型性能验证。
基于PaddlePaddle 2.5 的手写数字识别
导入模块包
from paddle.vision.datasets import MNIST
# 经典MNIST手写数字数据集
import paddle.nn as nn
# nn里面是神经网络的基本构建 与torch.nn差不多
import paddle.nn.functional as F
# functional 里面放的是纯函数
import paddle
import paddle.optimizer
# 梯度优化器的模块包
import random
# 随机模块
import matplotlib.pyplot as plt
# 画图模块用于检查数据
import numpy as np
# 数组
from sklearn.model_selection import train_test_split
# 数据集分割数据处理
def check_img(img, label):
# 用于查看图片 是否对应标签
print(label)
plt.imshow(img, cmap = 'gray')
plt.axis('off') # 关闭坐标轴
plt.show()
print(img)
dataset = MNIST()
# 导入数据集
img = []
# 图片数据
label = []
# 图片标签
for i in dataset:
img.append(np.array(i[0]))
# 把图片从PIL格式转为np
label.append(i[1])
# 读取数据
img = np.array(img, dtype = 'float32')
# 图片数据统一格式为 np.float32
label = np.array(label, dtype = 'int64')
# 标签数据统一格式为 np.int64 为后面的交叉熵Loss做准备
img = img/255
# 对数据进行归一化
x_train, x_test, y_train, y_test = train_test_split(img, label, test_size = 0.2, random_state=40)
# 进行训练集,测试集的划分
check_img(x_train[0], y_train[0])
# 检查数据构建网络模型
# 定义CNN数据识别网络结构
class CNN(nn.Layer):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2D(1, 20, kernel_size=5, stride=1, padding = 2)
self.maxpool1 = nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = nn.Conv2D(20, 20, kernel_size=5, stride=1, padding = 2)
self.maxpool2 = nn.MaxPool2D(kernel_size=2, stride=2)
self.fc = nn.Linear(in_features=980, out_features=10)
# 定义网络结构的前向计算过程
def forward(self, inputs, label):
x = self.conv1(inputs)
x = F.relu(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.maxpool2(x)
# print(x.shape)
# 检查x的shape 确保可以跟全连接层的输入层维度对应的上
# [batch, 20, 7, 7] 因为20*7*7 = 980 所以是正确的
x = paddle.reshape(x, [x.shape[0], 980])
x = self.fc(x)
if not self.training:
x = F.softmax(x)
# 如果在训练阶段使用这个模型,我们通常不希望应用 softmax,
# 因为 softmax 会使得梯度在所有类别中平均分配,这可能会导致训练缓慢。
# 所以在训练阶段,通常不会对最后一层的输出应用 softmax。
if label is not None:
acc = paddle.metric.accuracy(input=x, label=label)
return x, acc
else:
return x模型训练
def data_batch(xs, ys, batch):
# 定义batch函数
x_list = []
y_list = []
index_list = list(range(len(xs)))
random.shuffle(index_list)
for i in index_list:
x = np.array(xs[i], dtype='float32').reshape(1, 28, 28)
y = np.array(ys[i], dtype='int64')
x_list.append(x)
y_list.append(y)
if len(x_list) == batch:
yield np.array(x_list), np.array(y_list)
x_list = []
y_list = []
# 如果数据量达到了一批次的量 那么就返回该批次
# 并清除list的数据 为下一次批次做准备
if len(x_list) > 0:
yield np.array(x_list), np.array(y_list)
# 如果到了最后 还有剩余的量 不足以形成一个批次 就直接返回
def train(net, x_train, y_train, epoch = 1, batch = 100):
# 模型训练函数
# x_train:训练数据
# y_train:训练标签
# net: 网络模型
# epoch: 训练轮次
# batch: 批次量
net.train()
# 模型转为训练模式
opt = paddle.optimizer.Adam(learning_rate=0.01, parameters=net.parameters())
#定义Adam梯度优化器
for i in range(epoch):
for batch_id, data in enumerate(data_batch(x_train, y_train, batch)):
x, y = data
# print(x.shape, y.shape)
# (10, 1, 28, 28) (10, 1)
images = paddle.to_tensor(x)
labels = paddle.to_tensor(y)
# 转换成tensor 也就是张量
predicts, acc = net(images, labels)
# 向前传播
loss = F.cross_entropy(predicts, labels)
# 计算损失
avg_loss = paddle.mean(loss)
# 计算一批次损失的均值
if batch_id % 10 == 0:
print(avg_loss.numpy(), acc.numpy())
# 每十个就输出一次loss 和 训练集ac
avg_loss.backward()
# 反向传播
opt.step()
# 更新参数
opt.clear_grad()
# 清除梯度
paddle.save(net.state_dict(), 'mnist.pdparams')
# 保存模型
net = CNN()
# 初始化网络
train(net, x_train, y_train, 1, 100)
# 训练网络保存模型
模型评估
def evaluation(model, x_test, y_test):
# 模型评估
# model:网络模型
# x_test:测试数据
# y_test:测试标签
print('start evaluation .......')
# 定义预测过程
params_file_path = 'mnist.pdparams'
# 加载模型参数
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
model.eval()
# 启用模型评估模式
acc_set = []
# 放置正确率
avg_loss_set = []
# 放置Loss
for batch_id, data in enumerate(data_batch(x_test,y_test, 100)):
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
predicts, acc = model(images, labels)
loss = F.cross_entropy(input=predicts, label=labels)
avg_loss = paddle.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
#计算多个batch的平均损失和准确率
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean()
print('loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean))
net = CNN()
# 重新定义网络结构 等价于 把网络参数清零了
evaluation(net, x_test, y_test)
# 网络评估单个数据测试
def pre_one(model, data):
# 定义预测过程
params_file_path = 'mnist.pdparams'
# 加载模型参数
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
data = paddle.to_tensor(data.reshape(1,1,28,28))
# 数据格式转换
model.eval()
p = model(data, None)
result = list(p.numpy()[0])
# 保存softmax的结果
print('识别的数字是:',result.index(max(result)))
# 输出概率最大的数字
index = int(random.random()*50)
# 随机产生index 等价于从数据集里面随机挑选一个数字
data_one = img[index]
check_img(data_one, label[index])
# 查看这个数字是多少
pre_one(CNN(), data_one)
# 用训练好的网络 识别我们的数字 得出识别结果运行效果图:
模型训练:
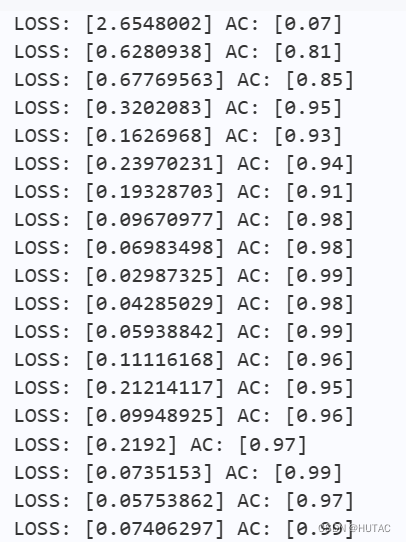
模型评估:

单个数据测试:
随机产生数字:

总结:
这是一次基础的深度学习实例。本次实例需要注意的细节有:
- 全连接层与卷积层的连接时,数据的shape和全连接层的输入节点的个数要对应的上;
- 使用cross-entropy作为损失函数时,标签数据的数据类型应该为int64;
- 模型训练时,输入数据的格式为[batch, c, h, w],batch为批次量,c为通道数,h为图像的高,w为图像的宽;
补充:
常见梯度优化器:SGD,Adam(动态学习率加惯性),Adagrad(动态学习率),Momentum(惯性)


















 1675
1675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











