









一、引言
宋词是我们中国古代文学的瑰宝,具有独特的艺术魅力。通过自然语言处理技术实现宋词的自动生成,不仅可以为文学创作提供新的思路和方法,还能帮助人们更好地理解和传承宋词文化。
本系统基于 2-gram 模型,设计并实现了一个具有文学创作能力的宋词智能生成系统。该系统融合了规则约束与统计语言模型,采用Python技术架构开发,实现了多词牌自动生成、历史回溯、语义解释等核心功能。本文将深入剖析系统的技术原理与实现细节。
本项目所有源代码以及相关语料均已打包上传,有需要的小伙伴可以点击:

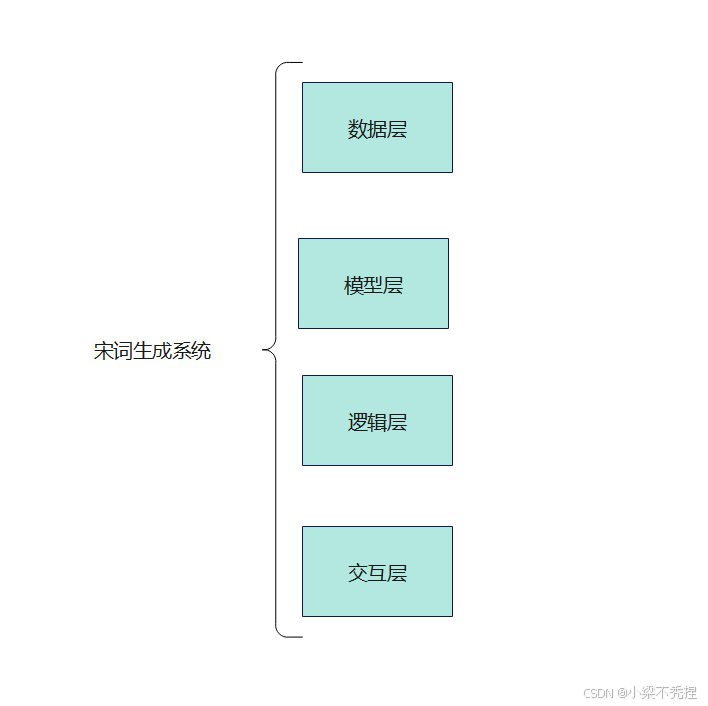
二、系统架构
本系统采用分层架构设计,由数据层、模型层、逻辑层和交互层四部分组成:
-
数据层:包含宋词语料库(processed_ci.txt)、单双字词典(result_single/double.txt)及解释词库(dictionary.json)
-
模型层:基于2-gram语言模型构建概率转移矩阵
-
逻辑层:实现词牌规则引擎、生成算法、历史管理模块
-
交互层:TKinter图形界面及功能控制器
三、模型原理
1 规则模型:
系统内置五大词牌模板,以浣溪沙为例,规则编码:[2,2,1,2,',\n',...]表示:
-
数字代表词语长度(1-单字,2-双字)
-
标点符号控制句式结构
-
'\n'实现换行分段
self.rules = {
'浣溪沙': [2, 2, 1, 2, ',\n', 2, 2, 1, 2, '。\n', 2, 2, 2, 1, '。\n', 2, 2, 1, 2, ',\n', 2, 2, 1, 2, '。\n', 2,
2, 1, 2, '。\n'],
'酒泉子': [2, 2, ',', 2, 2, 1, 2, '。\n', 2, 2, 1, 2, '。\n', 2, 1, 2, '。\n',
2, 2, 2, 1, '。\n', 2, 2, 1, 2, '。\n', 2, 2, 2, 1, '。\n', 2, 1, 2, '。\n'],
'天净沙': [2, 2, 2, ',', 2, 2, 2, ',', 2, 2, 2, '。\n', 2, 2, ',', 2, 1, 1, 2, '。\n'],
'渔家傲': [2, 2, 2, 1, ',', 2, 2, 1, 2, '。\n', 2, 2, 2, 1, ',', 2, 1, ',', 2, 2, 2, 1, '。\n',
2, 2, 1, 2, ',', 2, 2, 1, 2, '。\n', 2, 2, 1, 2, ',', 1, 2, ',', 2, 2, 2, 1, '。\n'],
'苏幕遮': [1, 2, ',', 2, 1, ',', 2, 2, ',', 2, 2, 1, '。', 1, 1, 2, 1, 1, 1, ',', 2, 2, ',', 1, 1, 2, 1,
'。\n',
1, 2, ',', 1, 2, ',', 2, 2, ',', 2, 2, 1, '。', 2, 2, 1, 2, ',', 1, 1, 2, ',', 2, 2, 1, '。\n']
}在生成宋词时,SongCi_maker函数根据这些规则来确定每个位置应该生成单字还是双字,以及何时插入标点符号。
2 2-gram概率模型:
设文本序列为,则N-gram概率可表示为:
采用最大似然估计(MLE)进行参数学习:
Unigram(1-gram):
(T为总次数,C(•)是计数函数,表示某个n-gram在语料库中出现的次数,下同)
Bigram(2-gram):
P_2_gram函数用于构建2-gram概率模型。这个函数可计算给定一个字(或词)后,下一个字(或词)出现的概率。
def _build_2gram_model(self):
"""构建2-gram语言模型"""
try:
with open('D:\\桌面\\code\\exp1\\processed_ci.txt', 'r', encoding='UTF-8') as f:
text = f.read()
# 构建转移概率矩阵
self._build_transition_matrices(text)
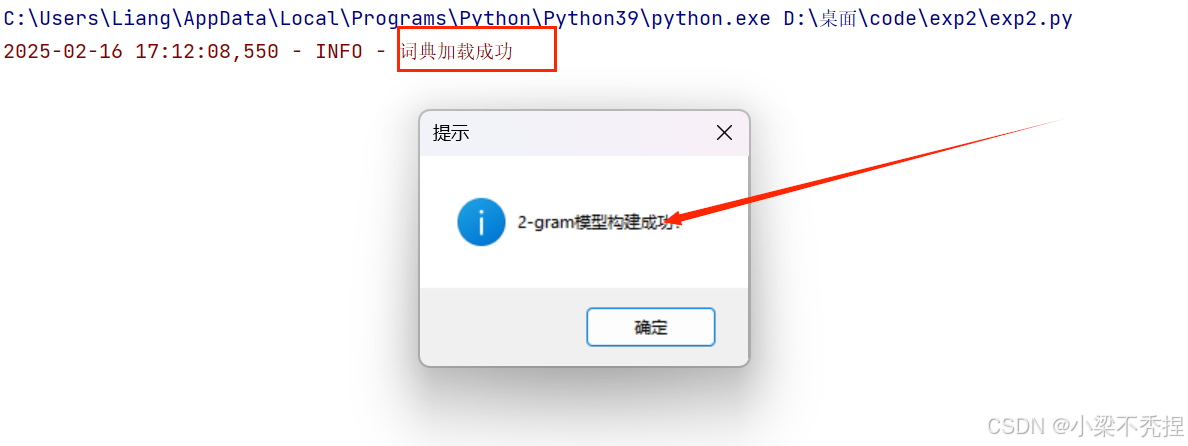
messagebox.showinfo('提示', '2-gram模型构建成功!')
logger.info("2-gram模型构建成功")
except Exception as e:
logger.error(f"构建2-gram模型失败: {str(e)}")
messagebox.showerror('错误', f'构建模型失败: {str(e)}')
该函数分别计算了以下四种2-gram概率:
单字到单字的概率(P_single_single)。
单字到双字的概率(P_single_double)。
双字到单字的概率(P_double_single)。
双字到双字的概率(P_double_double)。
这些概率是通过统计语料库中相邻字(或词)的出现次数,并除以前一个字(或词)的出现次数来计算的。
3 动态生成算法
采用马尔可夫决策过程实现词语选择:
a) 初始化:根据词牌首项随机选择词语
b) 迭代生成:
i. 读取当前规则项类型(字长/标点)
ii. 若为字长项,查询转移矩阵选择最高概率词
iii. 若无匹配记录,启用蒙特卡洛随机采样
iv. 添加标点控制格式
c) 回溯机制:当连续3次选择低概率词(<0.1)时,回退两步重新生成
4 条件概率选择:
在SongCi_maker函数中,对于每个需要生成的位置,代码根据前一个字(或词)的条件概率来选择下一个字(或词)。具体来说,它使用max函数和key参数来选择具有最高概率的字(或词)。
4.随机选择:
当根据规则模型和概率模型无法确定下一个字(或词)时,将随机选择一个字(或词)来插入。通过get_random函数实现,从预先统计好的单字和双字频率文件中随机选择一个字(或词)。
5.字典数据结构:
代码使用字典来存储字(或词)及其频率,以及2-gram概率。这种数据结构允许快速查找和更新字(或词)的概率信息。
四、关键技术实现
1 语言模型构建
采用n-gram语言模型中的2-gram方法,通过统计语料中相邻词语的共现概率建立转移矩阵:
单字转移矩阵P_single_single:记录单字词→单字词的概率分布
跨级转移矩阵P_single_double:处理单字词→双字词的转移概率
逆向转移矩阵P_double_single:计算双字词→单字词的转移关系
双字延续矩阵P_double_double:保持双字词间的语义连贯性
def _build_2gram_model(self):
"""构建2-gram语言模型"""
try:
with open('D:\\桌面\\code\\exp1\\processed_ci.txt', 'r', encoding='UTF-8') as f:
text = f.read()
# 构建转移概率矩阵
self._build_transition_matrices(text)
messagebox.showinfo('提示', '2-gram模型构建成功!')
logger.info("2-gram模型构建成功")
except Exception as e:
logger.error(f"构建2-gram模型失败: {str(e)}")
messagebox.showerror('错误', f'构建模型失败: {str(e)}')2 转移概率矩阵构建
根据词典,系统构建了转移概率矩阵。矩阵中的每个元素表示一个词语后面出现另一个词语的概率。例如,对于单字词A和单字词B,矩阵中的元素P(A|B)表示在宋词中,B后面出现A的概率。
def _build_transition_matrices(self, text: str):
"""构建转移概率矩阵"""
# [单字词][单字词]的转移概率
for i in range(len(text) - 1):
if text[i] not in self.punctuation_list and text[i + 1] not in self.punctuation_list:
if text[i] not in self.P_single_single:
self.P_single_single[text[i]] = {}
if text[i + 1] not in self.P_single_single[text[i]]:
self.P_single_single[text[i]][text[i + 1]] = 0
self.P_single_single[text[i]][text[i + 1]] += 1
3 宋词生成算法
系统根据2-gram模型和转移概率矩阵,采用贪心策略生成宋词。具体步骤如下:
(1)随机选择一个词语作为宋词的开头;
(2)根据当前词语和转移概率矩阵,预测下一个词语;
(3)将预测到的词语添加到宋词中,重复步骤2,直至生成完整的宋词。
def generate_songci(self, name: str):
"""生成宋词"""
try:
self.production = f' {name}\n'
# 随机生成第一个词
first_word_length = self.rules[name][0]
self.production += self._get_random_word(first_word_length)
# 生成后续词
for i in range(1, len(self.rules[name])):
if isinstance(self.rules[name][i], int): # 如果是数字(1或2)
if self.rules[name][i] == 1: # 单字词
if self.rules[name][i - 1] == 1: # 前面是单字词
try:
# 获取最可能跟在当前单字后面的单字
next_word = max(self.P_single_single[self.production[-1]],
key=lambda x: self.P_single_single[self.production[-1]][x])
self.production += next_word
except:
# 如果没有找到合适的转移概率,随机选择
self.production += self._get_random_word(1)
elif self.rules[name][i - 1] == 2: # 前面是双字词
try:
# 获取最可能跟在当前双字词后面的单字
next_word = max(self.P_double_single[self.production[-2:]],
key=lambda x: self.P_double_single[self.production[-2:]][x])
self.production += next_word
except:
self.production += self._get_random_word(1)
else: # 前面是标点
self.production += self._get_random_word(1)
elif self.rules[name][i] == 2: # 双字词
if self.rules[name][i - 1] == 1: # 前面是单字词
try:
# 获取最可能跟在当前单字后面的双字词
next_word = max(self.P_single_double[self.production[-1]],
key=lambda x: self.P_single_double[self.production[-1]][x])
self.production += next_word
except:
self.production += self._get_random_word(2)
elif self.rules[name][i - 1] == 2: # 前面是双字词
try:
# 获取最可能跟在当前双字词后面的双字词
next_word = max(self.P_double_double[self.production[-2:]],
key=lambda x: self.P_double_double[self.production[-2:]][x])
self.production += next_word
except:
self.production += self._get_random_word(2)
else: # 前面是标点
self.production += self._get_random_word(2)
else: # 如果是标点符号
self.production += self.rules[name][i]
# 添加到历史记录
history_entry = {
'timestamp': datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
'style': name,
'content': self.production
}
self.history.append(history_entry)
self._save_history()
# 显示生成的宋词
self.text_output.delete('1.0', tk.END) # 清空文本框
self.text_output.insert(tk.END, self.production)
except Exception as e:
logger.error(f"生成宋词失败: {str(e)}")
messagebox.showerror('错误', f'生成失败: {str(e)}')五、系统展示与分析
1 加载词典
2 系统主页面

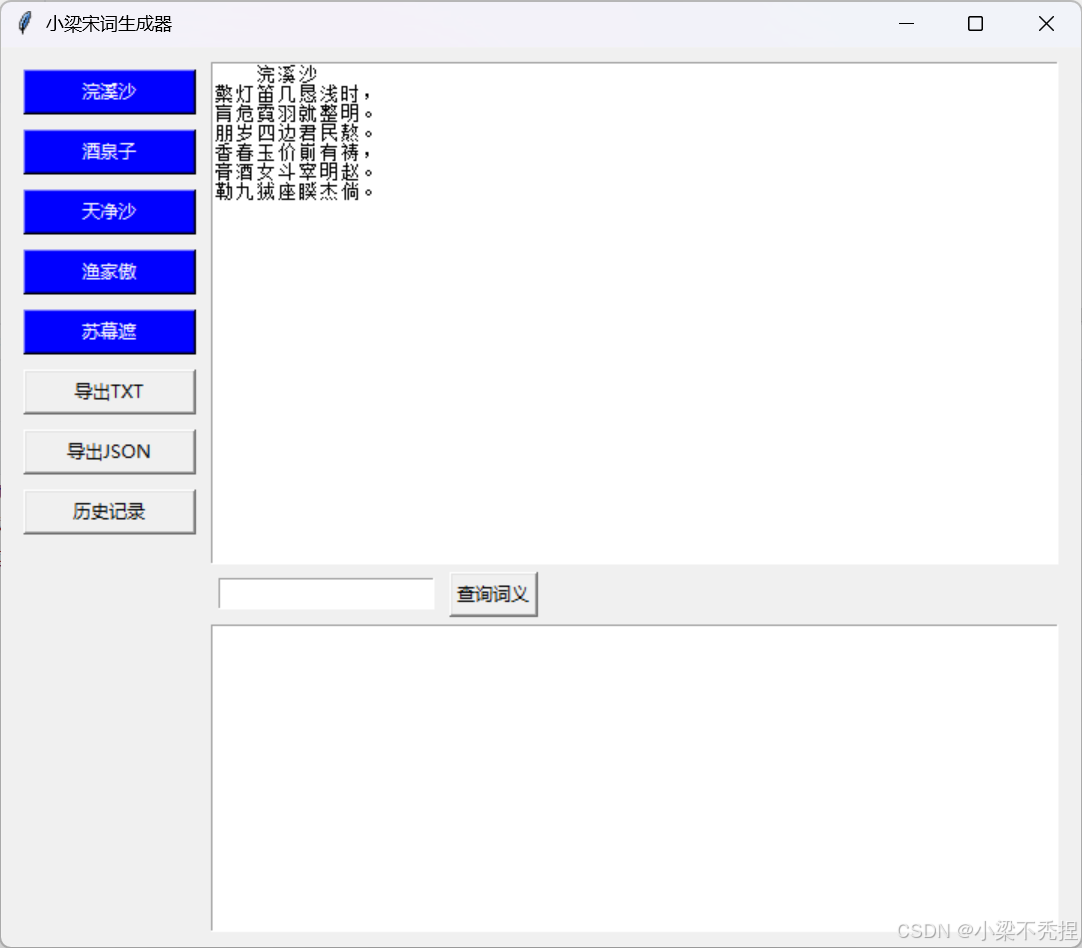
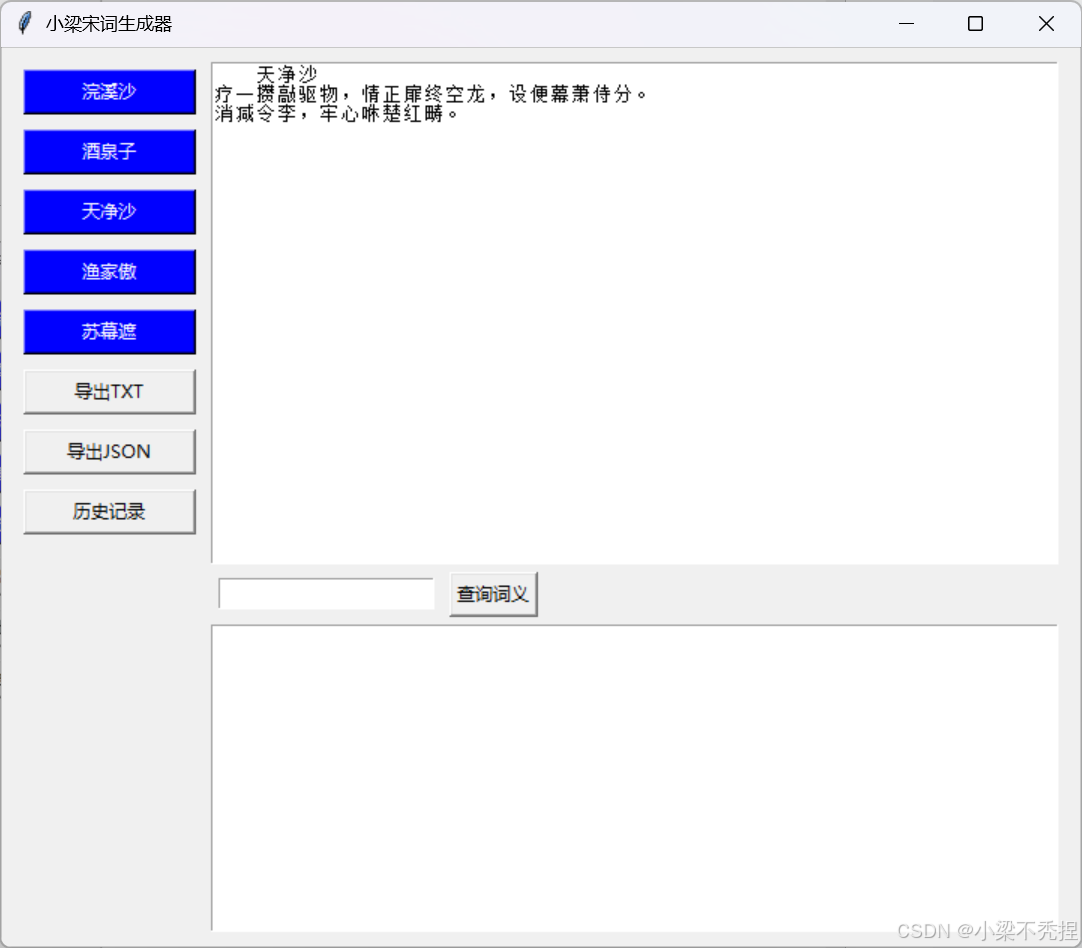
3 生成宋词



4 宋词导出功能

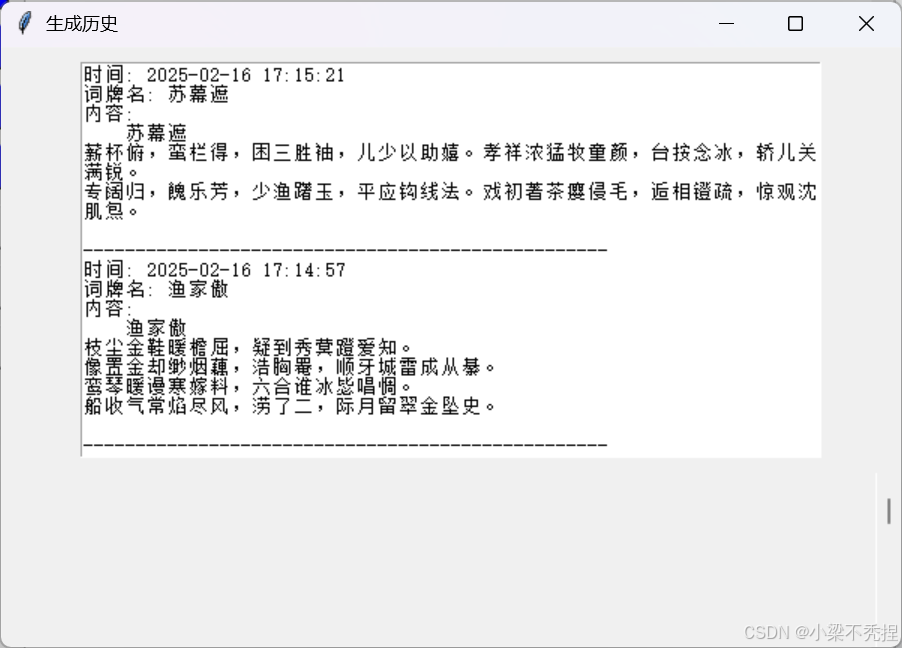
5 查询历史记录
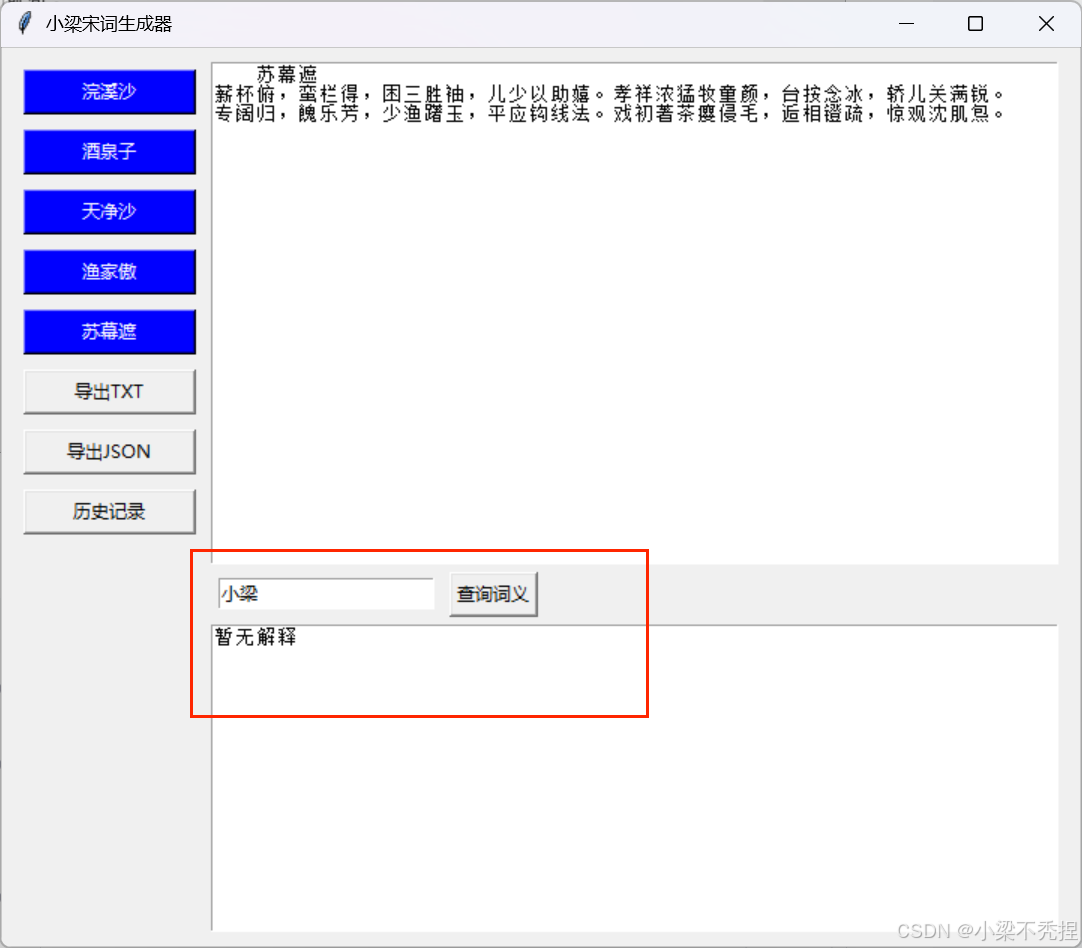
6 查询词义功能
六、结语
本系统通过 2-gram 语言模型和预设的词牌规则,实现了宋词的自动生成。同时,提供了图形界面,方便用户进行交互操作。然而,由于 2-gram 模型的局限性,生成的宋词可能存在语义连贯性不足的问题。未来可以考虑使用更复杂的语言模型,如神经网络模型,以提高生成结果的质量。同时可以增加系统功能,比如加入宋词评分功能。


















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











