







VIT 原理
概念
VIT 是 Vision Transformer 的缩写。Vision Transformer 是一种基于 Transformer 架构的计算机视觉模型,最初由谷歌研究团队在 2020 年提出。它将 Transformer 架构(原本用于自然语言处理任务)应用于图像分类任务,取得了显著的效果。
Transformer很强,但视觉任务中的应用还有限。ViT尝试将纯Transformer结构引入到CV的基本任务--图像分类中。
自 VIT 被提出以来,已经有许多改进和变种出现,如 Swin Transformer、DeiT 等。这些模型在更广泛的视觉任务中(如目标检测、图像分割等)展示了强大的性能。
Vision Transformer 的引入标志着计算机视觉领域从传统的 CNN 向基于 Transformer 的新架构的一个重要转变。
研究背景
Transformer很强,但视觉任务中的应用还有限
Transformer提出后在NLP领域中取得了极好的效果,其全Attention的结构,不仅增强了特征提取能力,还保持了并行计算的特点,可以又快又好的完成NLP领域内几乎所有任务,极大地推动自然语言处理的发展。
但在其在计算机视觉领域的应用还非常有限。在此之前只有目标检测(0bject detection)中的DETR大规模使用了Transformer,其他领域很少,而纯Transformer结构的网络则是没有。
Transformer的优势:
- 并行计算
- 全局视野
- 灵活的堆叠能力
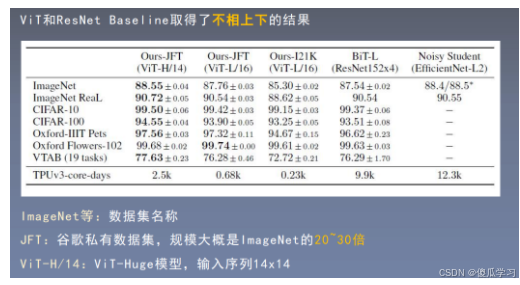
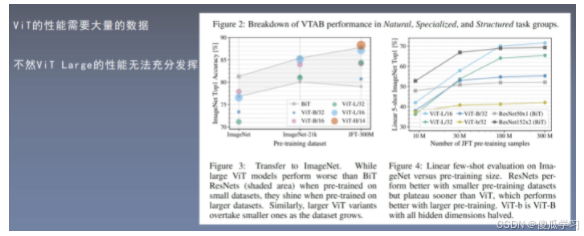
VIT的性能分析
ViT的历史意义
-
展示了在计算机视觉中使用纯Transformer结构的可能
-
拉开了新一轮Transformer研究热潮的序幕
VIT 模型结构图
我们将图像分割为固定大小的块,对每个块进行线性嵌入,添加位置编码,然后将生成的向量序列输入到标准Transformer编码器中。为了进行分类,我们使用了标准方法,即在序列中添加一个额外的可学习“分类标记”。
ViT结构的数据流
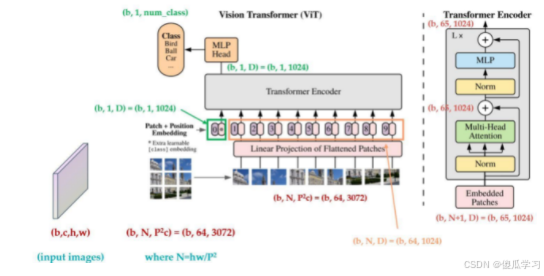
(b,c,h,w)
- b 代表batch size 批次大小
- c 代表通道数,彩色图片中c=3,就是三个通道rgb
- h w 分别代表图像的高和宽
(b,N,(P^2)c)
- b 代表batch size 批次大小(不更改)
- N 代表图像切分的块数patch(根据情况自定义宽高分成多少块N)
- P 代表切分后的图像大小 (P^2)c 是 32x32x3(宽高分别除以块数N,得到分割后的每一个图像块的宽高32x32,在将每个图像块的c通道的所有像素点平铺,最终是将宽高像素合并形成一维数据)
(b,65,1024)
3027考虑到维度太大,通过fc进行特征的降为,并将其降维维1024,所以通过fc后的每个图像块的形状为(b,64,1024),最后在加上一个哨兵(patch 0),最终输入encoder编码器中的维度为(b,65,1024)
Linear
在VIT(Vision Transformer)的模型结构中,"Linear Projection of Flattened Patches" 指的是将图像分割成小块(称为patches),然后对这些patches进行展平(flatten),最后通过线性投影(linear projection)将展平后的向量映射到一个更低维度的空间。作用在于将图像中的局部信息提取出来,并将其转换为可以输入到Transformer模型中的形式。
- 特征提取和编码:通过将图像分成小块并展平,可以有效地捕获图像的局部特征。这些特征通常包含有关颜色、纹理和形状等信息,对于理解图像内容至关重要。
- 减少输入维度:传统的图像数据非常大,直接输入到Transformer模型中会导致计算和内存消耗过大。将patches展平并通过线性投影映射到更低维度的向量,可以有效减少输入的维度,同时保留重要的特征信息。
- 提升模型性能:通过提取和编码局部特征,模型能够更好地理解图像的结构和内容,从而在进行后续的Transformer处理(如自注意力机制)时,提升模型在图像理解和处理任务上的性能。
经过FC之后的结果是(b,64,1024)然后输入到transformer的encoder中,再经过MLP Head 用额外的块patch 0 输出最终的分类(b,1,class_num)
patch 0
在Vision Transformer(VIT)中,需要额外输入一个小块(patch 0)通常是为了确保模型能够处理整个图像的信息。这种做法可以获得全局的信息:尽管Transformer模型以自注意力机制为核心,可以在不同位置之间建立关联,但在某些情况下,特别是对于涉及全局上下文的任务(如图像分类),引入额外的全局信息有助于模型更好地理解整个图像。
VIT 代码
前期准备
Source code
不是官方的repo,简化版本的,官方的跑不动时间太长,而且官方的是基于tensorflow框架
通过程序入口定位核心代码
下载vit-pytorch库查看源代码&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









