






 本文详细介绍了Python中的pandas库在数据分析中的应用,包括读入数据、数据格式转换、排序功能(如降序排列),以及基本统计分析(如describe、异常值处理、聚合函数等)。此外,还讲解了数据透视表pivot_table的使用方法,展示其在汇总和分析数据的强大能力。
本文详细介绍了Python中的pandas库在数据分析中的应用,包括读入数据、数据格式转换、排序功能(如降序排列),以及基本统计分析(如describe、异常值处理、聚合函数等)。此外,还讲解了数据透视表pivot_table的使用方法,展示其在汇总和分析数据的强大能力。
Python数据分析之pandas-2
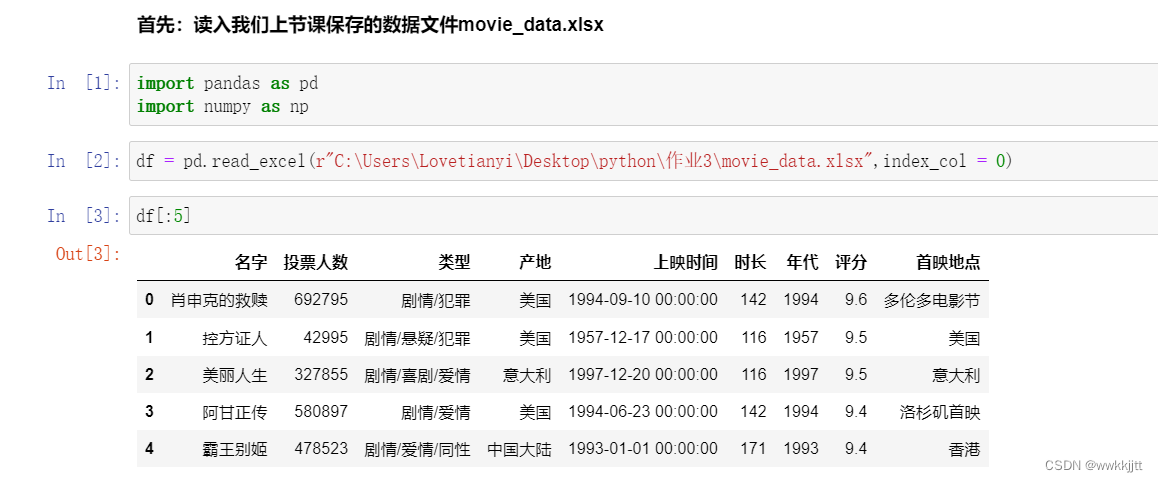
读入数据
数据格式转换
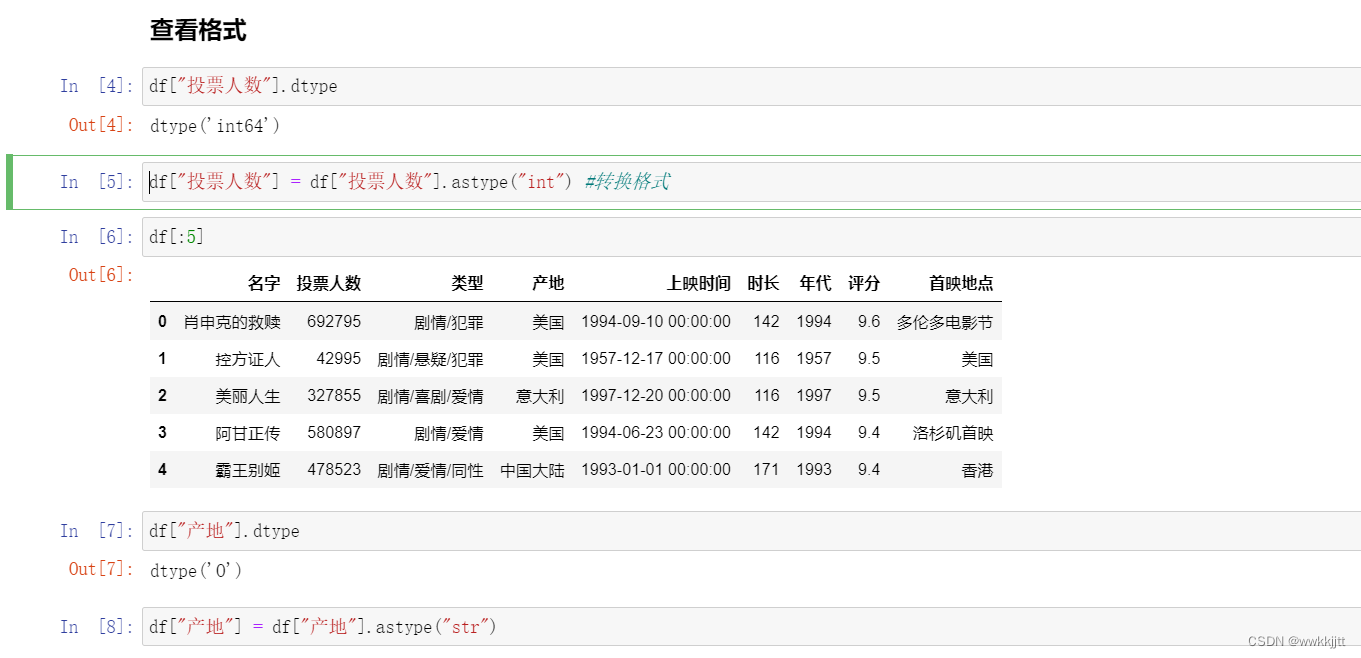
- 在做数据分析的时候,原始数据往往会因为各种各样的原因产生各种数据格式的问题。
- 数据格式是我们非常需要注意的一点,数据格式错误往往会造成很严重的后果。
- 并且,很多异常值也是我们经过格式转换后才会发现,对我们规整数据,清洗数据有着重要的作用。
- 查看格式:使用dtype函数查看,使用astype函数实现格式转换。
排序
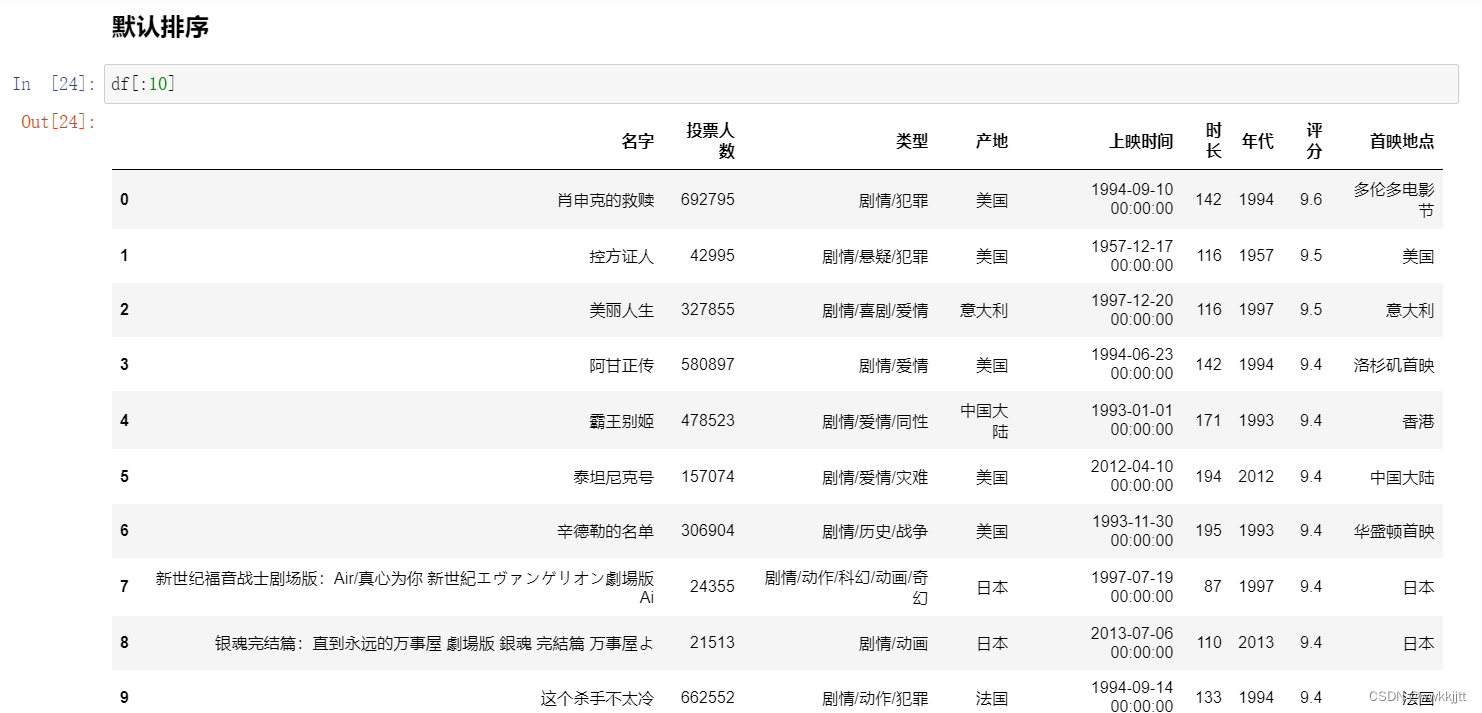
- 默认排序
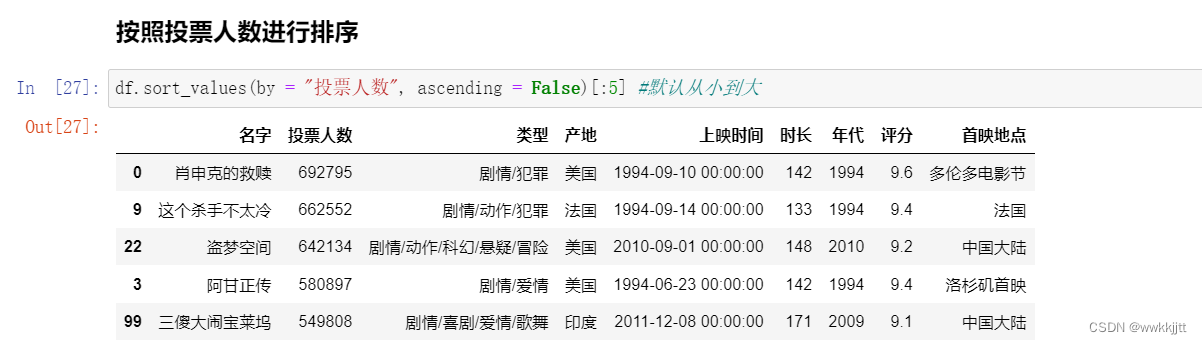
- 使用sort_values函数,参数by用于确定根据什么进行排序,参数ascending确定排序的方式。ascending默认值为True,表示从小到大排序;这里设置为False,表示从大到小排序。
基本统计分析
- describe函数,可以对二维数组中的数值型数据进行描述性统计。
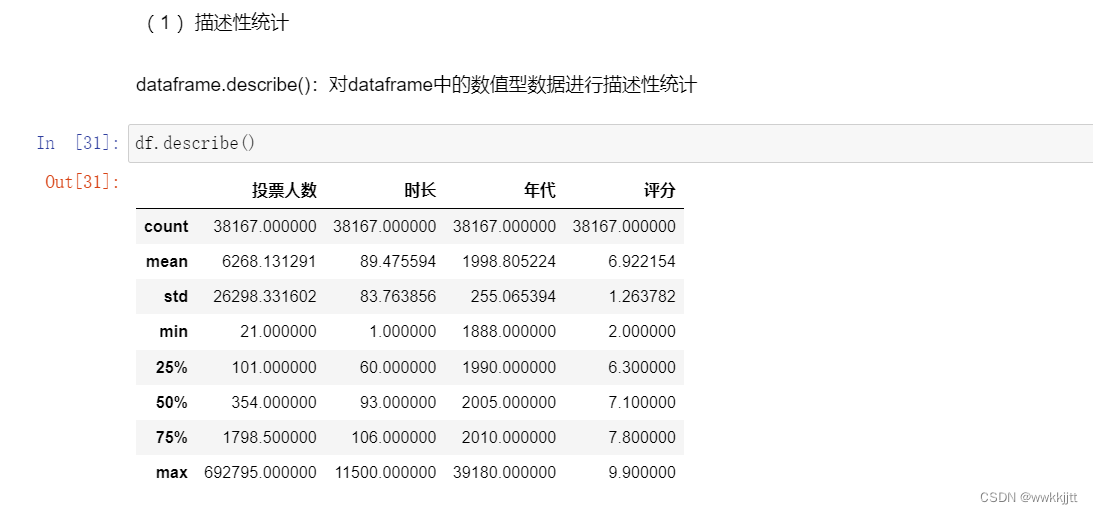
- 通过描述性统计,可以发现一些异常值,很多异常值往往是需要我们逐步去发现的。
- 刚才的描述性统计中显示,年代最大值有39180,这显然是不合理的。

- 使用drop函数删除异常值,并将索引(index)重新更改为连续的。

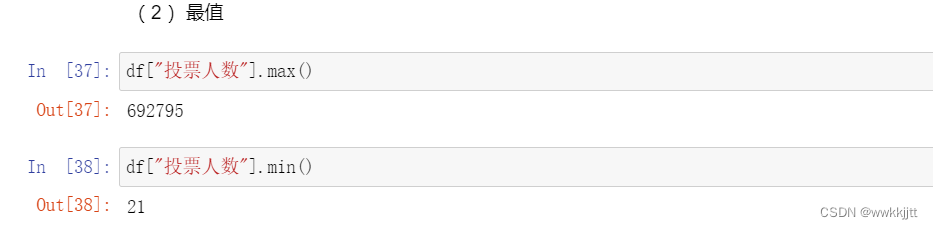
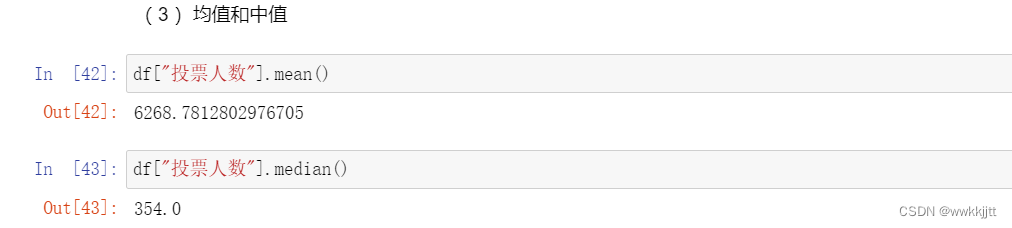
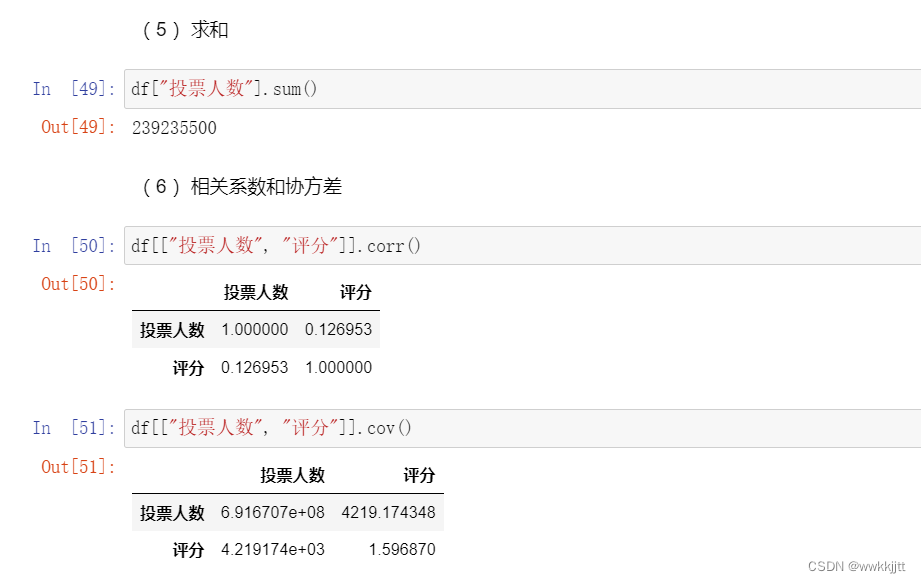
- 最值:max(),min() ;均值:mean() ;中值:median() ;方差:var() ;标准差:std() ;求和:sum() ;相关系数:corr() ;协方差:cov() ;统计每个值的唯一出现:unique() 。


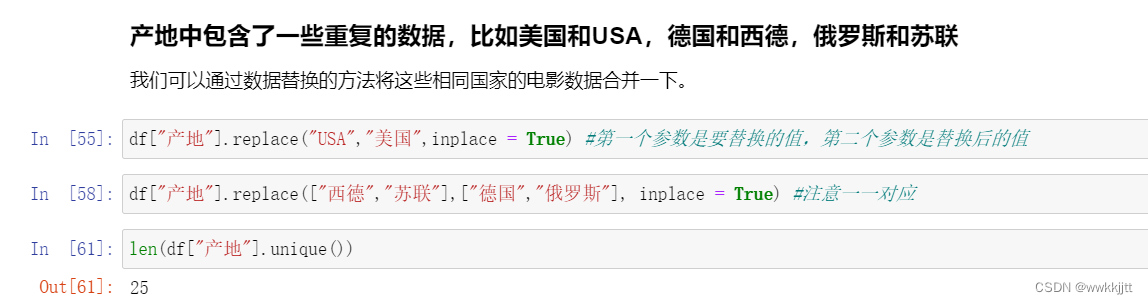
- 替换重复值,使用replace函数。
- 使用value_counts计算值的数量。

数据透视
-
Excel中数据透视表的使用非常广泛,其实Pandas也提供了一个类似的功能,名为pivot_table。
-
pivot_table非常有用,我们将重点解释pandas中的函数pivot_table。
-
使用pandas中的pivot_table的一个挑战是,你需要确保你理解你的数据,并清楚地知道你想通过透视表解决什么问题。虽然pivot_table看起来只是一个简单的函数,但是它能够快速地对数据进行强大的分析。
-
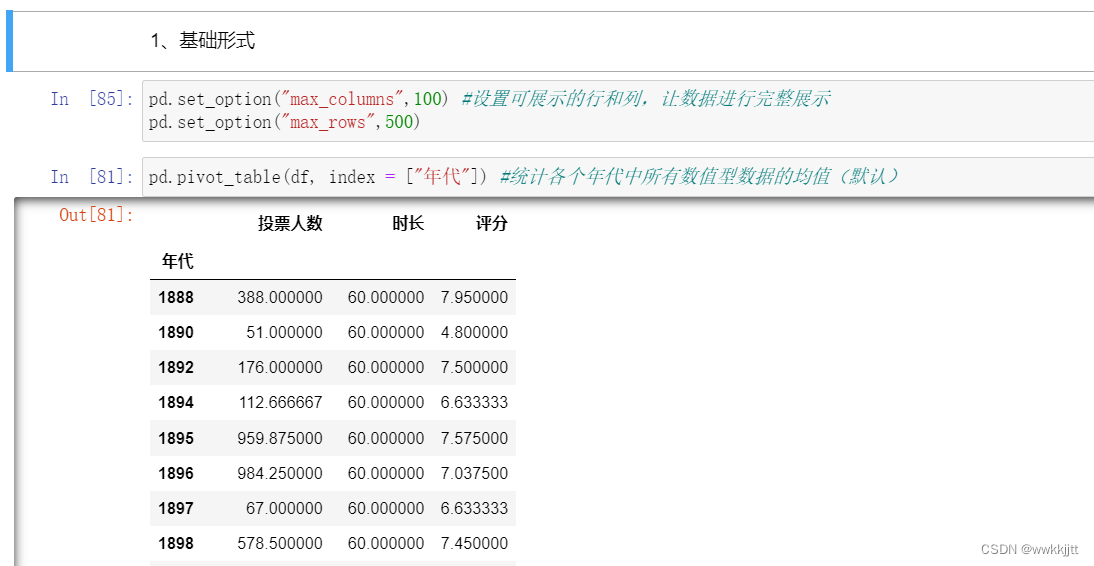
使用pivot_table函数,统计各个年代中所有数值型数据的均值(默认)。set_option用于指定显示最大的行数或列数,以便数据完整地显示。
-
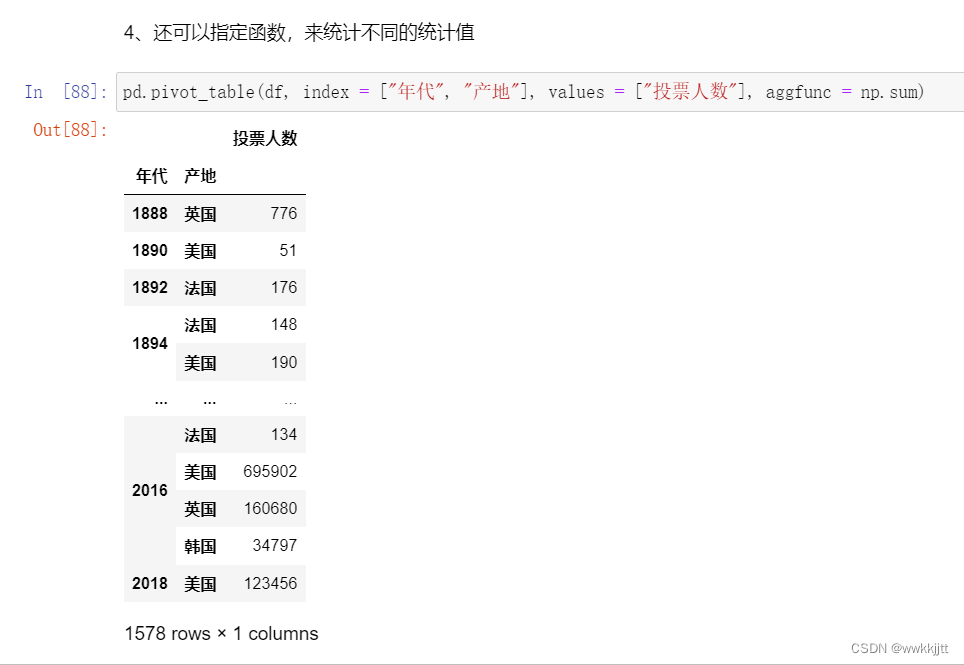
pivot_table中的values参数用于选定需要统计的数据;aggfunc参数用于指定用什么方式对数据进行统计(这里使用sum对投票人数求和)。
-
使用fill_value将非数值(NaN)设置成0。

-
margins参数用于显示最后的总和数据。


-
将刚才进行数据透视操作的数据赋给变量table,发现table的数据类型也是DataFrame二维数组,可以对其进行二维数组的一般操作。

以上就是本文的全部内容,感谢各位的阅读与支持!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









