







确定性推理
原文地址链接: https://kashima19960.github.io/2024/07/17/人工智能/3.确定性推理,一般有最新的修改都是在我的个人博客里面,所以在当前平台的更新会比较慢,请见谅😃
概述
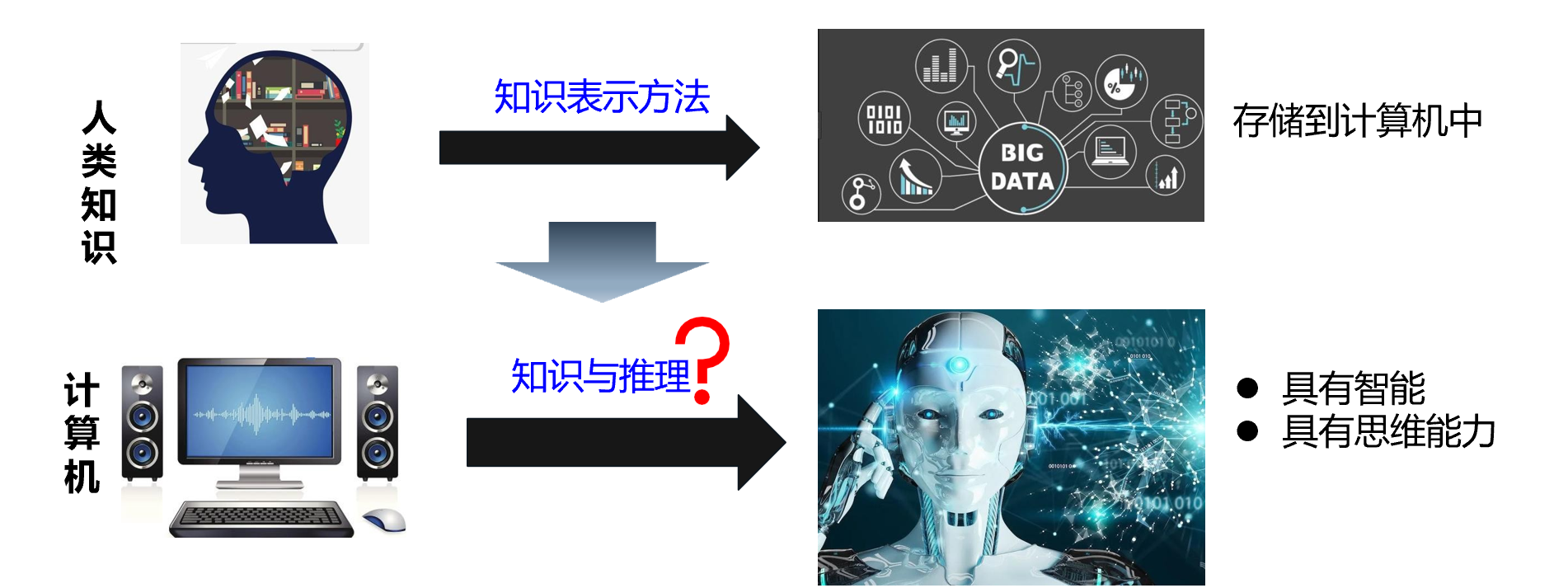
上一章:讨论了“知识与知识表示”,可以把知识用某种模式表示出来存储到计算机中,但为使计算机具有智能,还必须使它具有思维能力。
本章:1)推理是求解问题的一种重要方法。因此,推理方法成为人工智能的一个重要研究课题。2)目前已提出多种可在计算机上实现自动推理的方法。
基本概念 - 定义、要素
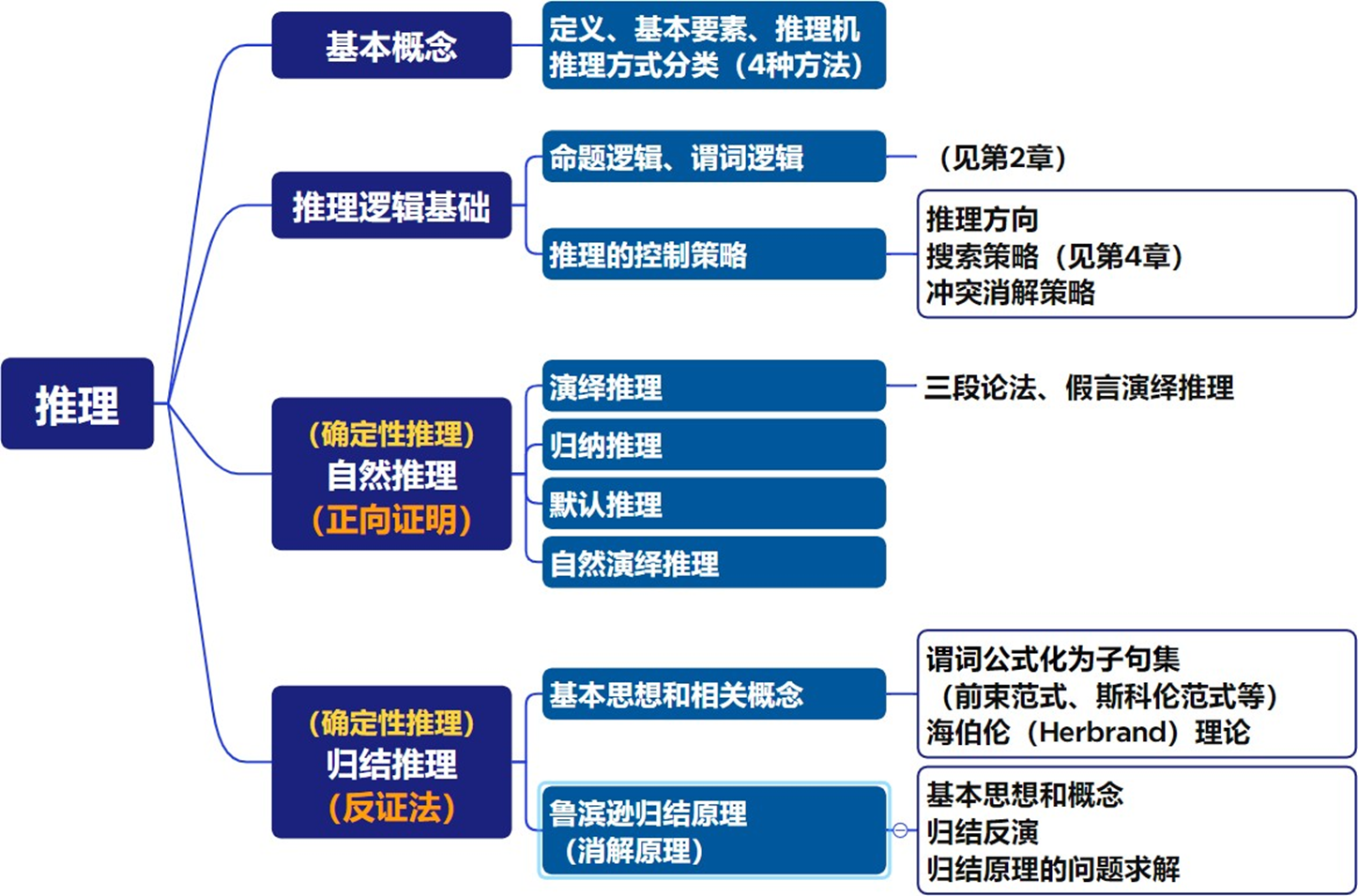
推理:从初始证据(已知事实)出发,按某种策略或规则,不断运用知识库中的已知知识,逐步推出结论的过程,或者归纳出新事实的思维过程。
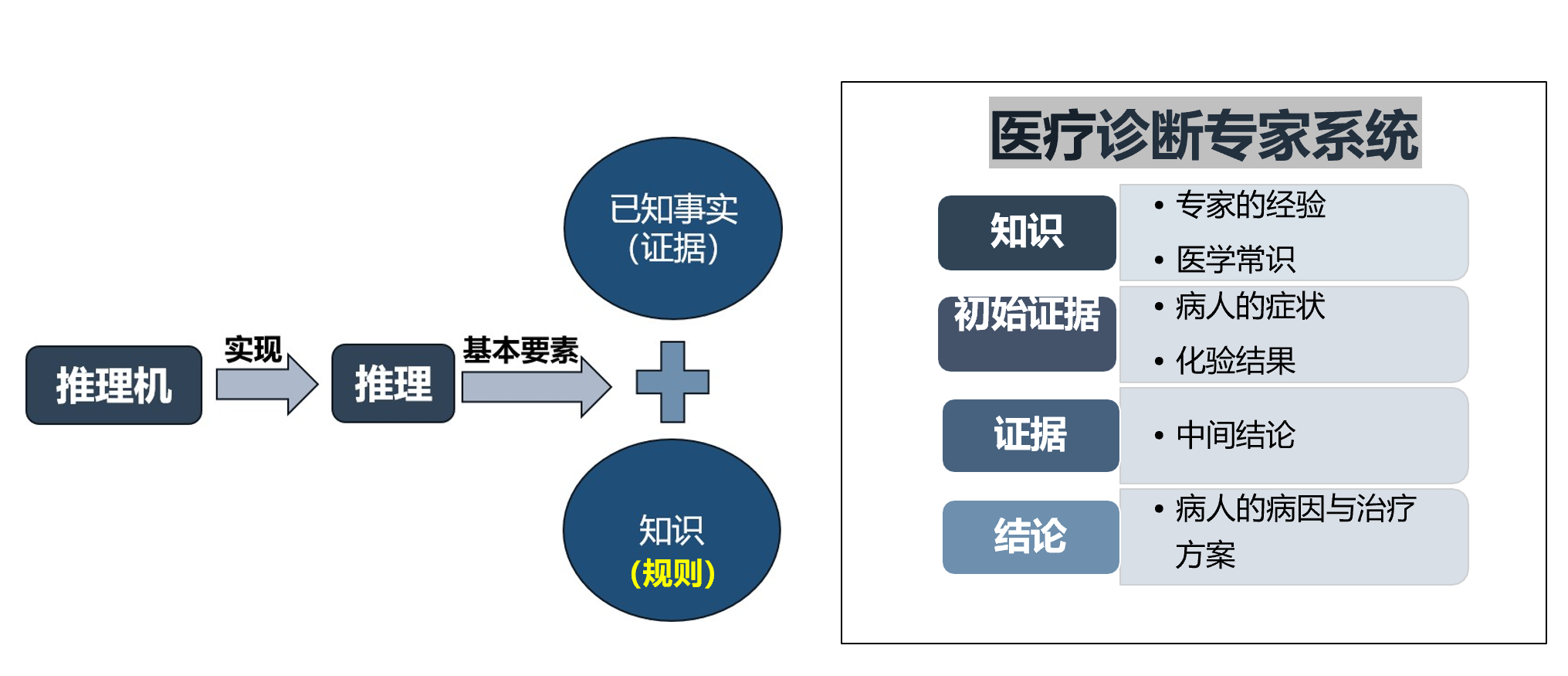
两个基本要素:
- 事实/证据:推理的出发点、推理时应该使用的知识
- 知识:使推理得以向前推进,并逐步达到最终目标的依据
推理机:在AI系统中,推理过程通常由推理机来实现,它通常是一组程序,用来控制协调整个系统。
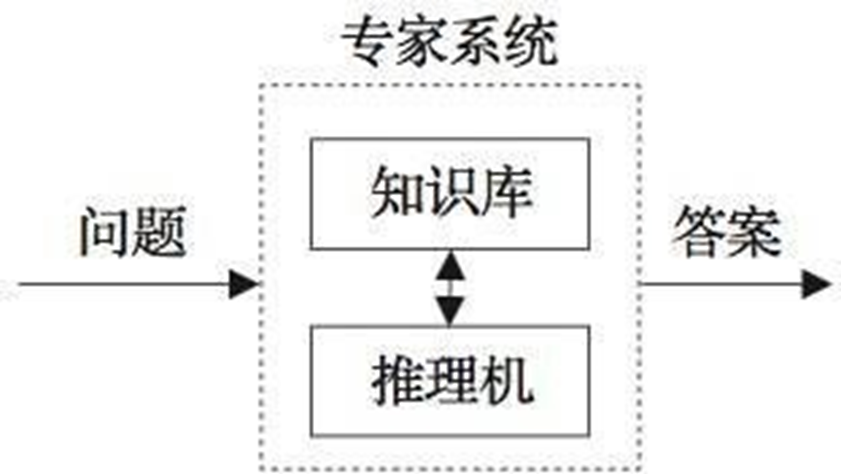
推理过程、案例
推理方式及其分类
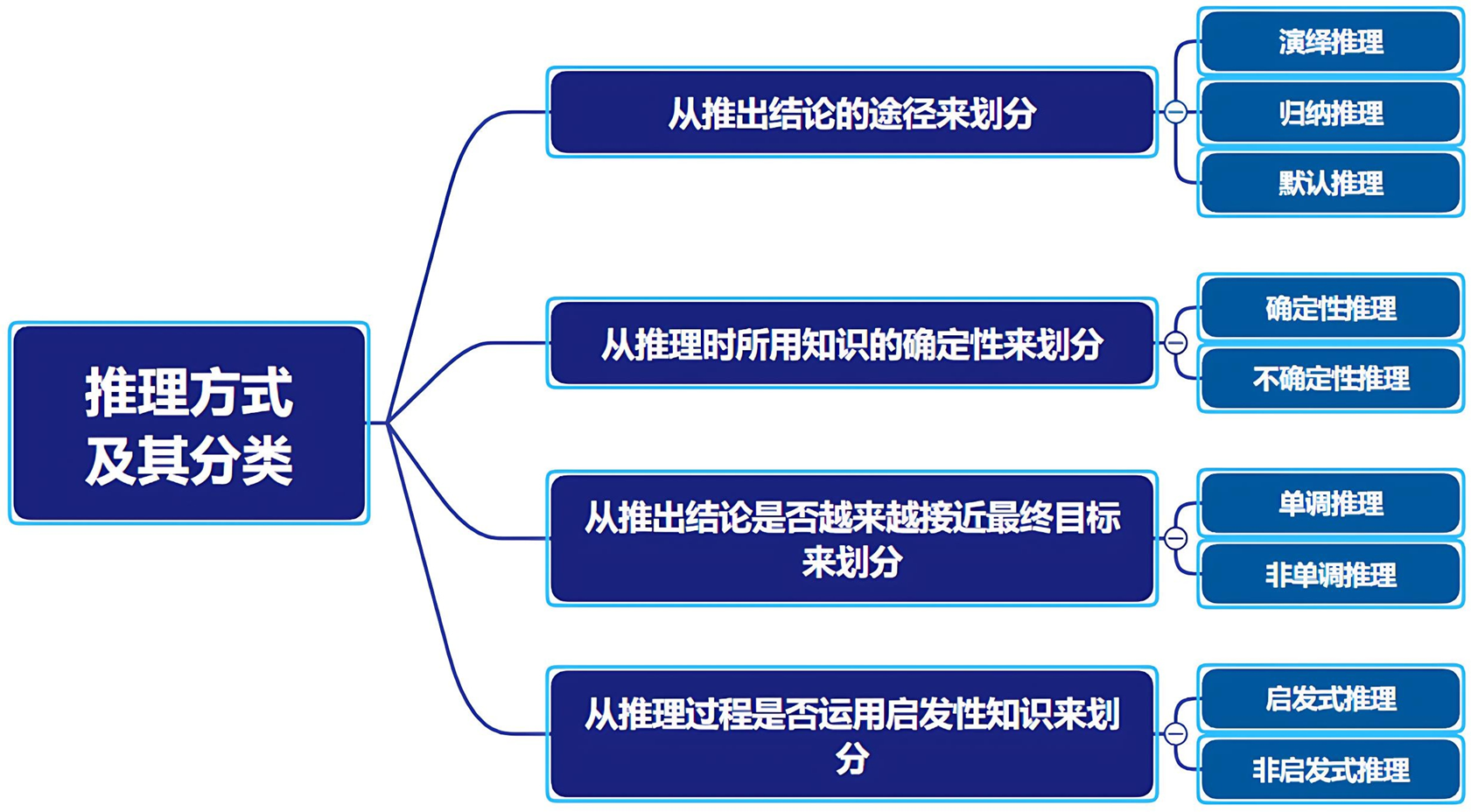
推理方式分类 - 按推出结论的途径
演绎推理(从一般到个别)
由一般性知识推出适合于某一具体情况的结论。
形式:三段论式
大前提:已知的一般性知识或假设。
小前提:关于所研究的具体情况或个别事实的判断。
结论:由大前提推出的适合于小前提所式情况的新判断。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1874
1874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









