






起初是这样的,我想到网上些408考研的,想做电子笔记,手敲的话实在是太累了,就想的怎么下载字幕,网上一搜快速提取视频字幕!适用B站、AI字幕等等。好用 - 哔哩哔哩 (bilibili.com),发现这样做的话还是麻烦,就想的能不能用python爬取字幕,
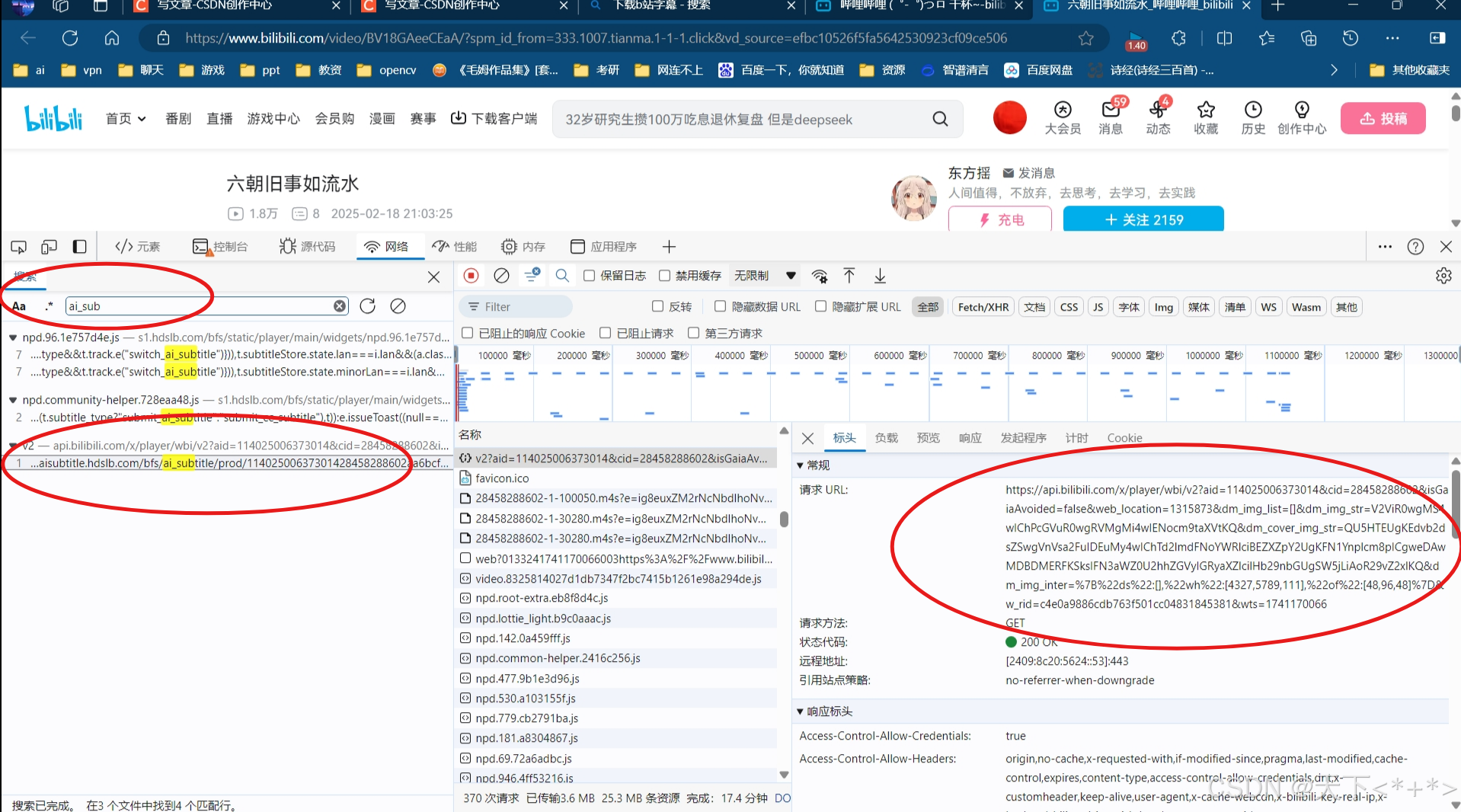
我就找到这样的规律,发现了要找的字幕的文件就放在了这里,
又多次实验发现了只要bv和av就可以获取到,那么如何获取到bv或者av呢,我开始搜索到了的话
BV-AV号互转 - 碧梨工具箱 | bilitools.top。用python模拟其实现逻辑
# 定义所需的常量和函数以执行转换
XORCODE = 23442827791579
MASKCODE = 2251799813685247
BASE = 58
datastring = "FcwAPNKTMug3GV5Lj7EJnHpWsx4tb8haYeviqBz6rkCy12mUSDQX9RdoZf"
# 定义常量和字符串
base = 58
# Python中的reduce函数
from functools import reduce
# 定义reduce操作的函数
def reduceoperation(t, n):
index = datastring.index(n) # 获取字符在字符串中的索引
return t * base + index # 返回累加结果
# 使用reduce函数处理数组n,初始值为0
# 定义常量
BASE = 58
XOR_CODE = 23442827791579
MASK_CODE = 2251799813685247
# 将字符映射到索引值
# 示例数据
# 执行转换
# 打印结果
def bv2av(bv):
n = list(bv)
n[3], n[9] = n[9], n[3]
n[4], n[7] = n[7], n[4]
n = n[3:]
o = reduce(reduceoperation, n, 0)
return (o & MASKCODE) ^ XORCODE
# 将BV号转换为AV号
bv = "BV1tP9iYsEzq"
av = bv2av(bv)
但后面发现没有这么麻烦,直接提取页面中的信息就行了
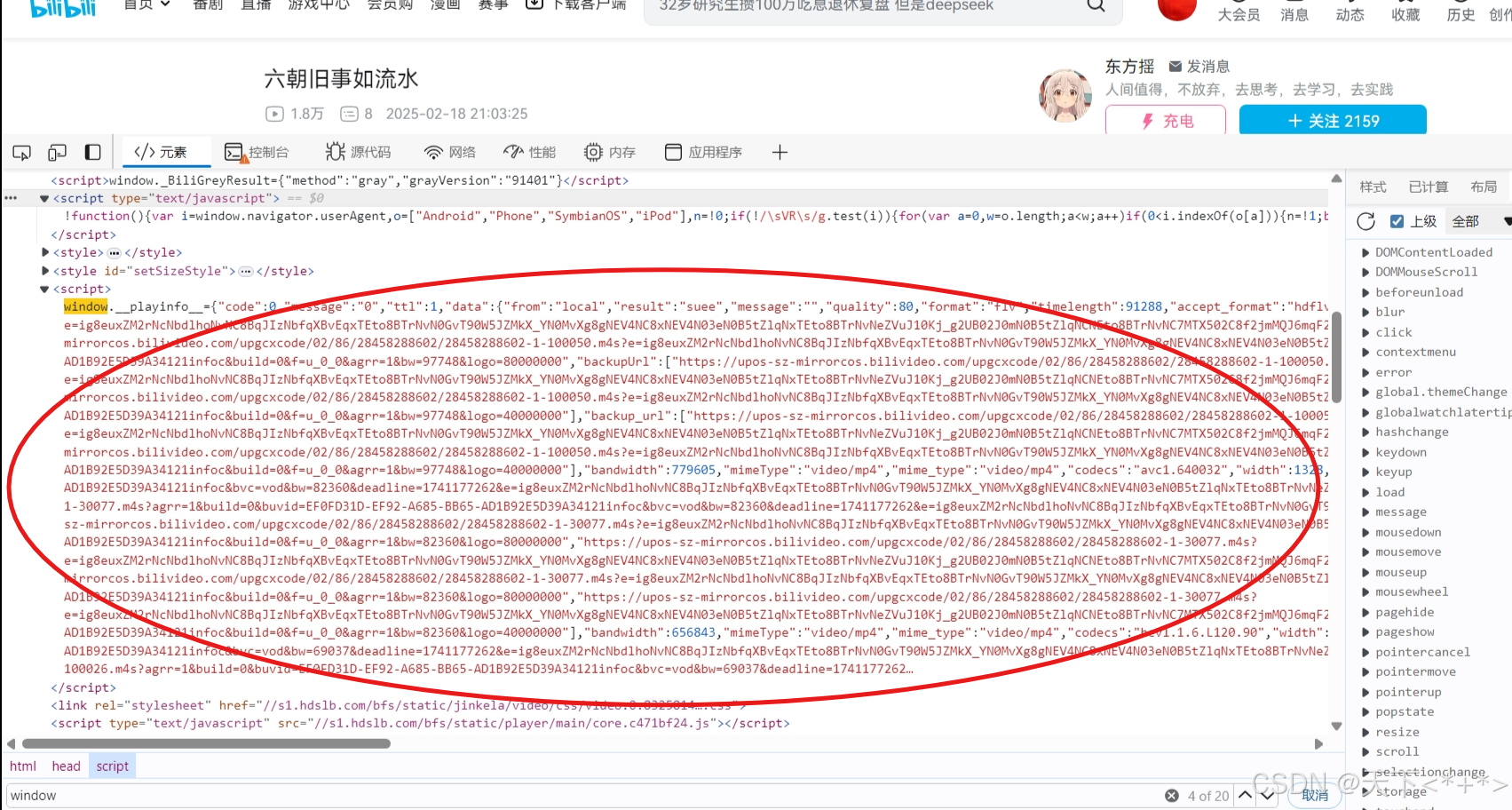
这里window_playinfo.然后的话提取里面的aid和cids。
import json
import requests
from bs4 import BeautifulSoup
import re
# 目标网址
headers = {
"Cookie":
"Origin": "https://www.bilibili.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0"
}
bvnane="BV1wANCebE8z"
pp="0"
url = f"https://www.bilibili.com/video/{bvnane}/?spm_id_from=333.1007.tianma.1-2-2.click&vd_source=efbc10526f5fa5642530923cf09ce506&p={pp}"
# 发送HTTP请求
response = requests.get(url, headers=headers)
aid_match = re.findall(r'.*,"aid":(\d+),', response.text)[0]
cids_match = re.findall(f'.*"{url.split("/")[4]}","cid":(\d+),', response.text)[0]
# print(response.text)
# print(cids_match)
htur=f"https://api.bilibili.com/x/player/wbi/v2?aid={aid_match}&cid={cids_match}"
print(htur)
#28248114986
response2 = requests.get(htur, headers=headers)
# print(response2.text)
pattern = r'"subtitle_url":"(.*?)","subtitle_url_v2"'
# 使用re.search()查找匹配的内容
match = re.search(pattern, response2.text)
# 如果找到匹配项,则提取第一个括号内的内容
if match:
subtitle_url = match.group(1)
print(subtitle_url)
else:
print("No match found")
uul=f"https:{subtitle_url}"
responses1=requests.get(uul,headers=headers)
print(responses1.text)
data = json.loads(responses1.text)
# 提取content内容
print("\n\n\n\n")
contents = [item['content'] for item in data['body']]
print(contents)注意每次请求的时候都要带上cookie,不然返回的数据有缺失的
我们请求
将bv号粘贴上去请求
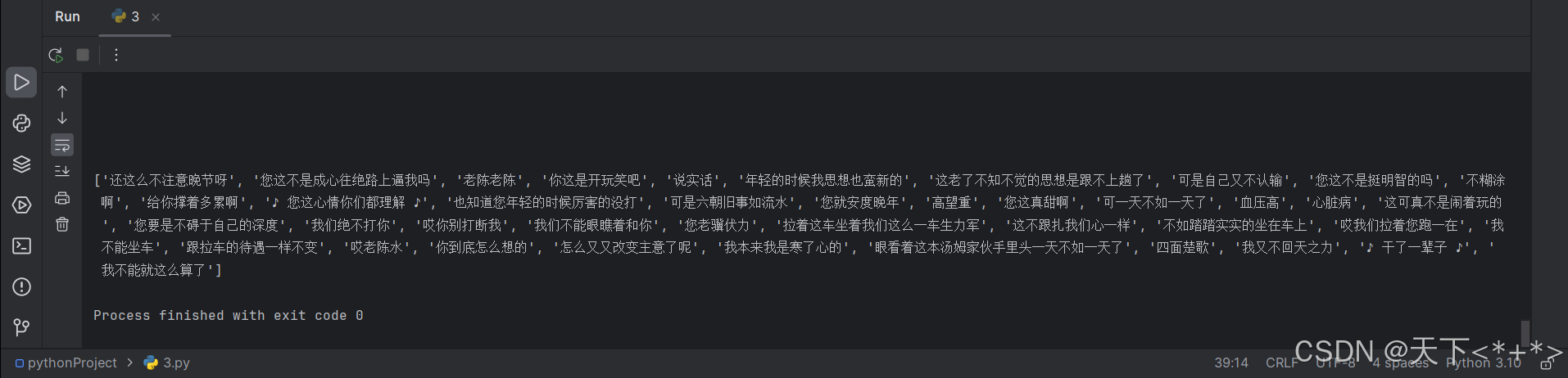
成功得到字幕

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









