




 本文介绍了如何从B站视频中获取字幕,并利用这些字幕数据生成词云。通过打开视频,找到特定链接,抓取弹幕网址,然后使用代码处理这些数据,最终得到词云结果。
本文介绍了如何从B站视频中获取字幕,并利用这些字幕数据生成词云。通过打开视频,找到特定链接,抓取弹幕网址,然后使用代码处理这些数据,最终得到词云结果。
首先打开B站,随便打开一个视频(要打开视频,再刷新),找到左边箭头的那个项,
然后电击右边header, 这个网址就是我们要爬取的弹幕了
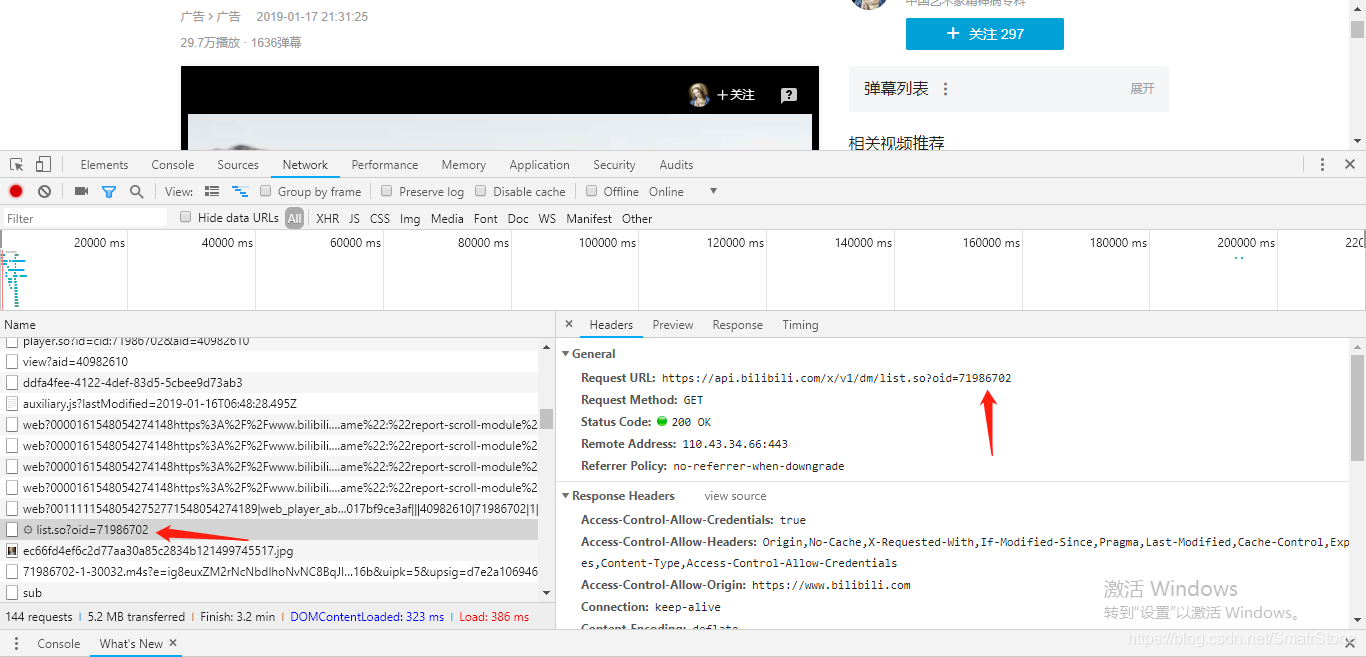
以下是源码, 把网址后面那串数字放进程序入口就可以出结果了
import requests, re
from matplotlib import pyplot as plt
from wordcloud import WordCloud
# 获取网页信息
def get_webpage(cid):
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid='+str(cid) # 1.需抓取的网址
header ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
webpage = requests.get(url=url,headers=header)
with open('bili02.txt','wb') as w:
w.write(webpage.content)
with open('bili02.txt','r',encoding='utf-8') as r:
rs = r.read()
list = re.findall('>.*?<',rs)
result=''
for i in list:
result += str(i).strip('>').strip('<')+'\n'
return result
# 词云
def wrodcloud(str):
font = r'C:\Windows\Fonts\FZSTK.TTF'
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









