







PyTorch深度学习快速入门
- 1.PyTorch环境配置及安装
- 2.python编辑器的选择、安装、配置(pycharm、JupyTer安装)
- 3.为什么torch.cuda.is_available()返回false
- 4.python学习中两大法宝函数(也可用在pytorch)
- 5.pycharm和jupyter(究bi特)使用及对比
- 6.pytorch加载数据初认识
- 7.dataset类代码实战
- 8.TensorBoard的使用(一)
- 9.TensorBoard的使用(二)
- 10.Transforms的使用(一)
- 11.Transforms的使用(二)
- 12.常见的Transforms(一)
- 13.常见的Transforms(二)
- 14.torchvision中的数据集的使用
- 15.DataLoader的使用
- 16.神经网络的基本骨架-nn.Module的使用
- 17.卷积操作
- 18.卷积层
- 19.神经网络最大池化的使用
- 20.神经网络非线性激活
- 21.神经网络-线性层及其它层介绍
- 22.搭建小实战和Sequential的使用
- 22.损失函数和反向传播
- 23.优化器
- 24.现有网络模型的使用及修改
- 25.网络模型的保存和读取
- 26.完整的模型训练套路(一)
- 27.完整的模型训练套路(二)
- 28.完整的模型训练套路(三)
- 29.利用GPU训练(一)
- 30.利用GPU训练(二)
- 31.完整的模型验证套路
- 32.开源项目
1.PyTorch环境配置及安装

https://repo.anaconda.com/
在开始菜单打开Anaconda prompt
在命令行窗口看见base就是安装成功
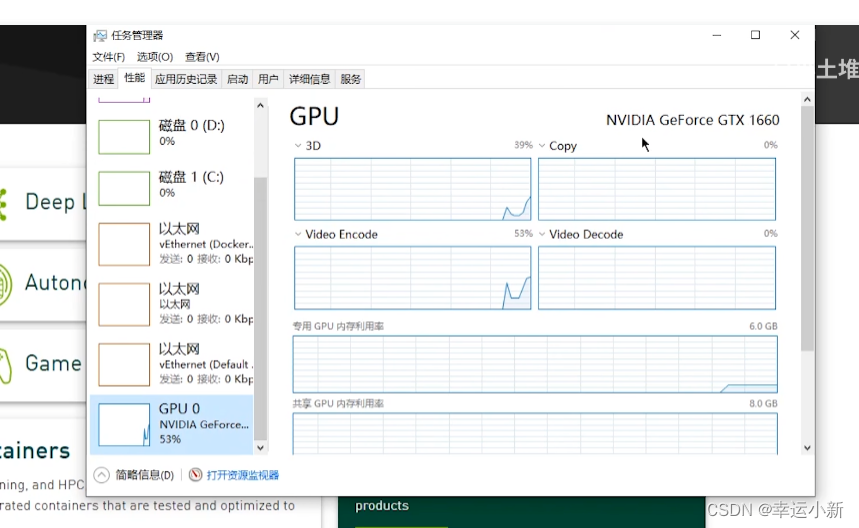
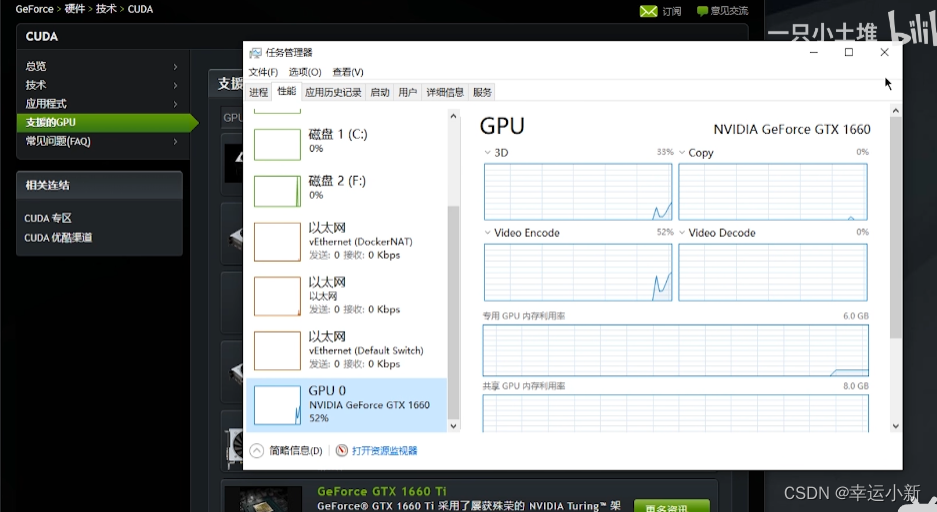
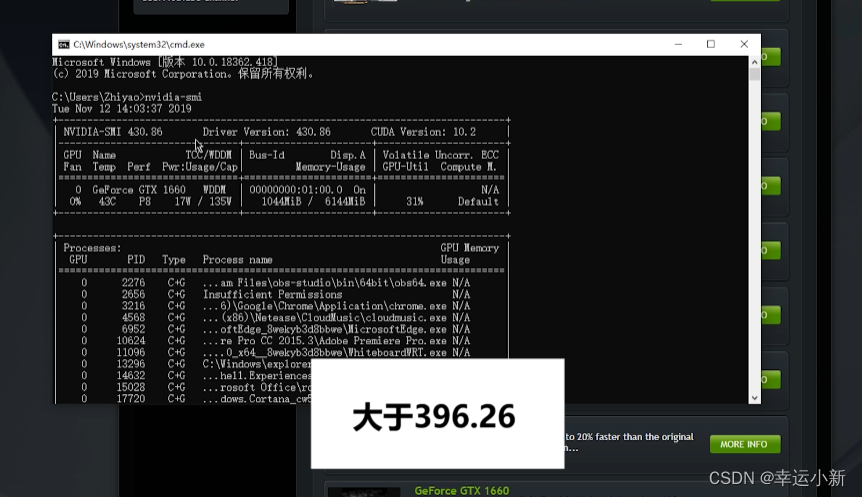
我们要检查显卡的驱动是否正确安装
看到GPU正常显示型号,则显卡驱动已经正确安装了
在正确安装pytorch之前
我们要学会如何正确管理环境
因为我们之后在不同的项目、代码需要的环境是不一样的
有的代码需要pytorch0.4、有的需要1.0
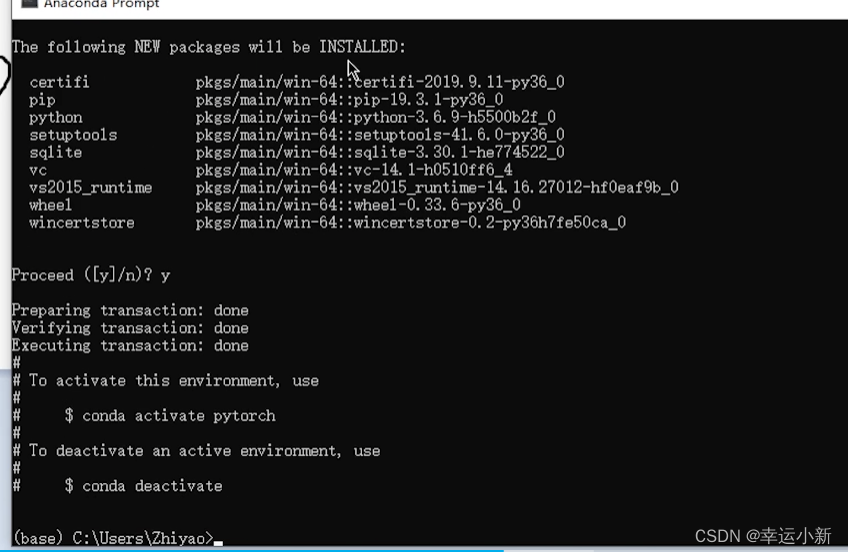
conda create -n pytorch python=3.6
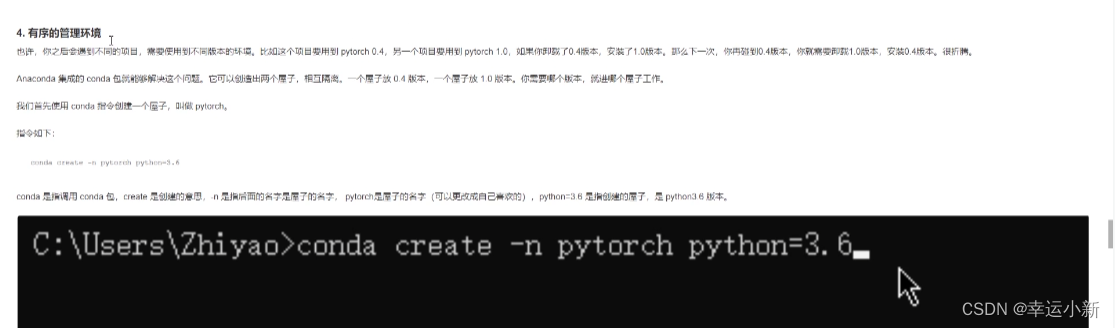
n表示name的意思,pytorch就是这个环境的名字
python=3表示要安装的包

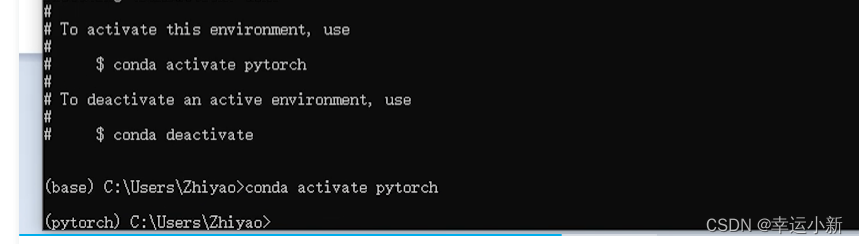
conda activate pytorch用来激活这个环境
左边括号里面的就是环境的名称
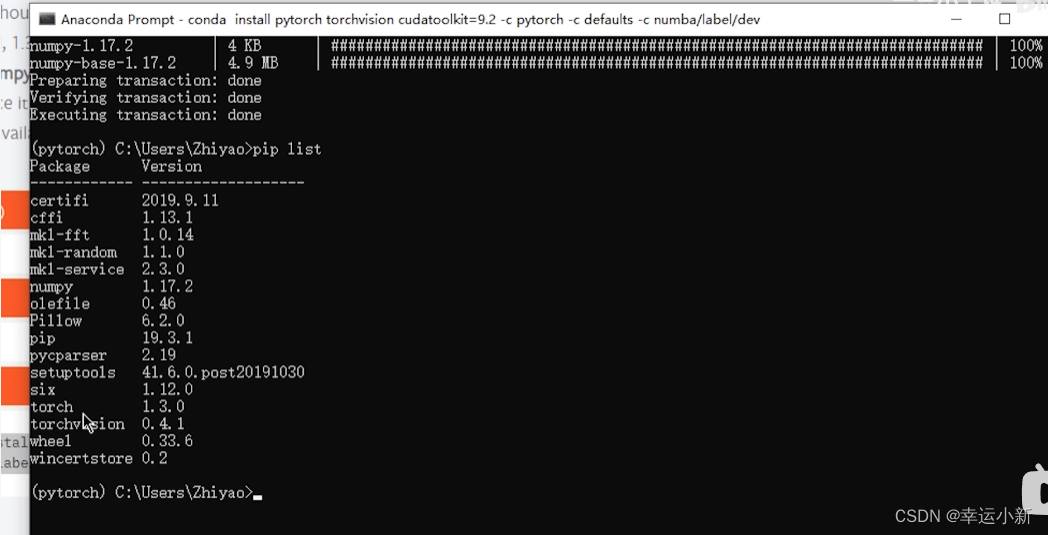
pip list用来查看环境中有哪些工具包
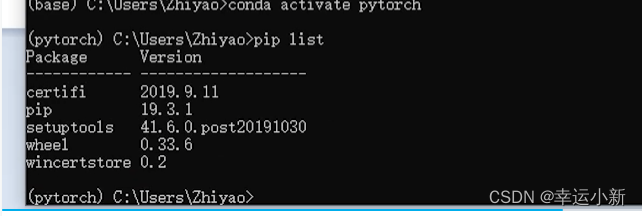
但其中没有我们需要的pytorch
下面我们开始安装pytorch
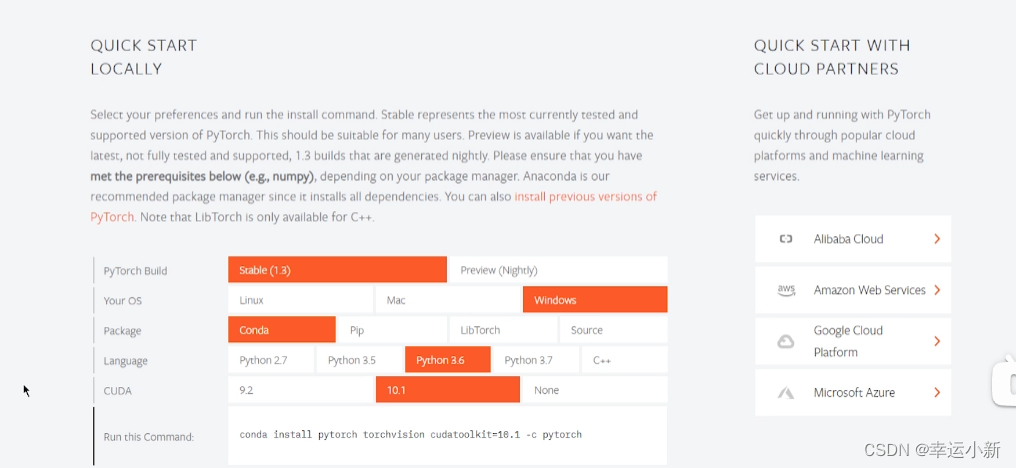
我们需要知道自己GPU的型号
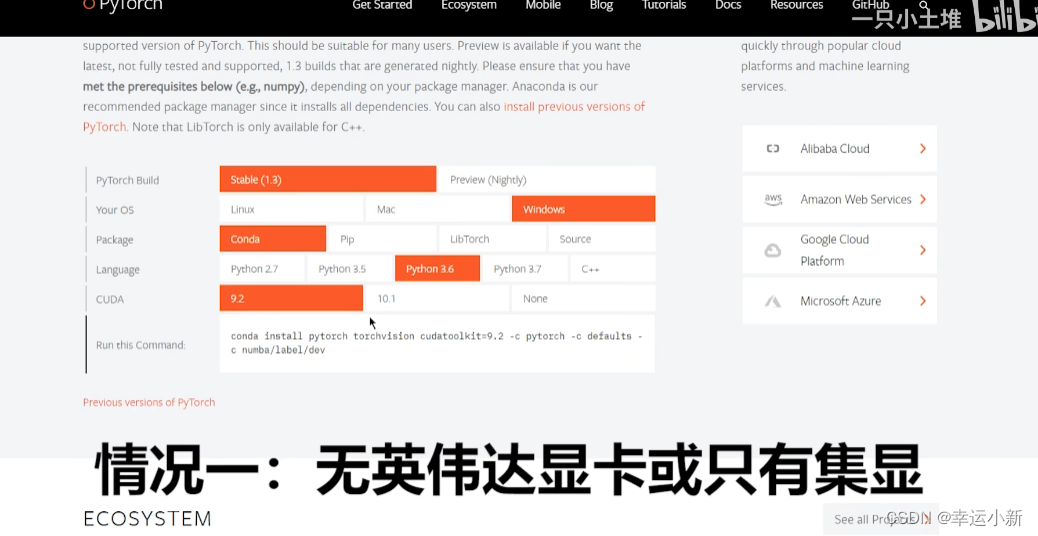
没有显卡 CUDA选择None
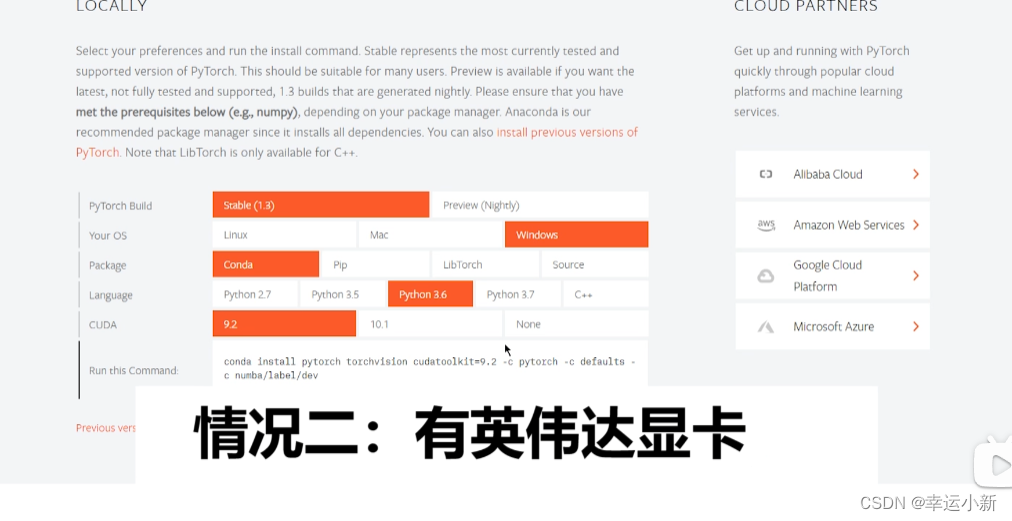
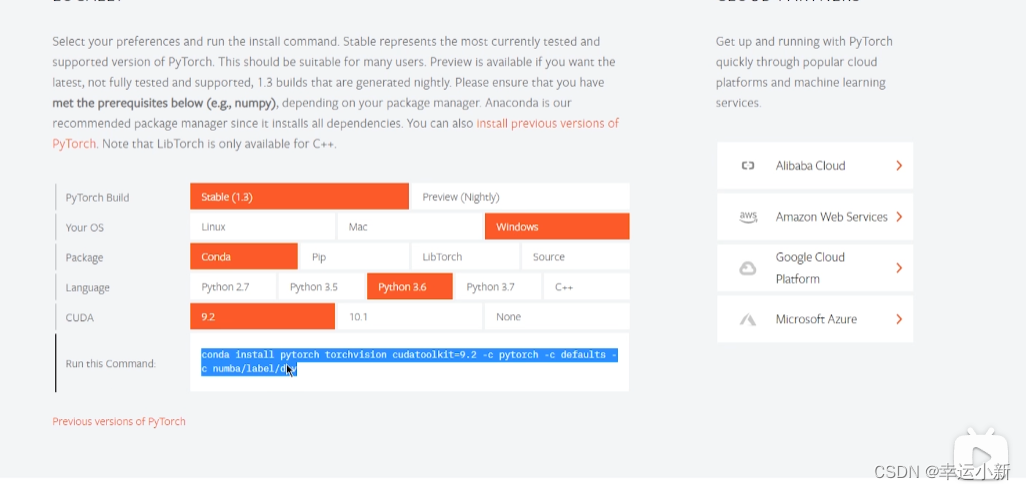
conda9.2以上要确保我们的驱动版本大于396.26
我们要先查询一下自己的驱动版本nvidia-smi

conda install pytorch torchvision cudatoolkit=9.2 -c pytorch -c defaults -c numba/label/dev

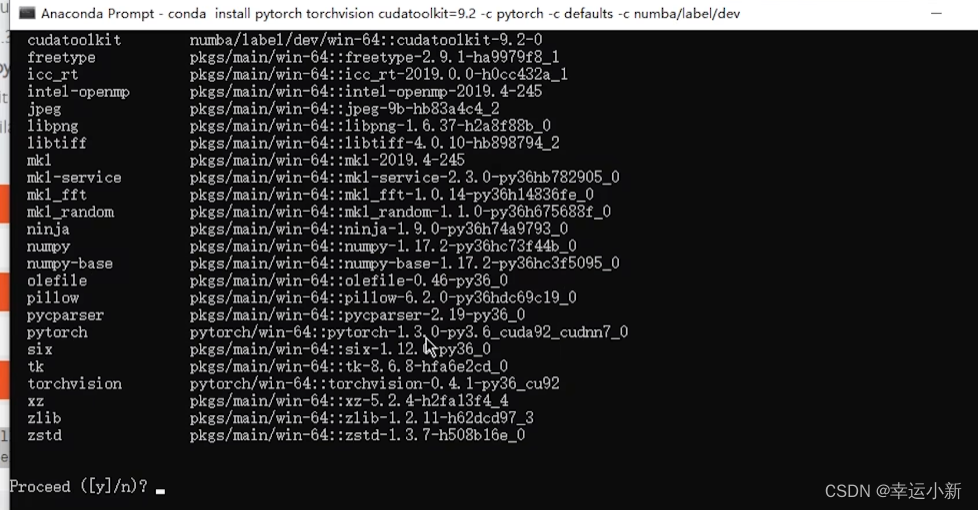
使用python
import torch
观察pytorch是否安装成功
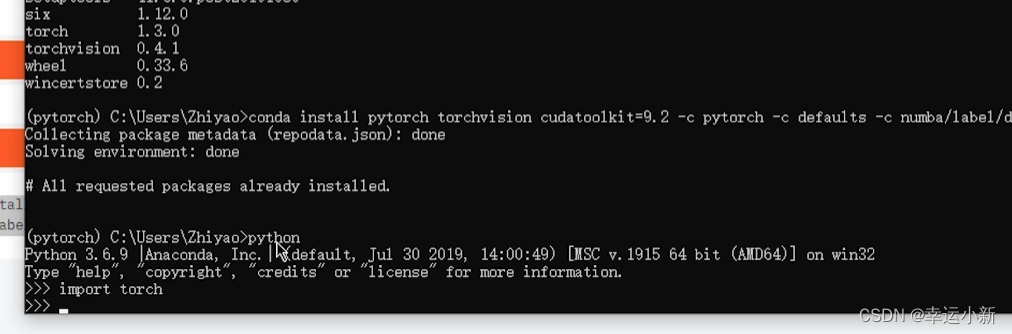
使用torch.cuda.is_available()这个命令观察是否可以使用GPU

显示false是因为cuda下错版本了,要与自己的电脑对应起来
比如我的
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia

3060最低要11.1的cuda
2.python编辑器的选择、安装、配置(pycharm、JupyTer安装)


选择地址和环境
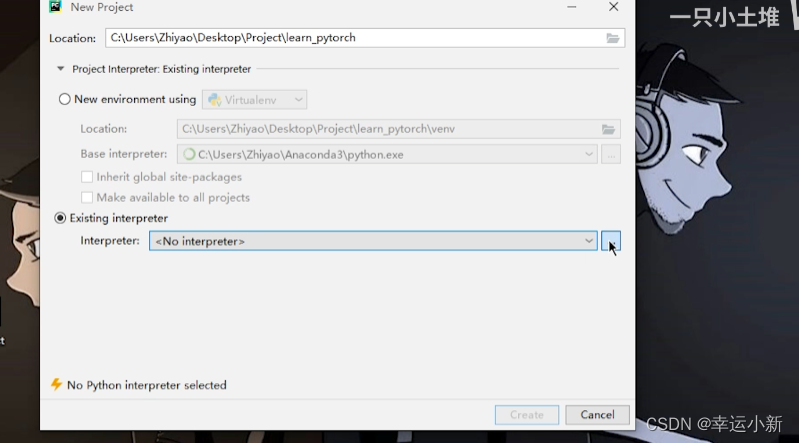
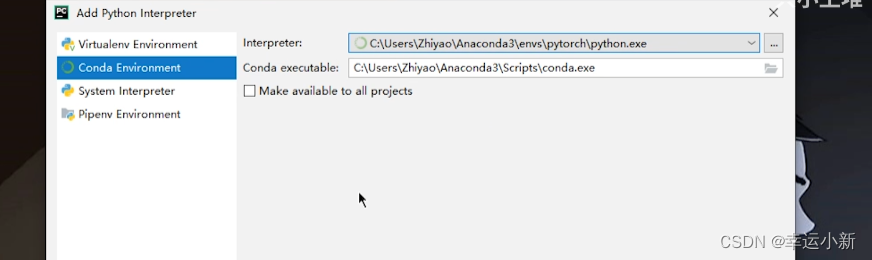
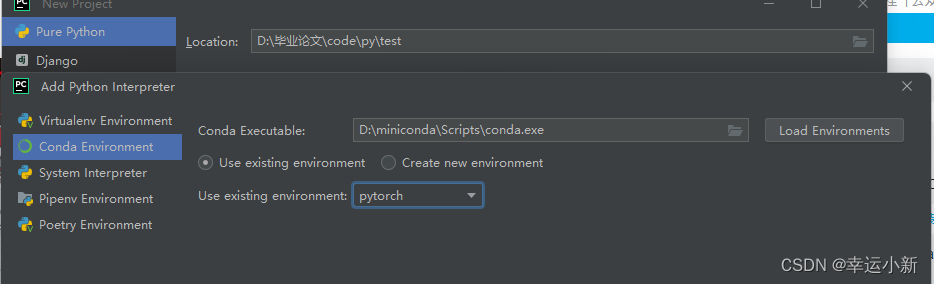
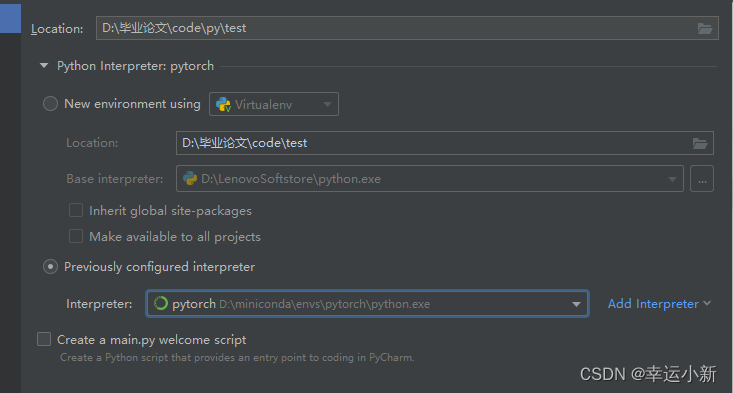
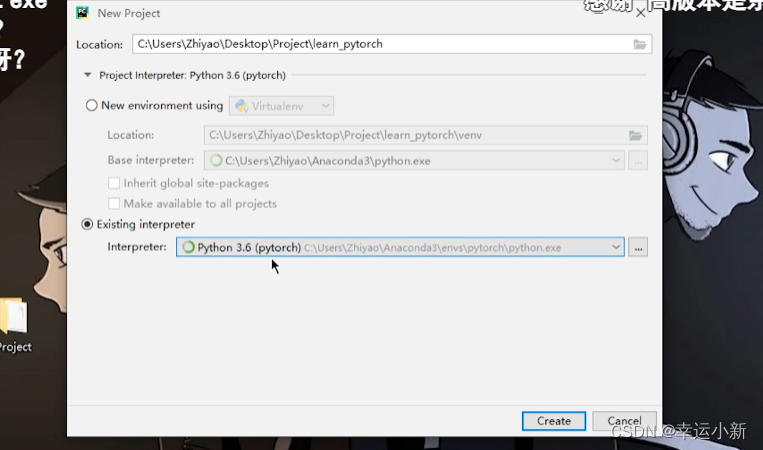
下面检测一下pycharm是否成功导入了conda的运行环境
torch.cuda.is_available()
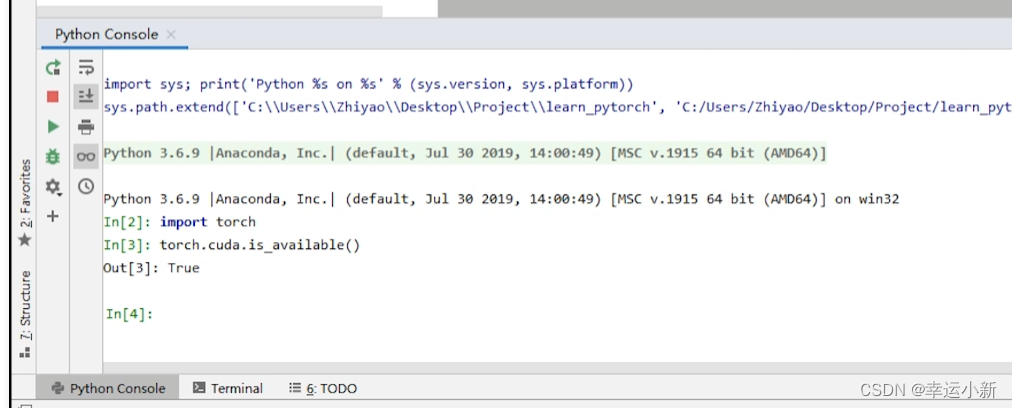

jupyter是默认安装在外面的base环境中的
但我们的base环境是没有安装pytorch的
所以这个jupyter无法使用pytorch
我们可以在base环境中安装pytorch或者在pytorch环境中安装jupyter
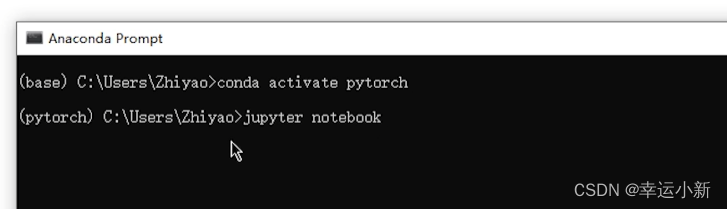
我们使用第二种方法
先进入pytorch环境
conda activate pytorch
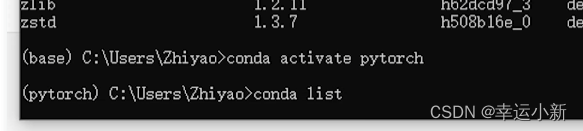
我的pytorch环境中没有

使用conda install nb_conda安装

安装完成后输入jupyter notebook

http://localhost:8888/?token=f0d9cb3f4543dceeb4737d957381b4c3ab37070ce474b819
点击shift+回车运行代码块
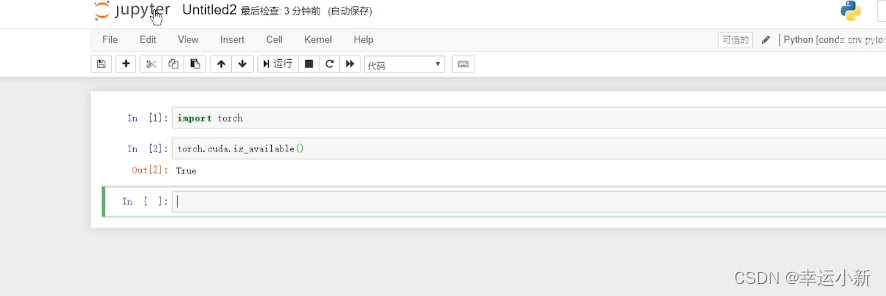
torch.cuda.is_available()
如果是中文用户名可能会运行不了
在环境变量下做如下修改
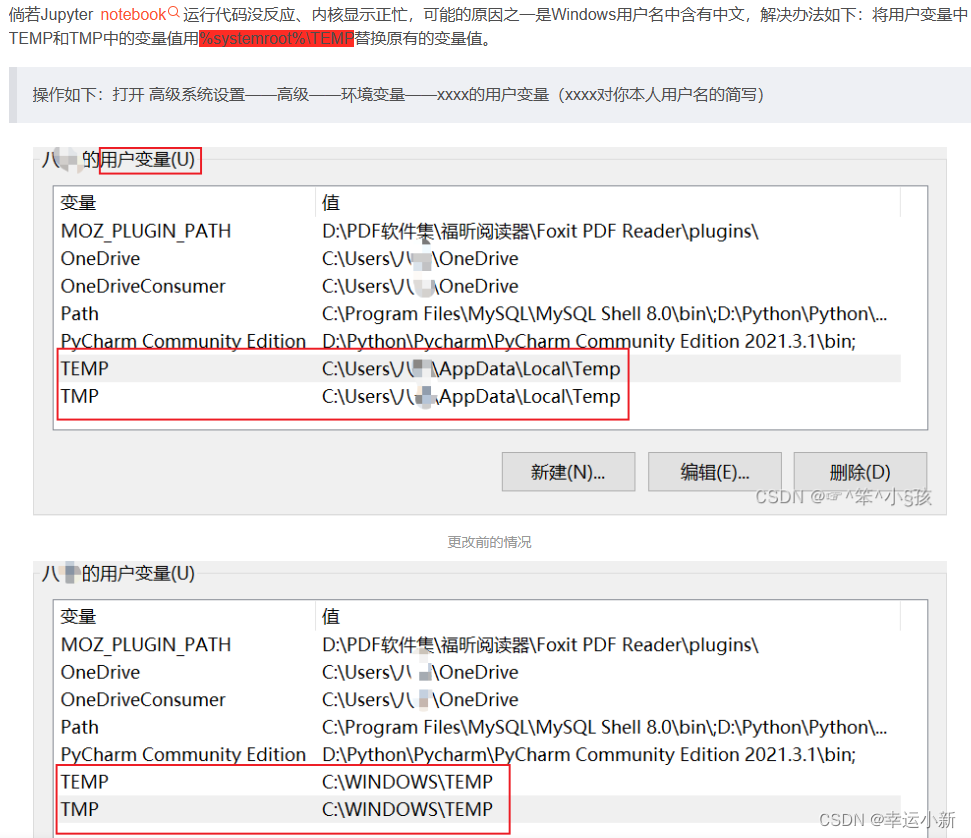
%systemroot%\TEMP

%USERPROFILE%\AppData\Local\Temp
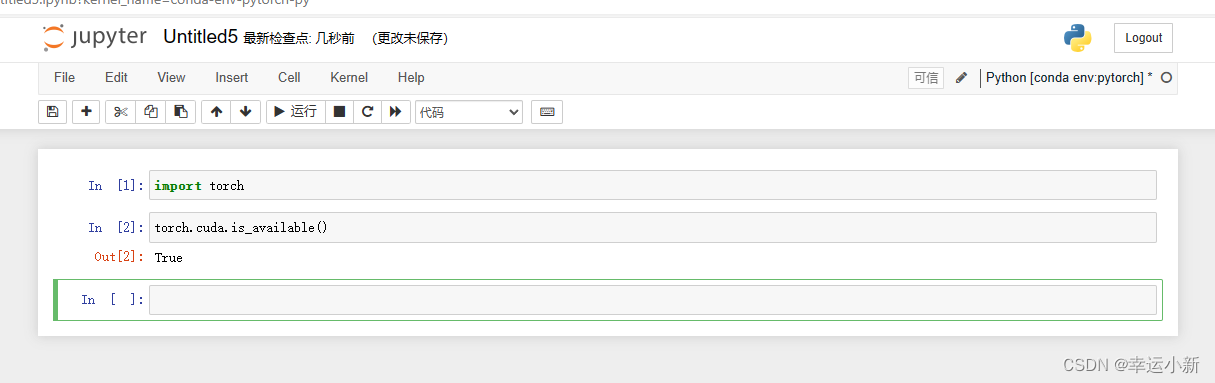

3.为什么torch.cuda.is_available()返回false
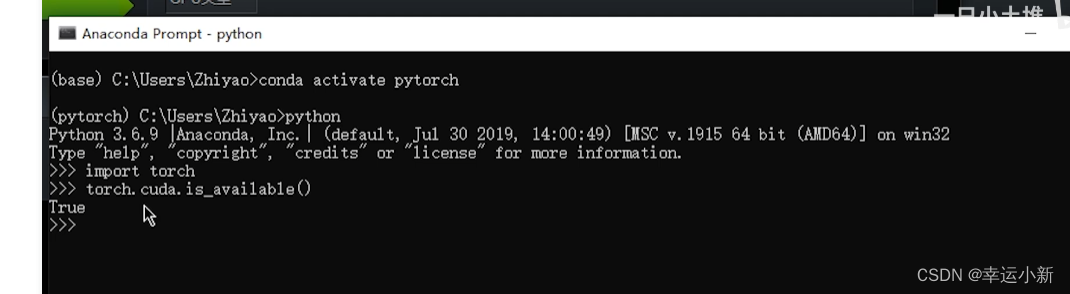

4.python学习中两大法宝函数(也可用在pytorch)
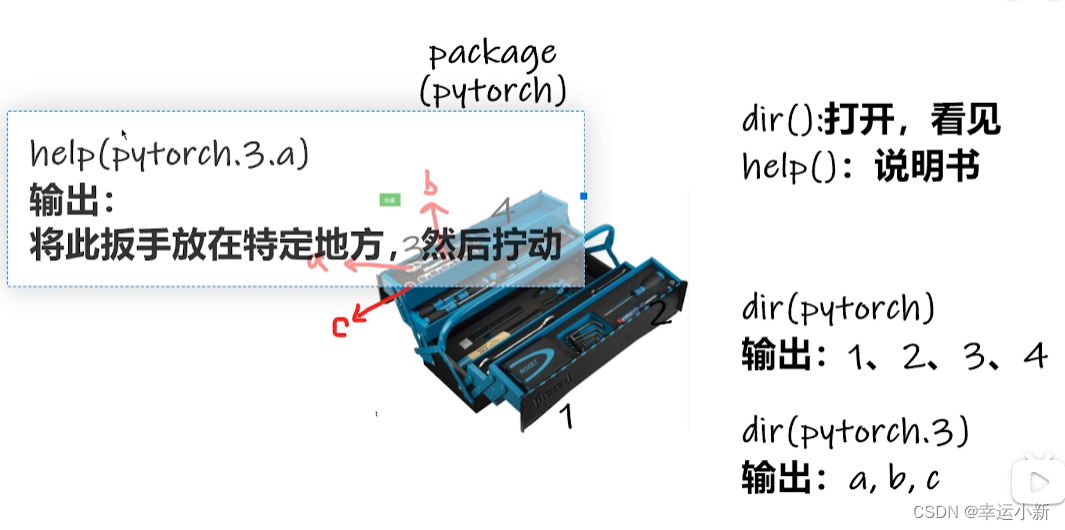

输出只有一行的,可以点击此刻页面最左侧第2列第一个按钮“Soft-warp”
查看torch.cuda
我们可以看见之前用的is.available

有_表示它是一个函数
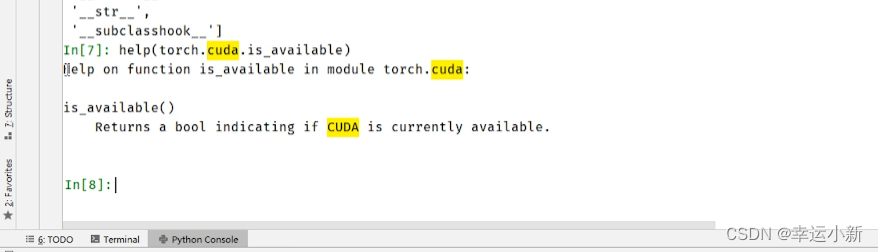
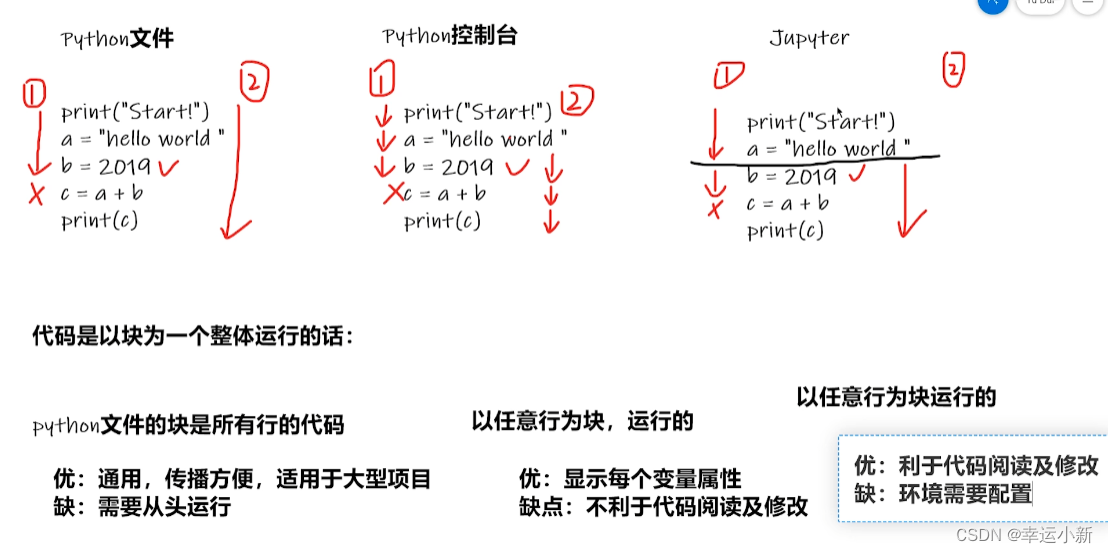
5.pycharm和jupyter(究bi特)使用及对比
首先是pycharm
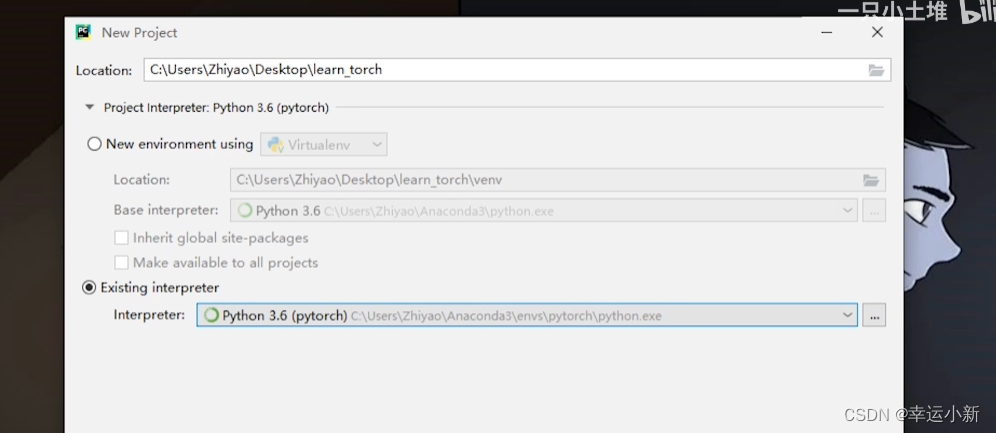
如何确定这个文件使用的是我们的pytorch的cuda环境呢
新建一个python文件
如何运行这个文件
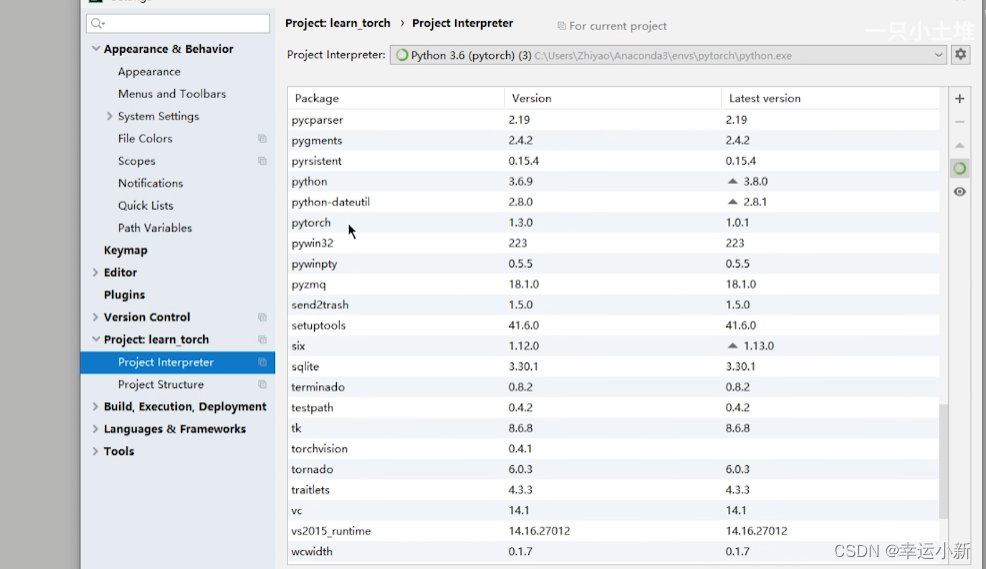
我们要添加相应的python解释器
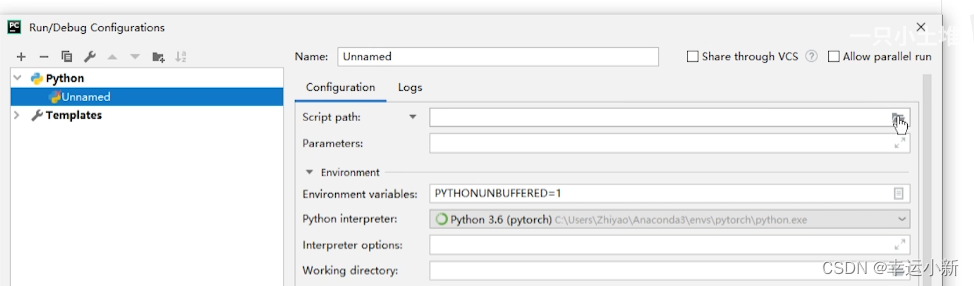
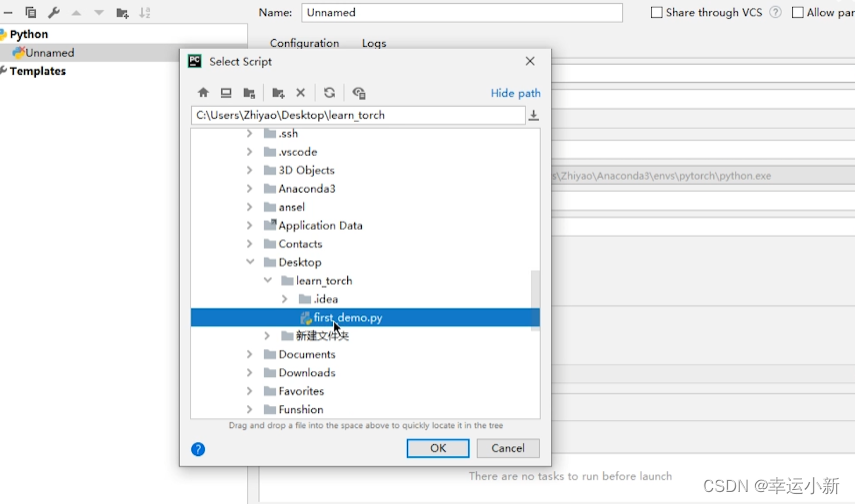
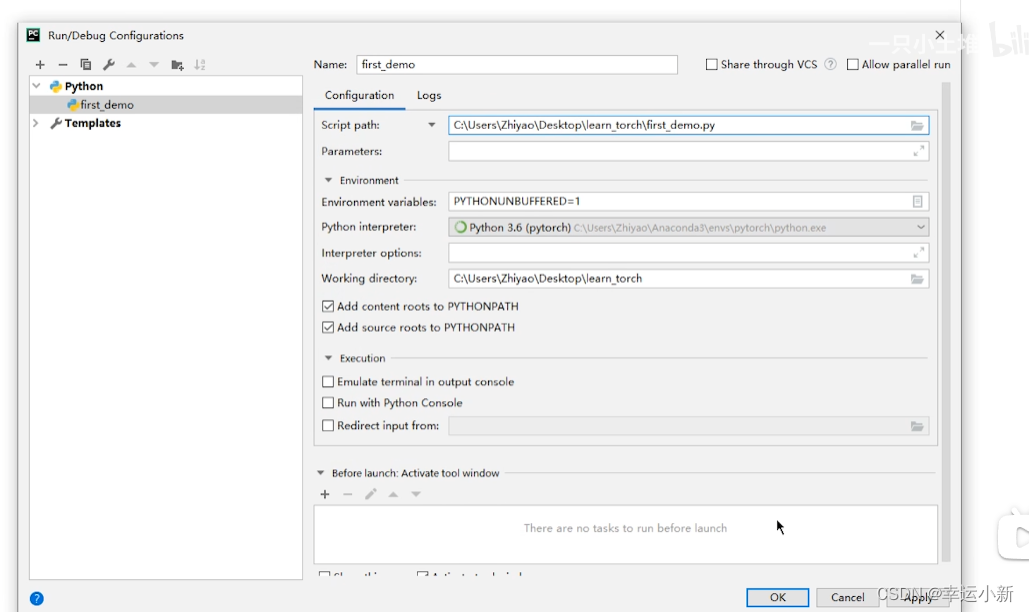
点击确定就OK了
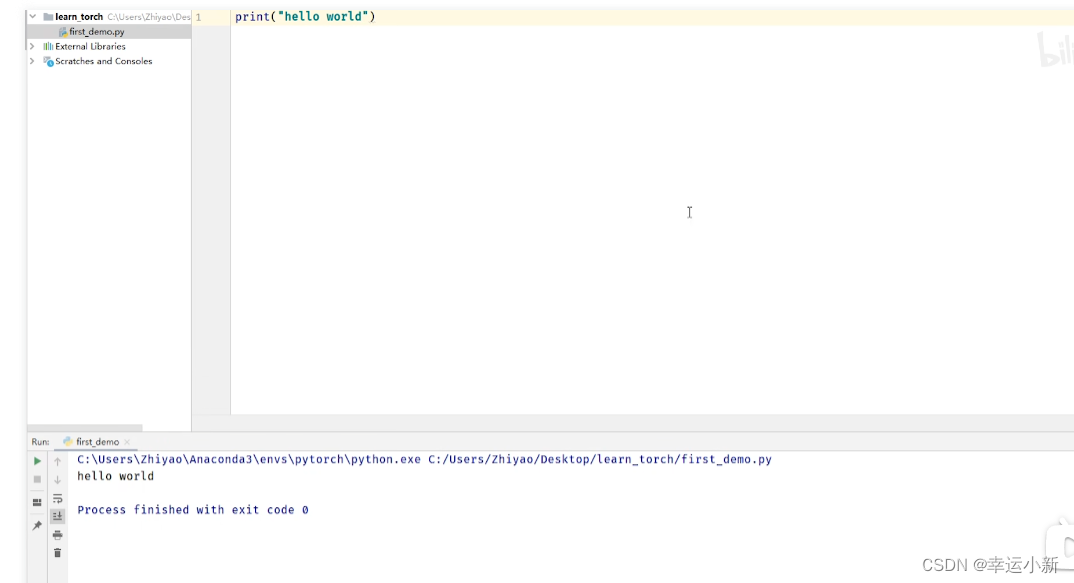
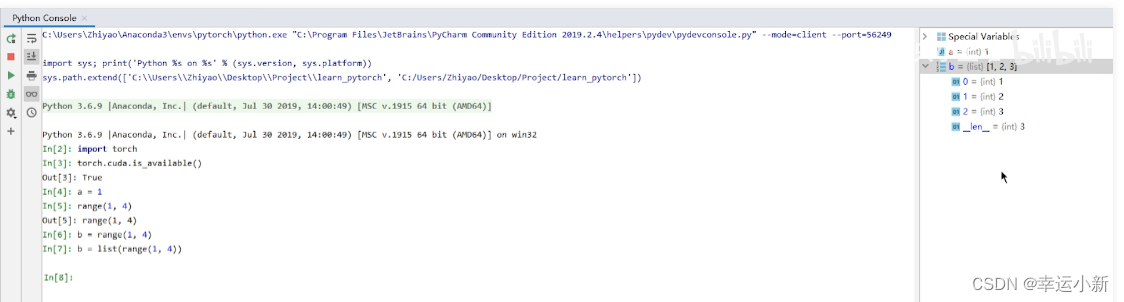
我们也可以直接在python控制台
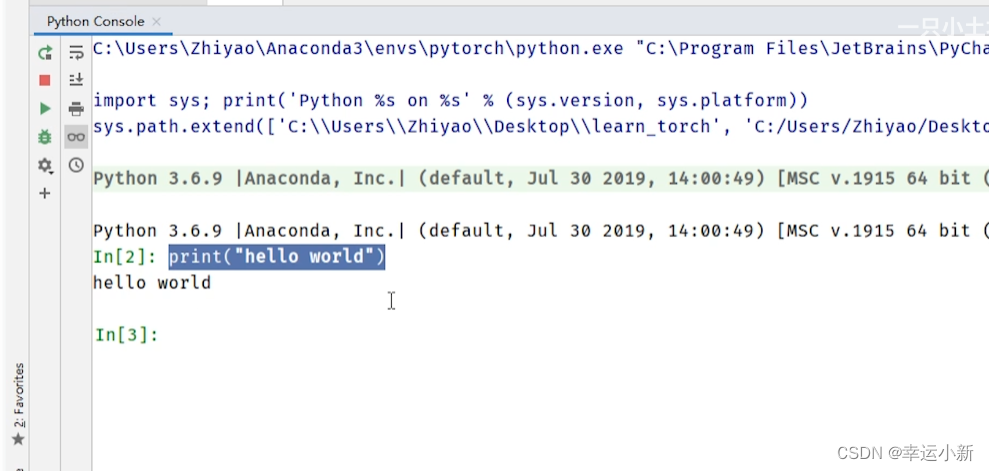



在里面创建一个新的文件
先选择相应的环境



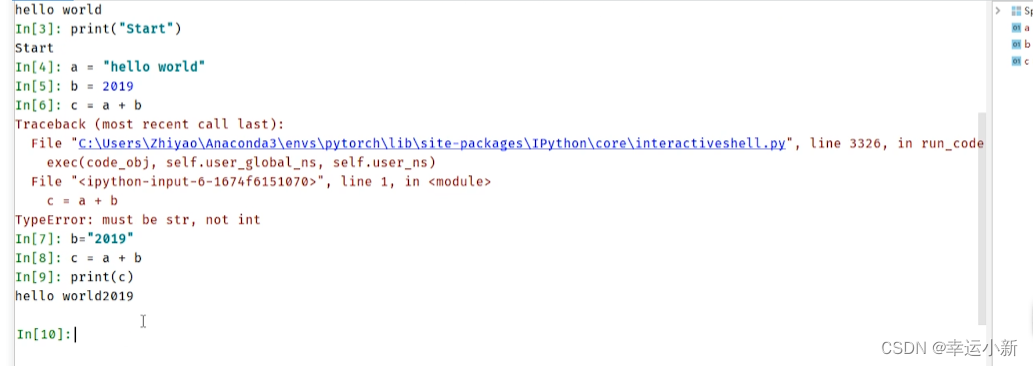

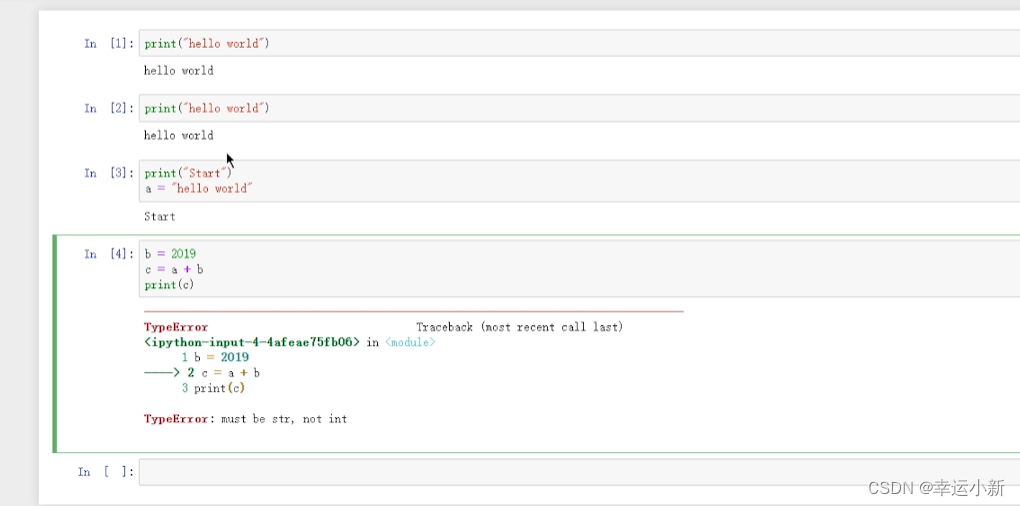
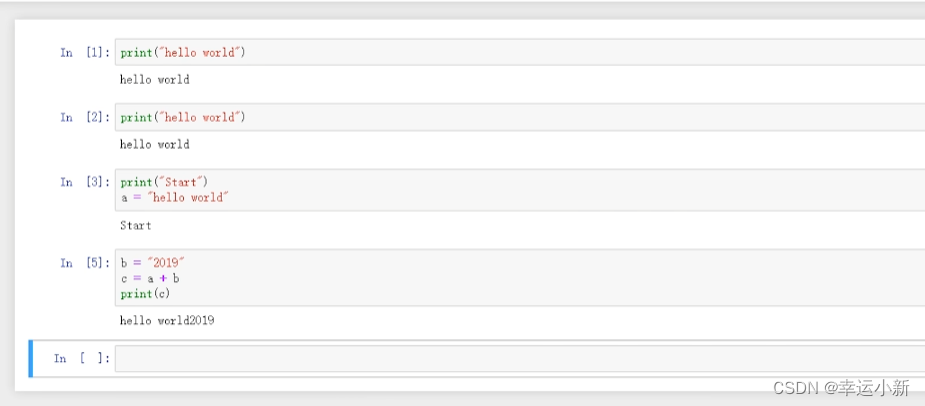
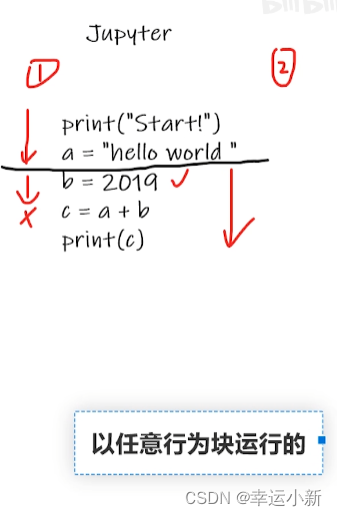
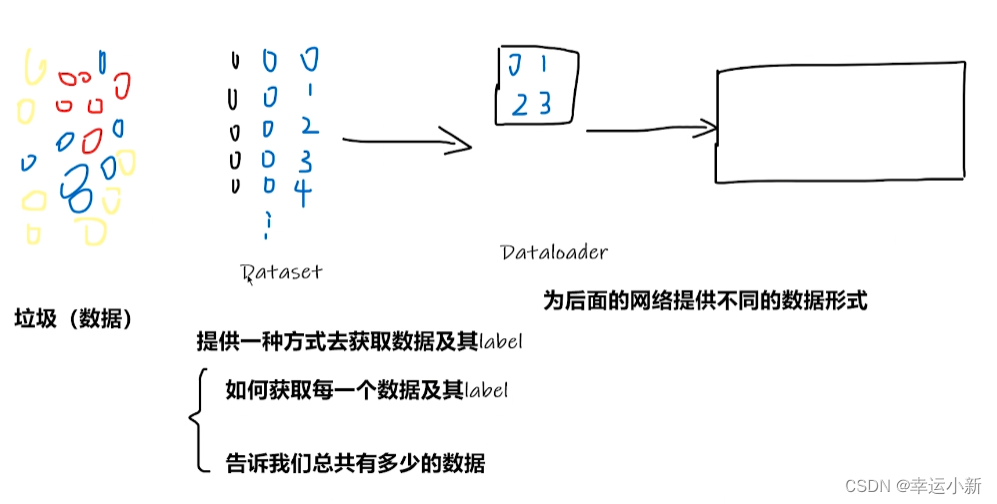
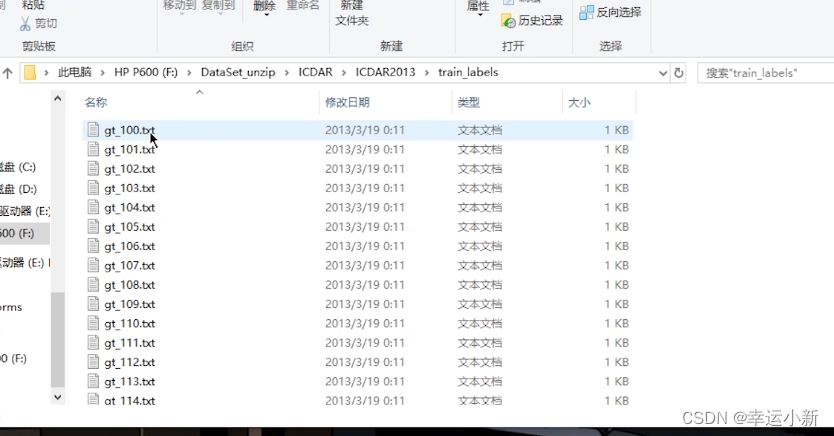
6.pytorch加载数据初认识
https://pan.baidu.com/s/1jZoTmoFzaTLWh4lKBHVbEA 密码: 5suq
可以下载一下数据集
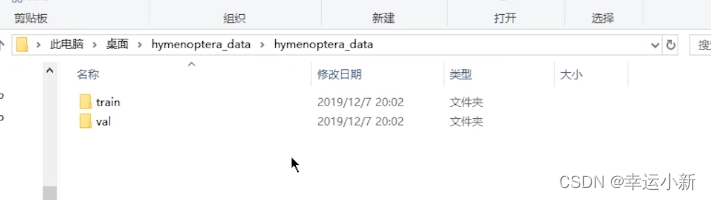
这个数据集分为train(训练数据集)和val(验证数据集)
下面是train
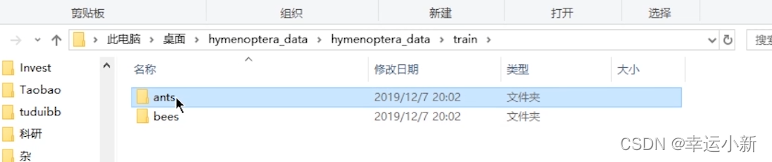
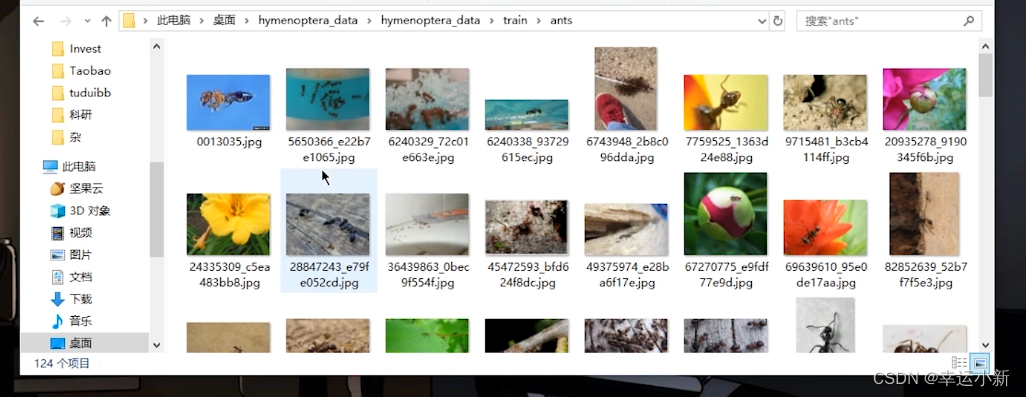
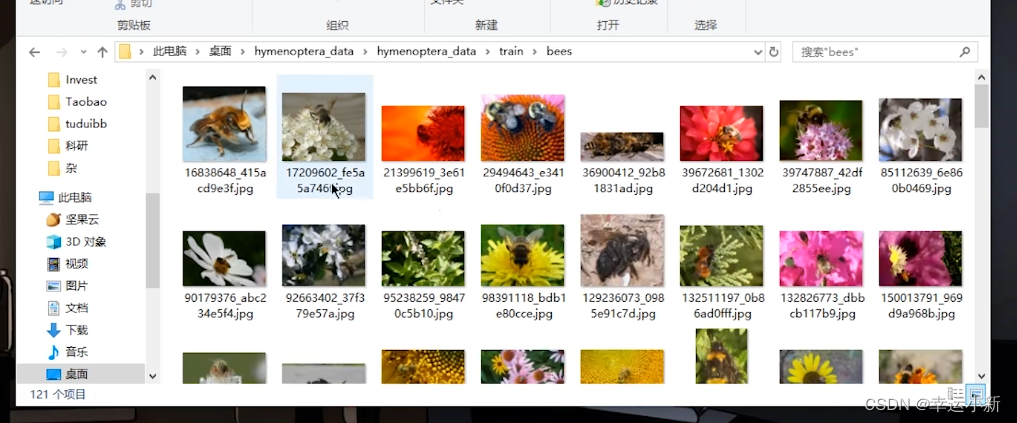
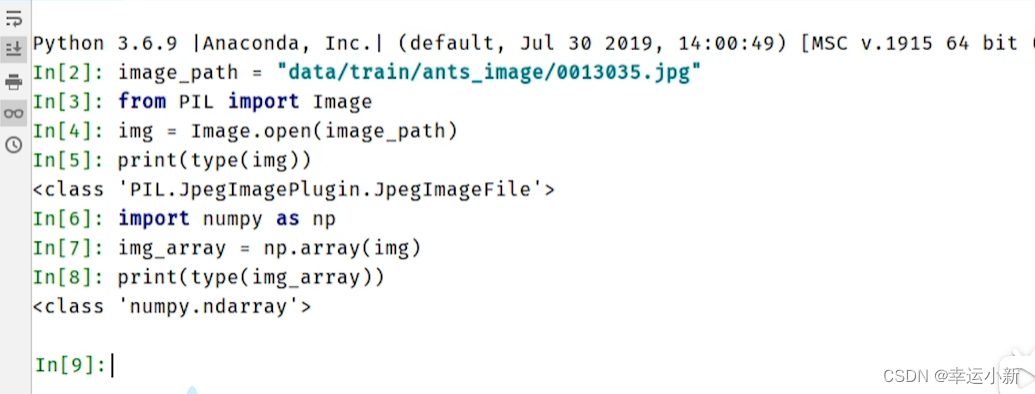
这是一个识别蚂蚁和蜜蜂对他进行二分类的一个数据集
其中ants和bees这两个文件的名称就是label
还有其他的形式
告诉我们训练的图片是什么样子
告诉我们训练的label是什么样子
或者我们也可以将label直接写在图片名称上面
下面说明如何使用dataset类
或者


7.dataset类代码实战
使用控制台进行一个调试
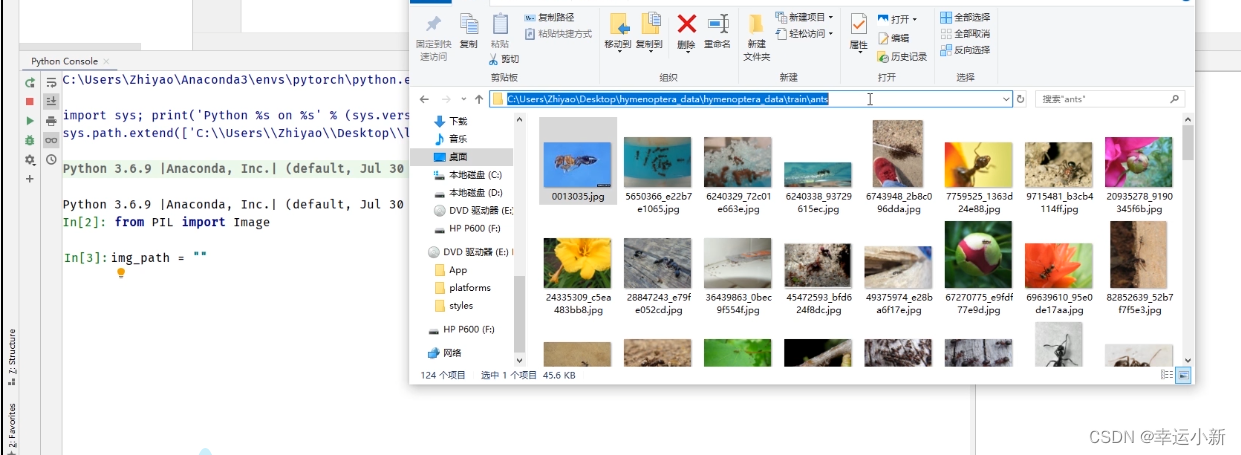
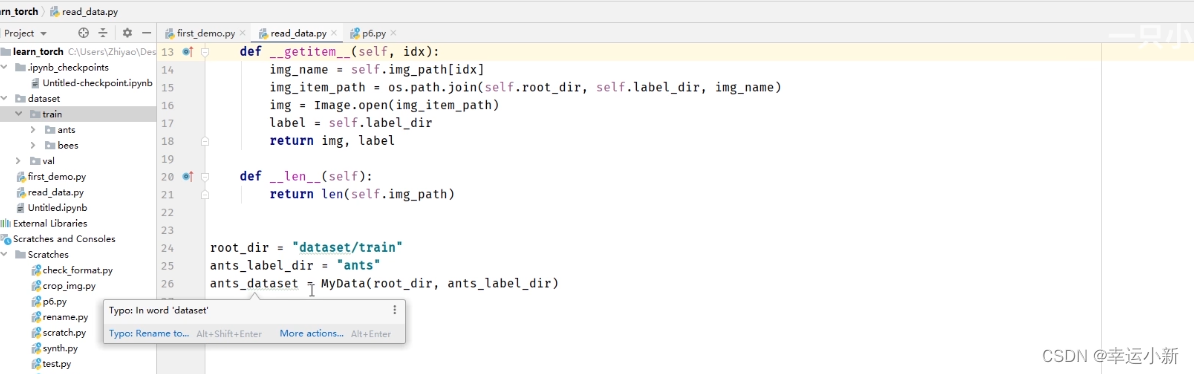
将数据集放到项目中,并且重命名为dataset
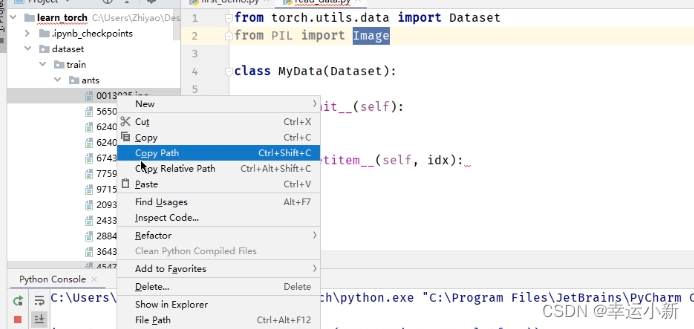
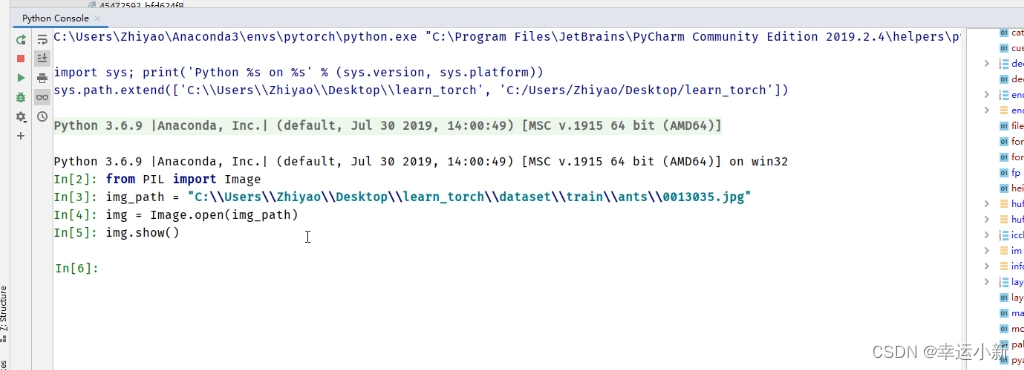
我们要获取图片的地址
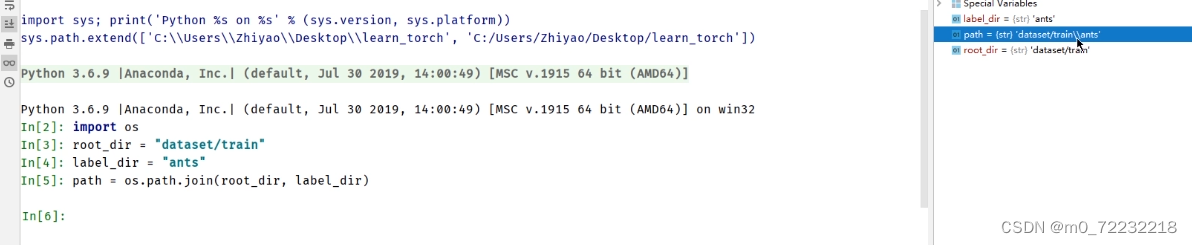
根据def getitem(self, idx):中的idx这个索引去获取
先去获取所有图片地址的一个列表
使用OS去获取
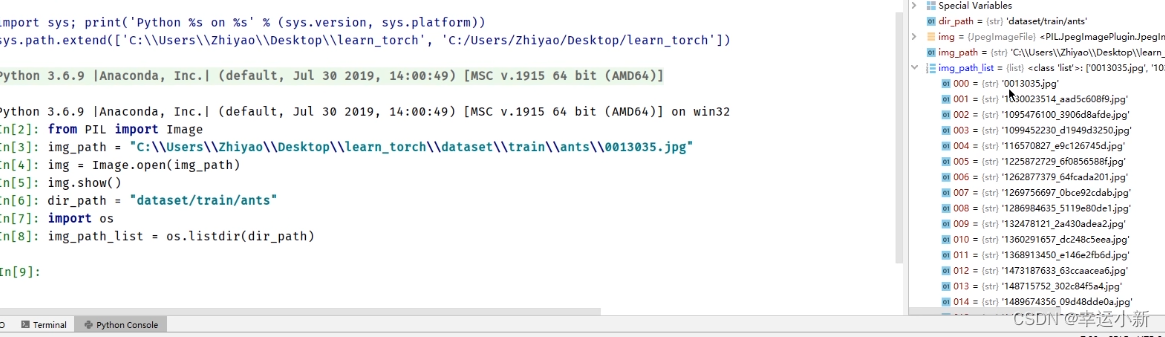
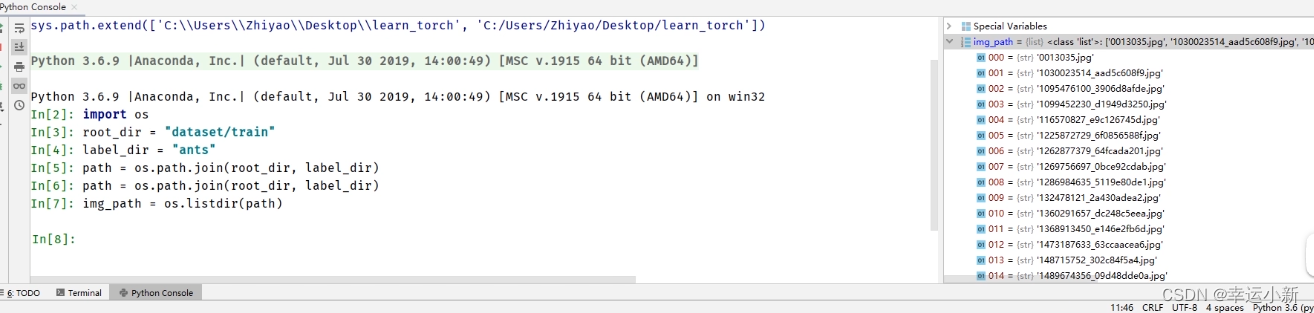
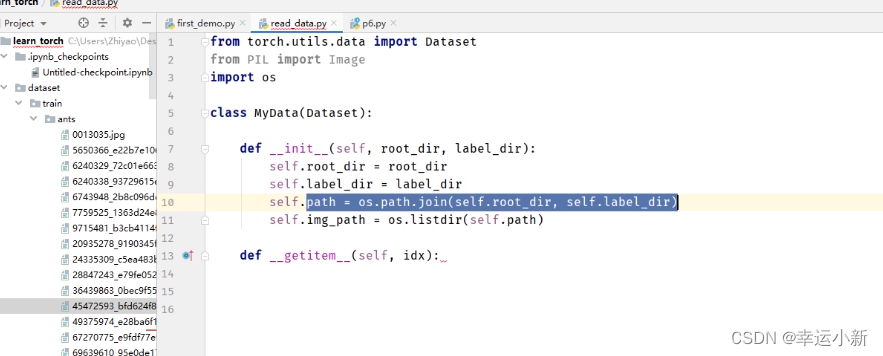
上面我们就是获得了所有图片的地址
下面我们要获取每一个图片
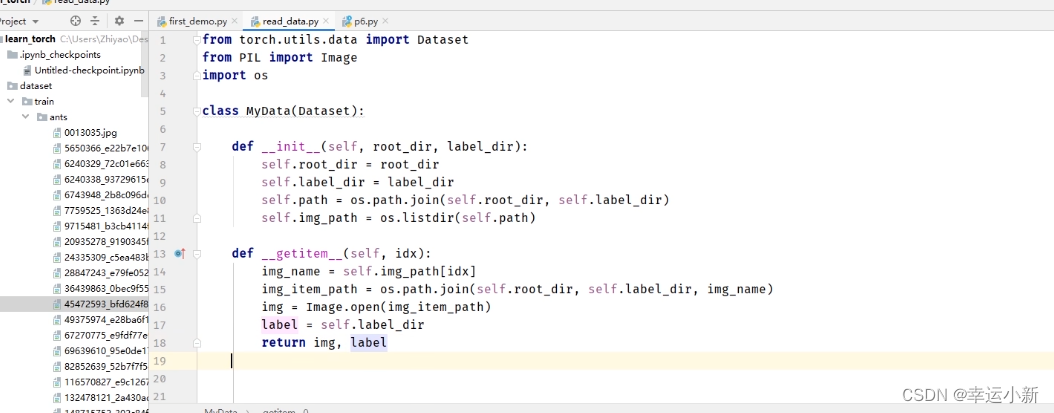
下面考虑这个数据有多长
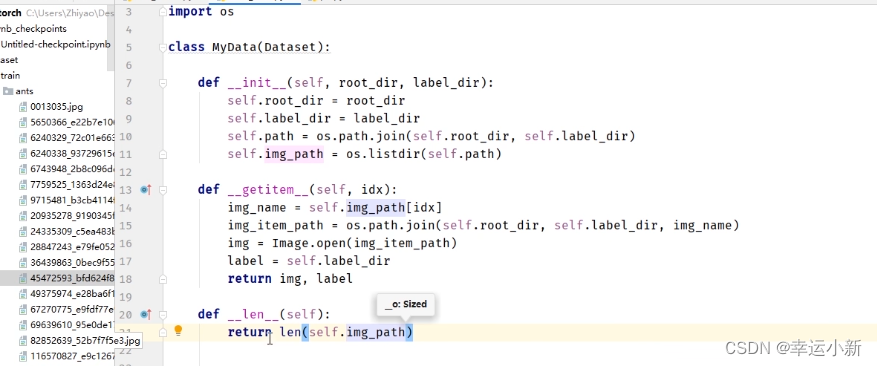
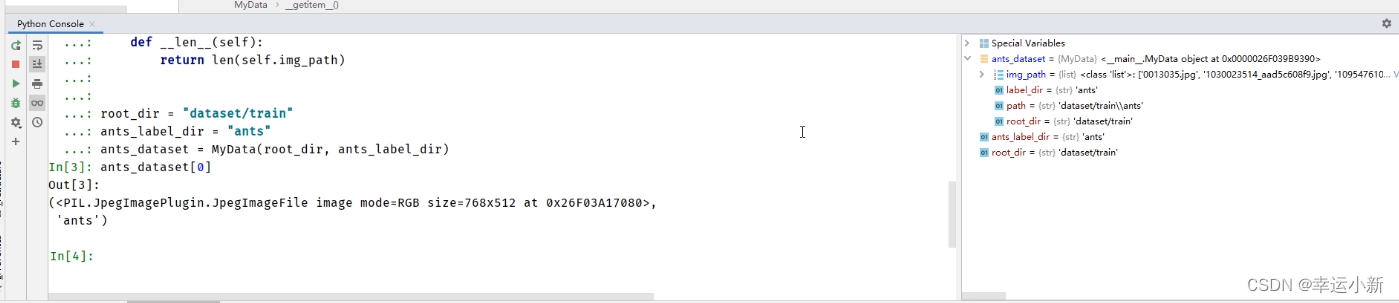
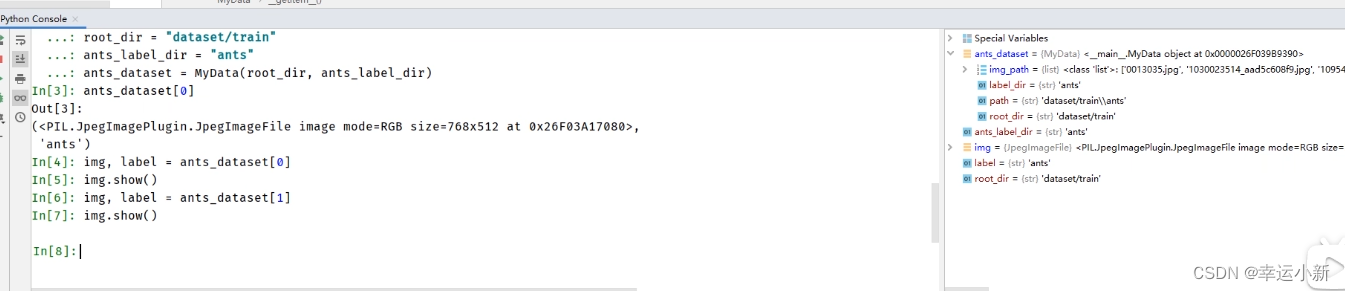
如果我们想要获取蜜蜂的数据集
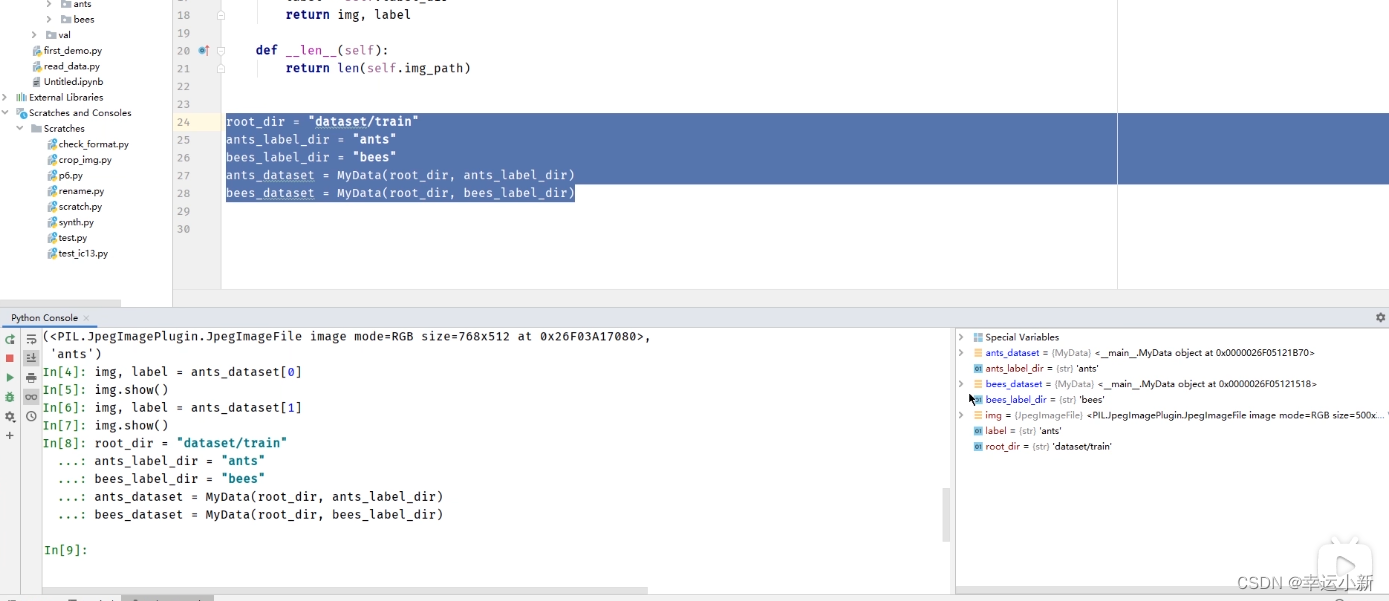
我们训练数据集就是这两个数据集的一个集合
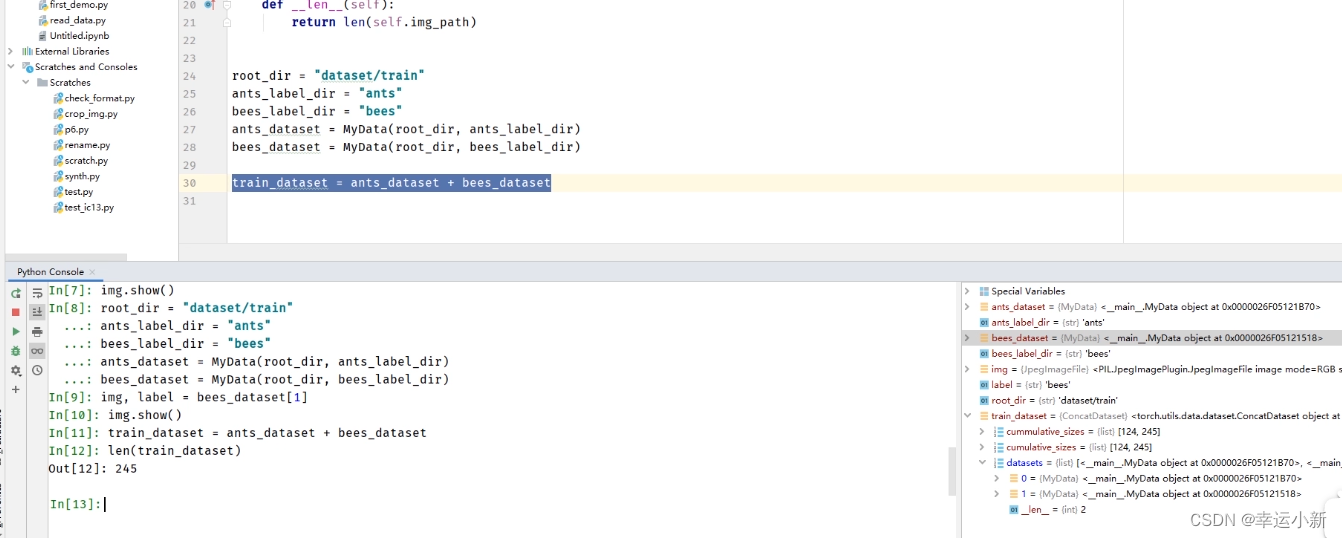 如果我们将数据集进行另外一种形式的表达
如果我们将数据集进行另外一种形式的表达
每一张图片对应的label
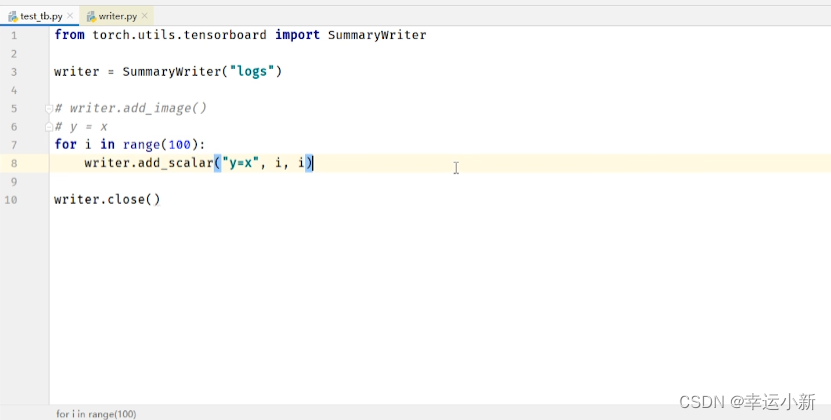
8.TensorBoard的使用(一)

tranform可以我们的图像统一到同一个尺寸
或者对图像中的每一个数据进行一个类的转换
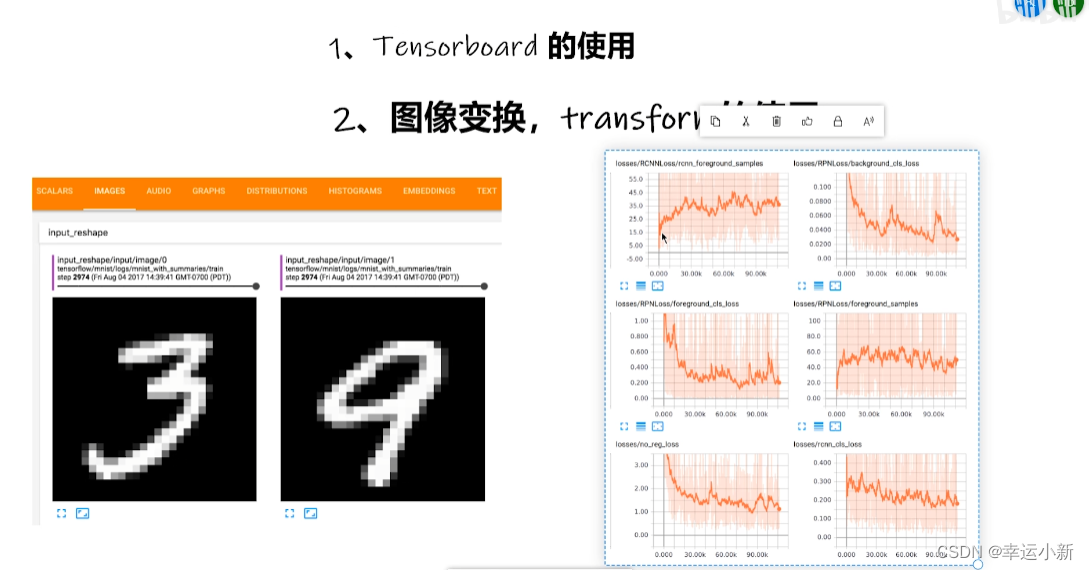
我们一般想知道我们的训练过程中的loss是如何变化的
通过这个loss知道我们的训练过程是否安装我们预想的变化
我们也可以从相应的loss中去看一下我们选择什么样的模型
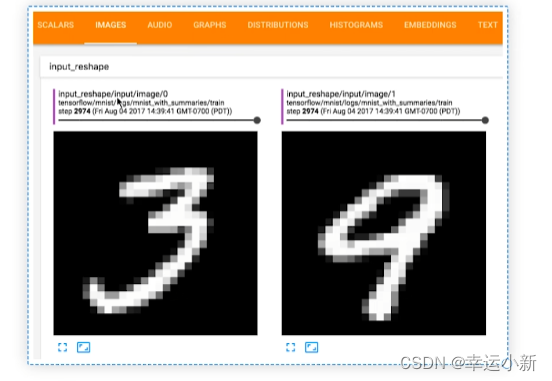
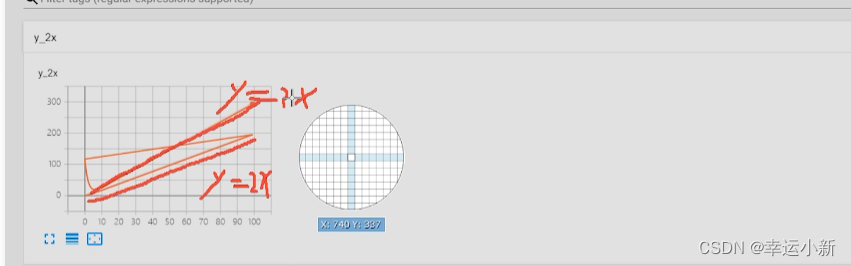
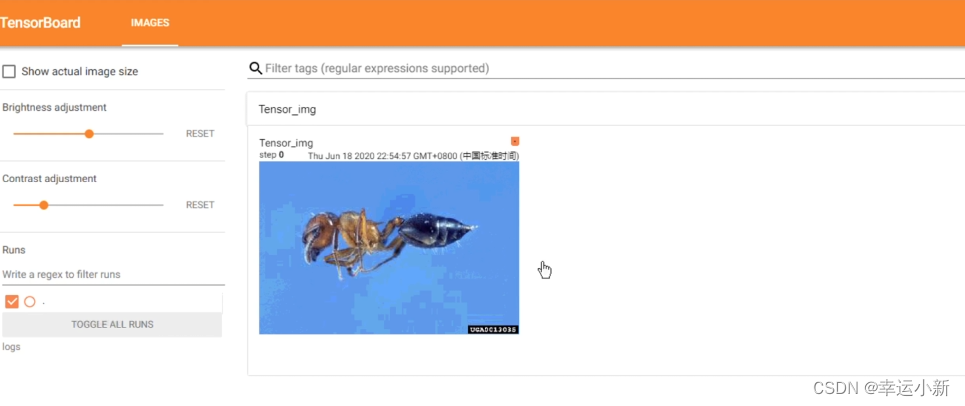
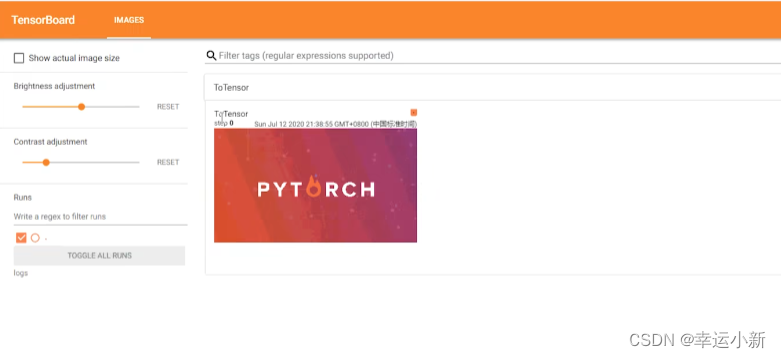
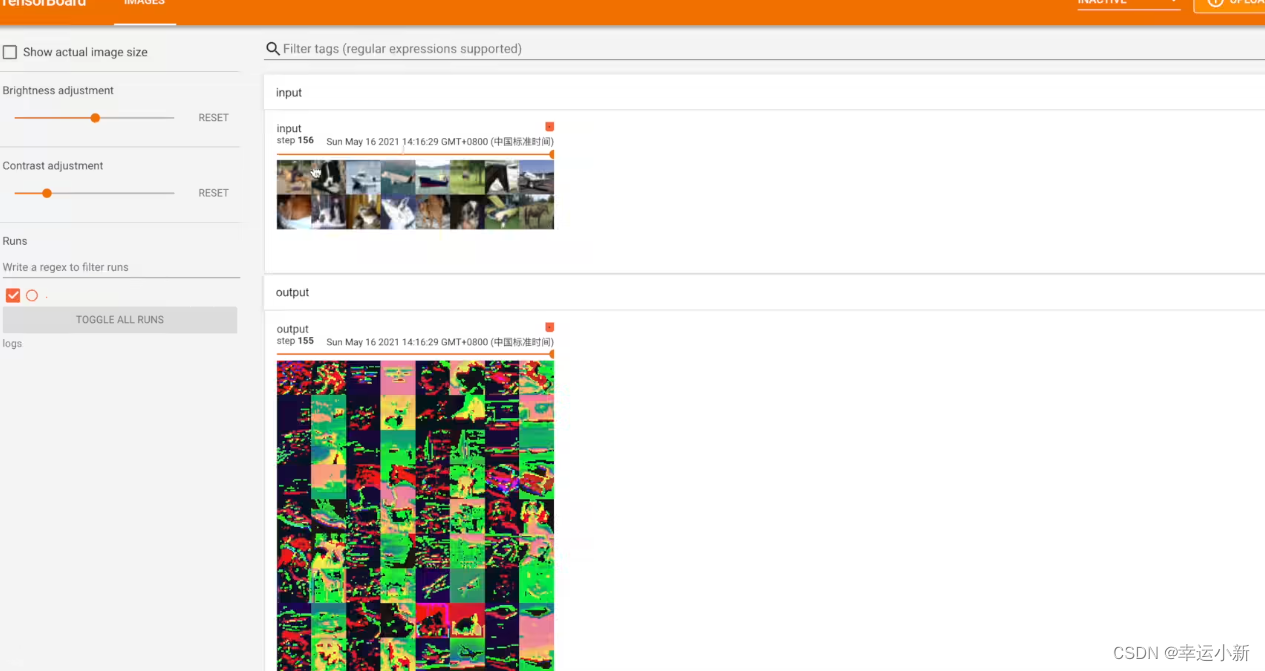
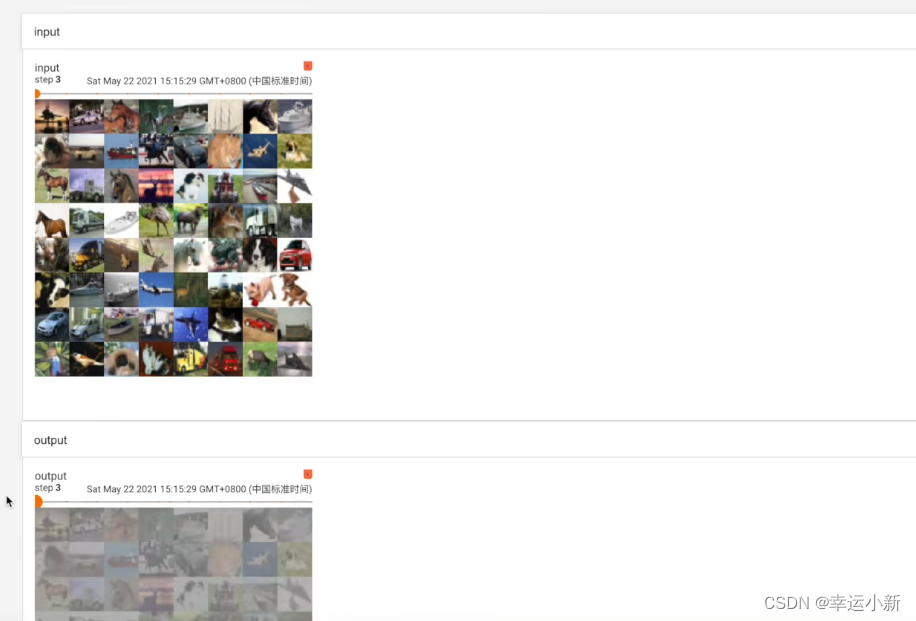
上面这个图就是在外面的2974步输入的图像
这个TensorBoard可以帮助我们探究一些模型在不同的阶段是如何输出的

首先打开项目文件夹,设置环境


查看如何使用

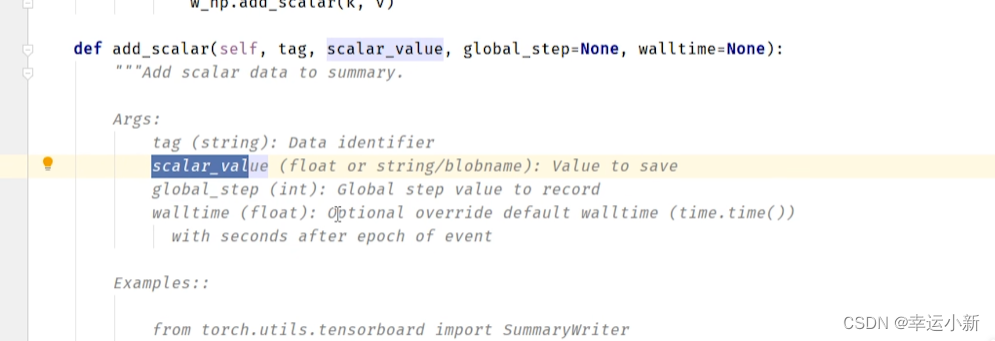
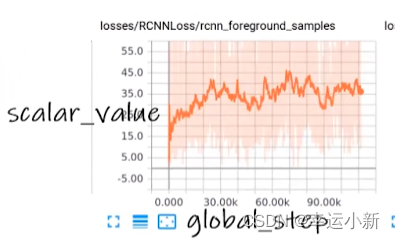
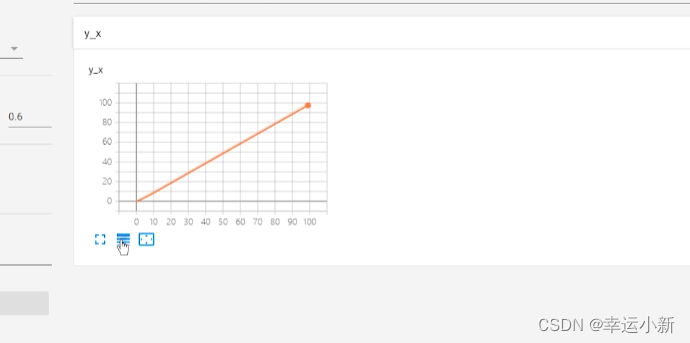
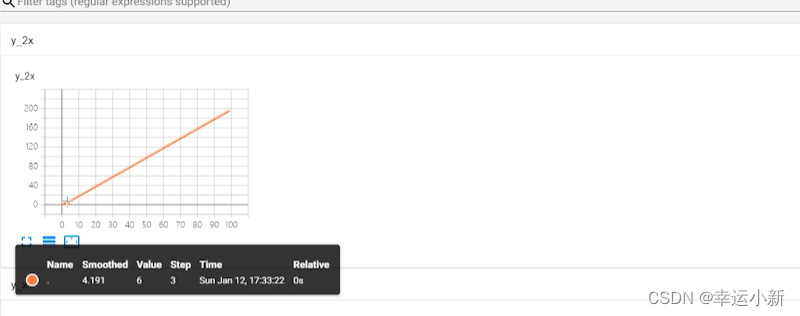
tag就是图表的title
scalar_value是我们对应的数值,y轴
global_step是我们训练到多少步,x轴
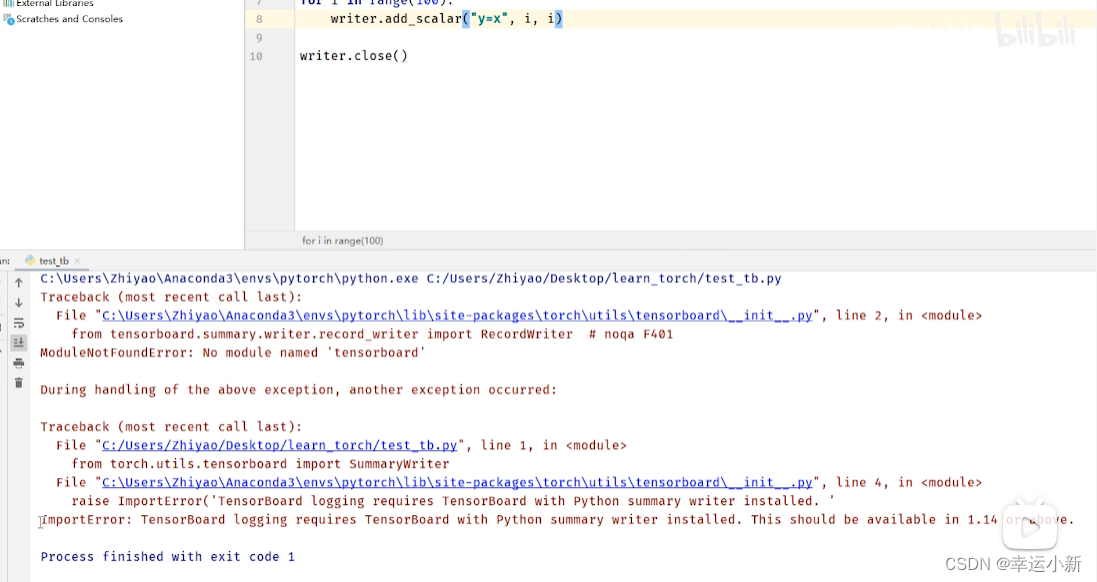
我们没有还没有安装tensorboard这个包

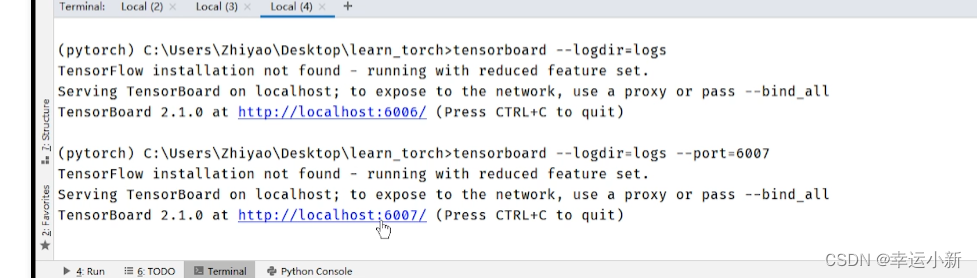
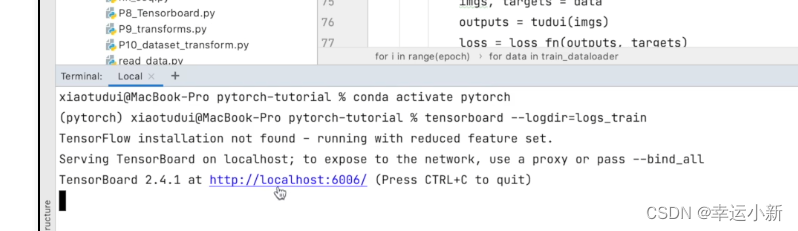
如果在一台服务器上有好几个人训练
可能端口会冲突
我们可以指定一下这个端口
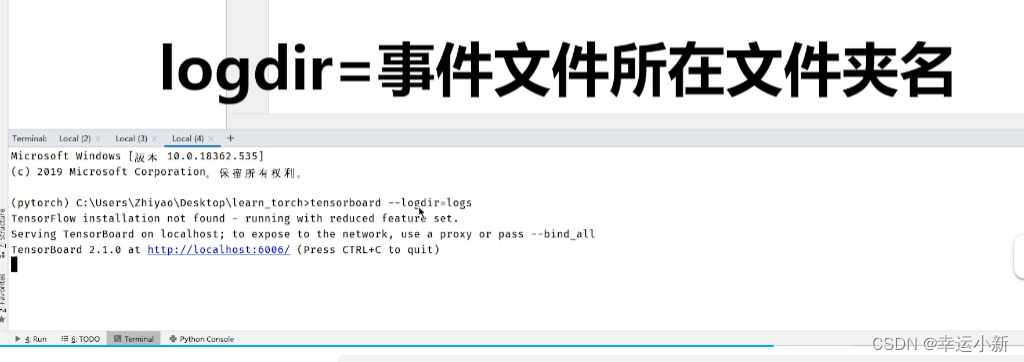
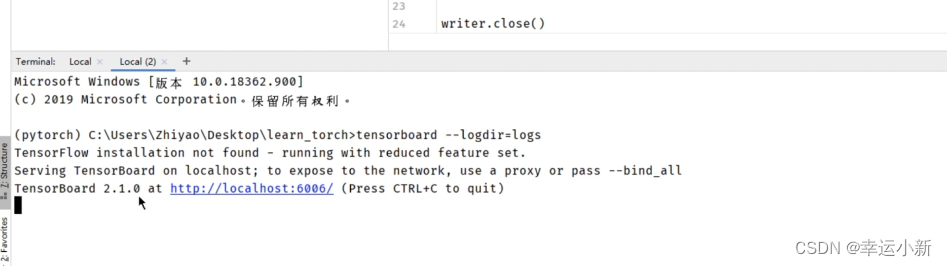
tensorboard --logdir=logs
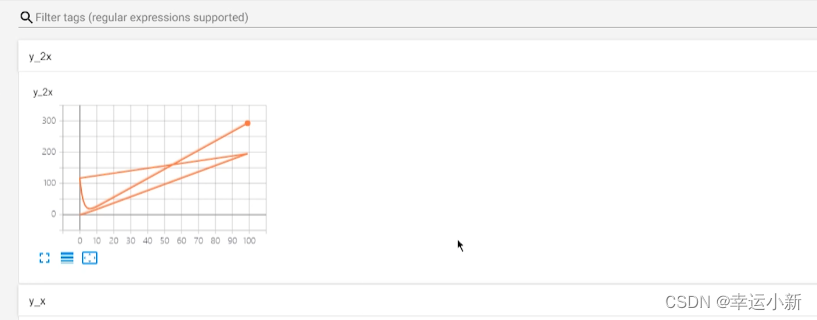
write写入一个新的事件当中
其实也进入了上一个事件当中
就会出现上面的情况
第一种方法
我们可以将对应的logs下面的文件全部删除
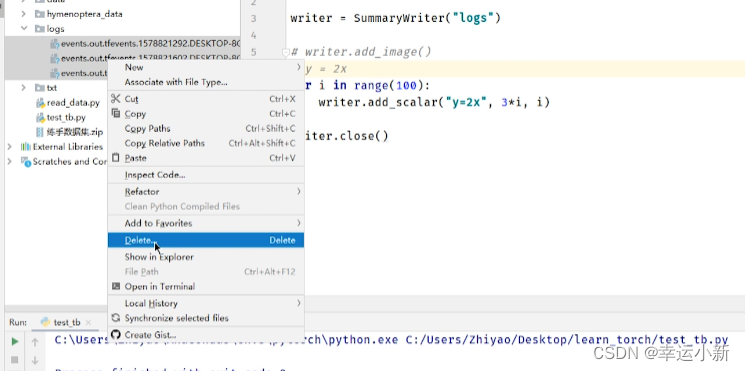
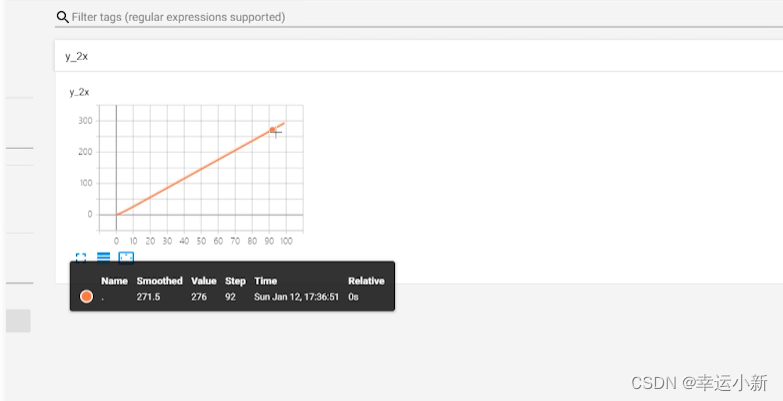
第二种方法
9.TensorBoard的使用(二)


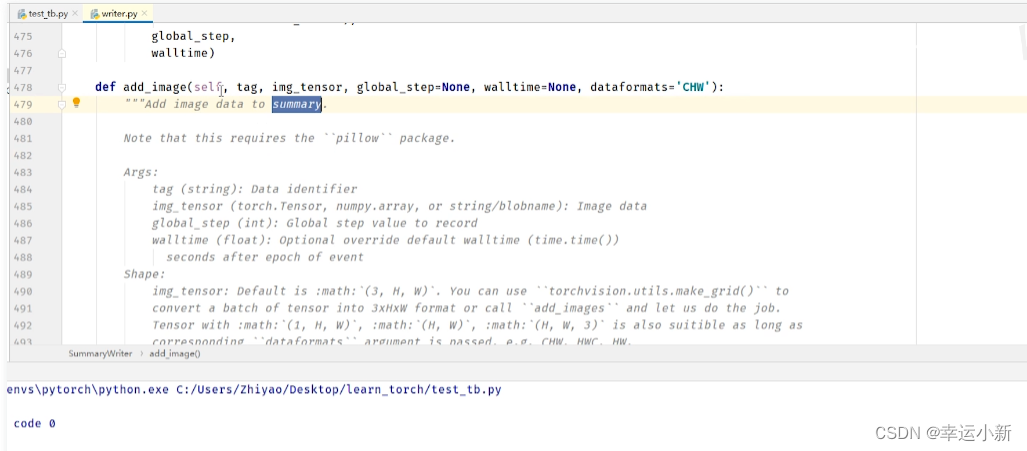
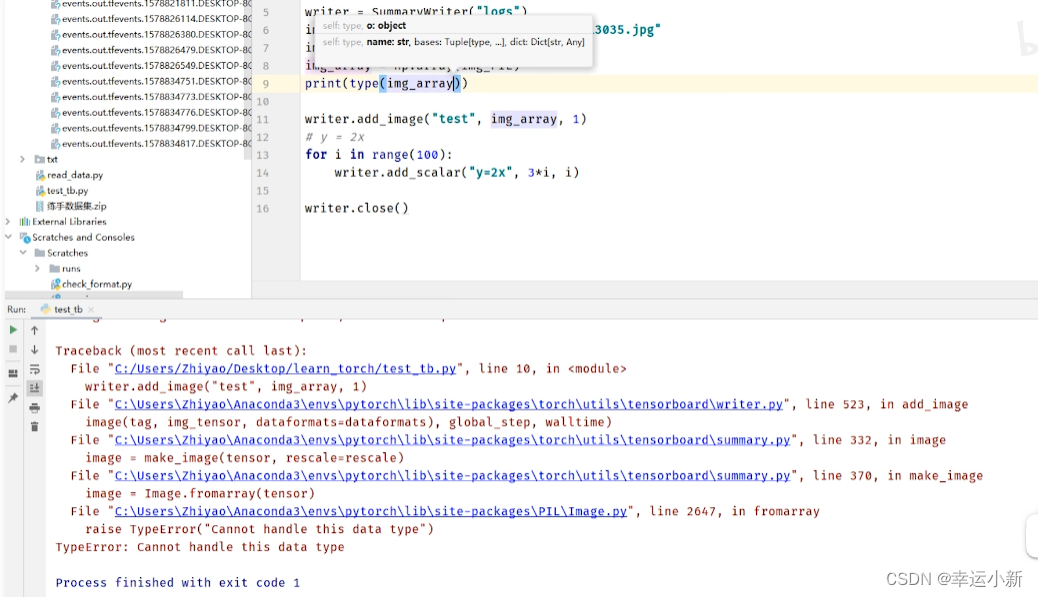
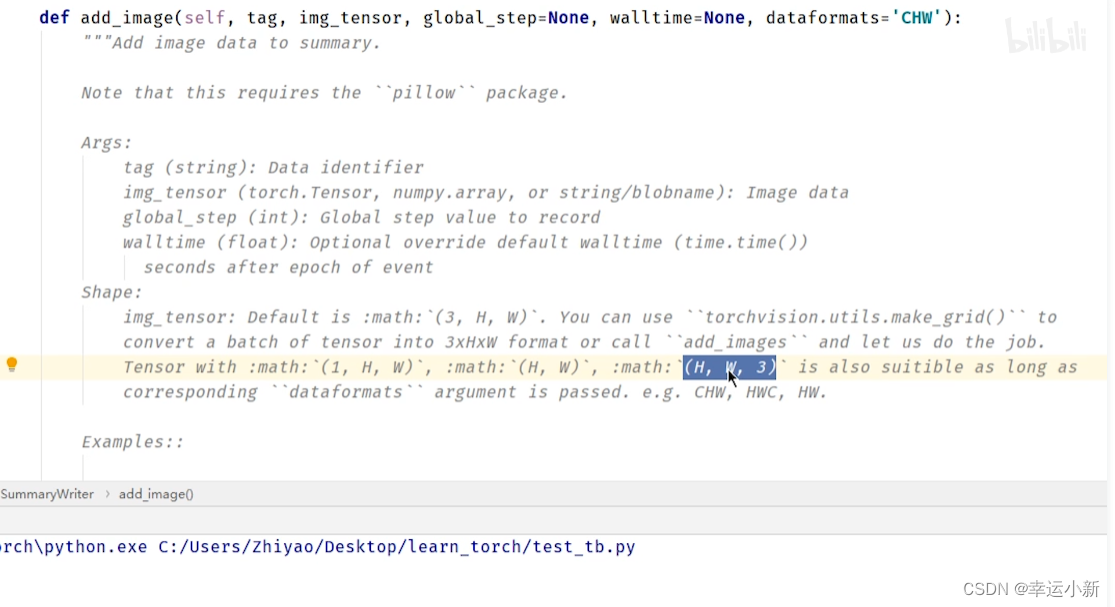
其中的img_tensor要么是torch_tensor型,要么是numpy.array型。。。
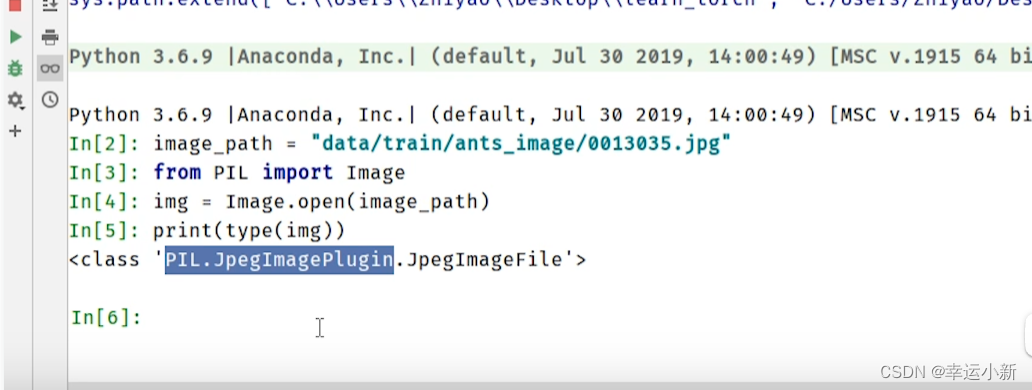
我们这边的图片类型是不满足要求的
我们安装一下opencv

转换为numpy型
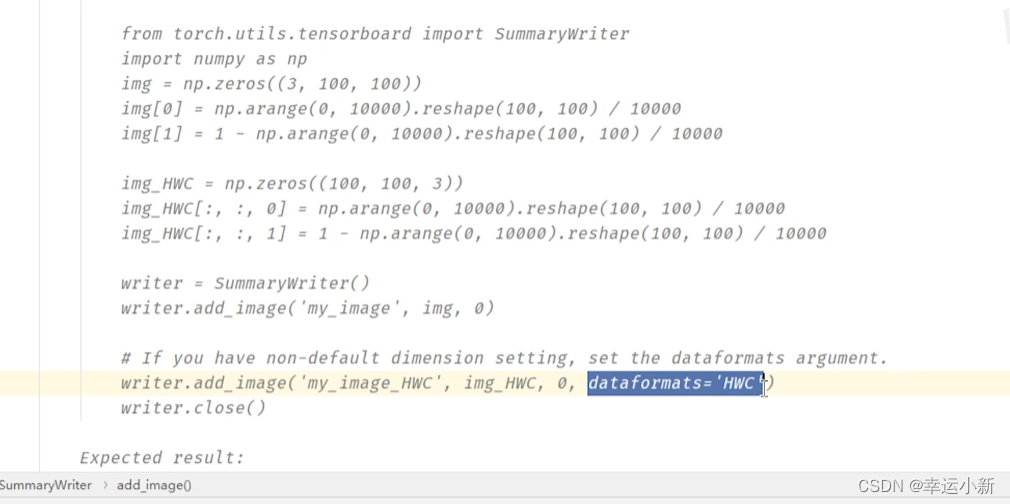
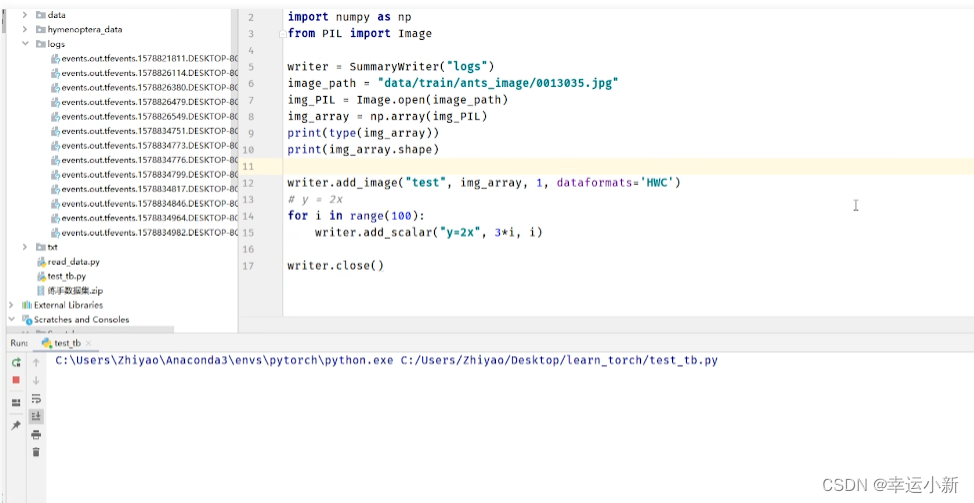

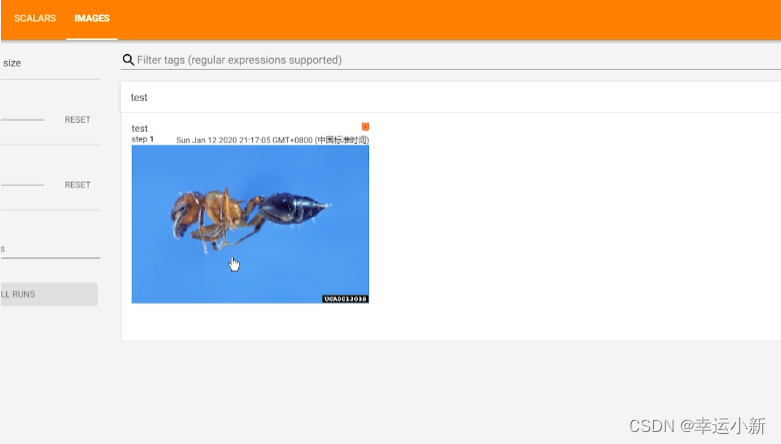
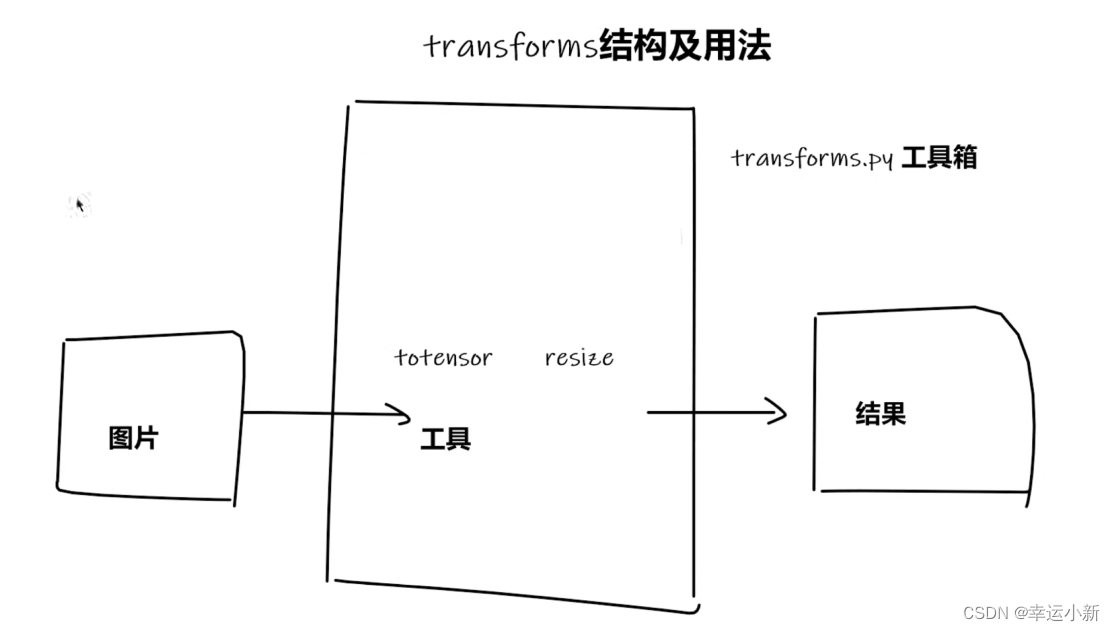
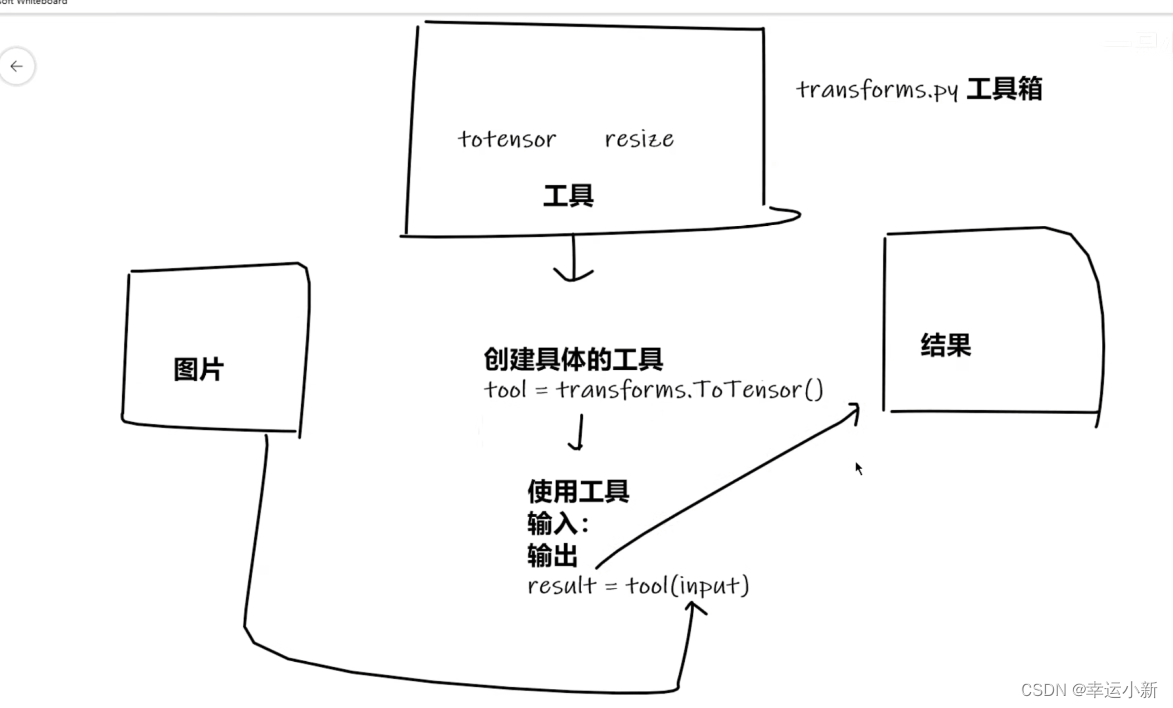
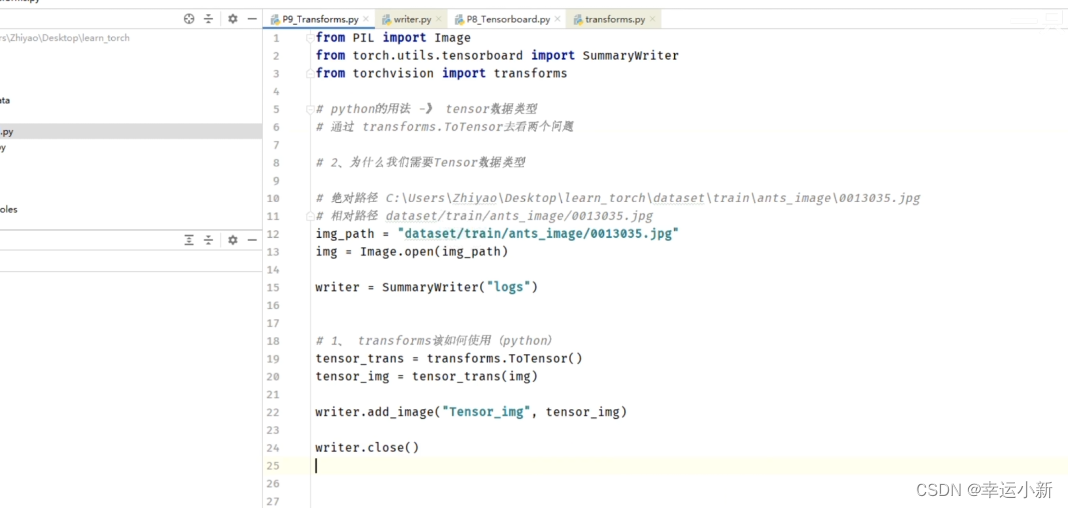
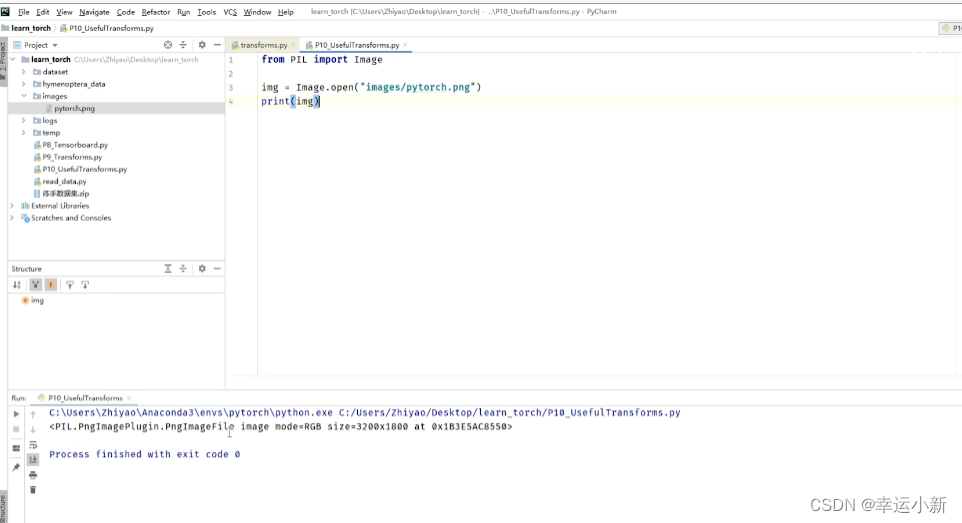
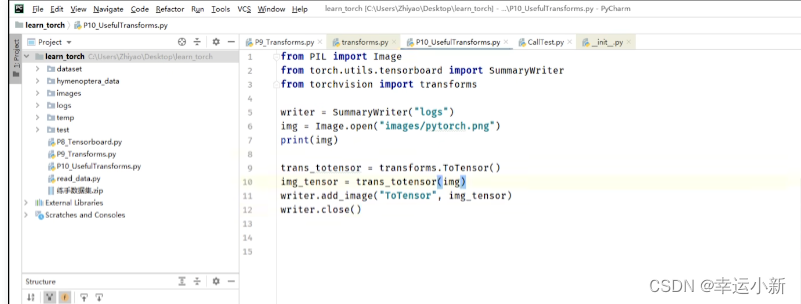
10.Transforms的使用(一)

transforms主要用来对图片进行一些变换
左边的structure可以看它的结构
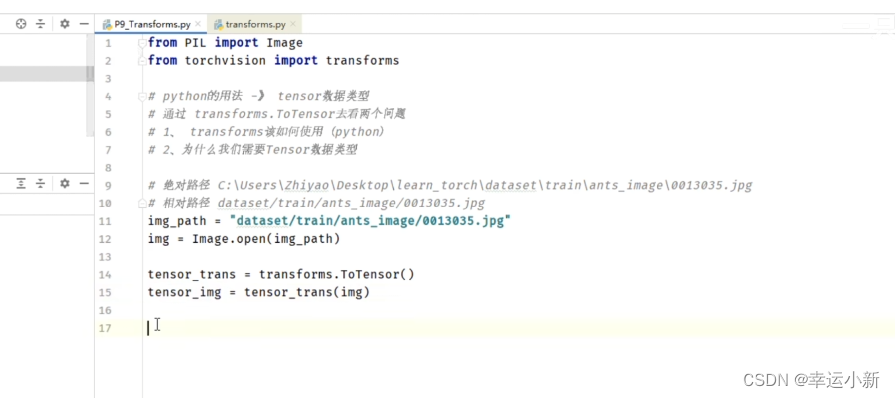
我们上面就是将img类型的图片转换为我们tensor类型的一个图片
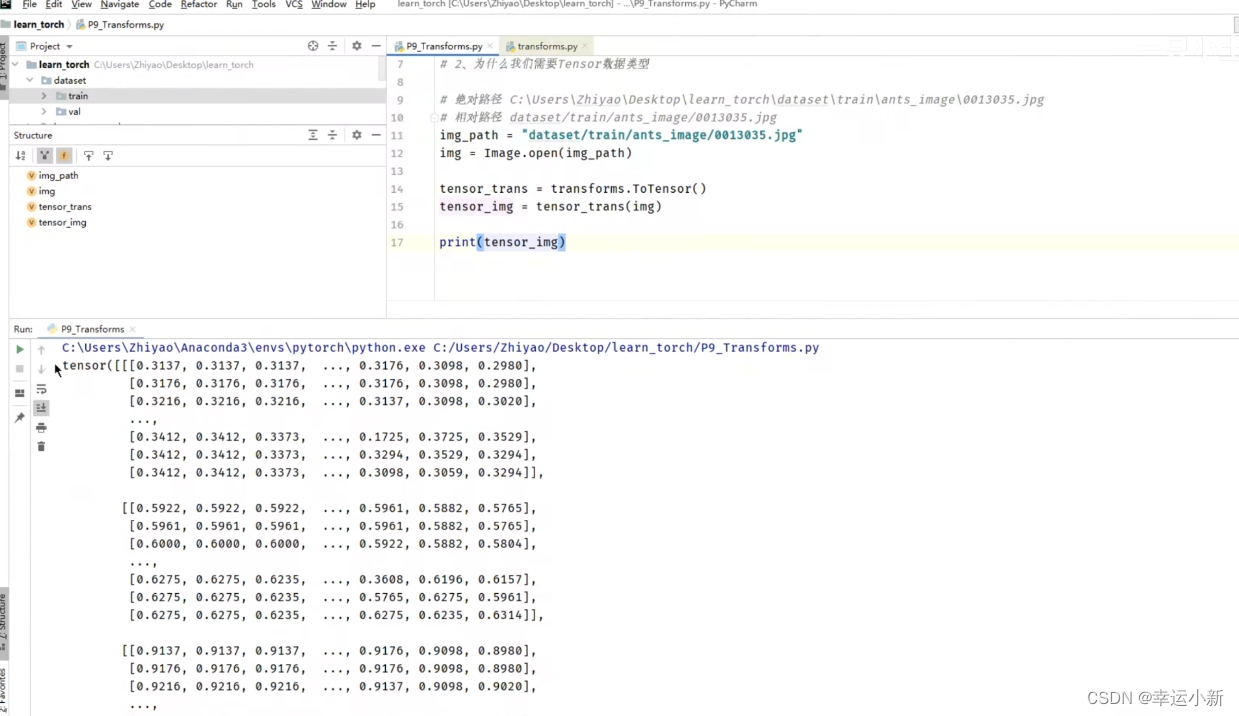
11.Transforms的使用(二)
我们为什么需要tensor这个数据类型
tensor包装了我们神经网络所需要的一些参数
我们在神经网络中一般先把数据转化为tensor型,然后进行一些训练
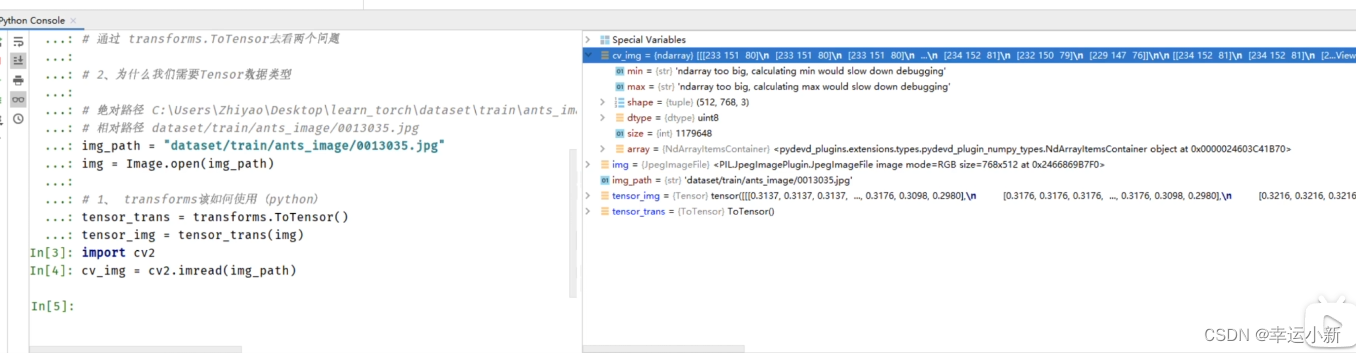
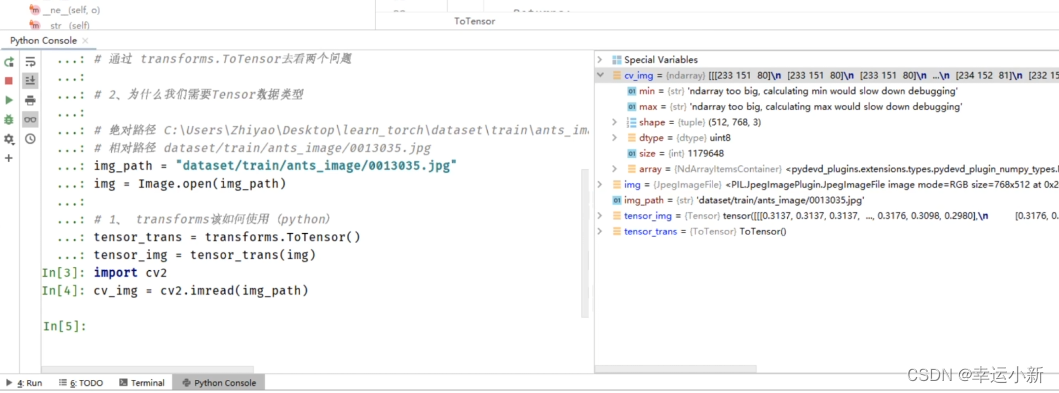
我们上面学习了PIL Image类型的读取
那么如何读取numpy类型的呢
最常用的就是使用opencv
我们安装一下OpenCV
pip install opencv-python( conda install py-opencv)
12.常见的Transforms(一)


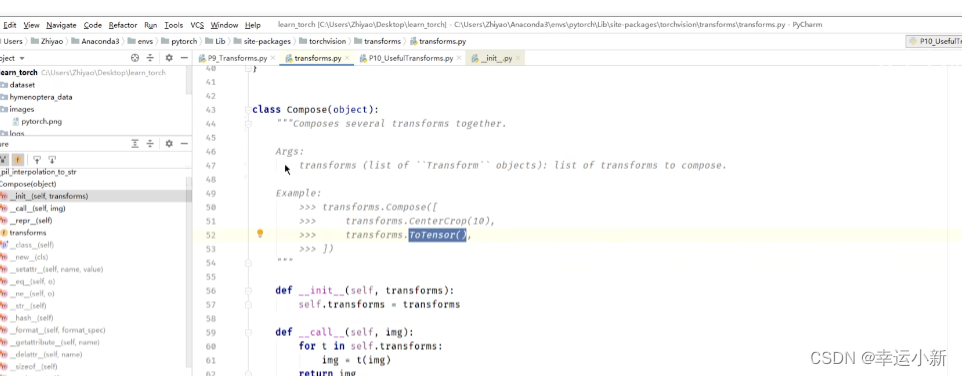
compose是将图片进行一个中心的裁剪然后转换为tensor

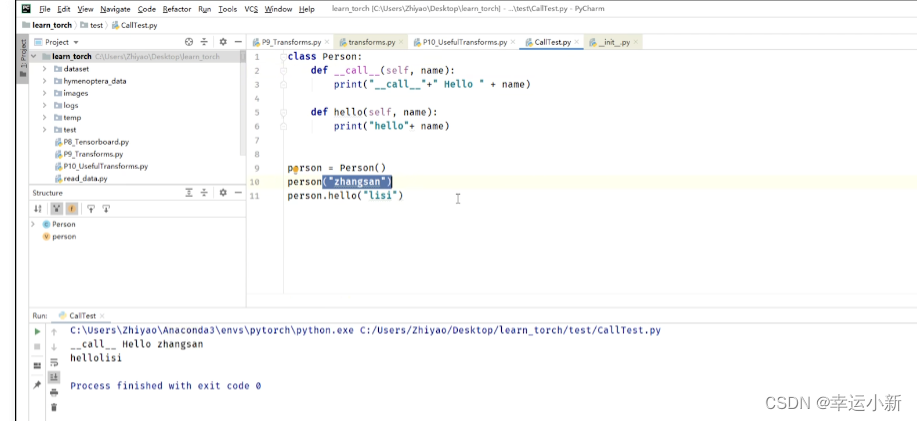
_ _ cal l_ _ 可以直接调用

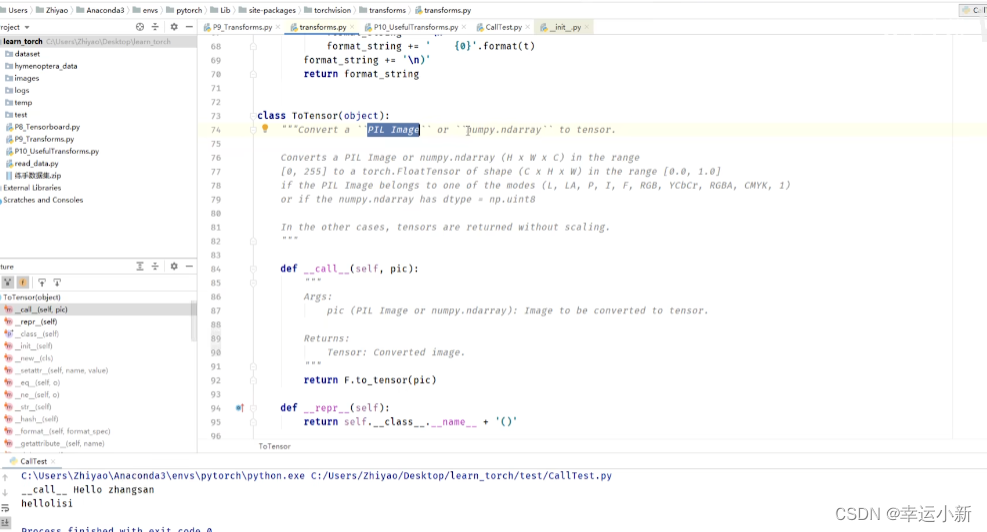
输入必须是一个PIL Image或者numpy类型转换为一个tensor类型

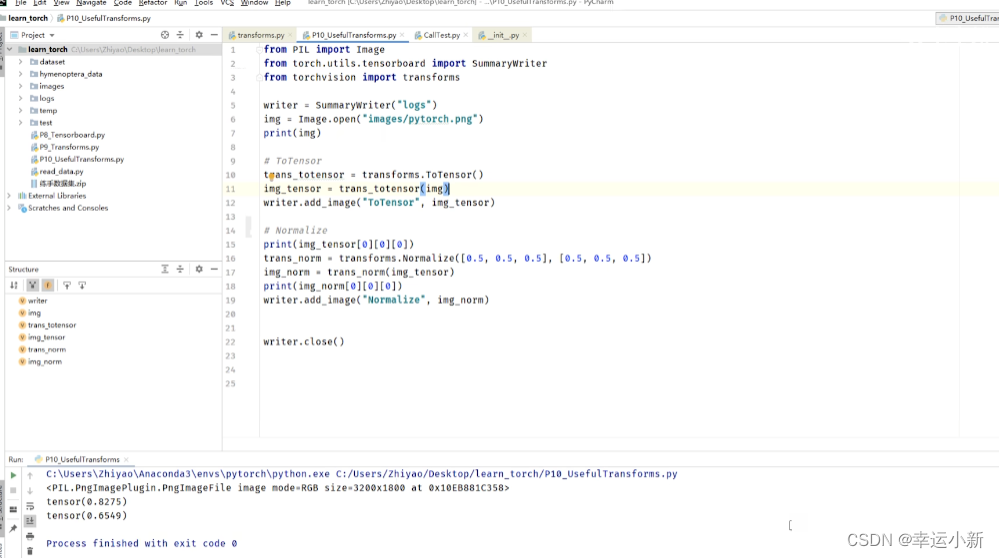
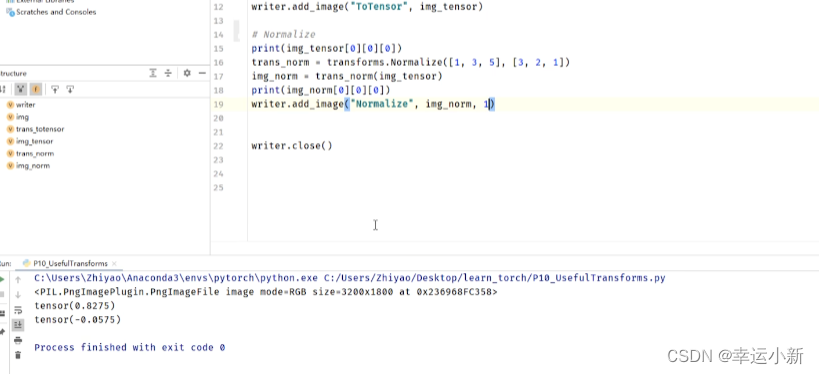
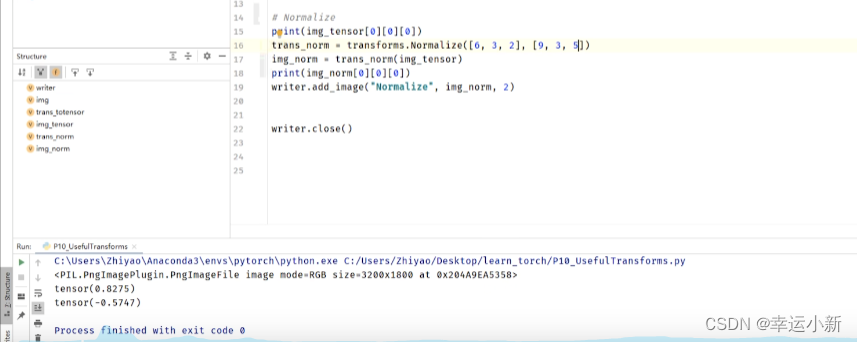
归一化
输入必须是一个tensor类型
用平均值和标准差对张量图像进行归一化
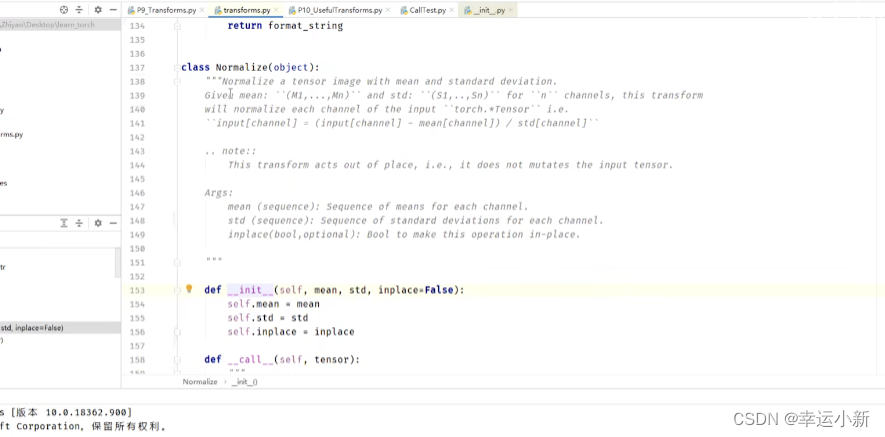

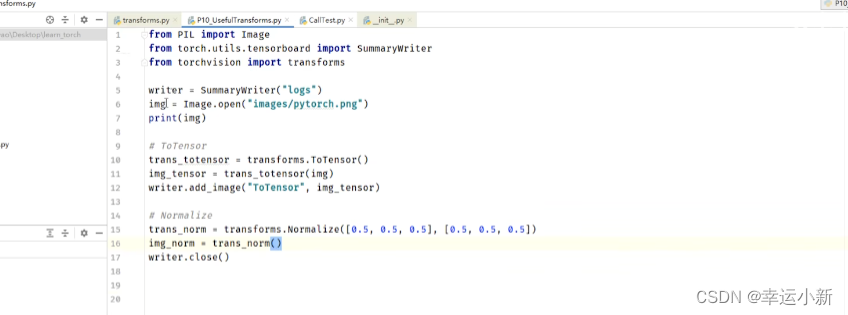

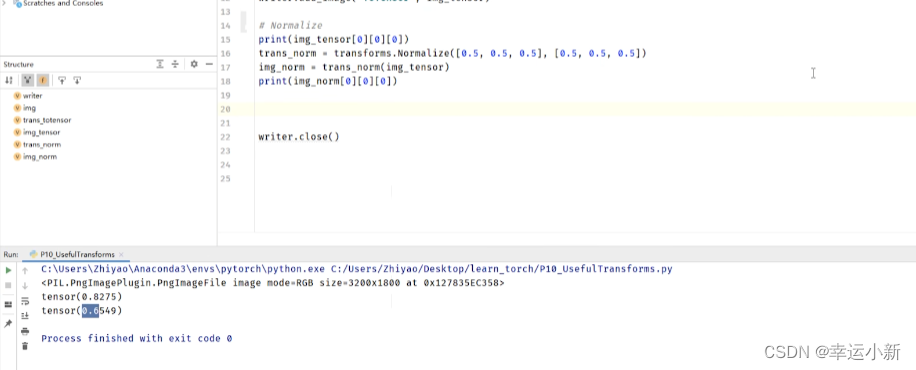
输入的img_tensor有三个通道,人为设置均值和标准差都是0.5,
然后利用公式算的输出值img_norm
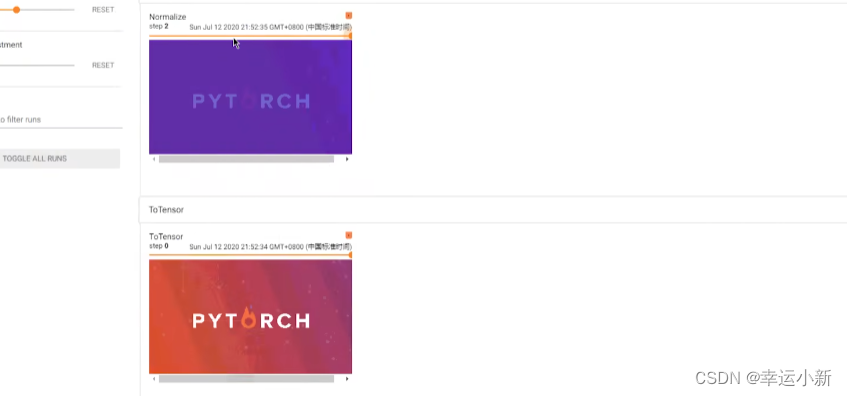
下面就是我们归一化后的一个结果
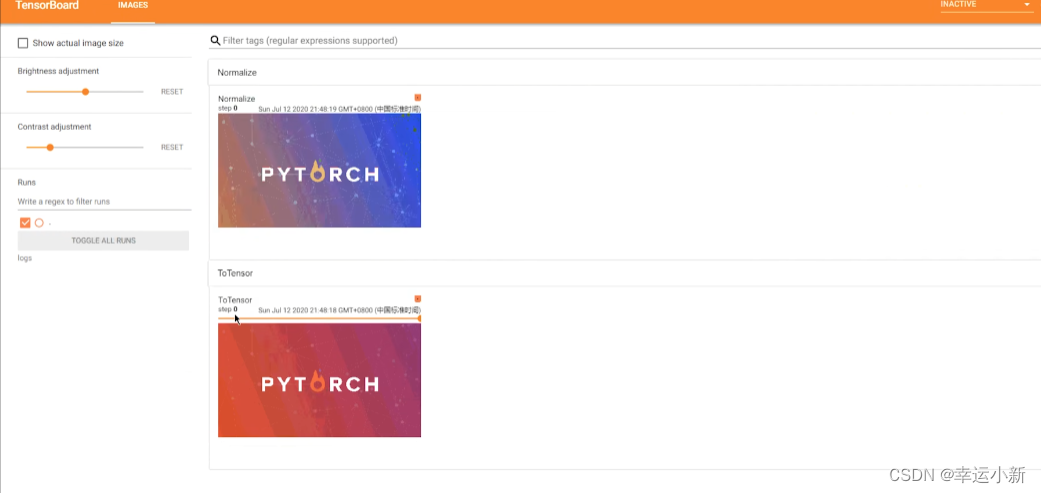
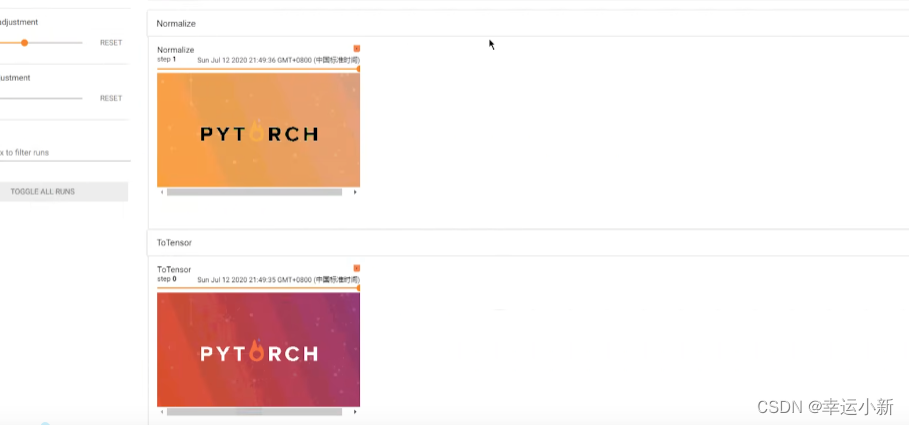

一般图像多少RGB,三通道
13.常见的Transforms(二)
输入是PIL Image类型
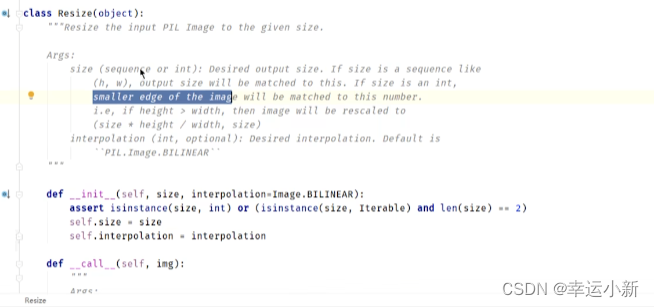
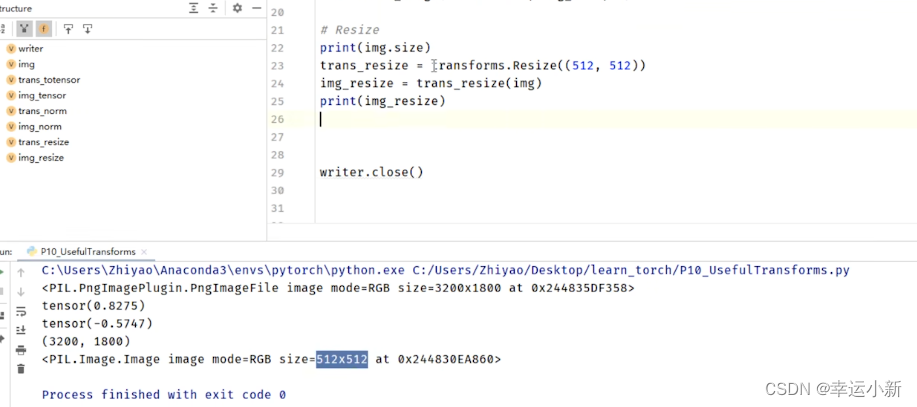
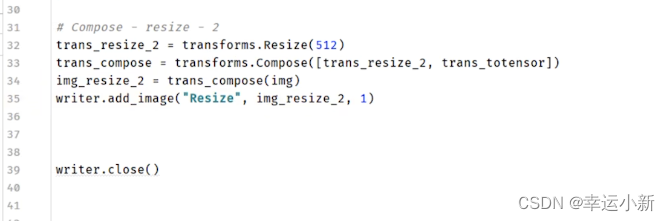
尺寸由原来的3200 * 3200 变为 512 * 512
输出的是PIL Image类型
如果我们想要在tensorboard进行显示的话
我们要将img_resize变为totensor的一个数据类型
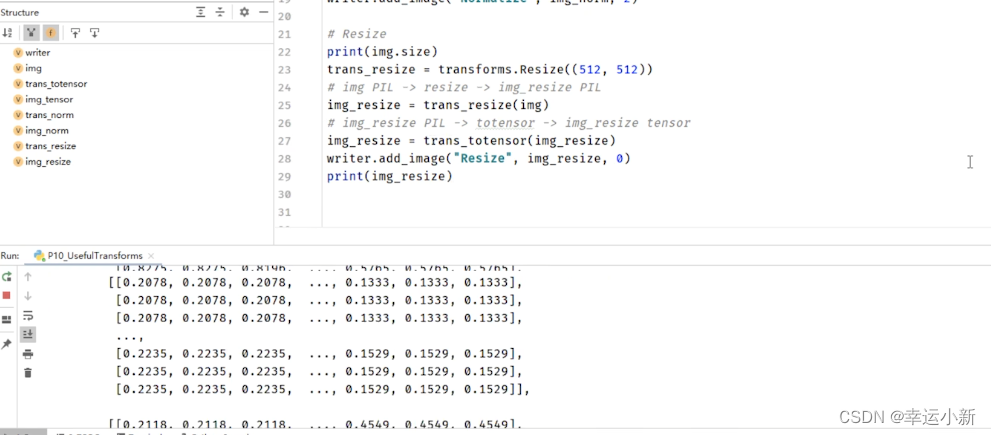
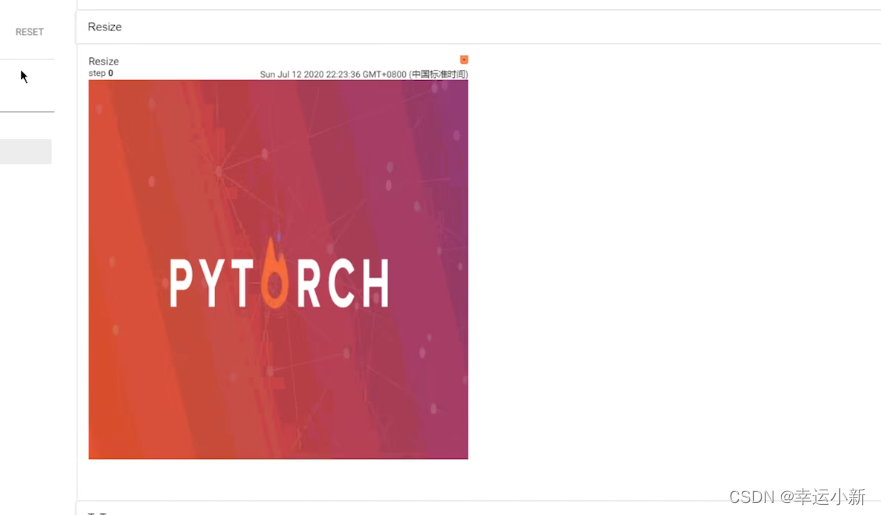

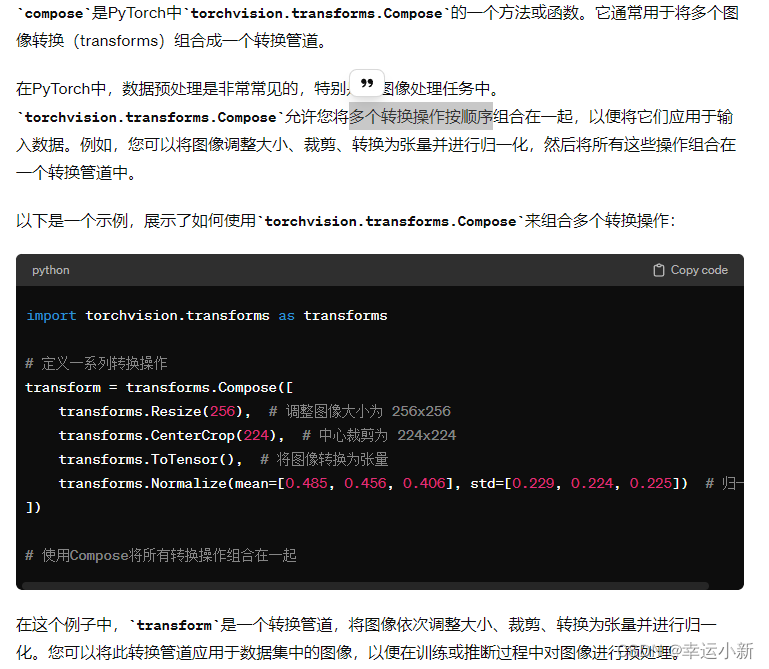
当你对一个图像应用trans_compose变换时,它首先会使用trans_resize_2进行尺寸调整,然后使用trans_totensor将PIL图像转换为PyTorch的Tensor。
这个参数是个列表
其实就是将resize变换和totensor合并了
所以列表两个参数代表这两个过程合并。


下面我们看另外一个方法
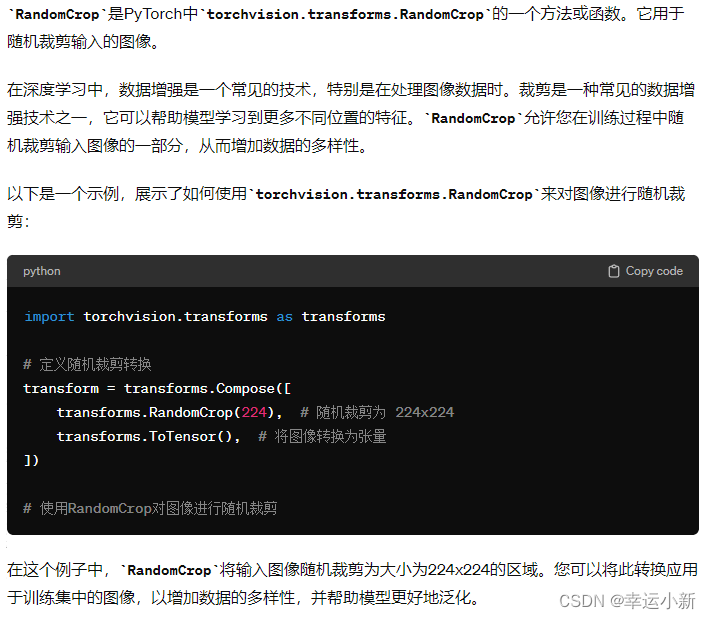
随机裁剪

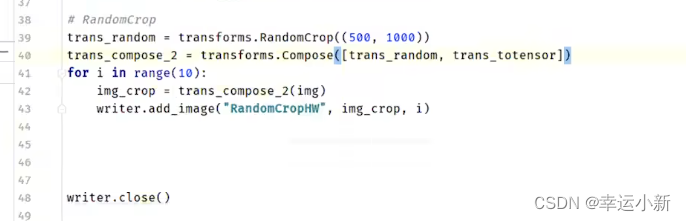



14.torchvision中的数据集的使用
介绍如何将数据集和我们的transforms结合在一起
在科研当中一些标准的数据集如何去下载、组织、查看、使用
下面是官网提供的数据集
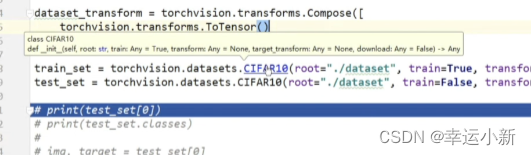
比如其中的CIFAR10数据集一般用于物体识别
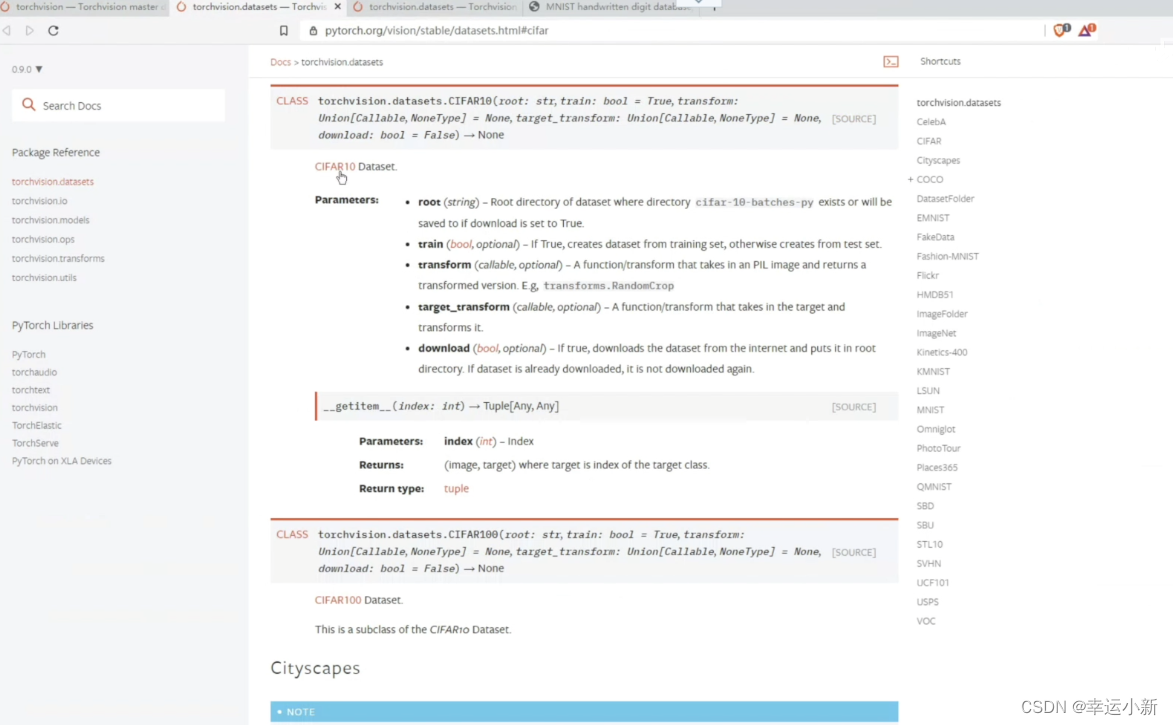
root表示数据集在什么位置
train为true的话表示为训练集、false表示为测试集
transform表示我们想对训练的数据集进行一个什么样的变化
target_transform表示对target进行一个transform
download如果为true的话,会从网上自动给我们下载这个数据集
torchvision.models中会提供一些预训练好的神经网络模块

介绍如何将数据集和我们的transforms结合在一起
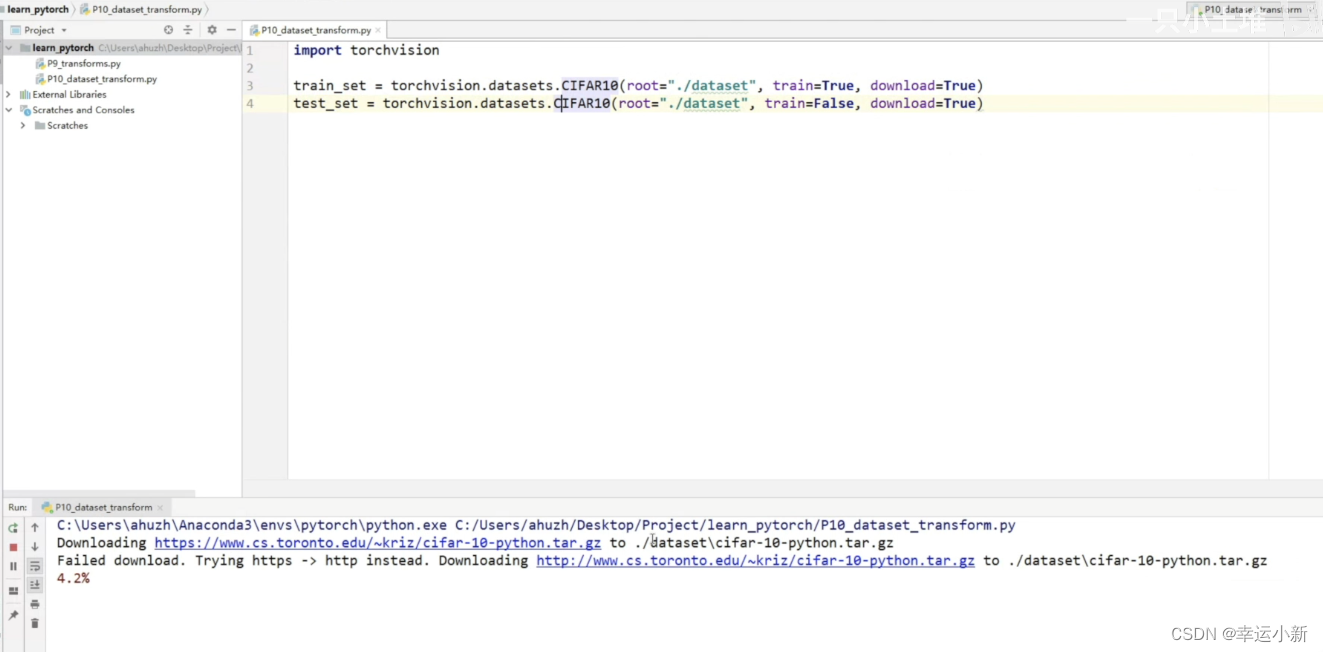
这里会在我们的文件夹下创建dataset,并且下载CIFR10数据集到其中
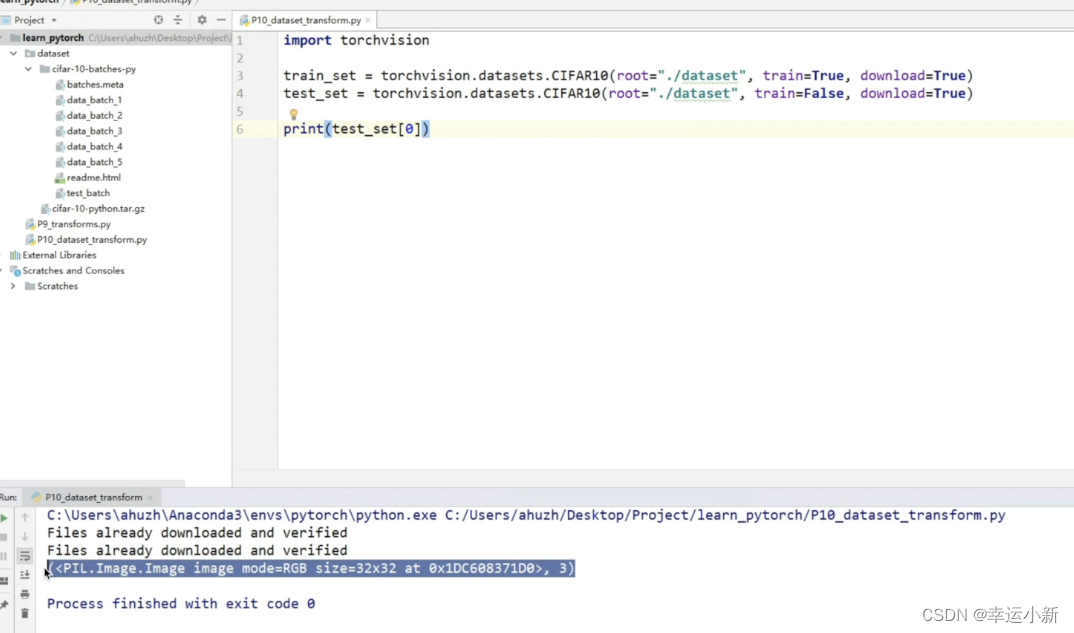
前面是我们的输入图片
后面是我们的target类别,这里将我们的真实类别表示为一个数字3
如果target为0,就是airplane

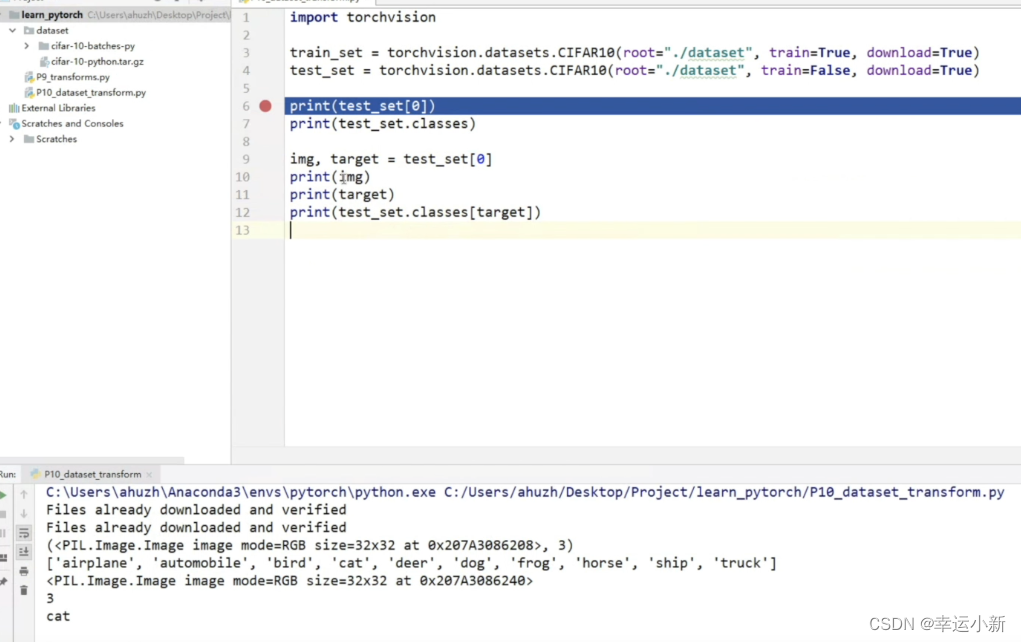
如果我们想要看一下这个图片

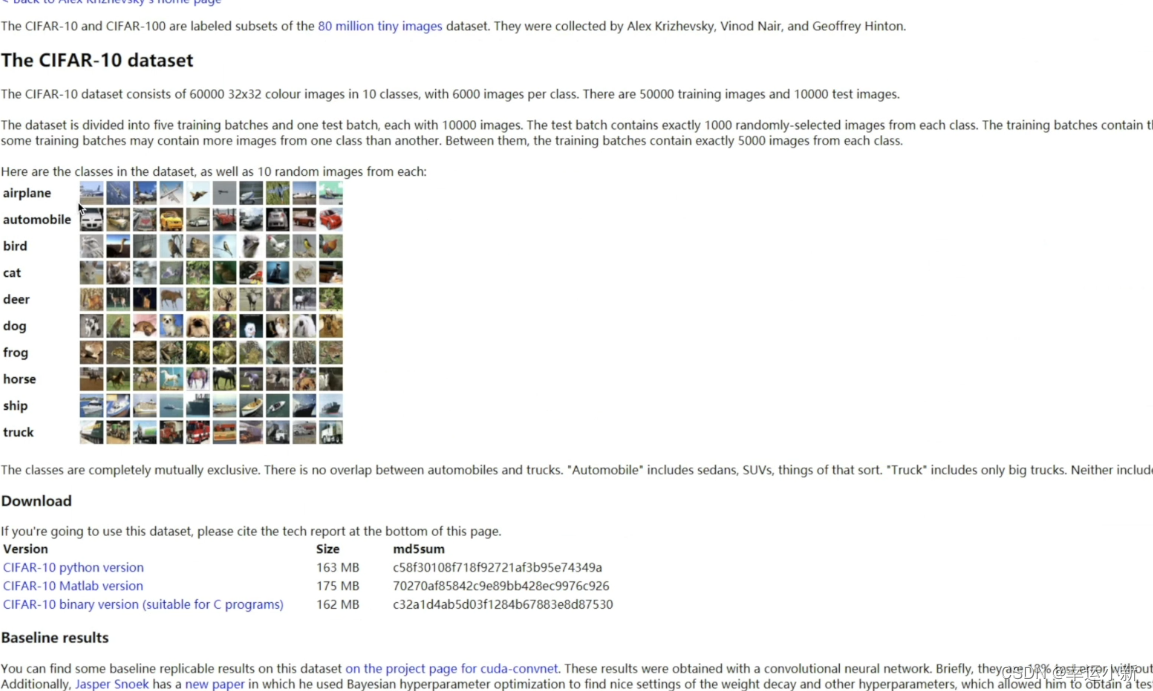
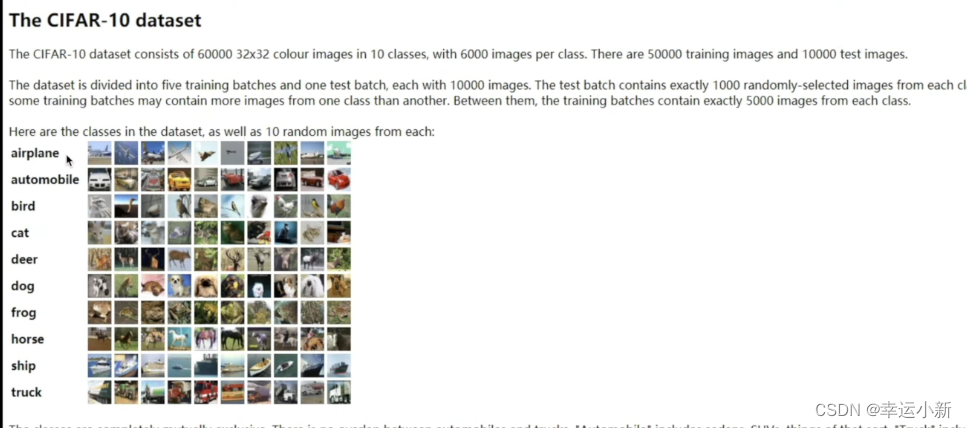
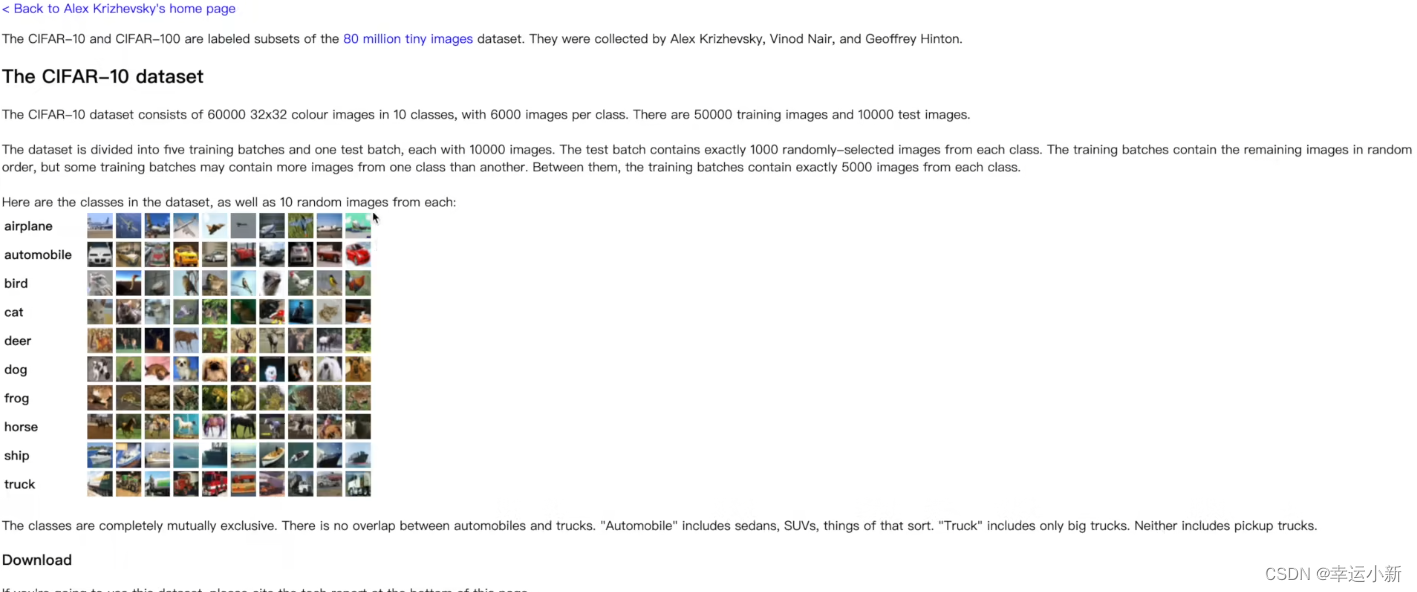
下面介绍一下CIFAR10这个数据集
6万张32 * 32像素的彩色图片,且分为10个类别
5w训练,1w测试
下面和我们的transform进行联动
因为我们的原始图片是PIL Image
如果要给我们的pytorch进行使用,需要转为tensor数据类型
这里我们就使用transform
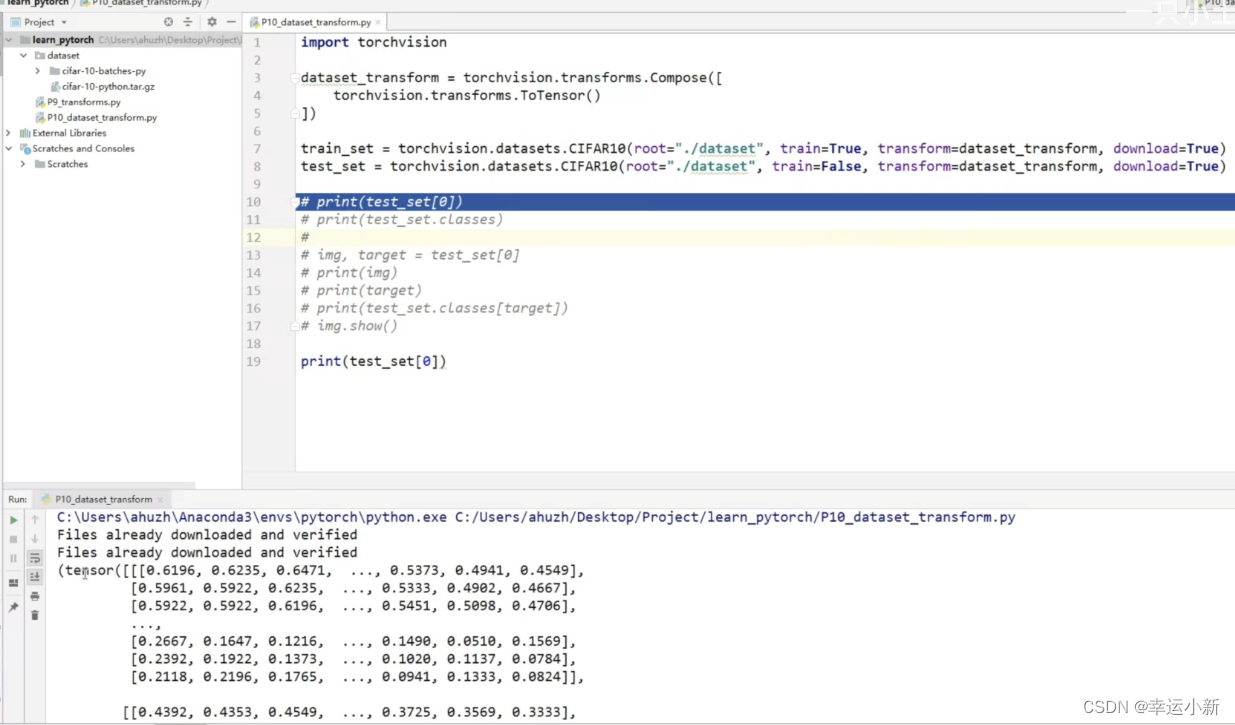
这里就是一个tensor数据类型
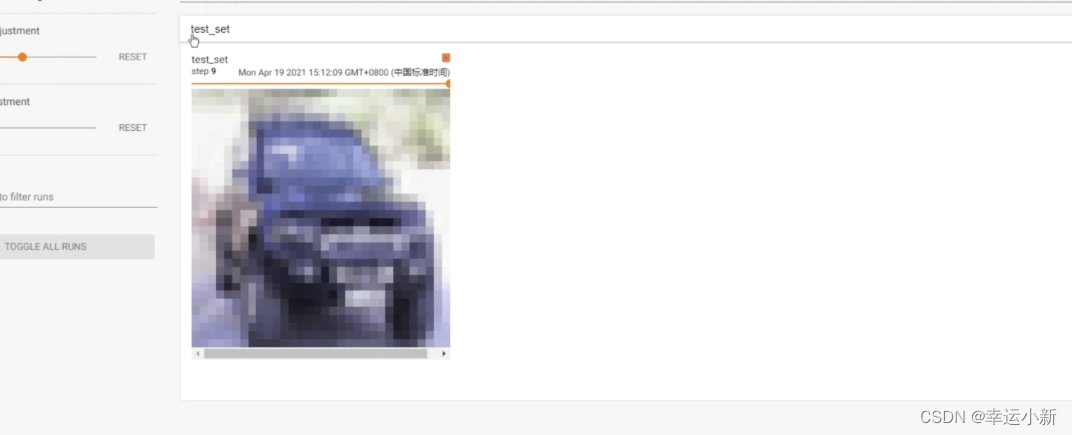
我们也可以使用我们的tensorboard进行一个显示
比如我们想显示测试数据集中的前10张图片
我们下载数据集的时候,可以直接在迅雷上使用URL链接进行下载
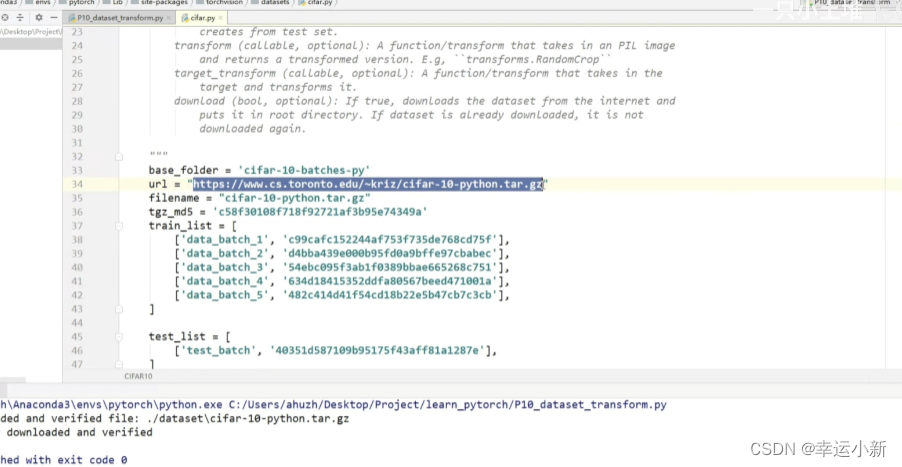
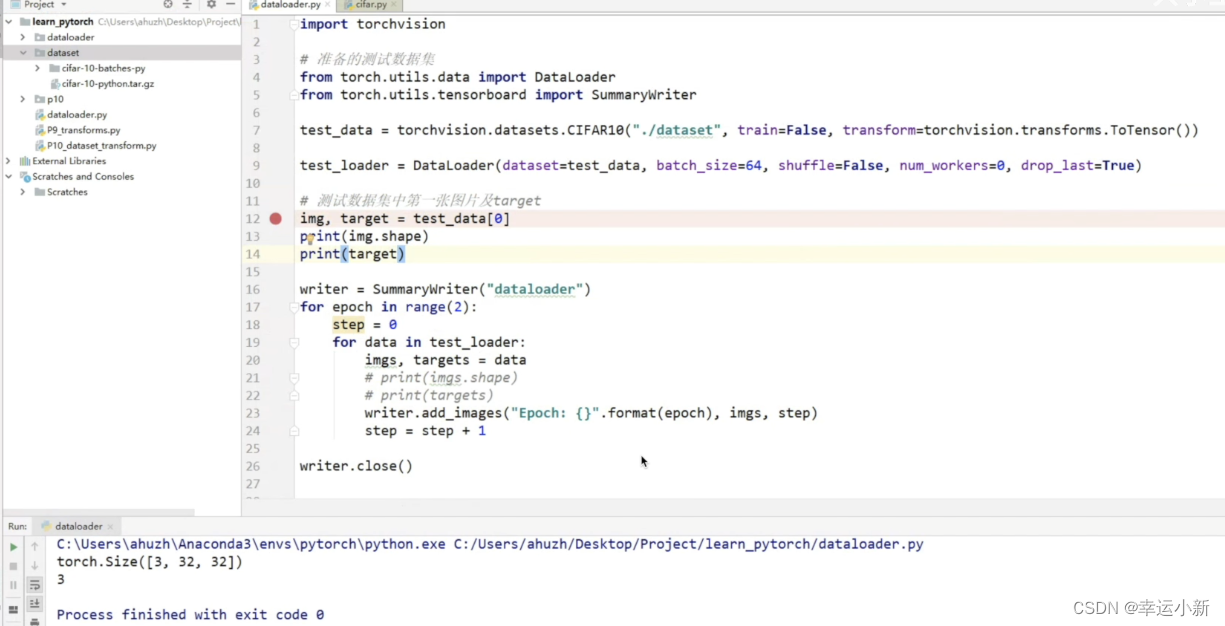
15.DataLoader的使用

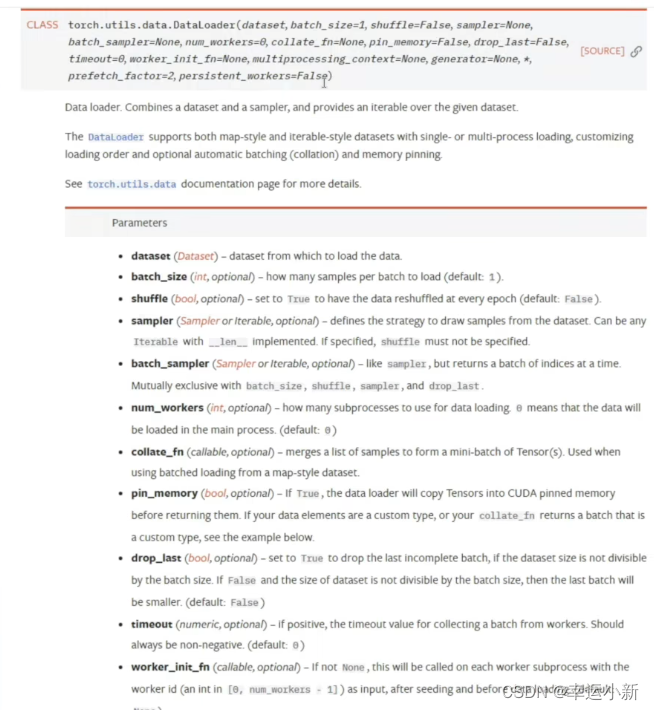
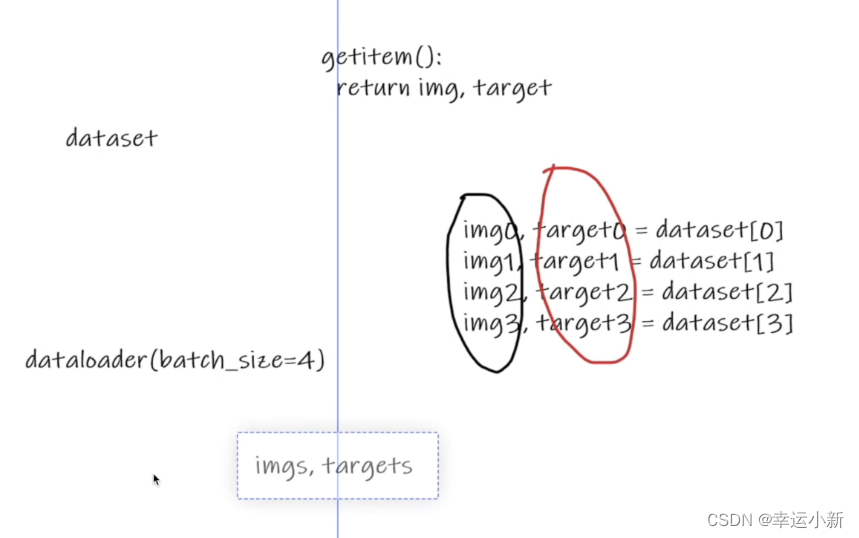
dataset就是告诉我们的程序数据在什么地方,包括第一张数据、第二种数据是什么…
还有总共有多少张数据
其他的参数都是有默认值的
我们介绍几个
batch_size我们每次抓几张牌
shuffle表示是否打乱,打牌之后进行一个洗牌,我们第一局和第二局牌堆的顺序是否一样
为true表示不一样
num_worker表示我们是使用多少个进程进行加载
drop_last假设我们有100张牌,每次摸3张,经过33次后还余一张,这张牌是否省去
true表示省去,只要前面99张
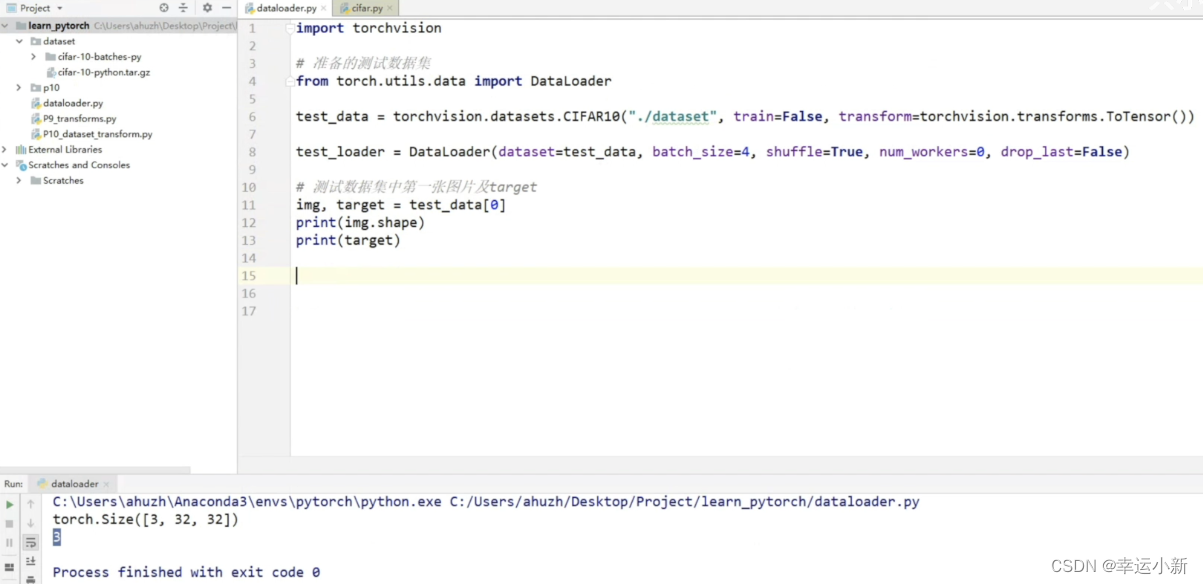
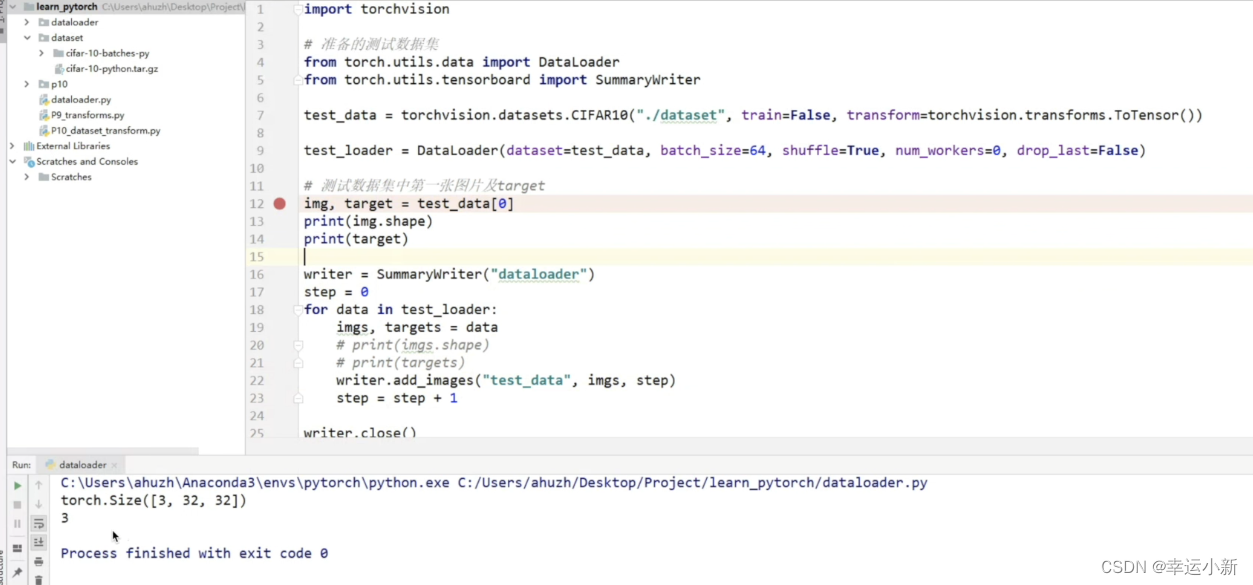
第一张图片的通道就3通道(rgb),大小32 * 32
类别target属于3
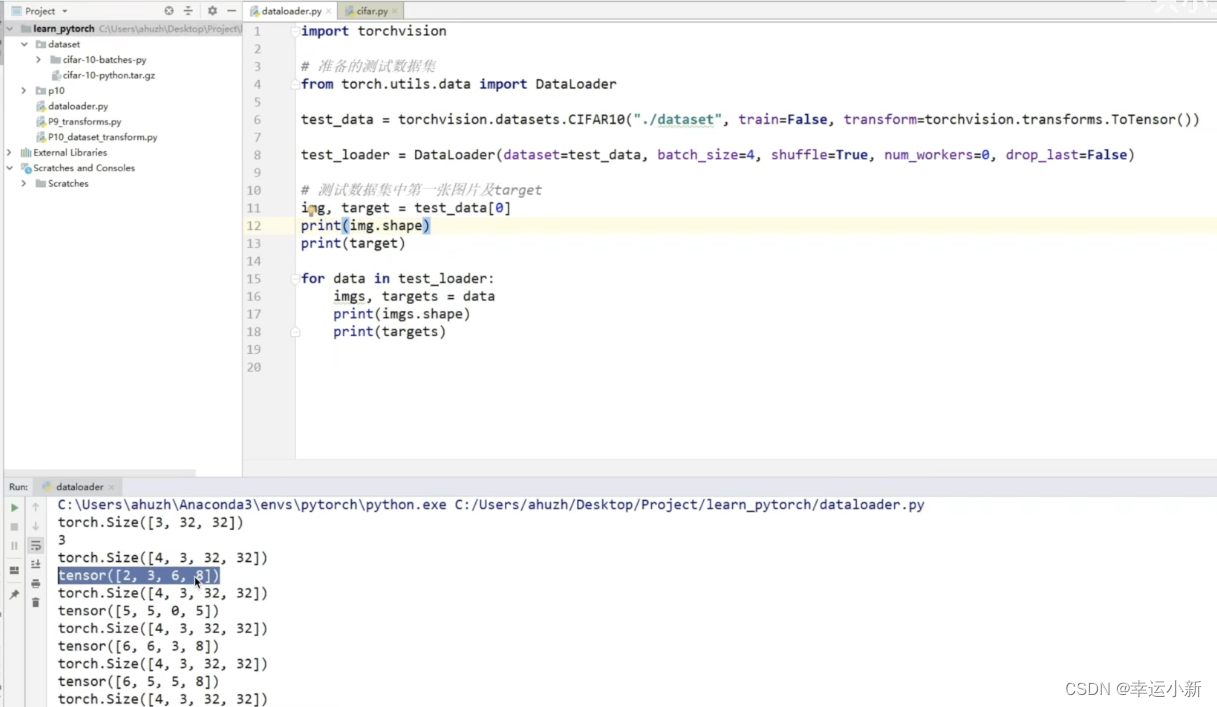
4张图片,每张都是3通道(rgb),大小32 * 32
类别也进行了打包,分别为2,3,6,8
我们这里设置的抓取方法是randomsampler就是每次随机抓取4张
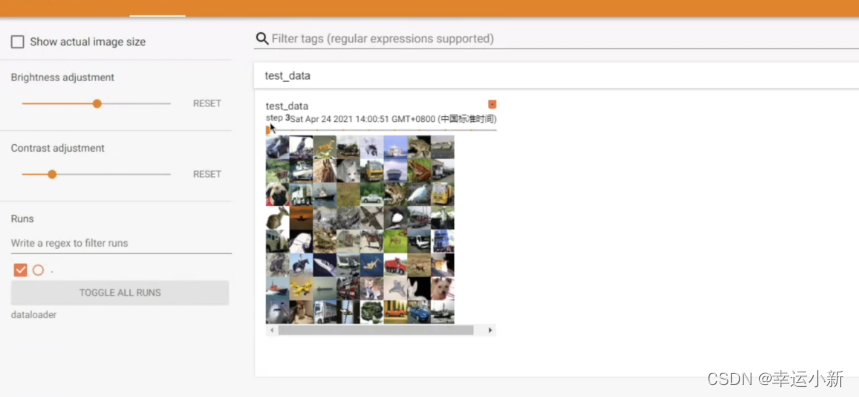
比如我们这边第三次取数据的时候,总共是8列8行64张图片
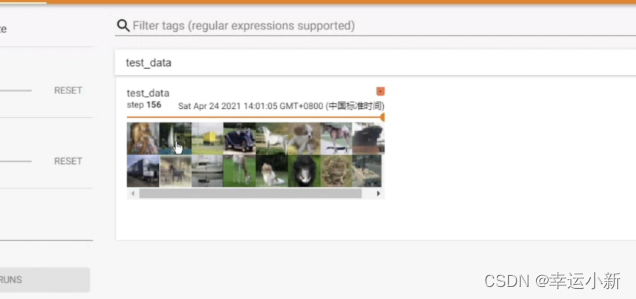
最后一次比较特殊,8列2行16张图片,因为我们的drop_last设置的是false
下面我们观察一下shuffle的用法
shuffle表示是否打乱,打牌之后进行一个洗牌,我们第一局和第二局牌堆的顺序是否一样
为true表示不一样
我们首先设置为false
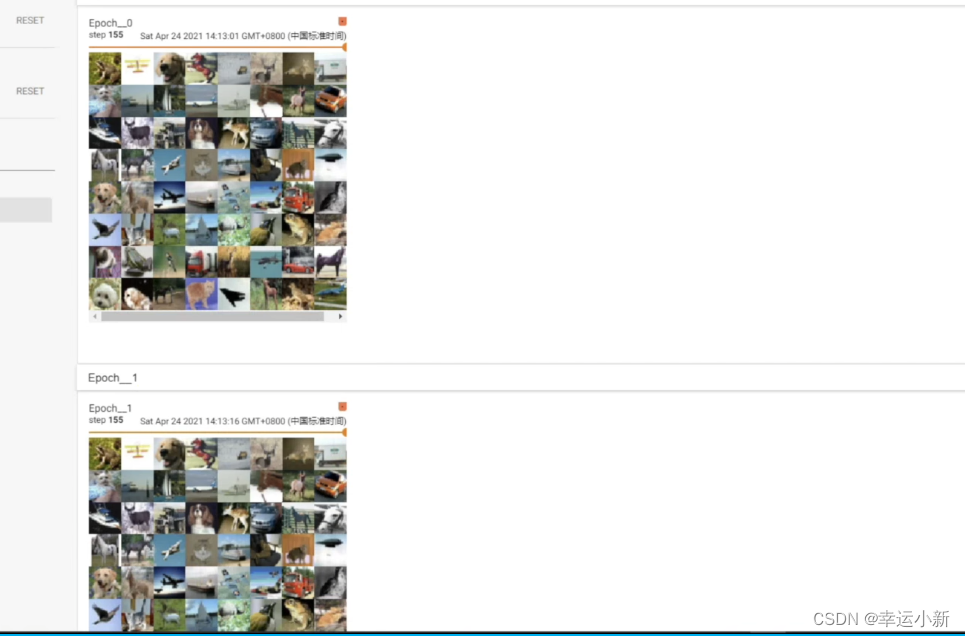
图片取的顺序是一模一样的
在实际的训练中也是一样的
我们会将for data后面取出的img输送到我们的神经网络当中
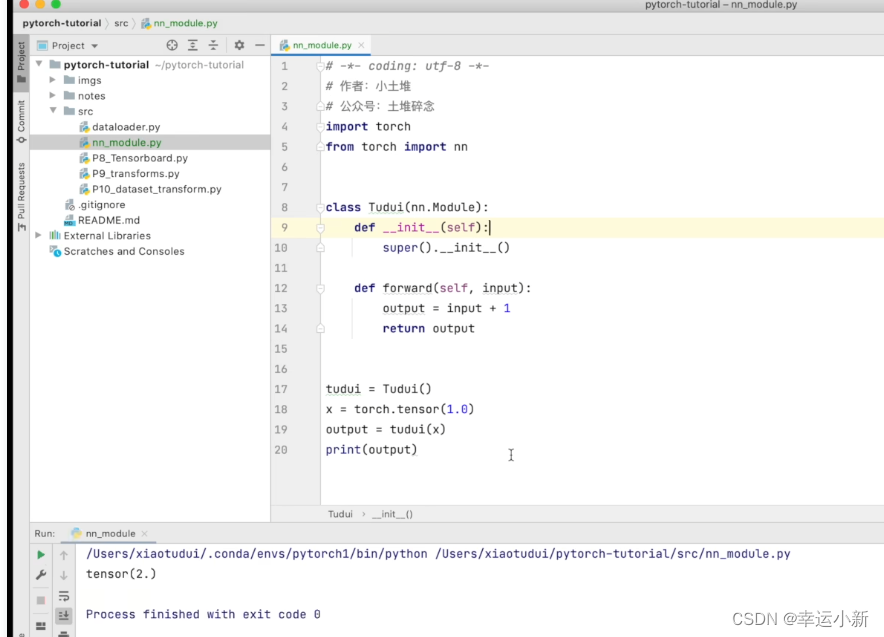
16.神经网络的基本骨架-nn.Module的使用
怎么主要学习containers
就是一个骨架,我们可以往里面添加内容

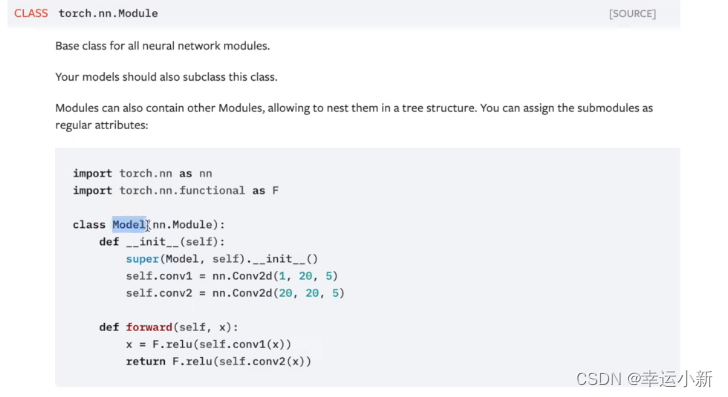
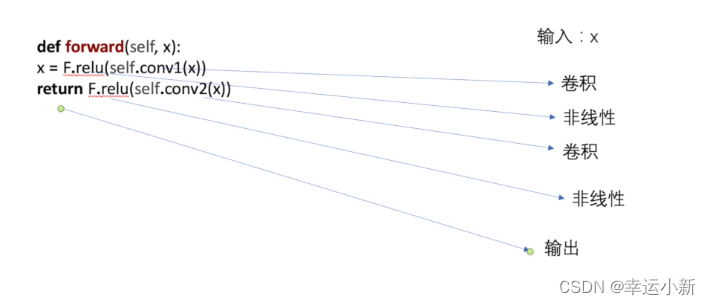
forward就是前向传播
self指本身这个类,是必备的
x指输入的参数
conv1表示进行一次卷积
relu表示进行一次非线性的处理
得到x
后面又进行了一次卷积和非线性的处理
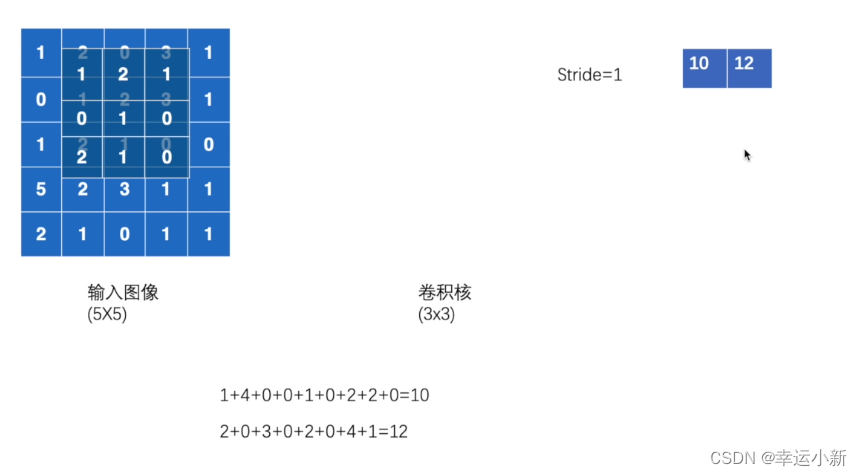
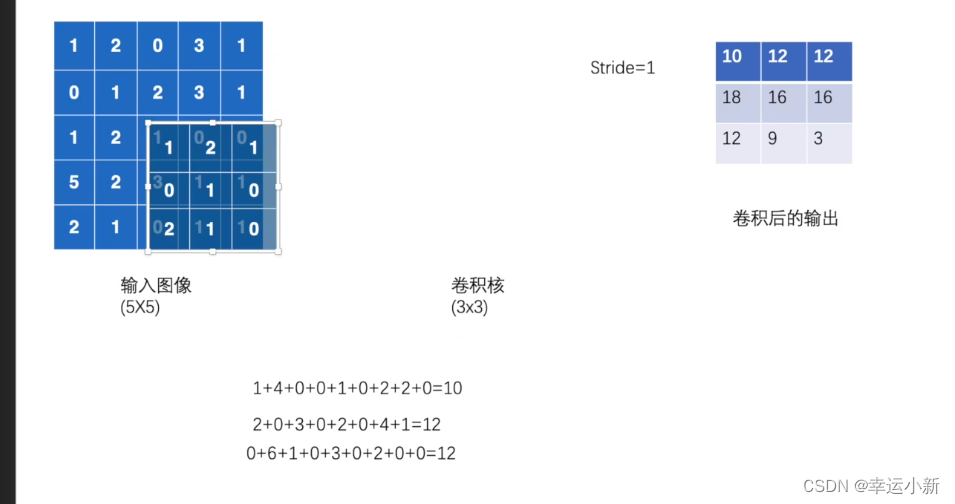
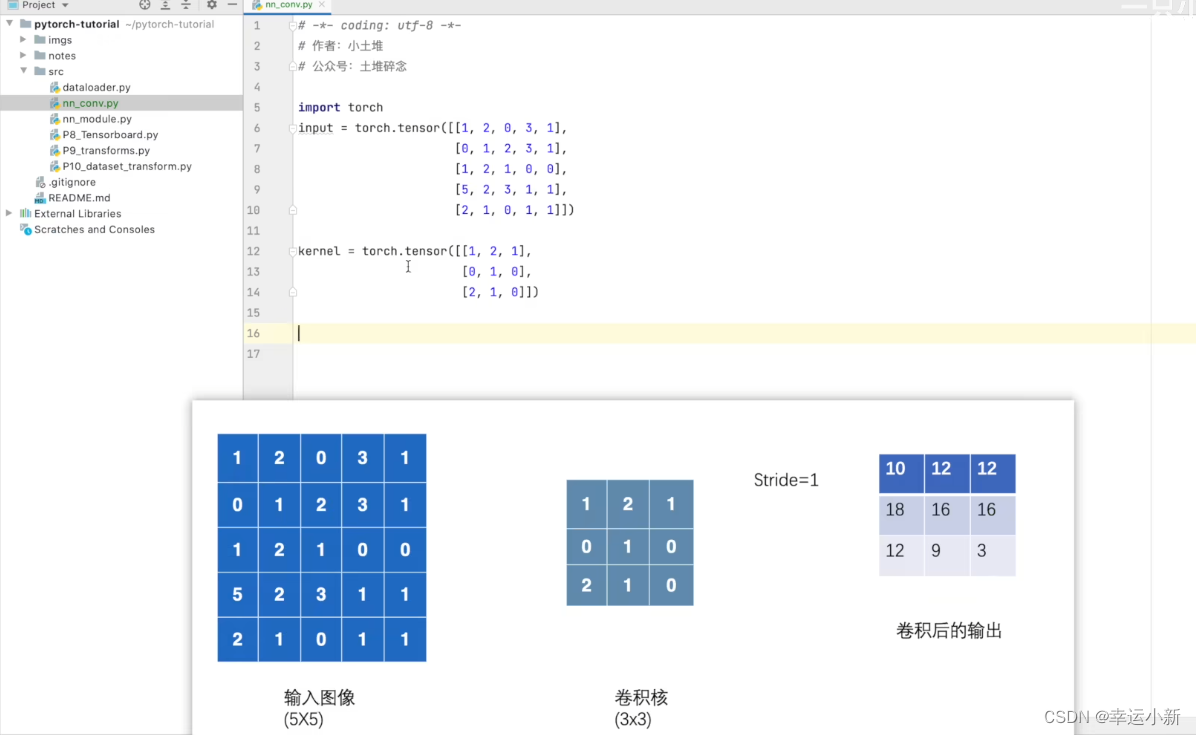
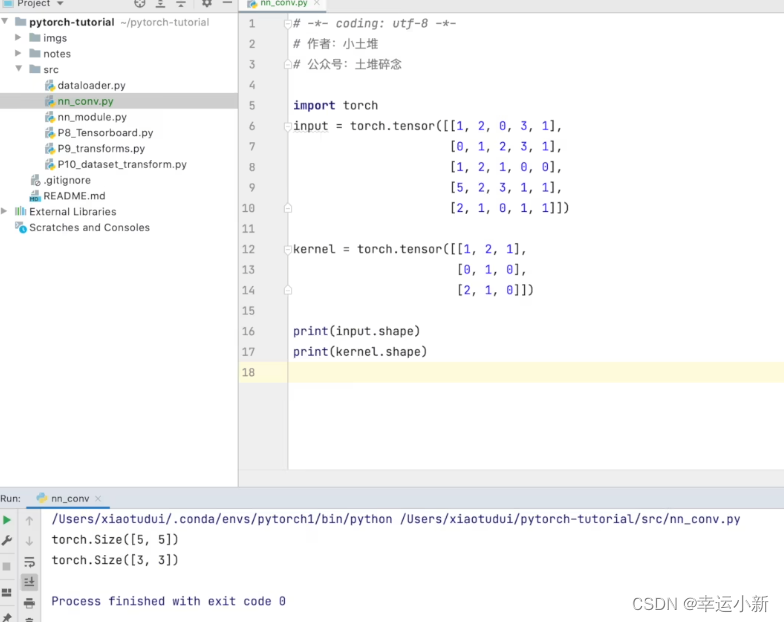
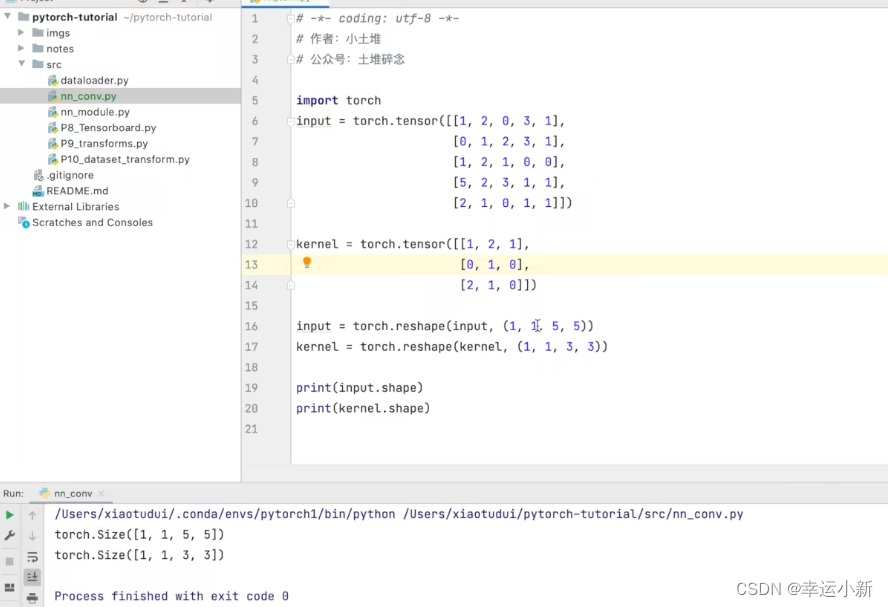
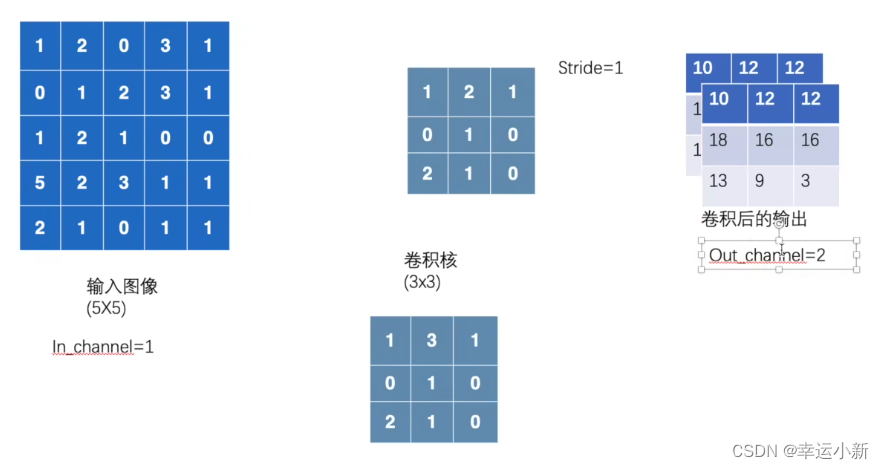
17.卷积操作

我们的torch.nn是对torch.nn.functional的一个封装,使用起来更加方便

weight就是卷积核
bias是偏置
stride是步长

我们这个不满足要求
因为参数需要四个
我们只有两个
我们使用pytorch的一个尺寸变换


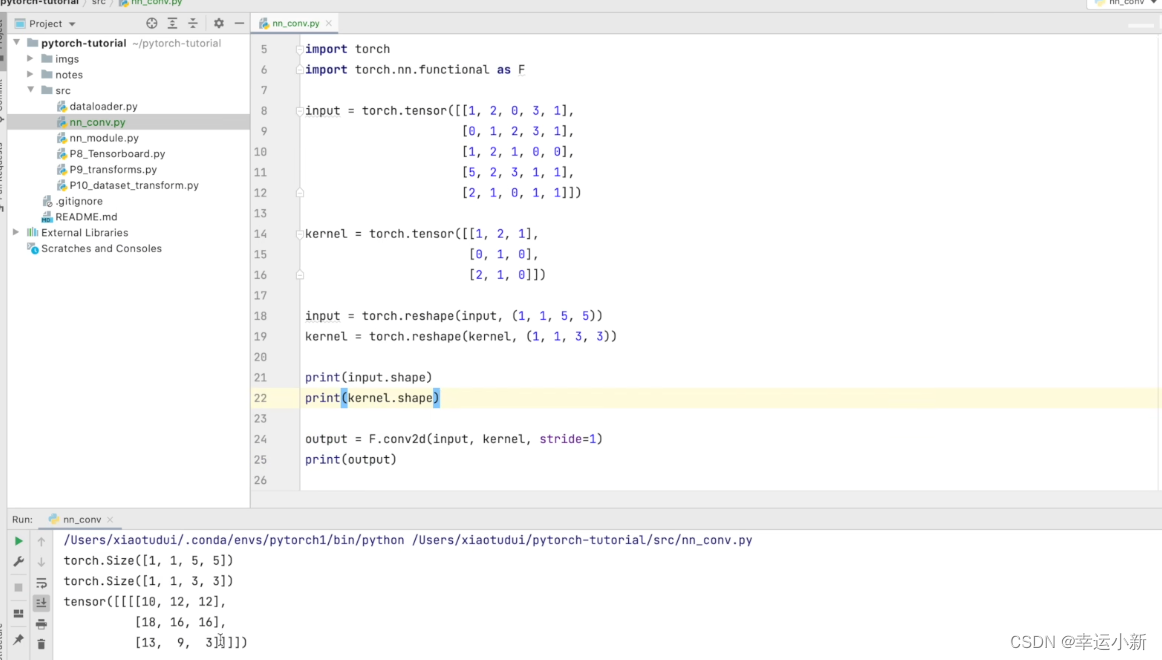
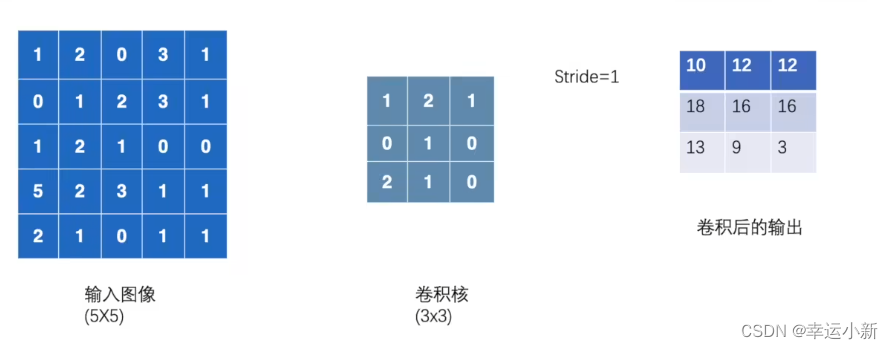
结果是一样的
如果我们的步长(stride)设置为2
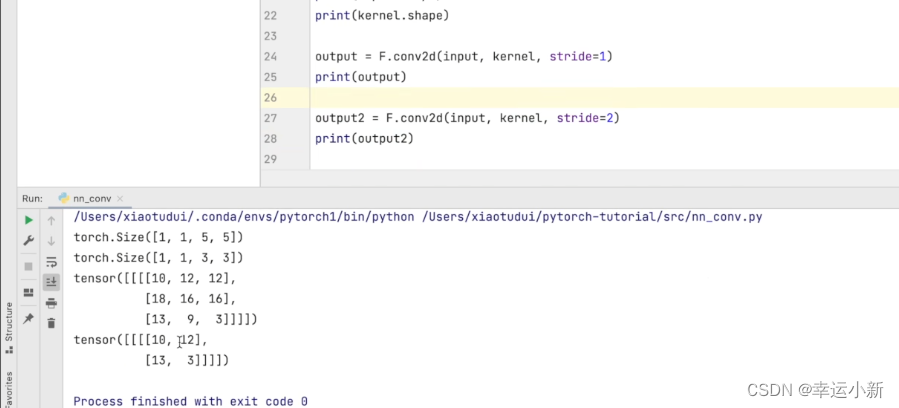

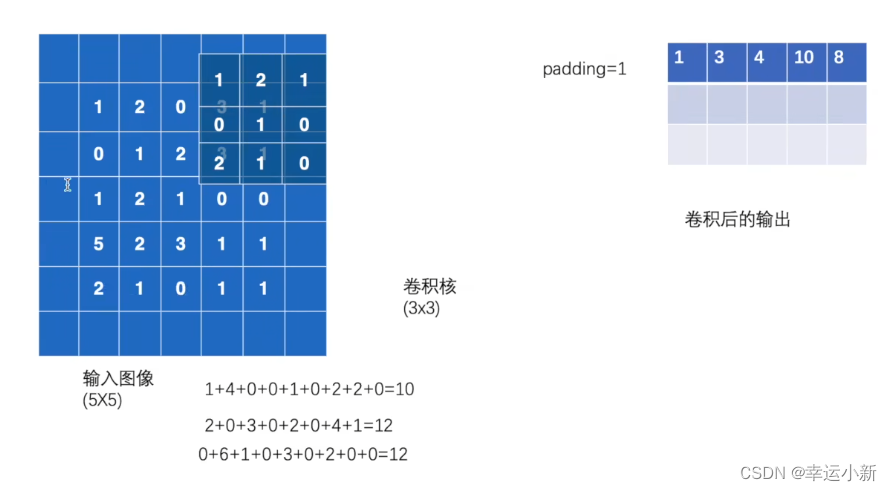
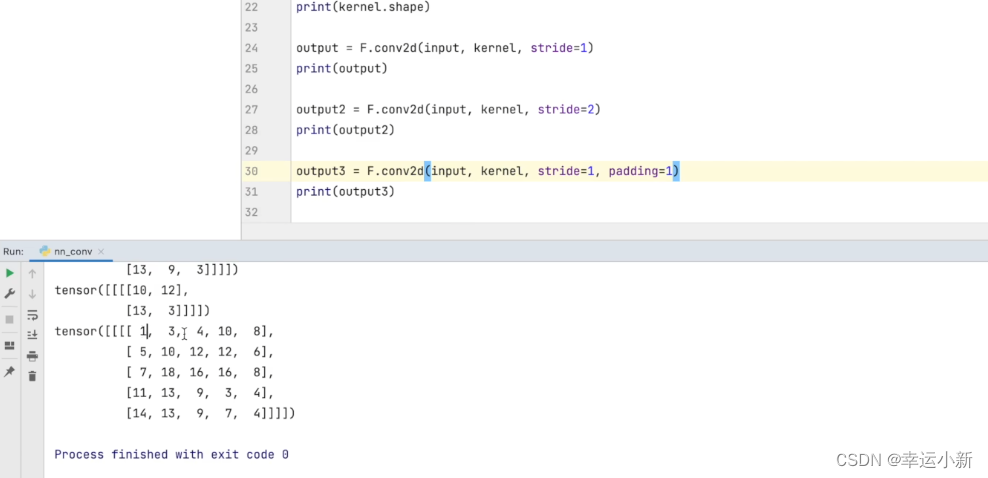
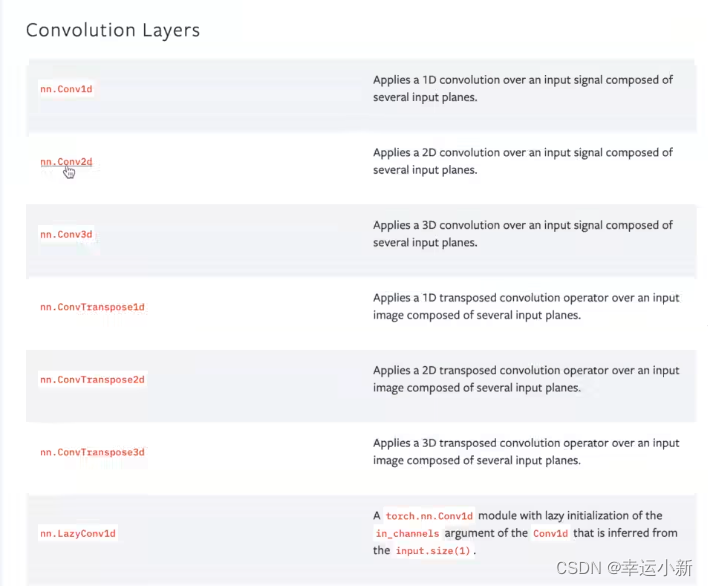
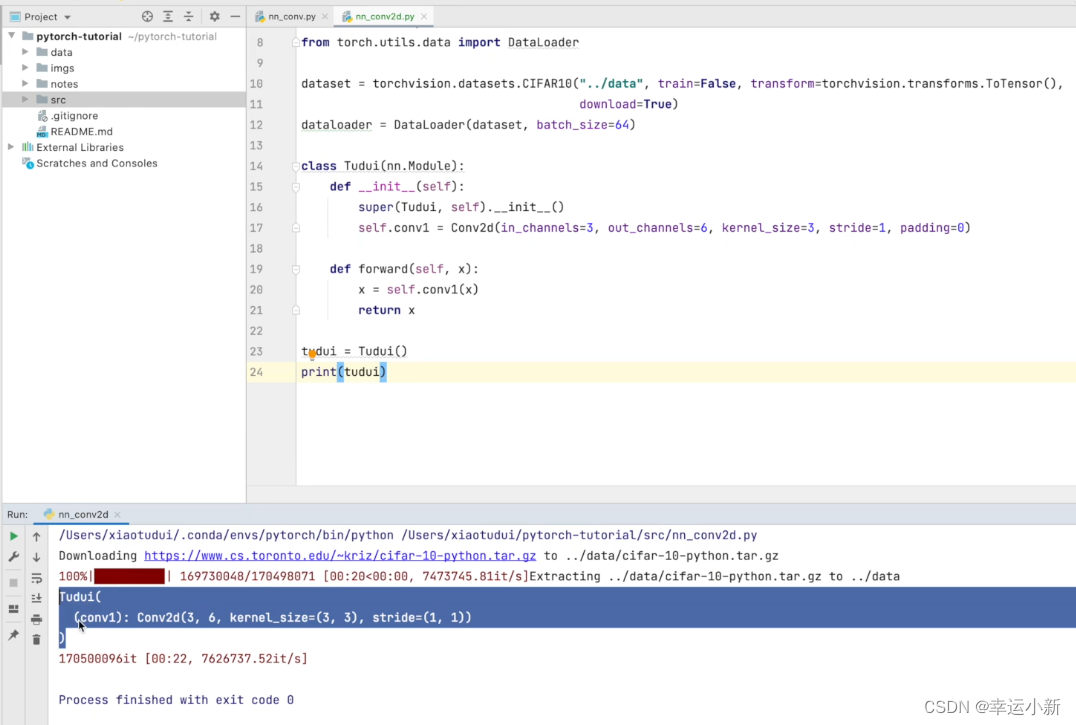
18.卷积层
Conv1d表示1维卷积
Conv2d表示2维卷积
Conv3d表示3维卷积
一般2d使用是最多的


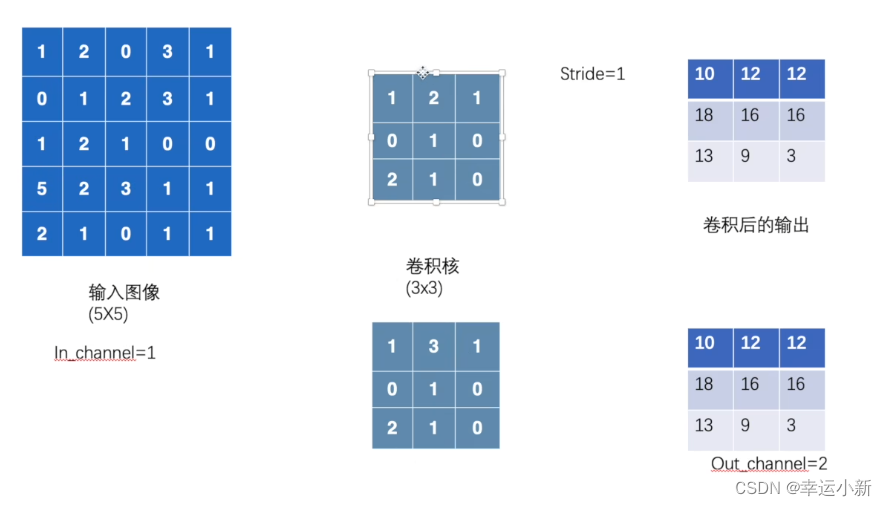
in_channels就是我们输入图像的通道数,我们的彩色图像一般就是3通道
out_channels就是通过卷积之后,我们的一个输出通道数是多少
kernel_size就是卷积核的大小,写3的话就是定义一个3* 3的卷积核
(1,2)就是定义一个1* 2的卷积核
stride就是步长
padding就是边缘填充
padding_mode就是我们填充的方式,一般就是zeros
bias就是偏置,用于微调,一般设置为true
如果in_channels为1,out_channels为2
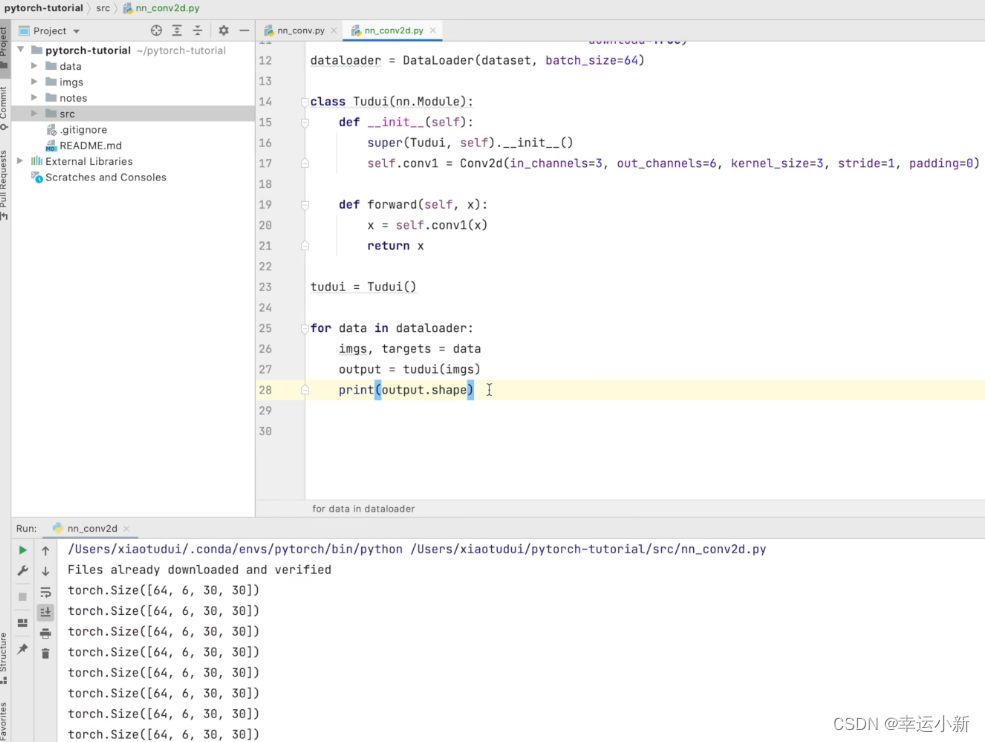
这个output就是将我们的数据放到神经网络,返回的结果就是output
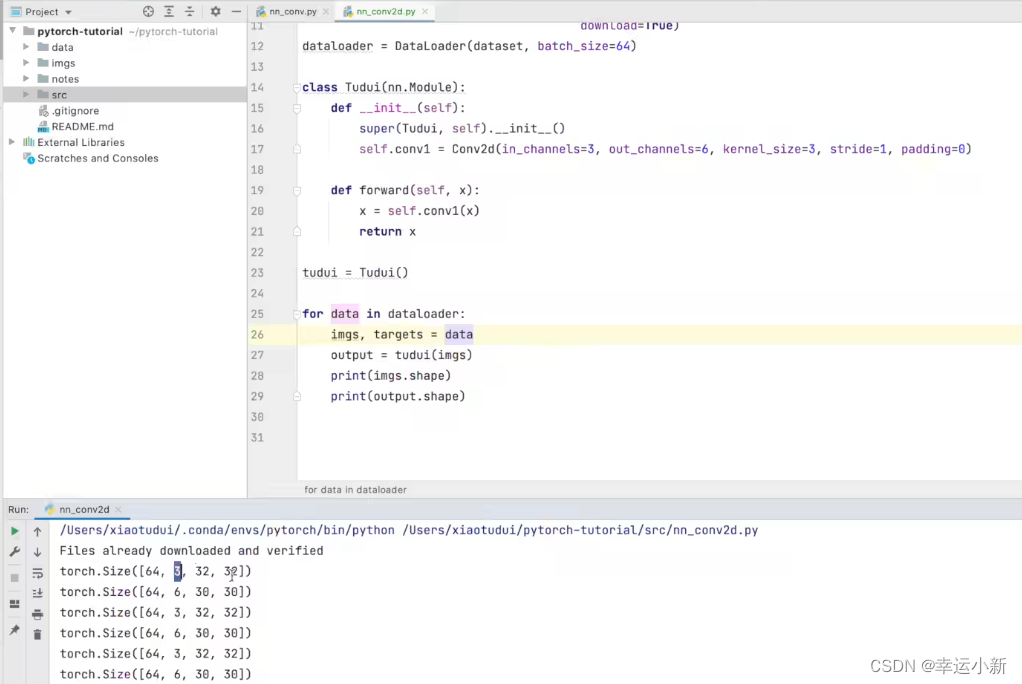
我们他可以使用tensorboard进行一个直观的显示
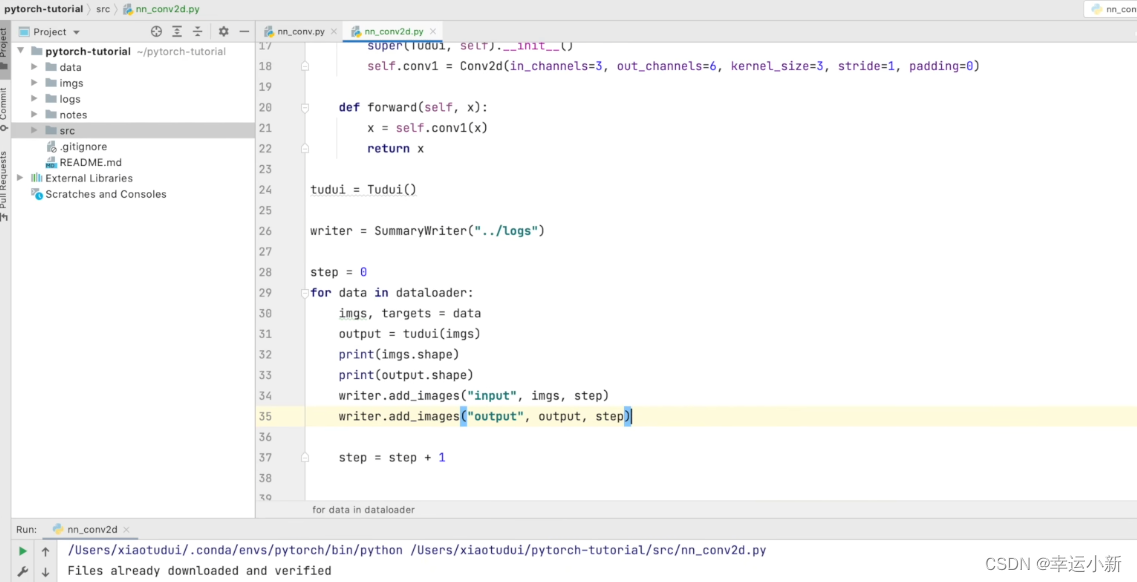
保持,因为彩色图像是3个channel
这里有6个
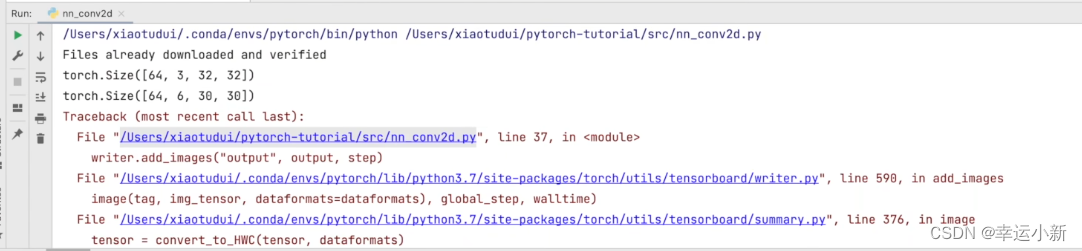
无法显示
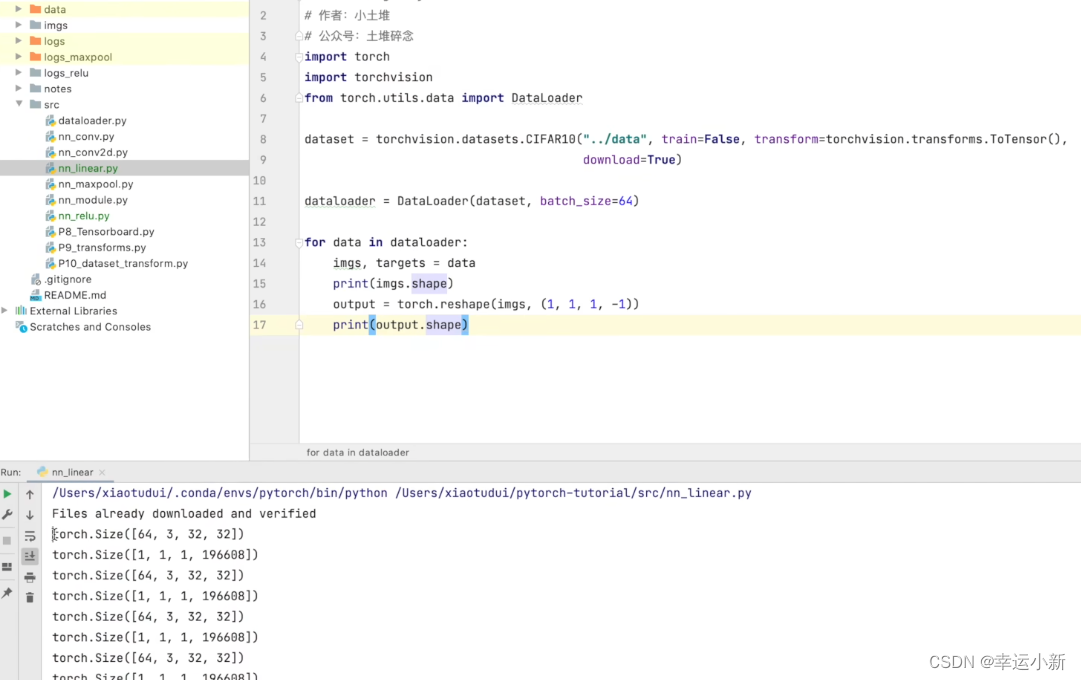
-1 是一个占位符,表示让 PyTorch 自动计算该维度的大小。
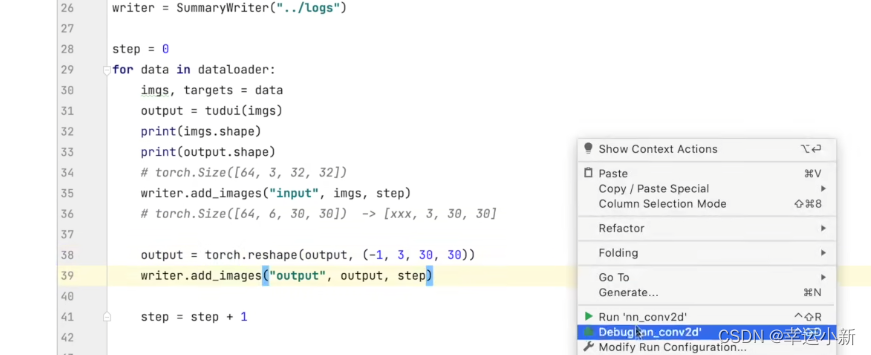
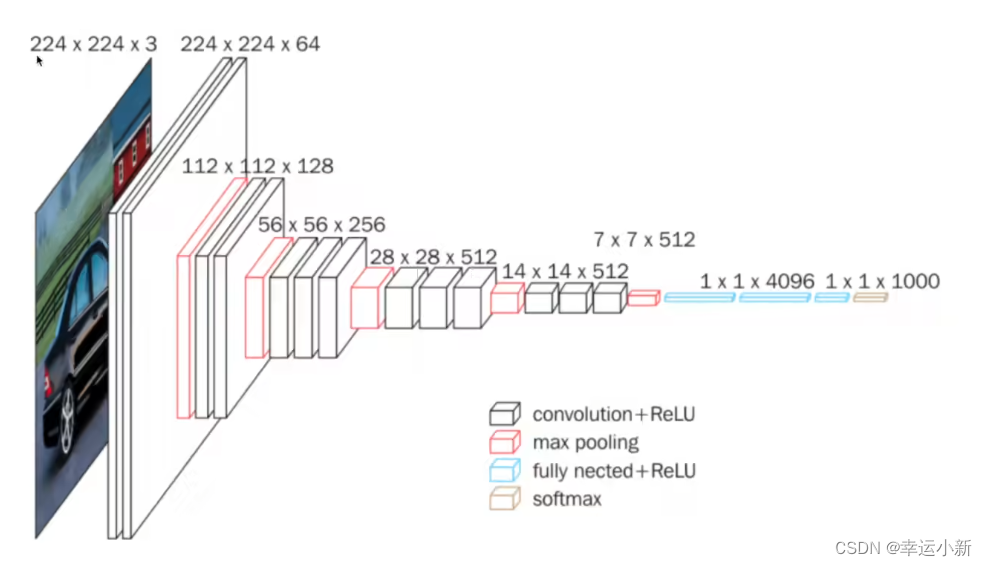
这里in_channel就是3
out_channel就是64

N表示batch_size
C表示in_channel
H表示高
W表示宽
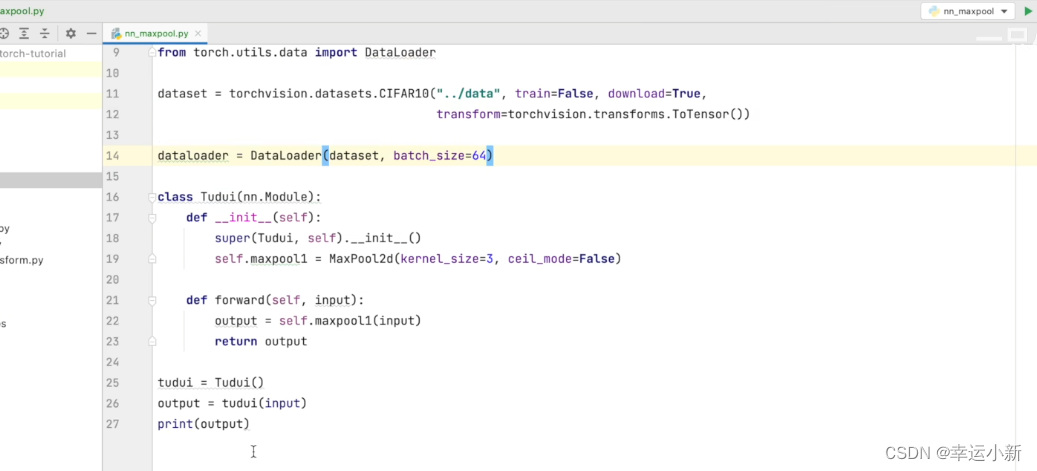
19.神经网络最大池化的使用
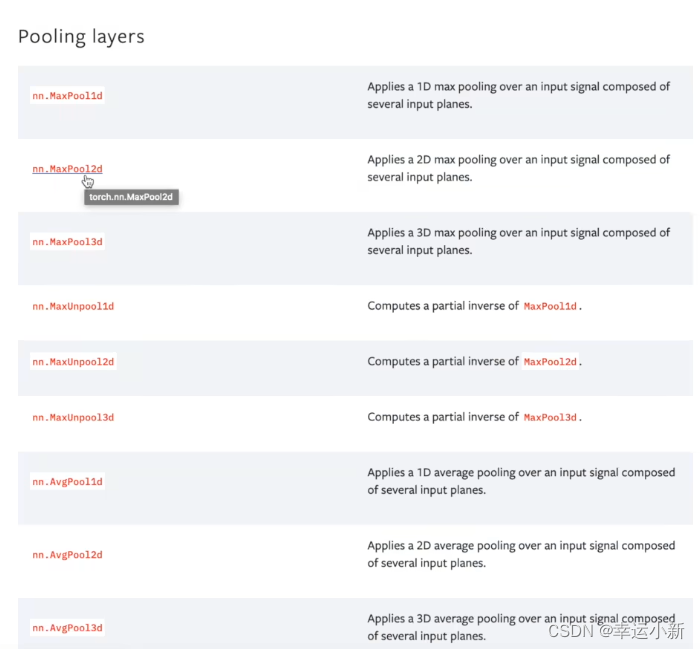
最常用的是maxpool2d

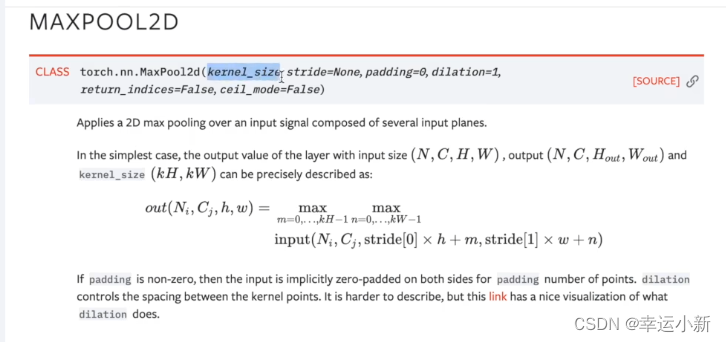
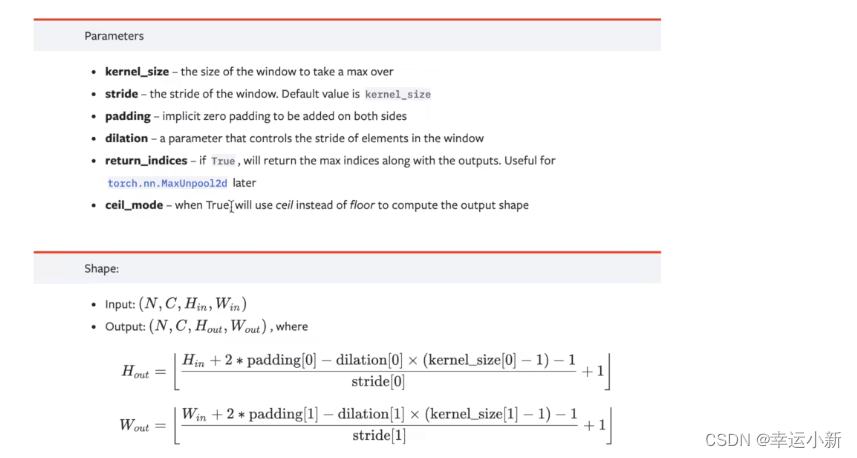
dilation(空洞卷积)

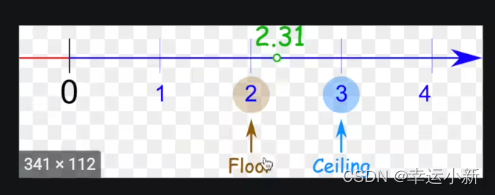
ceil_mode的参数为floor就是向下取整
我们举例说明
设置步长stride为3
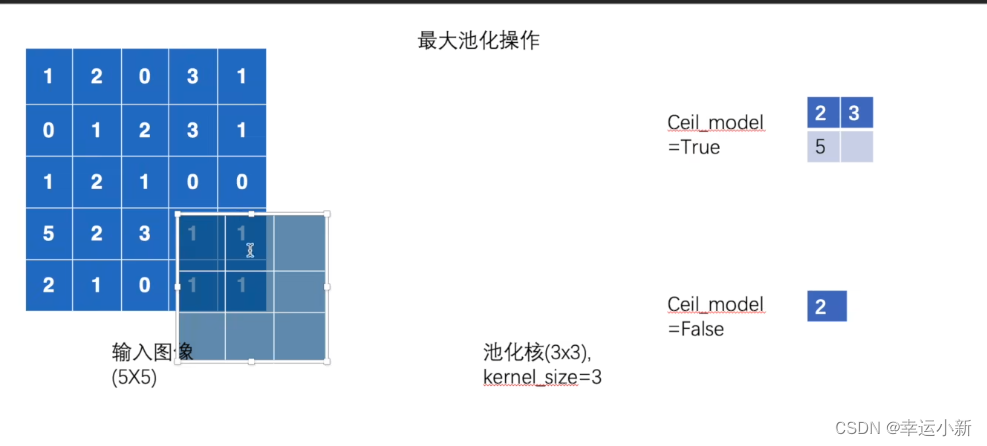

默认ceil_mode为false
一般情况下,最大池化我们只要设置参数kernel_size就行

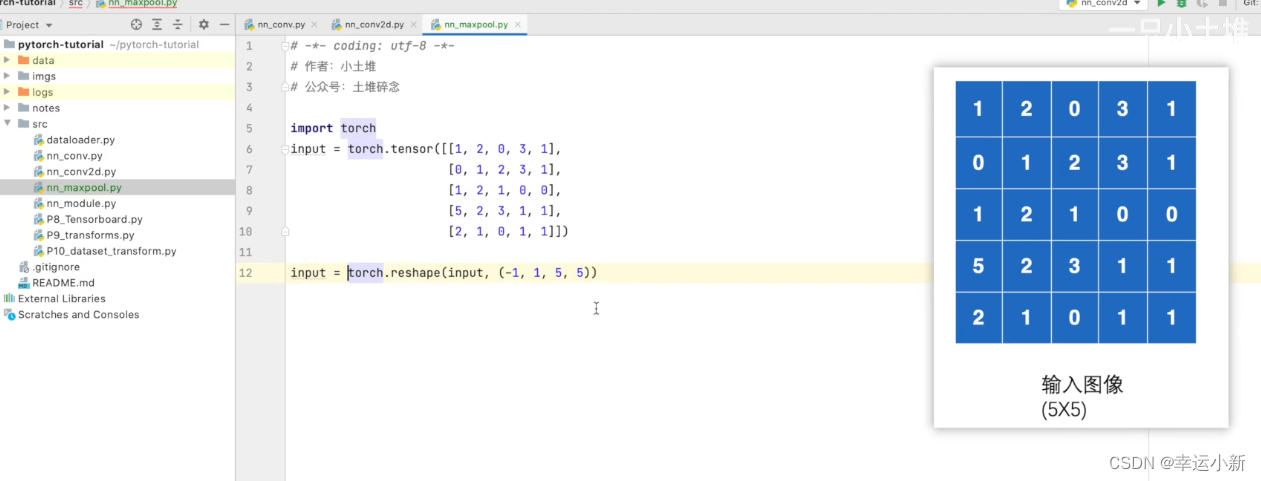
N表示batch_size,这里设置为-1,意味着让它自己计算batch_size
因为这里只有一层,所以channel为1
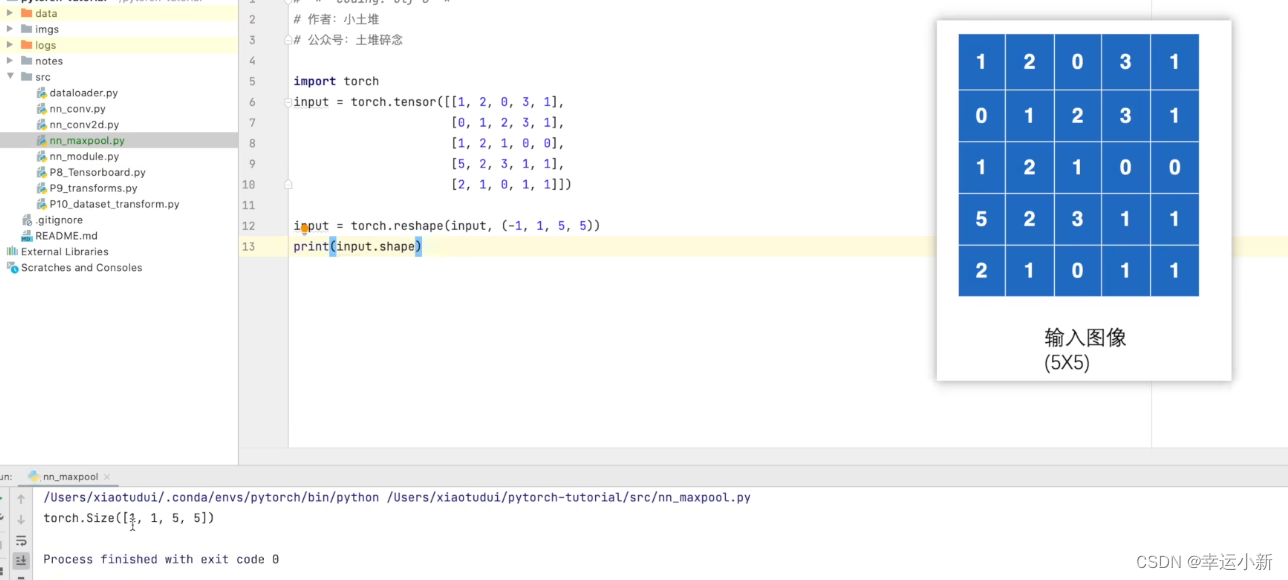
现在input可以只有(C,H,W)了,不需要N四维

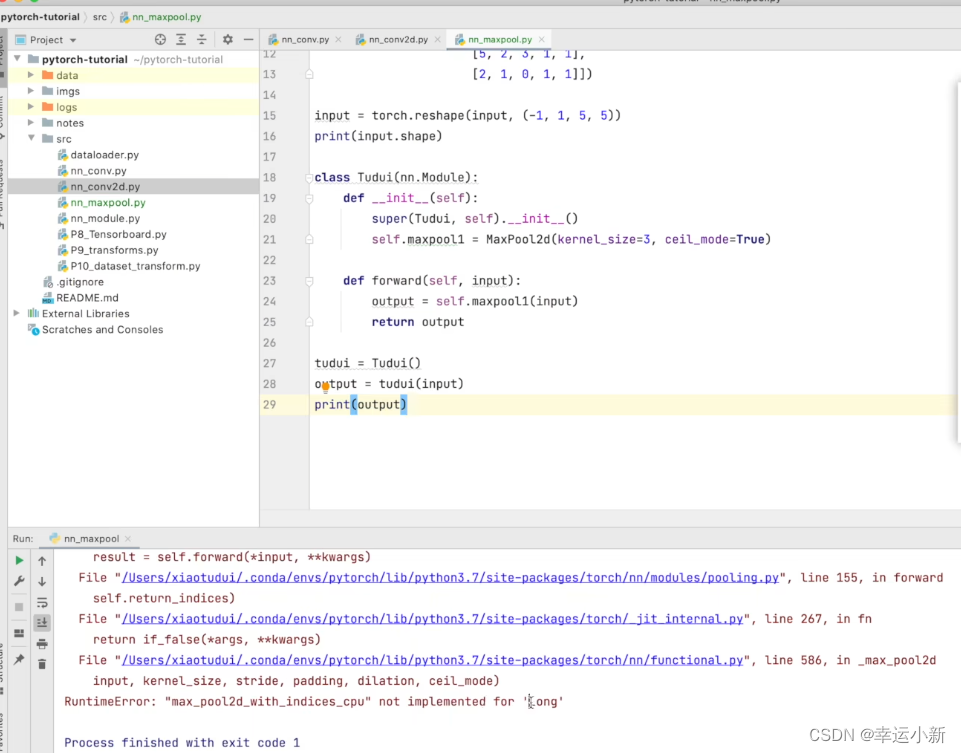
原因是无法操作long类型数据
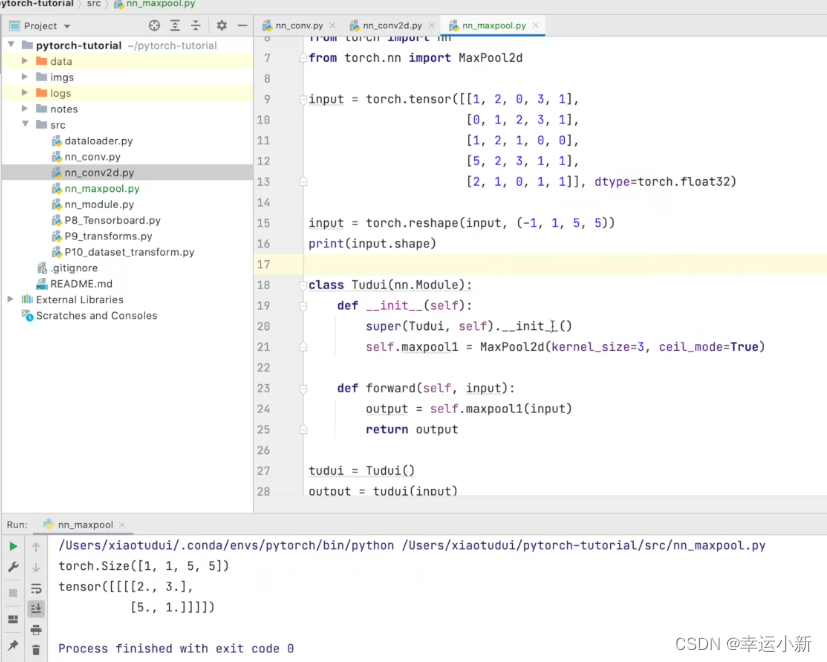
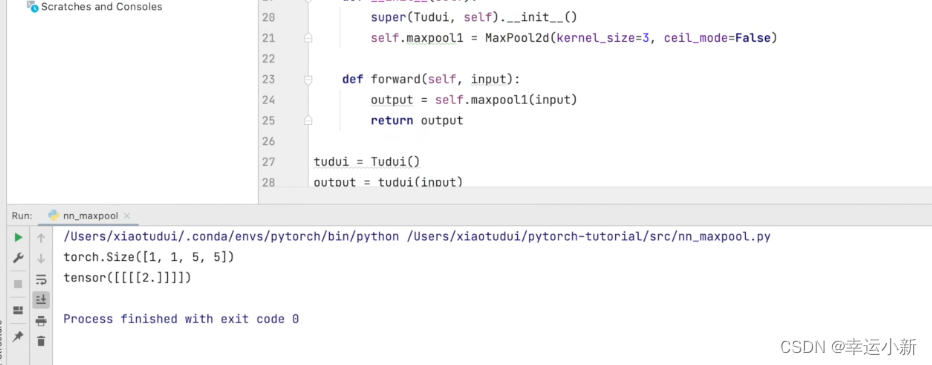
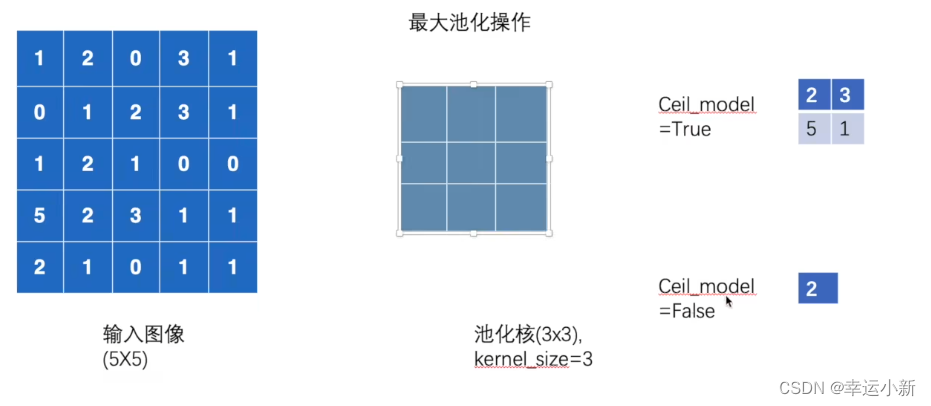
结果一致
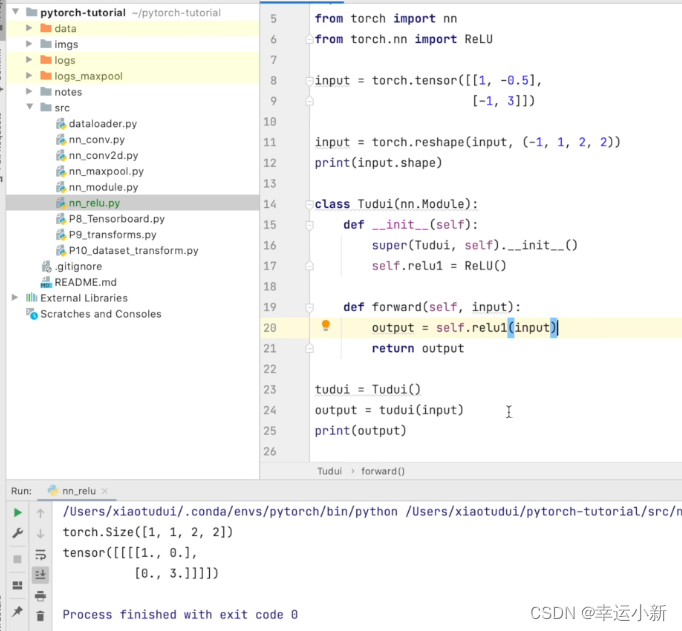
20.神经网络非线性激活
为了给我们的神经网络引入非线性的特质
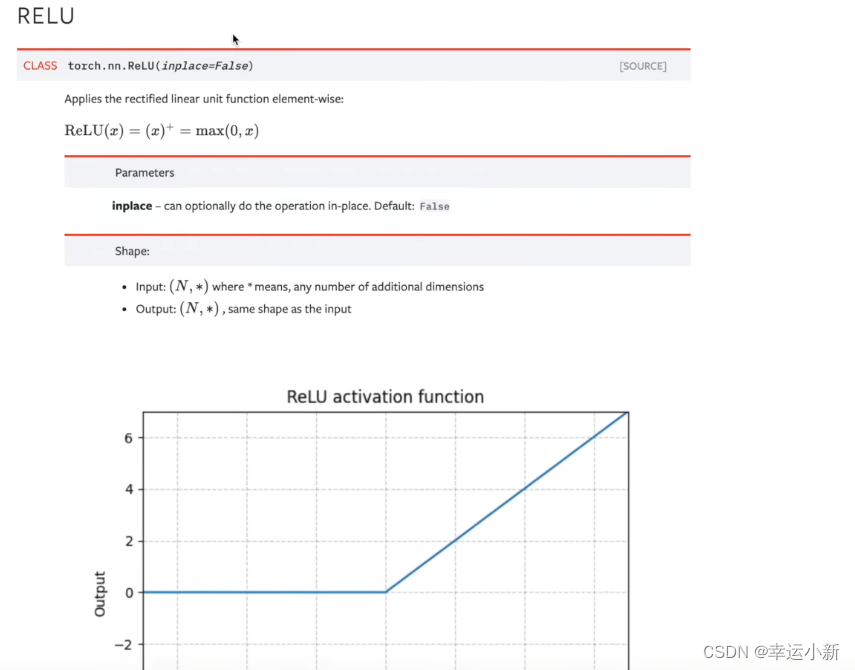
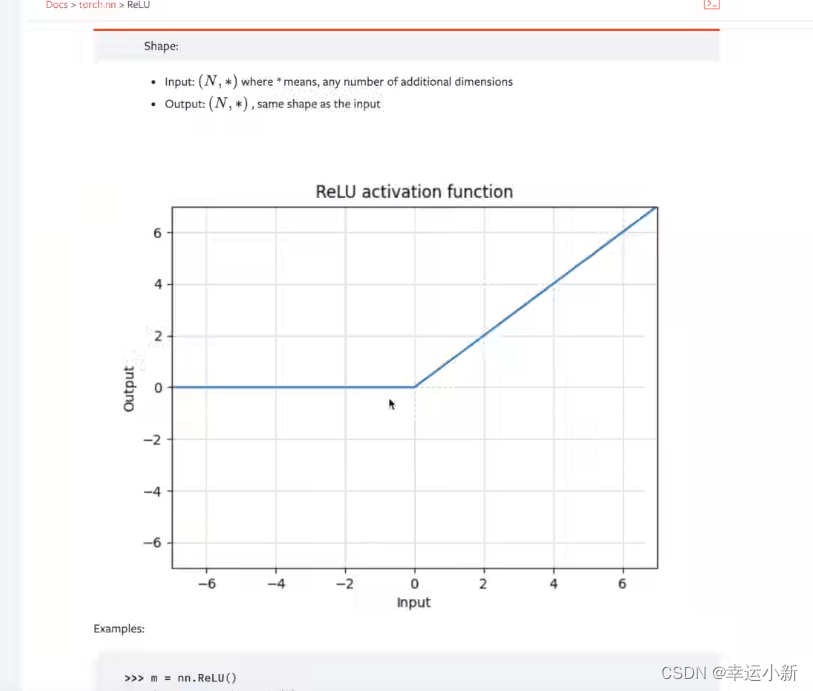
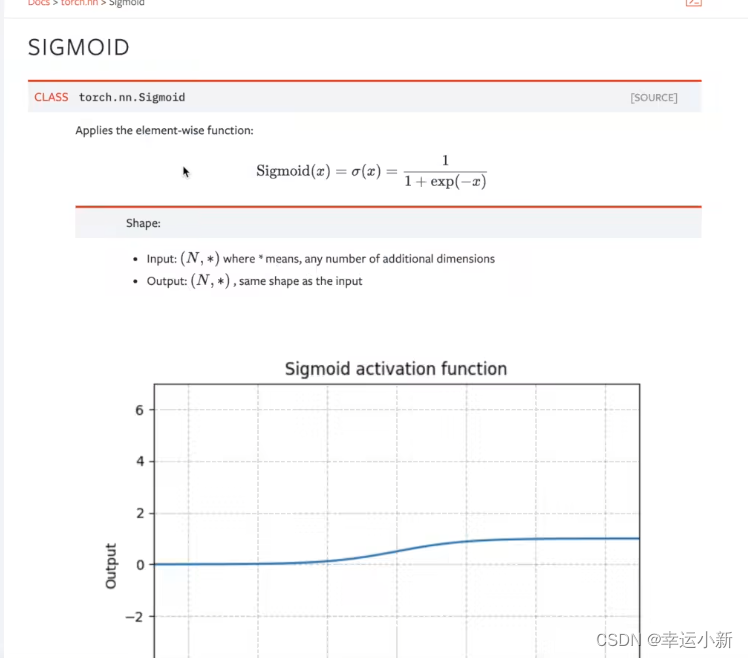
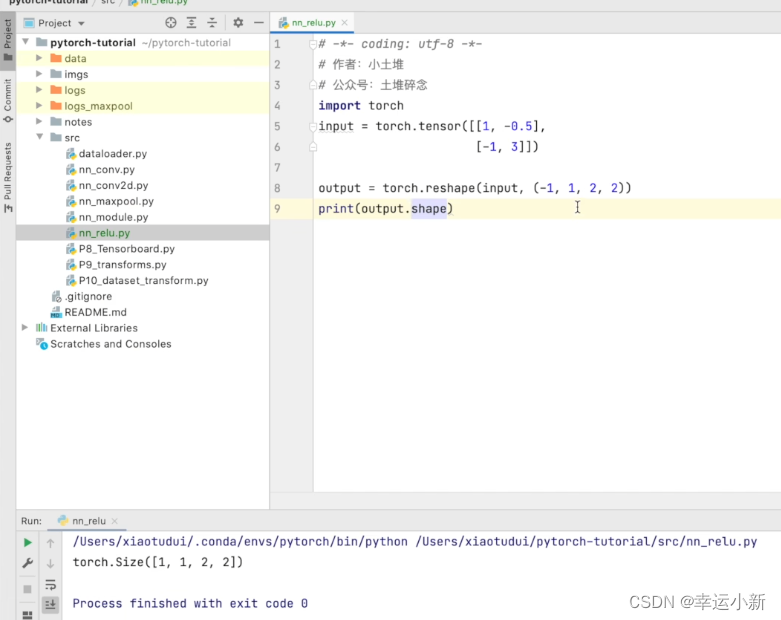

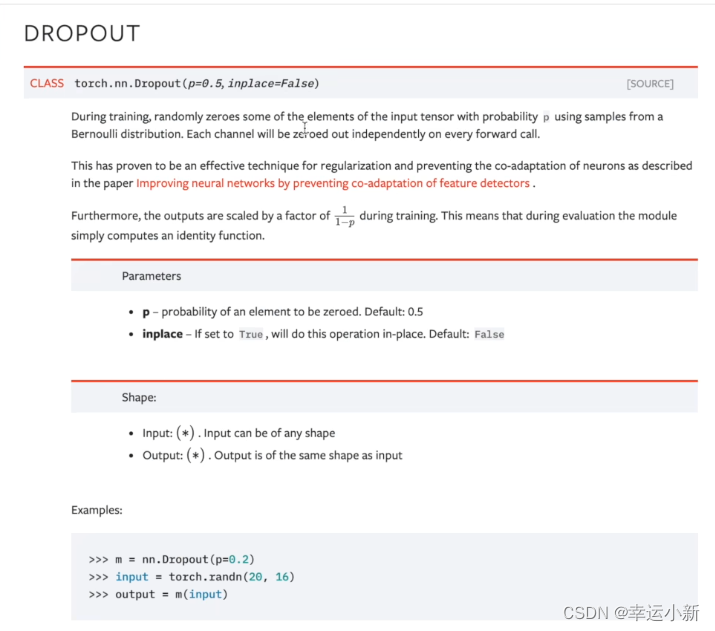
inplace表示是否对我们原来的结果进行一个替换,默认为false
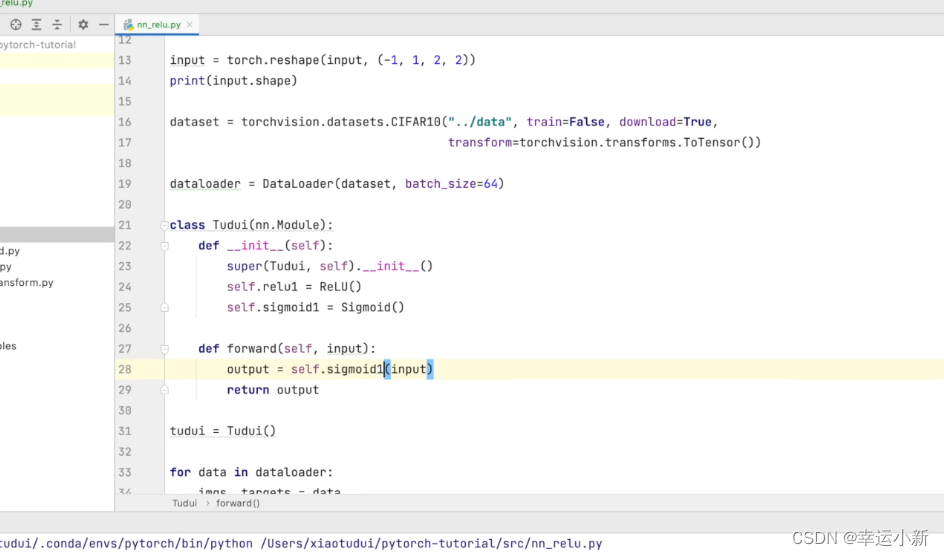
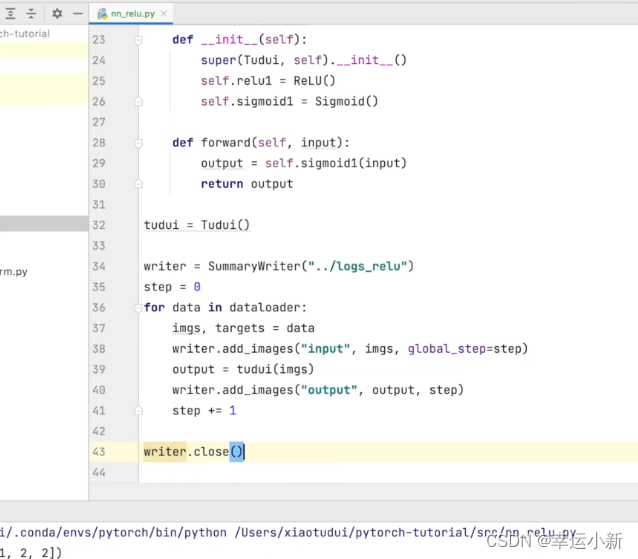
下面我们使用具体的数据集做一个测试
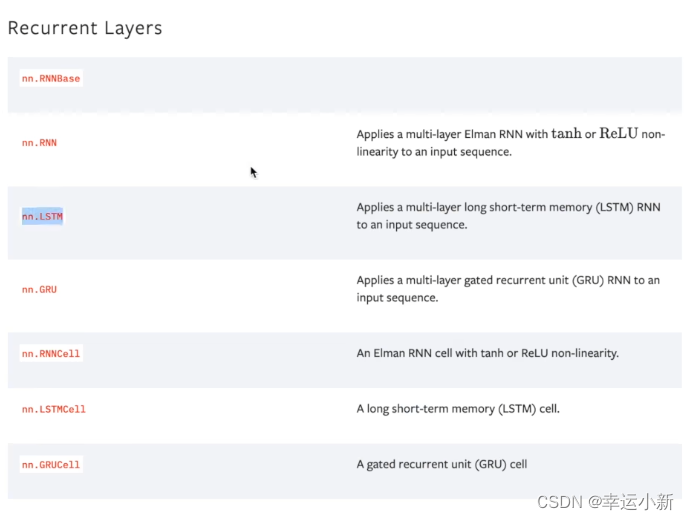
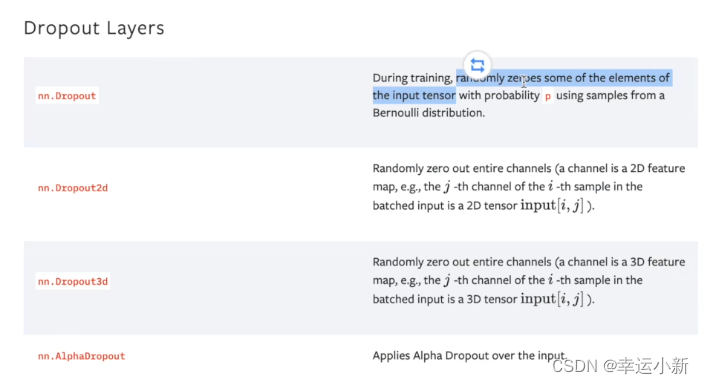
21.神经网络-线性层及其它层介绍
正则化层
这个用的也不多
有论文说到
使用正则化可以提高我们神经网络训练的速度
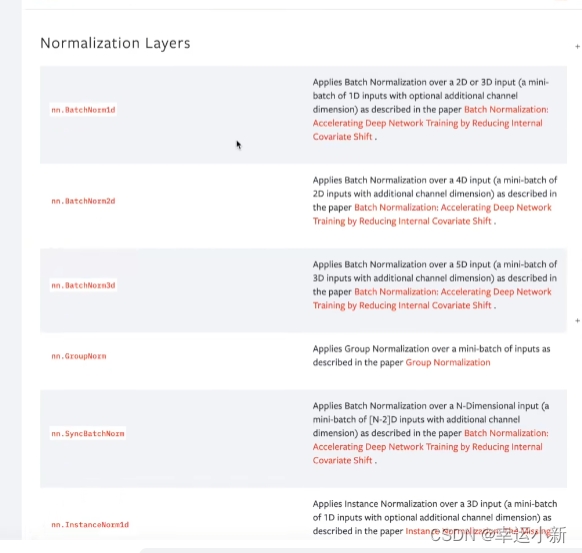



这里的参数主要是num_features,就是C
其他的参数可以使用默认值


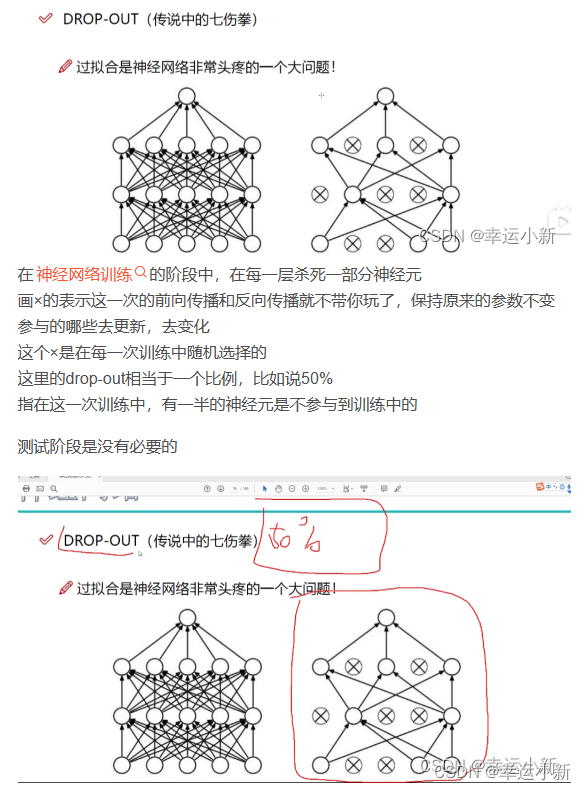
主要防止过拟合
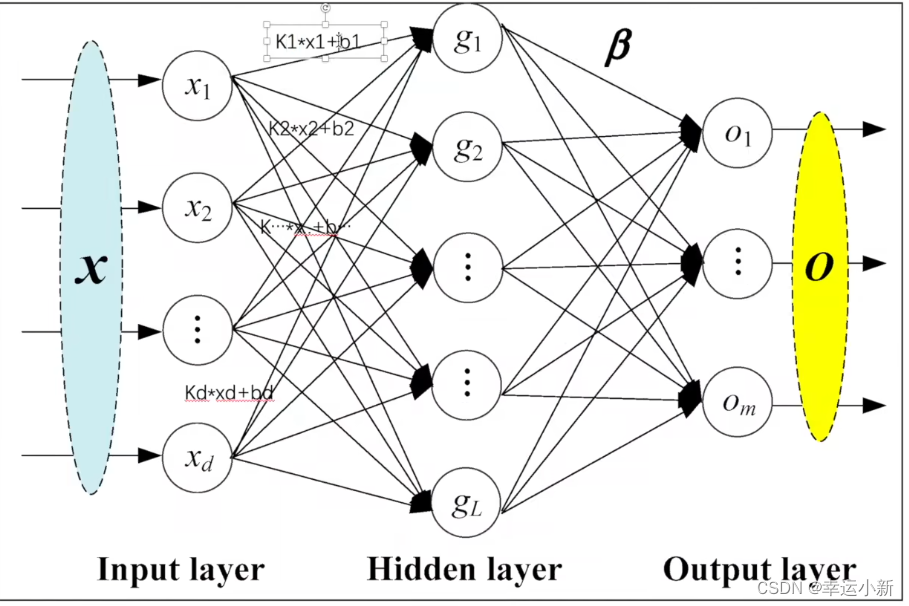
下面居然看一下线性层

in_feature就是这里的x1、x2…
out_feature就是这里的g1、g2…
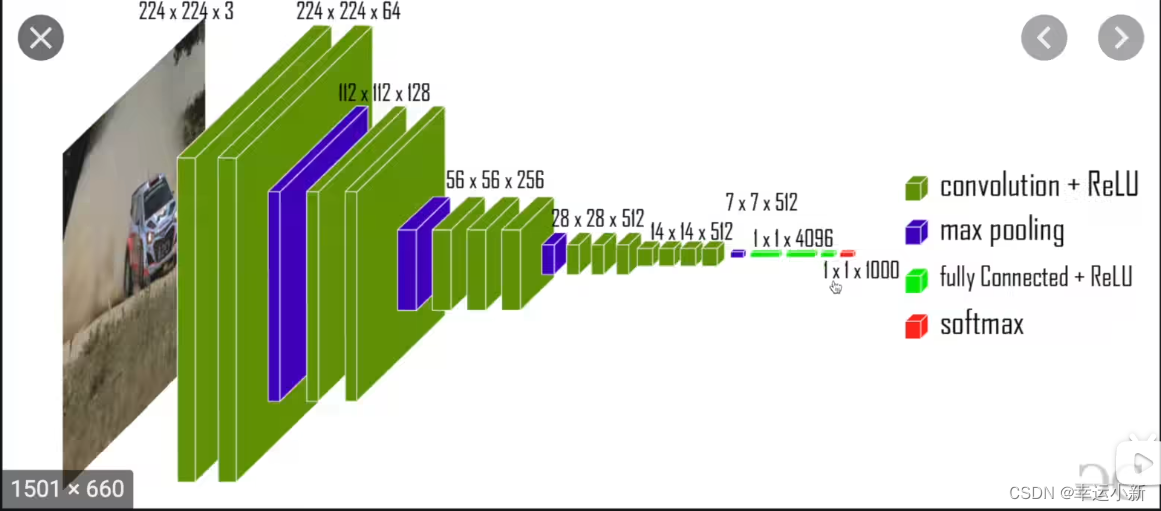
就是1 * 1 * 4096到1 * 1 * 1000这个过程
in_feature为4096
out_feature为1000



up谷歌的图片要求把图片以111*4090的形式传输给下一层,所以现在(1,1,1,-1)就是为了找到和之前相同的格式
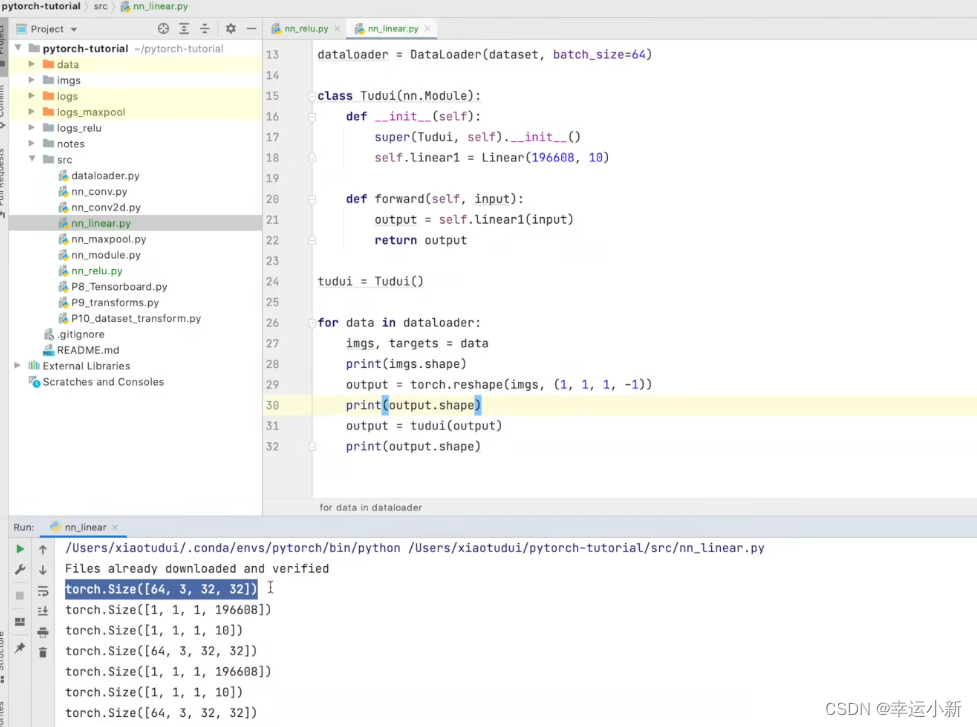
通过上面这个例子我们
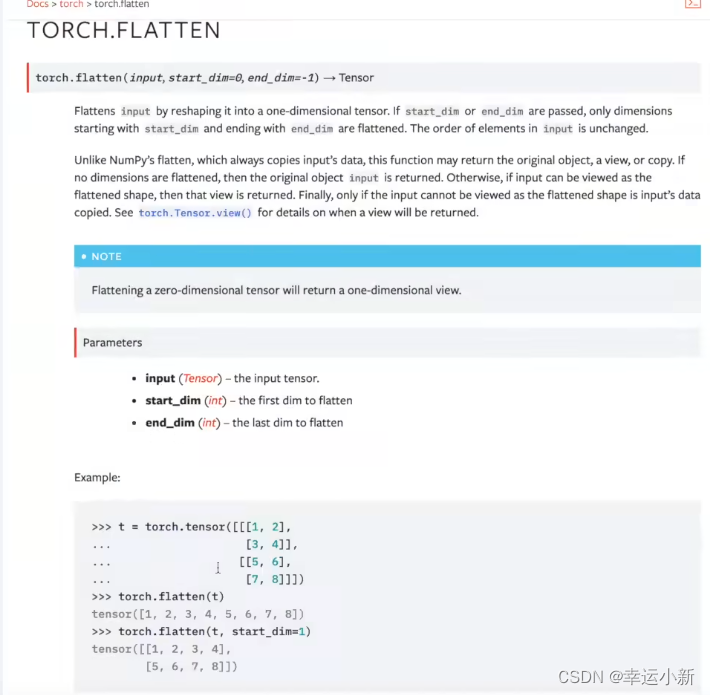
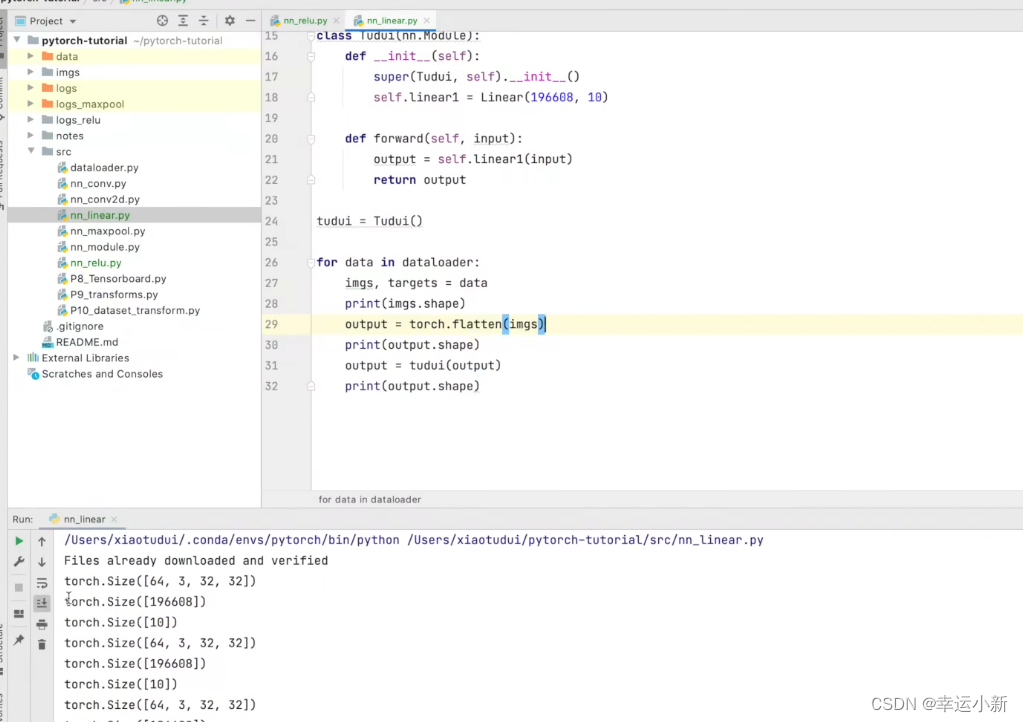
引出flatten,就是将我们的特征摊平
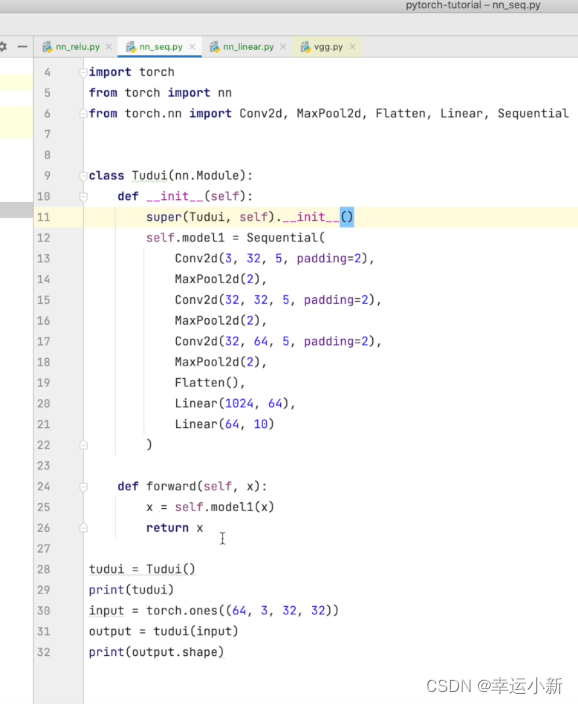
22.搭建小实战和Sequential的使用
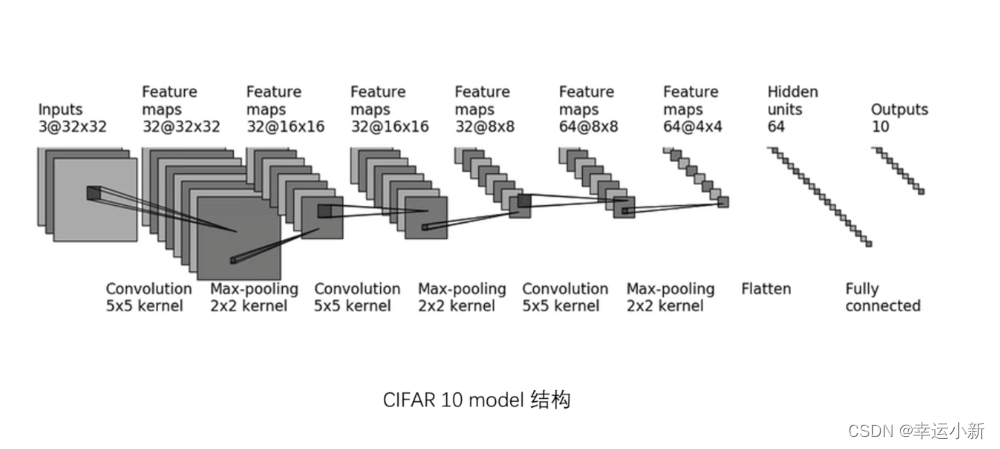
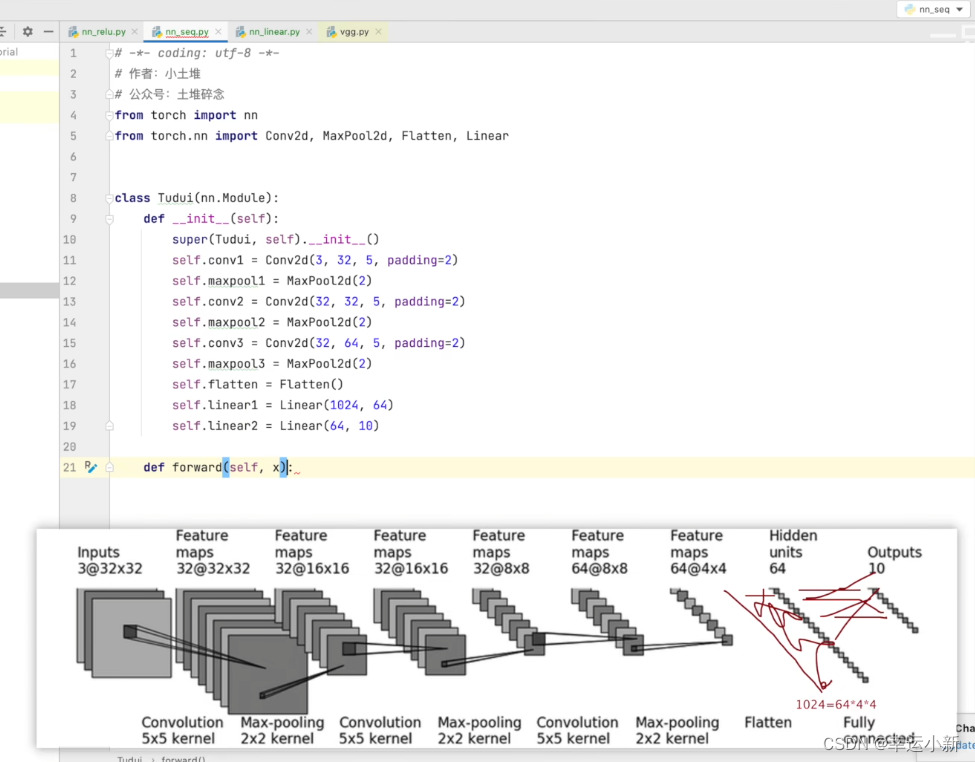
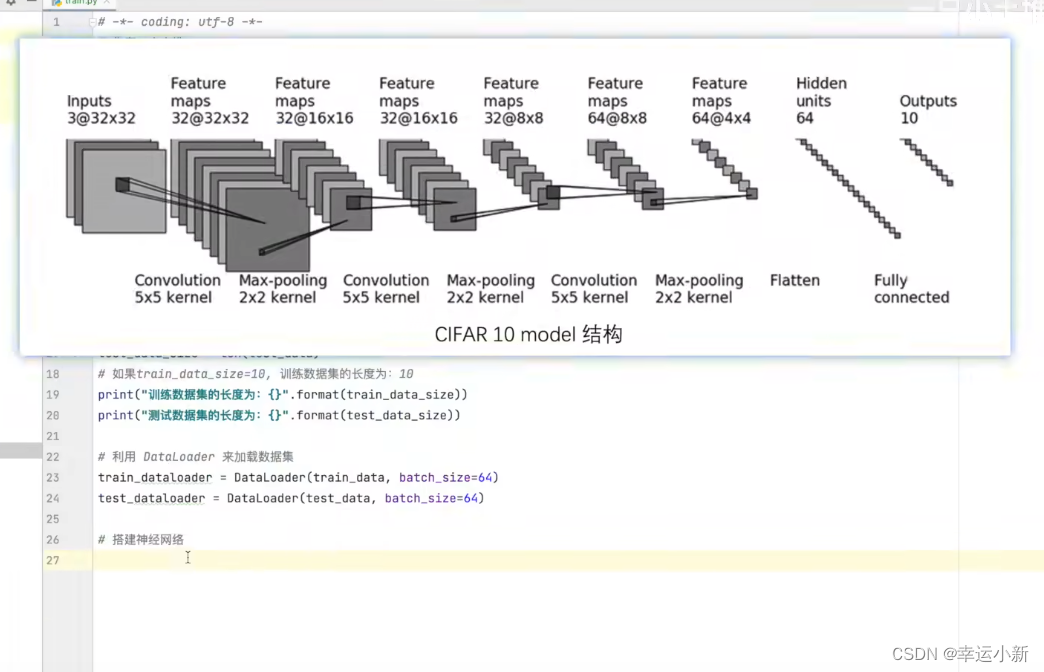
下面我们写一个对CIFAR10数据集进行分类的简单神经网络
最后为10的原因是要分成10个类别
比如预测的是概率的话,就取当中最大的对应的类别就是进过神经网络预测到的一个类别
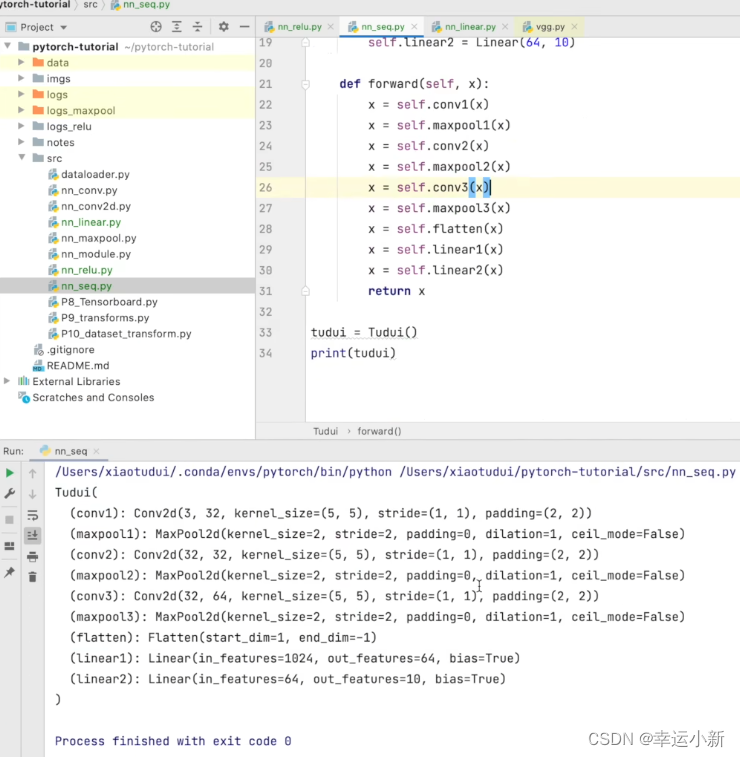
如何看我们网络是否正确呢
就是看我们网络的一个输入是否得到一个正确的输出
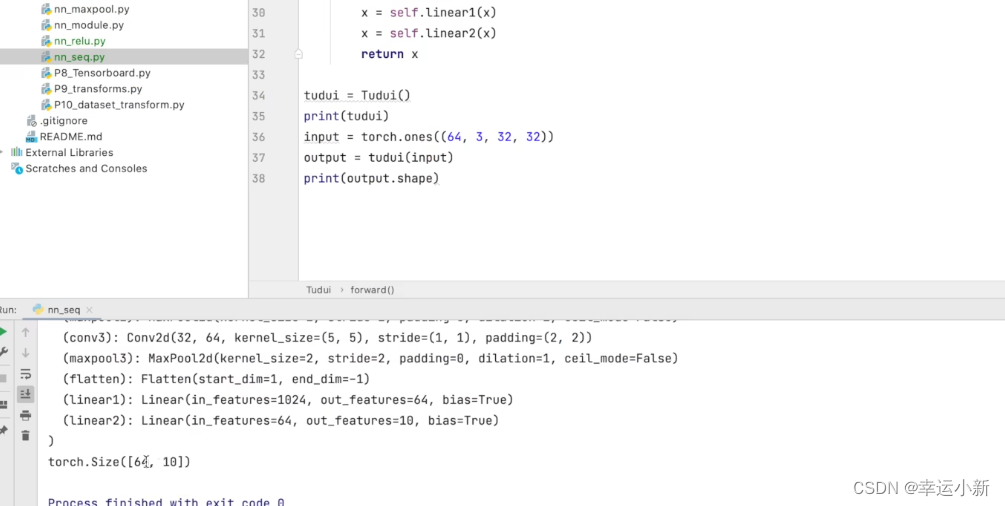

上面的1024是我们算出来的
有时候我们不会算怎么办
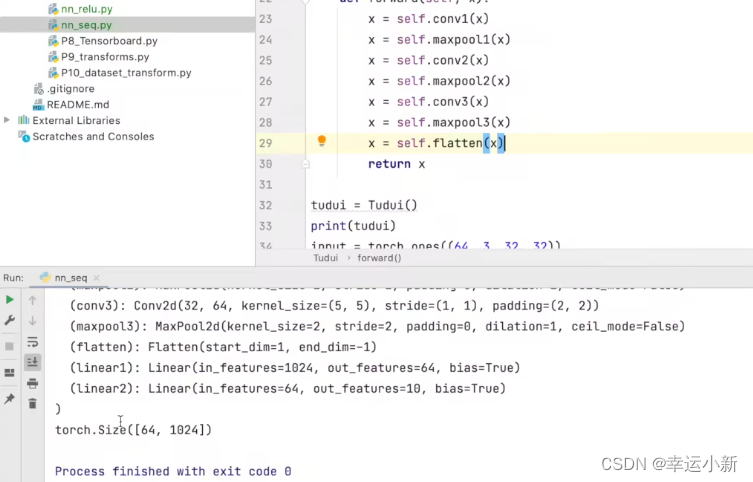
这里我们就当成有64张图片,每一张图片我们都是展成1024维的
使用sequential的话
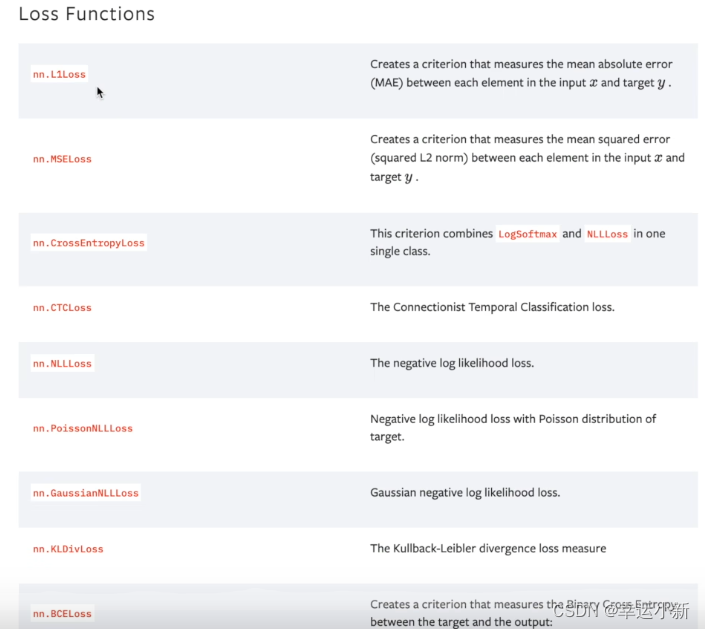
22.损失函数和反向传播



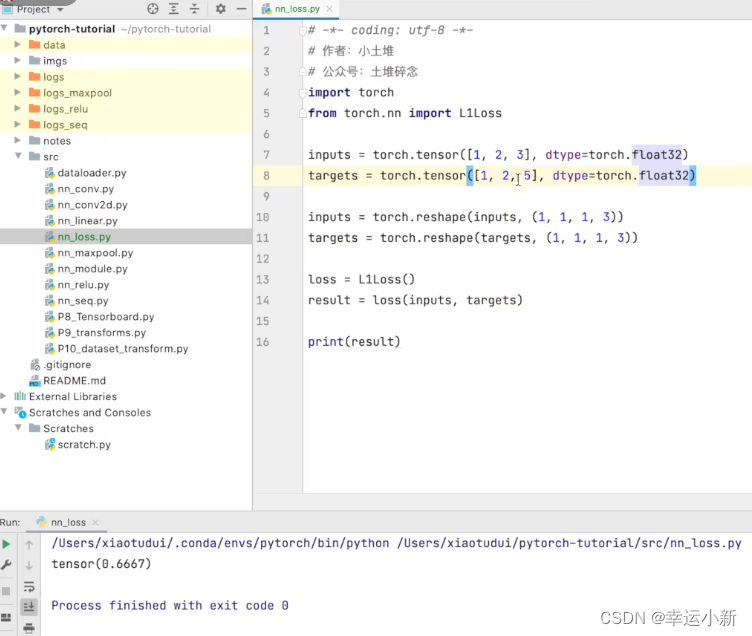
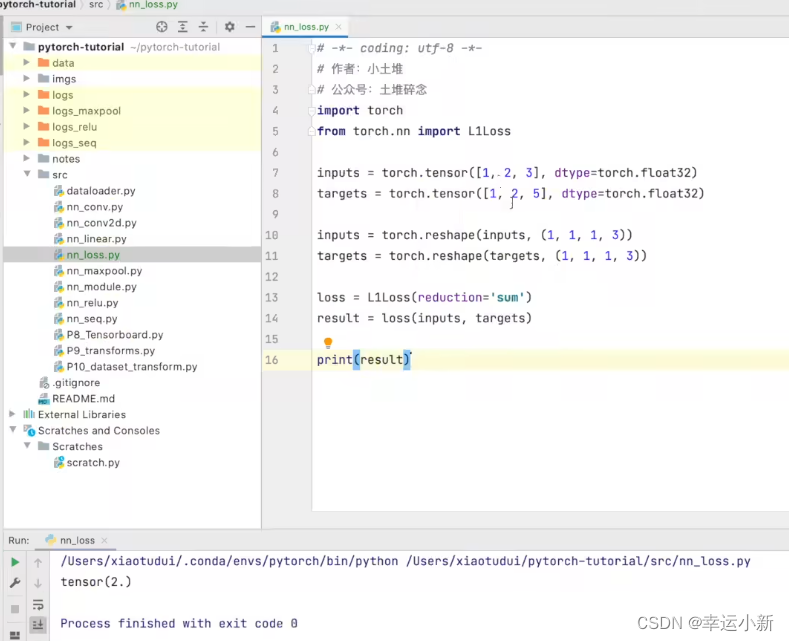
reshape是为了添加维度,原来的tensor是二维的
tensor在产生时会自带维度的,reshape是为了保证其维度是我们想要的,
符合某个你想使用的函数的特定要求
1 1 1 3 意思是 1个样本 通道为1 宽高为 1*3
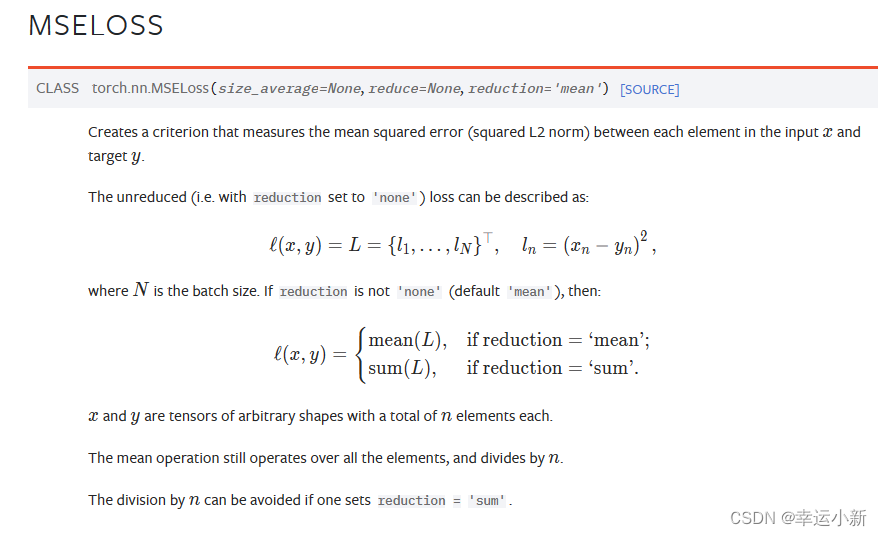
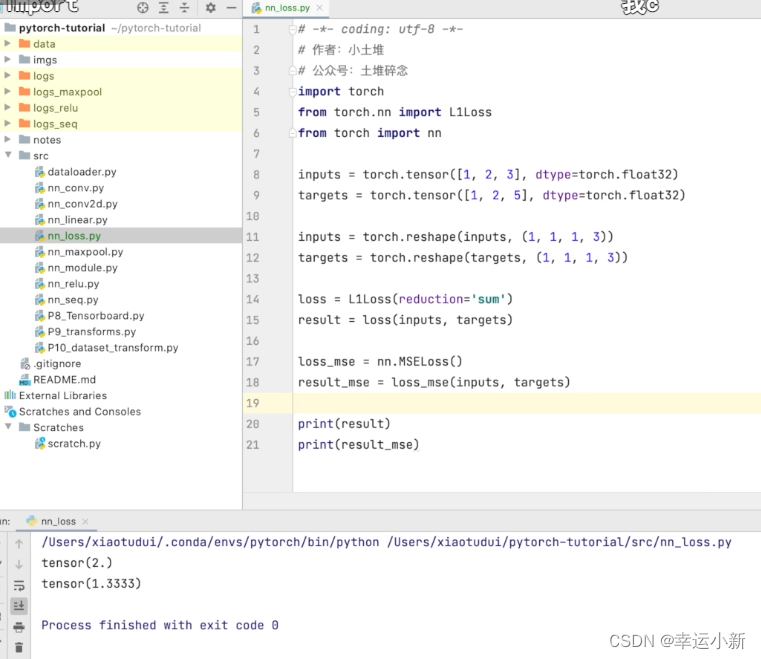

如果你看过一点机器学习的推到的话,优化器会有一个优化函数,那个函数你可以定性的理解为最小二乘,不同的优化函数对应不同的损失函数,mse是比较经典用于回归的损失函数
交叉熵,常用于分类的损失函数
It is useful when training a classification problem with C classes.
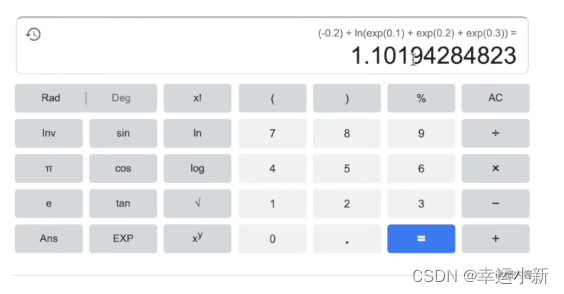
这里的交叉熵公式的输入值是未经过softmax的,经过softmax之后的输入值进行交叉熵函数和这个表达不一样,但最后得到的值和up主截的这个公式差别很小,几乎相等。



exp,高等数学里以自然常数e为底的指数函数,它同时又是航模名词,全称Exponential(指数曲线)。
算交叉熵一般都要soft-max的,概率和是1
注意这里的交叉熵损失公式是组合了softmax的结果
这里我们算的是类别1的softmax的函数值,我么希望这个值越大越好,但是通常损失函数都是最小化,所以我们最开始在前面加了个负号,然后我们求这个损失函数的最小值就行了
这里是经过softmax激活函数下的loss表示方式

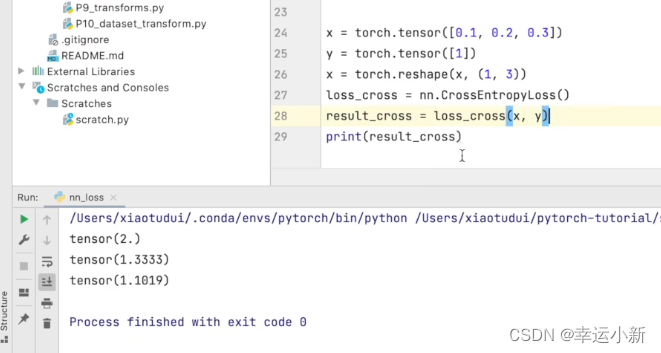
这里的输入要求是两个参数N和C
所以我们要torch.reshape(x,(1,3))表示1batch_size、3类


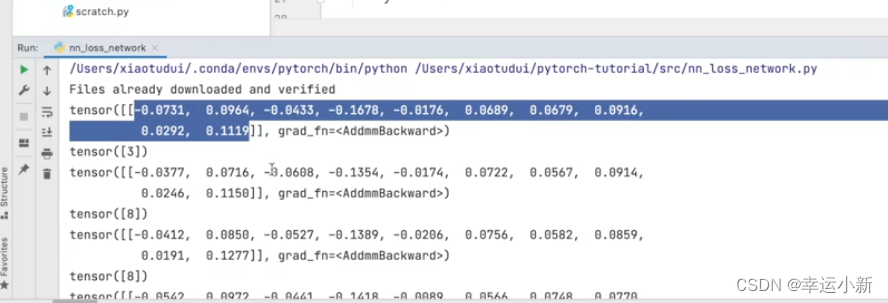
output一共有10个数,表示对应的CIFAR10这个数据集的10个类别的概率(其实这个不是概率,还要经过softmax层计算才能得到概率)
target为3
下面我们加入交叉熵损失函数
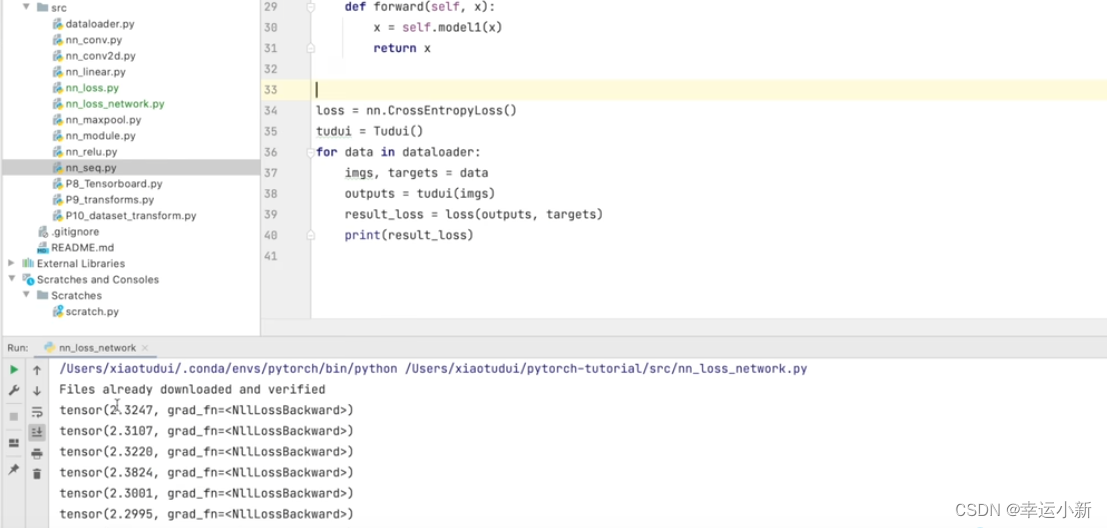
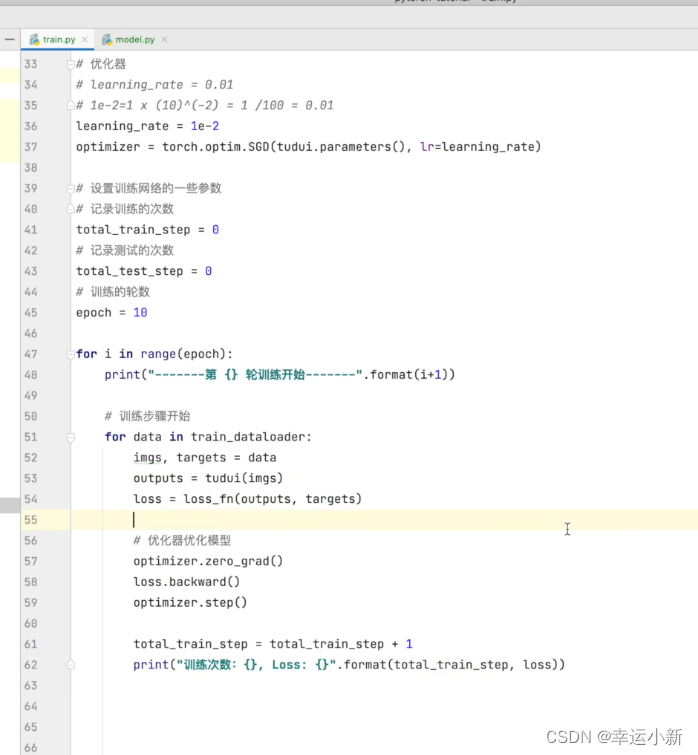
科普:反向传播意思就是,尝试如何调整网络过程中的参数才会导致最终的loss变小(因为是从loss开始推导参数,和网络的顺序相反,所以叫反向传播),以及梯度的理解可以直接当成“斜率”
我们debug一下

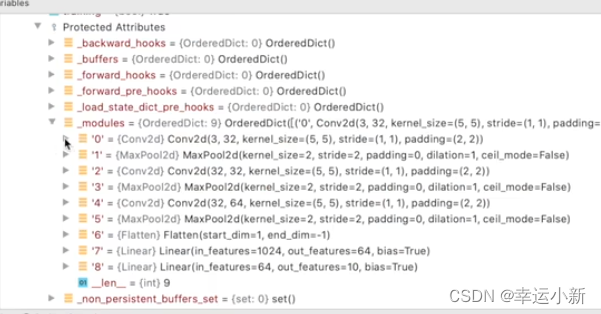
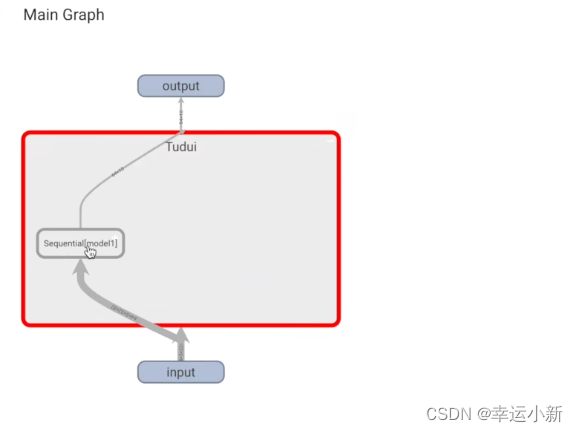
这里就是我们的网络
第一个就是一个卷积层
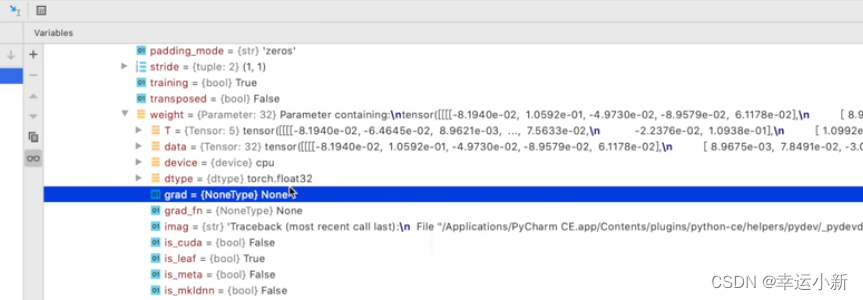
权重里面就有grad(gradient梯度)这个参数
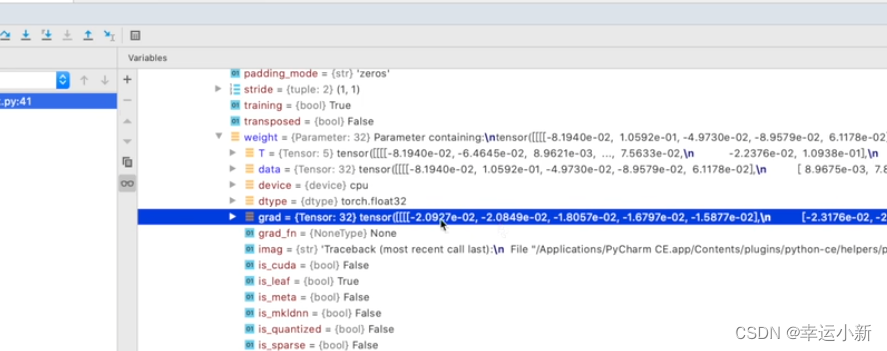
运行到下一步就会有这个梯度了
下面我们就要选择合适的优化器,优化器会利用这些梯度对我们神经网络中的参数进行一个更新,以达到对整个loss进行降低的一个目的
如果我们不进行backward()反向传播这个操作,我们是没有梯度这个参数的
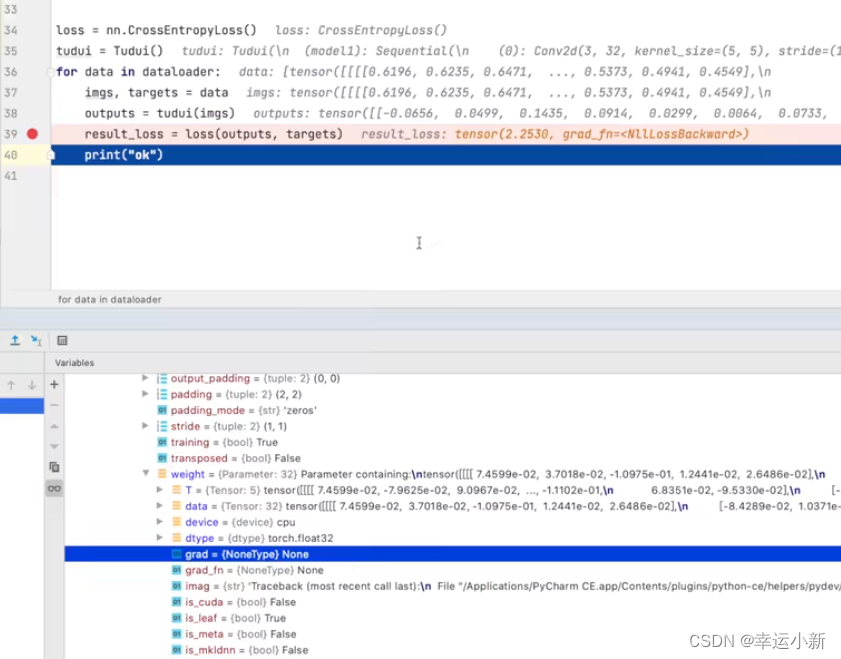
下面我们就要选择合适的优化器,优化器会利用这些梯度对我们神经网络中的参数进行一个更新,以达到对整个loss进行降低的一个目的
23.优化器
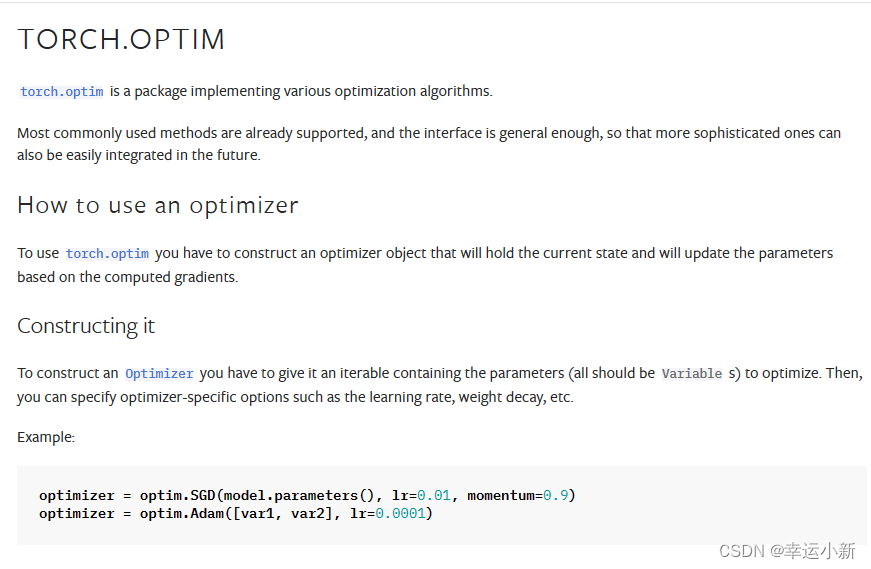
model.parameters()是模型参数,这个是必备的
Ir是模型速率
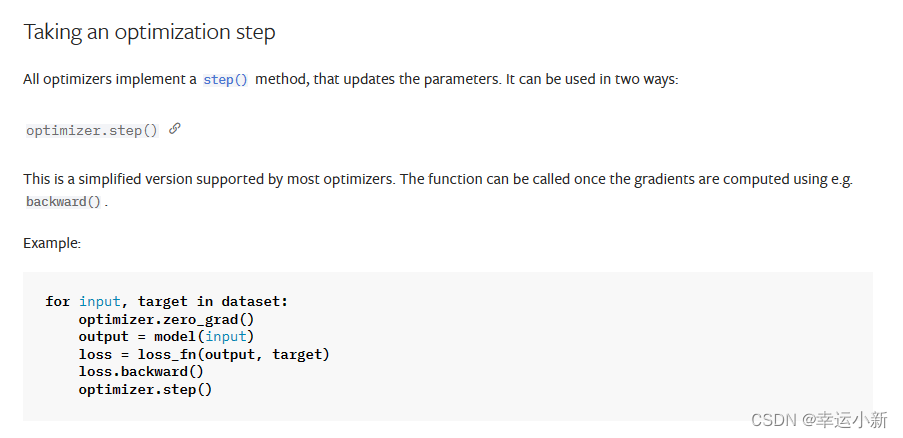
这里的step会利用我们的梯度对模型进行一个更新

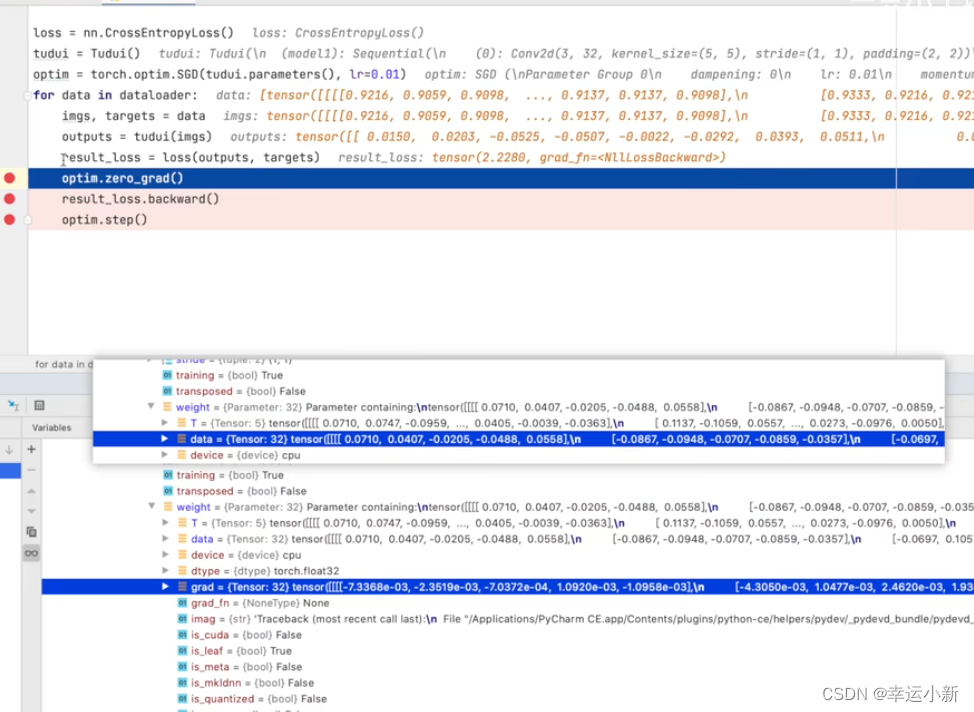
这里我们就是使用grad来更新我们的weight
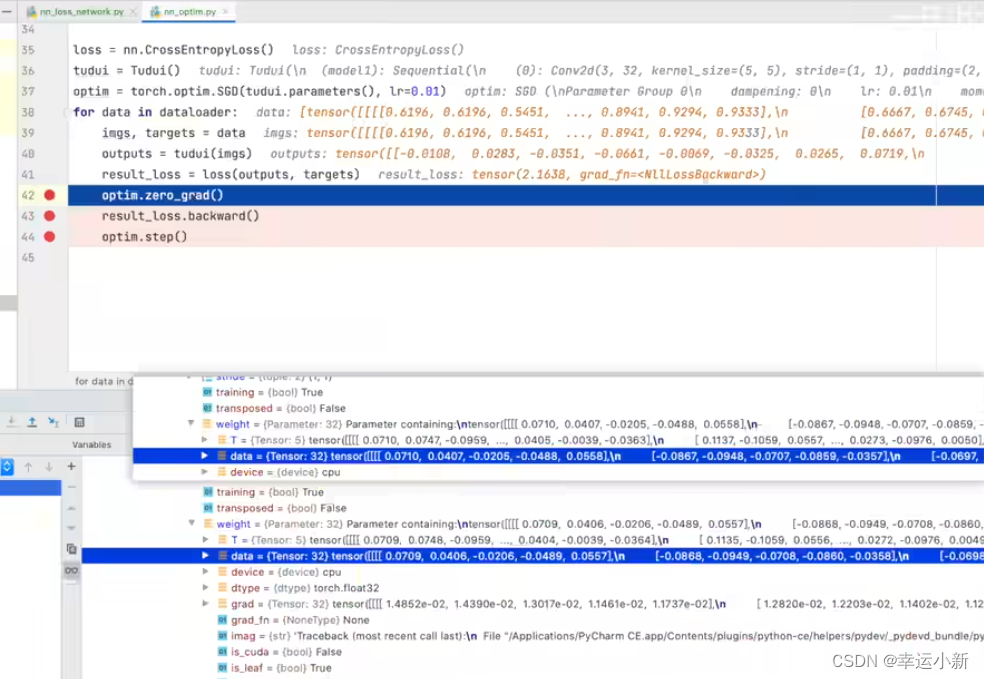
不断地清零grad,更新weight,使我们的loss变小
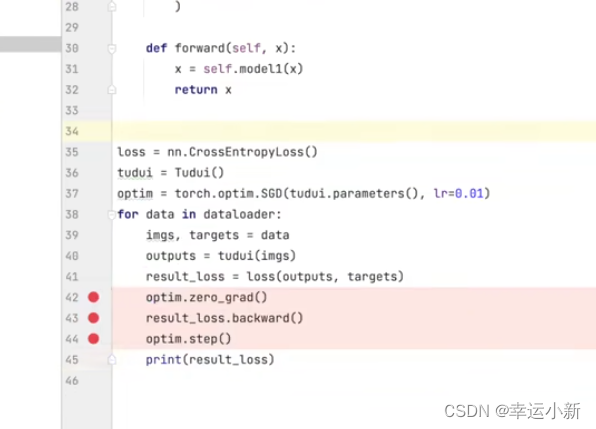
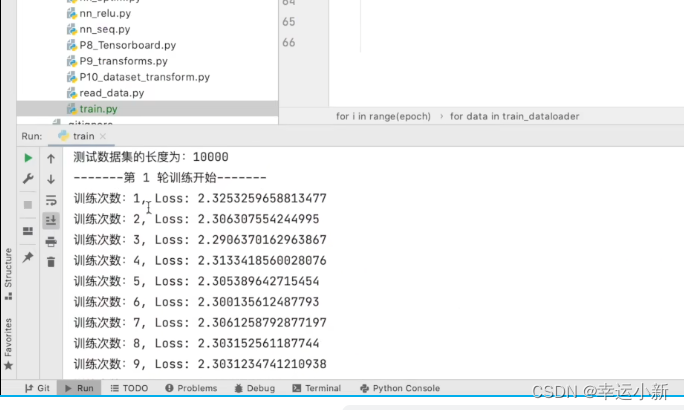
我们可以看一下结果
下面这个就是我们的loss每次更新后的变化
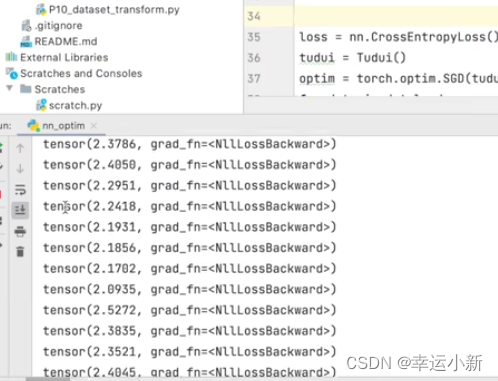
我们发现loss好像并没有减小
因为这里相当于我们的网络模型对我们的数据(dataloader)只看了一遍
我们一般情况下都要对这个数据进行好几轮的学习

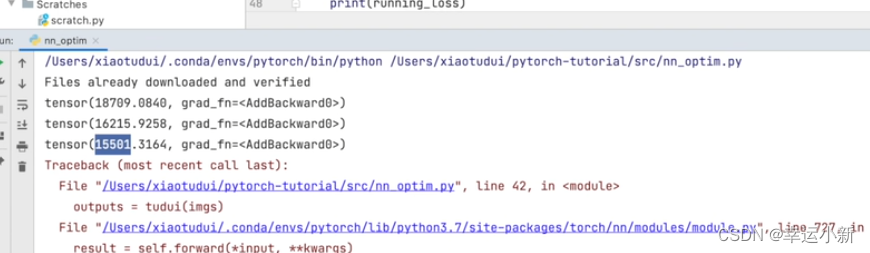
我们发现优化器不断优化
每一轮的loss不断减小
一般我们可能要训练成百上千次,20次算比较小了
24.现有网络模型的使用及修改
官网有很多预训练好的模型
比如用于分类的
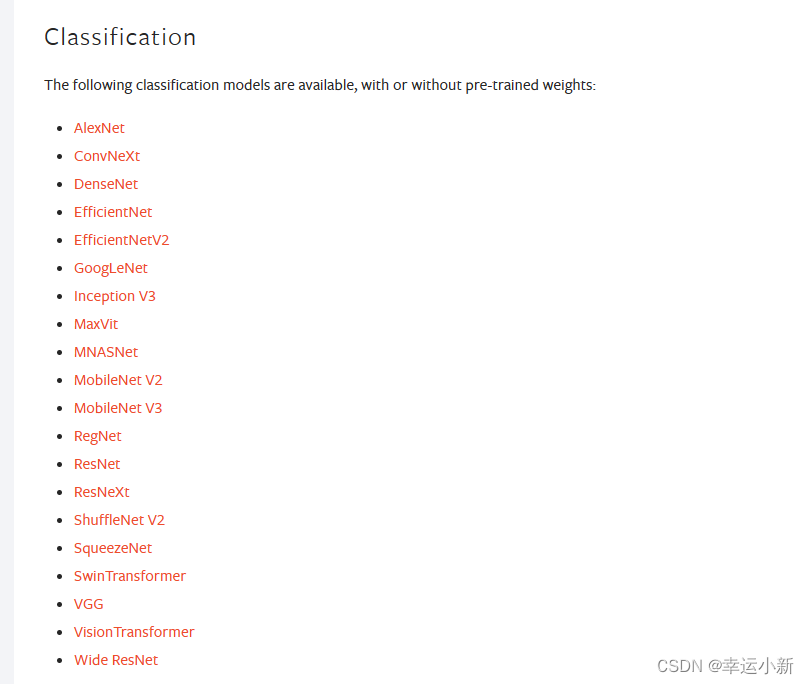
用于语义分割的
用于目标检测的

这次我们讲解一个分类模型VGG16,还是用CIFAR10这个数据集
新版本中这个参数被取代为weights,如果不进行预训练,在weights = none;如果仍想加载在ImageNet上的预训练参数,则weight= ‘imagenet’
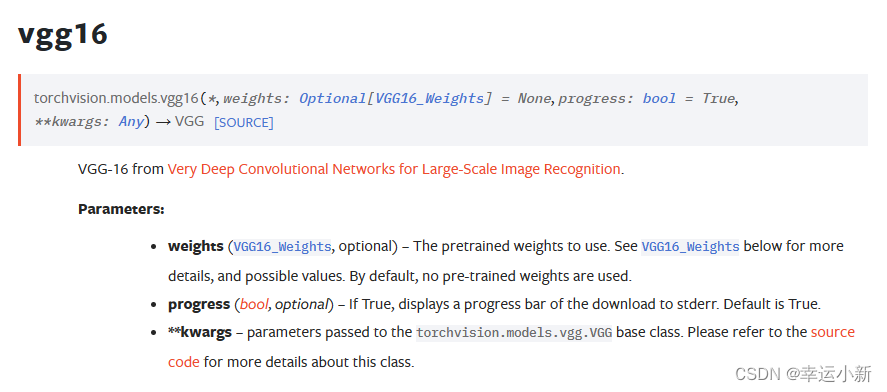

pretrained为true的话,就是相当于我们的网络模型的参数在ImageNet这个数据集中已经训练好了
为false的话,参数就是初始化的参数,没有在任何的数据集上进行一个训练
progress为true的话,就会显示一个下载进度条
装这个数据集要先安装scipy
scipy,用于科学计算的一个Python包

没有就安装

这个数据集太大了
最新调用预训练模型权重方法:weights=VGG16_Weights.DEFAULT
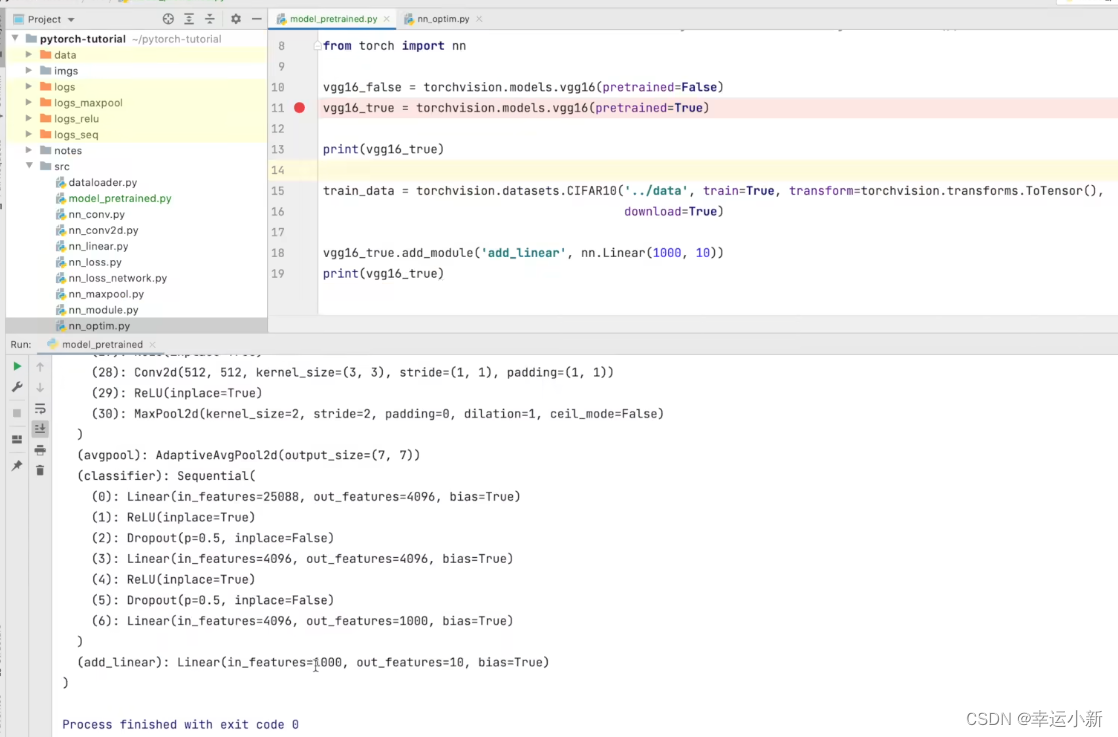
我们直接看一下,这个训练好的模型和没有训练好的有什么区别


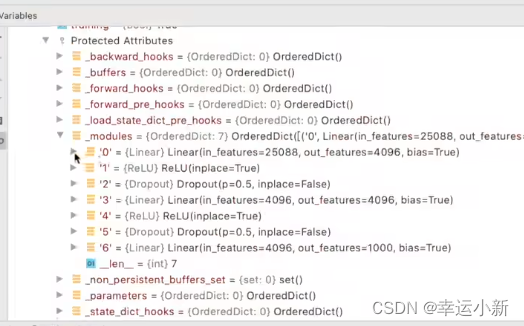
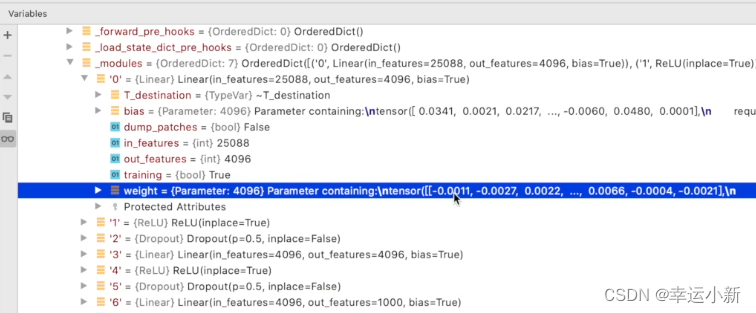
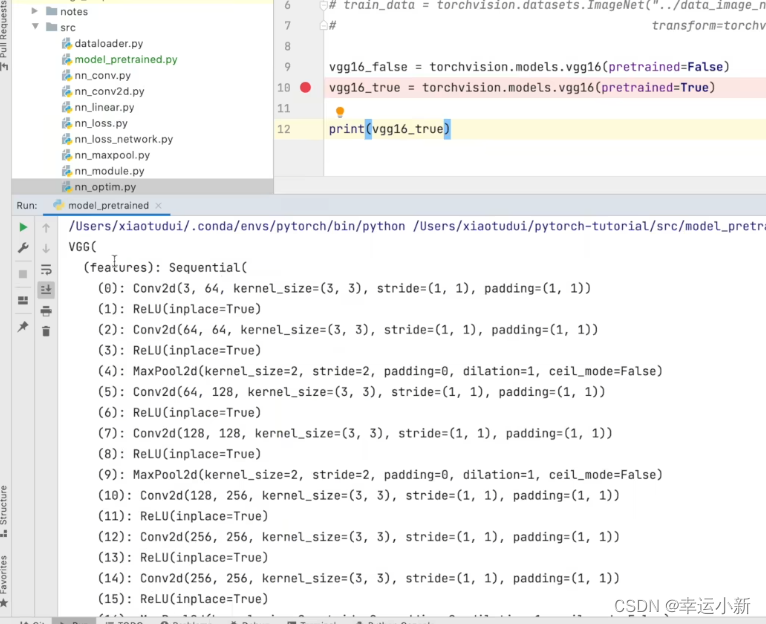
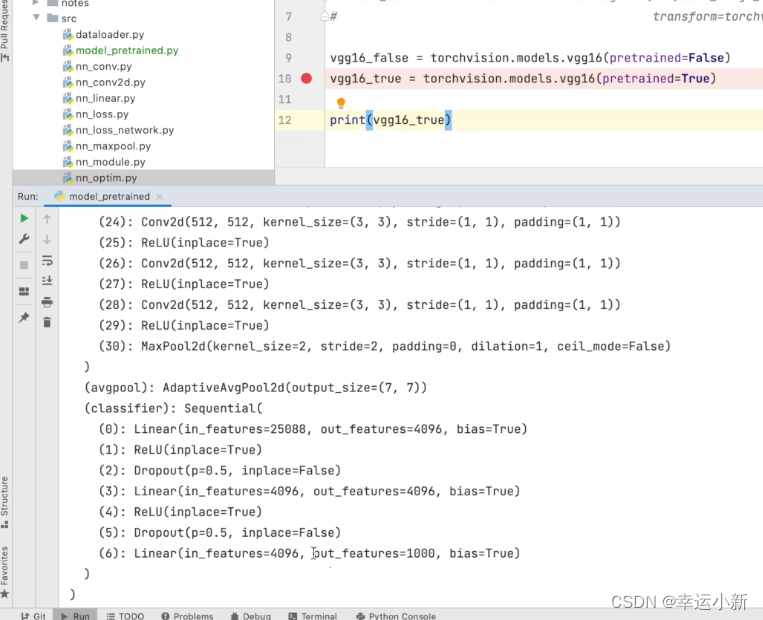
我们看到最后的线性层,发现输出是1000
说明我们的vgg模型是一个分类模型,有1000个类别

如果我们有一个VGG模型
他将这个数据集分成了1000个类,那么我们如何去运用这个网络模型呢
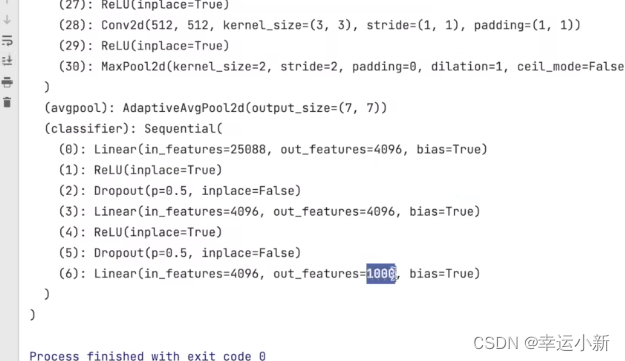
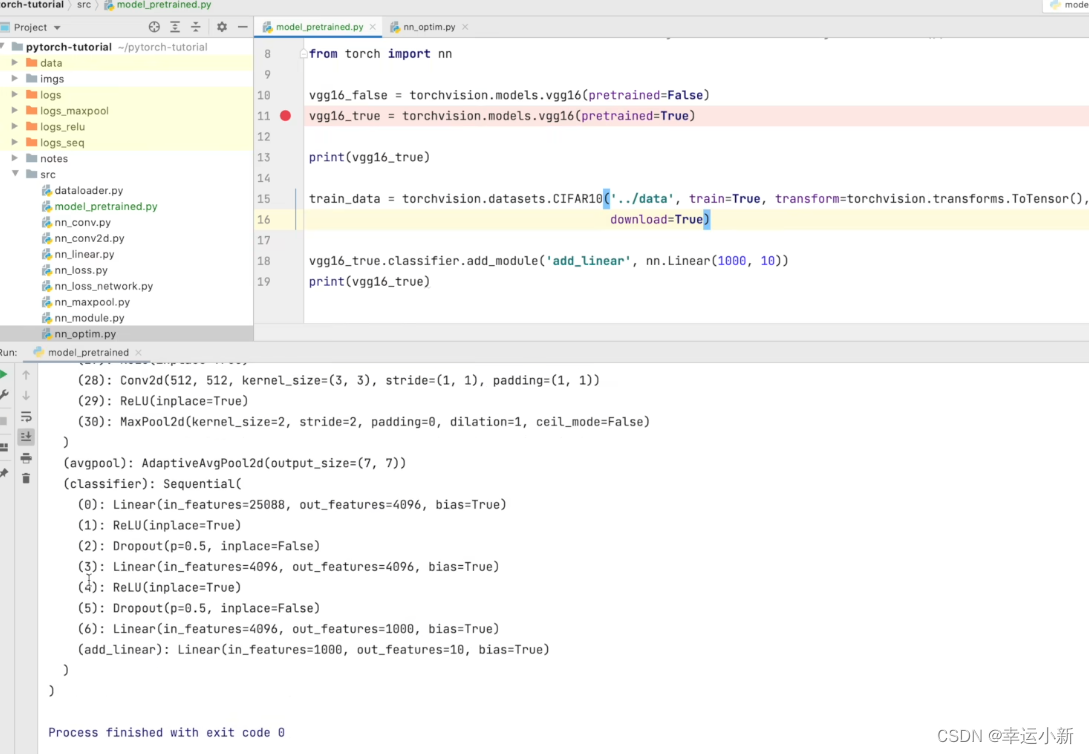
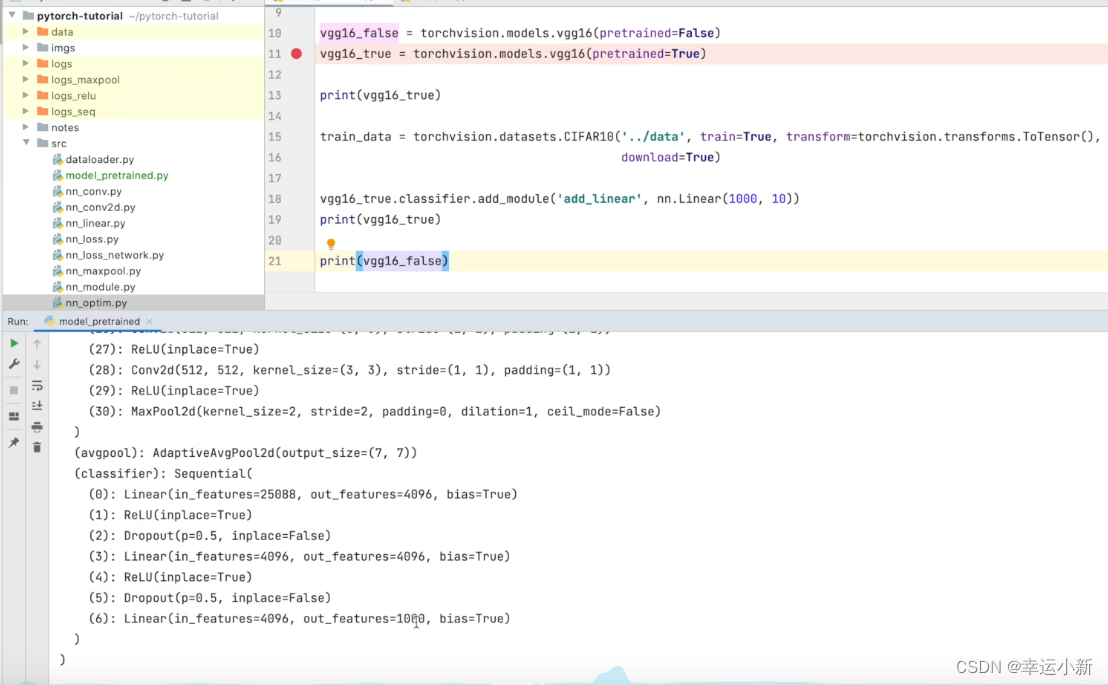
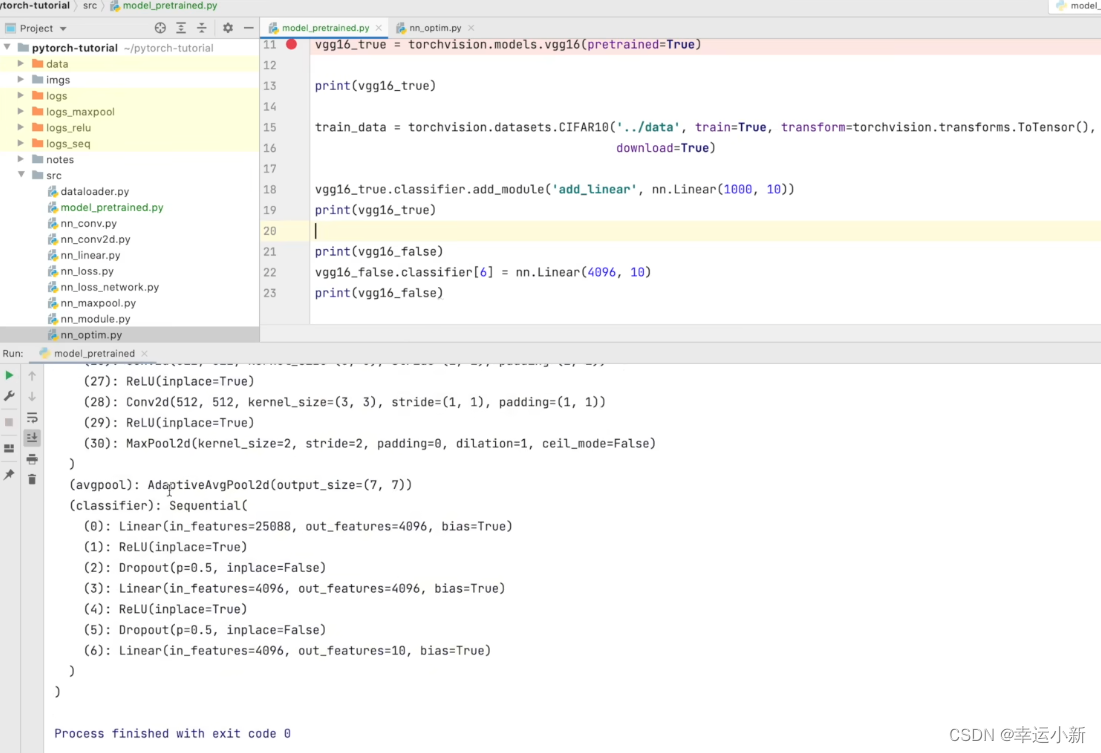
第一种方法就是将out_features的1000改为10
第二种方式我们就在最后的线性层下面再加一层,in_features为1000,out_features为10
下面我们就讲讲,如何使用现有的网络去改动他的结构
选择很多网络就是将VGG16当成一个前置的网络结构,利用这个VGG16去提取一些特征,在VGG16后面再加一些结构去实现它的一个功能
只有在分类相近的情况下才比较有用,不能乱迁移
如果我们是要做一个修改
25.网络模型的保存和读取

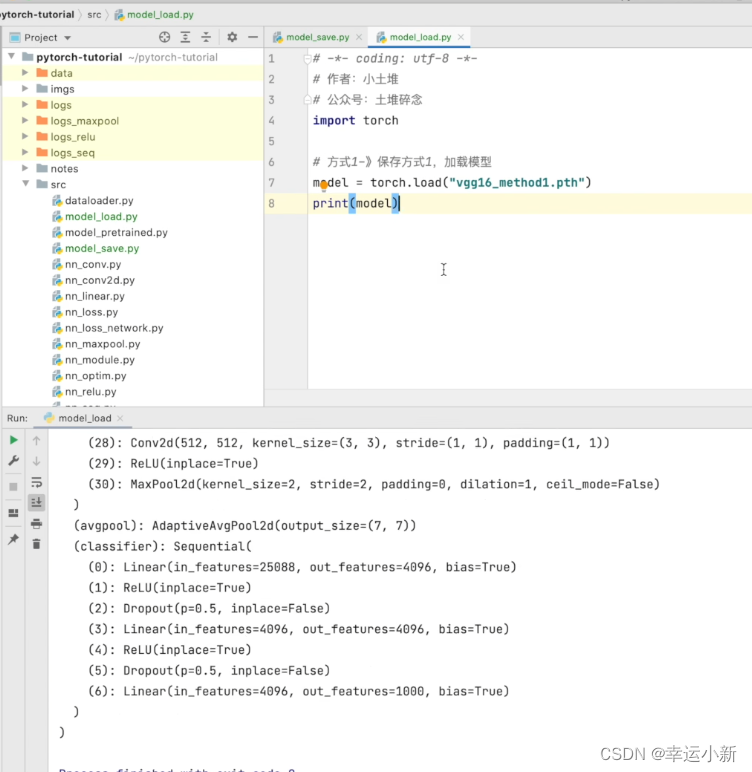
保存方式一
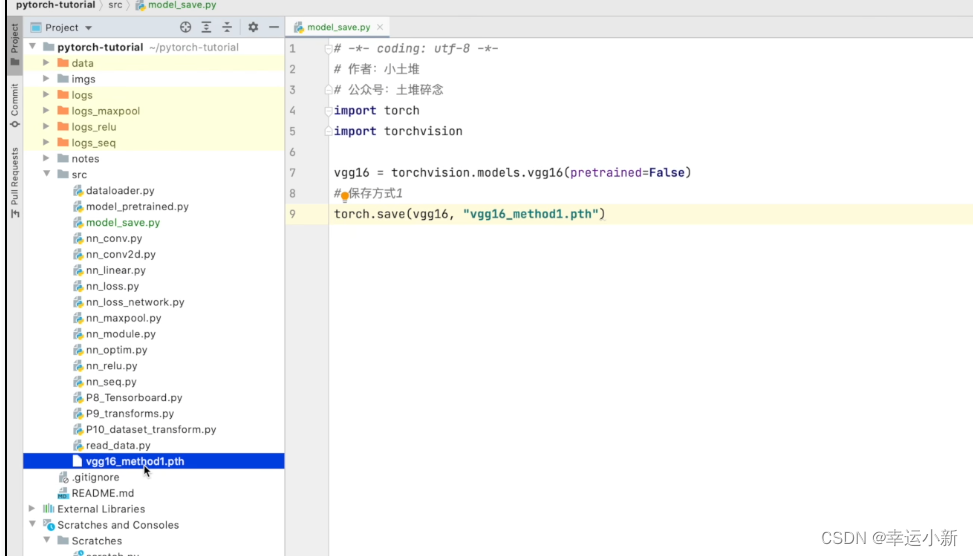
这种方式保存的不仅是我们网络模型的结构,还有我们网络模型的参数
保存方式二


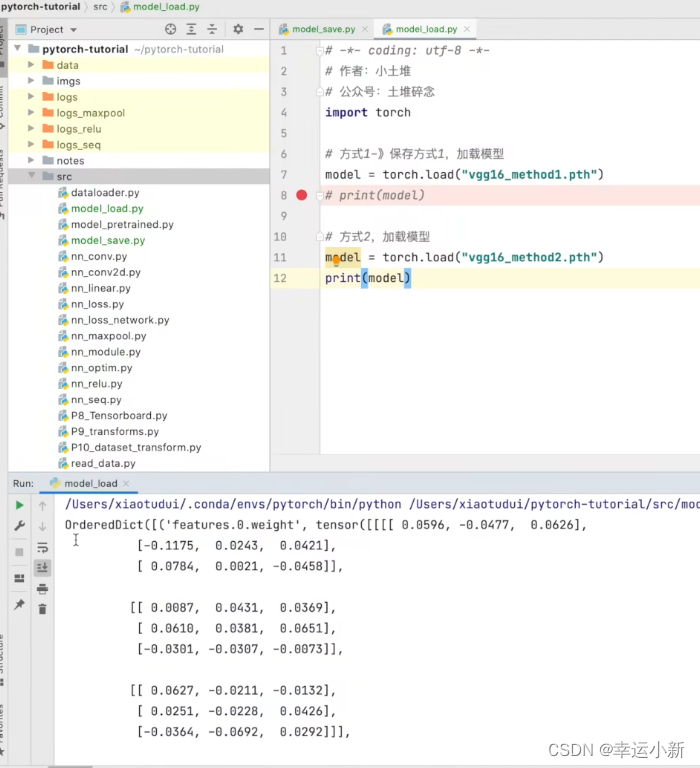
方式二打印出来的是一个个字典形式
如果我们要回复成网络模型
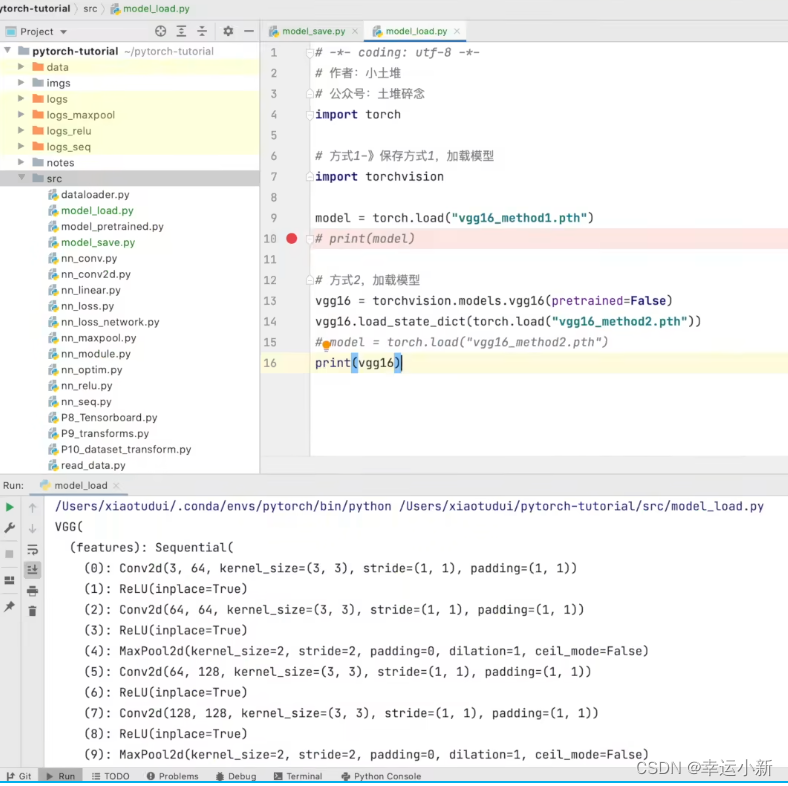
陷阱
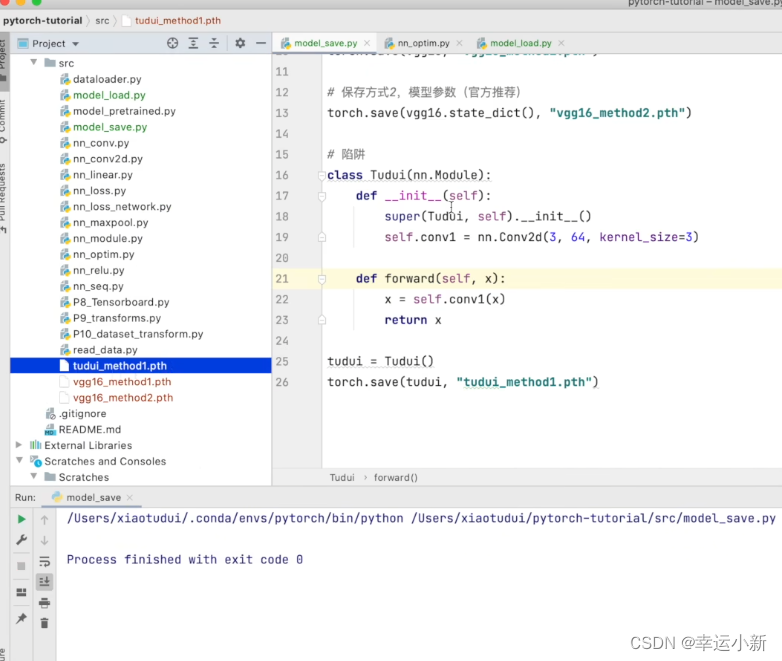
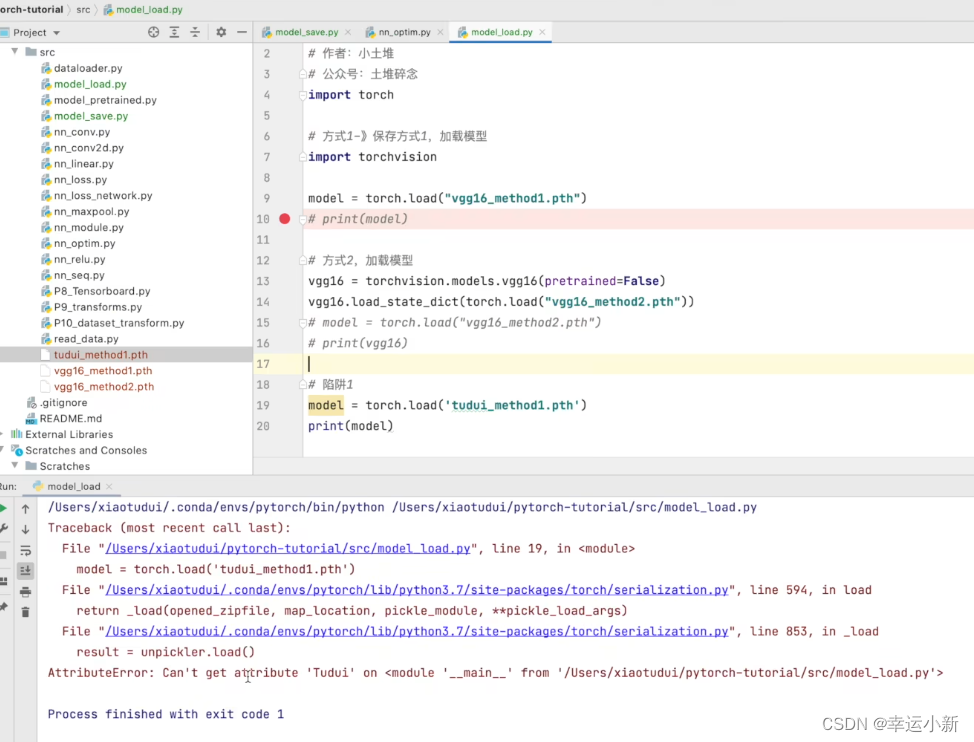
加载这个模型的时候就会出错
因为这里没有tudui这个属性
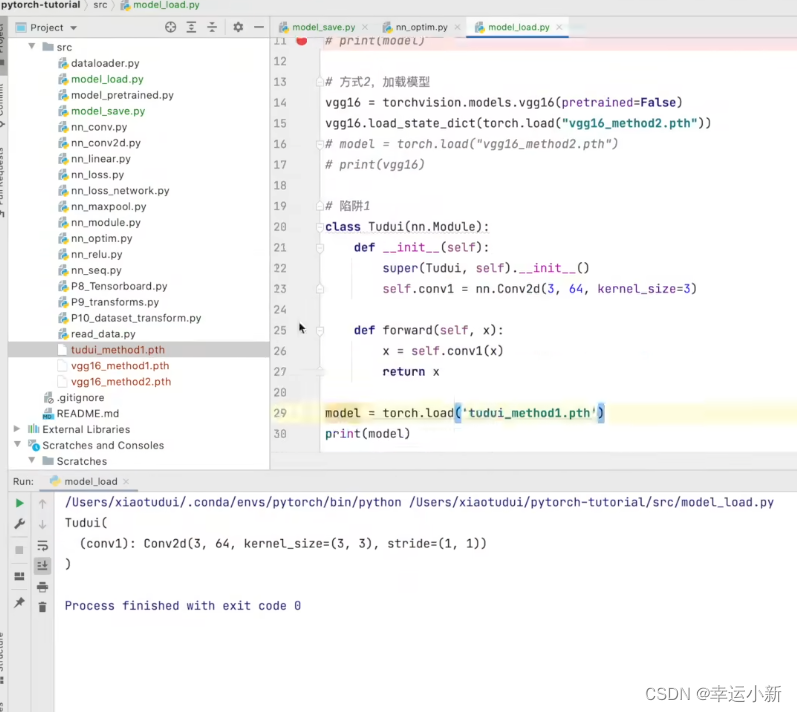
或者直接import

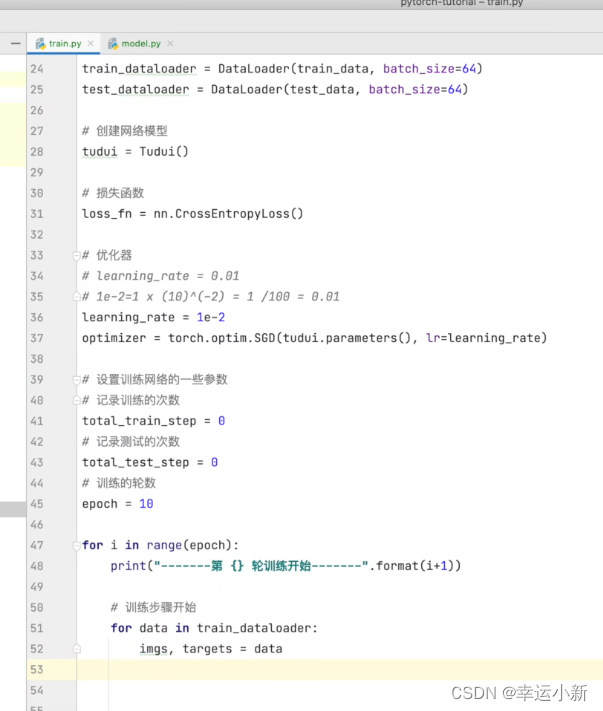
26.完整的模型训练套路(一)

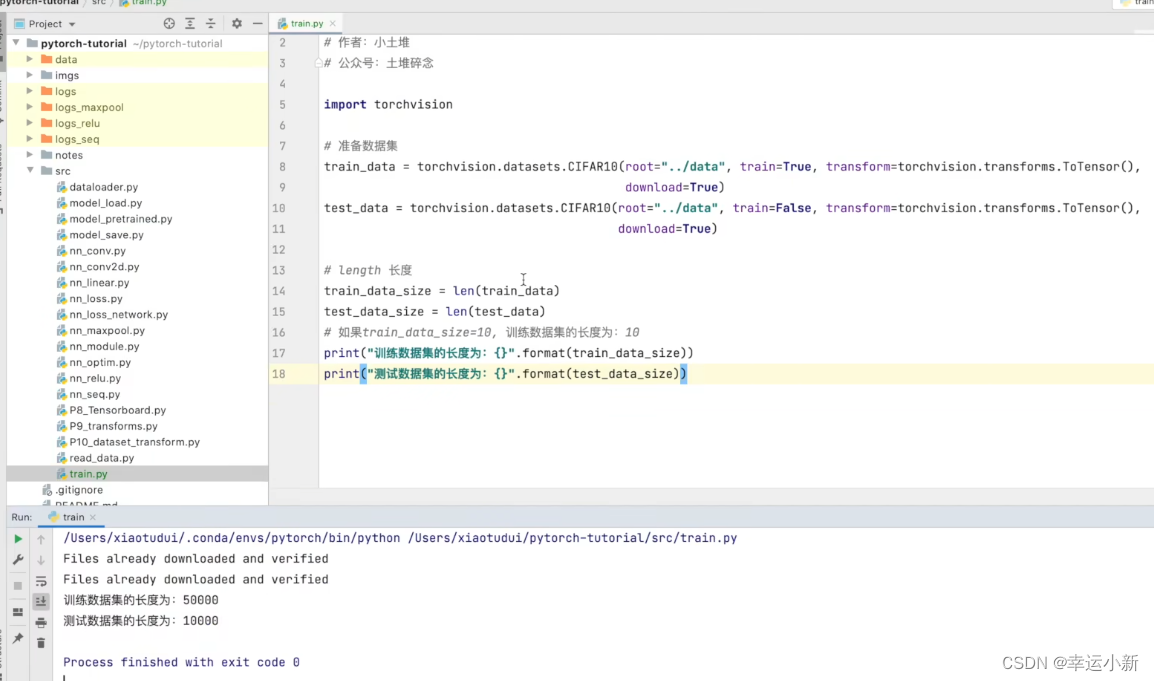
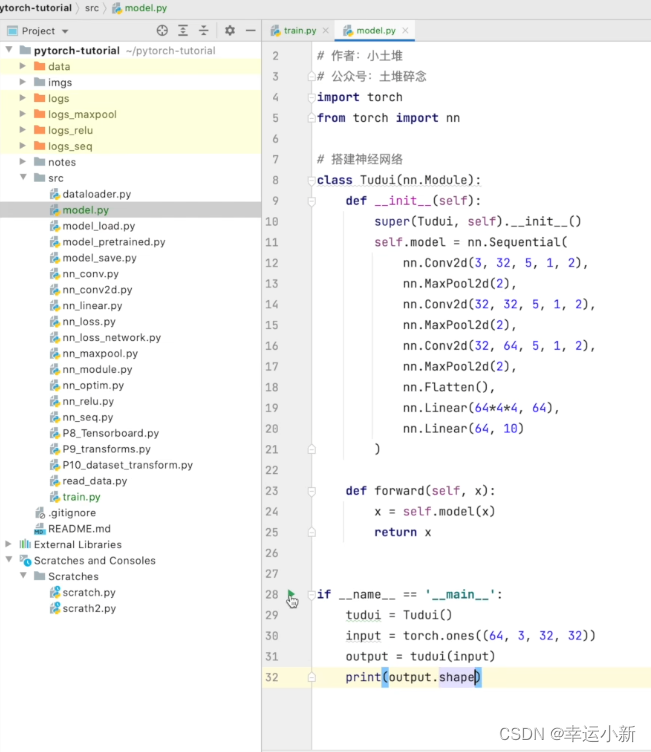
我们还是搭建之前的网络模型
上面的64表示batch_size为64
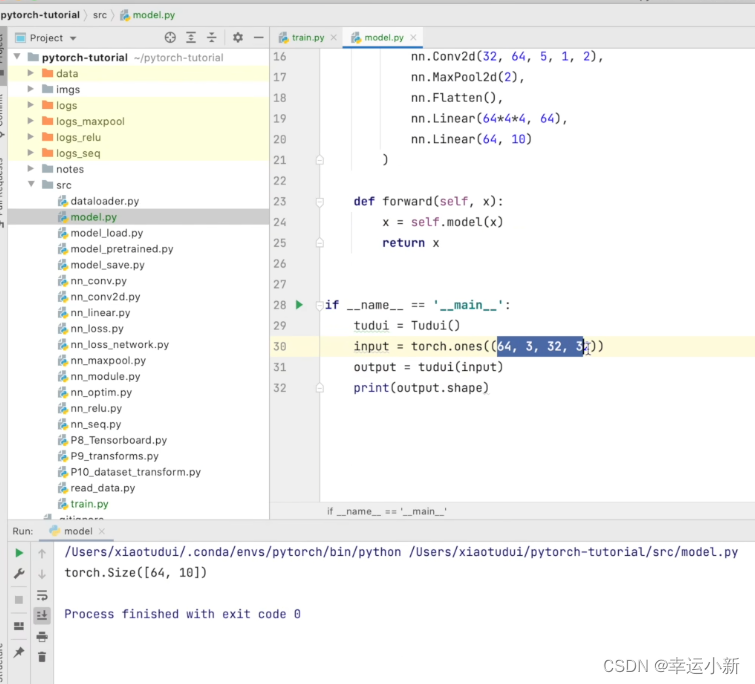
返回的是64行数据,每一行10个数,表示属于每一个类的概率
引入model

27.完整的模型训练套路(二)
下面我们考虑一下
我们怎么知道我们的模型有没有训练好,有没有达到我们的需求
我们会在每一次训练完一轮的时候进行一个测试
在测试数据集上跑一遍
以测试数据集上的一个损失、准确率来评估模型有没有训练好
在训练集我们就取消梯度,保证无法对模型进行一个调优
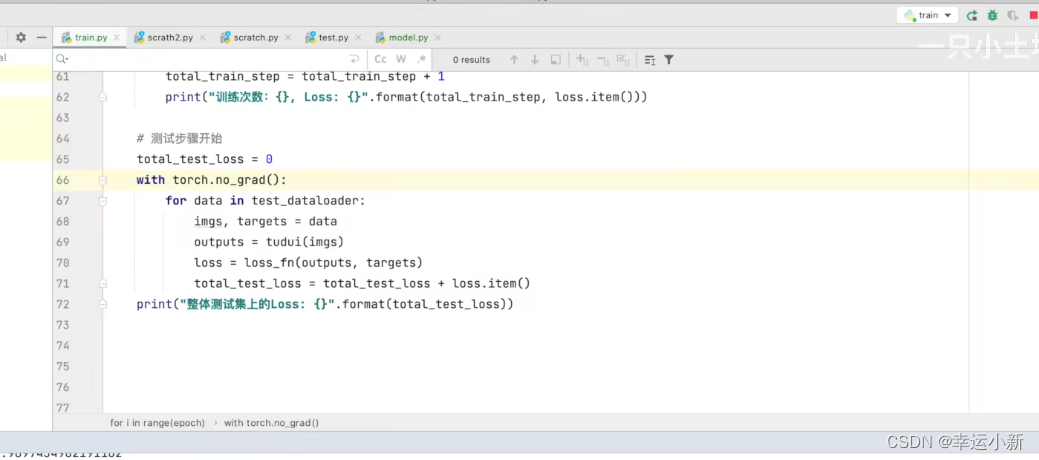
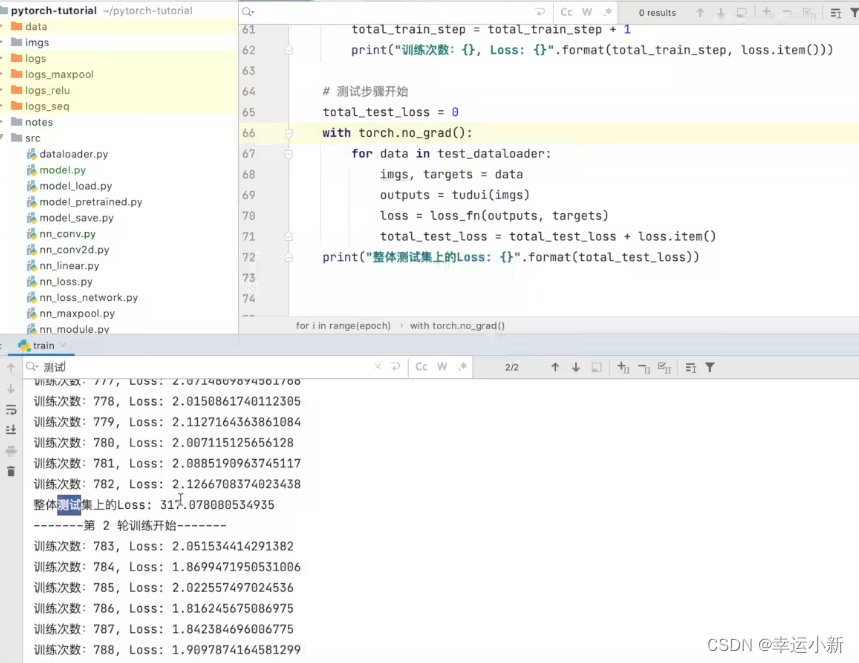
我们发现这个测试的loss不太好找
调整一下代码
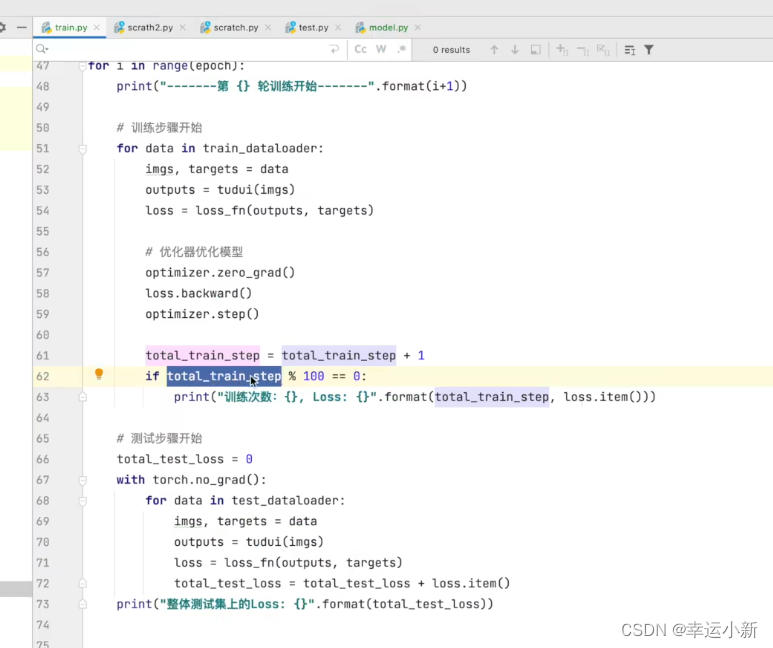
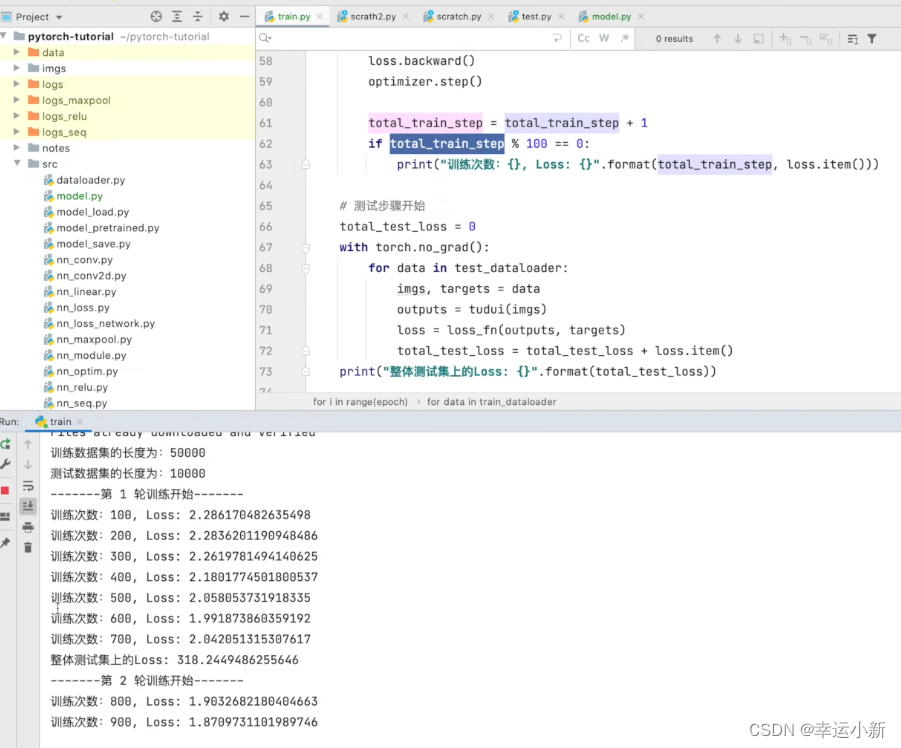
下面我们再继续一个优化
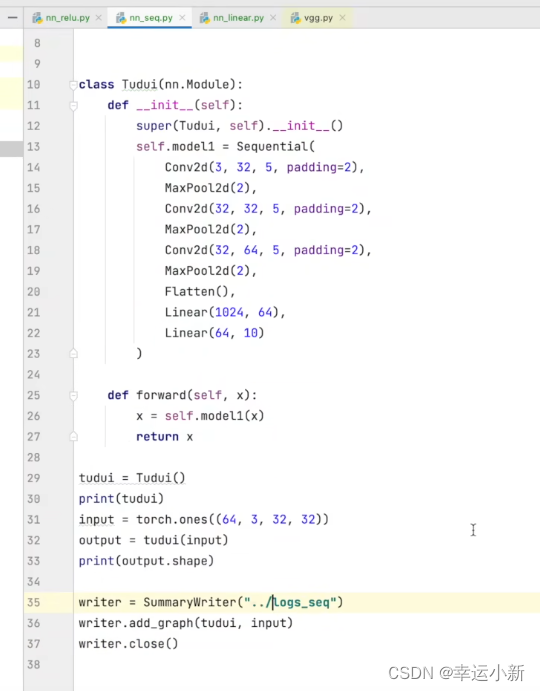
下面我们将我们每次的数据存储到tensorboard中
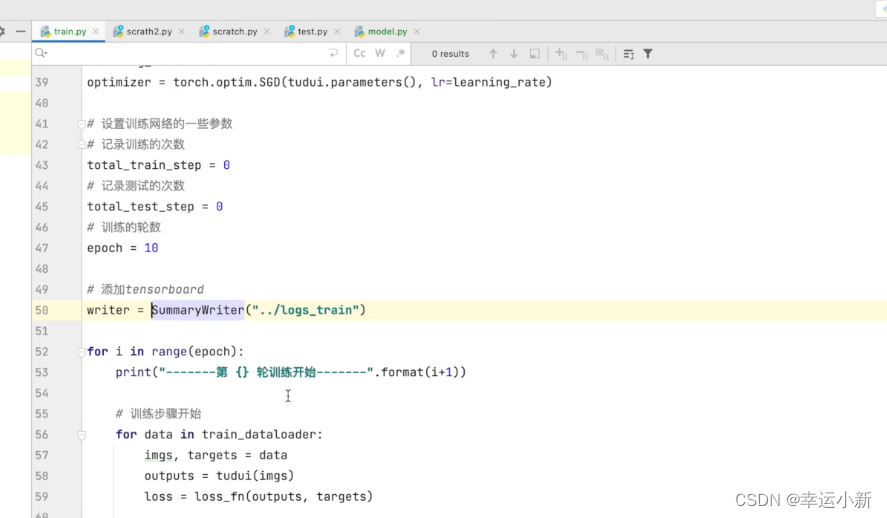
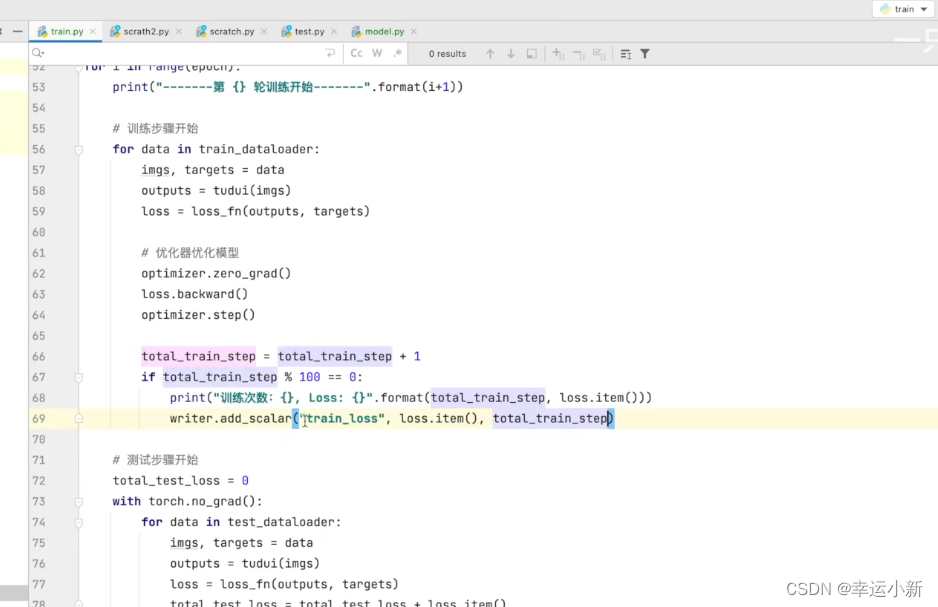
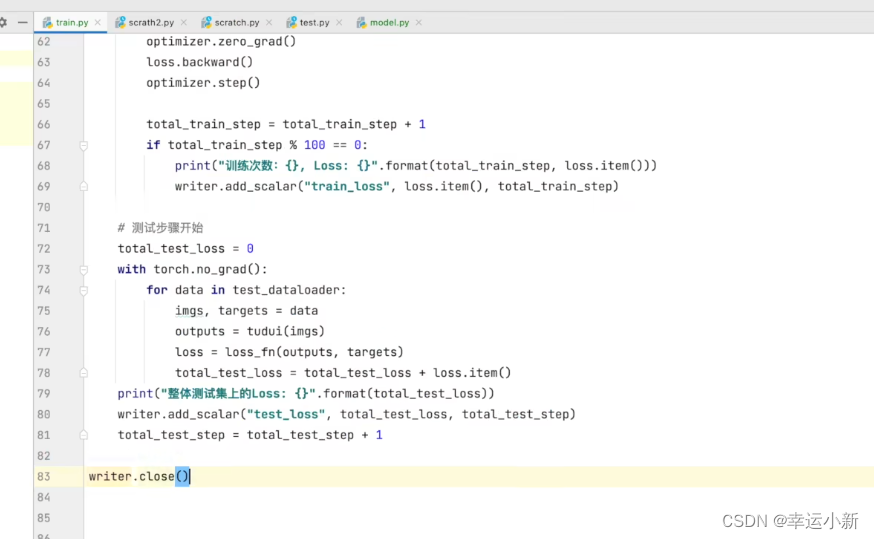
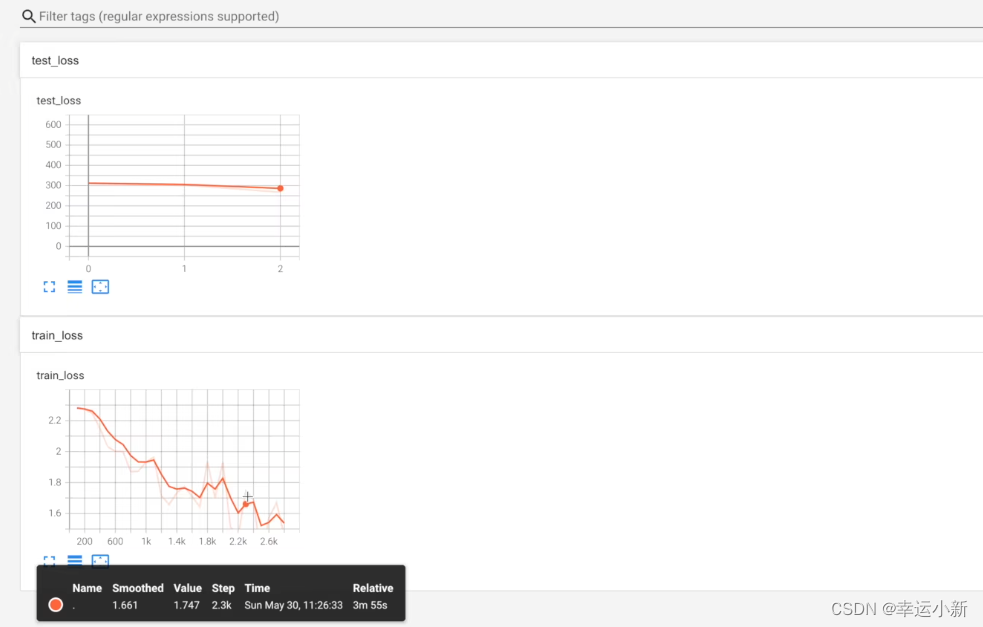
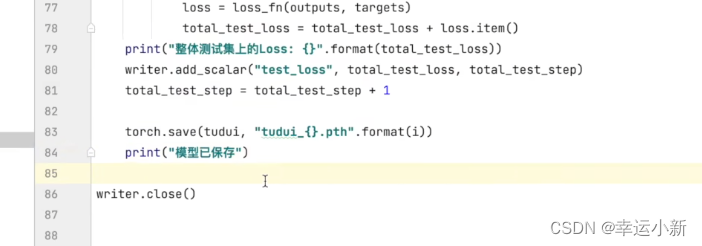
如果我们需要保存我们每一轮训练的模型
还有一个问题就是我们整体测试集上的一个loss也不能很好的说明我们在测试集上表现的一个效果
在我们的分类问题中,我们可以使用一个正确率来进行一个表示
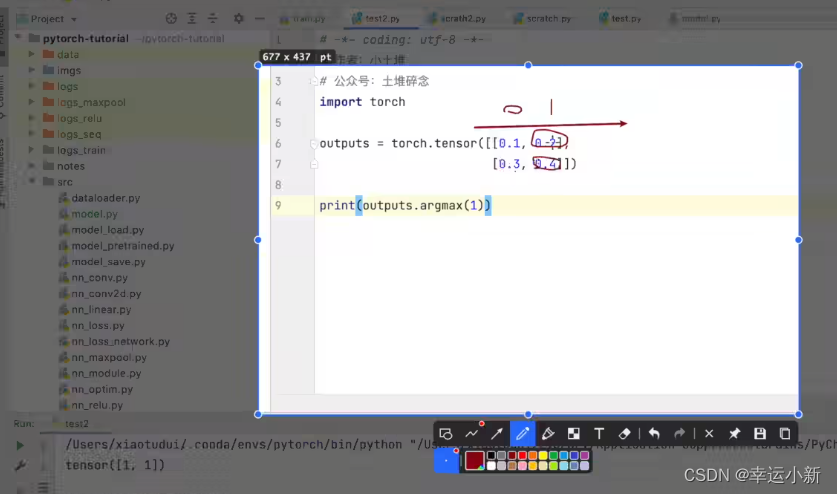
argmax中参数为1就横向看
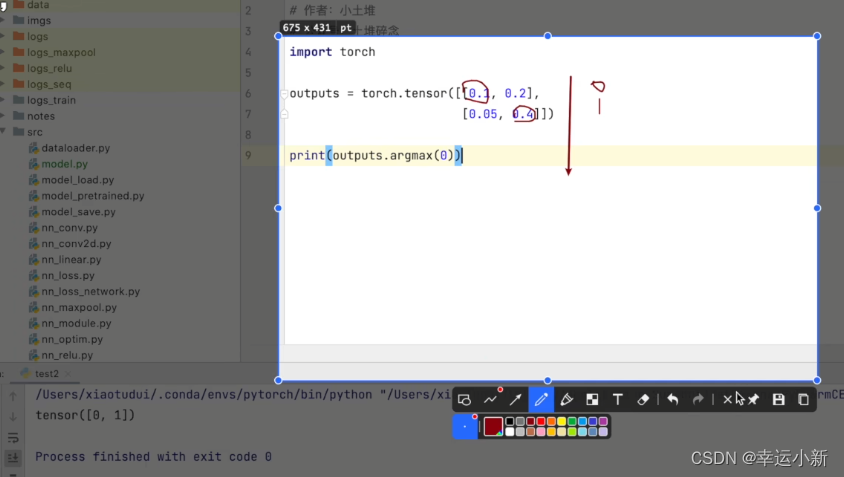
argmax中参数为1就纵向看
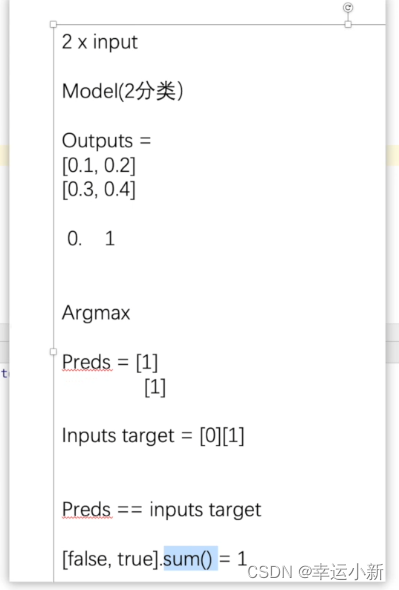
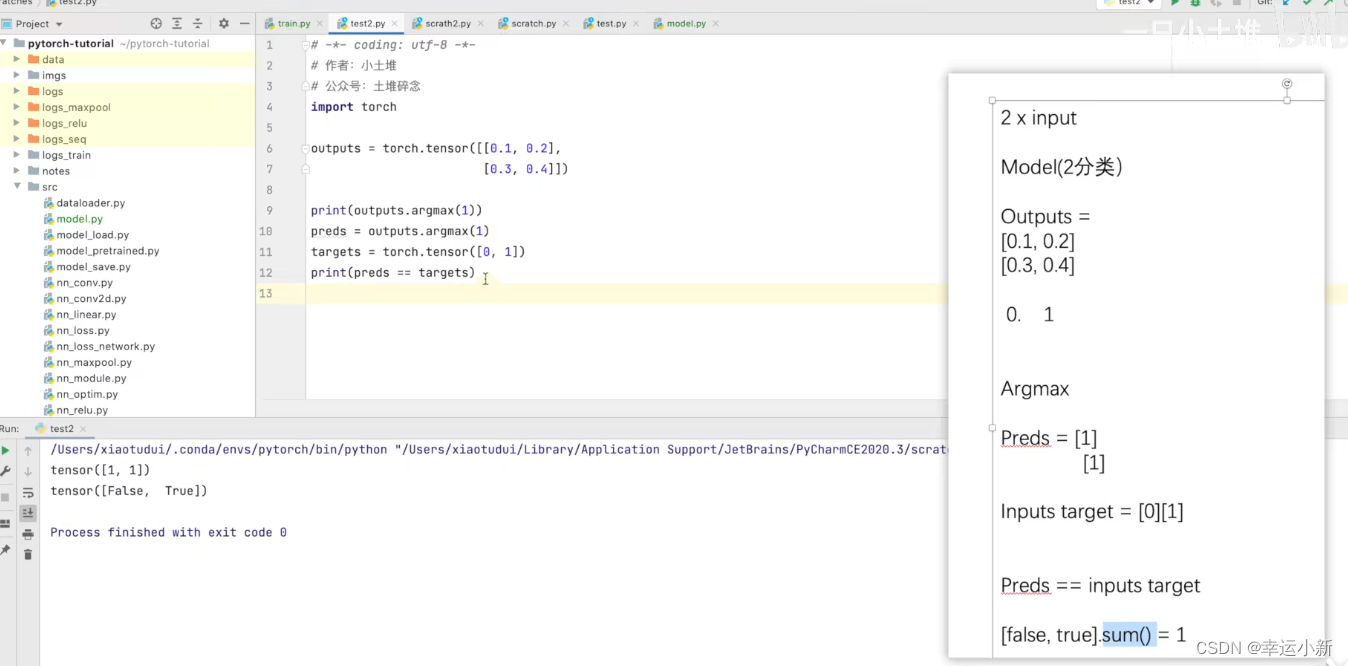
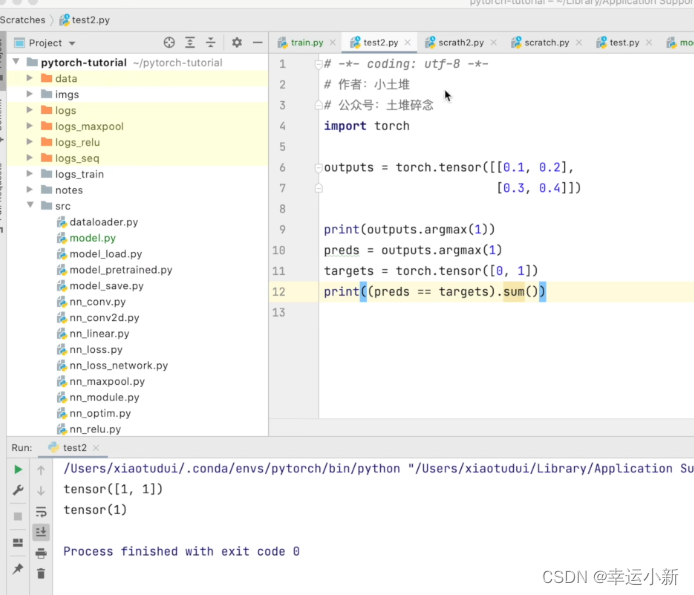
下面我们就可以给我们的代码继续做一个优化
我们可以计算出整体的正确率
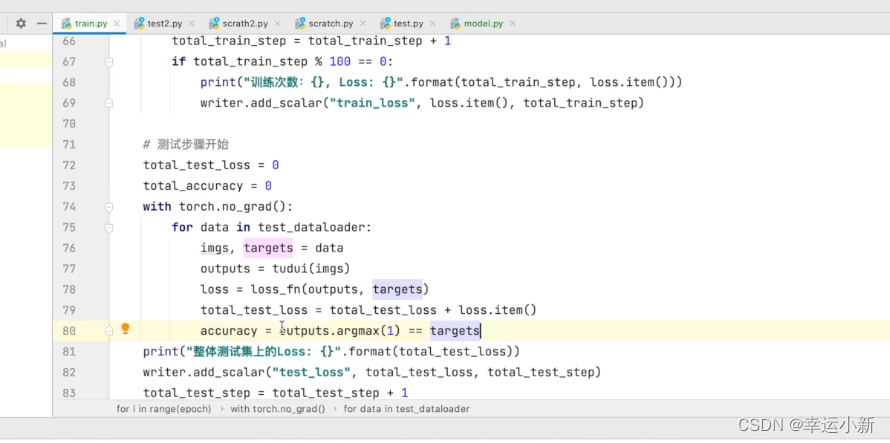
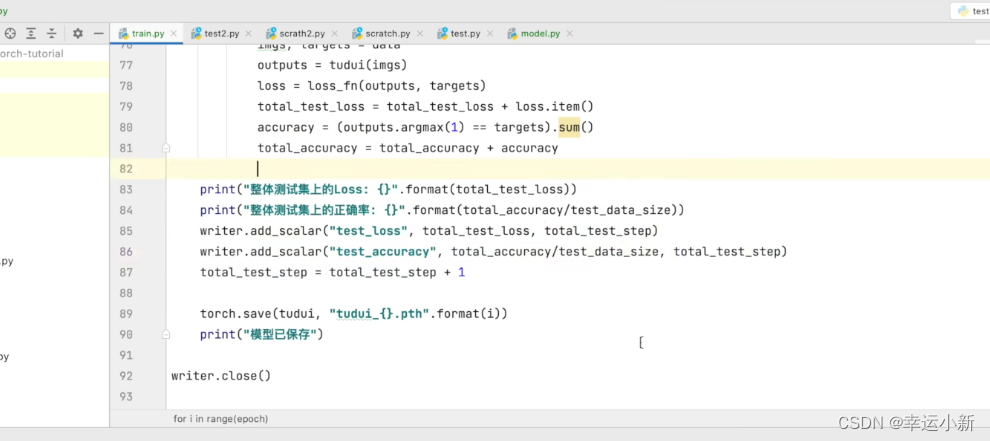
28.完整的模型训练套路(三)
有的代码在训练开始前会加上tuidui.train()
在测试前加上tuidui.eval()
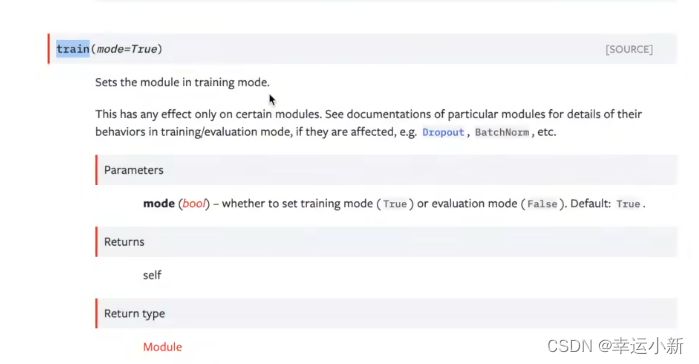
这两个不是必要的
官方文档说明了,这里只对例如dropout或者BatchNorm有作用
29.利用GPU训练(一)

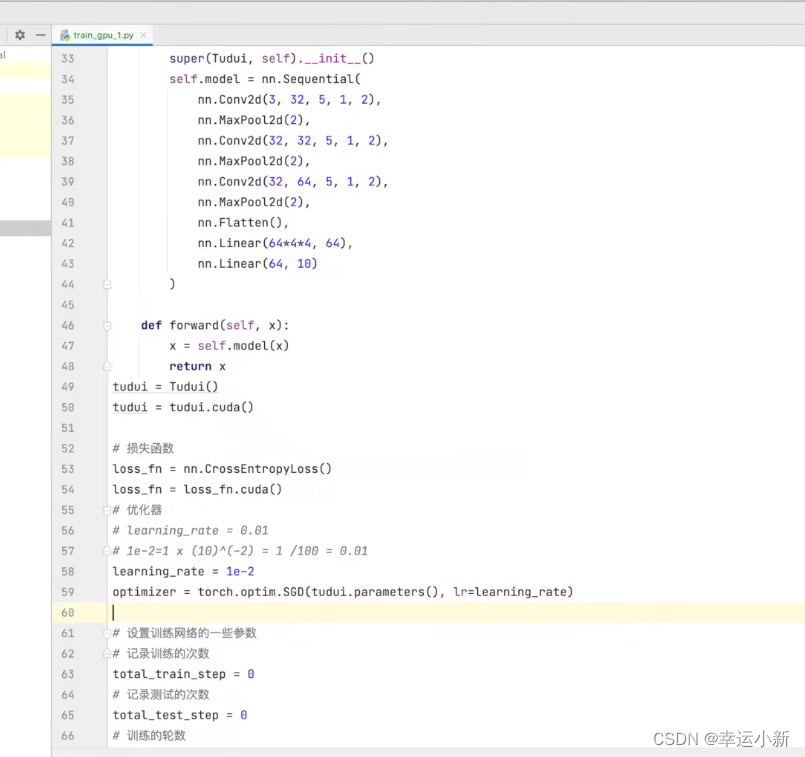
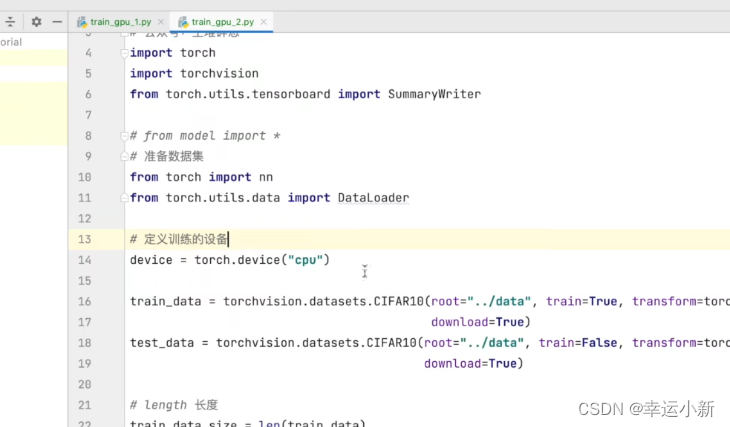
我们将网络模型和损失函数转移到cuda上
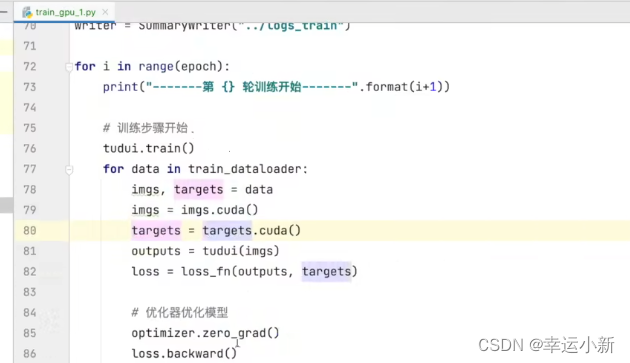
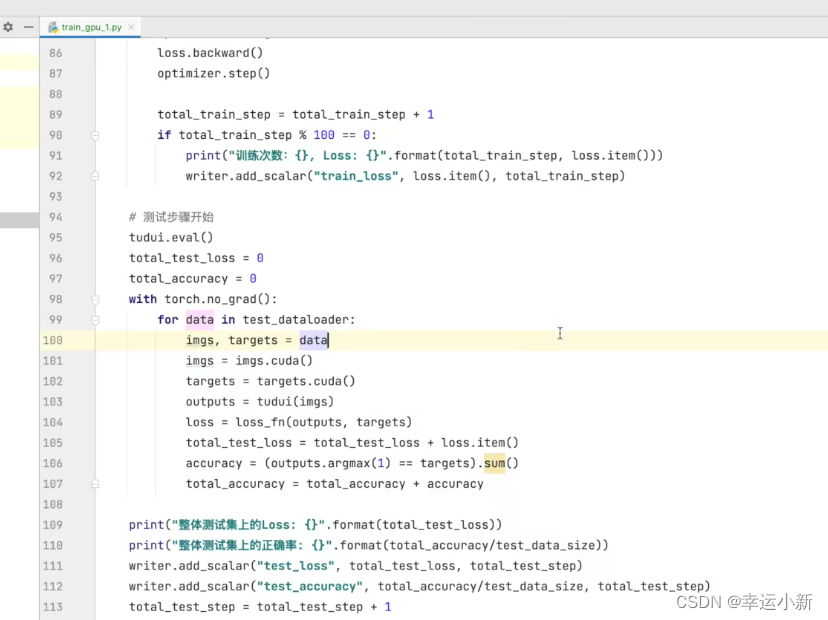
将训练和测试数据(img、targets)转移到cuda上
防止你的电脑没有GPU任何报错
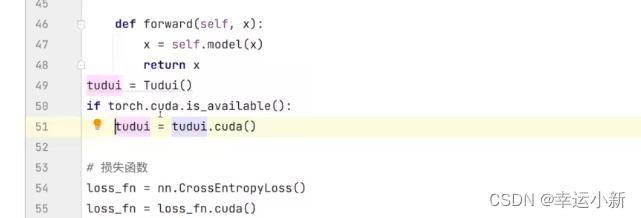
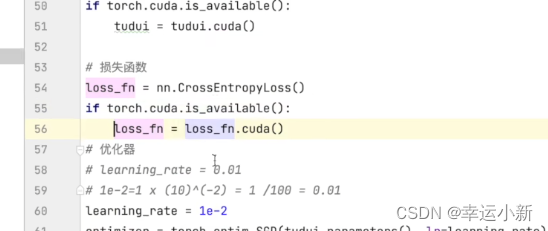
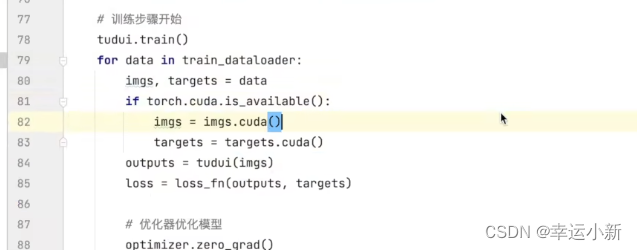
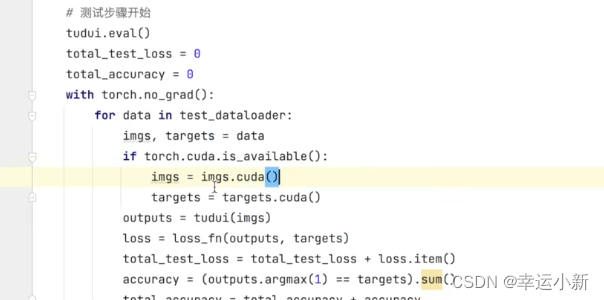
如果你的电脑没有GPU
30.利用GPU训练(二)
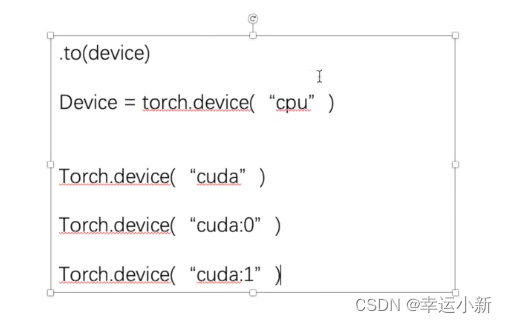

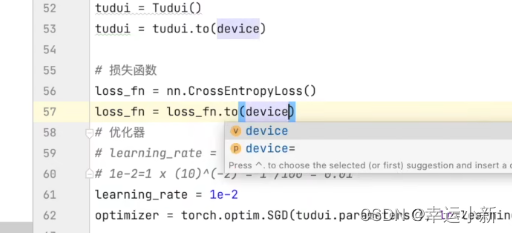

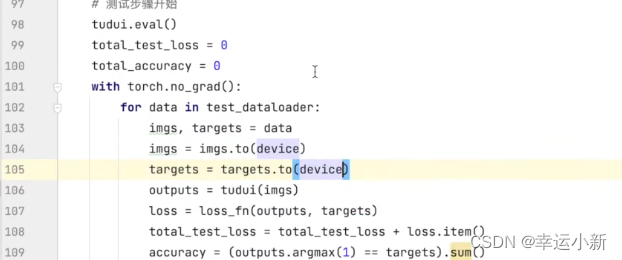
如果我们要在GPU上运行,则

31.完整的模型验证套路

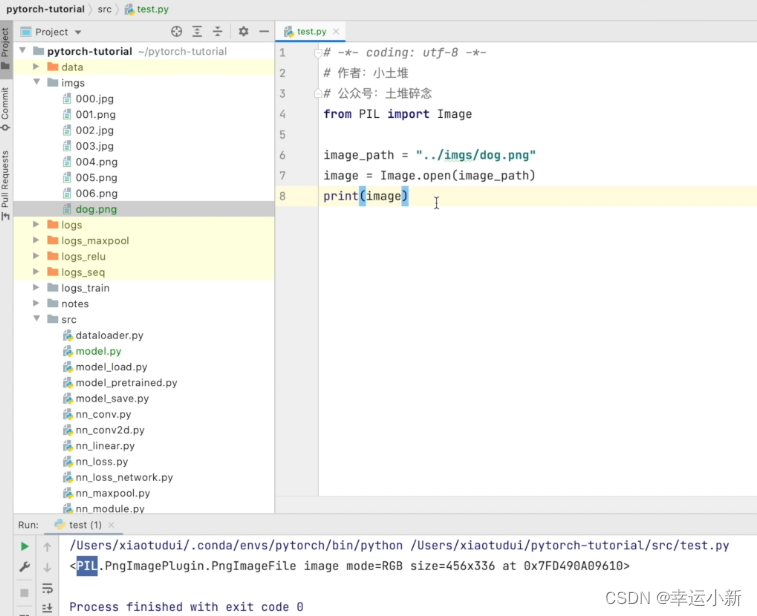
先将我们的图片变成了一个PIL类型

我们的dog的图片大小为456 * 336的
我们要将其变为32 * 32大小的,然后再变为totensor类型的
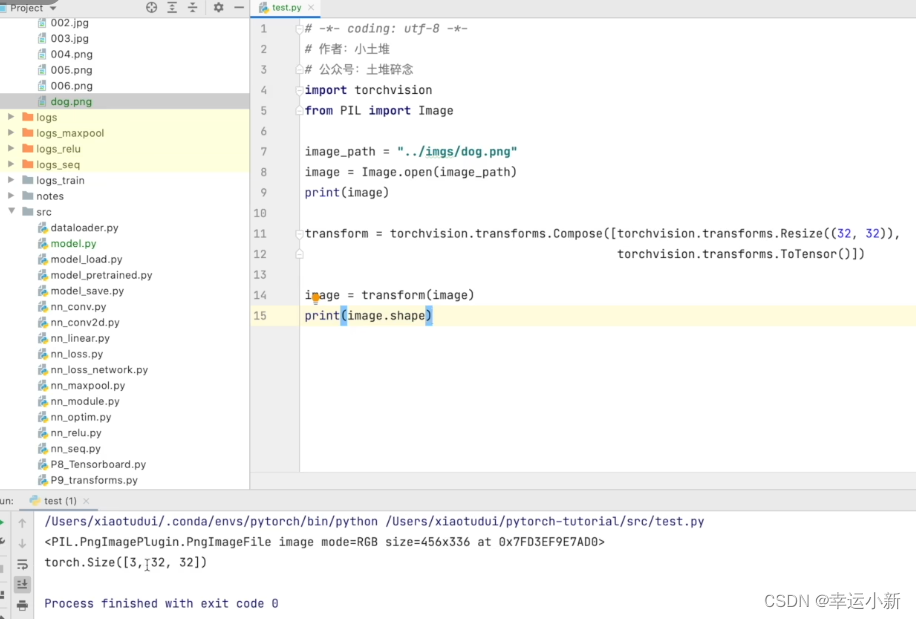
下面为我们就可以加载我们的网络模型
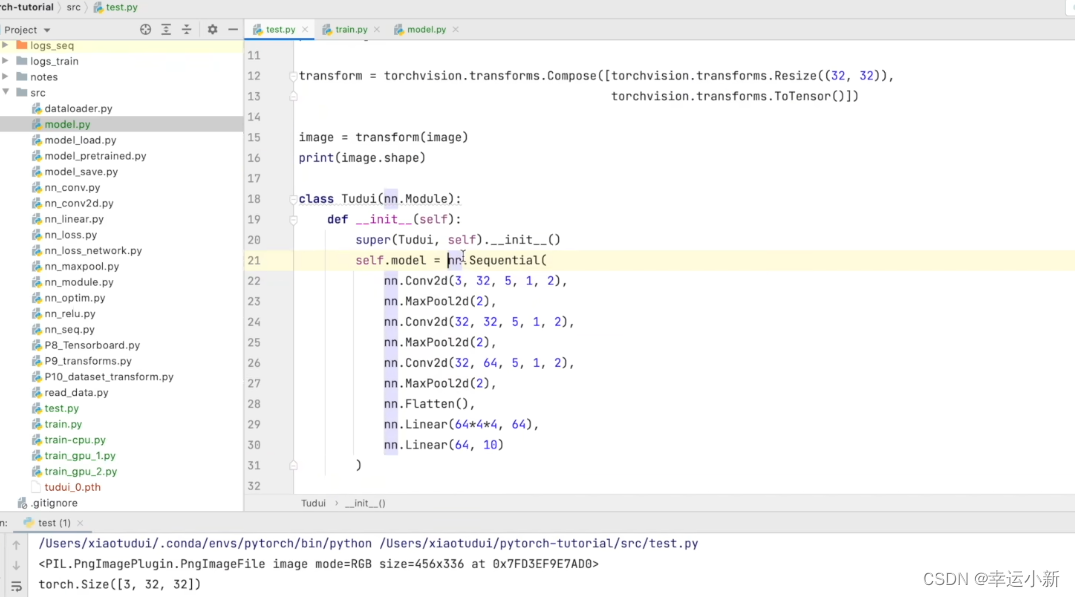
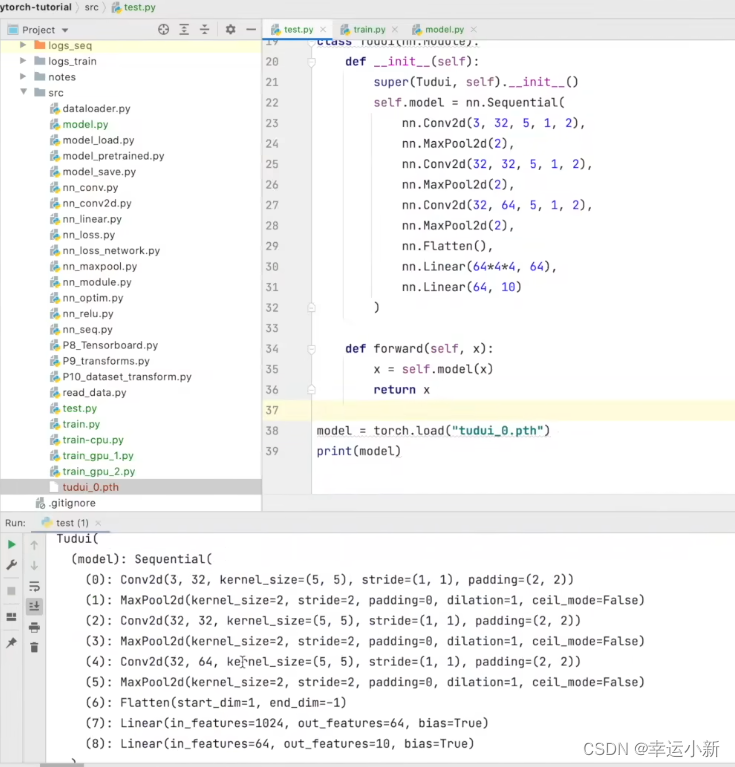
我们的网络模型就已经加载成功了
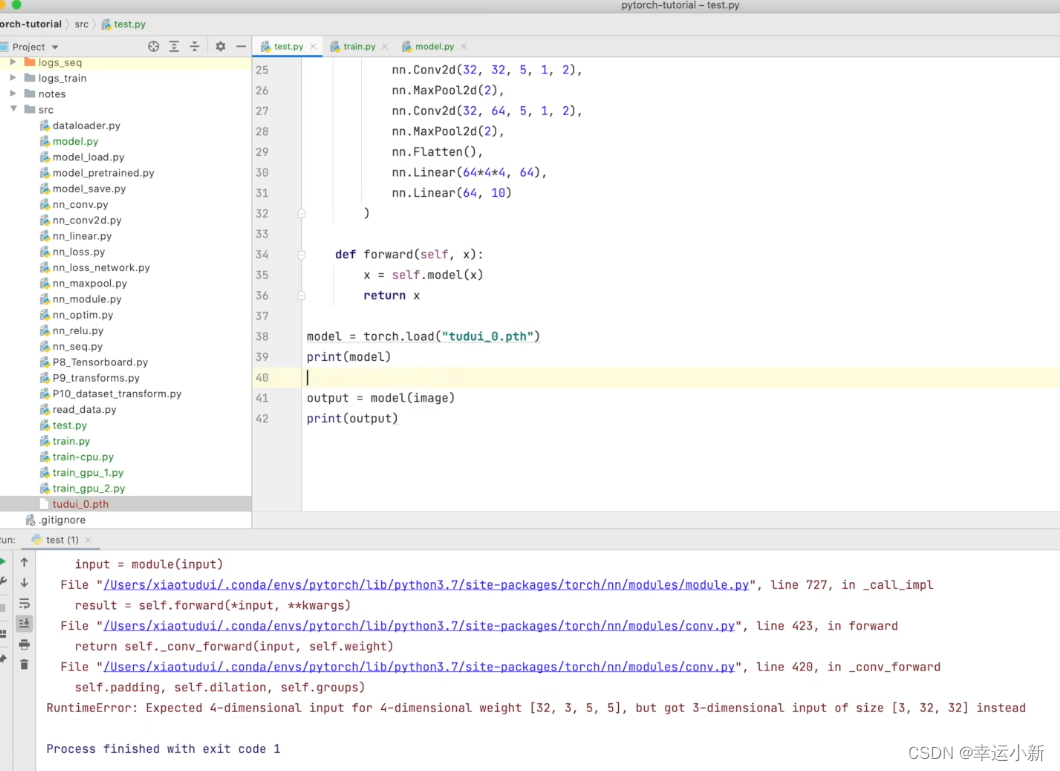
我们的尺度不符合,缺少batch_size
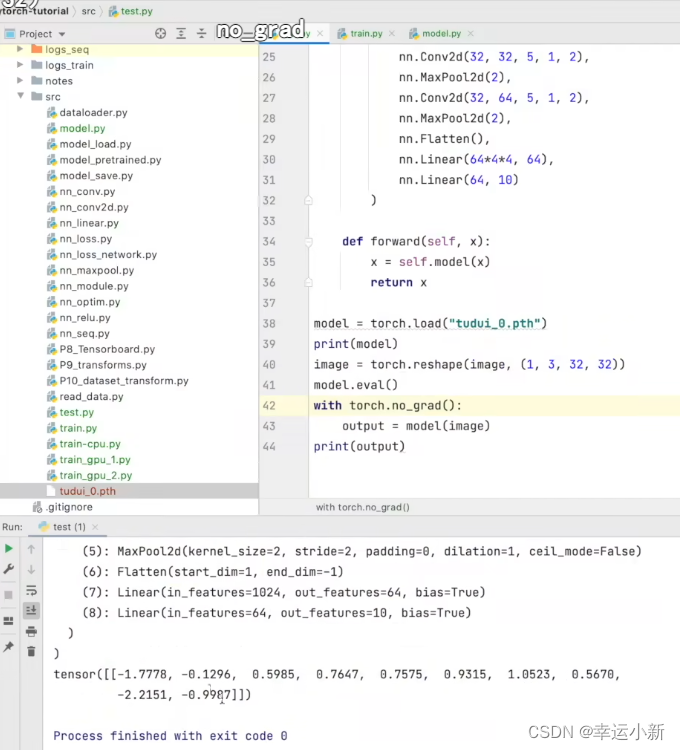
最后这个就我们预测出来的结果
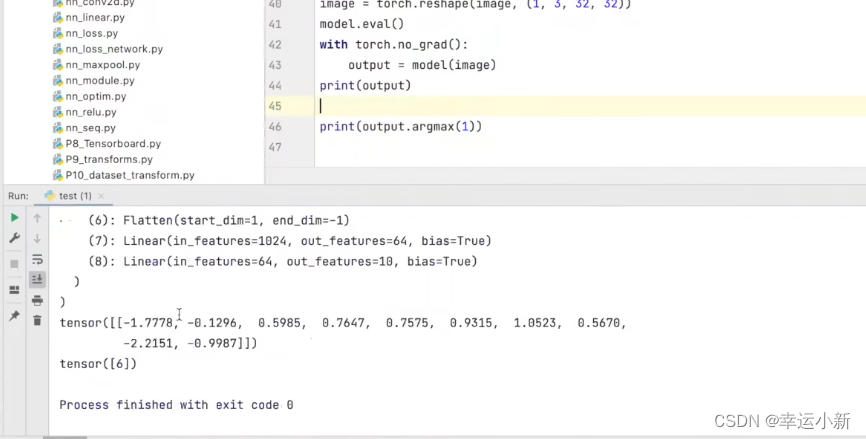
预测出来的结果是第6个类别
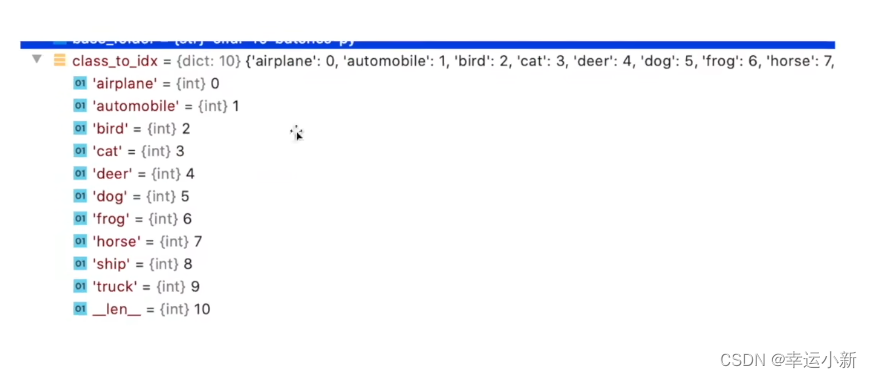
这个结果不太好
主要是我们的模型只训练了一轮
效果也不太好
我们换一个训练次数多一点的
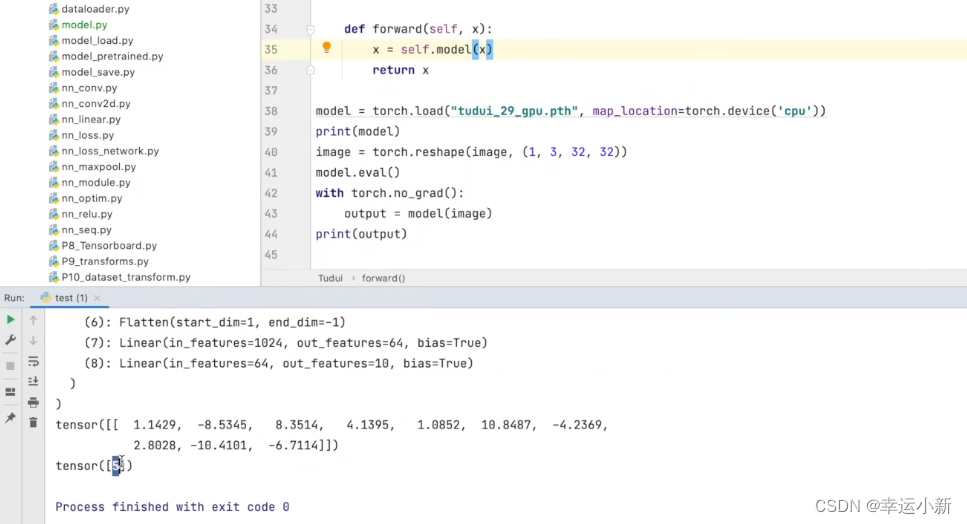
结果正确
32.开源项目

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









