







目录
缓存击穿问题及解决思路
-
缓存击穿也叫热点Key问题,就是一个被
高并发访问并且缓存重建业务较复杂的key突然失效了,那么无数请求访问就会在瞬间给数据库带来巨大的冲击 -
举个不太恰当的例子:一件秒杀中的商品的key突然失效了,大家都在疯狂抢购,那么这个瞬间就会有无数的请求访问去直接抵达数据库,从而造成缓存击穿
-
常见的解决方案有两种
- 互斥锁
- 逻辑过期
-
逻辑分析:假设线程1在查询缓存之后未命中,本来应该去查询数据库,重建缓存数据,完成这些之后,其他线程也就能从缓存中加载这些数据了。但是在线程1还未执行完毕时,又进来了线程2、3、4同时来访问当前方法,那么这些线程都不能从缓存中查询到数据,那么他们就会在同一时刻访问数据库,执行SQL语句查询,对数据库访问压力过大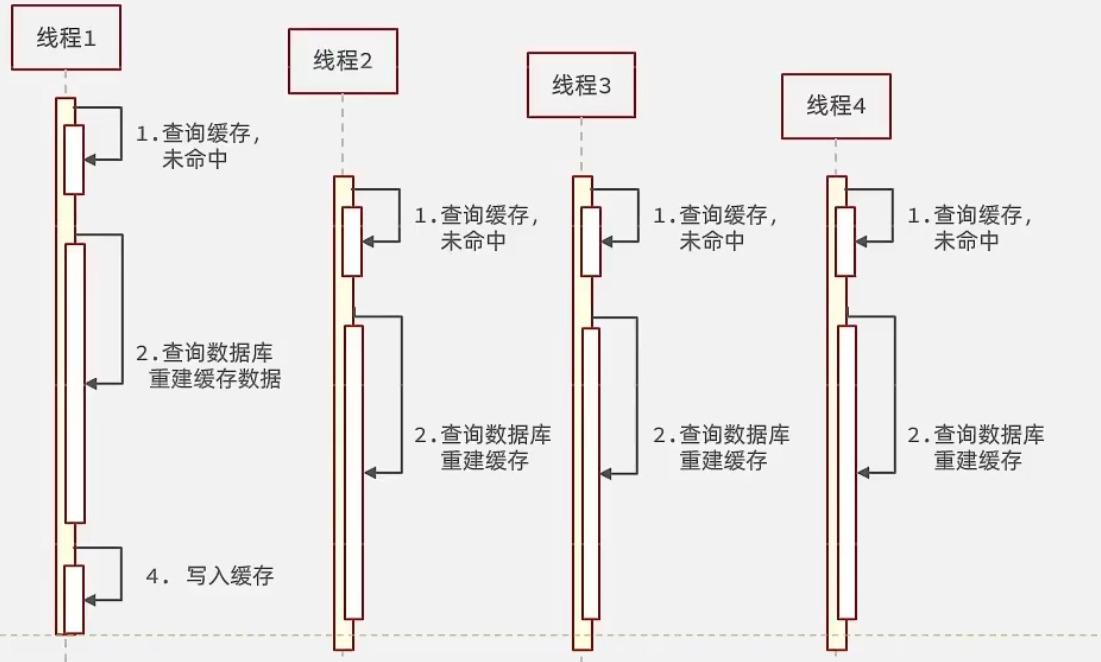
-
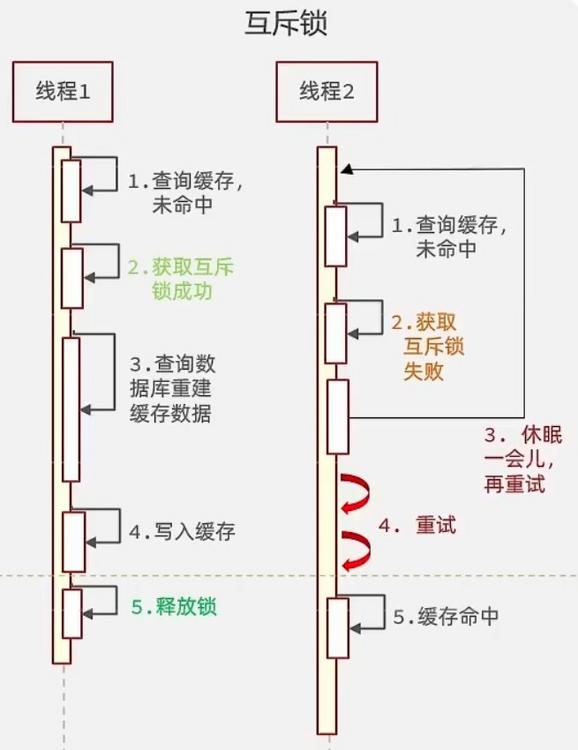
解决方案一:互斥锁 -
利用锁的互斥性,假设线程过来,只能一个人一个人的访问数据库,从而避免对数据库频繁访问产生过大压力,但这也会影响查询的性能,将查询的性能从并行变成了串行,我们可以采用tryLock方法+double check来解决这个问题
-
线程1在操作的时候,拿着锁把房门锁上了,那么线程2、3、4就不能都进来操作数据库,只有1操作完了,把房门打开了,此时缓存数据也重建好了,线程2、3、4直接从redis中就可以查询到数据。
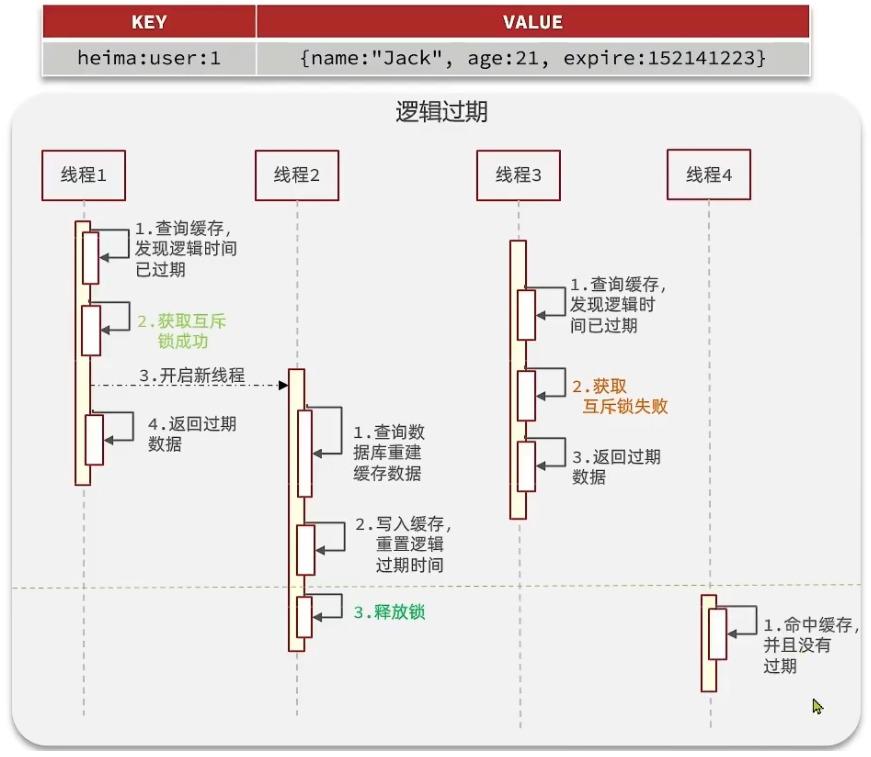
解决方案二:逻辑过期方案- 方案分析:我们之所以会出现缓存击穿问题,主要原因是在于我们对key设置了TTL,如果我们不设置TTL,那么就不会有缓存击穿问题,但是不设置TTL,数据又会一直占用我们的内存,所以我们可以采用逻辑过期方案
- 我们之前是TTL设置在redis的value中,注意:这个过期时间并不会直接作用于Redis,而是我们后续通过逻辑去处理。假设线程1去查询缓存,然后从value中判断当前数据已经过期了,此时线程1去获得互斥锁,那么其他线程会进行阻塞,获得了锁的进程他会开启一个新线程去进行之前的重建缓存数据的逻辑,直到新开的线程完成者逻辑之后,才会释放锁,而线程1直接进行返回,假设现在线程3过来访问,由于线程2拿着锁,所以线程3无法获得锁,线程3也直接返回数据(但只能返回旧数据,牺牲了数据一致性,换取性能上的提高),只有等待线程2重建缓存数据之后,其他线程才能返回正确的数据
- 这种方案巧妙在于,异步构建缓存数据,缺点是在重建完缓存数据之前,返回的都是脏数据
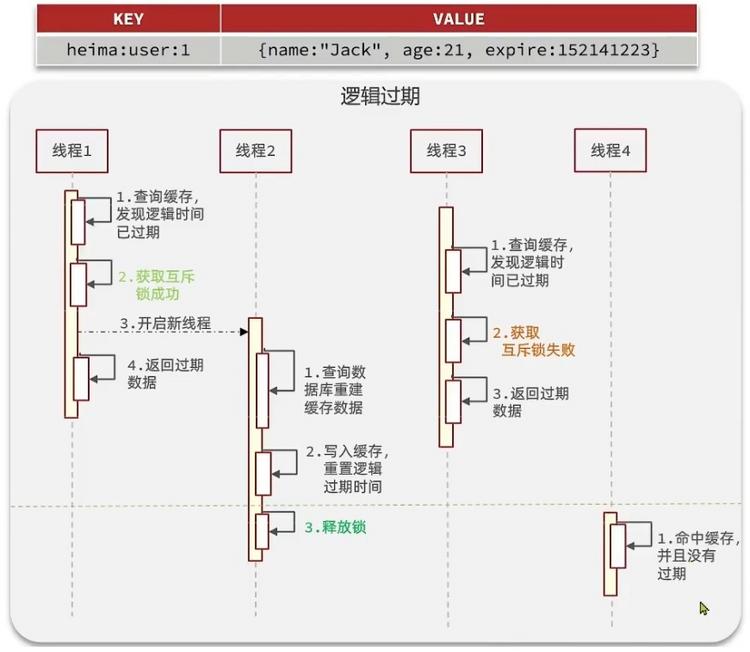
对比互斥锁与逻辑删除
互斥锁方案:由于保证了互斥性,所以数据一致,且实现简单,只是加了一把锁而已,也没有其他的事情需要操心,所以没有额外的内存消耗,缺点在于有锁的情况,就可能死锁,所以只能串行执行,性能会受到影响逻辑过期方案:线程读取过程中不需要等待,性能好,有一个额外的线程持有锁去进行重构缓存数据,但是在重构数据完成之前,其他线程只能返回脏数据,且实现起来比较麻烦
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | 没有额外的内存消耗 保证一致性 实现简单 | 线程需要等待,性能受影响 可能有死锁风险 |
| 逻辑过期 | 线程无需等待,性能较好 | 不保证一致性 有额外内存消耗 实现复杂 |
利用互斥锁解决缓存击穿问题
-
核心思路:相较于原来从缓存中查询不到数据后直接查询数据库而言,现在的方案是,进行查询之后,如果没有从缓存中查询到数据,则进行互斥锁的获取,获取互斥锁之后,判断是否获取到了锁,如果没获取到,则休眠一段时间,过一会儿再去尝试,知道获取到锁为止,才能进行查询 -
如果获取到了锁的线程,则进行查询,将查询到的数据写入Redis,再释放锁,返回数据,利用互斥锁就能保证只有一个线程去执行数据库的逻辑,防止缓存击穿
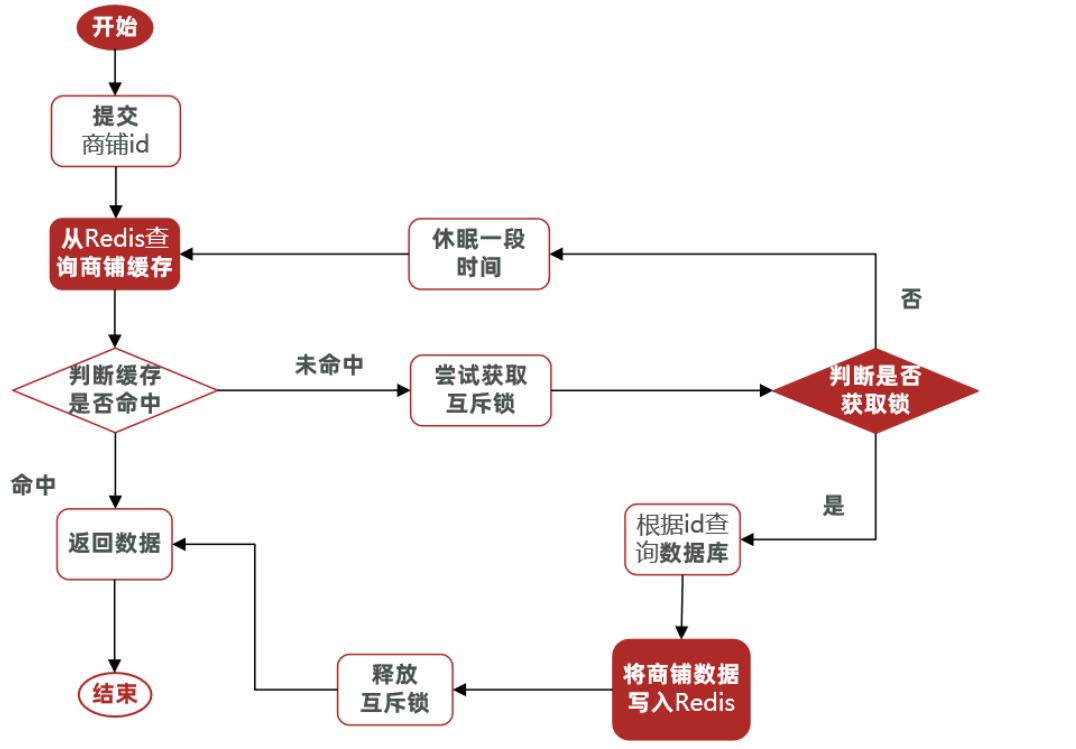
-
操作锁的代码 -
核心思路就是利用redis的setnx方法来表示获取锁,如果redis没有这个key,则插入成功,返回1,如果已经存在这个key,则插入失败,返回0。在StringRedisTemplate中返回true/false,我们可以根据返回值来判断是否有线程成功获取到了锁

- tryLock//生成锁
-
private boolean tryLock(String key) { Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS); //避免返回值为null,我们这里使用了BooleanUtil工具类 return BooleanUtil.isTrue(flag); } - unlock//释放锁
-
private void unlock(String key) { stringRedisTemplate.delete(key); }@Override public Shop queryWithMutex(Long id) { //先从Redis中查,这里的常量值是固定的前缀 + 店铺id String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id); //如果不为空(查询到了),则转为Shop类型直接返回 if (StrUtil.isNotBlank(shopJson)) { Shop shop = JSONUtil.toBean(shopJson, Shop.class); return shop; } if (shopJson != null) { return null; } Shop shop = null; try { //否则去数据库中查 boolean flag = tryLock(LOCK_SHOP_KEY + id); if (!flag) { Thread.sleep(50); return queryWithMutex(id); } //查不到,则将空值写入Redis shop = getById(id); if (shop == null) { stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, "", CACHE_NULL_TTL, TimeUnit.MINUTES); return null; } //查到了则转为json字符串 String jsonStr = JSONUtil.toJsonStr(shop); //并存入redis,设置TTL stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, jsonStr, CACHE_SHOP_TTL, TimeUnit.MINUTES); //最终把查询到的商户信息返回给前端 } catch (InterruptedException e) { throw new RuntimeException(e); } finally { unlock(LOCK_SHOP_KEY + id); } return shop; }使用try/catch/finally包裹,因为不管前面是否会有异常,最终都必须释放锁
- 使用Jmeter进行测试
- 我们先来模拟一下缓存击穿的情景,缓存击穿是指在某时刻,一个热点数据的TTL到期了,此时用户不能从Redis中获取热点商品数据,然后就都得去数据库里查询,造成数据库压力过大。
- 那么我们首先将Redis中的热点商品数据删除,模拟TTL到期,然后用Jmeter进行压力测试,开100个线程来访问这个没有缓存的热点数据
- 如果后台日志只输出了一条SQL语句,则说明我们的互斥锁是生效的,没有造成大量用户都去查询数据库,执行SQL语句
asciidoc

- 如果日志输出了好多SQL语句,则说明我们的代码有问题
利用逻辑过期解决缓存击穿问题
- 需求:根据id查询商铺的业务,基于逻辑过期方式来解决缓存击穿问题
- 思路分析:当用户开始查询redis时,判断是否命中
- 如果没有命中则直接返回空数据,不查询数据库
- 如果命中,则将value取出,判断value中的过期时间是否满足
- 如果没有过期,则直接返回redis中的数据
- 如果过期,则在开启独立线程后,直接返回之前的数据,独立线程去重构数据,重构完成后再释放互斥锁
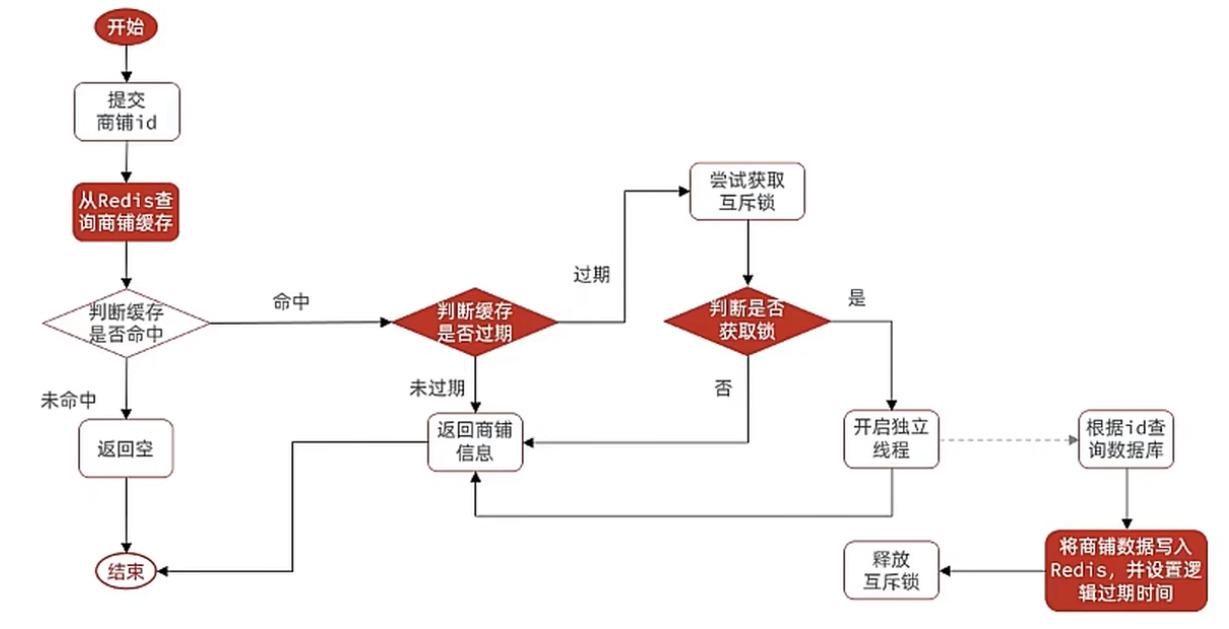
- 封装数据:因为现在redis中存储的数据的value需要带上过期时间,此时要么你去修改原来的实体类,要么新建一个类包含原有的数据和过期时间
- 这里我们选择新建一个实体类,包含原有数据(用万能的Object)和过期时间,这样对原有的代码没有侵入性
-
@Data public class RedisData<T> { private LocalDateTime expireTime; private T data; } 步骤二- 在ShopServiceImpl中新增方法,进行单元测试,看看能否写入数据
-
public void saveShop2Redis(Long id, Long expirSeconds) { Shop shop = getById(id); RedisData redisData = new RedisData(); redisData.setData(shop); redisData.setExpireTime(LocalDateTime.now().plusSeconds(expirSeconds)); stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData)); } - 编写测试方法
@SpringBootTest class HmDianPingApplicationTests { @Autowired private ShopServiceImpl shopService; @Test public void test(){ shopService.saveShop2Redis(1L,1000L); } } - 运行测试方法,去Redis图形化页面看到存入的value,确实包含了data和expireTime1
步骤三:正式代码
正式代码我们就直接照着流程图写就好了-
//这里需要声明一个线程池,因为下面我们需要新建一个现成来完成重构缓存 private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10); @Override public Shop queryWithLogicalExpire(Long id) { //1. 从redis中查询商铺缓存 String json = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id); //2. 如果未命中,则返回空 if (StrUtil.isBlank(json)) { return null; } //3. 命中,将json反序列化为对象 RedisData redisData = JSONUtil.toBean(json, RedisData.class); //3.1 将data转为Shop对象 JSONObject shopJson = (JSONObject) redisData.getData(); Shop shop = JSONUtil.toBean(shopJson, Shop.class); //3.2 获取过期时间 LocalDateTime expireTime = redisData.getExpireTime(); //4. 判断是否过期 if (LocalDateTime.now().isBefore(time)) { //5. 未过期,直接返回商铺信息 return shop; } //6. 过期,尝试获取互斥锁 boolean flag = tryLock(LOCK_SHOP_KEY + id); //7. 获取到了锁 if (flag) { //8. 开启独立线程 CACHE_REBUILD_EXECUTOR.submit(() -> { try { this.saveShop2Redis(id, LOCK_SHOP_TTL); } catch (Exception e) { throw new RuntimeException(e); } finally { unlock(LOCK_SHOP_KEY + id); } }); //9. 直接返回商铺信息 return shop; } //10. 未获取到锁,直接返回商铺信息 return shop; }


















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









