






概述:
数据集:来源于测试时自然收集的数据集,包括传感器观测数据、执行的动作、是否处于自主模式
预测模型:当前观测值和一系列未来的控制动作作为输入,并预测机器人未来是否仍处于自主模式
测试:利用预测模型规划并执行能够最小化退出概率的动作,同时保证机器人向目标位置前进。
特点:
无需额外数据,只需要原本测试过程中就会收集的数据
直接从退出事件中学习,将其直接作为监督信号
不依赖高精度地图或复杂的环境建模,只需自身传感器的数据
在测试过程中不断收集数据,是模型不断优化
相关工作:
基于学习的方法:直接学习环境的导航提示(如深度估计、物体检测和道路分割),但是这类方法训练成本极高
模仿学习:训练一个策略模型,使其模仿专家的行为,但局限在视觉上较为简单的环境,且为了增加数据多样性,需要在专家策略中注入随机噪声,但这会带来安全风险。
强化学习:机器人通过试错来学习,通常在模拟环境中训练策略,然后迁移到现实环境;或者直接从机器人自身的经验中学习,但是会诸多限制
从退出事件中学习导航:
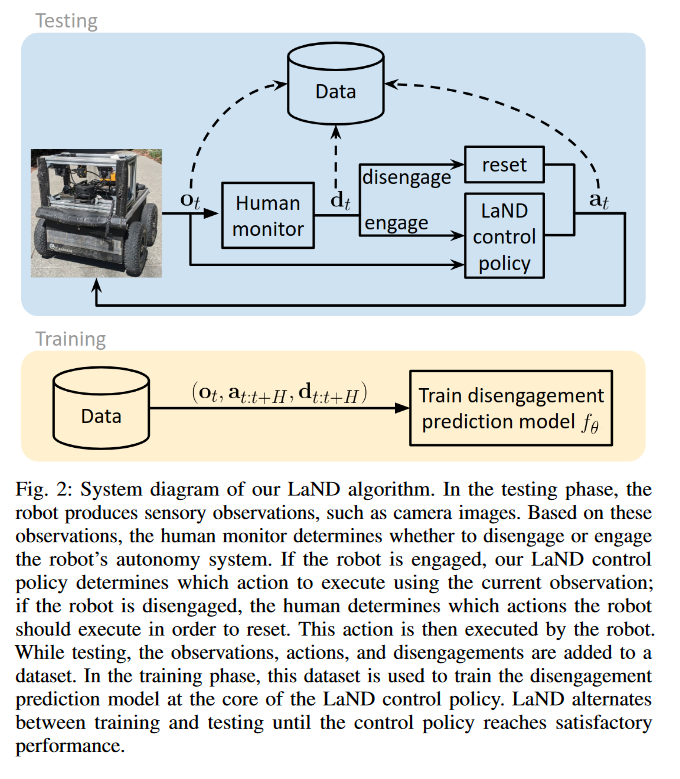
数据收集:
观测值Ot:是一个96×192 像素的 RGB 图像,由前向单目相机(170° 视场角) 采集
动作at:控制机器人的指令,这里是期望的航向变化角度
退出信号dt:由人类监控员通过远程监控器给出的一个二值信号
数据收集的过程:机器人执行自主控制的策略,人类监测员实时观察,如果出现故障则手动退出自主模式,然后由人类手动调整至正常位置并重新自主控制。
三种典型的退出场景:碰到障碍物、驶入机动车道、驶入住宅车道
在收集过程中,每0.5米就储存当前时刻的ot、at和dt,这些数据被存入训练集D用于训练预测模型
预测模型:
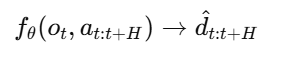
给定ot和一系列未来H步的at,预测未来H步的dt
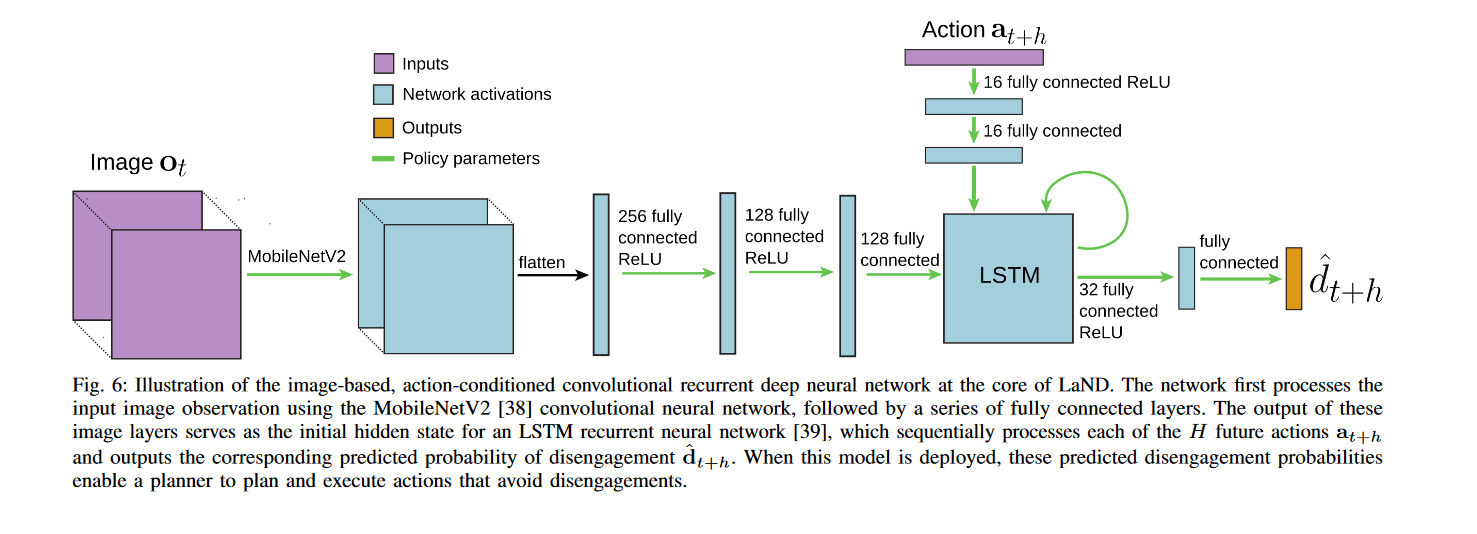
输入层:CNN(MobileNetV2),用于处理传感器观测的RGB图像
全连接层:将CNN的输出映射到一个低维嵌入空间,作为LSTM递归网络的初始隐藏状态
LSTM:逐步处理H个未来动作,输出H个对应的预测dt
损失函数:最小化交叉熵损失
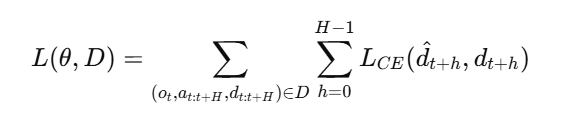
优化策略:训练时,批量数据中50%包含退出事件,防止退出数据太低;扩展退出状态
规划与控制:
测试时,机器人利用训练好的预测模型,通过最小化损失函数去选择那些能最大程度避免退出的动作
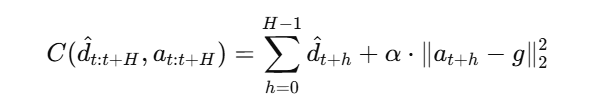
第一项鼓励机器人避免退出, 第二项鼓励机器人向目标方向移动,超参数α控制二者的权衡,g 是目标航向(遇到路口时:左转、右转或直行,没有路口时:设置α=0)
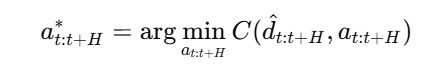
机器人在每个时间步求解最优动作,然后执行第一个动作,重复该过程(零阶随机优化算法求解)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









