






引言:
我们身处大数据时代,我们都知道在大数据时代,数据即为重点且可以说是值钱。
数据来源:
- 国家统计局网站获取
- 到第三方公司购买数据
- 通过爬虫爬取数据
- 人工收集数据(如问卷调查)
一、什么是爬虫
定义:爬虫(Web Crawler) 是一种自动获取网页信息的程序或脚本,也称为网络蜘蛛或网络机器人。
二、学习爬虫的目的
爬虫可以帮助我们快速、自动地获取互联网上的各种数据,包括新闻、天气、价格、股票数据等,这些数据对于研究、分析和决策都非常有用,并且当我们写论文时也不可避免地需要大量数据。
三、爬虫的用途
- 搜索引擎:爬虫可以自动地、大规模地抓取互联网上的网页信息,并将这些网页数据进行分析、处理和存储,以供搜索引擎的索引和搜索功能使用。
- 数据分析:爬虫能够自动化地从各种网站、社交媒体平台等在线资源中收集大量数据。这些数据可以包括文本、图片、视频、链接等,为数据分析提供丰富的原材料。
- 舆情分析
- 信息监控
- 信息聚合
- 应用开发
四、爬虫的分类
一、通用爬虫
通用爬虫是一种能够自动抓取互联网上各种网站信息的爬虫,它们不针对特定的网站,而是通过智能化的方式发现和抓取网页。比如百度、谷歌、搜狗等搜索引擎的数据都是通过通用爬虫抓取而来的。通用爬虫一般用于搜索引擎等需要广泛收集网页信息的应用中,具有以下特点:
- 广泛性:通用爬虫可以访问和抓取互联网上的绝大多数网站,具有很强的覆盖能力。
- 自动化:通用爬虫能够自动发现和抓取网页,无需人工干预,提高了效率。
- 智能化:通用爬虫通常会根据网页连接关系进行智能化的抓取,以尽可能全面地收集网页信息。
- 持续性:通用爬虫可以持续地抓取网页信息,保持数据的更新和完整性。
- 去重处理:通用爬虫会对抓取到的网页进行去重处理,避免重复抓取相同内容。
- 性能优化:通用爬虫会针对不同类型的网站和网络环境进行性能优化,提高抓取效率。
二、聚焦爬虫
聚焦爬虫是一种针对特定网站或特定类型网站进行定制开发的爬虫程序。与通用爬虫不同,聚焦爬虫的抓取范围更为有限,主要用于针对特定需求或特定网站的数据抓取。聚焦爬虫有以下特点:
- 定制性强:聚焦爬虫根据特定需求定制开发,可以针对性地抓取目标网站的特定信息。
- 精准度高:由于定位明确,聚焦爬虫可以精准地抓取目标网站的所需信息,减少无效数据的抓取。
- 效率高:相比普通爬虫,聚焦爬虫只需抓取目标网站的特定内容,因此效率更高,消耗的资源更少。
- 隐蔽性强:聚焦爬虫一般不会频繁访问大量网站,降低了被目标网站封禁的风险。
- 数据处理:聚焦爬虫通常会对抓取到的数据进行处理和分析,以便更好地满足特定需求。
- 定时更新:聚焦爬虫可以定时更新目标网站的数据,保持数据的新鲜性和有效性。
三、增量式爬虫
增量式爬虫则会在上一次抓取的基础上,只抓取新增或有更新的数据,从而减少了重复抓取和提高了效率,增量式爬虫适用于需要频繁更新数据的场景,比如新闻网站、论坛等内容更新较快的网站。通过增量式爬虫,可以及时获取到最新的数据,保持数据的及时性和准确性。
四、深层网络爬虫
深层网络爬虫专门用来抓取存在于互联网深层的页面,这些页面通常是非结构化的,需要通过特定的查询参数或请求才能访问。深层网络爬虫可能需要更多的技术和资源来实现高效的网页抓取。
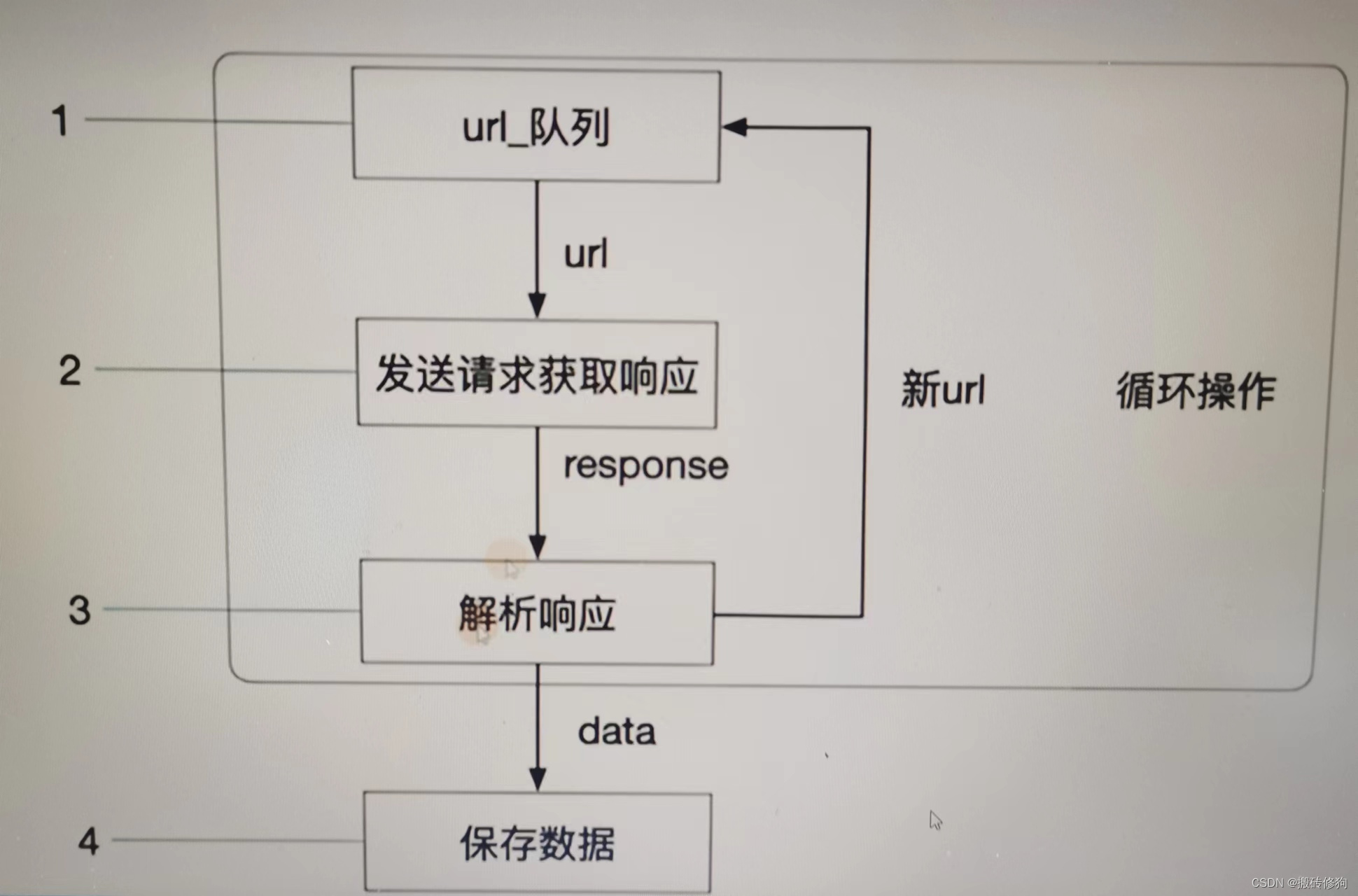
五、爬虫的工作流程
- 发送请求:爬虫首先发送HTTP请求到目标网站
- 获取响应:获取请求返回的相应内容
- 解析响应、提取数据:爬虫解析响应内容,提取需要的信息,比如url链接、文本数据等
- 存储数据:爬虫将提取的信息存储到本地文件或数据库中。
六、robots协议
Robots协议(也称为robots.txt) 是一个位于网站根目录下的文本文件,用于指示搜索引擎爬虫哪些页面可以访问,哪些页面不应该被访问。该文件包含一系列规则,定义了爬虫对网站的访问权限。
- User-agent:指定了爬虫的名称或标识符
- Disallow:指定了不允许被访问的URL路径。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











