






1. vLLM简介
vLLM(Vectorized Large Language Model Serving System)是由加州大学伯克利分校团队开发的高性能、易扩展的大语言模型(LLM)推理引擎,专注于通过创新的内存管理和计算优化技术实现高吞吐、低延迟、低成本的模型服务。vLLM采用PagedAttention内存管理技术,显著提升GPU显存利用率,同时支持分布式推理,能高效利用多机多卡资源。无论是低延迟、高吞吐的在线服务,还是资源受限的边缘部署场景,vLLM 都能提供卓越的性能表现。
-
中文站点:https://vllm.hyper.ai/docs/
-
英文站点:https://docs.vllm.ai/en/latest/index.html
2. ModelScope简介
ModelScope是一个由阿里巴巴集团推出的开源模型即服务(MaaS)平台,旨在简化模型应用的过程,为AI开发者提供灵活、易用、低成本的一站式模型服务产品。该平台汇集了多种最先进的机器学习模型,涵盖自然语言处理、计算机视觉、语音识别等多个领域,并提供丰富的API接口和工具,使开发人员能够轻松地集成和使用这些模型。
- 官方网站:https://modelscope.cn/models
安装ModelScope
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
创建存储目录
mkdir -p /data/Qwen/models/Qwen-32B
下载QwQ-32B模型
modelscope download --local_dir /data/Qwen/models/Qwen-32B --model Qwen/QWQ-32B
3. 启用与优化NVIDIA GPU
更新软件包列表
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
配置NVIDIA容器运行时
sudo nvidia-ctk runtime configure --runtime=docker
重启服务
sudo systemctl daemon-reload && sudo systemctl restart docker
4. 运行vLLM容器
拉取镜像
docker pull docker.1panel.live/vllm/vllm-openai
启动vLLM容器
docker run -itd --restart=always --name Qwen-32B \` `-v /data/Qwen:/data \` `-p 18005:8000 \` `--gpus '"device=1,2,3,4"' \` `--ipc=host --shm-size=16g \` `vllm/vllm-openai:latest \` `--dtype bfloat16 \` `--served-model-name Qwen-32B \` `--model "/data/models/Qwen-32B" \` `--tensor-parallel-size 4 \` `--gpu-memory-utilization 0.95 \` `--max-model-len 81920 \` `--api-key token-abc123 \` `--enforce-eager
Docker命令参数解析详解
-
-i(interactive):允许用户与容器进行交互,即使容器不在前台运行。用户可以通过
docker logs或docker attach命令查看容器的输出日志 -
-t(tty):分配一个伪TTY(虚拟终端)到容器,模拟终端环境。
-
-d(detach:在后台运行容器,不占用当前终端。
-
–restart=always:设置容器在主机重启或容器退出后自动重启。
-
–name Qwen-32B:为容器指定一个唯一的名称。
-
-v /data/Qwen:/data:将宿主机上的
/data/Qwen目录挂载到容器内的/data目录。避免容器重启或删除而导致的数据丢失问题。 -
-p 18005:8000:将宿主机的18005端口映射到容器内的8000端口。
-
–gpus ‘“device=1,2,3,4”’:指定容器使用宿主机上的GPU设备1、2、3、4。
-
–ipc=host:共享宿主机的IPC(进程间通信)命名空间,允许容器与宿主机的进程进行通信。
VLLM模型启动参数
-
–dtype bfloat16:指定使用bfloat16(Brain Floating Point 16)进行模型计算。
-
–served-model-name Qwen-32B:设置模型的服务名称为“Qwen-32B”,用于API请求时的模型标识。
-
–model “/data/models/Qwen-32B”:指定模型文件的路径为容器内的
/data/models/Qwen-32B。 -
–tensor-parallel-size 4:设置张量并行的规模为4,对应使用4块GPU进行模型并行计算。
-
–gpu-memory-utilization 0.85:设置GPU内存使用率为85%,预留15%的内存空间,防止因内存溢出导致的程序崩溃。
-
–max-model-len 81920:指定模型的最大上下文长度为81920 Token。模型在单次推理中可以处理的输入和输出的总Token数不超过81920个。
-
–api-key token-abc123:设置API访问密钥为“token-abc123”,调用API时需要在请求头中提供此密钥。
-
–enforce-eager:启用Eager执行模式,确保模型推理时逐层计算,避免由于延迟执行可能引发的内存问题。
5. Open Web UI部署
拉取open-webui镜像
docker pull ghcr.nju.edu.cn/open-webui/open-webui:main
启动Open Web UI
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway \` `-v /data/open-webui:/app/backend/data \` `--name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:main
访问Web界面
浏览器访问:http://localhost:3000

管理员面板–外部链接–新建模型连接
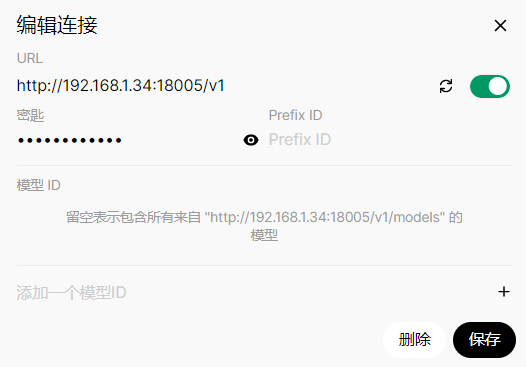
模型ID留空即可自动从/v1/models接口中获取,开启新对面默认选择DeepSeek-R1-Distill-Llama-70B模型
开启新对话
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 1801
1801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









